
问题导读:
1、统计总行数,理想的方式应该是怎样?
2、什么是Endpoint,怎样去实现它 ?
3、有哪几种方式去部署 ?![]()
前言:
如果要统对hbase中的数据,进行某种统计,比如统计某个字段最大值,统计满足某种条件的记录数,统计各种记录特点,并按照记录特点分类(类似于sql的group by)~
常规的做法就是把hbase中整个表的数据scan出来,或者稍微环保一点,加一个filter,进行一些初步的过滤(对于rowcounter来说,就加了FirstKeyOnlyFilter),但是这么做来说还是会有很大的副作用,比如占用大量的网络带宽(当标级别到达千万级别,亿级别之后)尤为明显,RPC的量也是不容小觑的。
理想的方式应该是怎样?
拿row counter这个简单例子来说,我要统计总行数,如果每个region 告诉我他又多少行,然后把结果告诉我,我再将他们的结果汇总一下,不就行了么?
现在的问题是hbase没有提供这种接口,来统计每个region的行数,那是否我们可以自己来实现一个呢?
没错,正如本文标题所说,我们可以自己来实现一个Endpoint,然后让hbase加载起来,然后我们远程调用即可。
什么是Endpoint?
先弄清楚什么是hbase coprocessor
hbase有两种coprocessor,一种是Observer(观察者),类似于关系数据库的trigger(触发器),另外一种就是EndPoint,类似于关系数据库的存储过程。
观察者这里就多做介绍了,这里介绍Endpoint。
EndPoint是动态RPC插件的接口,它的实现代码被部署在服务器端(regionServer),从而能够通过HBase RPC调用。客户端类库提供了非常方便的方法来调用这些动态接口,它们可以在任意时候调用一个EndPoint,它们的实现代码会被目标region远程执行,结果会返回到终端。用户可以结合使用这些强大的插件接口,为HBase添加全新的特性。
怎么实现一个EndPoint
1. 定义一个新的protocol接口,必须继承CoprocessorProtocol.
2. 实现终端接口,继承抽象类BaseEndpointCoprocessor,改实现代码需要部署到
3. 在客户端,终端可以被两个新的HBase Client API调用 。单个region:HTableInterface.coprocessorProxy(Class<T> protocol, byte[] row) 。rigons区域:HTableInterface.coprocessorExec(Class<T> protocol, byte[] startKey, byte[] endKey, Batch.Call<T,R> callable),这里的region是通过一个row来标示的,就是说,改row落到那个region,RPC就发给哪个region,对于start-end的,[start,end)范围内的region都会受到RPC调用。
如下图所示:
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14.3999996185303px; line-height: 16.7999992370605px;">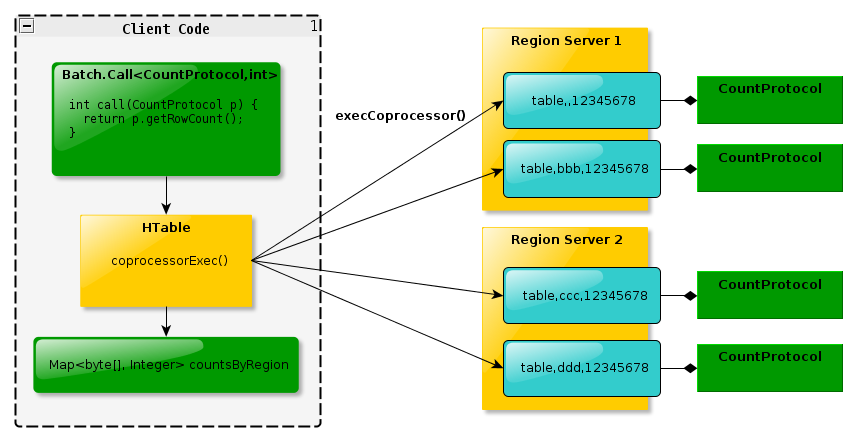
整个程序的框架其实又是另外一个mapreduce,只是运行在region server上面,reduce运行在客户端,其中map计算量较大,reduce计算量很小!
另外需要提醒的是:
protocol的返回类型,可以是基本类型。
如果是一个自定义的类型需要实现org.apache.hadoop.io.Writable接口。
关于详细的支持类型,请参考代码hbase源码:org.apache.hadoop.hbase.io.HbaseObjectWritable
怎么部署?
1. 通过hbase-site.xml增加
1、如果要配置多个,就用逗号(,)分割。
2、包含此类的jar必须位于hbase的classpath
3、这种coprocessor是作用于所有的表,如果你只想作用于部分表,请使用下面一种方式。
2、 通过shell方式
增加:
coprocessor格式为:
[FilePath]|ClassName|Priority|arguments
arguments: k=v[,k=v]+
其中FilePath是hdfs路径,例如/tmp/zhenhe/cp/zhenhe-1.0.jar
ClassNameEndPoint实现类的全名
Priority为,整数,框架会根据这个数据决定多个cp的执行顺序
Arguments,传给cp的参数
如果hbase的classpath包含改类,FilePath可以留空
卸载:
先describe “tableName‘,查看你要卸载的cp的编号
然后alter 't1', METHOD => 'table_att_unset', NAME=> 'coprocessor$3',coprocessor$3可变。
应用场景
这是一个最简单的例子,另外还有很多统计场景,可以用在这种方式实现,有如下好处:
节省网络带宽
减少RPC调用(scan的调用随着CacheSzie的变小而线性增加),减轻hbase压力
可以提高统计效率,那我之前写过的一个groupby类型的例子来说,大约可以提高50%以上的统计速度。
其他应用场景?
一个保存着用户信息的表,可以统计每个用户信息(counter job)
统计最大值,最小值,平均值,参考:官网
批量删除记录,批量删除某个时间戳的记录



相关推荐
2.高性能:HBase Coprocessor 可以提高 HBase 的性能,例如使用 Endpoint 机制可以实现高效的数据处理。 3.灵活的扩展:HBase Coprocessor 可以根据需要实现自定义的数据处理逻辑,例如二级索引、数据聚合等。 ...
### HBase Coprocessor 优化与实验 #### HBase及Coprocessor概述 HBase是一种非关系型、面向列的分布式数据库系统,它基于Hadoop之上构建,旨在为大规模数据提供高可靠、高性能的支持。HBase的核心优势在于其能够...
HBase Coprocessor 为 HBase 提供了极大的灵活性和可扩展性,通过 Endpoint 和 Observer 接口,不仅可以提高数据处理的效率,还能简化复杂的业务逻辑。无论是实现高效的聚合操作还是创建和维护二级索引,Coprocessor...
讲师:陈杨——快手大数据高级研发工程师 ...内容概要:(1)讲解hbase coprocessor的原理以及使用场景,(2) coprocessor整个流程实战,包括开发,加载,运行以及管理(3)结合1,2分析coprocessor在rsgroup中的具体使用
通过阅读“HBaseCoprocessor的实现与应用.pdf”,你可以更深入地了解如何利用Coprocessor来定制HBase的行为,提升系统效率,以及在实际项目中遇到的问题和解决方案。这份资料对于理解和掌握HBase的高级特性具有很高...
《深入理解HBase Coprocessor:扩展与应用》 HBase Coprocessor 是一个强大的功能,它为HBase提供了一种扩展机制,使得用户可以在不修改核心代码的情况下,实现对HBase的操作进行自定义处理。Coprocessor 分为...
在HBase中,Coprocessor机制是一个强大的特性,它允许用户在HBase服务器端自定义扩展功能,如数据过滤、统计计算、访问控制等。这个压缩包“hbase_coprocessor_hbase_coprocessorjava_源码”显然包含了用Java API...
1. **开发Coprocessor**:创建一个继承自HBase的Endpoint类,并实现相关接口,比如`BulkLoadEndpoint`,以处理批量数据同步。在`bulkLoadHFile`方法中,我们可以获取到写入HBase的数据,并将其发送到Elasticsearch。...
总的来说,HBase Coprocessor通过Endpoint机制实现了服务端的扩展,允许在RegionServer上执行用户定义的计算逻辑,优化了数据处理流程,降低了延迟,增强了系统的整体处理能力。这对于大数据场景下的实时分析和复杂...
通过这个实例,学习者可以深入了解HBase与MapReduce的整合过程,掌握如何利用MapReduce进行HBase数据的批处理,以及如何设计和优化MapReduce任务以提高处理效率。这对于大数据开发人员来说,是一份非常有价值的参考...
### HBase Coprocessor:深度解析与应用案例 #### 概览 HBase Coprocessor 是 HBase 的一个核心特性,允许用户在 RegionServer 上执行自定义代码,从而实现数据处理逻辑靠近数据存储的位置。这一特性极大地提高了...
hbase-solr-coprocessor 测试代码,目的是借助solr实现hbase二级索引,以使hbase支持高效的多条件查询。主要通过hbase的coprocessor的Observer实现,通过coprocessor在记录插入hbase时向solr中创建索引。 项目核心为...
### HBase原理及实例解析 #### 一、HBase概览与原理 HBase是Apache Hadoop项目下的一个子项目,它是一个分布式、版本化的非关系型列存储数据库,受到Google Bigtable论文的启发设计而成。HBase利用Hadoop ...
本文将通过一个具体的Eclipse工程实例,深入解析HBase与MapReduce的集成应用。 一、HBase简介 HBase是基于Google Bigtable设计的一个开源NoSQL数据库,运行在Hadoop之上。它提供了高可靠性和高性能的数据存储,特别...
HBase.Coprocessor优化与实验.pptx
### HBase备份与恢复技术详解 #### 一、引言 在大数据处理和分布式存储领域,HBase作为一款开源的、非关系型的分布式数据库,因其高性能和高可靠性而受到广泛青睐。但在实际应用过程中,如何高效地进行数据备份与...
本主题将深入探讨如何使用Java客户端API与HBase进行交互,包括集成Spring、MapReduce实例以及协处理器的使用。 首先,让我们从HBase的基础开始。HBase是构建在Hadoop文件系统(HDFS)之上的开源NoSQL数据库,它为非...
增量式的Apriori算法,有点像分布式的Apriori,因为我们可以把已挖掘的事务集和新增的事务集看作两个互相独立的数据集,挖掘新增的事务集,获取所有新增频繁集,然后与已有的频繁集做并集,对于两边都同时频繁的项集...
《HBase项目实例详解》 HBase,全称为Hadoop Database,是一款开源的分布式列式存储系统,基于Google的Bigtable设计思想构建,是Apache Hadoop生态中的重要组成部分。本资料将围绕一个具体的HBase项目实例,深入...
hbase 开发实例