
йЧЃйҐШеѓЉиѓї
1гАБYarnеѓєMRv1зЪДжФєињЫжЬЙеУ™дЇЫпЉЯ
2гАБжАОж†ЈеѓєYarnзЃАеНХзЪДеЖЕе≠ШйЕНзљЃпЉЯ
3гАБе¶ВдљХзРЖиІ£YarnзЪДиµДжЇРжКљи±°containerпЉЯ![]()
еЬ®ињЩзѓЗдЄ≠пЉМдЄїи¶БдїЛзїНдЇЖYarnеѓєMRv1зЪДжФєињЫпЉМдї•еПКYarnзЃАеНХзЪДеЖЕе≠ШйЕНзљЃеТМYarnзЪДиµДжЇРжКљи±°containerгАВ
жИСдєИзЯ•йБУMRv1е≠ШеЬ®зЪДдЄїи¶БйЧЃйҐШжШѓпЉЪеЬ®ињРи°МжЧґпЉМJobTrackerжЧҐиіЯиі£иµДжЇРзЃ°зРЖеПИиіЯиі£дїїеК°и∞ГеЇ¶пЉМињЩеѓЉиЗідЇЖеЃГзЪДжЙ©е±ХжАІгАБиµДжЇРеИ©зФ®зОЗдљОз≠ЙйЧЃйҐШгАВдєЛжЙАдї•е≠ШеЬ®ињЩж†ЈзЪДйЧЃйҐШпЉМжШѓдЄОеЕґжЬАеИЭзЪДиЃЊиЃ°жЬЙеЕ≥пЉМе¶ВдЄЛеЫЊпЉЪ
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">  
 
дїОдЄКеЫЊеПѓдї•зЬЛеИ∞пЉМMRv1жШѓеЫізїХзЭАMapReduceињЫи°МпЉМеєґж≤°жЬЙињЗе§ЪеЬ∞иАГиЩСдї•еРОеЗЇзО∞зЪДеЕґеЃГжХ∞жНЃе§ДзРЖжЦєеЉП гАВжМЙзЭАдЄКеЫЊзЪДиЃЊиЃ°жАЭиЈѓпЉМжИСдїђжѓПеЉАеПСдЄАзІНжХ∞жНЃе§ДзРЖжЦєеЉПпЉИдЊЛе¶ВsparkпЉЙпЉМйГљи¶БйЗНе§НеЃЮзО∞зЫЄеЇФзЪДйЫЖзЊ§иµДжЇРзЃ°зРЖеТМжХ∞жНЃе§ДзРЖгАВеЫ†ж≠§пЉМYarnе∞±еЊИиЗ™зДґзЪД襀еЉАеПСеЗЇжЭ•дЇЖгАВ
YarnеѓєMRv1зЪДжЬАе§ІжФєињЫе∞±жШѓе∞ЖиµДжЇРзЃ°зРЖдЄОдїїеК°и∞ГеЇ¶еИЖз¶їпЉМдљњеЊЧеРДзІНжХ∞жНЃе§ДзРЖжЦєеЉПиГље§ЯеЕ±дЇЂиµДжЇРзЃ°зРЖпЉМе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">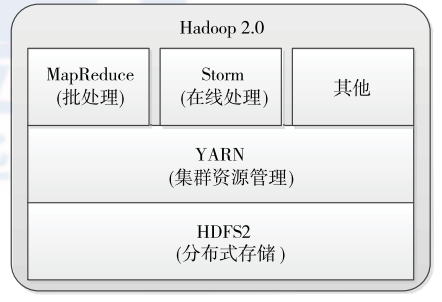  
 
дїОдЄКеЫЊжИСдїђеПѓдї•зЬЛеИ∞пЉМYarnжШѓдЄАзІНзїЯдЄАиµДжЇРзЃ°зРЖжЦєеЉПпЉМжШѓдїОMRv1дЄ≠зЪДJobTrackerеИЖз¶їеЗЇжЭ•зЪДгАВињЩж†ЈзЪДе•ље§ДжШЊиАМжШУиІБпЉЪиµДжЇРеЕ±дЇЂпЉМжЙ©е±ХжАІе•љз≠ЙгАВ
MRv1дЄОYarnзЪДдЄїи¶БеМЇеИЂпЉЪеЬ®MRv1дЄ≠пЉМзФ±JobTrackerиіЯиі£иµДжЇРзЃ°зРЖеТМдљЬдЄЪжОІеИґпЉМиАМYarnдЄ≠пЉМJobTracker襀еИЖдЄЇдЄ§йГ®еИЖпЉЪResourceManagerпЉИRMпЉЙеТМApplicationMasterпЉИAMпЉЙгАВе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">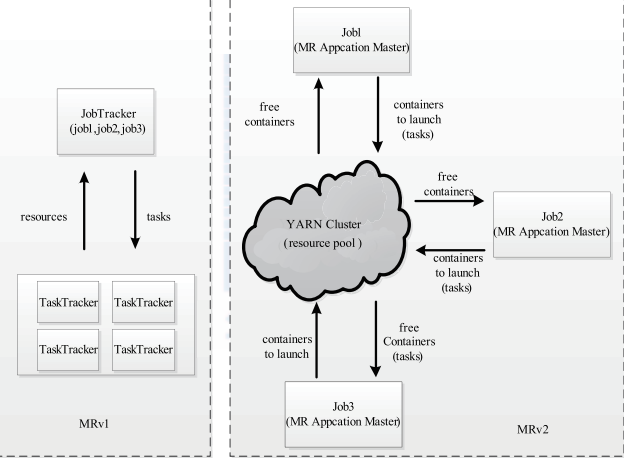  
 
дїОдЄКеЫЊдЄ≠пЉМжИСдїђеПѓдї•жЄЕжЩ∞зЪДзЬЛеИ∞ пЉМеѓєдЇОMRv1жЧ†иЃЇжШѓиµДжЇРзЃ°зРЖйЗМињШжШѓдїїеК°и∞ГеЇ¶йГљжШѓжЬЙJobTrackerжЭ•еЃМжИРеЊЧгАВињЩеѓЉиЗідЇЖпЉМJobTrackerиіЯиͣ姙姲дЄНдЊњдЇОзЃ°зРЖеТМжЙ©е±ХиАМеѓєдЇОYarnпЉМжИСдїђзЬЛеПѓдї•жЄЕжЩ∞еЬ∞зЬЛеИ∞иµДжЇРзЃ°зРЖеТМдїїеК°и∞Г寶襀еИЖдЄЇдЇЖдЄ§дЄ™йГ®еИЖпЉЪRMеТМAMгАВ
YarnдЄОMRv1зЪДеЈЃеЉВеѓєзЉЦз®ЛзЪДељ±еУНпЉЪжИСдїђзЯ•йБУпЉМMRv1дЄїи¶БзФ±дЄЙйГ®еИЖзїДжИРпЉЪзЉЦз®Лж®°еЮЛ(API)гАБжХ∞жНЃе§ДзРЖеЉХжУО(MapTaskеТМReduceTask)еТМињРи°МзОѓеҐГ(JobTrackerеТМTaskTracker);YarnзїІжЙњдЇЖMRv1зЪДзЉЦз®Лж®°еЮЛеТМжХ∞жНЃе§ДзРЖпЉМжФєеПШзЪДеП™жШѓињРи°МзОѓеҐГпЉМжЙАдї•еѓєзЉЦз®Лж≤°жЬЙдїАдєИељ±еУНгАВ
дЄЇдЇЖжЫіе•љ зЪДиѓіжШОYarnзЪДиµДжЇРзЃ°зРЖпЉМй¶ЦеЕИжЭ•зЬЛдЄЛYarnзЪДж°ЖжЮґпЉМе¶ВдЄЛеЫЊжЙАз§ЇпЉЪ
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">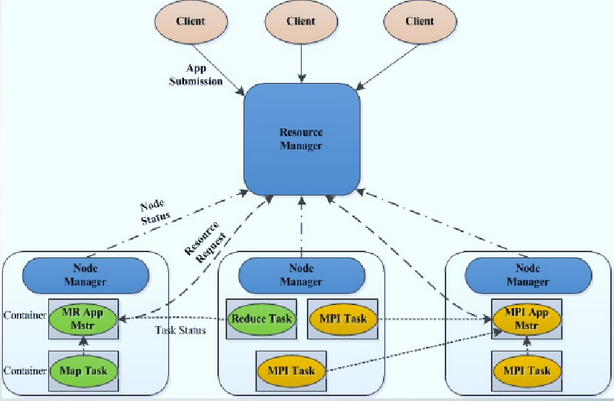  
 
дїОдЄКеЫЊеПѓдї•зЬЛеИ∞ пЉМељУеЃҐжИЈеРСRMжПРдЇ§ дљЬдЄЪжЧґпЉМзФ±AMиіЯиі£еРСRMжПРеЗЇиµДжЇРзФ≥иѓЈпЉМеТМеРСNameManagerпЉИNMпЉЙжПРеЗЇtaskжЙІи°М гАВдєЯе∞±жШѓиѓі еЬ®ињЩдЄ™ињЗз®ЛдЄ≠пЉМRMиіЯиі£иµДжЇРи∞ГеЇ¶пЉМAM иіЯиі£дїїеК°и∞ГеЇ¶гАВеЗ†зВєйЗНи¶БиѓіжШОпЉЪRMиіЯиі£жХідЄ™йЫЖзЊ§зЪДиµДжЇРзЃ°зРЖдЄОи∞ГеЇ¶пЉЫNodemanager(NM)иіЯиі£еНХдЄ™иКВзВєзЪДиµДжЇРзЃ°зРЖдЄОи∞ГеЇ¶пЉЫNMеЃЪжЧґзЪДйАЪињЗењГиЈ≥зЪД嚥еЉПдЄОRMињЫи°МйАЪдњ°пЉМжК•еСКиКВзВєзЪДеБ•еЇЈзКґжАБдЄОеЖЕе≠ШдљњзФ®жГЕеЖµпЉЫAMйАЪињЗдЄОRMдЇ§дЇТиОЈеПЦиµДжЇРпЉМзДґеРОзДґеРОйАЪињЗдЄОNMдЇ§дЇТпЉМеРѓеК®иЃ°зЃЧдїїеК°гАВ
дЄЛйЭҐеѓєдЄКйЭҐзЪДеЖЕеЃєйАЪињЗеЖЕе≠ШиµДжЇРйЕНзљЃињЫи°Миѓ¶зїЖиѓіжШОпЉЪдЄЛйЭҐеѓєдЄКйЭҐзЪДеЖЕеЃєйАЪињЗеЖЕе≠ШиµДжЇРйЕНзљЃињЫи°Миѓ¶зїЖиѓіжШОпЉЪ
RMзЪДеЖЕе≠ШиµДжЇРйЕНзљЃпЉМдЄїи¶БжШѓйАЪињЗдЄЛйЭҐзЪДдЄ§дЄ™еПВжХ∞ињЫи°МзЪДпЉИињЩдЄ§дЄ™еАЉжШѓYarnеє≥еП∞зЙєжАІпЉМеЇФеЬ®yarn-sit.xmlдЄ≠йЕНзљЃе•љпЉЙпЉЪ¬†
yarn.scheduler.minimum-allocation-mb 
yarn.scheduler.maximum-allocation-mb
иѓіжШОпЉЪеНХдЄ™еЃєеЩ®еПѓзФ≥иѓЈзЪДжЬАе∞ПдЄОжЬАе§ІеЖЕе≠ШпЉМеЇФзФ®еЬ®ињРи°МзФ≥иѓЈеЖЕе≠ШжЧґдЄНиГљиґЕињЗжЬАе§ІеАЉпЉМе∞ПдЇОжЬАе∞ПеАЉеИЩеИЖйЕНжЬАе∞ПеАЉпЉМдїОињЩдЄ™иІТеЇ¶зЬЛпЉМжЬАе∞ПеАЉжЬЙзВєжГ≥жУНдљЬз≥їзїЯдЄ≠зЪДй°µгАВжЬАе∞ПеАЉињШжЬЙеП¶е§ЦдЄАзІНзФ®йАФпЉМиЃ°зЃЧдЄАдЄ™иКВзВєзЪДжЬАе§ІcontainerжХ∞зЫЃж≥®пЉЪињЩдЄ§дЄ™еАЉдЄАзїПиЃЊеЃЪдЄНиГљеК®жАБжФєеПШ(ж≠§е§ДжЙАиѓізЪДеК®жАБжФєеПШжШѓжМЗеЇФзФ®ињРи°МжЧґ)гАВ
NMзЪДеЖЕе≠ШиµДжЇРйЕНзљЃпЉМдЄїи¶БжШѓйАЪињЗдЄЛйЭҐдЄ§дЄ™еПВжХ∞ињЫи°МзЪДпЉИињЩдЄ§дЄ™еАЉжШѓYarnеє≥еП∞зЙєжАІпЉМеЇФеЬ®yarn-sit.xmlдЄ≠йЕНзљЃпЉЙ пЉЪ
yarn.nodemanager.resource.memory-mb
yarn.nodemanager.vmem-pmem-ratio
иѓіжШОпЉЪжѓПдЄ™иКВзВєеПѓзФ®зЪДжЬАе§ІеЖЕе≠ШпЉМRMдЄ≠зЪДдЄ§дЄ™еАЉдЄНеЇФиѓ•иґЕињЗж≠§еАЉгАВж≠§жХ∞еАЉеПѓдї•зФ®дЇОиЃ°зЃЧcontainerжЬАе§ІжХ∞зЫЃпЉМеН≥пЉЪзФ®ж≠§еАЉйЩ§дї•RMдЄ≠зЪДжЬАе∞ПеЃєеЩ®еЖЕе≠ШгАВиЩЪжЛЯеЖЕе≠ШзОЗпЉМжШѓеН†taskжЙАзФ®еЖЕе≠ШзЪДзЩЊеИЖжѓФпЉМйїШиЃ§еАЉдЄЇ2.1еАН;ж≥®жДПпЉЪзђђдЄАдЄ™еПВжХ∞жШѓдЄНеПѓдњЃжФєзЪДпЉМдЄАжЧ¶иЃЊзљЃпЉМжХідЄ™ињРи°МињЗз®ЛдЄ≠дЄНеПѓеК®жАБдњЃжФєпЉМдЄФиѓ•еАЉзЪДйїШиЃ§е§Іе∞ПжШѓ8GпЉМеН≥дљњиЃ°зЃЧжЬЇеЖЕе≠ШдЄНиґ≥8GдєЯдЉЪжМЙзЭА8GеЖЕе≠ШжЭ•дљњзФ®гАВ
AMеЖЕе≠ШйЕНзљЃзЫЄеЕ≥еПВжХ∞пЉМж≠§е§Ддї•MapReduceдЄЇдЊЛињЫи°МиѓіжШОпЉИињЩдЄ§дЄ™еАЉжШѓAMзЙєжАІпЉМеЇФеЬ®mapred-site.xmlдЄ≠йЕНзљЃпЉЙпЉМе¶ВдЄЛпЉЪ
mapreduce.map.memory.mb
mapreduce.reduce.memory.mb
иѓіжШОпЉЪињЩдЄ§дЄ™еПВжХ∞жМЗеЃЪзФ®дЇОMapReduceзЪДдЄ§дЄ™дїїеК°пЉИMap and Reduce taskпЉЙзЪДеЖЕе≠Ше§Іе∞ПпЉМеЕґеАЉеЇФиѓ•еЬ®RMдЄ≠зЪДжЬАе§ІжЬАе∞ПcontainerдєЛйЧігАВе¶ВжЮЬж≤°жЬЙйЕНзљЃеИЩйАЪињЗе¶ВдЄЛзЃАеНХеЕђеЉПиОЈеЊЧпЉЪ
max(MIN_CONTAINER_SIZE, (Total Available RAM) / containers))
дЄАиИђзЪДreduceеЇФиѓ•жШѓmapзЪД2еАНгАВж≥®пЉЪињЩдЄ§дЄ™еАЉеПѓдї•еЬ®еЇФзФ®еРѓеК®жЧґйАЪињЗеПВжХ∞жФєеПШпЉЫ
AMдЄ≠еЕґеЃГдЄОеЖЕе≠ШзЫЄеЕ≥зЪДеПВжХ∞пЉМињШжЬЙJVMзЫЄеЕ≥зЪДеПВжХ∞пЉМињЩдЇЫеПВжХ∞еПѓдї•йАЪињЗпЉМе¶ВдЄЛйАЙй°єйЕНзљЃпЉЪ
mapreduce.map.java.opts
mapreduce.reduce.java.opts
иѓіжШОпЉЪињЩдЄ§дЄ™еПВдЄїи¶БжШѓдЄЇйЬАи¶БињРи°МJVMз®ЛеЇПпЉИjavaгАБscalaз≠ЙпЉЙеЗЖе§ЗзЪДпЉМйАЪињЗињЩдЄ§дЄ™иЃЊзљЃеПѓдї•еРСJVMдЄ≠дЉ†йАТеПВжХ∞зЪДпЉМдЄОеЖЕе≠ШжЬЙеЕ≥зЪДжШѓпЉМ-XmxпЉМ-Xmsз≠ЙйАЙй°єгАВж≠§жХ∞еАЉе§Іе∞ПпЉМеЇФиѓ•еЬ®AMдЄ≠зЪДmap.mbеТМreduce.mbдєЛйЧігАВ
жИСдїђеѓєдЄКйЭҐзЪДеЖЕеЃєињЫи°МдЄЛжАїзїУпЉМељУйЕНзљЃYarnеЖЕе≠ШзЪДжЧґеАЩдЄїи¶БжШѓйЕНзљЃе¶ВдЄЛдЄЙдЄ™жЦєйЭҐпЉЪжѓПдЄ™MapеТМReduceеПѓзФ®зЙ©зРЖеЖЕе≠ШйЩРеИґпЉЫеѓєдЇОжѓПдЄ™дїїеК°зЪДJVMеѓєе§Іе∞ПзЪДйЩРеИґпЉЫиЩЪжЛЯеЖЕе≠ШзЪДйЩРеИґпЉЫ
дЄЛйЭҐйАЪињЗдЄАдЄ™еЕЈдљУйФЩиѓѓеЃЮдЊЛпЉМињЫи°МеЖЕе≠ШзЫЄеЕ≥иѓіжШОпЉМйФЩиѓѓе¶ВдЄЛпЉЪ
Container[pid=41884,containerID=container_1405950053048_0016_01_000284] is running beyond virtual memory limits. Current usage: 314.6 MB of 2.9 GB physical memory used; 8.7 GB of 6.2 GB virtual memory used. Killing container.
йЕНзљЃе¶ВдЄЛпЉЪ
йАЪињЗйЕНзљЃжИСдїђзЬЛеИ∞пЉМеЃєеЩ®зЪДжЬАе∞ПеЖЕе≠ШеТМжЬАе§ІеЖЕе≠ШеИЖеИЂдЄЇпЉЪ3000mеТМ10000mпЉМиАМreduceиЃЊзљЃзЪДйїШиЃ§еАЉе∞ПдЇО2000mпЉМmapж≤°жЬЙиЃЊзљЃпЉМжЙАдї•дЄ§дЄ™еАЉеЭЗдЄЇ3000mпЉМдєЯе∞±жШѓlogдЄ≠зЪДвАЬ2.9 GB physical¬†
memory usedвАЭгАВиАМзФ±дЇОдљњзФ®дЇЖйїШиЃ§иЩЪжЛЯеЖЕе≠ШзОЗ(дєЯе∞±жШѓ2.1еАН)пЉМжЙАдї•еѓєдЇОMap TaskеТМReduce TaskжАїзЪДиЩЪжЛЯеЖЕе≠ШдЄЇйГљдЄЇ3000*2.1=6.2GгАВиАМеЇФзФ®зЪДиЩЪжЛЯеЖЕе≠ШиґЕињЗдЇЖињЩдЄ™жХ∞еАЉпЉМжХЕжК•йФЩ гАВиІ£еЖ≥еКЮ
ж≥ХпЉЪеЬ®еРѓеК®YarnжШѓи∞ГиКВиЩЪжЛЯеЖЕе≠ШзОЗжИЦиАЕеЇФзФ®ињРи°МжЧґи∞ГиКВеЖЕе≠Ше§Іе∞ПгАВ
еЬ®дЄКYarnзЪДж°ЖжЮґзЃ°зРЖдЄ≠пЉМжЧ†иЃЇжШѓAMдїОRMзФ≥иѓЈиµДжЇРпЉМињШжШѓNMзЃ°зРЖиЗ™еЈ±жЙАеЬ®иКВзВєзЪДиµДжЇРпЉМйГљжШѓйАЪињЗcontainerињЫи°МзЪДгАВContainerжШѓYarnзЪДиµДжЇРжКљи±°пЉМж≠§е§ДзЪДиµДжЇРеМЕжЛђеЖЕе≠ШеТМcupз≠ЙгАВдЄЛйЭҐеѓє
containerпЉМињЫи°МжѓФиЊГиѓ¶зїЖзЪДдїЛзїНгАВдЄЇдЇЖжШѓе§ІеЃґеѓєcontainerжЬЙдЄ™жѓФиЊГ嚥豰зЪДиЃ§иѓЖпЉМй¶ЦеЕИзЬЛдЄЛеЫЊпЉЪ
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun;">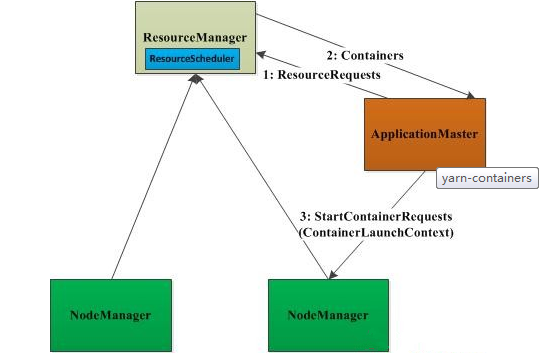  
 
дїОдЄКеЫЊдЄ≠жИСдїђеПѓдї•зЬЛеИ∞пЉМй¶ЦеЕИAMйАЪињЗиѓЈж±ВеМЕResourceRequestдїОRMзФ≥иѓЈиµДжЇРпЉМељУиОЈеПЦеИ∞иµДжЇРеРОпЉМAMеѓєеЕґињЫи°Ме∞Би£ЕпЉМе∞Би£ЕжИРContainerLaunchContextеѓєи±°пЉМйАЪињЗињЩдЄ™еѓєи±°пЉМAMдЄОNMињЫи°МйАЪиЃѓпЉМ
дї•дЊњеРѓеК®иѓ•дїїеК°гАВдЄЛйЭҐйАЪињЗResourceRequestгАБcontainerеТМContainerLaunchContextзЪДprotocol buffsеЃЪдєЙпЉМеѓєеЕґињЫи°МеЕЈдљУеИЖжЮРгАВ
ResourceRequestзїУжЮДе¶ВдЄЛпЉЪ
еѓєдЄКйЭҐзїУжЮДињЫи°МзЃАи¶БжМЙеЇПеПЈиѓіжШОпЉЪ
2пЉЪеЬ®жПРдЇ§зФ≥иѓЈжЧґпЉМжЬЯжЬЫдїОеУ™еП∞дЄїжЬЇдЄКиОЈеЊЧпЉМдљЖжЬАзїИињШжШѓAMдЄОRMеНПеХЖеЖ≥еЃЪпЉЫ
3пЉЪеП™еМЕеРЂдЄ§зІНиµДжЇРпЉМеН≥пЉЪеЖЕе≠ШеТМcpuпЉМзФ≥иѓЈжЦєеЉПпЉЪ<memory_num,cup_num>
ж≥®пЉЪ1гАБзФ±дЇО2дЄО4еєґж≤°жЬЙйЩРеИґиµДжЇРзФ≥иѓЈйЗПпЉМеИЩAPеЬ®иµДжЇРзФ≥иѓЈдЄКжШѓжЧ†йЩРзЪДгАВ2гАБYarnйЗЗзФ®и¶ЖзЫЦеЉПиµДжЇРзФ≥иѓЈжЦєеЉПпЉМеН≥пЉЪAMжѓПжђ°еПСеЗЇзЪДиµДжЇРиѓЈж±ВдЉЪи¶ЖзЫЦжОЙдєЛеЙНеЬ®еРМдЄАиКВзВєдЄФдЉШеЕИзЇІзЫЄеРМзЪДиµДжЇРиѓЈж±В,
дєЯе∞±жШѓиѓіеРМдЄАиКВзВєдЄ≠зЫЄеРМдЉШеЕИзЇІзЪДиµДжЇРиѓЈж±ВеП™иГљжЬЙдЄАдЄ™гАВ
containerзїУжЮДпЉЪ
ж≥®пЉЪжѓПдЄ™containerдЄАиИђеПѓдї•ињРи°МдЄАдЄ™дїїеК°пЉМељУAMжФґеИ∞е§ЪдЄ™containerжЧґпЉМе∞ЖињЫдЄАж≠•еИЖзїЩжЯРдЄ™дЇЇзЙ©гАВе¶ВпЉЪMapReduce
ContainerLaunchContextзїУжЮДпЉЪ
дЄЛйЭҐзїУеРИдЄАжЃµдї£з†БпЉМдїЕдї•ContainerLaunchContextдЄЇдЊЛињЫи°МжППињ∞(жЬђеЇФиѓ•еЖЩдЄ™зЃАеНХзЪДжЬЙйЩРзКґжАБжЬЇзЪДпЉМдЊњдЇОе§ІеЃґзРЖиІ£пЉМдљЖжЧґйЧідЄНжАОдєИеЕЕеИЖ)пЉЪ
 



зЫЄеЕ≥жО®иНР
дЄАдЄ™иЃ°зЃЧyarnеЖЕе≠ШйЕНзљЃзЪДpythonиДЪжЬђyarn-util.pyпЉМиѓ•иДЪжЬђжЬЙеЫЫдЄ™еПВжХ∞ еПВжХ∞ жППињ∞ -c CORES жѓПдЄ™иКВзВєCPUж†ЄжХ∞ -m MEMORY жѓПдЄ™иКВзВєеЖЕе≠ШжАїжХ∞пЉИеНХдљНGпЉЙ -d DISKS жѓПдЄ™иКВзВєзЪДз°ђзЫШдЄ™жХ∞ -k HBASE е¶ВжЮЬеЃЙи£ЕдЇЖHbaseеИЩдЄЇTrueпЉМ...
жЬђзѓЗе∞ЖжЈ±еЕ•жОҐиЃ®YARNеЖЕе≠ШеИЖйЕНзЪДзЃ°зРЖжЬЇеИґдї•еПКзЫЄеЕ≥еПВжХ∞йЕНзљЃгАВ й¶ЦеЕИпЉМYARNеЖЕе≠ШзЃ°зРЖжґЙеПКеИ∞дЄЙдЄ™дЄїи¶БиІТиЙ≤пЉЪResourceManagerпЉИRMпЉЙгАБApplicationMasterпЉИAMпЉЙеТМNodeManagerпЉИNMпЉЙгАВ 1. ResourceManagerпЉИRMпЉЙпЉЪRMжШѓеЕ®е±А...
### YARNеЖЕе≠ШдЄОCPUйЕНзљЃиѓ¶иІ£ #### дЄАгАБеЉХи®А Apache Hadoop YARNпЉИYet Another Resource NegotiatorпЉЙдљЬдЄЇжЦ∞дЄАдї£зЪДиµДжЇРзЃ°зРЖеТМдїїеК°и∞ГеЇ¶ж°ЖжЮґпЉМеЬ®е§ІжХ∞жНЃе§ДзРЖйҐЖеЯЯеН†жНЃзЭАйЗНи¶БзЪДеЬ∞дљНгАВYARNдЄНдїЕжФѓжМБеЖЕе≠ШиµДжЇРзЪДи∞ГеЇ¶пЉМињШжФѓжМБ...
иЃ°зЃЧyarnеЖЕе≠ШйЕНзљЃзЪДpythonиДЪжЬђyarn-util.pyпЉМж≠§иДЪжЬђжЬЙеЫЫдЄ™еПВжХ∞ еПВжХ∞ жППињ∞ -c CORES жѓПдЄ™иКВзВєCPUж†ЄжХ∞ -m MEMORY жѓПдЄ™иКВзВєеЖЕе≠ШжАїжХ∞пЉИеНХдљНGпЉЙ -d DISKS жѓПдЄ™иКВзВєзЪДз°ђзЫШдЄ™жХ∞ -k HBASE е¶ВжЮЬеЃЙи£ЕдЇЖHbaseеИЩдЄЇTrueпЉМеР¶еИЩдЄЇ...
ињЩйЗМжПРеИ∞зЪД"hadop yarnдЉШеМЦйЕНзљЃй°єзФЯжИРеЈ•еЕЈ"жШѓдЄАдЄ™еЃЮзФ®зЪДиДЪжЬђеЈ•еЕЈпЉМзФ®дЇОж†єжНЃзЙєеЃЪзЪДз°ђдїґзОѓеҐГеТМеЈ•дљЬиіЯиљљзФЯжИРдЉШеМЦзЪДYARNйЕНзљЃеПВжХ∞гАВињЩдЄ™еЈ•еЕЈеЯЇдЇОPythonзЉЦеЖЩпЉМеРНдЄЇ`yarn-utils.py`гАВ и¶БдљњзФ®ињЩдЄ™еЈ•еЕЈпЉМй¶ЦеЕИз°ЃдњЭдљ†зЪДз≥їзїЯ...
еЬ®жПРдЇ§SparkдїїеК°еЙНпЉМйЬАи¶БйЕНзљЃSparkзЪДзЫЄеЕ≥е±ЮжАІпЉМе¶В`spark.master`иЃЊзљЃдЄЇ`yarn-client`жИЦ`yarn-cluster`пЉМеЙНиАЕзФ®дЇОеЃҐжИЈзЂѓж®°еЉПпЉМеРОиАЕзФ®дЇОйЫЖзЊ§ж®°еЉПгАВж≠§е§ЦпЉМињШйЬАжМЗеЃЪHadoopзЪДйЕНзљЃзЫЃељХпЉМдЊЛе¶В`spark.yarn.conf.archive`гАВ ...
3. **йЕНзљЃyarn-site.xml**пЉЪдЄЇдЇЖйШ≤ж≠ҐYARNеЫ†еЖЕе≠ШйЩРеИґиАМзїИж≠ҐSparkдїїеК°пЉМжИСдїђйЬАи¶БеЬ®`yarn-site.xml`дЄ≠еПЦжґИеЖЕе≠Шж£АжЯ•гАВињЩеПѓдї•йАЪињЗиЃЊзљЃдЄ§дЄ™е±ЮжАІ`yarn.nodemanager.pmem-check-enabled`еТМ`yarn.nodemanager.vmem-check-...
еЬ®HadoopйЫЖзЊ§дЄ≠пЉМYARNпЉИYet Another Resource NegotiatorпЉЙдљЬдЄЇиµДжЇРзЃ°зРЖеЩ®пЉМиіЯиі£и∞ГеЇ¶MapReduceдїїеК°зЪДеЖЕе≠ШеТМCPUиµДжЇРгАВYARNжФѓжМБеЯЇдЇОеЖЕе≠ШеТМCPUзЪДдЄ§зІНиµДжЇРи∞ГеЇ¶з≠ЦзХ•пЉМдї•з°ЃдњЭйЫЖзЊ§иµДжЇРзЪДжЬЙжХИеИ©зФ®гАВеЬ®йЭЮйїШиЃ§йЕНзљЃдЄЛпЉМеРИзРЖеЬ∞...
жАїзїУжЭ•иѓіпЉМSpark on YARNзЪДExecutorеЖЕе≠ШзЃ°зРЖжШѓдЄАдЄ™е§НжЭВзЪДињЗз®ЛпЉМйЬАи¶БзїЉеРИиАГиЩСExecutorзЪДеЖЕе≠ШйЬАж±ВгАБYARNзЪДиµДжЇРйЕНзљЃдї•еПКSparkиЗ™иЇЂзЪДеЖЕе≠Шз≠ЦзХ•гАВж≠£з°ЃйЕНзљЃеТМдЉШеМЦињЩдЇЫеПВжХ∞еѓєдЇОз°ЃдњЭSparkеЇФзФ®зЪДз®≥еЃЪињРи°МиЗ≥еЕ≥йЗНи¶БгАВ
йЩ§дЇЖи∞ГжХіеЖЕе≠ШйЕНзљЃпЉМињШеПѓдї•дЉШеМЦдї£з†БпЉМеЗПе∞СеЖЕе≠ШжґИиАЧпЉМжИЦиАЕиАГиЩСдљњзФ®жЫійЂШжХИзЪДзЃЧж≥ХгАВ - `[YARN-20003]` йЫЖзЊ§иµДжЇРиґ≥е§ЯжЧґпЉМе§ІйЗПдїїеК°е§ДдЇО Accepted зКґжАБпЉЪињЩеПѓиГљжШѓзФ±дЇОи∞ГеЇ¶з≠ЦзХ•жИЦйШЯеИЧиЃЊзљЃйЧЃйҐШгАВж£АжЯ• RM зЪДи∞ГеЇ¶еЩ®йЕНзљЃпЉМе¶В...
ж≠§е§ЦпЉМдљ†ињШйЬАи¶БжОМжП°YARNзЪДйЕНзљЃпЉМе¶ВеЬ®`yarn-site.xml`дЄ≠иЃЊзљЃзЪДеПВжХ∞пЉМдї•еПКе¶ВдљХйАЪињЗеСљдї§и°МжО•еП£дЄОYARNдЇ§дЇТпЉМе¶ВжПРдЇ§еЇФзФ®з®ЛеЇПгАБжЯ•зЬЛеЇФзФ®з®ЛеЇПзКґжАБз≠ЙгАВеРМжЧґпЉМдЇЖиІ£YARNдЄОMapReduceгАБSparkз≠ЙиЃ°зЃЧж°ЖжЮґзЪДйЫЖжИРдєЯжШѓеЊИйЗНи¶БзЪДгАВ жАї...
йАЪињЗжЈ±еЕ•е≠¶дє†"YARNе≠¶дє†дє¶з±НеПКж≥®иІ£"пЉМиѓїиАЕеПѓдї•еЕ®йЭҐдЇЖиІ£YARNзЪДеЈ•дљЬеОЯзРЖпЉМжОМжП°е¶ВдљХйЕНзљЃеТМзЃ°зРЖYARNйЫЖзЊ§пЉМдї•еПКе¶ВдљХйТИеѓєзЙєеЃЪеЇФзФ®еЬЇжЩѓињЫи°МдЉШеМЦпЉМињЩеѓєдЇОдїОдЇЛе§ІжХ∞жНЃе§ДзРЖеТМеИЖжЮРзЪДеЈ•з®ЛеЄИжЭ•иѓіжШѓйЭЮеЄЄеЃЭиіµзЪДжКАиГљгАВ
- **еЃєеЩ®йЕНзљЃпЉЪ** еПѓдї•йАЪињЗйЕНзљЃжЦЗдїґжЭ•иЃЊзљЃеЃєеЩ®зЪДжЬАе§ІеЖЕе≠ШгАБCPU ж†ЄењГжХ∞з≠ЙеПВжХ∞гАВ **2. и∞ГеЇ¶з≠ЦзХ•йЕНзљЃпЉЪ** - **FIFO и∞ГеЇ¶еЩ®йЕНзљЃпЉЪ** иЃЊзљЃйїШиЃ§зЪДи∞ГеЇ¶з≠ЦзХ•дЄЇ FIFOгАВ - **еЃєйЗПи∞ГеЇ¶еЩ®йЕНзљЃпЉЪ** еЃЪдєЙйШЯеИЧеПКеЕґдЉШеЕИзЇІгАБжЬАе§ІиµДжЇР...
3. HadoopйЕНзљЃпЉЪз°ЃдњЭ`hadoop.conf.dir`зОѓеҐГеПШйЗПжМЗеРСдЇЖHadoopзЪДйЕНзљЃзЫЃељХпЉМињЩж†ЈSparkжЙНиГљжЙЊеИ∞YARNзЪДзЫЄеЕ≥йЕНзљЃгАВ еЫЫгАБжЙУеМЕеТМжПРдЇ§ 1. жЙУеМЕеЇФзФ®пЉЪдљњзФ®MavenжИЦGradleе∞ЖJavaй°єзЫЃжЙУеМЕжИРjarжЦЗдїґпЉМдЊЛе¶В`my-spark-job.jar`гАВ 2...
еЬ®MapReduceдљЬдЄЪдЄ≠пЉМеРИзРЖйЕНзљЃеПВжХ∞еѓєжПРеНЗдљЬдЄЪжАІиГљиЗ≥еЕ≥йЗНи¶БгАВдї•дЄЛжШѓдЄАдЇЫеЕ≥йФЃзЪДиЃЊзљЃеПВжХ∞пЉЪ - **mapreduce.map.sort.spill.percent**пЉЪжМЗеЃЪжЇҐеЖЩйШИеАЉпЉМеН≥дљХжЧґе∞ЖжХ∞жНЃдїОеЖЕе≠ШжЇҐеЖЩеИ∞з£БзЫШгАВ - **mapreduce.job.reduces**пЉЪ...
еЬ®зФЯдЇІзОѓеҐГдЄ≠пЉМSparkдїїеК°ињРи°МеЬ®YarnйЫЖзЊ§дЄКпЉМдЉЪеЫ†дЄЇиµДжЇРзЃ°зРЖдЄНељУжИЦиАЕйЕНзљЃйЧЃйҐШеѓЉиЗіSparkзЪДcontainer襀YarnзЃ°зРЖеЩ®killжОЙпЉМдїОиАМеЉХеПСдїїеК°йЗНиЈСзФЪиЗ≥жХідЄ™SparkдљЬдЄЪ姱賕гАВи¶БзРЖиІ£YarnдЄЇдљХдЉЪkill SparkзЪДcontainerпЉМй¶ЦеЕИйЬАи¶Б...
жЬђжЦЗе∞Жиѓ¶зїЖдїЛзїНе¶ВдљХеЬ®дЉ™еИЖеЄГеЉПзОѓеҐГдЄЛйЕНзљЃHadoopдЄОYARNпЉМеєґеРѓзФ®CgroupsжЭ•йЪФз¶їCPUиµДжЇРпЉМдї•еПКињЩдЄАйЕНзљЃеѓєиµДжЇРзЃ°зРЖзЪДеЕЈдљУељ±еУНгАВ #### дЇМгАБCgroupsзЃАдїЛ CgroupsжШѓLinuxеЖЕж†ЄжПРдЊЫзЪДдЄАдЄ™зЙєжАІпЉМеЃГеЕБиЃЄзФ®жИЈе∞ЖдЄАзїДињЫз®ЛзїДзїЗеИ∞...
жО•зЭАпЉМйЬАи¶БжЫіжЦ∞HadoopйЕНзљЃжЦЗдїґпЉИе¶В`yarn-site.xml`еТМ`core-site.xml`пЉЙпЉМйЕНзљЃYARNзЪДзЫЄеЕ≥еПВжХ∞пЉМе¶ВеЖЕе≠ШеТМCPUзЪДеИЖйЕНз≠ЦзХ•гАВжЬАеРОпЉМеРѓеК®YARNжЬНеК°пЉМз°ЃдњЭжЙАжЬЙиКВзВєйГљиГљж≠£еЄЄйАЪдњ°гАВ жАїдєЛпЉМJDK 1.8еТМYARN 1.22.10зЪДзїУеРИпЉМдЄЇеЯЇдЇО...
еЬ®дљњзФ®SparkжИЦFlinkеЬ®YarnдЄКињРи°МдїїеК°жЧґпЉМдЇЖиІ£еТМжОМжП°еЃєеЩ®гАБCgroupгАБYarnеЖЕе≠ШзЃ°зРЖжЬЇеИґпЉМеРИзРЖйЕНзљЃиµДжЇРпЉМжШѓз°ЃдњЭдїїеК°з®≥еЃЪињРи°МзЪДеЕ≥йФЃгАВйАЪињЗжЈ±еЕ•еИЖжЮРеТМи∞ГдЉШпЉМеПѓдї•жЬЙжХИиІ£еЖ≥еЫ†еЖЕе≠ШйЩРеИґеѓЉиЗізЪДдїїеК°дЄНз®≥еЃЪйЧЃйҐШгАВ