- 浏览: 1415781 次
- 性别:

- 来自: 广州
-

文章分类
最新评论
-
sdgxxtc:
[quo[color=red]te][/color]
C#使用OleDb读取Excel,生成SQL语句 -
zcs302567601:
博主,你好,一直都有个问题没有搞明白,就是 2.x的版本是通过 ...
NGUI所见即所得之UIPanel -
一样的追寻:
感谢楼主!
有向强连通和网络流大讲堂——史无前例求解最大流(最小割)、最小费用最大流 -
cp1993518:
感谢!从你的博客里学到了很多
Unity日志工具——封装,跳转 -
cp1993518:
学习了~,话说现在的版本custom还真的变委托了
NGUI所见即所得之UIGrid & UITable
排序算法群星豪华大汇演
排序算法相对简单些,但是由于它的家族比较庞大——这也许是因为简单的缘故吧,网上整理排序算法实在太多了,什么经典排序算法,八大排序算法总结,精通八大排序算法等枚不胜举,当然这里也不例外,同样是整理,同样是学习的过程。
之前一些排序算法总是说不清楚(作者自己的感受),这倒不是因为太难,作者觉得是因为排序算法太繁复了(一些算法之间的区别不是很明显),那也没有他法,只有各个击破,认真理解每个排序的原理。经过一段时间的学习和整理,已经剧本一定的规模,故作一个总览,方便查阅。
当然,对于浩大的排序算法,这里只能列举部分,对其进行分别介绍,有的介绍相对简单,有的比较反复,日后有时间学习再详加论述,可能有些读者会觉得每个算法讲解时间复杂度(其实都尽力覆盖)和应用会相对少点(作者也是一直这么期待多点应用),但是作者觉得这些都是建立在对算法原理的充分理解的基础上的,换句话说,如果能充分理解算法的真谛,时间复杂度和空间复杂度那其实不是信手拈来的事吗,至于应用主要是要结合实际问题,就想人生的阅历一样只有在漫长时间的浸泡才会逐渐丰满起来,所以学习切勿本末倒置,孰能生巧(掌握基本的排序算法,混合排序算法(作者没有进行整理,作者认为只要充分掌握基本的原理,遇到实际问题自然就会想到的)就不在话下了才是学习真正在的过程,学习是要学习融会贯通的能力,当然这也需要积累的过程。
下面再附上维基百科的对Sort Algorithm的整理:
Comparison of algorithms
In this table, n is the number of records to be sorted. The columns "Average" and "Worst" give the time complexity in each case, under the assumption that the length of each key is constant, and that therefore all comparisons, swaps, and other needed operations can proceed in constant time. "Memory" denotes the amount of auxiliary storage needed beyond that used by the list itself, under the same assumption. These are all comparison sorts. The run time and the memory of algorithms could be measured using various notations like theta, omega, Big-O, small-o, etc. The memory and the run times below are applicable for all the 5 notations.
| Quicksort | 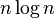 |
|
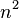 |
 |
Depends | Partitioning | Quicksort is usually done in place with O(log(n)) stack space.[citation needed] Most implementations are unstable, as stable in-place partitioning is more complex. Naïve variants use an O(n) space array to store the partition.[citation needed] |
| Merge sort | 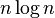 |
|
|
Depends; worst case is  |
Yes | Merging | Highly parallelizable (up to O(log(n))) for processing large amounts of data. |
| In-place Merge sort |  |
|
 |
 |
Yes | Merging | Implemented in Standard Template Library (STL);[2]can be implemented as a stable sort based on stable in-place merging.[3] |
| Heapsort | |
|
|
|
No | Selection | |
| Insertion sort | |
|
|
|
Yes | Insertion | O(n + d), where d is the number of inversions |
| Introsort | |
|
|
|
No | Partitioning & Selection | Used in SGI STL implementations |
| Selection sort | |
|
|
|
No | Selection | Stable with O(n) extra space, for example using lists.[4] Used to sort this table in Safari or other Webkit web browser.[5] |
| Timsort | 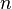 |
|
|
|
Yes | Insertion & Merging |
comparisons when the data is already sorted or reverse sorted. |
| Shell sort | |
 or  |
Depends on gap sequence; best known is |
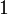 |
No | Insertion | |
| Bubble sort | |
|
|
|
Yes | Exchanging | Tiny code size |
| Binary tree sort | |
|
|
|
Yes | Insertion | When using a self-balancing binary search tree |
| Cycle sort | — | |
|
|
No | Insertion | In-place with theoretically optimal number of writes |
| Library sort | — | |
|
|
Yes | Insertion | |
| Patience sorting | — | — | |
|
No | Insertion & Selection | Finds all the longest increasing subsequences within O(n log n) |
| Smoothsort | |
|
|
|
No | Selection | An adaptive sort - comparisons when the data is already sorted, and 0 swaps. |
| Strand sort | |
|
|
|
Yes | Selection | |
| Tournament sort | — | |
|
Selection | |||
| Cocktail sort | |
|
|
|
Yes | Exchanging | |
| Comb sort | |
|
|
|
No | Exchanging | Small code size |
| Gnome sort | |
|
|
|
Yes | Exchanging | Tiny code size |
| Bogosort | |
 |
 |
|
No | Luck | Randomly permute the array and check if sorted. |
| [6] | |
|
|
|
Yes |
Non-Comparison of algorithms
The following table describes integer sorting algorithms and other sorting algorithms that are not comparison sorts. As such, they are not limited by a  lower bound. Complexities below are in terms of n, the number of items to be sorted, k, the size of each key, and d, the digit size used by the implementation. Many of them are based on the assumption that the key size is large enough that all entries have unique key values, and hence that n << 2k, where << means "much less than."
lower bound. Complexities below are in terms of n, the number of items to be sorted, k, the size of each key, and d, the digit size used by the implementation. Many of them are based on the assumption that the key size is large enough that all entries have unique key values, and hence that n << 2k, where << means "much less than."
| Pigeonhole sort | — | 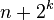 |
|
 |
Yes | Yes | |
| Bucket sort (uniform keys) | — |  |
 |
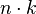 |
Yes | No | Assumes uniform distribution of elements from the domain in the array.[7] |
| Bucket sort (integer keys) | — | 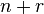 |
|
|
Yes | Yes | r is the range of numbers to be sorted. If r =  then Avg RT = [8] then Avg RT = [8]
|
| Counting sort | — | |
|
|
Yes | Yes | r is the range of numbers to be sorted. If r = then Avg RT = [7]
|
| LSD Radix Sort | — |  |
|
|
Yes | No | [7][8] |
| MSD Radix Sort | — | |
|
 |
Yes | No | Stable version uses an external array of size n to hold all of the bins |
| MSD Radix Sort | — | |
|
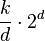 |
No | No | In-Place. k / d recursion levels, 2d for count array |
| Spreadsort | — | |
 |
 |
No | No | Asymptotics are based on the assumption that n << 2k, but the algorithm does not require this. |
要是你有任何建议或批评和补充,希望您能留言指出,不胜感激,更多参考请移步互联网。


发表评论

-
完结篇
2016-11-27 11:53 5098如题,这篇是我在iteye.com的最后一篇博客,后面会陆续在 ... -
一次北京,又一次开始:走在行云流水间
2014-05-03 09:43 3001一次北京,又一次开始 ... -
毕业了,就不能再那么纯真了?
2014-03-31 02:01 4622毕业了,就不能再那� ... -
C# 调用Delegate.CreateDelegate方法出现“未处理ArgumentException”错误解决
2013-05-31 12:24 3603在C# 调用Delegate.Create ... -
“奇怪”的后续
2013-05-10 19:02 1744写这篇博客主 ... -
数组问题集结号
2012-12-06 22:01 0数组是最简单的数据结构,数组问题作为公司招聘的笔试和面试题目 ... -
算法问题分析笔记
2012-12-05 11:59 01.Crash Balloon Zhejiang Univer ... -
雙月神話 by D.S.Qiu
2012-11-29 13:52 2001雙月神話 by D.S.Qiu 一直都对 ... -
Java基础进阶整理
2012-11-26 09:59 2353Java学习笔记整理 ... -
Java学习笔记整理
2012-11-24 23:43 211Java学习笔记整理 本文档是我个人 ... -
《C++必知必会》学习笔记
2012-11-24 23:40 2671《C++必知必会》学� ... -
《C++必知必会》学习笔记
2012-11-24 23:34 1《C++必知必会》学习笔� ... -
C语言名题精选百则——排序
2012-11-04 23:29 128第5章排 序 问题5.1 二分插入法(BIN ... -
C语言名题精选百则——查找
2012-11-04 23:29 4187尊重他人的劳动,支持原创 本篇博文,D.S.Q ... -
基本技术——贪心法、分治法、动态规划三大神兵
2012-11-03 19:30 0基本技术——贪心法、分治法、动态规划三大神兵 -
写在前面的话
2012-11-03 18:47 2467写在前面的话 尊重他人的劳动,支持原创 最近 ... -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:12 35711优先队列三大利器——二项堆、斐波那契堆、Pairing ... -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:01 3优先队列三大利器——二项堆、斐波那契堆、Pairing 堆 ... -
分布排序(distribution sorts)算法大串讲
2012-10-29 15:33 4700分布排序(distribution sorts)算法大串讲 ... -
归并排序(merge sorts)算法大串讲
2012-10-29 10:04 8347归并排序(merge sorts)算法大串讲 ...
相关推荐
该程序包含7大排序算法: # sort.bubbleSort() #冒泡排序 # sort.shellSort() #希尔排序 # sort.insertionSort() #插入排序 # sort.Selectionsort1() #选择排序 # sort.heapSort() #堆排序 # sort.countSort() ...
除了直接插入排序,还有其他类型的内部排序算法,如交换排序(如快速排序)、选择排序、归并排序、基数排序以及二叉排序树排序等。每种算法都有其独特的优点和适用场景,比如快速排序在平均情况下的时间复杂度为O...
合并排序是一种基于分治策略的排序算法,它将大问题分解为小问题来解决。首先将数组分为两个相等或近乎相等的部分,然后对每一部分递归地进行排序,最后将结果合并。这种算法的时间复杂度为O(n log n),稳定性好,...
常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结常用排序算法总结
在本文中,我们将深入探讨如何使用Qt5框架和C++编程语言实现九大经典的排序算法。Qt5是一个跨平台的应用程序开发框架,它提供了丰富的库和工具,使得开发人员能够便捷地构建用户界面和应用程序逻辑。C++则是一种强大...
本文将探讨如何使用这两种语言实现几种基本的排序算法:冒泡排序、选择排序,以及两种全比较排序(并行和串行)。 首先,让我们了解一下排序算法。排序是计算机科学中最基础的操作之一,它涉及到将一组数据按照特定...
本篇文章将详细讨论几种常见的排序算法:选择排序、冒泡排序、插入排序、合并排序以及快速排序,分析它们的算法原理、时间效率,并通过经验分析验证理论分析的准确性。 **1. 选择排序(Selection Sort)** 选择排序...
本项目旨在实现并比较六种经典的排序算法——直接插入排序、折半插入排序、起泡排序、简单选择排序、堆排序以及2-路归并排序,使用C语言编程。为了全面评估这些算法,我们将在一组随机生成的30000个整数上运行它们,...
本资源提供了七大经典排序算法的实现程序,包括快速排序、冒泡排序、选择排序、归并排序、插入排序、希尔排序和堆排序。下面将逐一详细介绍这些排序算法及其原理。 1. 快速排序:由C.A.R. Hoare提出,是一种采用...
【内部排序算法比较课程设计】主要关注的是对六种经典的内部排序算法的性能对比,包括起泡排序、直接插入排序、简单选择排序、快速排序、希尔排序和堆排序。这些算法是计算机科学中用于对数据进行排序的基础工具,各...
希尔排序,冒泡排序、快速排序递归排序,快速排序非递归排序,快速排序改进算法
**内部排序算法详解** 内部排序是指数据记录在内存中进行排序的过程。本篇文章将深入探讨10种常见的内部排序算法,包括它们的基本思想、比较次数和移动次数的计算,以便更直观地理解不同算法的效率。 1. **直接...
2. **数据规模**:待排序表的长度不小于1005,这确保了数据量足够大,可以充分反映算法的性能。 3. **数据生成**:使用伪随机数生成程序来产生待排序的数据,保证数据的随机性和不可预测性。 4. **比较指标**:...
归并排序是基于分治策略的排序算法,将大问题分解为小问题解决。它将序列分为两半,分别排序,然后合并两个有序子序列。归并排序的时间复杂度始终为O(n log n),但需要额外的空间O(n)。 7. **快速排序**: 快速...
在本系统中,我们主要实现了五种常用的排序算法:冒泡排序法、快速排序法、直接插入排序法、折半插入排序法和树形选择排序法。这些算法都是在计算机科学中最基本和最重要的排序算法,广泛应用于各种数据处理和分析...
1. 熟练运用冒泡排序、选择排序、插入排序、希尔排序、快速排序、合并排序、堆排序等七种常见的内排序算法 2. 使用不同的数据结合计算各种算法的运行时间,验证算法的时间复杂性 3. 能够运用二路归并算法进行外排序 ...
在这个C++实现的项目中,我们有三种经典的排序算法被可视化:冒泡排序、插入排序和选择排序。这些算法的可视化能够帮助我们更好地理解它们的工作原理。** ### 冒泡排序 冒泡排序是最基础的排序算法之一,它通过重复...
在计算机科学领域,排序算法是数据处理中至关重要的一部分,它涉及到如何有效地重新排列一组数据,使其按照特定标准(如升序或降序)排列。以下是对标题和描述中提到的经典排序算法的详细解释: 1. **选择排序...
算法设计与分析-排序算法性能分析大礼包 包括题目要求pdf,报告文档,c++源代码,pre ppt 选择排序 冒泡排序 插入排序 合并排序 快速排序算法原理及代码实现 不同排序算法时间效率的经验分析方法 验证理论分析与经验...
C++数据结构排序算法总结将为您提供详细的排序算法知识,包括比较排序和非比较排序两大类。 比较排序 比较排序是指通过比较元素的大小来确定其在序列中的位置的排序算法。比较排序算法的时间复杂度通常高于非比较...