- 浏览: 1414702 次
- 性别:

- 来自: 广州
-

文章分类
最新评论
-
sdgxxtc:
[quo[color=red]te][/color]
C#使用OleDb读取Excel,生成SQL语句 -
zcs302567601:
博主,你好,一直都有个问题没有搞明白,就是 2.x的版本是通过 ...
NGUI所见即所得之UIPanel -
一样的追寻:
感谢楼主!
有向强连通和网络流大讲堂——史无前例求解最大流(最小割)、最小费用最大流 -
cp1993518:
感谢!从你的博客里学到了很多
Unity日志工具——封装,跳转 -
cp1993518:
学习了~,话说现在的版本custom还真的变委托了
NGUI所见即所得之UIGrid & UITable
分布排序(distribution sorts)算法大串讲
本文内容框架:
§1 鸽巢排序(Pigeonhole)
§2 桶排序(Bucket Sort)
§3 基数排序(Radix Sort)
§4 计数排序(Counting Sort)
§5 Proxmap Sort
§6 珠排序(Bead Sort)
§7 小结
本文介绍的排序算法是基于分配、收集的排序算法,分配排序的基本思想:排序过程无须比较关键字,而是通过"分配"和"收集"过程来实现排序.它们的时间复杂度可达到线性阶:O(n)。不受比较排序算法时间复杂度O(nlogn)的下限限制。
§1 鸽巢排序(Pigeonhole)
鸽巢排序(Pigeonhole sort)
鸽巢排序(Pigeonhole sort),也被称作基数分类, 是一种时间复杂度为O(n)且在不可避免遍历每一个元素并且排序的情况下效率最好的一种排序算法。但它只有在差值(或者可被映射在差值)很小的范围内的数值排序的情况下实用,同时也要求元素个数(n)和成为索引的值(N)大小相当。
鸽巢排序(Pigeonhole sort)算法的时间复杂度都是O(N+n),空间复杂度是O(N)。
鸽巢排序(Pigeonhole sort)算法的思想就是使用一个辅助数组,这个辅助数组的下标对应要排序数组的元素值即使用辅助数组的下标进行排序,辅助数组元素的值记录该下标元素值的在要排序数组中的个数。
鸽巢排序(Pigeonhole sort)算法步骤:
1.对于给定的一组要排序的数组,需要初始化一个空的辅助数组(“鸽巢”),把初始数组中的每个值作为一个key(“鸽巢”)即辅助数组的索引即是待排序数组的值。
2.遍历初始数组,根据每个值放入辅助数组对应的“鸽巢”
3.顺序遍历辅助数组,把辅助数组“鸽巢”中不为空的数放回初始数组中
鸽巢排序(Pigeonhole sort)算法实现举例
void PigeonholeSort(int *array, int length)
{
int b[256] = {0};
int i,k,j = 0;
for(i=0; i<length; i++)
b[array[i]]++;
for(i=0; i<256; i++)
for(k=0; k<b[i]; k++)
array[j++] = i;
}
其实作者觉得鸽巢排序(Pigeonhole sort)的原理跟哈希表的原理类似——根据关键字的key就可以得到关键字的存储位置。
§2 桶排序(Bucket Sort)
箱排序(Bin Sort)
桶排序 (Bucket sort)或所谓的箱排序,是一个排序算法,工作的原理是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是比较排序,不受到 O(n log n) 下限的影响。
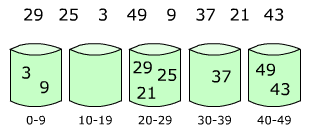

1、箱排序的基本思想
箱排序也称桶排序(Bucket Sort),其基本思想是:设置若干个箱子,依次扫描待排序的记录R[0],R[1],…,R[n-1],把关键字等于k的记录全都装入到第k个箱子里(分配),然后按序号依次将各非空的箱子首尾连接起来(收集)。
【例】要将一副混洗的52张扑克牌按点数A<2<…<J<Q<K排序,需设置13个"箱子",排序时依次将每张牌按点数放入相应的箱子里,然后依次将这些箱子首尾相接,就得到了按点数递增序排列的一副牌。
2、箱排序中,箱子的个数取决于关键字的取值范围。
若R[0..n-1]中关键字的取值范围是0到m-1的整数,则必须设置m个箱子。因此箱排序要求关键字的类型是有限类型,否则可能要无限个箱子。
3、箱子的类型应设计成链表为宜
一般情况下每个箱子中存放多少个关键字相同的记录是无法预料的,故箱子的类型应设计成链表为宜。
4、为保证排序是稳定的,分配过程中装箱及收集过程中的连接必须按先进先出原则进行。
(1) 实现方法一
每个箱子设为一个链队列。当一记录装入某箱子时,应做人队操作将其插入该箱子尾部;而收集过程则是对箱子做出队操作,依次将出队的记录放到输出序列中。
(2) 实现方法二
若输入的待排序记录是以链表形式给出时,出队操作可简化为是将整个箱子链表链接到输出链表的尾部。这只需要修改输出链表的尾结点中的指针域,令其指向箱子链表的头,然后修改输出链表的尾指针,令其指向箱子链表的尾即可。
桶排序算法实现举例
#include <iostream>
#include <list>
using namespace std;
struct Node
{
double value;
Node *next;
};
//桶排序主程序
void bucketSort(double* arr, int length)
{
Node key[10];
int number = 0;
Node *p, *q;//插入节点临时变量
int counter = 0;
for(int i = 0; i < 10; i++)
{
key[i].value = 0;
key[i].next = NULL;
}
for(int i = 0; i < length; i++)
{
Node *insert = new Node();
insert->value = arr[i];
insert->next = NULL;
number = arr[i] * 10;
if(key[number].next == NULL)
{
key[number].next = insert;
}
else
{
p = &key[number];
q = key[number].next;
while((q != NULL) && (q->value <= arr[i]))
{
q = q->next;
p = p->next;
}
insert->next = q;
p->next = insert;
}
}
for(int i = 0; i < 10; i++)
{
p = key[i].next;
if(p == NULL)
continue;
while(p != NULL)
{
arr[counter++] = p->value;
p = p->next;
}
}
}
int main()
{
double a[] = {0.78, 0.17, 0.39, 0.26, 0.72, 0.94, 0.21, 0.12, 0.23, 0.68};
bucketSort(a, 10);
for(int i = 0; i < 10; i++)
{
cout << a[i] << " ";
}
cout << endl;
return 0;
}
5、算法简析
分配过程的时间是O(n);收集过程的时间为O(m) (采用链表来存储输入的待排序记录)或O(m+n)。因此,箱排序的时间为O(m+n)。若箱子个数m的数量级为O(n),则箱排序的时间是线性的,即O(n),但最坏情况仍有可能是 O(n ^ 2)。
桶排序只适用于关键字取值范围较小的情况,否则所需箱子的数目 m 太多导致浪费存储空间和计算时间。
桶排序能够扩展为对整数元组序列进行排序,此时按照字典序排序。在面试的海量数据处理题目中,桶排序也很有作用。如对每天数以亿计的数据进行排序,直接排序即使采用nlgn的算法,依然是一件很恐怖的事情,内存也无法容纳如此多的数据。这时桶排序就可以有效地降低数据的数量级,再对降低了数量级的数据进行排序,可以得到比较良好的效果。
§3 基数排序(Radix Sort)
基数排序(Radix Sort)
基数排序(Radix Sort)是对桶排序的改进和推广。唯一的区别是基数排序强调多关键字,而桶排序没有这个概念,换句话说基数排序对每一种关键字都进行桶排序,而桶排序同一个桶内排序可以任意或直接排好序。
1、单关键字和多关键字
文件中任一记录R[i]的关键字均由d个分量
![]() 构成。
构成。
若这d个分量中每个分量都是一个独立的关键字,则文件是多关键字的(如扑克牌有两个关键字:点数和花色);否则文件是单关键字的,
![]() (0≤j<d)只不过是关键字中其中的一位(如字符串、十进制整数等)。
(0≤j<d)只不过是关键字中其中的一位(如字符串、十进制整数等)。
多关键字中的每个关键字的取值范围一般不同。如扑克牌的花色取值只有4种,而点数则有13种。单关键字中的每位一般取值范围相同。
2、基数
设单关键字的每个分量的取值范围均是:
C0≤kj≤Crd-1(0≤j<d)
可能的取值个数rd称为基数。
基数的选择和关键字的分解因关键宇的类型而异:
(1) 若关键字是十进制整数,则按个、十等位进行分解,基数rd=10,C0=0,C9=9,d为最长整数的位数;
(2) 若关键字是小写的英文字符串,则rd=26,Co='a',C25='z',d为字符串的最大长度。
3、基数排序的基本思想
基数排序的基本思想是:从低位到高位依次对Kj(j=d-1,d-2,…,0)进行箱排序。在d趟箱排序中,所需的箱子数就是基数rd,这就是"基数排序"名称的由来。
基数排序的时间复杂度是 O(k·n),其中n是排序元素个数,k是数字位数。注意这不是说这个时间复杂度一定优于O(n·log(n)),因为k的大小一般会受到 n 的影响。基数排序所需的辅助存储空间为O(n+rd)。
基数排序的方式可以采用LSD(Least significant digital)或MSD(Most significant digital),LSD的排序方式由键值的最右边开始,而MSD则相反,由键值的最左边开始。
基数排序算法实现举例
#include <stdio.h>
#include <stdlib.h>
void radixSort(int[]);
int main(void) {
int data[10] = {73, 22, 93, 43, 55, 14, 28, 65, 39, 81};
printf("\n排序前: ");
int i;
for(i = 0; i < 10; i++)
printf("%d ", data[i]);
putchar('\n');
radixSort(data);
printf("\n排序後: ");
for(i = 0; i < 10; i++)
printf("%d ", data[i]);
return 0;
}
void radixSort(int data[]) {
int temp[10][10] = {0};
int order[10] = {0};
int n = 1;
while(n <= 10) {
int i;
for(i = 0; i < 10; i++) {
int lsd = ((data[i] / n) % 10);
temp[lsd][order[lsd]] = data[i];
order[lsd]++;
}
// 重新排列
int k = 0;
for(i = 0; i < 10; i++) {
if(order[i] != 0) {
int j;
for(j = 0; j < order[i]; j++, k++) {
data[k] = temp[i][j];
}
}
order[i] = 0;
}
n *= 10;
}
}
基数排序应用到字符串处理的倍增算法里面,这个倍增算法,要反复的进行排序。如果排序能快一点,这个程序就能快很多。
§4 计数排序(Counting Sort)
计数排序(Counting sort)
计数排序(Counting sort)是一种稳定的排序算法,和基数排序一样都是桶排序的变体。计数排序使用一个额外的数组C,其中第i个元素是待排序数组A中值小于等于i的元素的个数。然后根据数组C来将A中的元素排到正确的位置。
计数排序的原理
设被排序的数组为A,排序后存储到B,C为临时数组。所谓计数,首先是通过一个数组C[i]计算大小等于i的元素个数,此过程只需要一次循环遍历就可以;在此基础上,计算小于或者等于i的元素个数,也是一重循环就完成。下一步是关键:逆序循环,从length[A]到1,将A[i]放到B中第C[A[i]]个位置上。原理是:C[A[i]]表示小于等于a[i]的元素个数,正好是A[i]排序后应该在的位置。而且从length[A]到1逆序循环,可以保证相同元素间的相对顺序不变,这也是计数排序稳定性的体现。在数组A有附件属性的时候,稳定性是非常重要的。
计数排序的前提及适用范围
A中的元素不能大于k,而且元素要作为数组的下标,所以元素应该为非负整数。而且如果A中有很大的元素,不能够分配足够大的空间。所以计数排序有很大局限性,其主要适用于元素个数多,但是普遍不太大而且总小于k的情况,这种情况下使用计数排序可以获得很高的效率。由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。例如:计数排序是用来排序0到100之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序中的算法来排序数据范围很大的数组。
当输入的元素是 n 个 0 到 k 之间的整数时,它的运行时间是 Θ(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。
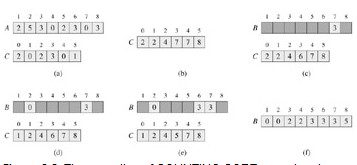
计数排序算法的步骤:
1.找出待排序的数组中最大和最小的元素
2.统计数组中每个值为i的元素出现的次数,存入数组C的第i项
3.对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
4.反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
计数排序算法实现举例
#include <stdio.h>
#include <conio.h>
#define MAX 1000
//函数原型
void counting_sort(int A[],int length_A,int B[],int k);
//测试代码
int main()
{
int A[]={-1,2,6,5,4,8,9,7,1,10,3};//1到10,十个测试数据
int B[11]={0};
int k=10;//所有测试数据都处于0到k之间
counting_sort(A,10,B,k);
for(int i=1;i<11;i++)
printf("%d ",B[i]);
getch();
}
//计数排序
void counting_sort(int A[],int length_A,int B[],int k)
{
int C[MAX]={0};//C是临时数组
for(int i=1;i<=length_A;i++)
C[A[i]]++;
//此时C[i]包含等于i的元素个数
for(int i=1;i<=k;i++)
C[i]=C[i]+C[i-1];
//此时C[i]包含小于或者等于i的元素个数
for(int i=length_A;i>=1;i--)//从length_A到1逆序遍历是为了保证相同元素排序后的相对顺序不改变
{ //如果从1到length_A,则相同元素的相对顺序会逆序,但结果也是正确的
B[C[A[i]]]=A[i];
C[A[i]]--;
}
}
可以使用链表节省辅助数组C的空间,只存储出现的出现元素情况。
§5 Proxmap Sort
Proxmap Sort
Proxmap Sort是桶排序和基数排序的改进。ProxMap的排序采用不同的方法来排序,这在概念上是类似哈希。该算法使用桶技术对哈希方法进行改变,桶的大小不相同。

Technique:
- Create 4 arrays and initialize
- int HitList[ARRAYSIZE] -- Keeps a count of the number of hits at each index in the sorted array. HitList[x] holds a count of the number of items whose keys hashed to x. Initialize to all 0.
- int Location[ARRAYSIZE] -- Indices in the sorted array calculated using the hash function. Item x in the unsorted array has its hash index stored in Location[x]. Does not need to be initialized.
- int ProxMap[ARRAYSIZE] -- Starting index in the sorted array for each bucket. If HitList[x] is not 0 then ProxMap[x] contains the starting index for the bucket of keys hashing to x. Initialize to all keys to -1 (unused).
- StructType DataArray2[ARRAYSIZE] -- Array to hold the sorted array. Initialize to all -1 (unused).
- Use the keys of the unsorted array and a carefully chosen hash function to generate the indices into the sorted array and save these. The hash function must compute indices always in ascending order. Store each hash index in the Location[] array. Location[i] will hold the calculated hash index for the ith structure in the unsorted array.
HIdx = Hash(DataArray[i]);
Location[i] = HIdx;
Care must be taken in selecting the hash function so that the keys are mapped to the entire range of indexes in the array. A good approach is to convert the keys to integer values if they are strings, then map all keys to floats in the range 0<= Key < 1. Finally, map these floats to the array indices using the following formulas:/* Map all integer keys to floats in range 0<= Key < 1 */ KeyFloat = KeyInt / (1 + MAXKEYINTVALUE); /* Map all float keys to indices in range 0<= Index < ARRAYSIZE */ Index = floor(ARRAYSIZE * KeyFloat);
This will then produce indices insuring that all the keys are kept in ascending order (hashs computed using a mod operator will not.) - Keep a count of the number of hits at each hash index. HitList[Hidx]++
- Create the ProxMap (short for proximity map) from the hit list giving the starting index in the sorted array for each bucket.
RunningTotal = 0; /* Init counter */ for(i=0; i 0) /* There were hits at this address */ { ProxMap[i] = RunningTotal; /* Set start index for this set */ RunningTotal += HitList[i]; } } - Move keys from the unsorted array to the sorted array using an insertion sort technique for each bucket.
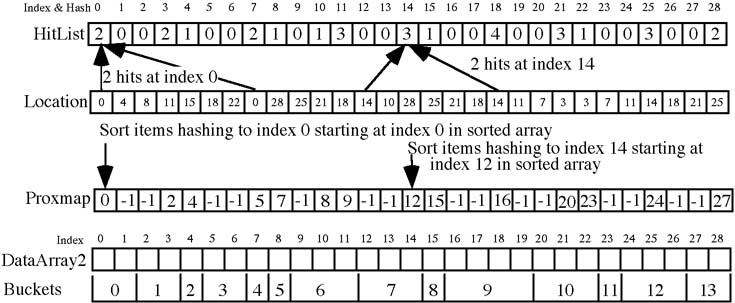
In this diagram 5 sets of structures are sorted when delta = 5
Analysis: ProxMap sorting runs in a surprisingly fast O(n) time.
/******************************************************/
/* ProxmapSort.c */
/* */
/* Proxmap sort demonstration. */
/* Author: Rick Coleman */
/* Date: April 1998 */
/******************************************************/
#include <stdio.h>
#include <conio.h>
#include "sort.h"
#include <math.h>
#define ARRAYSIZE 32
/* Prototype sort function */
void ProxmapSort(StructType DataArray[], StructType DataArray2[],int count);
int Hash(int key, int KeyMax, int KeyMin, int count);
void ProxMapInsertionSort(StructType DataArray[], StructType *theStruct,
int startIdx, int listLen);
int main(void)
{
StructType DataArray[32], DataArray2[32];
int count;
count = ReadRecords(DataArray, 32);
printf("Unsorted list of records.\n\n");
PrintList(DataArray, count);
ProxmapSort(DataArray, DataArray2, count);
printf("Sorted list of records.\n\n");
PrintList(DataArray2, count);
printf("Sorting done...\n");
getch();
return(0);
}
/***************************************/
/* ProxmapSort() */
/* */
/* Sort records on integer key using */
/* a proxmap sort. */
/***************************************/
void ProxmapSort(StructType DataArray[], StructType DataArray2[],int count)
{
int i;
int HitList[ARRAYSIZE];
int Hidx; /* Hashed index */
int ProxMap[ARRAYSIZE];
int RunningTotal; /* Number of hits */
int Location[ARRAYSIZE];
int KeyMax, KeyMin; /* Used in Hash() */
/* Initialize hit list and proxmap */
for(i=0; i<count; i++)
{
HitList[i] = 0; /* Init to all 0 hits */
ProxMap[i] = -1; /* Init to all unused */
DataArray2[i].key = -1; /* Init to all empty */
}
/* Find the largest key for use in computing the hash */
KeyMax = 0; /* Guaranteed to be less than the smallest key */
KeyMin = 32767; /* Guaranteed to be more than the largest key */
for(i=0; i<count; i++)
{
if(DataArray[i].key > KeyMax) KeyMax = DataArray[i].key;
if(DataArray[i].key < KeyMin) KeyMin = DataArray[i].key;
}
/* Compute the hit count list (note this is not a collision count, but
a collision count+1 */
for(i=0; i<count; i++)
{
Hidx = Hash(DataArray[i].key, KeyMax, KeyMin, count); /* Calculate hash index */
Location[i] = Hidx; /* Save this for later. (Step 1) */
HitList[Hidx]++; /* Update the hit count (Step 2) */
}
/* Create the proxmap from the hit list. (Step 3) */
RunningTotal = 0; /* Init counter */
for(i=0; i<count; i++)
{
if(HitList[i] > 0) /* There were hits at this address */
{
ProxMap[i] = RunningTotal; /* Set start index for this set */
RunningTotal += HitList[i];
}
}
// NOTE: UNCOMMENT THE FOLLOWING SECTION TO SEE WHAT IS IN THE ARRAYS, BUT
// COMMENT IT OUT WHEN DOING A TEST RUN AS PRINTING IS VERY SLOW AND
// WILL RESULT IN AN INACCURATE TIME FOR PROXMAP SORT.
/* ----------------------------------------------------
// Print HitList[] to see what it looks like
printf("HitList:\n");
for(i=0; i<count; i++)
printf("%d ", HitList[i]);
printf("\n\n");
getch();
// Print ProxMap[] to see what it looks like
printf("ProxMap:\n");
for(i=0; i<count; i++)
printf("%d ", ProxMap[i]);
printf("\n\n");
getch();
// Print Location[] to see what it looks like
printf("Location:\n");
for(i=0; i<count; i++)
printf("%d ", Location[i]);
printf("\n\n");
getch();
--------------------------------------------- */
/* Move the keys from A1 to A2 */
/* Assumes A2 has been initialized to all empty slots (key = -1)*/
for(i=0; i<count; i++)
{
if((DataArray2[ProxMap[Location[i]]].key == -1)) /* If the location in A2 is empty...*/
{
/* Move the structure into the sorted array */
DataArray2[ProxMap[Location[i]]] = DataArray[i];
}
else /* Insert the structure using an insertion sort */
{
ProxMapInsertionSort(DataArray2, &DataArray[i], ProxMap[Location[i]], HitList[Location[i]]);
}
}
}
/***************************************/
/* Hash() */
/* */
/* Calculate a hash index. */
/***************************************/
int Hash(int key, int KeyMax, int KeyMin, int count)
{
float keyFloat;
/* Map integer key to float in the range 0 <= key < 1 */
keyFloat = (float)(key - KeyMin) / (float)(1 + KeyMax - KeyMin);
/* Map float key to indices in range 0 <= index < count */
return((int)floor(count * keyFloat));
}
/***************************************/
/* ProxMapInsertionSort() */
/* */
/* Use insertion sort to insert a */
/* struct into a subarray. */
/***************************************/
void ProxMapInsertionSort(StructType DataArray[], StructType *theStruct,
int startIdx, int listLen)
{
/* Args: DataArray - Partly sorted array
*theStruct - Structure to insert
startIdx - Index of start of subarray
listLen - Number of items in the subarray */
int i;
/* Find the end of the subarray */
i = startIdx + listLen - 1;
while(DataArray[i-1].key == -1) i--;
/* Find the location to insert the key */
while((DataArray[i-1].key > theStruct->key) && (i > startIdx))
{
DataArray[i] = DataArray[i-1];
i--;
}
/* Insert the key */
DataArray[i] = *theStruct;
}
§6 珠排序(Bead Sort)
珠排序(Bead Sort)
珠排序是一种自然排序算法,由Joshua J. Arulanandham, Cristian S. Calude 和 Michael J. Dinneen 在2002年发展而来,并且在欧洲理论计算机协会(European Association for Theoretical Computer Science,简称EATCS)的新闻简报上发表了该算法。无论是电子还是实物(digital and analog hardware)上的实现,珠排序都能在O(n)时间内完成;然而,该算法在电子上的实现明显比实物要慢很多,并且只能用于对正整数序列进行排序。并且,即使在最好的情况,该算法也需要O(n^2) 的空间。
下面仅从实例来理解这个算法
先了解一个概念,一个数字3用3个1来表示,一个数字9用9个1来表示,珠排序中的珠指的是每一个1,它把每一个1想像成一个珠子,这些珠子被串在一起,想像下算盘和糖葫芦:

图1
上图1中的三个珠就表示数字3,两个珠表示数字2。

图2
图2(a)中有两个数字,4和3,分别串在四条线上,于是数字4的最后一个珠子下落,因为它下边是空的,自由下落后变成图2(b),图2(c)中随机给了四个数字,分别是3,2,4,2,这些珠子自由下落,就变成了(d)中,落完就有序了,2,2,3,4,以上就是珠排序的精华。
珠排序算法的图很像之前介绍过的跳跃表(Skip List)的结构。
§7 小结
这篇博文列举了选择排序的6个算法,基本可以掌握其中概要,管中窥豹,不求甚解。如果你有任何建议或者批评和补充,请留言指出,不胜感激,更多参考请移步互联网。
参考:
①awsqsh: http://blog.csdn.net/awsqsh/article/details/6133562
②数据结构自考网: http://student.zjzk.cn/course_ware/data_structure/web/paixu/paixu8.6.1.1.htm
③juvenfan:http://www.cnblogs.com/juventus/archive/2012/06/06/2538834.html
④Gossip@caterpillar: http://caterpillar.onlyfun.net/Gossip/AlgorithmGossip/RadixSort.htm
⑤数据结构自考网: http://student.zjzk.cn/course_ware/data_structure/web/paixu/paixu8.6.2.htm
⑥NeilHappy: http://blog.csdn.net/neilhappy/article/details/7202507
⑦kkun: http://www.cnblogs.com/kkun/archive/2011/11/23/2260301.html
⑧Promap Sort: http://www.cs.uah.edu/~rcoleman/CS221/Sorting/ProxMapSort.html
顶
踩


发表评论

-
C# 调用Delegate.CreateDelegate方法出现“未处理ArgumentException”错误解决
2013-05-31 12:24 3595在C# 调用Delegate.Create ... -
数组问题集结号
2012-12-06 22:01 0数组是最简单的数据结构,数组问题作为公司招聘的笔试和面试题目 ... -
算法问题分析笔记
2012-12-05 11:59 01.Crash Balloon Zhejiang Univer ... -
Java基础进阶整理
2012-11-26 09:59 2346Java学习笔记整理 ... -
Java学习笔记整理
2012-11-24 23:43 211Java学习笔记整理 本文档是我个人 ... -
《C++必知必会》学习笔记
2012-11-24 23:40 2667《C++必知必会》学� ... -
《C++必知必会》学习笔记
2012-11-24 23:34 1《C++必知必会》学习笔� ... -
C语言名题精选百则——排序
2012-11-04 23:29 128第5章排 序 问题5.1 二分插入法(BIN ... -
C语言名题精选百则——查找
2012-11-04 23:29 4182尊重他人的劳动,支持原创 本篇博文,D.S.Q ... -
基本技术——贪心法、分治法、动态规划三大神兵
2012-11-03 19:30 0基本技术——贪心法、分治法、动态规划三大神兵 -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:12 35701优先队列三大利器——二项堆、斐波那契堆、Pairing ... -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:01 3优先队列三大利器——二项堆、斐波那契堆、Pairing 堆 ... -
排序算法群星豪华大汇演
2012-10-30 00:09 3173排序算法群星豪华大汇演 排序算法相对简单些,但是由于 ... -
归并排序(merge sorts)算法大串讲
2012-10-29 10:04 8336归并排序(merge sorts)算法大串讲 ... -
交换排序(exchange sorts)算法大串讲
2012-10-29 00:22 4442交换排序(exchange sorts)算法大串讲 本 ... -
选择排序(selection sorts)算法大串讲
2012-10-28 12:55 3750选择排序(selection sorts)算法大串讲 本文内 ... -
插入排序(insertion sorts)算法大串讲
2012-10-28 11:30 2773插入排序(insertion sorts� ... -
伸展树(Splay Tree)尽收眼底
2012-10-27 15:11 5608伸展树(Splay Tree)尽收眼底 本文内容 ... -
红黑树(Red-Black Tree)不在话下
2012-10-26 20:54 2257红黑树(Red-Black Tree) 红黑树定义 红黑树 ... -
平衡二叉树(AVL)原理透析和编码解密
2012-10-26 10:22 3036平衡二叉树(AVL)原理透析和编码解密 本文内容 ...
相关推荐
在计算机科学中,排序是一种基本而重要的数据处理操作,...最后,提及的"sorts-master"文件名称,可能指的是一个包含上述各种排序算法实现的代码库,这样的代码库对于学习、教学或实际项目开发来说都是非常宝贵的资源。
swift-sorts, Swift中,实现了排序算法的集合 Swift 排序 快速实现的排序算法集合。Read Read ,Apples, ,, ,, 。请参见 objective-c 排序和 c 排序比较。算法快速 sorted()快速排序堆排序规则插入排序规则选择...
在提供的压缩包"sorts"中,可能包含了实现这些排序算法的C++源代码。这些代码遵循面向对象的设计原则,结构紧凑,逻辑清晰,是学习和理解这些排序算法的好资源。通过阅读和分析这些代码,我们可以更深入地了解每种...
在提供的"sorts"压缩包中,可能包含了上述各种排序算法的C#源代码,你可以使用Visual Studio(VS)打开并运行这些代码,查看每个算法的执行效果。这些代码实例是学习和实践排序算法的好资源,特别适合作为毕业设计...
综上所述,"SORTS.zip 全排序"项目可能涵盖了C#中各种排序算法的实现,以及通过界面展示排序结果和将结果存储为二维数组的功能。对于初学者和经验丰富的开发者来说,这都是一个很好的学习和实践项目。
### 排序算法全集锦(Java代码实现) 本文将详细介绍和分析常见的几种排序算法,并通过Java语言实现这些算法。具体包括冒泡排序、简单选择排序、直接插入排序、希尔排序、归并排序以及快速排序等。每种排序算法都将...
JavaScript的排序算法也是理解和优化性能的关键,尤其是当处理大量数据时,选择正确的排序算法和优化方法至关重要。 排序在前端开发中的应用非常广泛,不仅限于简单的列表排序,还包括但不限于搜索、数据处理、用户...
本压缩包“数据结构-C++之11-sorts.zip”聚焦于在C++环境下实现数据排序的算法,包含至少11种不同的排序算法实现。 排序算法是数据结构课程和软件开发中的核心内容之一。它们在提高数据处理效率方面起着关键作用,...
本套文件“python-lianxi-sorts.rar”通过一系列的练习,旨在帮助Python初学者通过实际编码的方式掌握各种排序算法。这些练习题将以Python语言编写,通过从易到难的顺序排列,使学习者能够循序渐进地理解并实现每一...
冒泡排序算法是一种基础的排序算法,因其重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,就像水底下的气泡一样,越大的气泡会经过交换慢慢浮到数列的顶端,故称冒泡排序。...
总之,"数据结构算法演示系统"是一个强大的学习工具,尤其对于"sorts"部分,它能帮助用户深入理解排序算法的工作机制,提升编程技能,对于计算机科学的学习者和开发者来说具有极高的价值。通过实际操作和比较,学习...
排序算法的种类繁多,包括简单排序和高效排序两大类。简单排序如冒泡排序、选择排序和插入排序,虽然实现简单,但效率较低,适用于数据量较小的情况。高效排序包括快速排序、归并排序、堆排序等,这些算法在时间...
`scala-sorts` 项目专注于展示如何在 Scala 中实现不同的排序算法。这里我们将深入探讨这些算法,以及它们在实际编程中的应用。 首先,让我们了解排序算法的基本概念。排序是将一组数据按照特定顺序排列的过程。在...
《sorts:带打字稿的排序算法》 在编程领域,排序算法是核心基础知识之一,对于提升程序效率和理解数据处理逻辑至关重要。本资源主要关注的是使用TypeScript实现的各种排序算法,TypeScript是一种强类型、面向对象的...
8. **字符串排序(String Sorts)**:091_51StringSorts.pdf 专门讨论字符串的排序问题,涉及到字符串比较的细节和特定的排序算法,如Trie树、Boyer-Moore排序等。 9. **基础符号表(Elementary Symbol Tables)**:061...
通过本文件包中的14_sorts文件,学生和开发者可以更深入地学习和实践C++中的各种排序算法,这不仅对理解数据结构有帮助,而且对于提升编程能力和解决问题的能力都有非常积极的作用。在实际开发中,掌握这些排序算法...
做了个Java Swing 图形界面,选择3中排序方法进行排序。工程用NetBeans 打开,运行Main.java文件或直接点击运行主程序,3种算法在源包中的sorts文件夹...QKSort.java(快速排序算法) SelectSort.java(简单选择排序)
本篇将深入探讨"Sorts.zip"中的C++数据结构实现,特别是排序算法。 在C++中,排序算法是处理数组、向量等数据集合时的重要工具。它们的目标是按照特定规则(如升序或降序)重新排列元素。以下是几种常见的排序算法...
排序算法可以分为几大类:如冒泡排序、选择排序、插入排序、快速排序、归并排序等。 ### 1. 冒泡排序(Bubble Sort) 冒泡排序是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序...
`Sorts.h`可能是包含了各种排序算法定义的头文件,而`main.cpp`是主程序,负责读取10000个随机数,调用排序函数并记录运行时间,最后将结果输出到文件。在实际编程时,通常会用到`<iostream>`、`<fstream>`、`...