一、简洁
Solr是一个开源的,企业级搜索服务器。她已经是一个成熟的产品,用于强化网络站点的搜索功能,包括内部局域网。
她是用Java语言编写。使用HTTP和XML进行数据传输,Java的掌握对于学习Solr不是必须的。除了能返回搜索
结果外,还有包括高亮搜索关键字,方位导航(已广泛用于电子商务网站),查询关键字拼写校验,自动查询建议
和 “类似”查询 帮助更好定位搜索。
二、Lucene,solr的基础引擎
在相信介绍Solr前,我们先从Apache Lucene开始,Solr的核心基础引擎。Lucene是一个开源的,高效的
文本搜索引擎。Lucene是由Doug Cutting在2000年开发的,并且伴随着强大的在线社区不断进化和成熟。
Lucene不是一个服务器,也不是一个网络爬虫。这一点非常重要,她没有任何配置文件。我们需要编写代码来
存贮和查询在磁盘上的索引。
下面是Lucene的一些主要特征:
- 通过建立基于文本的反向索引来快速查询文件。
- 通过丰富的文本分析器(analyzers),将字符串形式的文本信息转换为一系列terms,来联系索引和搜索。
- 一个查询分析器,还有很多能 支持从简单查询到模糊查询 的查询类型(query types)
- 一个听上去叫Information Retrieval(IR)的得分算法,以产生更多可能的候选结果,有很多灵活的方式来设置得分策略。
- 在上下文中高亮显示被找到的查询关键字
- 根据索引内容 来 检查 查询关键字拼写(更多关于查询关键字拼写 可以参考Lucene In Action)
三、Solr,是Lucene的服务器化产物
在对Lucene的了解后,Solr可以理解为Lucene的服务器化产品。但她不是对Lucene的一次简单封装,Solr的大多数特征都与Lucene不同。Solr 和 Lucene 的界限经常是模糊的。以下是Solr的主要特性:
- 通过HTTP请求来 建立索引和搜索索引
- 拥有数个缓存 来 加快搜索速度
- 一个基于web的管理员控制台
运行时做性能统计,包括缓存 命中/错过 率
查询表单 来 搜索索引。
以柱状图形式 展示 频繁被查询的关键字
详细的“得分计算和文本解析”分析。
通过配置XML 来添加和配置 Lucene的文本分析库
引入“搜索字段类型”的概念(这个非常重要,然而在Lucne中没有)。类型用作表示日期和一些特殊的排序问题。
- 对最终用户和应用成素,disjunction-max 查询处理器比Lucene基础查询器更实用。
- 查询结果的分类
- 拼写检查用于寻找搜索关键字 的类似词,优化查询建议
- “更类似于”插件用以列出 于查询结果类似的 备选结果。
- Solr支持分布式来应对较大规模的部署。
以上特征都会在下面的章节内详述。
四、Solr 于数据库技术的比较
对于开发人员而言,数据库技术(特别是关系数据库)已经成为一个必须学习的知识。数据库和Lucene的搜索索引并没有显著的不同。假设我们已经非常熟悉数据库知识,现在来描述下她和Lucene有什么不同。(这里来帮助更好了解Solr)
最大的不同是,Lucene可以理解为一个 只有一张简单表格
的数据库,没有任何的关系查询(即JOINS)。这听上去很疯狂,不过记住索引只是为了去支持搜索,而不是去标识一条数据。所以数据库可以去遵守“第三范
式”,而索引就不会如此,表格中尽可能多的包含会被搜索到的数据而已。用来补充单表的是,一个域(列)中可以有多值。
其他一些显著的不同:
- 更新(Update):整个文档可以被删除,然后再添加,但不能被更新。
- 子字符串搜索与文本搜索:例如“Books”,数据库的Like匹配出“CookBooks”、“MyBooks”。Lucene基于查询分析器
的配置,可以查到更多形式的词匹配“Books”,比如book(这里是大小写被忽略),甚至发音相似的词。运用ngram技术,她可以提取部分搜索条件
的词干进行匹配。
- 结果打分:Lucene的强大在于她可以根据结果的匹配程度来打分。例如查询条件中有部分是可选的(OR
search),那匹配程度高的文档会得到更多的分。有一些其他因素,可以调整打分的方式。然而,数据库就没有这个功能,只是匹配或不匹配。Lucene
也可以在需要的时候对结果进行排序。
- 延迟提交:Solr的搜索速度通过建立缓存得以优化。当一个完成的文档需要被提交,所有的缓存会重新构建,根据其他一些因素,这可能花费几秒到一分钟。
五、正式开始Solr
Solr是用Java编写的,不过我们不需要对Java非常了解。如果需要扩展Solr的功能,那我们需要了解Java。
我们需要掌握的是命令行操作,包括Dos和Unix。
在正式开始前,我们可能需要安装以下一些包:
Solr 发布包下的目录结构:
- client::包含特定的编程语言与Solr通信。这里其实只有Ruby的例子。Java的客户端在src/solrj
- dist:这里包含Solr的Jar包和War包
- example:这里有Jetty安装所需要的包(Solr自带Jetty),包括一些样本数据和Solr的配置文件。
example/etc:Jetty的配置文件。可以修改监听端口(默认8983)
example/multicore:多核环境下,solr的根目录(后面会具体讨论)
example/solr:默认环境下的solr根目录
example/webapps:Solr的WAR包部署在这里
- lib:所有Solr依赖的包。一大部分是Lucene,一些Apache常用的工具包,和Stax(XML处理相关)
- src:各种源码。可以归为以下几个重要目录:
src/java:Solr的源代码,用Java编写。
src/scripts:Unix的bash shell脚本,应用与在大型应用中部署多个Solr服务。
src/solrj:Solr Java的客户端。
src/webapp:Solr web端的管理员用户界面,包括Servlets和JSP。这些其实也都是War中的内容。
注意:要看Java源码的话,src/java下是主要的Solr源码;src/common下是一部分通用类,供server端和solrj客户端;src/test中是测试代码;src/webapp/src下是servlet代码;
六、Solr的根目录
Solr的根目录下包括Solr的配置和运行Solr实例需要的数据。
Sole有一个样例根目录,在example/solr下,我们将会使用这个
另一个更技术层面的,在example/solr下,也是Solr的一个根目录不过是用在多核的环境下,稍后讨论。
让我们来看下根目录下有些什么:
- bin:如果想自己设置Solr,这里可以放脚本。
- conf:配置文件。下面的2个文件很重要,这个文件夹下还包括一些其他文件,都是被这2个文件引用,为了一些其他配置,比如文本分析的细节。
conf/schema.xml:这里是索引的概要,包括 域类型(field type)定义和相关分析器链。
conf/sorconfig.xml:这是Solr配置的主文件。
conf/xslt:这个目录薄厚一些XSLT文件,用来把Solr搜索结果(XML)转换为其他形式,例如Atom/RSS。
- data:包含Lucene的索引数据,Solr自动生成。这些都是二进制数据(binary),我们基本不会去动它,除非需要删除。
- lib:一些额外的,可选的Java Jar包,Solr会在启动时调用。当你不是通过修改Solr源码 强化Solr的一些功能,可以将包放在这里。
七、Solr如何找到自己的根目录
Solr启动后的第一件事是从根目录加载配置信息。这可以通过好几种方式来指定。
- Solr先从Java的系统环境变量中搜寻 solr.solr.home这个变量。通常通过命令行设置,如启动Jetty时:java
-Dsolr.solr.home = solr/ -jar start .jar ;也可以用JNDI
绑定路径到java:comp/env/solr/home,可以设置web.xml来让app-server维护这个变量(src/web-app
/web/WEB-INF)
-
<
env-entry
>
-
<
env-entry-name
>
solr/home
</
env-entry-name
>
-
<
env-entry-value
>
solr/
</
env-entry-value
>
-
<
env-entry-type
>
java.lang.String
</
env-entry-type
>
-
</
env-entry
>
这里修改了web.xml,需要使用ant dist-war重新打包部署。这里仅仅如此还不够,需要设置JNDI,这里就不深入了。
PS:JNDI需要设置2个环境变量,具体查看EJB相关笔记。
- 如果根目录没有设置在环境变量或JNDI中,默认地址是 solr/。我们后面会沿用这个地址。(具体产品还是需要配置来设定,比较安全,可以使用绝对或相对路径)
设置完根路径后,在Solr启动中的log会显示:
Aug 7, 2008 4:59:35 PM org.apache.solr.core.Config getInstanceDir
INFO: Solr home defaulted to 'null' (could not find system property or JNDI)
Aug 7, 2008 4:59:35 PM org.apache.solr.core.Config setInstanceDir
INFO: Solr home set to 'solr/'
八、部署和运行Solr
部署就是apach-solr-1.4.war。这里不包含Solr的根目录。
这里我们以自带的Jetty为例子,进入example目录
cd example
java -jar start.jar
看到下面这句日志,即启动完成:
2010-07-09 15:31:06.377::INFO: Started SocketConnector @ 0.0.0.0:8983
在控制台点击Ctrl-C 可以关闭服务器。
0.0.0.0表示她监听来自任务主机的请求,8983是端口号。
此时,可以进入连接:http://localhost:8983/solr
,如果启动失败会显示原因,如果成功即可看到管理员入口(http://localhost:8983/solr/admin/
)。
九、简单浏览下Solr
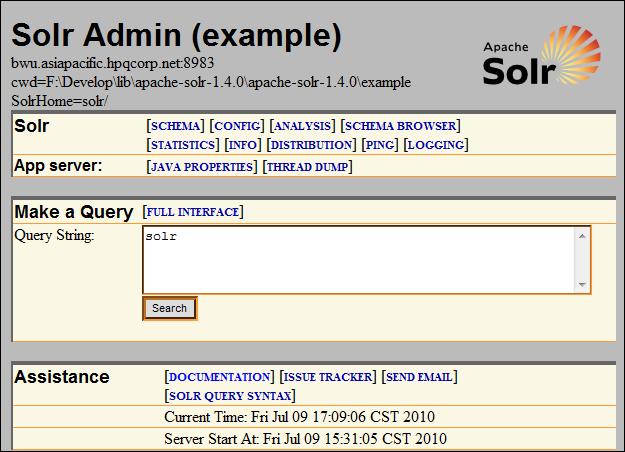
顶部灰色部分:
- 头部信息,当启动多个Solr实例时,可以帮助了解在操作哪个实例。IP地址和端口号都是可见的。
- example(Admin旁边)是对这个schema的引用,仅仅是标识这个schema。如果你有很多schema,可以用这个标识去区分。
- 当前工作目录(cwd) ,和Solr的根目录(SolrHome)。
导航栏上的功能:
- SCHEMA:显示当前的schema的配置文件。(不同浏览器显示可能不同,Firefox会高亮显示语法关键字)
- CONFIG:显示当前的Solr config文件。
- ANALYSIS:她用来诊断潜在的 文本分析 的查询/索引问题。这是高级功能,稍后做讨论。
- SCHEMA BROWSER:这是一个简洁的 反映当前索引中实际存放数据的 视图,稍后做讨论。
- STATISTICS:这里是 时间和缓存命中率统计。稍后做讨论。
- INFO:她列出了Solr当前应用组件的版本信息,不是很常用。
- DISTRIBUTION:这里包含了分布式/复制的状态信息,稍后讨论。
- PING:可以忽略,她用来在分布式模式下提供健壮性检查。
- LOGGING:可以在这里设置Solr不同部分的Logging levels。在Jetty下,输出的信息都在控制台。(Solr使用SLF4j)
- JAVA PROPERTIES:列出了JAVA系统环境变量。
- THREAD DUMP:这里显示了Java中的线程信息,帮助诊断问题。
- FULL INTERFACE:一个更多选择的查询表单,可以帮助诊断问题。这个表单也是能力有限的,只能提交一小部分搜索选项给Solr
Assistance 部分包括一些在线的帮助信息。
十、装在示例数据
Solr有一些示例数据和装载脚本,在example/exampledocs下。
进入example/exampledoce下,输入:
java -jar post.jar *.xml (如果在unix环境下,就运行post.sh)
post.jar是一个简单的程序,会遍历所有的参数(这里就是*.xml),然后对本机正运行的Solr(example)服务器的默认配置(http://localhost:8983/solr/update
) 发送post请求(HTTP)。这里可以看下post.sh,就可以了解在干什么了。
可以在控制台命令行中看到发送的文件:
SimplePostTool: POSTing files to http://localhost:8983/solr/update
..
SimplePostTool: POSTing file hd.xml
SimplePostTool: POSTing file ipod_other.xml
SimplePostTool: POSTing file ipod_video.xml
SimplePostTool: POSTing file mem.xml
SimplePostTool: POSTing file monitor.xml
SimplePostTool: POSTing file monitor2.xml
SimplePostTool: POSTing file mp500.xml
SimplePostTool: POSTing file payload.xml
SimplePostTool: POSTing file sd500.xml
SimplePostTool: POSTing file solr.xml
SimplePostTool: POSTing file utf8-example.xml
SimplePostTool: POSTing file vidcard.xml
SimplePostTool: COMMITting Solr index changes..
最后一行会执行commit操作,保证之前的文档都被保存,并可见。
理论上post.sh 和 post.jar是可以用在产品脚本上的,但这里仅仅用作示例。
这里取其中一个文件monitor.xml 看下:
-
<
add
>
-
<
doc
>
-
<
field
name
=
"id"
>
3007WFP
</
field
>
-
<
field
name
=
"name"
>
Dell Widescreen UltraSharp 3007WFP
</
field
>
-
<
field
name
=
"manu"
>
Dell, Inc.
</
field
>
-
<
field
name
=
"cat"
>
electronics
</
field
>
-
<
field
name
=
"cat"
>
monitor
</
field
>
-
<
field
name
=
"features"
>
30" TFT active matrix LCD, 2560 x 1600,
-
.25mm dot pitch, 700:1 contrast</
field
>
-
<
field
name
=
"includes"
>
USB cable
</
field
>
-
<
field
name
=
"weight"
>
401.6
</
field
>
-
<
field
name
=
"price"
>
2199
</
field
>
-
<
field
name
=
"popularity"
>
6
</
field
>
-
<
field
name
=
"inStock"
>
true
</
field
>
-
</
doc
>
-
</
add
>
这个发送给Solr的文件非常简单。这里只用了一些简单的标签,不过都是非常重要的。
<add>标签中可以放置多个<doc>标签(一个doc代表一个document),在大量数据装载时这样做能提高性能。
Solr在每个POST请求中都会收到一个<commit/>标签。更多的一些特性会在之后介绍。
十一、一次简单的搜索。
在管理员界面,让我们运行一次简单的搜索。
在管理员界面,点击查询按钮,或进入FULL INTERFACE再作更详细的查询。
在我们查看XML输出文件之前,先看下URL和参数信息:
http://localhost:8983/solr/select/?q=monitor&version=2.2&start=0&rows=10&indent=on
.
然后浏览器中会显示输出的用XML标识的搜索结果,如下:
-
<?
xml
version
=
"1.0"
encoding
=
"UTF-8"
?>
-
<
response
>
-
<
lst
name
=
"responseHeader"
>
-
<
int
name
=
"status"
>
0
</
int
>
-
<
int
name
=
"QTime"
>
3
</
int
>
-
<
lst
name
=
"params"
>
-
<
str
name
=
"indent"
>
on
</
str
>
-
<
str
name
=
"rows"
>
10
</
str
>
-
<
str
name
=
"start"
>
0
</
str
>
-
<
str
name
=
"q"
>
monitor
</
str
>
-
<
str
name
=
"version"
>
2.2
</
str
>
-
</
lst
>
-
</
lst
>
-
-
-
-
<
result
name
=
"response"
numFound
=
"2"
start
=
"0"
>
-
<
doc
>
-
<!--如果是full interface查询,这里会有得分情况(默认)
-
<
float
name
=
"score"
>
0.5747526
</
float
>
-
-->
-
<!--默认情况Solr会列出所有存储的fields
-
(不是所有field都需要存储,虽然可能根据它来查索引,但不用包含在就结果中)
-
-->
-
-
-
-
<
arr
name
=
"cat"
>
<
str
>
electronics
</
str
>
<
str
>
monitor
</
str
>
</
arr
>
-
<
arr
name
=
"features"
>
<
str
>
30" TFT active matrix LCD, 2560 x 1600,
-
.25mm dot pitch, 700:1 contrast</
str
>
</
arr
>
-
<
str
name
=
"id"
>
3007WFP
</
str
>
-
<
bool
name
=
"inStock"
>
true
</
bool
>
-
<
str
name
=
"includes"
>
USB cable
</
str
>
-
<
str
name
=
"manu"
>
Dell, Inc.
</
str
>
-
<
str
name
=
"name"
>
Dell Widescreen UltraSharp 3007WFP
</
str
>
-
<
int
name
=
"popularity"
>
6
</
int
>
-
<
float
name
=
"price"
>
2199.0
</
float
>
-
<
str
name
=
"sku"
>
3007WFP
</
str
>
-
<
arr
name
=
"spell"
>
<
str
>
Dell Widescreen UltraSharp 3007WFP
</
str
>
-
</
arr
>
-
<
date
name
=
"timestamp"
>
2008-08-09T03:56:41.487Z
</
date
>
-
<
float
name
=
"weight"
>
401.6
</
float
>
-
</
doc
>
-
<
doc
>
-
...
-
</
doc
>
-
</
result
>
-
</
response
>
这只是一个简单的查询结果,可以加入例如高亮显示等查询条件,然后在result标记后会有更多信息。
十二、一些统计信息
进入http://localhost:8983/solr/admin/stats.jsp
。
在这里,当我们没有加载任何数据时,numDocs显示0,而现在显示19。
maxDocs的值取决于当你删除一个文档但却没有提交。
可以关注以下的一些handler:
/update,standard。
注意:这些统计信息都是实时的,不在磁盘上做保存。
十三、solrconfig.xml
这里包含很多我们可以研究的参数,现在先让我们看下<requestHandler>下定义的 request handers。
-
<
requestHandler
name
=
"standard"
class
=
"solr.SearchHandler"
-
default
=
"true"
>
-
-
<
lst
name
=
"defaults"
>
-
-
<
str
name
=
"echoParams"
>
explicit
</
str
>
-
<!--
-
<
int
name
=
"rows"
>
10
</
int
>
-
<
str
name
=
"fl"
>
*
</
str
>
-
<
str
name
=
"version"
>
2.1
</
str
>
-
-->
-
</
lst
>
-
</
requestHandler
>
当我们通过POST通知Solr(如索引一个文档)或通过GET搜索,都会有个特定的request hander做处理。
这些handers可以通过URL来注册。之前我们加载文档时,Solr通过以下注册的handler做处理:
<requestHandler name="/update" class="solr.XmlUpdateRequestHandler" />
而当使用搜索时,是使用solr.SearchHandler(上面的XML定义了)
通过URL参数或POST中的参数,都可以调用这些request handler
也可以在solrconfig.xml中通过default,appends,invariants来指定。
这里的一些参数等于是默认的,就像已经放在了URL后面的参数一样。
十四、一些重要的Solr资源
十五、查询参数
fl=*,score&q.op=
AND
&start=0&
rows
=16&hl=
true
&hl.fl=merHeading&hl.snippets=3&hl.simple.pre=<font color=red>&hl.simple.post=</font>&facet=
true
&facet.field=merCategory&q=+(merHeading%3A%E4%BD%A0%E5%A5%BD+
AND
+merHeadingWithWord%3A%E6%BD%98 ) +merActualendTime:[1239264030468
TO
1240473630468]&sort=merActualendTime
asc
fl表示索引显示那些field(*表示所有field, score 是solr 的一个匹配热度)
q.op 表示q 中 查询语句的 各条件的逻辑操作 AND(与) OR(或)
start 开始返回条数
rows 返回多少条
hl 是否高亮
hl.fl 高亮field
hl.snippets 不太清楚(反正是设置高亮3就可以了)
hl.simple.pre 高亮前面的格式
hl.simple.post 高亮后面的格式
facet 是否启动统计
facet.field 统计field
q 查询语句(类似SQL) 相关详细的操作还需lucene 的query 语法
sort 排序
十六、删除索引
post "<delete><id>42</id></delete>"





相关推荐
**2.1 Solr基本概况** Solr是一个基于Lucene的全文搜索引擎,由Apache基金会维护,具有以下特点: - **开发语言**:Java - **功能**:提供丰富的查询语言和可配置性,支持索引和搜索性能优化。 - **架构**:可独立...
本资源摘要信息主要介绍了一份Java开发工程师的简历模板,涵盖了个人基本信息、教育经历、工作经历、技能概况、项目经验等方面。 基本信息 * 姓名、性别、出生年月、民族、籍贯、现居地、联系方式、电子邮件等个人...
Apache Ranger 是一个 Apache 项目,旨在提供集中式授权和审核解决方案,涵盖 Hadoop 组件,如 HDFS、Hive、HBase、Knox、Strom、YARN、Kafka、Solr 等。Ranger 提供了基于资源和资源分类的访问授权机制,能够对...
博客地址: : 如果你觉得这个项目不错,请为它点赞博客演示 运行环境JDK 7以上MavenMySQL 雷迪斯索尔七牛云(图片和视频都通过七牛云托管加速) Docker(可有可无)技术概况Spring && Spring Boot( ) Spring ...
* 软件架构:SpringMVC + Spring + MyBatis + Maven + CentOS + Solr + Redis + Nginx * 项目描述:开发在线购买平台,包括用户管理、商品管理、类目管理、客服管理、内容管理、用户意见管理等模块 * 责任描述:负责...
本资源是一份java开发工程师的个人简历,简历中展示了个人概况、工作经历、项目经验和技能等信息。以下是从中提取的知识点: 1. Java编程: * 熟悉Java编程语言,熟悉面向对象编程 * 熟悉Java相关的开源框架,如...
在Java个人博客系统中,开发者可能会使用诸如Spring Security进行权限管理,使用Elasticsearch或者Solr进行全文搜索,利用Maven或Gradle作为构建工具,以及使用Git进行版本控制。此外,系统可能还支持Markdown或富...
2. 学习信息通信技术领域的电子设备和系统工程概况,通过实习基地的现场指导。 3. 通过团队合作完成机器人控制和通信系统的案例,增强团队协作能力。 4. 设计和实现多任务系统,进行项目整合与联调。 5. 编写实习...