
Task Attempt
Table of contents:
- Finite State Machine
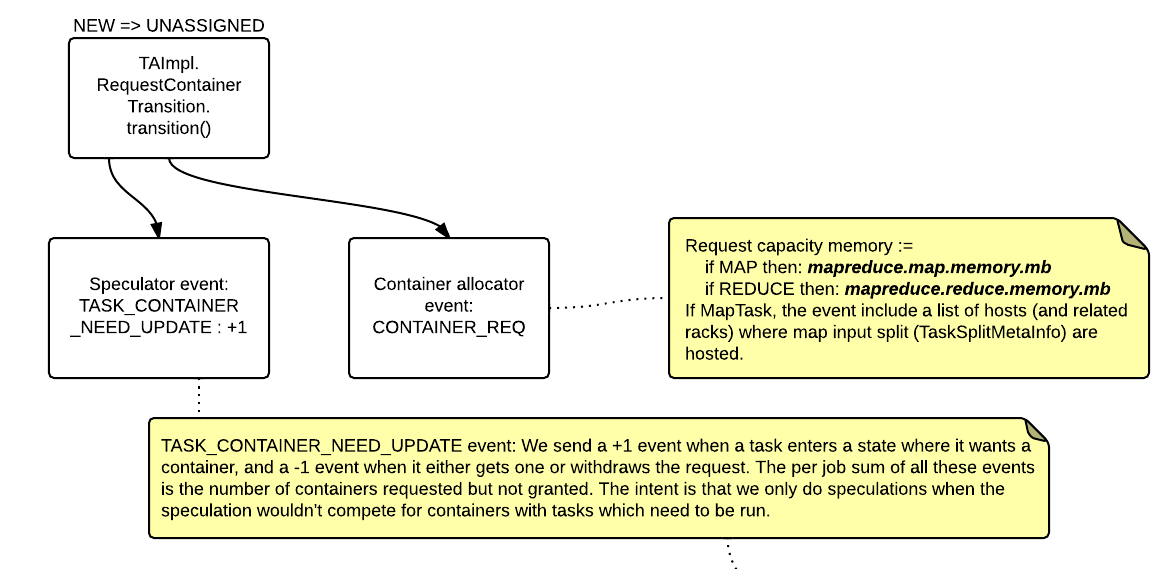
- NEW => UNASSIGNED [TA_SCHEDULE]
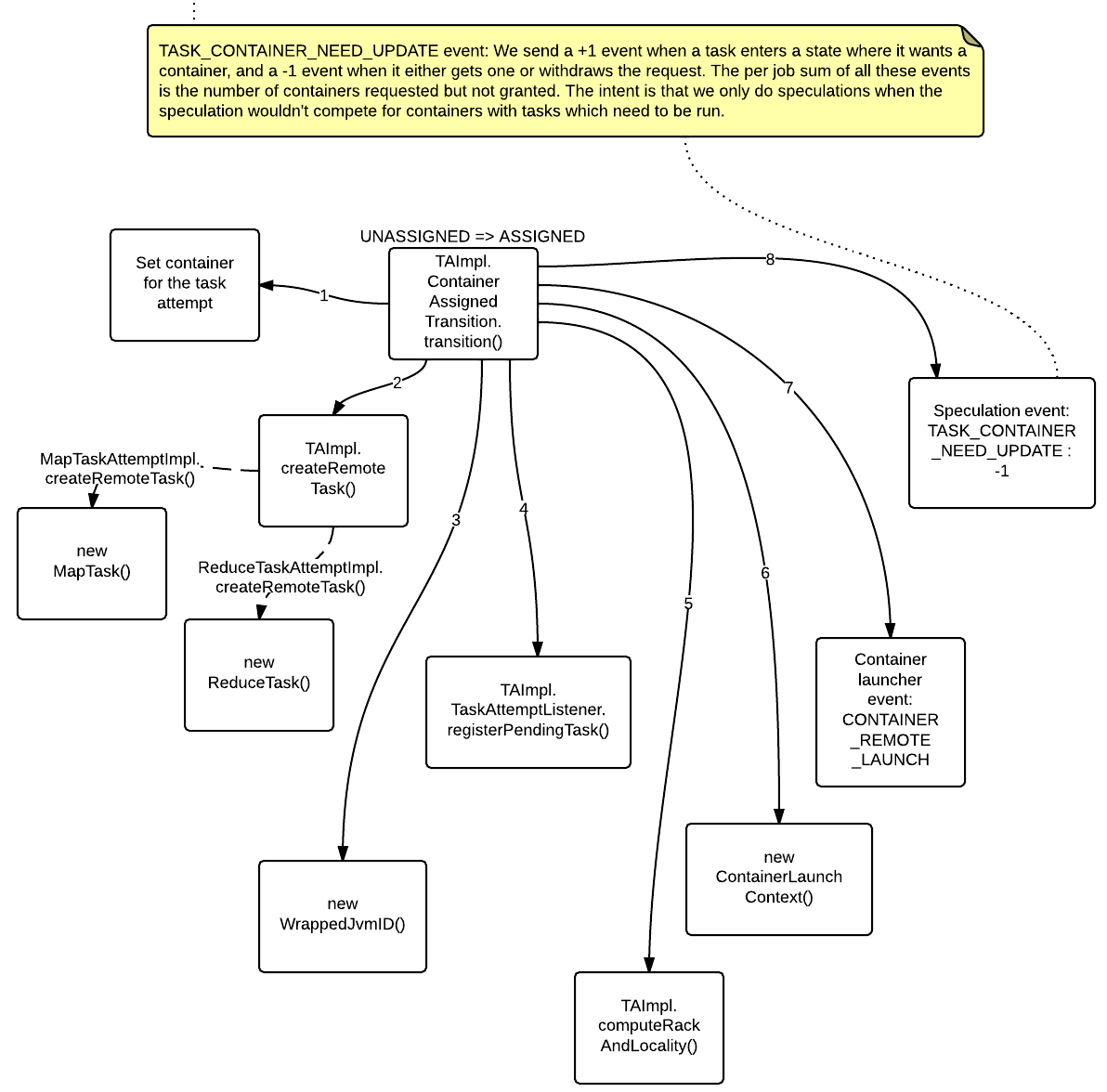
- UNASSIGNED => ASSIGNED [TA_ASSIGNED]
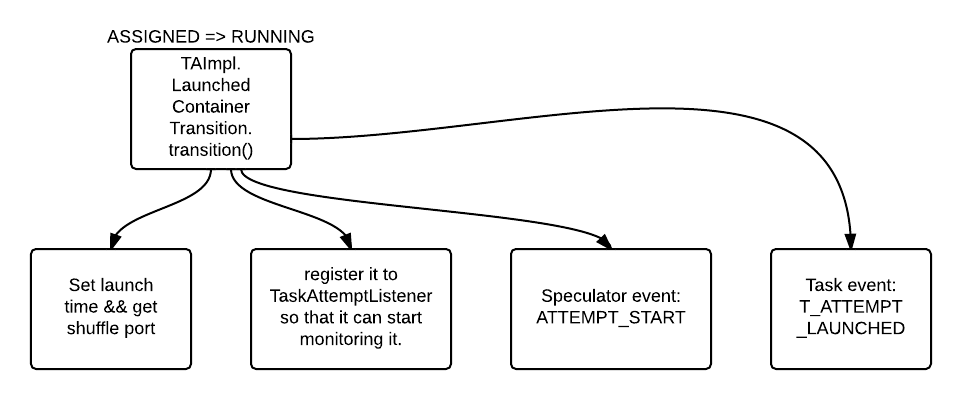
- ASSIGNED => RUNNING [TA_CONTAINER_LAUNCHED]
- RUNNING => SUCCESS_CONTAINER_CLEANUP [TA_DONE], COMMIT_PENDING => SUCCESS_CONTAINER_CLEANUP[TA_DONE]
- SUCCESS_CONTAINER_CLEANUP => SUCCEEDEED [TA_CONTAINER_CLEANED]
Finite State Machine
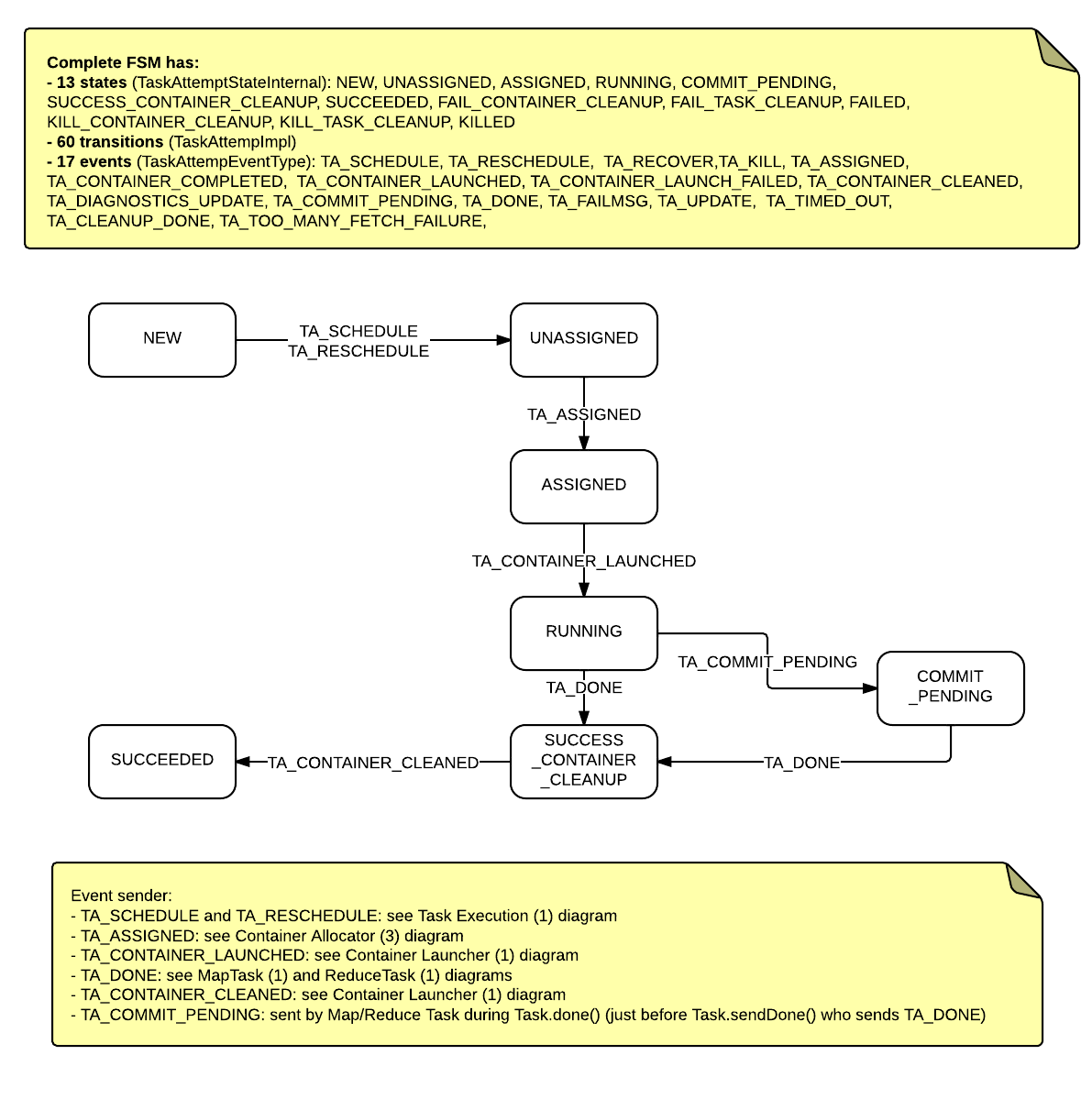
NEW => UNASSIGNED [TA_SCHEDULE]
UNASSIGNED => ASSIGNED [TA_ASSIGNED]
ASSIGNED => RUNNING [TA_CONTAINER_LAUNCHED]
RUNNING => SUCCESS_CONTAINER_CLEANUP [TA_DONE], COMMIT_PENDING => SUCCESS_CONTAINER_CLEANUP [TA_DONE]
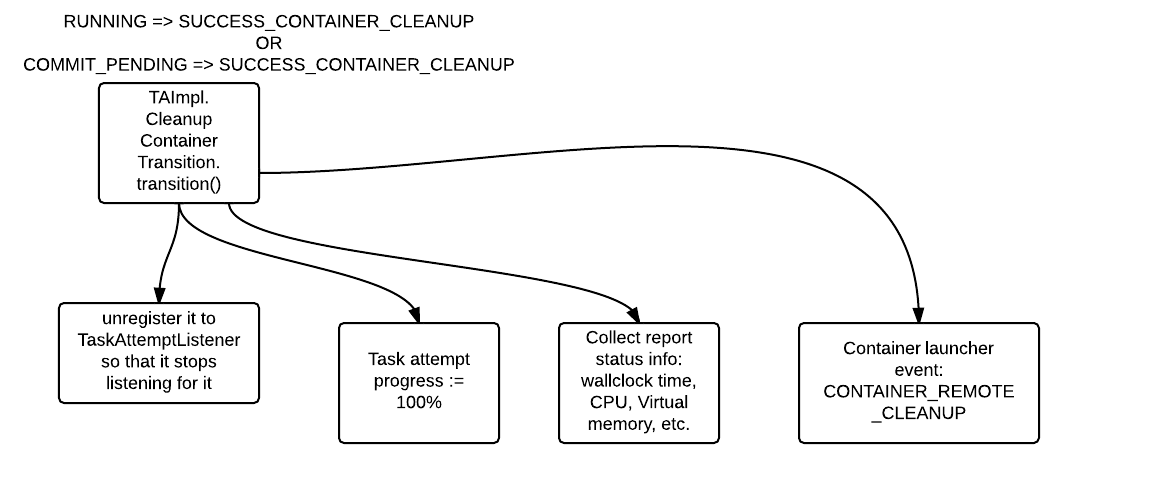
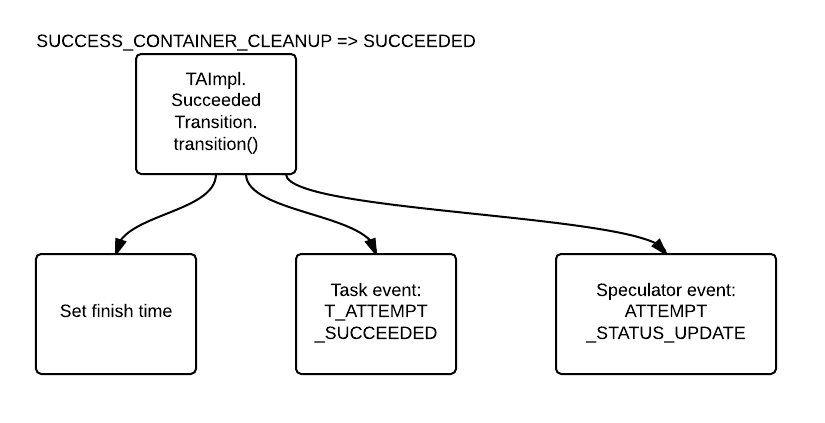
SUCCESS_CONTAINER_CLEANUP => SUCCEEDEED [TA_CONTAINER_CLEANED]
MapTask
Table of contents:
Startup
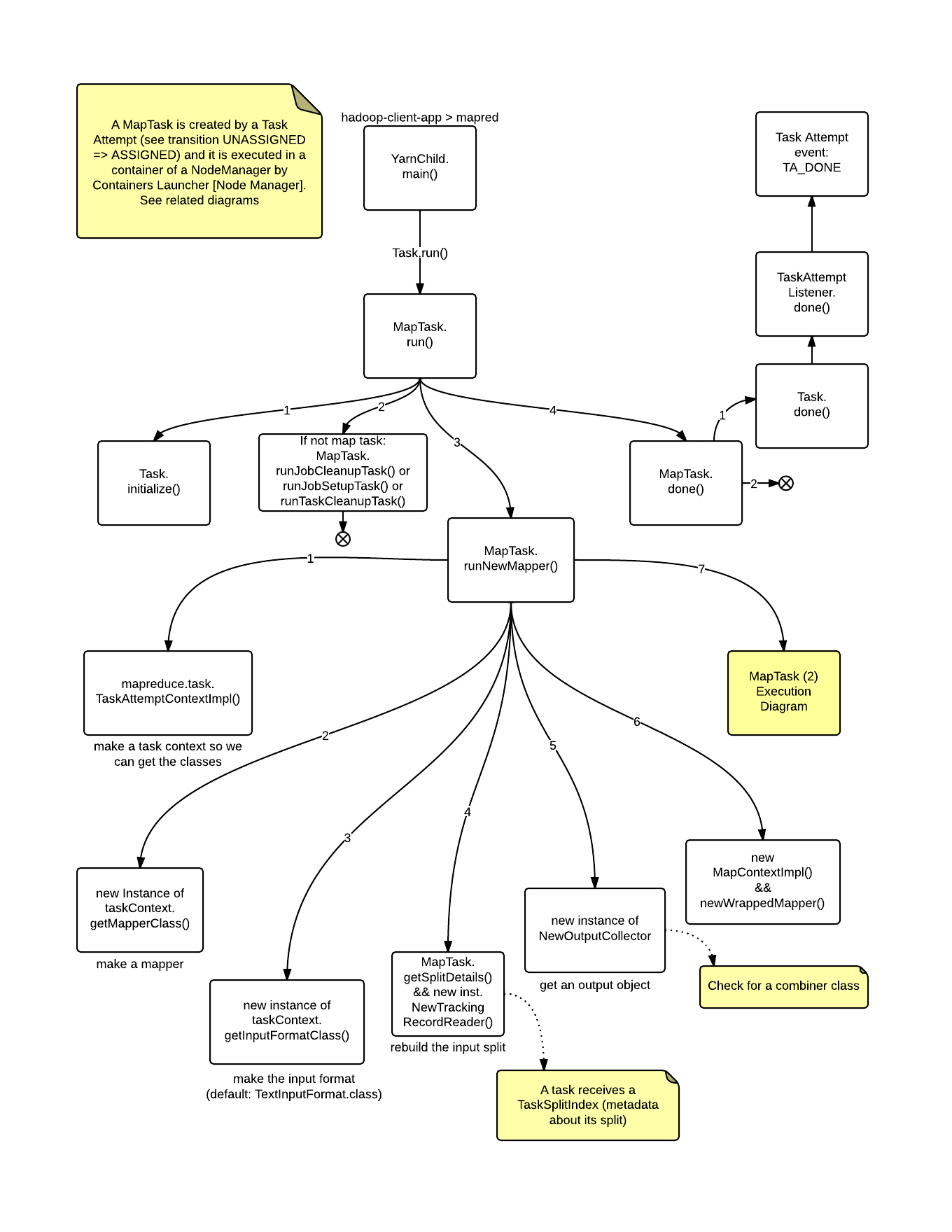
Execution
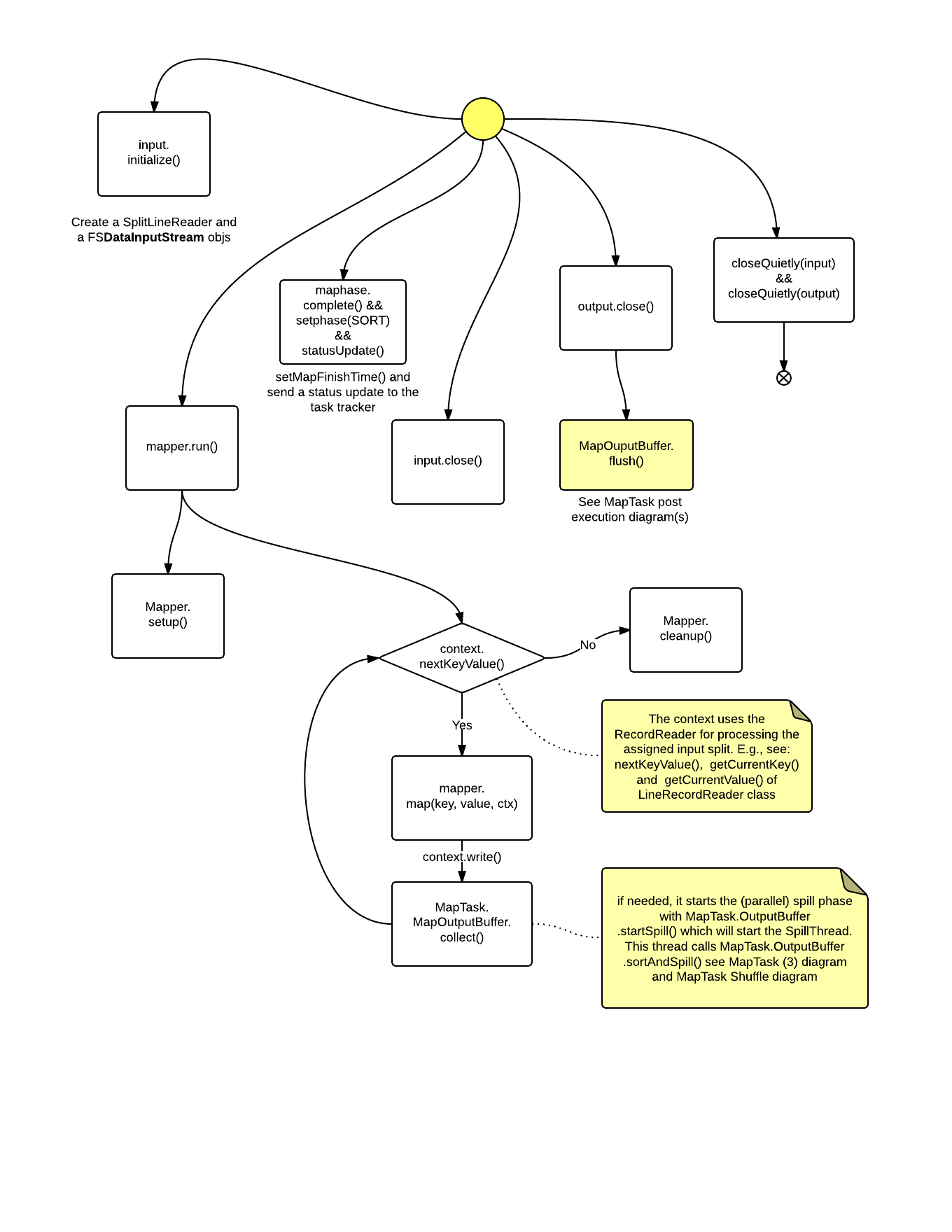
Post Execution - Shuffle

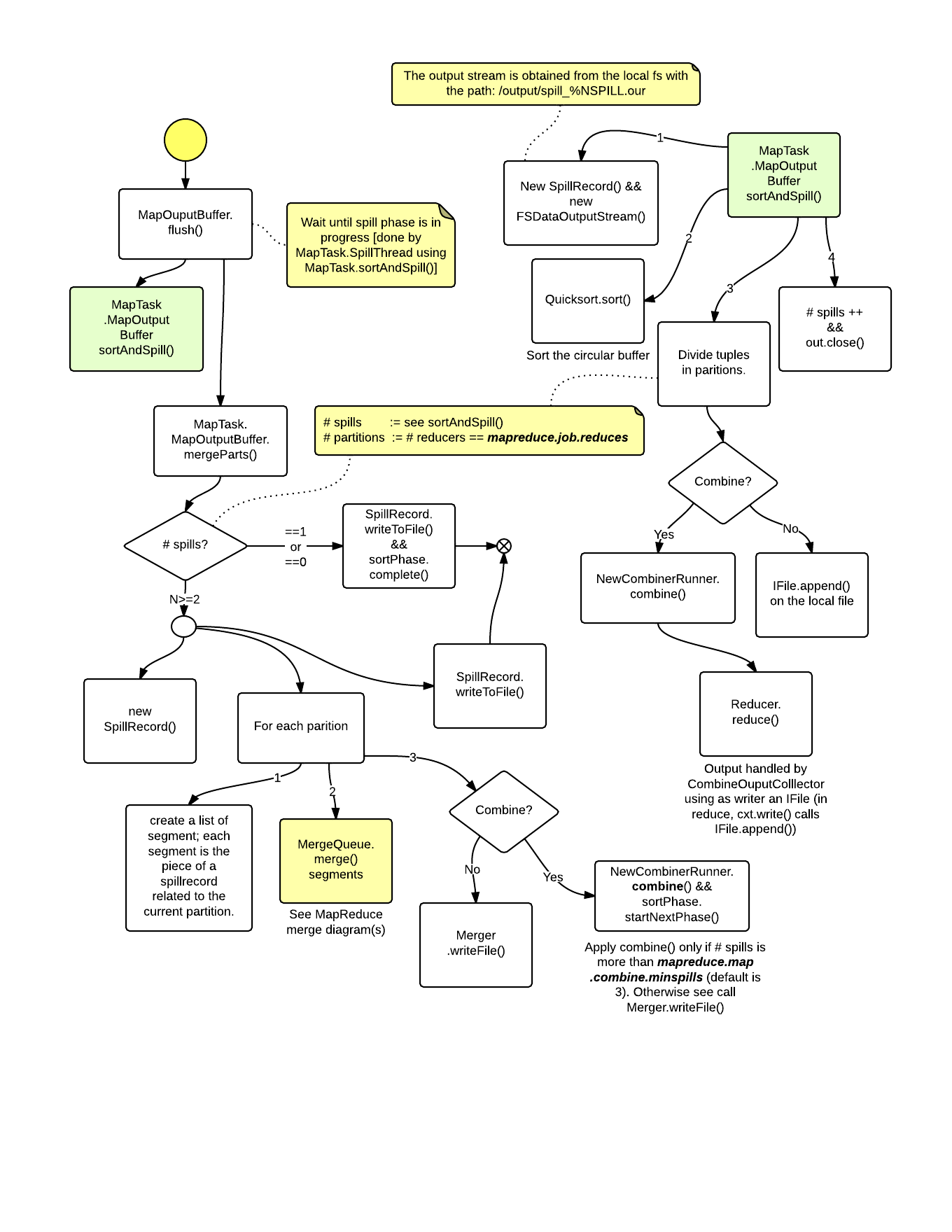
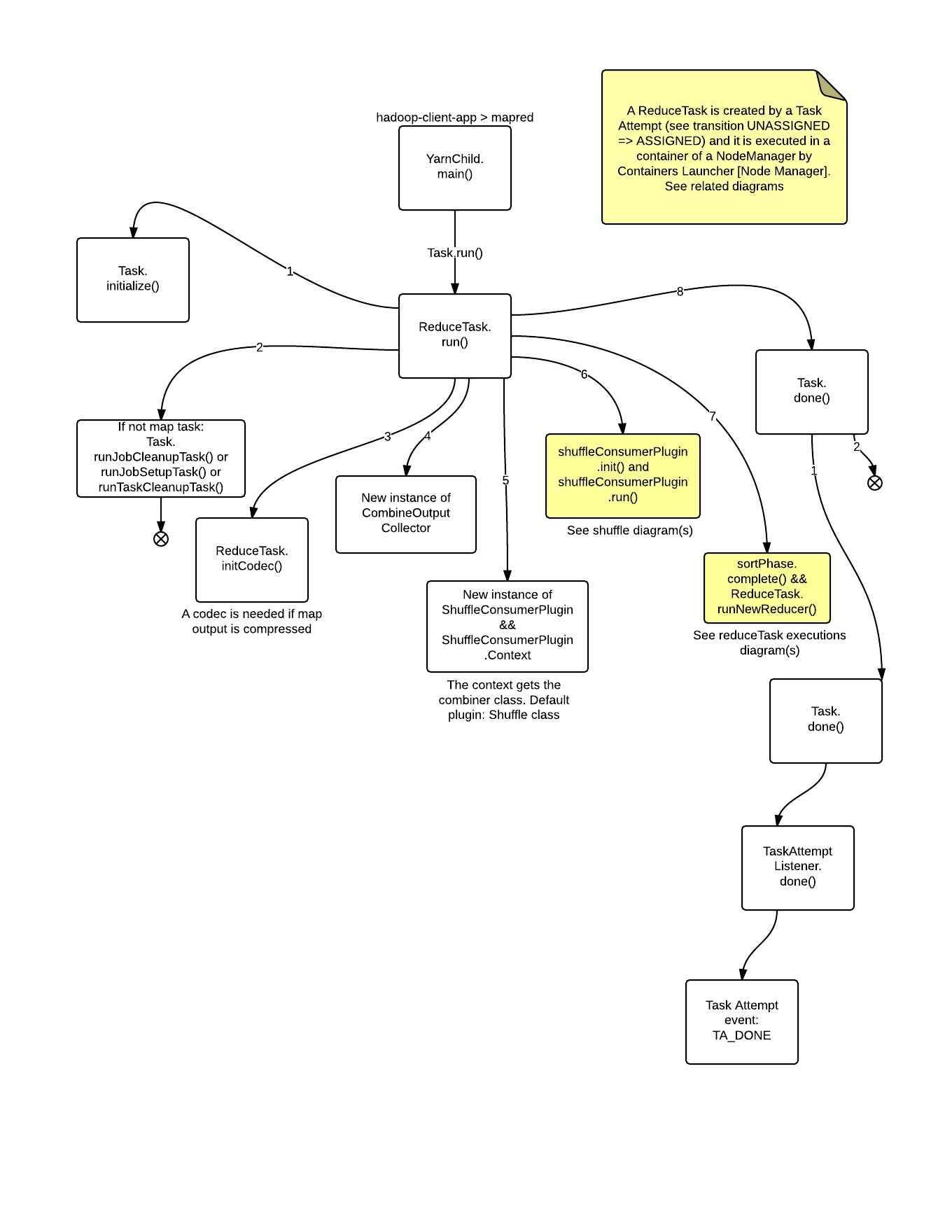
ReduceTask
Table of contents:
Startup
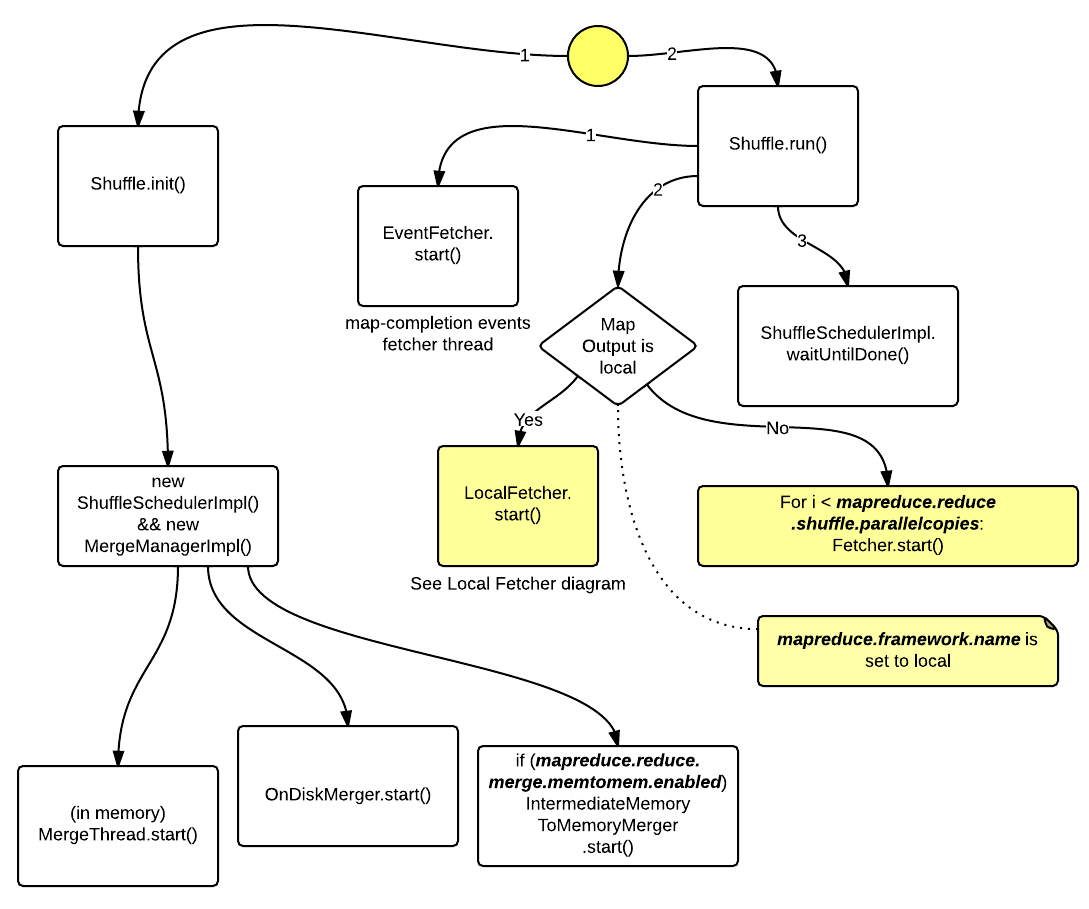
Shuffle
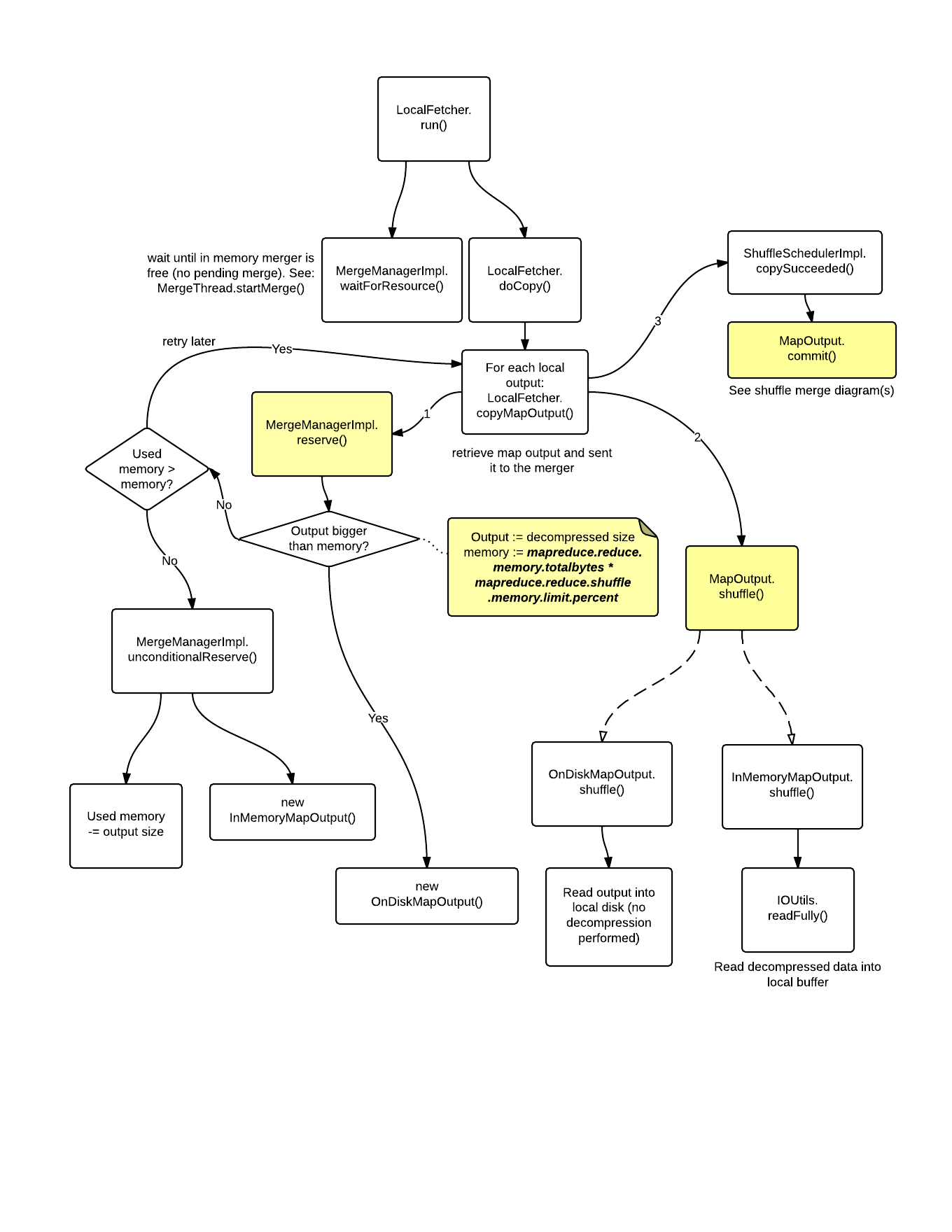
Local Fetcher
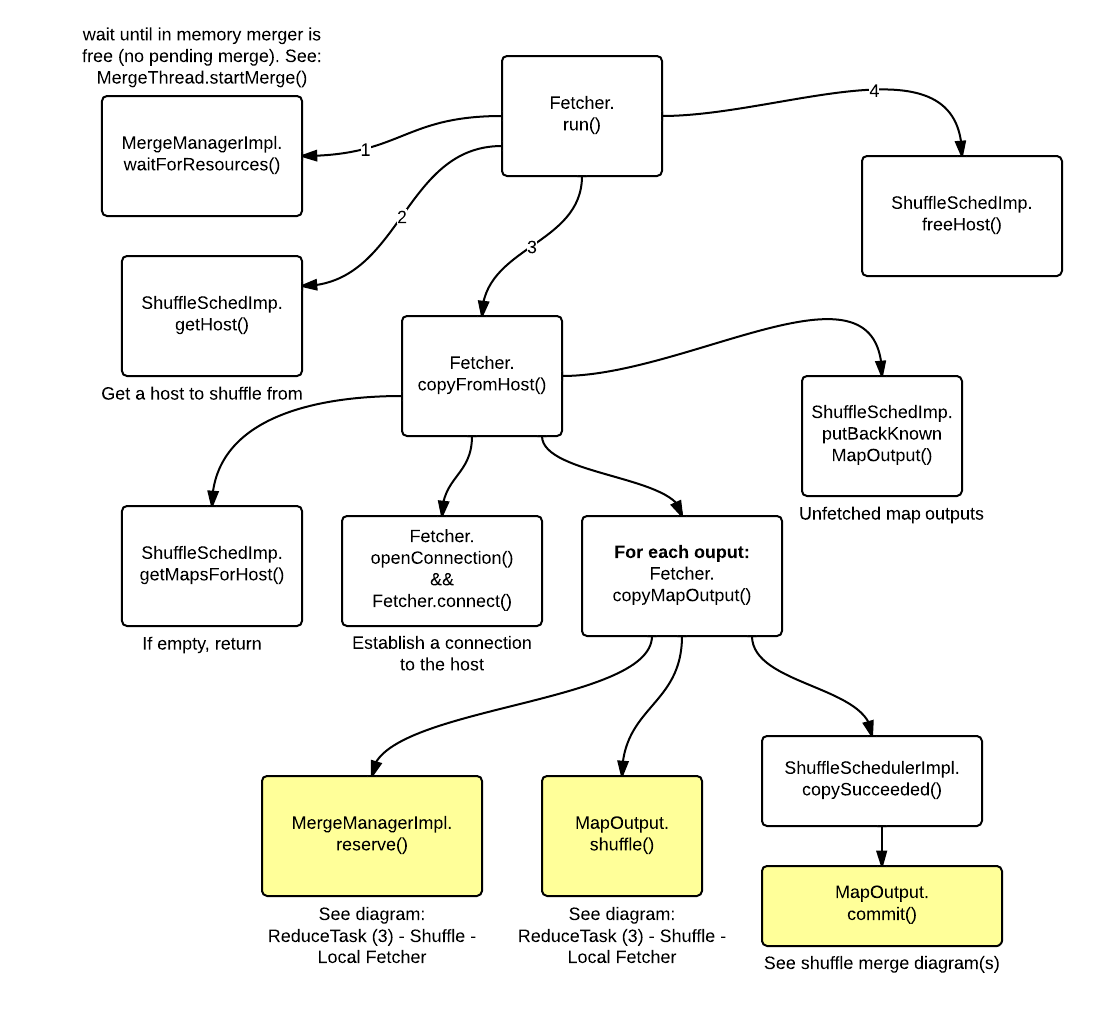
Fetcher
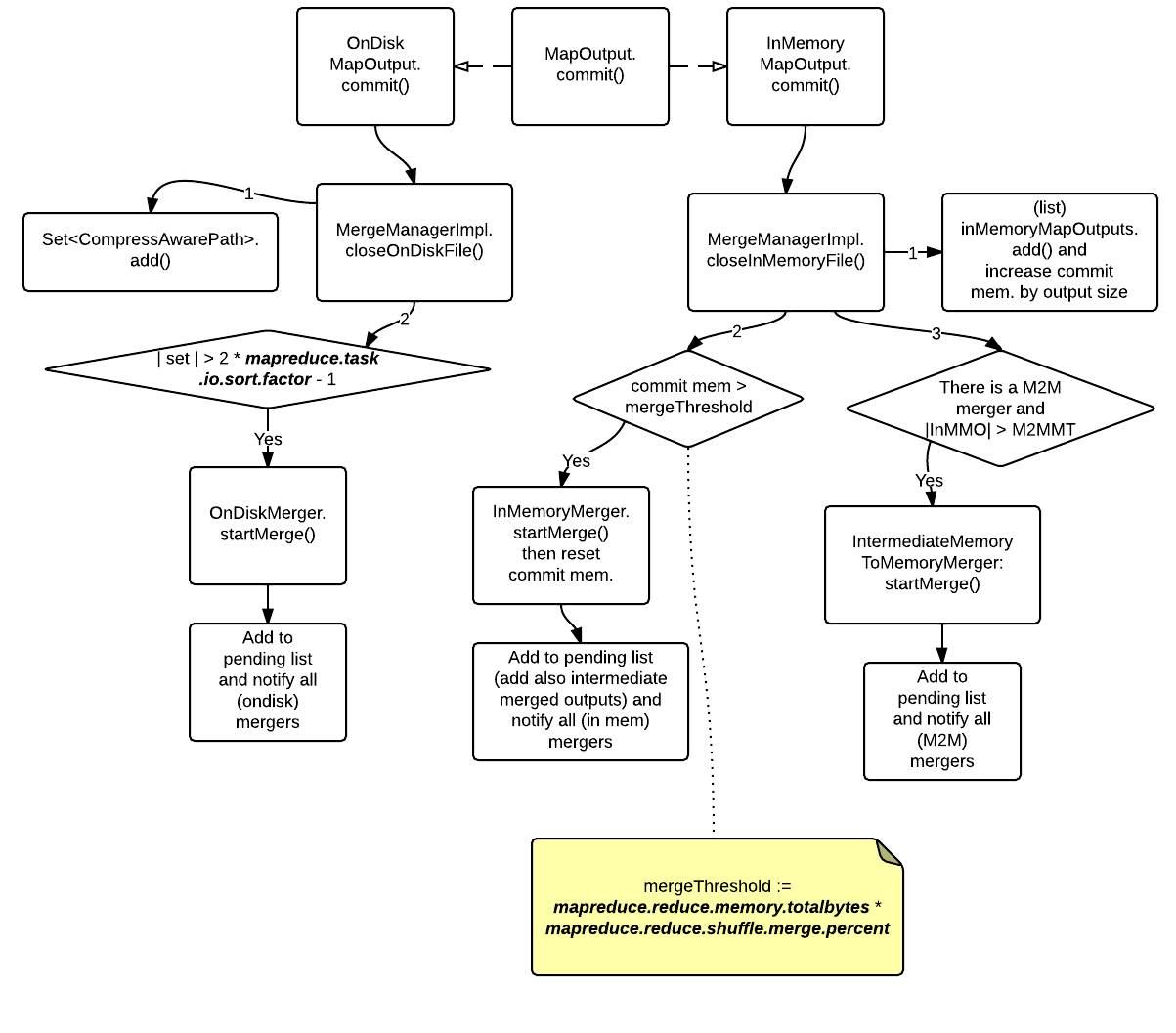
Shuffle - Merge
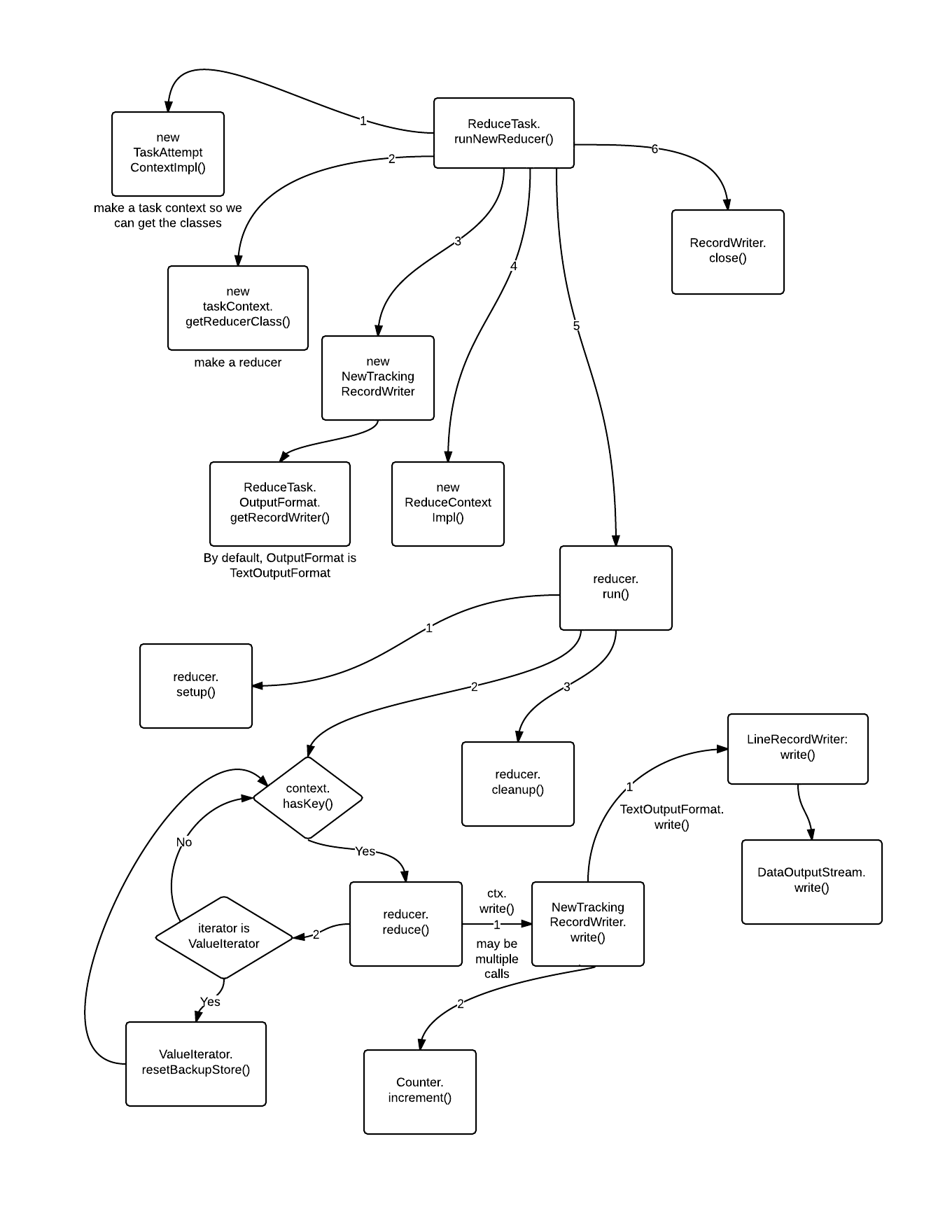
Execution
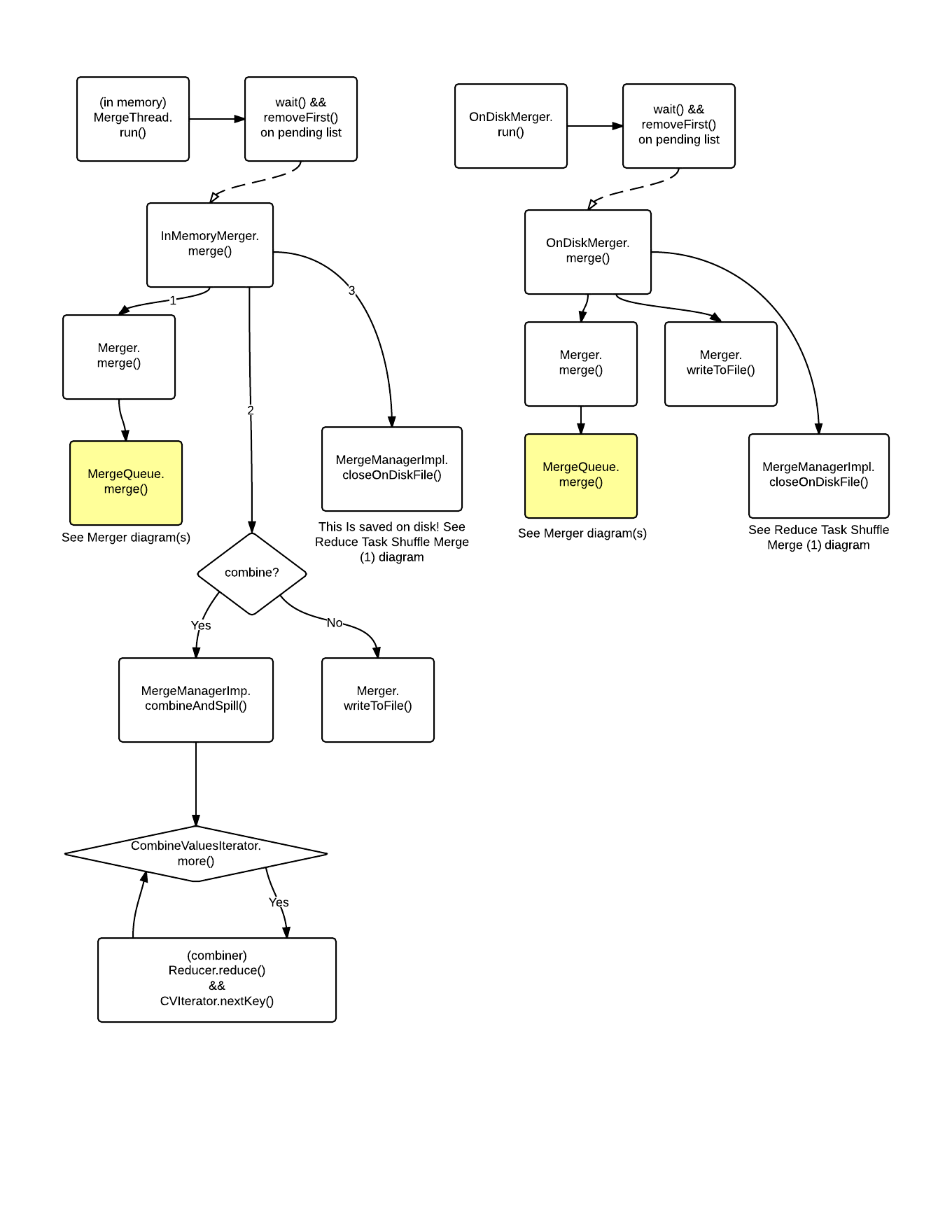
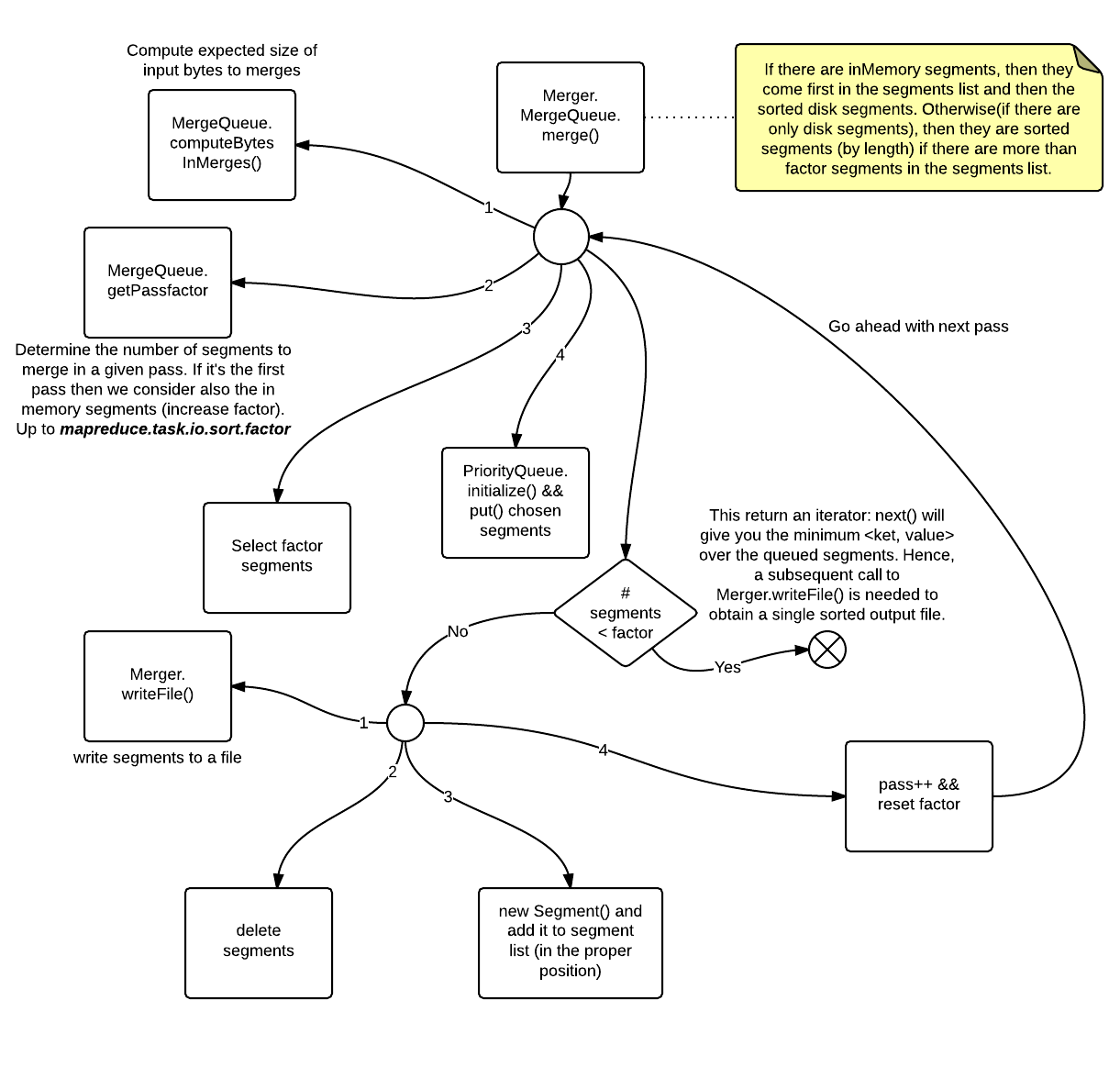
Merger



相关推荐
Map/Reduce介绍。一些基本基础介绍。
该模型的核心思想是将复杂的并行和分布式计算过程简化为两个主要步骤:Map 和 Reduce。Map 阶段将原始数据拆分成键值对,应用用户自定义的映射函数,生成中间键值对;Reduce 阶段则将具有相同中间键的值聚合,通过...
### 基于Map/Reduce的分布式搜索引擎研究 #### 1. 引言 随着互联网信息量的爆炸性增长,如何高效地处理和存储海量数据成为了一个亟待解决的问题。传统的集中式搜索引擎在处理大规模数据时面临诸多挑战,如性能瓶颈...
在Windows平台上进行Hadoop的Map/Reduce开发可能会比在Linux环境下多一些挑战,但通过详细的步骤和理解Map/Reduce的工作机制,开发者可以有效地克服这些困难。以下是对标题和描述中涉及知识点的详细说明: **Hadoop...
通过以上介绍,我们可以看到,远程调用执行Hadoop Map/Reduce涵盖了从编写MapReduce程序到提交、监控和管理作业的全过程。理解和掌握这一过程对于开发和优化大数据处理应用至关重要。在实际项目中,开发者可以根据...
MapReduce的设计理念源于Google的同名论文,它通过将大规模数据处理任务分解为两个阶段:Map(映射)和Reduce(化简),使得海量数据能够在多台计算机上并行处理,极大地提高了数据处理效率。 Map阶段是数据处理的...
该模块介绍了使用 Map/Reduce 的并行编程概念--这是有效使用地球引擎分析大量数据的关键。您将学习如何使用地球引擎 API 计算各种光谱指数,进行云遮蔽,然后使用 Map/reduce 将这些计算应用于图像集合。您还将学习...
本文将深入探讨云计算的三大关键技术:Dynamo、Bigtable和Map/Reduce,并对比分析它们的设计理念和应用场景。 首先,Dynamo是亚马逊公司开发的一种分布式键值存储系统,主要用于支持大规模的在线服务,如S3存储服务...
win7_64eclispe插件 解决An internal error occurred during: "Map/Reduce location status updater". org/codehaus/jackson/map/JsonMappingException 重新编译包
标题中的“map/reduce template”指的是MapReduce编程模型的一个模板或框架,它是Apache Hadoop项目的核心部分,用于处理和生成大数据集。MapReduce的工作原理分为两个主要阶段:Map阶段和Reduce阶段,它允许程序员...
标题中的“在solr文献检索中用map/reduce”指的是使用Apache Solr,一个流行的开源搜索引擎,结合Hadoop的MapReduce框架来处理大规模的分布式搜索任务。MapReduce是一种编程模型,用于处理和生成大型数据集,它将...
Reporter 是 Map/Reduce 框架中的一个组件,负责报告作业的执行状态和进度。 OutputCollector 是 Map/Reduce 框架中的一个组件,负责收集 Reduce 任务的输出结果,并将其存储在文件系统中。 作业配置是 Map/Reduce...
同时为该系统定义一组关于作业的建立、管理和维护的通信规程,即拓扑管理协议.SPATE系统解决了在线Map/Reduce流数据处理过程中要求实时性及可扩展性的问题.实验验证了拓扑管理协议的有效性,拓扑管理协议能有效管理...
在对Map/Reduce算法进行分析的基础上,利用开源Hadoop软件设计出高容错高性能的分布式搜索引擎,以面对搜索引擎对海量数据的处理和存储问题
- **Reduce**: reduce() 函数属于 functools 模块,用于累积地对序列中的元素执行某个函数操作。 **3. 实战案例** 例如,我们可以使用lambda表达式配合map()函数来实现列表元素的平方操作: ```python numbers = ...
不过本文的Skynet没这么恐怖,它是一个ruby版本的Google Map/Reduce框架的名字而已。 Google的Map/Reduce框架实在太有名气了,他可以把一个任务切分为很多份,交给n台计算机并行执行,返回的结果再并行的归并,最后...
它由两部分组成:`Map`阶段和`Reduce`阶段。MapReduce框架负责调度任务、管理计算节点和处理系统故障等底层细节。 ### MapReduce实现案例分析 根据题目要求,我们需要连接`student.txt`和`student_score.txt`这两...
本研究聚焦于在云计算环境中,基于Map/Reduce框架的改进选择算法在Web数据挖掘中的应用。Map/Reduce是一种编程模型,用于大规模数据集的并行计算,特别适合处理和生成超大规模数据。其基本思想是将任务分解为两个...