
هژںهˆ›و–‡ç« ,转载请و³¨وکژ:转载è‡ھآ ه‘¨ه²³é£هچڑه®¢(http://zhou-yuefei.iteye.com/)آ آ
ن¸ٹ篇هچڑه®¢è®¨è®؛ن؛†Spark Streaming 程ه؛ڈهٹ¨و€پç”ںوˆگJobçڑ„è؟‡ç¨‹,ه¹¶ç•™ن¸‹ن¸€ن¸ھç–‘é—®:آ JobSchedulerه°†هٹ¨و€پç”ںوˆگçڑ„Jobوڈگن؛¤,然هگژ调用ن؛†Jobه¯¹è±،çڑ„runو–¹و³•,وœ€هگژrunو–¹و³•çڑ„调用وک¯ه¦‚ن½•è§¦هڈ‘RDDçڑ„Actionو“چن½œ,ن»ژ而çœںو£è§¦هڈ‘Jobçڑ„و‰§è،Œçڑ„ه‘¢?وœ¬و–‡ه°±ه…·ن½“讲解è؟™ن¸ھé—®é¢کم€‚
آ
ن¸€م€پDStreamه’ŒRDDçڑ„ه…³ç³»
آ آ DSream ن»£è،¨ن؛†ن¸€ç³»هˆ—è؟ç»çڑ„RDD,DStreamن¸و¯ڈن¸ھRDDهŒ…هگ«ç‰¹ه®ڑو—¶é—´é—´éڑ”çڑ„و•°وچ®ï¼Œه¦‚ن¸‹ه›¾و‰€ç¤؛ï¼ڑ
آ
آ آ آ 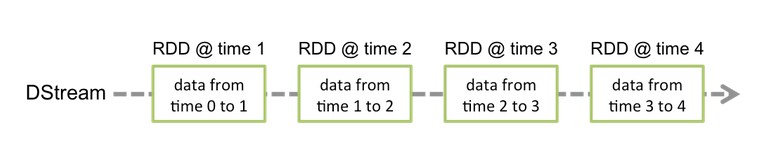
ن»ژن¸ٹه›¾هڈ¯ن»¥çœ‹ه‡؛,ن¸€ن¸ھDStream ه¯¹ه؛”ن؛†و—¶é—´ç»´ه؛¦ن¸ٹçڑ„ه¤ڑن¸ھRDDم€‚
آ
DStream ن½œن¸؛Spark Streamçڑ„ن¸€ن¸ھهں؛وœ¬وٹ½è±،,وڈگن¾›ن؛†é«که±‚çڑ„APIو¥è؟›è،ŒSpark Streaming 程ه؛ڈه¼€هڈ‘,ه…ˆçœ‹ن¸€ن¸ھ简هچ•çڑ„Spark Streamingçڑ„WordCount程ه؛ڈه®ن¾‹ï¼ڑ
آ
object WordCount{def main(args:Array[String]):Unit={val sparkConf =newSparkConf().setMaster("local[4]").setAppName("WordCount")val ssc =newStreamingContext(sparkConf,Seconds(1))val lines = ssc.socketTextStream("localhost",9999)val words = lines.flatMap(_.split(" "))val wordCounts = words.map(x =>(x,1)).reduceByKey(_+_)wordCounts.print()ssc.start()ssc.awaitTermination()}}
آ
وˆ‘ن»¬ن¼ڑهڈ‘çژ°ه¯¹DStreamçڑ„و“چن½œه’ŒRDDçڑ„و“چن½œوƒٹن؛؛çڑ„相ن¼¼, é€ڑè؟‡ه¯¹DStreamçڑ„ن¸چو–转وچ¢,ه½¢وˆگن¾èµ–ه…³ç³»م€‚و‰€ن»¥çڑ„DStreamو“چن½œوœ€ç»ˆن¼ڑ转وچ¢وˆگه؛•ه±‚çڑ„RDDçڑ„و“چن½œï¼Œن¸ٹé¢çڑ„ن¾‹هگن¸
lines DStream转وچ¢وˆگwods DSteamم€‚lines DStreamçڑ„flatMapو“چن½œن¼ڑن½œç”¨ن؛ژه…¶ن¸و¯ڈن¸€ن¸ھRDDهژ»ç”ںوˆگwords DStream ن¸çڑ„RDD, è؟‡ç¨‹ه¦‚ن¸‹ه›¾و‰€ç¤؛:
آ

آ
ن¸‹é¢ن»ژو؛گç پ角ه؛¦çœ‹ن¸€ن¸‹DStreamه’ŒRDDçڑ„ه…³ç³»:
آ آ DStream ن¸ وœ‰ن¸€ن¸ھHashMap[Time,RDD[T]]ç±»ه‹çڑ„ه¯¹è±، generatedRDDs,ه…¶ن¸Keyن¸؛ن½œن¸ڑه¼€ه§‹و—¶é—´,RDDن¸؛该DStreamه¯¹ه؛”çڑ„RDD,و؛گç په¦‚ن¸‹:
آ
آ آ آ 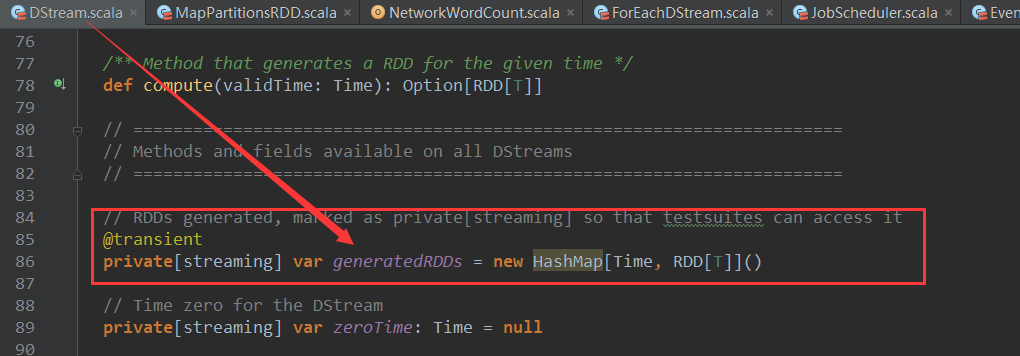
آ
آ
ن؛Œم€پDstream çڑ„هˆ†ç±»
آ آ Dstream ن¸»è¦پهˆ†ن¸؛ن¸‰ه¤§ç±»:
آ آ آ آ آ 1. Input DStream
آ آ آ آ آ 2.آ Transformed DStream
آ آ آ آ آ 3. Output DStream
آ
2.1 InputDStream وک¯DStream وœ€هˆè¯ç”ںçڑ„هœ°و–¹,ن¹ںوک¯RDDوœ€هˆè¯ç”ںçڑ„هœ°و–¹,ه®ƒوک¯ن¾وچ®و•°وچ®و؛گهˆ›ه»؛çڑ„وœ€هˆçڑ„DStream,ه¦‚ن¸ٹé¢ن¾‹هگن¸çڑ„ن»£ç پ:
آ
val lines = ssc.socketTextStream("localhost",9999)
آ
هں؛ن؛ژSocketو•°وچ®و؛گهˆ›ه»؛ن؛†SocketInputDStreamه¯¹è±،lines,ن¸‹é¢ن»ژو؛گç پ角ه؛¦هˆ†وگن¸€ن¸‹ن»–وک¯و€ژن¹ˆç”ںوˆگRDDçڑ„,آ SocketInputDStreamç”ںوˆگRDDçڑ„و–¹و³•هœ¨ه®ƒçڑ„父类ReceiverInputDSteamن¸:
آ

آ
ReceiverInputDSteamآ çڑ„computeو–¹و³•ن¸è°ƒç”¨ن؛†createBloackRDDو–¹و³•هں؛ن؛ژBlockن؟،وپ¯هˆ›ه»؛ن؛†RDD :
آ

آ
هڈ¯ن»¥çœ‹هˆ°آ ReceiverInputDSteam çڑ„createBloackRDD و–¹و³•newن؛†BlockRDDه¯¹è±،,BlockRDD وک¯ç»§و‰؟è‡ھRDDم€‚至و¤ï¼Œوœ€هˆçڑ„RDDهˆ›ه»؛ه®Œوˆگم€‚
آ
2.2م€پآ Transformed DStream وک¯ç”±ه…¶ن»–DStream é€ڑè؟‡éOutputç®—هگ装وچ¢è€Œو¥çڑ„DStream
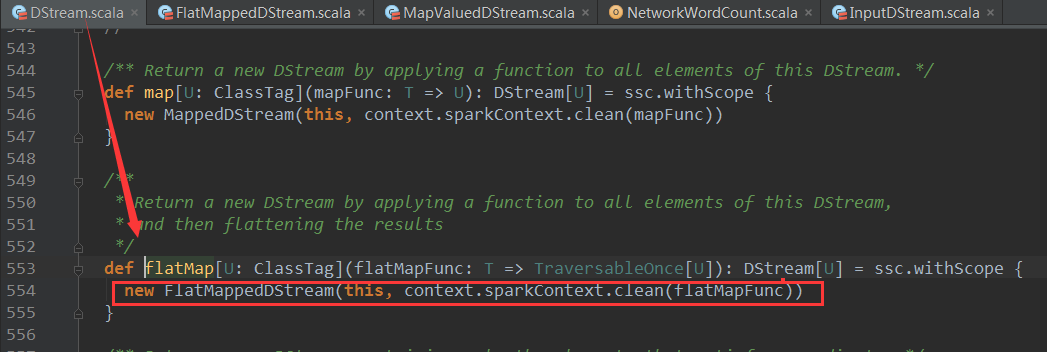
آ آ ن¾‹ه¦‚ن¾‹هگن¸çڑ„linesé€ڑè؟‡flatMapç®—هگ转وچ¢ç”ںوˆگن؛†FlatMappedDStream:
آ آ آ val words = lines.flatMap(_.split(" "))
آ آ ن¸‹é¢çœ‹ن¸€ن¸‹flatMapçڑ„و؛گç پ:
آ آ آ
 آ آ آ
آ آ آ آ
هڈ¯ن»¥çœ‹هˆ°flatMapوک¯DStreamçڑ„و–¹و³•,ه®ƒهˆ›ه»؛ن؛†FlatMappeedDStreamه¹¶è؟”ه›,ن¸ٹé¢ن¾‹هگن¸words ه°±وک¯FlatMappeedDStream ه¯¹è±،,هˆ›ه»؛FlatMappeedDStreamه¯¹è±،و—¶ن¼ ه…¥ن؛†هڈ‚و•°flatMapFunc,è؟™é‡Œçڑ„flatMapFuncه°±وک¯ç”¨وˆ·ç¼–ه†™çڑ„ن¸ڑهٹ،逻辑,وˆ‘ن»¬ه†چè؟›ه…¥FlatMappedDStream,وں¥çœ‹ه…¶computeو–¹و³•:
آ
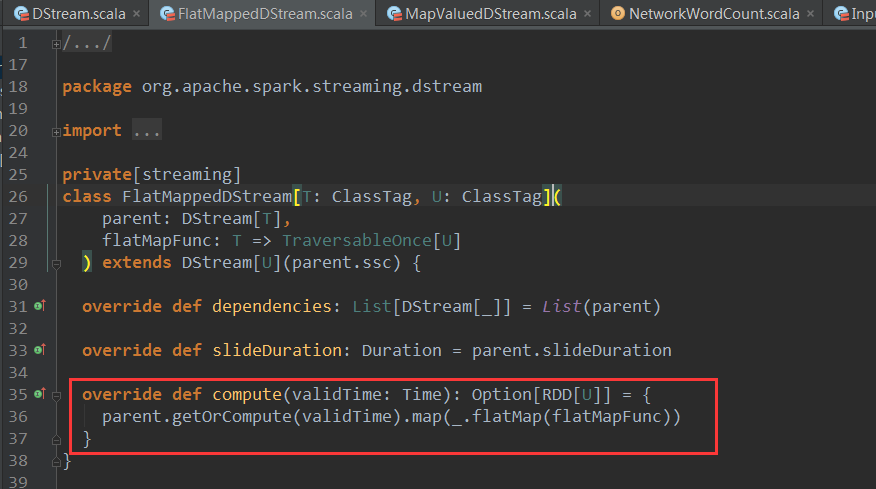
آ
هڈ¯ن»¥وƒٹه–œçڑ„看هˆ°FlatMappedDStreamçڑ„computeو–¹و³•è°ƒç”¨ن؛†parentçڑ„getOrComputeو–¹و³•èژ·هڈ–父DStreamçڑ„RDD.é€ڑè؟‡ه¯¹çˆ¶DStreamçڑ„RDDçڑ„flatMapç®—هگç”ںوˆگو–°çڑ„RDD,转وچ¢çڑ„ن¸ڑهٹ،逻辑é€ڑè؟‡flatMapFuncهڈ‚و•°ن¼ 递给flatMapç®—هگم€‚è؟™و ·ه¯¹DStreamçڑ„و“چن½œéƒ½è½¬وچ¢وˆگن؛†ه¯¹RDDçڑ„و“چن½œï¼ŒهگŒو—¶DSreamçڑ„ن¾èµ–ه…³ç³»ن¹ںن¸ژRDDن¹‹é—´ن¾èµ–ه…³ç³»هگŒو—¶ه»؛ç«‹ن؛†èµ·و¥م€‚
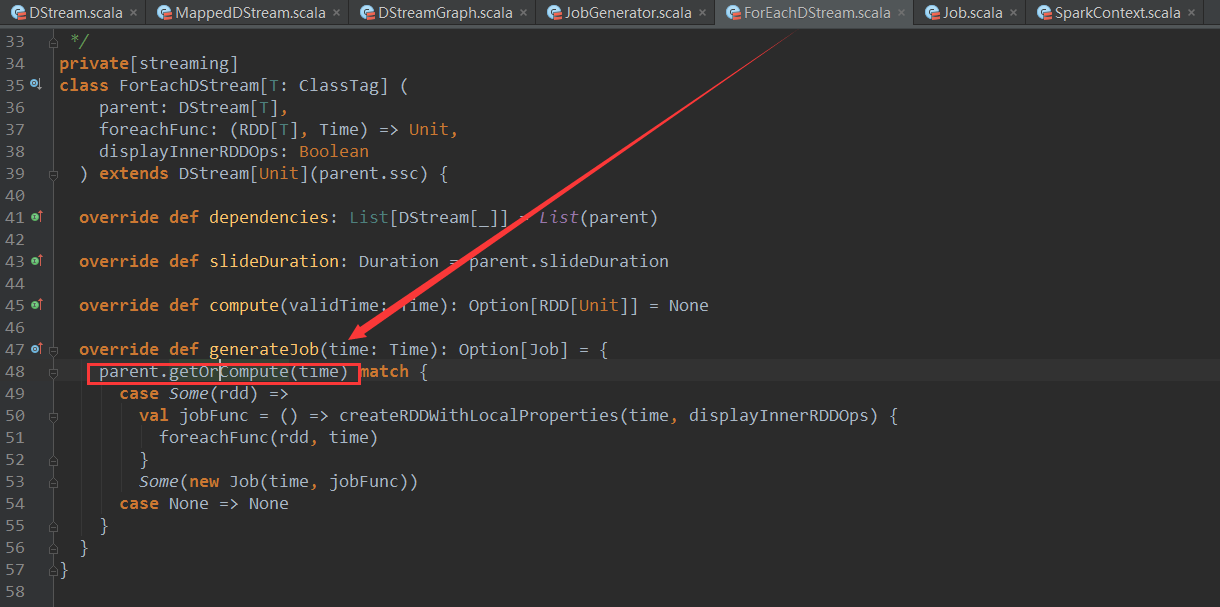
说وکژï¼ڑè؟™ن؛›RDDçڑ„هˆ›ه»؛وک¯هœ¨Jobهٹ¨و€پç”ںوˆگو—¶ه€™هڈ‘ç”ںçڑ„,Jobç”ںوˆگوœ€ç»ˆن¼ڑ调用ForeachDStreamçڑ„generateJobو–¹و³•ï¼Œو؛گç په¦‚ن¸‹
آ
آ
ه…¶ن¸çڑ„parent.getOrComputeو–¹و³•ن¼ڑن¾وچ®DStreamن¹‹é—´çڑ„ن¾èµ–ه…³ç³»,ه¯¼è‡´ن¸€ç³»هˆ—çڑ„链ه¼ڈ调用,ن»ژ而هˆ›ه»؛و‰€وœ‰çڑ„RDD,ه¹¶ه½¢وˆگRDDن¹‹é—´çڑ„ن¾èµ–ه…³ç³»م€‚
آ
3.3آ Output DStream وک¯وœ‰ه…¶ن»–DStreamé€ڑè؟‡Outputç®—هگç”ںوˆگ,ه®ƒهڈھهکهœ¨ن؛ژOutputç®—هگه†…部,ه¹¶ن¸چن¼ڑهƒڈTransformed Streamن¸€و ·ç”±ç®—هگè؟”ه›ï¼Œن»–وک¯è§¦هڈ‘Jobو‰§è،Œçڑ„ه…³é”®م€‚
آ آ آ آ آ آ é‚£ن¹ˆن»€ن¹ˆوک¯Output ç®—هگه‘¢ï¼ںOutput ç®—هگوک¯è®©DStreamن¸çڑ„و•°وچ®è¢«وژ¨é€پçڑ„ه¤–部系ç»ں,هƒڈو•°وچ®ه؛“,و–‡ن»¶ç³»ç»ں(HDFS,GFSç‰ï¼‰çڑ„ç®—هگم€‚ه› ن¸؛Output ç®—هگوک¯ه°†è½¬وچ¢هگژçڑ„و•°وچ®وژ¨é€پهˆ°ه¤–部系ç»ں被ن½؟用çڑ„و“چن½œï¼Œو‰€ن»¥ن»–触هڈ‘ن؛†ه‰چé¢è½¬وچ¢و“چن½œçڑ„çœںو£و‰§è،Œï¼ˆç±»ن¼¼ن؛ژRDDçڑ„actionو“چن½œï¼‰م€‚
آ آ آ آ آ آ ن¸‹é¢ï¼Œوˆ‘ن»¬çœ‹çœ‹وœ‰ه“ھن؛›Outputç®—هگï¼ڑ
آ
| print() | Prints the first ten elements of every batch of data in a DStream on the driver node running the streaming application. This is useful for development and debugging.آ Python APIآ This is calledآ pprint()آ in the Python API. |
| saveAsTextFiles(prefix, [suffix]) | Save this DStream's contents as text files. The file name at each batch interval is generated based onprefixآ andآ suffix:آ "prefix-TIME_IN_MS[.suffix]". |
| saveAsObjectFiles(prefix, [suffix]) | Save this DStream's contents asآ SequenceFilesآ of serialized Java objects. The file name at each batch interval is generated based onآ prefixآ andآ suffix:آ "prefix-TIME_IN_MS[.suffix]".آ Python APIآ This is not available in the Python API. |
| saveAsHadoopFiles(prefix, [suffix]) | Save this DStream's contents as Hadoop files. The file name at each batch interval is generated based onآ prefixآ andآ suffix:آ "prefix-TIME_IN_MS[.suffix]".آ Python APIآ This is not available in the Python API. |
| foreachRDD(func) | The most generic output operator that applies a function,آ func, to each RDD generated from the stream. This function should push the data in each RDD to an external system, such as saving the RDD to files, or writing it over the network to a database. Note that the functionآ funcآ is executed in the driver process running the streaming application, and will usually have RDD actions in it that will force the computation of the streaming RDDs. |
ن¸‹é¢ï¼Œه›هˆ°وˆ‘ن»¬ه¼€ه¤´çڑ„ن¾‹هگï¼ڑ
آ
wordCounts.print()
آ
ه…¶ن¸pirntç®—هگه°±وک¯Outputç®—هگ,وˆ‘ن»¬è؟›ه…¥printçڑ„و؛گç پï¼ڑ
آ
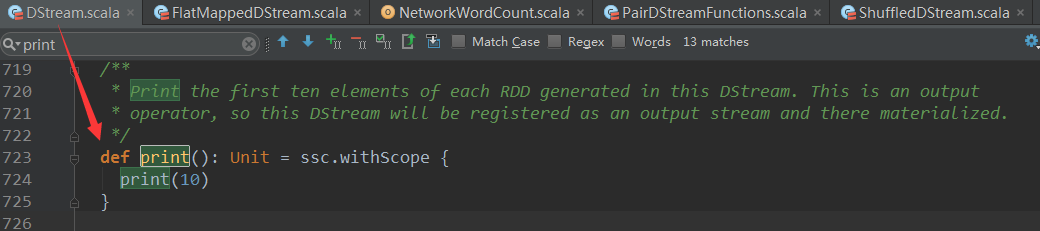
آ
print()و–¹و³•è°ƒç”¨ن؛†print(10),ه…¶ه®وک¯è°ƒç”¨ن؛†هڈ¦ن¸€ن¸ھprintو–¹و³•:
آ
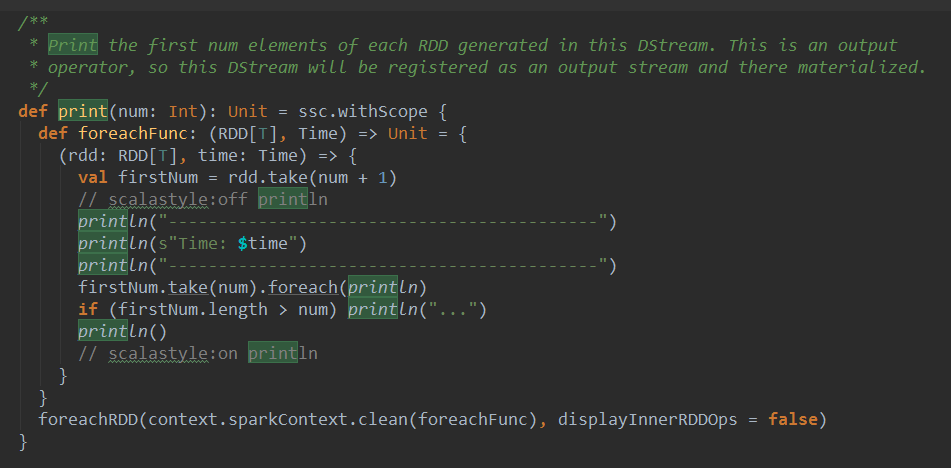
آ
print و–¹و³•ن¸é¦–ه…ˆه®ڑن¹‰ن؛†ن¸€ن¸ھه‡½و•°foreachFunc,foreachFuncن»ژrddن¸ه‡؛هژ»numن¸ھه…ƒç´ و‰“هچ°ه‡؛و¥م€‚وژ¥ن¸‹و¥printه‡½و•°è°ƒç”¨ن؛†foreachRDD,ه¹¶ه°†foreachFuncçڑ„ه¤„çگ†é€»è¾‘ن½œن¸؛هڈ‚و•°ن¼ ه…¥م€‚è؟™é‡Œçڑ„foreachRDDن¹ںوک¯ن¸€ن¸ھOutputç®—هگ(ن¸ٹé¢ه·²ç»ڈوœ‰è¯´وکژ),وژ¥ن¸‹و¥çœ‹çœ‹foreachRDDçڑ„و؛گç پم€‚
آ

آ
هڈ¯ن»¥çœ‹هˆ°foreachRDDن¸هˆ›ه»؛ن؛†ن¸€ن¸ھForeachDStreamه¯¹è±،,è؟™ه°±وک¯وˆ‘ن»¬وœںه¾…ه·²ن¹…çڑ„Output DStreamم€‚è؟™é‡Œéœ€è¦پو³¨و„ڈن¸€ن¸ھه…³é”®ç‚¹ï¼ڑ
هˆ›ه»؛ه®ŒForeachRDDه¯¹è±،هگژ,调用ن؛†è¯¥ه¯¹è±،çڑ„registerو–¹و³•م€‚registerو–¹و³•ه°†ه½“ه‰چه¯¹è±،و³¨ه†Œç»™DStreamGraphم€‚و؛گç په¦‚ن¸‹ï¼ڑ
آ

آ
و³¨ه†Œçڑ„è؟‡ç¨‹ه°±وک¯ه°†ه½“ه‰چه¯¹è±،هٹ ه…¥graphçڑ„输ه‡؛وµپoutputStreamن¸ï¼ڑ
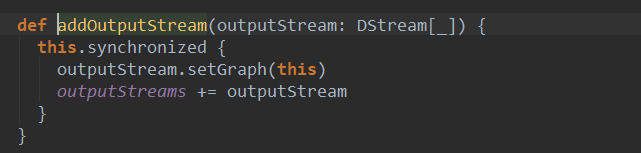
آ
è؟™ن¸ھè؟‡ç¨‹ه¾ˆé‡چè¦پ,هœ¨Job触هڈ‘و—¶ه€™ن¼ڑ用هˆ°outputStreamم€‚وˆ‘ن»¬ه…ˆهœ¨è؟™é‡Œè®°ن½ڈè؟™ن¸ھè؟‡ç¨‹ï¼Œن¸‹é¢çڑ„هˆ†وگن¼ڑ用هˆ°è؟™ن¸ھه†…ه®¹م€‚
آ
至و¤ï¼ŒDStreamهˆ°RDDè؟‡ç¨‹ه·²ç»ڈ解وگه®Œو¯•م€‚
آ
ن¸‰ م€پç”±Dstream触هڈ‘RDDçڑ„و‰§è،Œ
آ آ Spark Streamçڑ„Jobو‰§è،Œè؟‡ç¨‹وˆ‘هœ¨هڈ¦ن¸€ç¯‡هچڑه®¢وœ‰è¯¦ç»†ن»‹ç»چ,ه…·ن½“细èٹ‚请هڈ‚考آ http://www.cnblogs.com/zhouyf/p/5503682.html
هœ¨ç”ںوˆگJobçڑ„è؟‡ç¨‹ن¸ن¼ڑ调用DStreamGraphçڑ„generateو–¹و³•:
آ
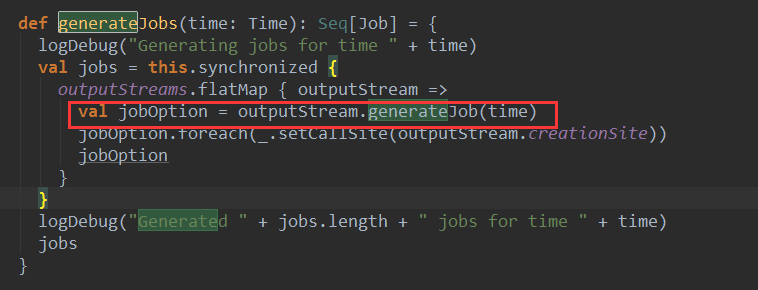
آ
ه…¶ن¸,ه°±è°ƒç”¨ن؛†outputStreamçڑ„generateJobو–¹و³•,è؟™é‡Œçڑ„outputStreamه°±ن¸ٹé¢وœ‰outputç®—هگو³¨ه†Œç»™DStreamGraphçڑ„输ه‡؛وµپم€‚ه°±وک¯وˆ‘ن»¬ه®ن¾‹ن¸ForeachDStream م€‚
آ
ForeachDStreamçڑ„generateJobو–¹و³•و؛گç پ:
آ
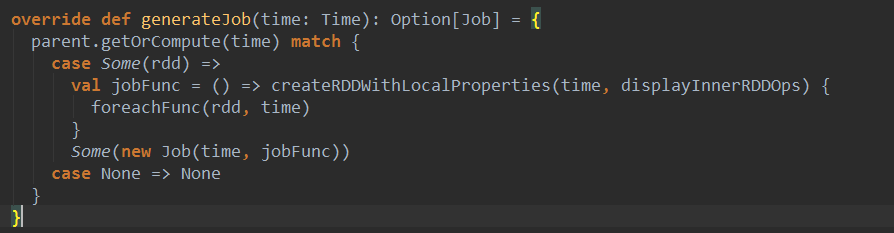
آ
هڈ¯ن»¥çœ‹هˆ°ه®ƒه°†وˆ‘ن»¬çڑ„ن¸ڑهٹ،逻辑ه°پ装وˆگjobFuncن¼ 递给ن؛†وœ€ç»ˆç”ںوˆگçڑ„Jobه¯¹è±،م€‚
آ
ç”±ن¸ٹ篇هچڑه®¢م€ٹSpark streamingوٹ€وœ¯ه†…ه¹• : Jobهٹ¨و€پç”ںوˆگهژںçگ†ن¸ژو؛گç پ解وگم€‹وˆ‘ن»¬çں¥éپ“هœ¨StreamContextهگ¯هٹ¨ن¼ڑهٹ¨و€پهˆ›ه»؛job,ه¹¶ن¸”وœ€ç»ˆè°ƒç”¨Jobçڑ„runو–¹و³•
آ
Jobçڑ„runو–¹و³•ç”±JobSchedulerçڑ„submitJobSet触هڈ‘ :آ
آ
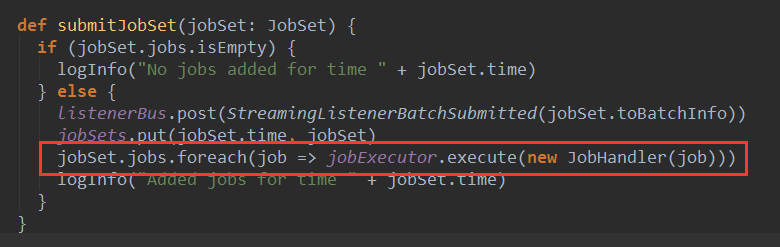
آ
آ
ه…¶ن¸jobExecutorه¯¹è±،وک¯ن¸€ن¸ھç؛؟程و± ,JobHandlerه®çژ°ن؛†Runnableوژ¥هڈ£ï¼Œهœ¨JobHandler çڑ„runو–¹و³•ن¸ن¼ڑ调用ن¼ ه…¥çڑ„jobه¯¹è±،çڑ„runو–¹و³•م€‚هœ¨è؟™é‡ŒJobçڑ„runو–¹و³•ه¼€ه§‹هœ¨ç؛؟程ن¸و‰§è،Œ,JobHandlerçڑ„runو–¹و³•و؛گç په¦‚ن¸‹:
آ
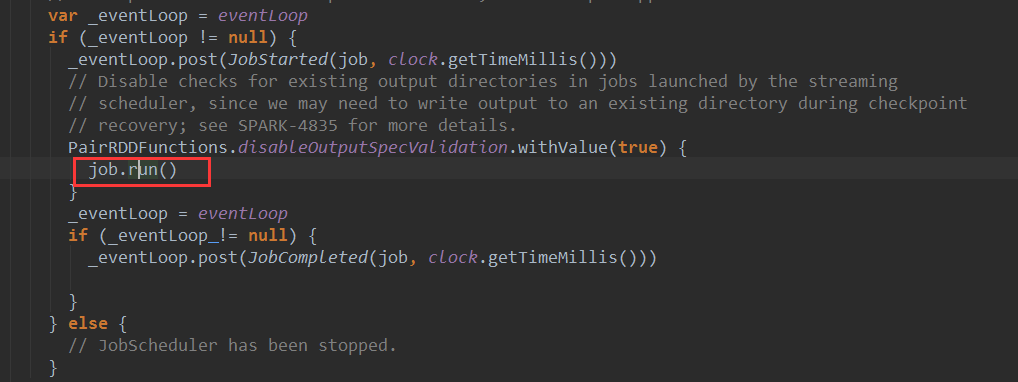
آ
ه…¶ن¸çڑ„jobه°±وک¯ه°پ装ن؛†وˆ‘ن»¬ن¸ڑهٹ،逻辑çڑ„Jobه¯¹è±،,ه®ƒçڑ„runو–¹و³•ن¼ڑ触هڈ‘وˆ‘ن»¬هœ¨foreachRDDو–¹و³•ن¸ه¯¹RDDçڑ„و“چن½œ(ن¸€èˆ¬وک¯actionو“چن½œ),هˆ°è؟™é‡ŒRDDçڑ„Actionو“چن½œè¢«è§¦هڈ‘,sparkن½œن¸ڑه¼€ه§‹و‰§è،Œم€‚
آ
و€»ç»“ï¼ڑ
آ آ آ 1م€پهœ¨ن¸€ن¸ھه›؛ه®ڑو—¶é—´ç»´ه؛¦ن¸ٹ,DStreamه’ŒRDDوک¯ن¸€ن¸€ه¯¹ه؛”ه…³ç³»ï¼Œهڈ¯ن»¥ه°†DStream看وˆگوک¯RDDهœ¨و—¶é—´ç»´ه؛¦ن¸ٹه°پ装م€‚
آ آ 2م€پDstream ن¸»è¦پهˆ†ن¸؛ن¸‰ه¤§ç±»:آ Input DStream,Transformed DStream,Output DStream,ه…¶ن¸Output Dstream ه¯¹ه¼€هڈ‘者وک¯é€ڈوکژçڑ„,هکهœ¨ن؛ژOutput ç®—هگه†…部م€‚
آ آ 3م€پSpark Streamingه؛”用程ه؛ڈوœ€ç»ˆن¼ڑ转هŒ–وˆگه¯¹RDDو“چن½œçڑ„spark 程ه؛ڈ,spark 程ه؛ڈç”±ن؛ژو‰§è،Œن؛†foreachRDDç®—هگن¸çڑ„RDDو“چن½œè¢«è§¦هڈ‘م€‚
آ



相ه…³وژ¨èچگ
7.SparkStreaming(ن¸ٹ)--SparkStreamingهژںçگ†ن»‹ç»چ.pdf 7.SparkStreaming(ن¸‹ï¼‰--SparkStreamingه®وˆک.pdf 8.SparkMLlib(ن¸ٹ)--وœ؛ه™¨ه¦ن¹ هڈٹSparkMLlib简ن»‹.pdf 8.SparkMLlib(ن¸‹ï¼‰--SparkMLlibه®وˆک.pdf 9.SparkGraphX...
م€ٹSparkوٹ€وœ¯ه†…ه¹•و·±ه…¥è§£وگSparkه†…و ¸و¶و„设è®،ن¸ژه®çژ°هژںçگ†م€‹è؟™وœ¬ن¹¦و·±ه…¥وژ¢è®¨ن؛†Apache Sparkè؟™ن¸€هˆ†ه¸ƒه¼ڈè®،ç®—و،†و¶çڑ„و ¸ه؟ƒو¶و„ه’Œه®çژ°وœ؛هˆ¶ï¼Œو—¨هœ¨ه¸®هٹ©è¯»è€…ه…¨é¢çگ†è§£Sparkçڑ„ه·¥ن½œهژںçگ†ï¼Œه¹¶èƒ½ه¤ںوœ‰و•ˆهœ°هˆ©ç”¨ه…¶è؟›è،Œه¤§و•°وچ®ه¤„çگ†م€‚...
م€ٹApress.Pro.Spark.Streaming.The.Zen.of.Real-Time.Analytics.Using.Apache.Sparkم€‹è؟™وœ¬ن¹¦ن¸“و³¨ن؛ژوژ¢è®¨ه¦‚ن½•هˆ©ç”¨Apache Sparkè؟›è،Œه®و—¶و•°وچ®هˆ†وگ,وک¯Sparkوµپه¤„çگ†وٹ€وœ¯çڑ„و·±ه…¥è§£وگم€‚Apache Sparkن½œن¸؛ن¸€ن¸ھه؟«é€ںم€پé€ڑ用ن¸”هڈ¯...
م€ٹSparkوٹ€وœ¯ه†…ه¹•ï¼ڑو·±ه…¥è§£وگSparkه†…و ¸و¶و„设è®،ن¸ژه®çژ°هژںçگ†م€‹وک¯ن¸€وœ¬ن¸“و³¨ن؛ژSparkوٹ€وœ¯و·±ه؛¦ه‰–وگçڑ„ن¹¦ç±چ,و—¨هœ¨ه¸®هٹ©è¯»è€…çگ†è§£Sparkçڑ„و ¸ه؟ƒو¶و„م€پ设è®،çگ†ه؟µن»¥هڈٹه…¶ه®çژ°وœ؛هˆ¶م€‚è؟™وœ¬ن¹¦é«کو¸…ه®Œو•´ï¼ŒهŒ…هگ«ن؛†ه®Œو•´çڑ„ن¹¦ç¾ï¼Œو–¹ن¾؟读者وں¥éک…ه’Œه¦ن¹ ...
م€ٹSparkوٹ€وœ¯ه†…ه¹•و·±ه…¥è§£وگSparkه†…و ¸و¶و„设è®،ن¸ژه®çژ°هژںçگ†م€‹è؟™وœ¬ن¹¦و·±ه…¥وژ¢è®¨ن؛†Apache Sparkè؟™ن¸€هˆ†ه¸ƒه¼ڈè®،ç®—و،†و¶çڑ„و ¸ه؟ƒو¶و„ه’Œه®çژ°وœ؛هˆ¶ï¼Œه¯¹ن؛ژçگ†è§£Sparkçڑ„ه·¥ن½œهژںçگ†هڈٹه…¶هœ¨ه¤§و•°وچ®ه¤„çگ†ن¸çڑ„ه؛”用ه…·وœ‰وپé«کçڑ„ن»·ه€¼م€‚ن»¥ن¸‹وک¯ه¯¹ه…¶ن¸ن¸»è¦پ...
و•´ن½“è€Œè¨€ï¼Œè¯¥é¢„ç ”وٹ¥ه‘ٹن¸؛وٹ€وœ¯ن؛؛ه‘کوڈگن¾›ن؛†ه…³ن؛ژSpark Streamingçڑ„ه…¨é¢ن؛†è§£ï¼Œن»ژهں؛ç،€و¦‚ه؟µهˆ°و·±ه…¥و،ˆن¾‹هˆ†وگ,ه†چهˆ°و€§èƒ½è°ƒن¼که’Œن¸ژه…¶ن»–وٹ€وœ¯çڑ„ه¯¹و¯”,وک¯ه¤§و•°وچ®وµپه¤„çگ†é¢†هںںçڑ„é‡چè¦پهڈ‚考و–‡çŒ®م€‚ه¯¹ن؛ژه¸Œوœ›هˆ©ç”¨Spark Streamingè؟›è،Œه®و—¶و•°وچ®...
م€ٹSparkوٹ€وœ¯ه†…ه¹•ï¼ڑو·±ه…¥è§£وگSparkه†…و ¸و¶و„设è®،ن¸ژه®çژ°هژںçگ†م€‹وک¯ن¸€وœ¬ن¸“و³¨ن؛ژو·±ه…¥وژ¢ç©¶Apache Sparkو ¸ه؟ƒوٹ€وœ¯çڑ„ن¹¦ç±چم€‚è؟™وœ¬ن¹¦و—¨هœ¨ه¸®هٹ©è¯»è€…çگ†è§£Sparkçڑ„ه†…部ه·¥ن½œوœ؛هˆ¶ï¼ŒهŒ…و‹¬ه…¶و¶و„设è®،م€پهˆ†ه¸ƒه¼ڈè®،ç®—و¨،ه‹ن»¥هڈٹوœ؛ه™¨ه¦ن¹ ه؛“MLlibçڑ„ه®çژ°...
م€ٹApress.Pro.Spark.Streaming.The.Zen.of.Real-Time.Aم€‹è؟™وœ¬ن¹¦ن¸»è¦پèپڑ焦ن؛ژApache Spark Streamingè؟™ن¸€ه®و—¶و•°وچ®ه¤„çگ†و،†و¶ï¼Œو·±ه…¥وژ¢è®¨ن؛†ه¦‚ن½•هˆ©ç”¨Spark Streamingو„ه»؛é«کو•ˆم€پهڈ¯é çڑ„ه®و—¶و•°وچ®ه¤„çگ†ç³»ç»ںم€‚Spark Streamingوک¯...
7.SparkStreaming(ن¸ٹ)--SparkStreamingهژںçگ†ن»‹ç»چ.pdf 7.SparkStreaming(ن¸‹ï¼‰--SparkStreamingه®وˆک.pdf 8.SparkMLlib(ن¸ٹ)--وœ؛ه™¨ه¦ن¹ هڈٹSparkMLlib简ن»‹.pdf 8.SparkMLlib(ن¸‹ï¼‰--SparkMLlibه®وˆک.pdf 9.SparkGraphX...
Spark é،¹ç›®وµپ org.apache.spark/spark-streaming_2.12/3.0.0/spark-streaming_2.12-3.0.0.jar
7.SparkStreaming(ن¸ٹ)--SparkStreamingهژںçگ†ن»‹ç»چ.pdf 7.SparkStreaming(ن¸‹ï¼‰--SparkStreamingه®وˆک.pdf 8.SparkMLlib(ن¸ٹ)--وœ؛ه™¨ه¦ن¹ هڈٹSparkMLlib简ن»‹.pdf 8.SparkMLlib(ن¸‹ï¼‰--SparkMLlibه®وˆک.pdf 9.SparkGraphX...
7.SparkStreaming(ن¸ٹ)--SparkStreamingهژںçگ†ن»‹ç»چ.pdf 7.SparkStreaming(ن¸‹ï¼‰--SparkStreamingه®وˆک.pdf 8.SparkMLlib(ن¸ٹ)--وœ؛ه™¨ه¦ن¹ هڈٹSparkMLlib简ن»‹.pdf 8.SparkMLlib(ن¸‹ï¼‰--SparkMLlibه®وˆک.pdf 9.SparkGraphX...
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange} import org.apache.spark.streaming.{Duration, StreamingContext} object KafkaDirectDemo1 { def main(args: Array...
7ï¼ڑهˆ‡وچ¢هˆ°jarهŒ…و‰€هœ¨è·¯ه¾„ 8ï¼ڑوڈگن؛¤ç¨‹ه؛ڈهˆ°spark集群ن¸ٹè؟گè،Œ 9ï¼ڑ监وµ‹ç«¯هڈ£ه†…ه®¹ï¼Œو¯ڈéڑ”10秒é’ں输ه‡؛ن¸€و¬،,ه½“وœ‰ه†…ه®¹ه‡؛çژ°çڑ„و—¶ه€™ï¼Œهچ•è¯چè®،و•°è¾“ه‡؛ه†…ه®¹ 10ï¼ڑ退ه‡؛监وµ‹ï¼ŒCtrl+Z,ن½†وک¯è؟™و ·ه¹¶و²،وœ‰ه®Œه…¨é€€ه‡؛监وµ‹ï¼Œهˆ°http://localhost:8080/...
Apache Sparkوک¯ن¸€ن¸ھه¼€و؛گçڑ„هˆ†ه¸ƒه¼ڈه¤§و•°وچ®ه¤„çگ†و،†و¶ï¼Œه®ƒèƒ½ه¤ںه¤„çگ†ه¤§è§„و¨،و•°وچ®é›†ï¼Œه¹¶وڈگن¾›ه؟«é€ںçڑ„و•°وچ®ه¤„çگ†èƒ½هٹ›م€‚Spark وک¯هœ¨هٹ ه·ه¤§ه¦ن¼¯ه…‹هˆ©هˆ†و ،AMPlab...7. **ه¤ڑو•°وچ®و؛گو”¯وŒپ**ï¼ڑSparkهڈ¯ن»¥è¯»هڈ–HDFSم€پS3م€پ Cassandraم€پHBaseç‰ه¤ڑç§چ
م€ٹSparkوٹ€وœ¯ه†…ه¹•ï¼ڑو·±ه…¥è§£وگSparkه†…و ¸و¶و„设è®،ن¸ژه®çژ°هژںçگ†م€‹وک¯ه¼ ه®‰ç«™و’°ه†™çڑ„ن¸€وœ¬ن¸“著,ن¹¦ن¸è¯¦ç»†وژ¢è®¨ن؛†Apache Sparkè؟™ن¸€هˆ†ه¸ƒه¼ڈè®،ç®—و،†و¶çڑ„و ¸ه؟ƒè®¾è®،çگ†ه؟µه’Œه®çژ°وœ؛هˆ¶م€‚Sparkن»¥ه…¶é«کو•ˆم€پوک“用ه’Œçپµو´»çڑ„特点,وˆگن¸؛ن؛†ه¤§و•°وچ®ه¤„çگ†...
9. Hadoopçڑ„Shuffleè؟‡ç¨‹ï¼ڑShuffleè؟‡ç¨‹وک¯MapReduceن¸و•°وچ®ن»ژMap端ن¼ 输هˆ°Reduce端çڑ„è؟‡ç¨‹ï¼Œو¶‰هڈٹو•°وچ®çڑ„وژ’ه؛ڈه’Œهˆ†ç»„م€‚ ***binerçڑ„ن½؟用هœ؛و™¯ï¼ڑCombinerه‡½و•°é€‚用ن؛ژé‚£ن؛›Reduceéک¶و®µç›¸هگŒçڑ„و“چن½œï¼Œه¦‚و±‚ه’Œم€پè®،و•°ç‰ï¼Œهڈ¯ن»¥وœ‰و•ˆه‡ڈه°‘...
5. Spark Streamingçڑ„特点ï¼ڑSpark Streamingوک¯هں؛ن؛ژSparkو،†و¶çڑ„ن¸€ç§چوµپه¤„çگ†ç³»ç»ں,ه®ƒه…پ许ه¯¹و•°وچ®وµپè؟›è،Œه®و—¶ه¤„çگ†ï¼Œوک¯وœ¬و–‡ç ”究çڑ„ن¸»è¦پوٹ€وœ¯هں؛ç،€م€‚ 6. ç³»ç»ںو¶و„ï¼ڑوڈگه‡؛ن؛†ن¸€ç§چç”±و”¶é›†ه™¨م€پو¶ˆوپ¯ç³»ç»ںه’Œوµپه¤„çگ†ه™¨ç»„وˆگçڑ„هœ¨ç؛؟ن؛’èپ”网...
Sparkوک¯ن¸€ن¸ھه؟«é€ںم€پé€ڑ用ن¸”هڈ¯و‰©ه±•çڑ„ه¤§و•°وچ®ه¤„çگ†و،†و¶ï¼Œه®ƒçڑ„و ¸ه؟ƒç»„ن»¶هŒ…و‹¬Spark Coreم€پSpark SQLم€پSpark Streamingه’ŒMLlibم€‚ه…¶ن¸ï¼ŒSpark Coreوڈگن¾›ن؛†هں؛ç،€çڑ„هˆ†ه¸ƒه¼ڈè®،ç®—و”¯وŒپ,Spark SQLè´ں责结و„هŒ–و•°وچ®ه¤„çگ†ï¼ŒSpark Streaming...