
 
┬á ┬á┬áňÄčňłŤŠľçšźá´╝îŔŻČŔŻŻŔ»ĚŠ│ĘŠśÄ:ŔŻČŔŻŻŔç¬┬áňÉČÚúÄň▒ůňúźňŹÜň«ó(http://zhou-yuefei.iteye.com/)┬á┬á
┬á ┬á┬áSpark streaming šĘőň║ĆÚťÇŔŽüńŞŹŠľşŠÄąŠöŠľ░ŠĽ░ŠŹ«´╝îšäÂňÉÄŔ┐ŤŔíîńŞÜňŐíÚÇ╗ŔżĹňĄäšÉć´╝îŔÇîšöĘń║ÄŠÄąňĆŚŠĽ░ŠŹ«šÜäň░▒Šś»ReceverŃÇ銜żšäÂReceiveršÜ䊺úňŞŞŔ┐ÉŔíîň»╣ň║öŠĽ┤ńެSpark Streamingň║öšöĘšĘőň║ĆŔç│ňů│ÚçŹŔŽü´╝îňŽéŠ×ťReceiverňç║šÄ░ň╝éňŞŞ´╝îňÉÄÚŁóšÜäńŞÜňŐíÚÇ╗ŔżĹň░▒ŠŚáń╗ÄŔ░łŔÁĚŃÇéSpark Streaming Šś»ňŽéńŻĽň«×šÄ░Receiverń╗ąń┐ŁŔ»üňůÂňƻڣáŠÇžšÜä´╝Ȋľçň░ćš╗ôňÉłSpark StreamingšÜäReceiverŠ║Éšáüň«×šÄ░Ŕ»Žš╗ćŔžúŠ×ÉReceiveršÜäň«×šÄ░ňÄčšÉćŃÇé
 
ńŞÇŃÇüReceiver ň«×šÄ░šşľšĽąŠÇŁŔÇâ
┬á ┬á┬á1ŃÇüňÉ»ňŐĘReceiveršÜ䊌ÂňÇÖ,ňÉ»ňŐĘńŞÇńެJob´╝îŔ┐ÖńެJobÚçîÚŁóŠťëRDDšÜätransformationsŠôŹńŻťňĺîactionšÜäŠôŹńŻť´╝îŔ┐ÖńެJobňƬŠťëńŞÇńެpartition.Ŕ┐ÖńެpartitionšÜäšë╣Š«ŐŠś»ÚçîÚŁóňƬŠťëńŞÇńެŠłÉňĹś´╝îŔ┐ÖńެŠłÉňĹśň░▒Šś»ňÉ»ňŐĘšÜäReceiverŃÇéŔ┐ÖŠáĚňüÜšÜäÚŚ«Úóś´╝Ü
┬á ┬á┬á┬á ┬á┬áa) ┬áňŽéŠ×ťŠťëňĄÜńެInputDStream´╝îÚéúň░▒ŔŽüňÉ»ňŐĘňĄÜńެReceiver´╝ĆńެReceiverń╣čň░▒šŤŞňŻôń║Äňłćšëçpartition´╝îÚéúŠłĹń╗ČňÉ»ňŐĘReceiveršÜ䊌ÂňÇÖšÉćŠâ│šÜäŠâůňćÁńŞőŠś»ňťĘńŞŹňÉîšÜ䊝║ňÖĘńŞŐňÉ»ňŐĘReceiver´╝îńŻćŠś»Spark CorešÜäŔžĺň║ŽŠŁąšťőň░▒Šś»ň║öšöĘšĘőň║Ć´╝îŠäčŔžëńŞŹňł░ReceiveršÜäšë╣Š«ŐŠÇž´╝îŠëÇń╗ąň░▒ń╝ÜŠîëšůžŠşúňŞŞšÜäJobňÉ»ňŐĘšÜ䊾╣ň╝ĆŠŁąňĄäšÉć´╝îŠ×üŠťëňĆ»ŔâŻňťĘńŞÇńެExecutorńŞŐňÉ»ňŐĘňĄÜńެReceiver.Ŕ┐ÖŠáĚšÜäŔ»Łň░▒ňĆ»ŔâŻň»╝Ŕç┤Ŕ┤čŔŻŻńŞŹňŁçŔííŃÇé
┬á ┬á┬á┬á ┬á┬áb) ┬ኝëňĆ»ŔâŻňÉ»ňŐĘReceiverňĄ▒Ŕ┤ą´╝îňƬŔŽüÚŤćšżĄňşśňťĘReceiverň░▒ńŞŹň║öŔ»ąňĄ▒Ŕ┤ąŃÇé
┬á ┬á┬á┬á ┬á┬ác) ┬áŔ┐ÉŔíîŔ┐çšĘőńŞş´╝îň░▒Ú╗śŔ«ĄšÜäŔÇîŔĘÇňŽéŠ×ťŠś»ńŞÇńެpartitionšÜäŔ»Ł´╝îÚéúňÉ»ňŐĘšÜ䊌ÂňÇÖň░▒Šś»ńŞÇńެTask´╝îńŻćŠś»ŠşĄTaskń╣čňżłňĆ»ŔâŻňĄ▒Ŕ┤ą´╝îňŤáŠşĄń╗ąTaskňÉ»ňŐĘšÜäReceiverń╣čń╝ÜŠîéŠÄëŃÇé
 
┬á ┬á 2ŃÇüšö▒Spark Streaming Ŕç¬ňĚ▒š«íšÉćReceiver´╝îŔ┤čŔ┤úReceiveršÜäŔ░âň║Žňĺîň«╣ÚöÖňĺîňÉ»ňŐĘŃÇéŔ┐ÖŠáĚňüÜšÜäňąŻňĄä´╝Ü
┬á ┬á┬á┬á ┬á a´╝ëšö▒Spark Streaming┬áŔ░âň║ŽReceiver ňĆ»ń╗ąňůůňłćŔÇâŔÖĹŔ┤čŔ┤úňŁçŔíí´╝îÚü┐ňůŹň░ćňĄÜńެReceiverŔ░âň║Žňł░ňÉîńŞÇňĆ░Šť║ňÖĘńŞŐ
┬á ┬á┬á┬á ┬á b´╝ëReceiver ňĄ▒Ŕ┤ąňÉÄňĆ»ń╗ąŔç¬ňŐĘÚ珊ľ░ňÉ»ňŐĘ´╝îš╗žš╗şŠÄąňĆŚŠĽ░ŠŹ«´╝îń╗ÄŔÇîńŻ┐šĘőň║ĆŠîüš╗şńŞŹŠľşš╗žš╗şňĚąńŻťńŞőňÄ╗ŃÇé
┬á ┬á┬á┬á ┬á c´╝ëReceiver ÚçŹňÉ»ńŞŹŠöÂTaskÚçŹňÉ»ŠČ튼░šÜäÚÖÉňłÂŃÇé
 
ń║îŃÇüSpark StreamingšÜäReceiverň«×šÄ░ňÄčšÉć
┬á ┬á┬á2.1ŃÇüňĺîReceiverň«×šÄ░šŤŞňů│ŠáŞň┐⊳ÉňĹś
┬á ┬á┬á┬á ┬á ´╝ł1´╝ëReceiverTracker
┬á ┬á┬á┬á ┬á┬á´╝ł2´╝ëReceiverTrackerEndpoint
┬á ┬á┬á┬á ┬á ´╝ł3´╝ëReceiverSuperVisor
┬á ┬á┬á┬á ┬á ´╝ł4´╝ëReceiver
┬á ┬á┬áReceiverTrackerňťĘDriveršź»,ReceiverSuperVisorňĺîReceiverňťĘExecutoršź»,Š×Š×äňŤżňŽéńŞő´╝Ü
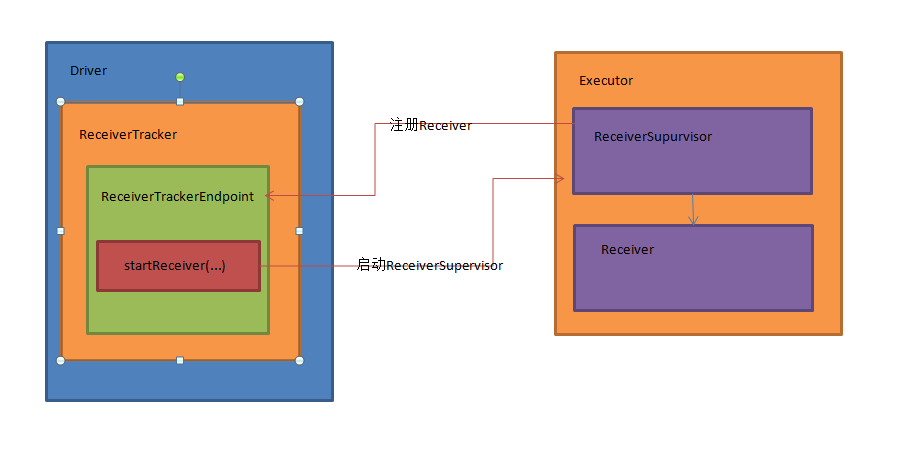
 
┬á ┬á┬á2.2 ┬áSpark StreamingšÜäReceiverň«×šÄ░Š║ÉšáüŔžúŠ×É
ÚŽľňůłSparkStreamňÉ»ňŐĘŠŚÂňÇÖń╝ÜňÉ»ňŐĘJobScheduler,ňťĘJobSceduleršÜästartŠľ╣Š│ĽńŞş,ń╝Üň«×ńżőňîľReceiverTracker,ň╣ÂŔ░âšöĘReceiverTrackeršÜästartŠľ╣Š│ĽňÉ»ňŐĘReceiverTrackerŃÇé
 
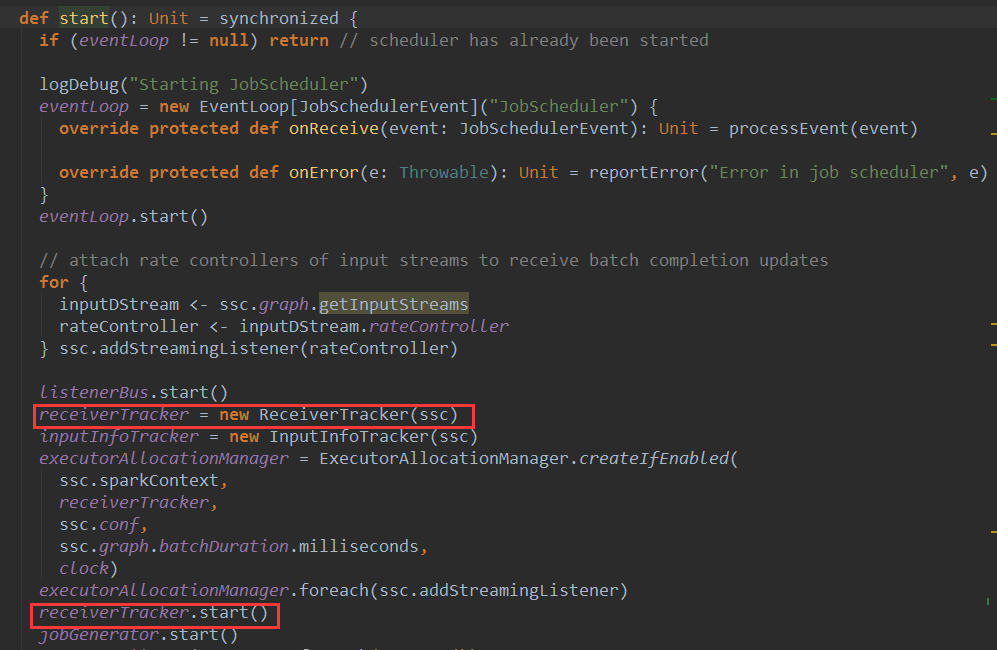
 
ReceiverTrackeršÜästartŠľ╣Š│ĽÚŽľňůłŠúÇŠčąŔżôňůąŠÁüŠś»ňÉŽńŞ║šę║´╝îňŽéŠ×ťńŞŹńŞ║šę║ń╝ÜňłŤň╗║ReceiverTrackerEndpointň╣Š│Ęňćîš╗ÖrpcEnvŃÇéšäÂňÉÄŔ░âšöĘlaunchReceiversŠľ╣Š│ĽňÉ»ňŐĘReceiverŃÇéňůÂńŞşreceiverInputStreamsŠś»Š│Ęňćîňł░DStreamGraphńŞşšÜäReceiverInputDStreamŃÇé
 

 
 
ńŞőÚŁóšťőńŞÇńŞőlaunchReceiverŠľ╣Š│Ľ´╝Üňč║ń║ÄReceiverInputDStream(Šś»ňťĘDriveršź»)ŠŁąŔÄĚňżŚňůĚńŻôšÜäReceiversň«×ńżő´╝îšäÂňÉÄň揊ŐŐń╗ľń╗ČňłćńŞŹňł░WorkerŔŐéšé╣ńŞŐŃÇéńŞÇńެReceiverInputDStreamňƬń║žšöčńŞÇńެReceiver
 
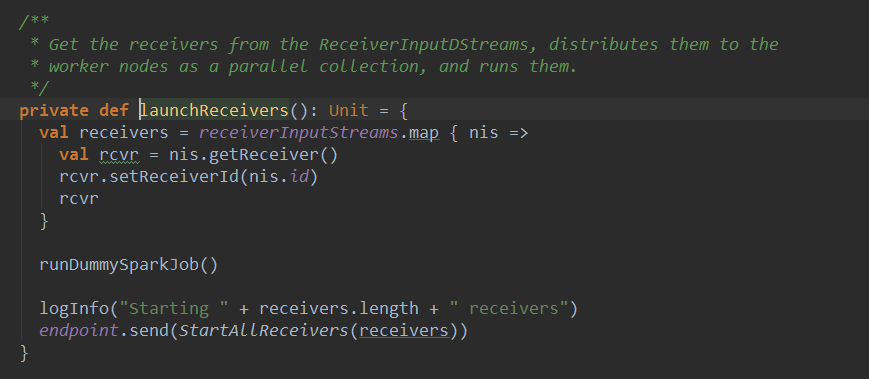
 
ÚŽľňůłń╗ÄReceiverInputDStreamńŞşŔÄĚňĆľReceiver´╝îšäÂňÉÄŔ░âšöĘrunDummySparkJobňÉ»ňŐĘńŞÇńެŔÖÜŠőčń╗╗ňŐí´╝Ĺń╗ČňťĘňÉÄÚŁóňćŹňłćŠ×ÉŔ┐ÖńެŔÖÜŠőčń╗╗ňŐí´╝îňůłšťőńŞÇńŞőňÉÄÚŁóšÜäŠáŞň┐âń╗úšáü´╝Ü
    endpoint.send(StartAllReceivers(receivers))
ŠşĄňĄäšÜäendpointň░▒Šś»ňłÜŠëŹň«×ńżőňîľšÜäReceiverTrackerEndpointň»╣Ŕ▒íšÜäň╝ĽšöĘ´╝îňĆ»ń╗ąšťőňł░ŠşĄňĄäš╗ÖendpointňĆĹÚÇüń║ćStartAllReceiversŠÂłŠü»ŃÇé
ńŞőÚŁóšťőńŞőńŞÇReceiverTrackerEndpointŠöÂňł░StartAllReceiversŠÂłŠü»ňÉÄšÜäňĄäšÉćÚÇ╗ŔżĹ´╝Ü
 
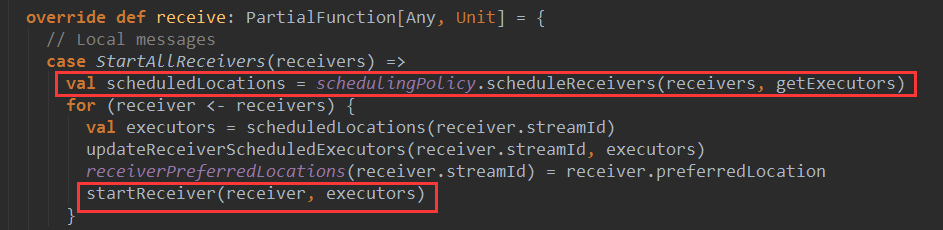
 
ÚŽľňůł´╝îŠá╣ŠŹ«ńŞÇň«ÜšÜäŔ░âň║ŽšşľšĽąš╗Öń╝áňůąreceiversňłćÚůŹšŤŞň║öšÜäexecutors´╝îń╗ÄŔ┐ÖÚçîňĆ»ń╗ąšťőňç║´╝îReceiveršÜäŔ░âň║Žň╣ÂńŞŹŠś»ń║Ąš╗ÖsparkňćůŠáŞň«îŠłÉšÜä´╝îŔÇ»šö▒Spark StreamingŠíćŠ×Âň«îŠłÉŔ░âň║ŽŔ┐çšĘőŃÇéŔ┐ÖŠáĚňüÜšÜ䚍«šÜäň░▒Šś»ńŞ║ń║ćÚü┐ňůŹSparkňćůŠáŞň░ćReceiverňŻôňüÜŠÖ«ÚÇÜšÜäjobŔÇîň░ćňĄÜńެReceiverŔ░âň║Žňł░ňÉîńŞÇńެŔŐéšé╣ńŞŐŃÇé┬á
Spark StreamingšÜäŔ░âň║ŽšşľšĽąŔ┐ÖÚçîńŞŹňüÜňłćŠ×É´╝îŠÄąšŁÇšťőńŞőÚŁóšÜäń╗úšáü´╝îŔ┐şń╗úŠëÇń╗ąšÜäreceiver ´╝îň»╣Š»ĆńެreceiverŔ░âšöĘ startReceiverŠľ╣Š│ĽňťĘňůĚńŻôExecutorńŞŐňÉ»ňŐĘReceiverŃÇé
 
Ŕ┐ÖńެstartReceiverŠ»öŔżâňĄŹŠŁé´╝Ĺń╗ČńŞÇŠşąŠşąňłćŠ×É´╝îňůłšťőŠťÇŠáŞň┐âšÜäńŞÇŔíîń╗úšáü´╝Ü
 

 
ňĆ»šťőňł░´╝îSpark Streaming ńŞ║Š»ĆńެReceiver ňÉ»ňŐĘń║ćńŞÇńެjob´╝îŔÇîńŞŹŠś»šö▒ActionŠôŹńŻťňç║ňĆĹJobŠëžŔíîŃÇé
Ŕ┐ÖÚçîjobšÜäŠĆÉń║ĄńŞ╗ŔŽüňů│Š│ĘńŞĄńެňĆ銼░receiverRDDňĺîstartReceiverFuncŃÇé
 
receiverRDDšÜäŠ║Éšáü´╝Ü
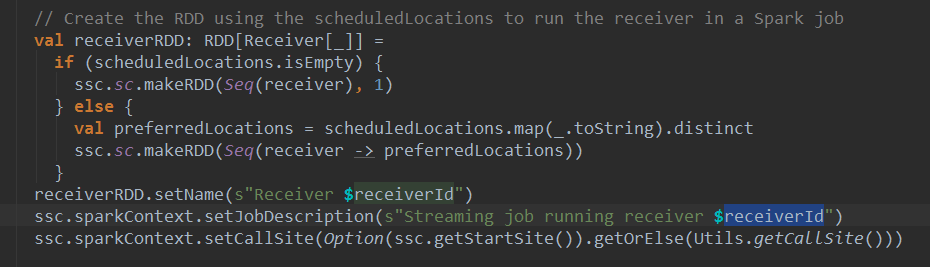
 
ňĆ»ń╗ąšťőňł░Ŕ░âšöĘń║ćSparkContextšÜämakeRDDŠľ╣Š│ĽňłŤň╗║ń║ćRDD´╝îŔ»ąRDDňƬŠťëńŞÇŠŁíŠĽ░ŠŹ«´╝îň░▒Šś»receiverň»╣Ŕ▒í
 
ńŞőÚŁóšťőńŞÇšťőstartReceiverFuncšÜäŠ║Éšáü
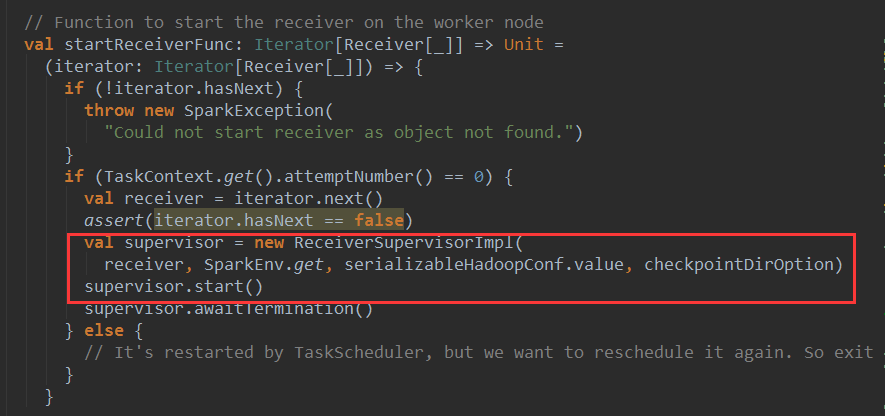
 
startReceiverFunc ňťĘworkerŔŐéšé╣ńŞŐňÉ»ňŐĘreceiver´╝îÚŽľňůłňłŤň╗║ń║ćńŞÇńެReceiverSupervisiorImpl ň»╣Ŕ▒í supervisor´╝îšäÂňÉÄŔ░âšöĘsupervisoršÜästartŠľ╣Š│ĽňťĘŔ»ąŔŐéšé╣ńŞŐňÉ»ňŐĘsupervisor´╝Ü
 
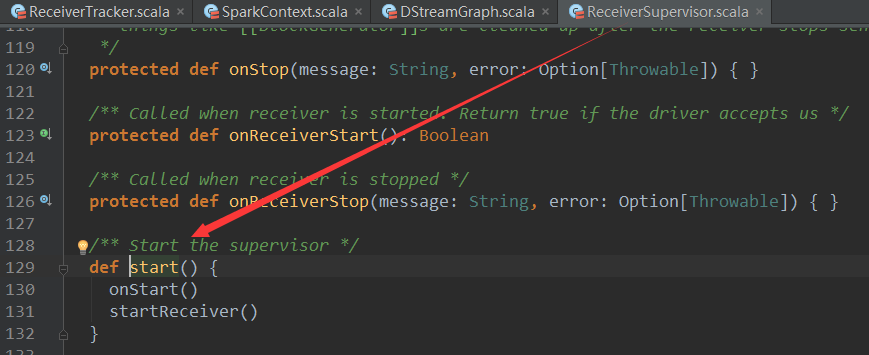
 
ReceiverSupervisiorImpl Šś»š╗žŠë┐Ŕç¬ReceiverSupervisor´╝îReceiverSupervisorńŞşŔ░âšöĘń║ćstartReceiverŠľ╣Š│Ľ´╝Ü
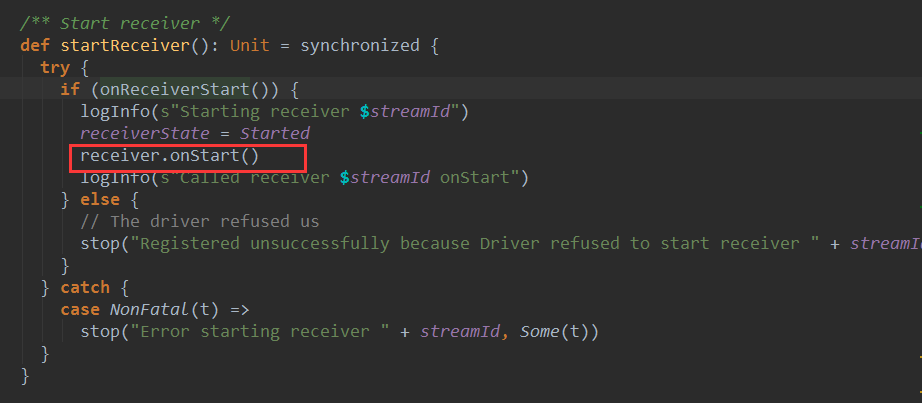
 
ÚŽľňůłŔ░âšöĘonReceiverStartŠľ╣Š│Ľ´╝îň░ćReceiverŠ│Ęňćîš╗ÖreceiverTracker´╝Ü

 
ňŽéŠ×ťŠ│ĘňćÉňŐč´╝îŔ░âšöĘń║ćReceiveršÜäonStartŠľ╣Š│ĽňťĘExecutorňÉ»ňŐĘReceiverńŞŹŠľşŠÄąňĆŚŠĽ░ŠŹ«´╝îň╣Âň░ćŠÄąŠöšÜ䊼░ŠŹ«ń║Ąš╗ÖBlockManagerš«íšÉć´╝îŔç│ŠşĄReceiverňÉ»ňŐĘň«îŠłÉŃÇé
 
ňŤ×ňł░ReceiverTrackeršÜästartReceiverŠľ╣Š│Ľ´╝îňŽéŠ×ťReceiverň»╣ň║öšÜäjobň«îŠłÉ´╝áŔ«║Ŕ┐öňŤ×ŠłÉňŐ芳ľňĄ▒Ŕ┤ą´╝îňƬŔŽüReceiverTrackerŔ┐śŠ▓튝ëňüťŠşóň░▒ń╝ÜňĆĹÚÇüRestartReceiverŠÂłŠü»š╗ÖReceiverTrakerEndpoint´╝îÚçŹňÉ»ReceiverŃÇéń╗ÄŔ┐ÖÚçîňĆ»ń╗ąšťőňç║ReceiverńŞŹń╝ÜňâĆŠÖ«ÚÇÜšÜäspark core šĘőň║ĆńŞÇŠáĚňĆŚňł░ÚçŹŔ»ĽŠČ튼░šÜäÚÖÉňłÂŔÇîň»╝Ŕç┤ńŻťńŞÜňĄ▒Ŕ┤ą
 
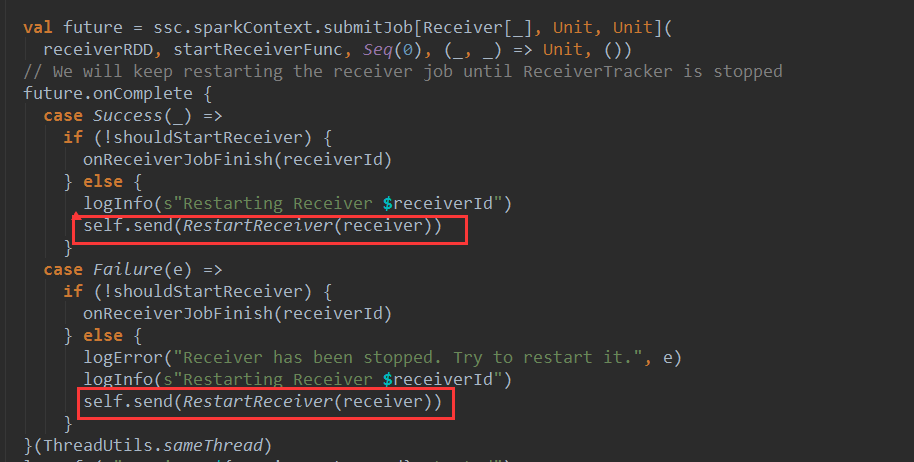
 
 
ŠťÇňÉÄ´╝îňťĘšťőńŞÇńŞőrunDummyJobŠľ╣Š│Ľ´╝Ü
 

 
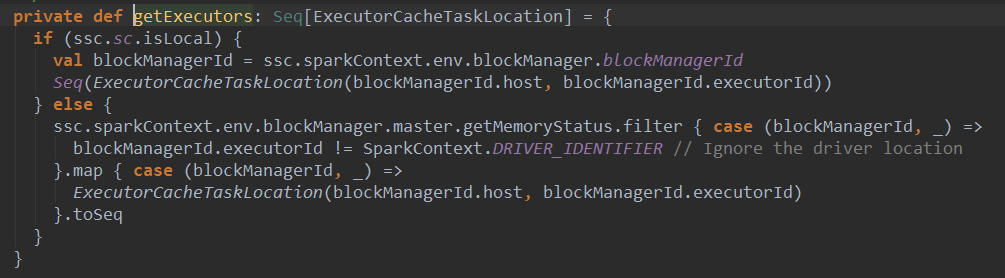
Ŕ»ąŠľ╣Š│ĽŔ┐ÉŔíîń║ćńŞÇńެš«ÇňŹĽšÜäwordcountšĘőň║Ć´╝îŔ┐ÉŔíîŔ»ąšĘőň║ĆšÜ䚍«šÜ䊜»ší«ń┐ŁŠëÇŠťëslavesŔŐéšé╣ÚâŻŔóźŠ│Ęňćîń║ć´╝îŔ«ęreceiverň░ŻÚçĆňłćÚůŹňł░ńŞŹňÉîšÜäworkńŞŐŔ┐ÉŔíî´╝îšťőńŞÇńŞőgetExecutorsšÜäŠ║Éšáü :
 
 
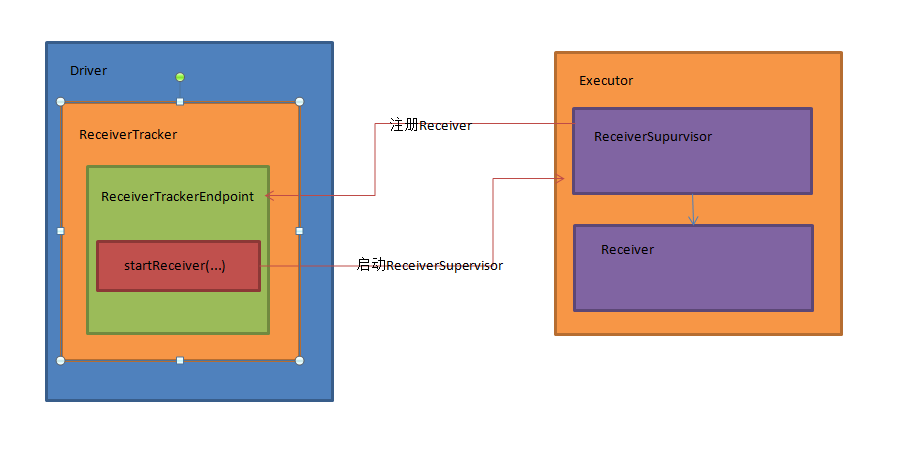
ŠÇ╗š╗ô´╝ÜDriveršź»šÜäReceiverTrackerš«íšÉćŠëÇŠťëExecutorńŞŐšÜäReceiverń╗╗ňŐí´╝îń╗ľŠťëńŞÇńެReceiverTrakerEndpoint ŠÂłŠü»ÚÇÜŔ«»ńŻô´╝îŔ┐ÖńެŠÂłŠü»ÚÇÜŔ«»ńŻôňťĘstartReceiverŠľ╣Š│ĽńŞşŠĆÉń║ĄReceiveršÜäjobňťĘňůĚńŻôExecutorńŞŐŔ┐ÉŔíî´╝îň╣ŠĹňĆŚExecutoršź»ňĆĹÚÇüŔ┐犣ąšÜäŠÂłŠü»´╝łŠ»öňŽéŠ│ĘňćîReceiver´╝ë,ňťĘExecutoršź»ŠťëńŞÇńެReceiverSupervisorńŞôÚŚĘš«íšÉćReceiver´╝îŔ┤čŔ┤úReceiveršÜäŠ│ĘňćîňÉ»ňŐĘńŞÄReceiverTrackeršÜäń┐íŠü»ń║Ąń║ĺŃÇé
 



šŤŞňů│ŠÄĘŔŹÉ
1.SparkňĆŐňůšöčŠÇüňťłš«Çń╗ő.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞŐ´╝ë--ňč║šíǚĻňóâŠÉşň╗║.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞő´╝ë--Sparkš╝ľŔ»Ĺň«ëŔúů.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞş´╝ë--Hadoopš╝ľŔ»Ĺň«ëŔúů.pdf 3.Sparkš╝ľšĘőŠĘíň×ő´╝łńŞŐ´╝ë--ŠŽéň┐ÁňĆŐSparkShellň«×Šłś....
ŃÇŐApress.Pro.Spark.Streaming.The.Zen.of.Real-Time.Analytics.Using.Apache.SparkŃÇőŔ┐ÖŠťČń╣ŽńŞôŠ│Ęń║ÄŠÄóŔ«ĘňŽéńŻĽňłęšöĘApache SparkŔ┐ŤŔíîň«×ŠŚÂŠĽ░ŠŹ«ňłćŠ×É´╝»SparkŠÁüňĄäšÉćŠŐÇŠť»šÜäŠĚ▒ňůąŔžúŠ×ÉŃÇéApache SparkńŻťńŞ║ńŞÇńެň┐źÚÇčŃÇüÚÇÜšöĘńŞöňĆ»...
ŃÇŐSparkŠŐÇŠť»ňćůň╣ĽŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŔ┐ÖŠťČń╣ŽŠĚ▒ňůąŠÄóŔ«Ęń║ćApache SparkŔ┐ÖńŞÇňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×šÜäŠáŞň┐âŠ×Š×äňĺîň«×šÄ░Šť║ňłÂ´╝ĘňťĘňŞ«ňŐęŔ»╗ŔÇůňůĘÚŁóšÉćŔžúSparkšÜäňĚąńŻťňÄčšÉć´╝îň╣ÂŔâŻňĄčŠťëŠĽłňť░ňłęšöĘňůÂŔ┐ŤŔíîňĄžŠĽ░ŠŹ«ňĄäšÉćŃÇé...
ŃÇŐSparkŠŐÇŠť»ňćůň╣ĽŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŔ┐ÖŠťČń╣ŽŠĚ▒ňůąŠÄóŔ«Ęń║ćApache SparkŔ┐ÖńŞÇňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×šÜäŠáŞň┐âŠ×Š×äňĺîň«×šÄ░Šť║ňłÂ´╝îň»╣ń║ÄšÉćŔžúSparkšÜäňĚąńŻťňÄčšÉćňĆŐňůÂňťĘňĄžŠĽ░ŠŹ«ňĄäšÉćńŞşšÜäň║öšöĘňůĚŠťëŠ×üÚźśšÜäń╗ĚňÇ╝ŃÇéń╗ąńŞőŠś»ň»╣ňůÂńŞşńŞ╗ŔŽü...
ńżőňŽé´╝îňŤż2-4ň▒ĽšĄ║ń║ćSpark StreamingńŞÄStormňťĘňÉ×ňÉÉÚçĆńŞŐšÜ䊻öŔżâš╗ôŠ×ť´╝îŔÇîňŤż6-3ŃÇüňŤż6-4ňĺîňŤż6-5ňłÖňłćňłźň▒ĽšĄ║ń║ćStormŃÇüSpark StreamingňĺîSamzašÜäŠ×Š×äňŤżŃÇéÚÇÜŔ┐çŔ┐Öń║Ťň»╣Š»ö´╝îŠŐÇŠť»ń║║ňĹśňĆ»ń╗ąŠŤ┤ňąŻňť░ń║ćŔžúňÉäŔ笚ÜäŠŐÇŠť»ń╝śňŐ┐ňĺîÚÇéšöĘňť║ŠÖ»ŃÇé 7. ...
ŃÇŐSparkŠŐÇŠť»ňćůň╣Ľ´╝ÜŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŠś»ńŞÇŠťČńŞôŠ│Ęń║ÄSparkŠŐÇŠť»ŠĚ▒ň║Žň뾊×ÉšÜäń╣Žš▒Ź´╝ĘňťĘňŞ«ňŐęŔ»╗ŔÇůšÉćŔžúSparkšÜäŠáŞň┐âŠ×Š×äŃÇüŔ«żŔ«íšÉćň┐Áń╗ąňĆŐňůÂň«×šÄ░Šť║ňłÂŃÇéŔ┐ÖŠťČń╣ŽÚźśŠŞůň«îŠĽ┤´╝îňîůňÉźń║ćň«îŠĽ┤šÜäń╣Žšşż´╝╣ńż┐Ŕ»╗ŔÇůŠčąÚśůňĺîňşŽń╣á...
1.SparkňĆŐňůšöčŠÇüňťłš«Çń╗ő.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞŐ´╝ë--ňč║šíǚĻňóâŠÉşň╗║.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞő´╝ë--Sparkš╝ľŔ»Ĺň«ëŔúů.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞş´╝ë--Hadoopš╝ľŔ»Ĺň«ëŔúů.pdf 3.Sparkš╝ľšĘőŠĘíň×ő´╝łńŞŐ´╝ë--ŠŽéň┐ÁňĆŐSparkShellň«×Šłś....
ŃÇŐSparkŠŐÇŠť»ňćůň╣Ľ´╝ÜŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŠś»ńŞÇŠťČńŞôŠ│Ęń║ÄŠĚ▒ňůąŠÄóšęÂApache SparkŠáŞň┐âŠŐÇŠť»šÜäń╣Žš▒ŹŃÇéŔ┐ÖŠťČń╣ŽŠŚĘňťĘňŞ«ňŐęŔ»╗ŔÇůšÉćŔžúSparkšÜäňćůÚâĘňĚąńŻťŠť║ňłÂ´╝îňîůŠőČňůŠ×Š×äŔ«żŔ«íŃÇüňłćňŞâň╝ĆŔ«íš«ŚŠĘíň×őń╗ąňĆŐŠť║ňÖĘňşŽń╣áň║ôMLlibšÜäň«×šÄ░...
5. ňĆ»Šëęň▒ĽŠÇžňĺîšĘ│ň«ÜŠÇž´╝ÜňťĘšáöšęÂň«×šÄ░ńŞş´╝îň»╣Š»öń║ćňĄÜńެŠÁüŔ«íš«ŚŠíćŠ×´╝îńżőňŽéSpark StreamingŃÇüApache StormŃÇüApache FlinkšşëŃÇéŔ┐Öń║ŤŠíćŠ×ÂňťĘŠÁüŠĘíň×őšÜäň«╣ÚöÖŠÇžŃÇüň╗ÂŔ┐čŃÇüňÉ×ňÉÉÚçĆń╗ąňĆŐšĘ│ň«ÜŠÇžšşëŠľ╣ÚŁóÚâŻňÉ䊝ëšë╣Ŕë▓´╝îÚÇëŠőęÚÇéňÉłšÜäŠíćŠ×Âň»╣ň«×šÄ░ÚźśŠĽł...
Šá╣ŠŹ«ŠĆÉńżŤšÜ䊾çń╗Âń┐íŠü»´╝Ȋľçň░ćŔ»Žš╗ćŔžúŠ×ÉÔÇťSpark StreamingńŞÄKafkašÜ䊼┤ňÉłÔÇŁŔ┐ÖńŞÇńŞ╗Úóś´╝îň╣š╗ôňÉłń╗úšáüšë犫ÁŠÄóŔ«ĘňůÂňťĘň«×ÚÖůňť║ŠÖ»ńŞşšÜäň║öšöĘŃÇéň░Żš«íŠáçšşżńŞşŠĆÉňł░ÔÇťŠĽ░ňşŽň╗║ŠĘíÔÇŁ´╝îńŻćń╗ÄŠáçÚóśňĺîŠĆĆŔ┐░ŠŁąšťő´╝îŔ┐ÖÚâĘňłćňćůň«╣ńŞÄŠĽ░ňşŽň╗║ŠĘ튌áňů│´╝îňŤáŠşĄŠłĹń╗Čň░ć...
ňťĘň«╣ÚöÖŠľ╣ÚŁó´╝îSpark StreamingŠö»ŠîüńŞĄšžŹň«╣ÚöÖŠť║ňłÂ´╝ÜExecutoršź»ÚĽ┐ŠŚÂň«╣ÚöÖňĺîDriveršź»ÚĽ┐ŠŚÂň«╣ÚöÖŃÇéŔ┐Öń║ŤŠť║ňłÂší«ń┐ŁňŹ│ńŻ┐ňç║šÄ░ŠĽůÚÜť´╝îň║öšöĘšÜäŠîüš╗şŔ┐ÉŔíîń╣čńŞŹń╝ÜňĆŚňł░ňŻ▒ňôŹŃÇé Structured StreamingŠś»Spark 2.xńŞşň╝ĽňůąšÜäŠĘíňŁŚ´╝îňůšŤ«šÜ䊜»ŠĆÉńżŤńŞÇ...
ŃÇŐApress.Pro.Spark.Streaming.The.Zen.of.Real-Time.AŃÇőŔ┐ÖŠťČń╣ŽńŞ╗ŔŽüŔüÜšäŽń║ÄApache Spark StreamingŔ┐ÖńŞÇň«×ŠŚÂŠĽ░ŠŹ«ňĄäšÉćŠíćŠ×´╝îŠĚ▒ňůąŠÄóŔ«Ęń║ćňŽéńŻĽňłęšöĘSpark StreamingŠ×äň╗║ÚźśŠĽłŃÇüňƻڣášÜäň«×ŠŚÂŠĽ░ŠŹ«ňĄäšÉćš│╗š╗čŃÇéSpark StreamingŠś»...
ň░ćSpark StreamingńŞÄDruidš╗ôňÉłńŻ┐šöĘ´╝îňĆ»ń╗ąň«×šÄ░ň»╣ŠÁüň╝ĆŠĽ░ŠŹ«Ŕ┐ŤŔíîň«×ŠŚÂňłćŠ×É´╝îň╣ÂÚÇÜŔ┐çDruidŔ┐ŤŔíîň┐źÚÇčšÜ䊼░ŠŹ«ŠčąŔ»óňĺîňĆ»Ŕžćňîľň▒ĽšĄ║ŃÇé #### ń║îŃÇüńżŁŔÁľÚůŹšŻ« ńŞ║ń║ćň«×šÄ░Spark StreamingńŞÄDruidšÜ䊼┤ňÉł´╝îÚŽľňůłÚťÇŔŽüňťĘÚí╣šŤ«ńŞşŠĚ╗ňŐáň┐ůŔŽüšÜäńżŁŔÁľŃÇé...
Spark Úí╣šŤ«ŠÁü org.apache.spark/spark-streaming_2.12/3.0.0/spark-streaming_2.12-3.0.0.jar
5. Spark StreamingšÜäšë╣šé╣´╝ÜSpark StreamingŠś»ňč║ń║ÄSparkŠíćŠ×šÜäńŞÇšžŹŠÁüňĄäšÉćš│╗š╗č´╝îň«âňůüŔ«Şň»╣ŠĽ░ŠŹ«ŠÁüŔ┐ŤŔíîň«×ŠŚÂňĄäšÉć´╝»ŠťČŠľçšáöšęšÜäńŞ╗ŔŽüŠŐÇŠť»ňč║šíÇŃÇé 6. š│╗š╗čŠ×Š×ä´╝ÜŠĆÉňç║ń║ćńŞÇšžŹšö▒ŠöÂÚŤćňÖĘŃÇüŠÂłŠü»š│╗š╗čňĺîŠÁüňĄäšÉćňÖĘš╗䊳ɚÜäňťĘš║┐ń║ĺŔüöšŻĹ...
1.SparkňĆŐňůšöčŠÇüňťłš«Çń╗ő.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞŐ´╝ë--ňč║šíǚĻňóâŠÉşň╗║.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞő´╝ë--Sparkš╝ľŔ»Ĺň«ëŔúů.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞş´╝ë--Hadoopš╝ľŔ»Ĺň«ëŔúů.pdf 3.Sparkš╝ľšĘőŠĘíň×ő´╝łńŞŐ´╝ë--ŠŽéň┐ÁňĆŐSparkShellň«×Šłś....
1.SparkňĆŐňůšöčŠÇüňťłš«Çń╗ő.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞŐ´╝ë--ňč║šíǚĻňóâŠÉşň╗║.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞő´╝ë--Sparkš╝ľŔ»Ĺň«ëŔúů.pdf 2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞş´╝ë--Hadoopš╝ľŔ»Ĺň«ëŔúů.pdf 3.Sparkš╝ľšĘőŠĘíň×ő´╝łńŞŐ´╝ë--ŠŽéň┐ÁňĆŐSparkShellň«×Šłś....
1.Spark StreamingŠĽ┤ňÉłFlumeÚťÇŔŽüšÜäň«ëŔúůňîů. 2. Spark StreamingŠőëňĆľFlumeŠĽ░ŠŹ«šÜäflumeÚůŹšŻ«Šľçń╗Â.conf 3. FlumeňÉĹSpark StreamingŠÄĘŠĽ░ŠŹ«šÜäflumeÚůŹšŻ«Šľçń╗Â.conf
Spark StreamingŠś»ńŞşňŤŻňĄžŠĽ░ŠŹ«ŠŐÇŠť»ÚóćňččńŞşň╣┐Š│ŤńŻ┐šöĘšÜäň«×ŠŚÂŠĽ░ŠŹ«ňĄäšÉćŠíćŠ×´╝îň«âňč║ń║ÄApache SparkšÜäŠáŞň┐âŔ«żŔ«í´╝îŠĆÉńżŤń║ćň»╣Šîüš╗şŠĽ░ŠŹ«ŠÁüšÜäňż«Šë╣ňĄäšÉćŔâŻňŐŤŃÇ銝ČÚí╣šŤ«ň«×ŠłśŠŚĘňťĘňŞ«ňŐęŔ»╗ŔÇůŠĚ▒ňůąšÉćŔžúňĺîň║öšöĘSpark Streaming´╝îÚÇÜŔ┐çň«×ÚÖůŠôŹńŻťŠŁąŠÄîŠĆí...