
 
Spark streaming šĘőň║ĆšÜäŔ┐ÉŔíîŔ┐çšĘőŠś»ň░ćDStreamšÜäŠôŹńŻťŔŻČňłÉRDDšÜäŠôŹńŻť´╝îSpark Streaming ňĺî Spark Core šÜäňů│š│╗ňŽéńŞőňŤż´╝łňŤżšë犣ąŔç¬sparkň«śšŻĹ´╝ë

Spark Streaming ń╝ÜŠîëšůžšĘőň║ĆŔ«żň«ÜšÜ䊌ÂÚŚ┤ÚŚ┤ÚÜöńŞŹŠľşňŐĘŠÇüšö芳ÉJobŠŁąňĄäšÉćŔżôňůąŠĽ░ŠŹ«´╝îŔ┐ÖÚçîšÜäJobšö芳Ɋś»Šîçň░ćSpark Streaming šÜäšĘőň║Ćš┐╗Ŕ»ĹŠłÉSparkňćůŠáŞšÜäRDDŠôŹńŻť´╝îš┐╗Ŕ»ĹšÜäŔ┐çšĘőň╣ÂńŞŹń╝ÜŔžŽňĆĹJobšÜäŔ┐ÉŔíî´╝îSpark Streaming ń╝Üň░ćš┐╗Ŕ»ĹšÜäňĄäšÉćÚÇ╗ŔżĹň░üŔúůňťĘJobň»╣Ŕ▒íńŞş´╝ÇňÉÄń╝Üň░ćJobŠĆÉń║Ąňł░ÚŤćšżĄńŞŐŔ┐ÉŔíîŃÇéŔ┐Öň░▒Šś»Spark Streaming Ŕ┐ÉŔíîšÜäňč║ŠťČŔ┐çšĘőŃÇéńŞőÚŁóŔ»Žš╗ćń╗őš╗ŹJobňŐĘŠÇüšö芳ÉňĺîŠĆÉń║ĄŔ┐çšĘőŃÇé
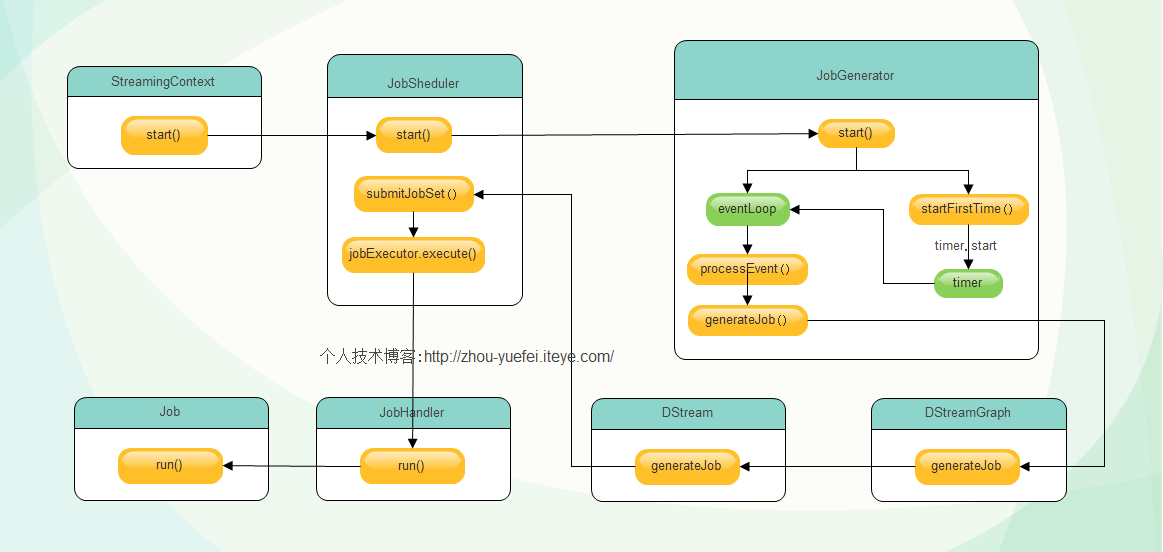
 
ÚŽľňůł,ňŻôSparkStreamingšÜästartŠľ╣Š│ĽŔ░âšöĘňÉÄ,ŠĽ┤ńެSpark Streaming šĘőň║Ćň╝ÇňžőŔ┐ÉŔíî,ŠîëšůžŠîçň«ÜšÜ䊌ÂÚŚ┤ÚŚ┤ÚÜöšö芳ÉJobň╣ŠĆÉń║Ąš╗ÖÚŤćšżĄŔ┐ÉŔíî,ňťĘšö芳ÉJobšÜäňĚąšĘőńŞşńŞ╗ŔŽüŠáŞň┐âň»╣Ŕ▒튝ë
    1.JobScheduler  
    2.JobGenerator
    3.DStreamGraph
    4.DStream
ňůÂńŞş,┬áJobScheduler┬áŔ┤čŔ┤úňÉ»ňŐĘJobGeneratoršö芳ÉJob,ň╣ŠĆÉń║Ąšö芳ɚÜäJobňł░ÚŤćšżĄŔ┐ÉŔíî,Ŕ┐ÖÚçîšÜäJobńŞŹŠś»ňťĘspark core ńŞşŠĆÉňł░šÜäjob,ň«âňƬŠś»ńŻťńŞÜŔ┐ÉŔíîšÜäń╗úšáüŠĘ튣┐,Šś»ÚÇ╗ŔżĹš║žňłźšÜä,ňĆ»ń╗ąš▒╗Š»öjavaš║┐šĘőńŞşšÜäRunnableŠÄąňĆúň«×šÄ░,ńŞŹŠś»šťčŠşúŔ┐ÉŔíîšÜäńŻťńŞÜ,┬áň«âň░üŔúůń║ćšö▒DStreamŔŻČňîľŔÇąšÜäRDDŠôŹńŻť.JobGeneratorŔ┤čŔ┤úň«ÜŠŚÂŔ░âšöĘDStreamingGraphšÜägenerateJobŠľ╣Š│Ľšö芳ÉJobňĺůšÉćDstreamšÜäňů⊼░ŠŹ«,┬áDStreamGraphŠîüŠťëŠ×䊳ÉDStreamňŤżšÜäŠëÇŠťëDStreamň»╣Ŕ▒í,ň╣ÂŔ░âšöĘDStreamšÜägenerateJobŠľ╣Š│Ľšö芳ÉňůĚńŻôJobň»╣Ŕ▒í.DStreamšö芳ɊťÇš╗łšÜäJobń║Ąš╗ÖJobScheduler┬áŔ░âň║ŽŠëžŔíîŃÇ銼┤ńŻôŔ┐çšĘőňŽéńŞőňŤżŠëÇšĄ║´╝Ü
 
 
ńŞőÚŁóš╗ôňÉłŠ║ÉšáüňłćŠ×ÉŠ»ĆńŞÇŠşąŔ┐çšĘő (Š║ÉšáüńŞşÚ╗äŔë▓ŔâîŠÖ»ÚâĘňłćńŞ║ŠáŞň┐âÚÇ╗ŔżĹń╗úšáü,ńżőňŽé :┬áscheduler.start()) :
ÚŽľňůł´╝îStreamingContextŔÁĚňŐĘŠŚÂŔ░âšöĘstartŠľ╣Š│Ľ
try{validate()// Start the streaming scheduler in a new thread, so that thread local properties// like call sites and job groups can be reset without affecting those of the// current thread.ThreadUtils.runInNewThread("streaming-start"){sparkContext.setCallSite(startSite.get)sparkContext.clearJobGroup()sparkContext.setLocalProperty(SparkContext.SPARK_JOB_INTERRUPT_ON_CANCEL,"false")savedProperties.set(SerializationUtils.clone(sparkContext.localProperties.get()).asInstanceOf[Properties])scheduler.start()}state =StreamingContextState.ACTIVE}catch{caseNonFatal(e)=>logError("Error starting the context, marking it as stopped", e)scheduler.stop(false)state =StreamingContextState.STOPPEDthrow e}
 
ňůÂńŞşŔ░âšöĘń║ćscheduleršÜästartŠľ╣Š│Ľ,ŠşĄňĄäšÜäscheduler ň░▒Šś»┬áorg.apache.spark.streaming.scheduler.JobScheduler┬áň»╣Ŕ▒í,
StreamingContextŠîüŠťëorg.apache.spark.streaming.scheduler.JobSchedulerň»╣Ŕ▒íšÜäň╝ĽšöĘŃÇé
ńŞőÚŁóšťőńŞÇńŞőJobScheduleršÜästartŠľ╣Š│Ľ:
 
eventLoop =newEventLoop[JobSchedulerEvent]("JobScheduler"){override protected def onReceive(event:JobSchedulerEvent):Unit= processEvent(event)override protected def onError(e:Throwable):Unit= reportError("Error in job scheduler", e)}eventLoop.start()// attach rate controllers of input streams to receive batch completion updatesfor{inputDStream <- ssc.graph.getInputStreamsrateController <- inputDStream.rateController} ssc.addStreamingListener(rateController)listenerBus.start()receiverTracker =newReceiverTracker(ssc)inputInfoTracker =newInputInfoTracker(ssc)executorAllocationManager =ExecutorAllocationManager.createIfEnabled(ssc.sparkContext,receiverTracker,ssc.conf,ssc.graph.batchDuration.milliseconds,clock)executorAllocationManager.foreach(ssc.addStreamingListener)receiverTracker.start()jobGenerator.start()executorAllocationManager.foreach(_.start())logInfo("Started JobScheduler")
 
ňĆ»ń╗ąšťőňł░JobSchedulerŔ░âšöĘń║ćjobGeneratoršÜästartŠľ╣Š│ĽňĺîeventLoopšÜästartŠľ╣Š│Ľ,eventLoopšöĘŠŁąŠÄąŠöÂJobSchedulerEventŠÂłŠü»,ň╣Âń║Ąš╗ÖprocessEventň篊Ľ░Ŕ┐ŤŔíîňĄäšÉć
ń╗úšáüňŽéńŞő:
private def processEvent(event:JobSchedulerEvent){try{event match {caseJobStarted(job, startTime)=> handleJobStart(job, startTime)caseJobCompleted(job, completedTime)=> handleJobCompletion(job, completedTime)caseErrorReported(m, e)=> handleError(m, e)}}catch{case e:Throwable=>reportError("Error in job scheduler", e)}}
 
┬áňĆ»ń╗ąšťőňł░JobSchedulerńŞşšÜäeventLoopňƬňĄäšÉćJobStarted,JobCompletedňĺîErrorReported ńŞëš▒╗ŠÂłŠü»,Ŕ┐ÖńŞëš▒╗ŠÂłŠü»šÜäňĄäšÉćńŞŹŠś»JobňŐĘŠÇüšö芳ɚÜäŠáŞň┐âÚÇ╗ŔżĹń╗úšáüňůłšĽąŔ┐ç,(Š│ĘŠäĆ:ňÉÄÚŁóJobGeneratorńŞşń╣芝ëńެeventLoopńŞŹŔŽüňĺîŔ┐ÖÚçîšÜäeventLoopŠĚĚŠĚćŃÇé)
JobGeneratoršÜästartŠľ╣Š│ĽÚŽľňůłnewń║ćńŞÇńެEventLoopň»╣Ŕ▒íeventLoop,ň╣ÂňĄŹňćÖonReceive(),ň░ćŠöÂňł░šÜäJobGeneratorEvent ŠÂłŠü»ń║Ąš╗Ö processEvent Šľ╣Š│ĽňĄäšÉć.Š║ÉšáüňŽéńŞő:
 
/** Start generation of jobs */ def start(): Unit = synchronized { if (eventLoop != null) return // generator has already been started // Call checkpointWriter here to initialize it before eventLoop uses it to avoid a deadlock. // See SPARK-10125 checkpointWriter eventLoop = new EventLoop[JobGeneratorEvent]("JobGenerator") { override protected def onReceive(event: JobGeneratorEvent): Unit = processEvent(event) override protected def onError(e: Throwable): Unit = { jobScheduler.reportError("Error in job generator", e) } } eventLoop.start() if (ssc.isCheckpointPresent) { restart() } else { startFirstTime() } }
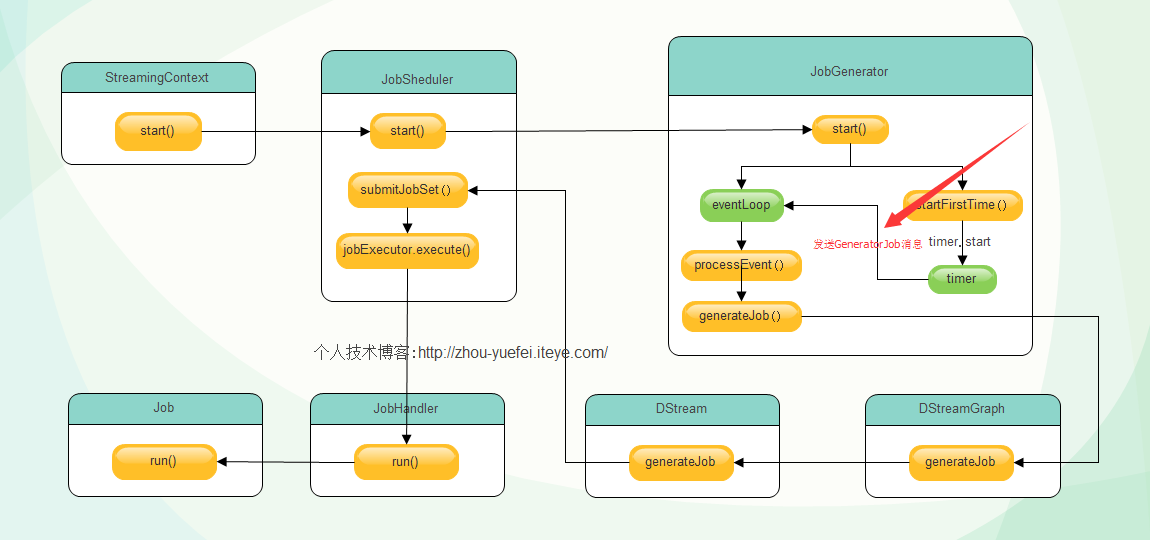
JobGeneratorňłŤň╗║ń║ćeventLoopň»╣Ŕ▒íń╣őňÉÄŔ░âšöĘŔ»ąň»╣Ŕ▒íšÜästartŠľ╣Š│Ľ,ňÉ»ňŐĘšŤĹňÉČŔ┐ŤšĘő,ňçćňĄçŠÄąŠöÂJobGeneratorEventš▒╗ň×őŠÂłŠü»ń║Ąš╗ÖprocessEventň篊Ľ░ňĄäšÉć,šäÂňÉÄŔ░âšöĘń║ćstartFirstTimeŠľ╣Š│Ľ,Ŕ»ąŠľ╣Š│ĽňÉ»ňŐĘDStreamGraphňĺîň«ÜŠŚÂňÖĘ,ň«ÜŠŚÂňÖĘňÉ»ňŐĘňÉÄŠá╣ŠŹ«šĘőň║ĆŔ«żň«ÜšÜ䊌ÂÚŚ┤ÚŚ┤ÚÜöš╗ÖeventLoopň»╣Ŕ▒íňĆĹÚÇüGenerateJobsŠÂłŠü»,ňŽéńŞőňŤż:
 
 
 
eventLoopň»╣Ŕ▒íŠöÂňł░┬áGenerateJobs┬áŠÂłŠü»ń║ĄńެprocessEventŠľ╣Š│ĽňĄäšÉć,processEventŠöÂňł░Ŕ»ąŠÂłŠü»,Ŕ░âšöĘgenerateJobsŠľ╣Š│ĽňĄäšÉć,Š║ÉšáüňŽéńŞő:
 
/** Generate jobs and perform checkpoint for the given `time`. */private def generateJobs(time:Time){// Checkpoint all RDDs marked for checkpointing to ensure their lineages are// truncated periodically. Otherwise, we may run into stack overflows (SPARK-6847).ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS,"true")Try{jobScheduler.receiverTracker.allocateBlocksToBatch(time)// allocate received blocks to batchgraph.generateJobs(time)// generate jobs using allocated block} match {caseSuccess(jobs)=>val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos))caseFailure(e)=>jobScheduler.reportError("Error generating jobs for time "+ time, e)}eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater =false))}
 
JobGeneratorńŞşšÜägenerateJobsŠľ╣Š│ĽńŞ╗ŔŽüňů│Š│ĘńŞĄŔíîń╗úšáü,ÚŽľňůłŔ░âšöĘgraphšÜägenerateJobsŠľ╣Š│Ľ,š╗ÖŠľ╣Š│ĽŔ┐öňŤ×Success(jobs) ŠłľŔÇů Failure(e),ňůÂńŞşšÜäjobsň░▒Šś»Ŕ»ąŠľ╣Š│ĽŔ┐öňŤ×šÜäJobň»╣Ŕ▒íÚŤćňÉł,ňŽéŠ×ťJobňłŤň╗║ŠłÉňŐč,ňćŹŔ░âšöĘJobScheduleršÜäsubmitJobSetŠľ╣Š│Ľň░ćjobŠĆÉń║Ąš╗ÖÚŤćšżĄŠëžŔíîŃÇé
ÚŽľňůłňłćŠ×ÉJobň»╣Ŕ▒íšÜäń║žšöč´╝îDStreamGraph šÜästartŠľ╣Š│ĽŠ║Éšáü´╝Ü
def generateJobs(time:Time):Seq[Job]={logDebug("Generating jobs for time "+ time)val jobs =this.synchronized{outputStreams.flatMap { outputStream =>val jobOption = outputStream.generateJob(time)jobOption.foreach(_.setCallSite(outputStream.creationSite))jobOption}}logDebug("Generated "+ jobs.length +" jobs for time "+ time)jobs}
 
DStreamGraph šÜästartŠľ╣Š│ĽŠ║ÉšáüŔ░âšöĘń║ćoutputStreamň»╣Ŕ▒íšÜägenerateJobŠľ╣Š│Ľ´╝îForeachDStreamÚçŹňćÖń║ćŔ»ąŠľ╣Š│Ľ´╝Ü
 
ForeachDStreamšÜägenerateJob ň░ćšöĘŠłĚš╝ľňćÖšÜäDStreamňĄäšÉćň篊Ľ░ň░üŔúůňťĘjobFuncńŞş´╝îň╣Âň░ćňůÂń╝áňůąJobň»╣Ŕ▒í´╝îŔç│ŠşĄJobšÜäšö芳ÉŃÇé
ŠÄąńŞőŠŁąňłćŠ×ÉJobŠĆÉń║ĄŔ┐çšĘő´╝îJobSchedulerŔ┤čŔ┤úJobšÜäŠĆÉń║Ą´╝îŠáŞň┐âń╗úšáüňťĘsubmitJobSetŠľ╣Š│ĽńŞş´╝Ü
 
def submitJobSet(jobSet:JobSet){if(jobSet.jobs.isEmpty){logInfo("No jobs added for time "+ jobSet.time)}else{listenerBus.post(StreamingListenerBatchSubmitted(jobSet.toBatchInfo))jobSets.put(jobSet.time, jobSet)jobSet.jobs.foreach(job => jobExecutor.execute(newJobHandler(job)))logInfo("Added jobs for time "+ jobSet.time)}}
 
ňůÂńŞşjobExecutorň»╣Ŕ▒튜»ńŞÇńެš║┐šĘőŠ▒á´╝îJobHandlerň«×šÄ░ń║ćRunnableŠÄąňĆú´╝îňťĘJobHandler šÜärunŠľ╣Š│ĽńŞşń╝ÜŔ░âšöĘń╝áňůąšÜäjobň»╣Ŕ▒íšÜärunŠľ╣Š│ĽŃÇé
 
šľĹÚŚ«´╝ÜJobšÜärunŠľ╣Š│ĽŠëžŔí»ňŽéńŻĽŔžŽňĆĹRDDšÜäActionŠôŹńŻťń╗ÄŔÇîňç║ňĆĹjobšÜ䚝芺úŔ┐ÉŔíîšÜäňĹó´╝芳Ĺń╗ČńŞőŠČíňćŹňůĚńŻôňłćŠ×É´╝îŔ»ĚÚÜĆŠŚÂňů│Š│ĘňŹÜň«óŠŤ┤Šľ░!
 



šŤŞňů│ŠÄĘŔŹÉ
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
1.SparkňĆŐňůšöčŠÇüňťłš«Çń╗ő.pdf2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞŐ´╝ë--ňč║šíǚĻňóâŠÉşň╗║.pdf2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞő´╝ë--Sparkš╝ľŔ»Ĺň«ëŔúů.pdf2.Sparkš╝ľŔ»ĹńŞÄÚâĘšŻ▓´╝łńŞş´╝ë--Hadoopš╝ľŔ»Ĺň«ëŔúů.pdf3.Sparkš╝ľšĘőŠĘíň×ő´╝łńŞŐ´╝ë--ŠŽéň┐ÁňĆŐSparkShellň«×Šłś.pdf3....
ŃÇŐSparkŠŐÇŠť»ňćůň╣ĽŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŔ┐ÖŠťČń╣ŽŠĚ▒ňůąŠÄóŔ«Ęń║ćApache SparkŔ┐ÖńŞÇňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×šÜäŠáŞň┐âŠ×Š×äňĺîň«×šÄ░Šť║ňłÂ´╝ĘňťĘňŞ«ňŐęŔ»╗ŔÇůňůĘÚŁóšÉćŔžúSparkšÜäňĚąńŻťňÄčšÉć´╝îň╣ÂŔâŻňĄčŠťëŠĽłňť░ňłęšöĘňůÂŔ┐ŤŔíîňĄžŠĽ░ŠŹ«ňĄäšÉćŃÇé...
ŃÇŐSparkŠŐÇŠť»ňćůň╣ĽŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŔ┐ÖŠťČń╣ŽŠĚ▒ňůąŠÄóŔ«Ęń║ćApache SparkŔ┐ÖńŞÇňłćňŞâň╝ĆŔ«íš«ŚŠíćŠ×šÜäŠáŞň┐âŠ×Š×äňĺîň«×šÄ░Šť║ňłÂ´╝îň»╣ń║ÄšÉćŔžúSparkšÜäňĚąńŻťňÄčšÉćňĆŐňůÂňťĘňĄžŠĽ░ŠŹ«ňĄäšÉćńŞşšÜäň║öšöĘňůĚŠťëŠ×üÚźśšÜäń╗ĚňÇ╝ŃÇéń╗ąńŞőŠś»ň»╣ňůÂńŞşńŞ╗ŔŽü...
ŃÇŐSparkŠŐÇŠť»ňćůň╣Ľ´╝ÜŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŠś»ńŞÇŠťČńŞôŠ│Ęń║ÄŠĚ▒ňůąŠÄóšęÂApache SparkŠáŞň┐âŠŐÇŠť»šÜäń╣Žš▒ŹŃÇéŔ┐ÖŠťČń╣ŽŠŚĘňťĘňŞ«ňŐęŔ»╗ŔÇůšÉćŔžúSparkšÜäňćůÚâĘňĚąńŻťŠť║ňłÂ´╝îňîůŠőČňůŠ×Š×äŔ«żŔ«íŃÇüňłćňŞâň╝ĆŔ«íš«ŚŠĘíň×őń╗ąňĆŐŠť║ňÖĘňşŽń╣áň║ôMLlibšÜäň«×šÄ░...
ŃÇŐSparkŠŐÇŠť»ňćůň╣Ľ´╝ÜŠĚ▒ňůąŔžúŠ×ÉSparkňćůŠáފ׊×äŔ«żŔ«íńŞÄň«×šÄ░ňÄčšÉćŃÇőŠś»ńŞÇŠťČńŞôŠ│Ęń║ÄSparkŠŐÇŠť»ŠĚ▒ň║Žň뾊×ÉšÜäń╣Žš▒Ź´╝ĘňťĘňŞ«ňŐęŔ»╗ŔÇůšÉćŔžúSparkšÜäŠáŞň┐âŠ×Š×äŃÇüŔ«żŔ«íšÉćň┐Áń╗ąňĆŐňůÂň«×šÄ░Šť║ňłÂŃÇéŔ┐ÖŠťČń╣ŽÚźśŠŞůň«îŠĽ┤´╝îňîůňÉźń║ćň«îŠĽ┤šÜäń╣Žšşż´╝╣ńż┐Ŕ»╗ŔÇůŠčąÚśůňĺîňşŽń╣á...
ŃÇŐApress.Pro.Spark.Streaming.The.Zen.of.Real-Time.Analytics.Using.Apache.SparkŃÇőŔ┐ÖŠťČń╣ŽńŞôŠ│Ęń║ÄŠÄóŔ«ĘňŽéńŻĽňłęšöĘApache SparkŔ┐ŤŔíîň«×ŠŚÂŠĽ░ŠŹ«ňłćŠ×É´╝»SparkŠÁüňĄäšÉćŠŐÇŠť»šÜäŠĚ▒ňůąŔžúŠ×ÉŃÇéApache SparkńŻťńŞ║ńŞÇńެň┐źÚÇčŃÇüÚÇÜšöĘńŞöňĆ»...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
ŃÇŐSparkňĄžŠĽ░ŠŹ«ňĄäšÉć´╝ÜŠŐÇŠť»ŃÇüň║öšöĘńŞÄŠÇžŔâŻń╝śňîľŃÇőŠś»ňĄžŠĽ░ŠŹ«ŠŐÇŠť»ńŞŤń╣ŽńŞşšÜäńŞÇŠťČ´╝îňůĘÚŁóŔžúŠ×Éń║ćApache SparkŔ┐ÖńŞÇŠáŞň┐âšÜäňĄžŠĽ░ŠŹ«ňĄäšÉćŠíćŠ×ÂŃÇéSparkń╗ąňůÂÚźśŠĽłŃÇüšüÁŠ┤╗ňĺôšöĘŠÇžňťĘňĄžŠĽ░ŠŹ«ÚóćňččňŹáŠŹ«ń║ćÚçŹŔŽüňť░ńŻŹ´╝îň«âńŞŹń╗ůŠö»ŠîüŠë╣ňĄäšÉć´╝îŔ┐śŠö»Šîüň«×ŠŚÂŠÁü...
2.šÉćŔžúSpark StreamingšÜäňĚąńŻťňÄčšÉćŃÇé 3.ňşŽń╝ÜńŻ┐šöĘSpark StreamingňĄäšÉćŠÁüň╝ĆŠĽ░ŠŹ«ŃÇé ń║îŃÇüň«×Ú¬îšÄ»ňóâ Windows 10 VMware Workstation ProŔÖÜŠő芝║ HadoopšÄ»ňóâ Jdk1.8 ńŞëŃÇüň«×Ú¬îňćůň«╣ ´╝łńŞÇ´╝ëSpark StreamingňĄäšÉćňąŚŠÄąňşŚŠÁü 1´╝Üš╝ľňćÖ...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
Apache SparkŠś»ńŞÇńެň╝ÇŠ║ÉšÜäňłćňŞâň╝ĆňĄžŠĽ░ŠŹ«ňĄäšÉćŠíćŠ×´╝îň«âŔâŻňĄčňĄäšÉćňĄžŔžäŠĘ튼░ŠŹ«...6. **ňĄÜŔ»şŔĘÇŠö»Šîü**´╝ÜSparkŠö»ŠîüScalaŃÇüJavaŃÇüPythonňĺîRšşëňĄÜšžŹš╝ľšĘőŔ»şŔĘÇŃÇé 7. **ňĄÜŠĽ░ŠŹ«Š║ÉŠö»Šîü**´╝ÜSparkňĆ»ń╗ąŔ»╗ňĆľHDFSŃÇüS3ŃÇü CassandraŃÇüHBasešşëňĄÜšžŹ
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
ńżőňŽé´╝îňŤż2-4ň▒ĽšĄ║ń║ćSpark StreamingńŞÄStormňťĘňÉ×ňÉÉÚçĆńŞŐšÜ䊻öŔżâš╗ôŠ×ť´╝îŔÇîňŤż6-3ŃÇüňŤż6-4ňĺîňŤż6-5ňłÖňłćňłźň▒ĽšĄ║ń║ćStormŃÇüSpark StreamingňĺîSamzašÜäŠ×Š×äňŤżŃÇéÚÇÜŔ┐çŔ┐Öń║Ťň»╣Š»ö´╝îŠŐÇŠť»ń║║ňĹśňĆ»ń╗ąŠŤ┤ňąŻňť░ń║ćŔžúňÉäŔ笚ÜäŠŐÇŠť»ń╝śňŐ┐ňĺîÚÇéšöĘňť║ŠÖ»ŃÇé 7. ...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...
7.SparkStreaming´╝łńŞŐ´╝ë--SparkStreamingňÄčšÉćń╗őš╗Ź.pdf 7.SparkStreaming´╝łńŞő´╝ë--SparkStreamingň«×Šłś.pdf 8.SparkMLlib´╝łńŞŐ´╝ë--Šť║ňÖĘňşŽń╣áňĆŐSparkMLlibš«Çń╗ő.pdf 8.SparkMLlib´╝łńŞő´╝ë--SparkMLlibň«×Šłś.pdf 9.SparkGraphX...