
在上一篇中介绍了Receiver的整体架构和设计原理,本篇内容主要介绍Receiver在Executor中数据接收和存储过程
一、Receiver启动过程回顾

如图,从ReceiverTracker的start方法开始,调用launchReceivers()方法,给endpoint发送消息,endpoint.send(StartAllReceivers(receivers)),endpoint就是ReceiverTrackerEndpoint,ReceiverTrackerEndpoint调用startReceiver方法在Executor中启动ReceiverSupervisor。详情请阅读链接中的文章http://blog.csdn.net/zhouzx2010
二、Receiver数据接收全过程总览
Receiver数据接收核心成员:
1.ReceiverSupervisor
2.BlockGenerator
3.Receiver
4.ReceiverTracker
5.BlockManager
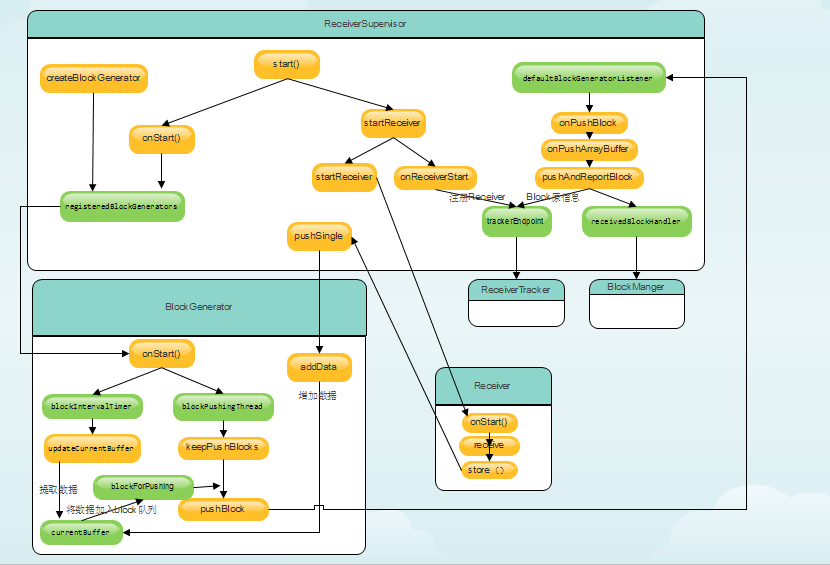
首先ReceiverSupervisor启动,继而启动BlockGenerator和Receiver,其中BlockGenerator首先启动一个定时器定时将接收的数据封装成Block,然后启动一个线程不断将Block数据推送给BlockManager。而Receiver启动后不断接收数据,并不断将接受的数据添加到BlockGenerator中,这样BlockGenerator就不断将Receiver接收的数据推送到BlockManager,整个数据接收过程如下图:

三、Receiver数据接收过程详解
3.1 ReceiverSupervisor 启动
Spark Streaming 在集群启动Receiver的时候会先在Executor中启动ReceiverSupervisor来管理Receiver,ReceiverSupervisor的启动是通过调用他的start方法完成的,源码如下:
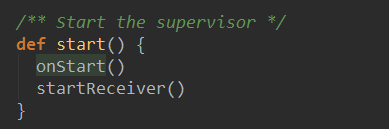
ReceiverSupervisor的start方法首先调用了onStart 方法,该方法启动了BlockGenerator,必须在启动Receiver之前调用该方法来启动BlockGenerator,因为必须BlockGenerator先启动,以保证接收到的数据能够被存储起来。该方法在ReceiverSupervisor的子类ReceiverSupervisorImpl有实现:

可以看到,在onStart方法中启动了所有的已经注册的BlockGenerator,其中registeredBlockGenerators是ReceiverSupervisorImpl的成员变量,在ReceiverSupervisorImpl实例化是被创建:
registeredBlockGenerators中的Generartor是什么时候产生,并加入到registeredBlockGenerators这个队列里的呢?ReceiverSupervisorImpl的createBlockGenerator方法对registeredBlockGenerators进行了元素添加:
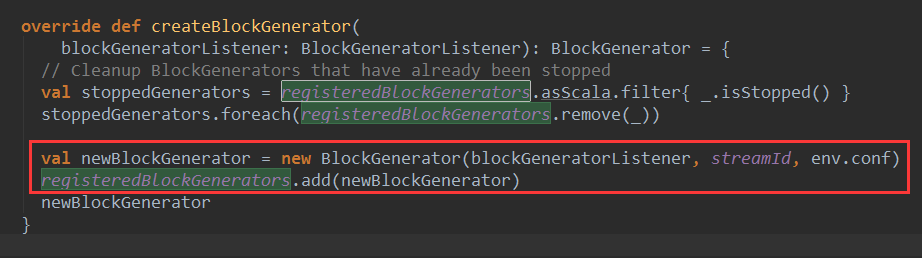
从源码可以看到每一个receiver创建一个BlockGenerator,因为streamId与receiver一一对应。createBlockGenerator首先还将已经停止的BlockGenerator从registeredBlockGenerators队列清除。createBlockGenerator 方法又是在什么时候被调用的呢,答案是在ReceiverSupervisorImpl实例化时候被调用,请看源码:
现在registeredBlockGenerators中有了BlockGenerator,接下来分析BlockGenerator的启动过程
3.2 BlockGenerator 启动

BlockGenerator的start方法启动一个定时器blockIntervalTimer,用来定时生成调用updateCurrentBuffer方法:

时间间隔默认是200毫秒:

下面看一下updateCurrentBuffer的源码:
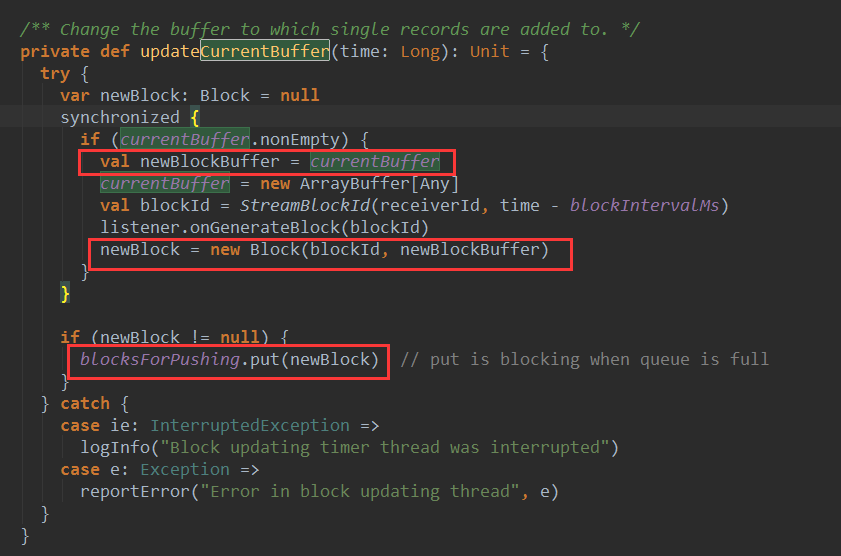
currentBuffer 是一个ArrayBuffer 存储了数据记录,updateCurrentBuffer方法将间隔时间段的数据记录封装成Block,然后将新的Block 放入等待推送的block队列blockForPushing:

回到BlockGenerator的start方法的另一个线程blockPushingThread
可以看到blockPushingThread的run方法调用了keepPushingBlocks方法将blockForPushing队列中的Block推送给BlockManager:

可以看到最多等待10毫秒从blockForPushing中取去Block,然后掉pushBlock方法将block推送给BlockManager,下面看一下pushBlock的源码

这里的listener 是 BlockGeneratorListener 对象,在ReceiverSupervisorImpl中被实例化:

我们关注其中的onPushBlock方法:调用了pushArrayBuffer方法:

这里调用了一个很重要的方法
pushAndReportBlock
我们看一下源码:
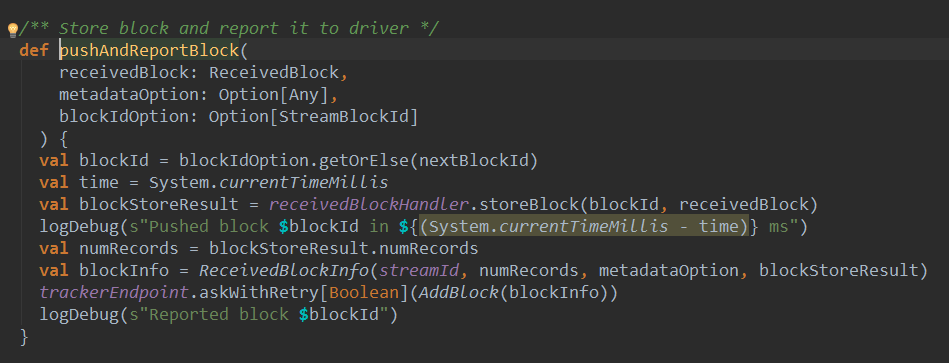
pushAndReportBlock方法用来存储接收的的数据Block并将元数据汇报给ReceiverTracker。
Block存储交给receivedBlockHandler处理,receivedBlockHandlery有两种实现方式:

看一下BlockManagerBasedBlockHandler的storeBlock方法:

BlockManagerBasedBlockHandler的storeBlock方法根据ReceivedBlock的不同类型分别处理,最终都是交给了BlockManger管理。
至此BlockGenerator 分析完毕,下面分析 Receiver 的启动过程
3.3 Receiver 启动
首先回到ReceiverSupervisorImpl的startReceiver方法:
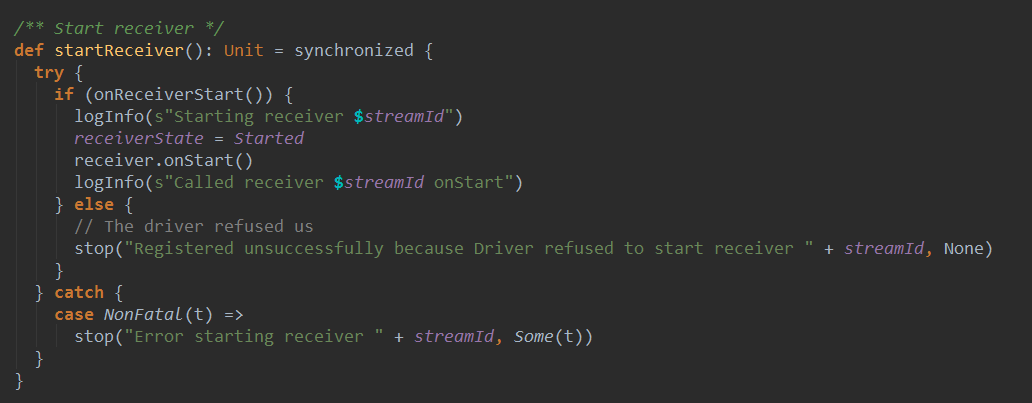
首先调用了onReceiverStart方法,将Receiver注册给ReceiverTracker,重点看代码rever.onStart(),调用了receiver的onStart方法,此处我们以SocketReceiver为例进行讲解:
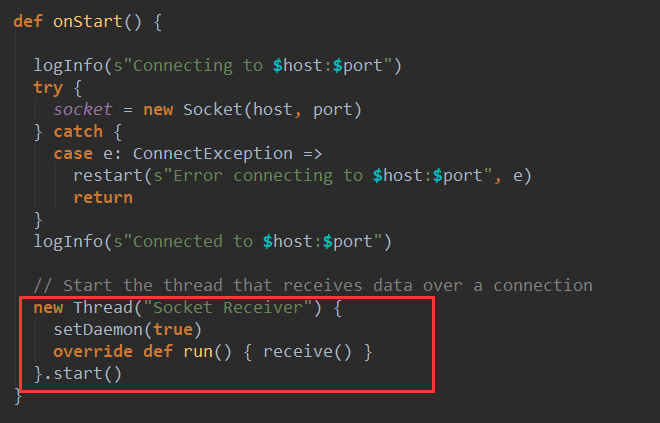
可以看到SocketReceiver的onStart()方法先给创建了一个Socket对象赋值给了socket,然后启动了一个后台进行“Socket Receiver” ,在后台进程的run方法中调用了receive()方法进行数据接收:
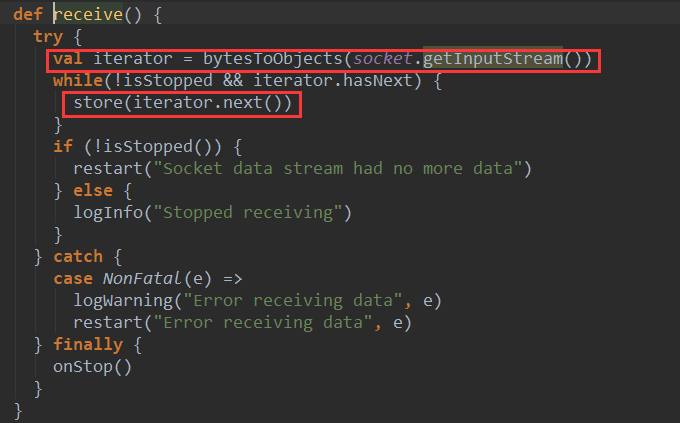
SocketReceiver的receive()方法不断从socket接收数据,然后调用store方法进行存储。
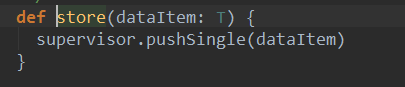
此处再次回到ReceiverSupervisor,调用了其中的pushSingle函数:

最终调用了BlockGenerator的addData方法:
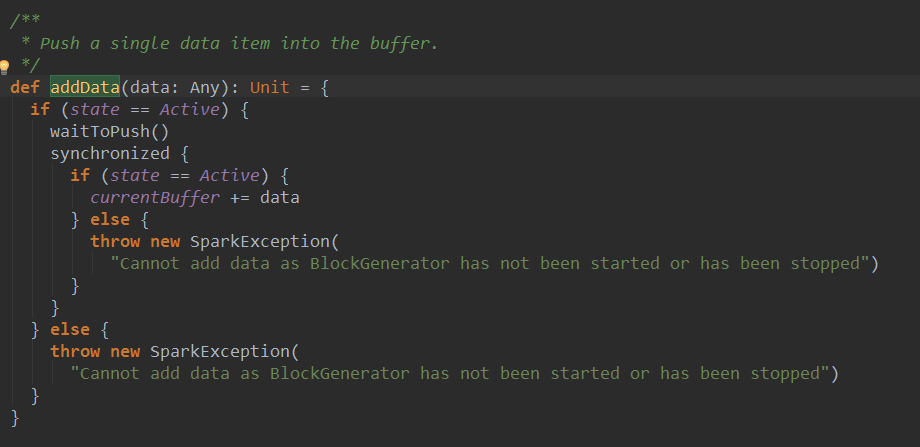
可以看到BlockGenerator的addData方法将数据添加到currentBuffer中,然后blockIntervalTimer会每个200毫秒从currentBuffer取出数据封装成Block,并将Block添加到blockForPushing队列,blockPushingThread会将blockForPushing队列中的block推送给BlockManager。至此Receiver运行流程分析完毕。
四、总结:receiver数据接收流程图
总体过程:ReceiverSupervisor启动时,启动了BlockGenerator和Receiver,其中BlockGenerator首先启动一个定时器定时将接收的数据封装成Block,然后启动一个线程不断将Block数据推送给BlockManager。而Receiver启动后不断接收数据,不断将接受的数据添加到BlockGenerator的currentBuffer中,BlockGenerator不断从currentBuffer取数据,这样整个数据接收过程不断循环。



相关推荐
7.SparkStreaming(上)--SparkStreaming原理介绍.pdf 7.SparkStreaming(下)--SparkStreaming实战.pdf 8.SparkMLlib(上)--机器学习及SparkMLlib简介.pdf 8.SparkMLlib(下)--SparkMLlib实战.pdf 9.SparkGraphX...
《Apress.Pro.Spark.Streaming.The.Zen.of.Real-Time.Analytics.Using.Apache.Spark》这本书专注于探讨如何利用Apache Spark进行实时数据分析,是Spark流处理技术的深入解析。Apache Spark作为一个快速、通用且可...
《Spark源码分析》这本书是针对那些希望深入了解大数据处理框架Spark以及与其紧密相关的Hadoop技术的专业人士所编写的。Spark作为一个快速、通用且可扩展的数据处理引擎,已经在大数据领域占据了重要地位,而深入...
《深入理解Spark:核心思想及源码分析》这本书旨在帮助读者深入掌握Apache Spark这一大数据处理框架的核心原理与实现细节。Spark作为一个快速、通用且可扩展的数据处理系统,已经在大数据领域得到了广泛应用。它提供...
Spark Streaming的计算流程涉及从数据源接收数据,转换成RDDs(弹性分布式数据集),然后对这些数据执行转换操作,并最终进行输出处理。在容错性方面,该平台利用了RDD的不变性和容错计算机制,确保了即使在发生故障...
Spark-2.4.5是该框架的一个稳定版本,提供了丰富的数据处理功能,包括批处理、交互式查询(通过Spark SQL)、实时流处理(通过Spark Streaming)以及机器学习(通过MLlib库)和图计算(通过GraphX)。这个版本的源码...
Receiver在Spark Streaming中是一个重要的组件,它负责从数据源接收数据。例如,使用Kafka作为输入源时,Receiver将从Kafka主题中读取数据并将其存储在Executor内存中。 在容错方面,Spark Streaming支持两种容错...
Spark源码的阅读和理解是一个逐步深入的过程,涉及到分布式系统、并发编程、内存管理和优化等多个领域。理解源码可以帮助我们更好地调试、优化和扩展Spark应用程序,提升整体性能和效率。在进行Spark二次开发时,...
2. **Spark Streaming接收数据**: - 设置Spark Streaming应用程序来接收来自消息队列的数据流。 - 使用DStream API进行数据处理。 3. **数据转换**: - 将接收到的数据转换为适合写入Druid的格式。 - 这可能...
《深入理解Spark:核心思想与源码分析》是一本针对大数据处理框架Spark的深度解析教材。这本书涵盖了Spark的全面知识,旨在帮助读者深入理解Spark的核心原理,并通过源码分析提升技术水平。以下是根据书名和描述提炼...
它支持从多种源接收数据,例如Kafka、Flume、TCP套接字等,并能够将数据流划分为一系列小批次,然后使用Spark引擎进行处理,从而实现高吞吐量和容错性。 3. 模型化方式:文章提出了通过模型化的方式来处理实时数据...
Spark 项目流 org.apache.spark/spark-streaming_2.12/3.0.0/spark-streaming_2.12-3.0.0.jar
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaUtils, OffsetRange} import org.apache.spark.streaming.{Duration, StreamingContext} object KafkaDirectDemo1 { def main(args: Array...
6.spark streaming对接kafka的数据进行消费 数据采集详情:项目其他\数据采集.docx 二.数据清洗:见项目 使用spark streaming完成数据清洗操作 三.数据分析:见项目 功能一: 统计到今天为止视频的访问量 ...
《Apress.Pro.Spark.Streaming.The.Zen.of.Real-Time.A》这本书主要聚焦于Apache Spark Streaming这一实时数据处理框架,深入探讨了如何利用Spark Streaming构建高效、可靠的实时数据处理系统。Spark Streaming是...
1.Spark Streaming整合Flume需要的安装包. 2. Spark Streaming拉取Flume数据的flume配置文件.conf 3. Flume向Spark Streaming推数据的flume配置文件.conf
7.SparkStreaming(上)--SparkStreaming原理介绍.pdf 7.SparkStreaming(下)--SparkStreaming实战.pdf 8.SparkMLlib(上)--机器学习及SparkMLlib简介.pdf 8.SparkMLlib(下)--SparkMLlib实战.pdf 9.SparkGraphX...
7.SparkStreaming(上)--SparkStreaming原理介绍.pdf 7.SparkStreaming(下)--SparkStreaming实战.pdf 8.SparkMLlib(上)--机器学习及SparkMLlib简介.pdf 8.SparkMLlib(下)--SparkMLlib实战.pdf 9.SparkGraphX...
"基于Spark Streaming的实时交通数据处理平台" 本文旨在构建一个实时交通数据处理平台,基于Spark Streaming和Apache Kafka的组合来处理通过双基基站采集的数据。该平台能够实时处理大规模高并发的数据流,具有高...