- жөҸи§Ҳ: 297794 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

ж–Үз« еҲҶзұ»
- е…ЁйғЁеҚҡе®ў (227)
- javascript (47)
- java (70)
- jquery (7)
- жӯЈеҲҷ (24)
- css (11)
- и®ҫи®ЎжЁЎејҸ (14)
- е…¶д»– (25)
- php (4)
- freemarker (4)
- ж–°жөӘеҫ®еҚҡжҺҘеҸЈ (1)
- phpcms (2)
- javaпјҢtomcat (1)
- Fckeditor (2)
- mysql (2)
- ж•°жҚ®еә“иЎЁи®ҫи®Ў (1)
- uploadify (1)
- jeecms (3)
- js (1)
- jboss (3)
- joomla (1)
- struts2 (2)
- з©әй—ҙ (1)
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 2)
еӯҳжЎЈеҲҶзұ»
- 2015-08 ( 1)
- 2015-01 ( 1)
- 2014-04 ( 2)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
е…Ёз«ҷе”ҜдёҖжҳҜжҲ‘д№Ҳпјҡ
иҜ·й—®дёӢиҜҘеҠҹиғҪзҡ„jdkзүҲжң¬жҳҜ1.4зҡ„д№ҲпјҢиҝҳжҳҜд»ҘдёҠзҡ„пјҹ
Javaе®һзҺ°з»ҷеӣҫзүҮж·»еҠ ж°ҙеҚ° -
Janneпјҡ
иҜ·й—®,дҪ и§ЈеҶіиҝҷй—®йўҳжІЎ?жҳҜжҖҺд№ҲеӣһдәӢ?жҲ‘д»ҠеӨ©д№ҹйҒҮеҲ°дәҶ,жІЎи§ЈеҶі
myeclipse6.5дёӯдҪҝз”Ёjax-wsеҗҜеҠЁtomcatжҠҘй”ҷй—®йўҳ -
xuedongпјҡ
studypi еҶҷйҒ“дҪ жҳҜжҖҺд№Ҳе’Ңж–°жөӘзҡ„жҠҖжңҜиҒ”зі»зҡ„пјҹиғҪе‘ҠиҜүдёҖдёӢжҲ‘еҗ— ...
ж–°жөӘеҫ®еҚҡ第дёүж–№жҺҘеҸЈи°ғз”ЁеӯҰд№ -
studypiпјҡ
дҪ жҳҜжҖҺд№Ҳе’Ңж–°жөӘзҡ„жҠҖжңҜиҒ”зі»зҡ„пјҹиғҪе‘ҠиҜүдёҖдёӢжҲ‘еҗ—пјҢи°ўи°ў
ж–°жөӘеҫ®еҚҡ第дёүж–№жҺҘеҸЈи°ғз”ЁеӯҰд№ -
dove19900520пјҡ
жңүз”ЁпјҢе‘өе‘ө
IE,FirefoxйғҪдёҚж”ҫејғпјҲе…је®№жҖ§й—®йўҳжҖ»з»“пјү
иҜҙжҳҺпјҡйғЁеҲҶеҶ…е®№жңүеҫ…иҝӣдёҖжӯҘз ”з©¶е’Ңдҝ®жӯЈпјҢеӣ дёәжңҖиҝ‘е·ҘдҪңеӨӘеҝҷпјҢжҡӮж—¶жҠҪдёҚеҮәж—¶й—ҙжқҘпјҢжңӘз ”з©¶иҝҮзҡ„еҸҜд»Ҙи·іиҝҮиҝҷдёҖзҜҮпјҢжғіз ”究зҡ„дёҚиҰҒиў«жҲ‘зҡ„жҖқи·ҜжүҖе·ҰеҸідәҶпјҢжңүз ”з©¶жё…жҘҡзҡ„иҝҳиҜ·жҢҮжӯЈ
1В В В В В В В й—®йўҳеј•еҮә
еүҚеҮ еӨ©еңЁCSDNи®әеқӣйҒҮеҲ°иҝҷж ·дёҖдёӘй—®йўҳпјҡ
var str="8912341253789";
йңҖиҰҒе°ҶиҝҷдёӘеӯ—з¬ҰдёІдёӯзҡ„йҮҚеӨҚзҡ„ж•°еӯ—з»ҷеҺ»жҺүпјҢд№ҹе°ұжҳҜз»“жһң89123457гҖӮ
йҰ–е…ҲйңҖиҰҒиҜҙжҳҺзҡ„жҳҜпјҢиҝҷз§ҚйңҖжұӮ并дёҚйҖӮеҗҲз”ЁжӯЈеҲҷжқҘе®һзҺ°пјҢиҮіе°‘пјҢжӯЈеҲҷдёҚжҳҜжңҖеҘҪзҡ„е®һзҺ°ж–№ејҸгҖӮ
иҝҷдёӘй—®йўҳжң¬иә«дёҚжҳҜжң¬ж–Үи®Ёи®әзҡ„йҮҚзӮ№пјҢжң¬ж–ҮжүҖиҰҒи®Ёи®әзҡ„пјҢдё»иҰҒжҳҜз”ұиҝҷдёҖй—®йўҳзҡ„и§ЈеҶіж–№жЎҲиҖҢеј•еҮәзҡ„еҸҰдёҖдёӘжӯЈеҲҷеҢ№й…ҚеҺҹзҗҶй—®йўҳгҖӮ
е…ҲзңӢдёҖдёӢй’ҲеҜ№иҝҷдёҖй—®йўҳжң¬иә«з»ҷеҮәзҡ„и§ЈеҶіж–№жЎҲгҖӮ
string str = "8912341253789";
Regex reg = new Regex(@"((/d)/d*?)/2");
while (str != (str = reg.Replace(str, "$1"))) { }
richTextBox2.Text = str;
/*--------иҫ“еҮә--------
89123457
*/
еҹәдәҺжӯӨжңүжңӢеҸӢжҸҗеҮәеҸҰдёҖдёӘз–‘й—®пјҢдёәд»Җд№ҲдҪҝз”ЁдёӢйқўзҡ„жӯЈеҲҷжІЎжңүж•Ҳжһң
вҖң(?<=(?<value>/d).*?)/k<value>вҖқ
з”ұжӯӨд№ҹеј•еҮәжң¬ж–ҮжүҖиҰҒи®Ёи®әзҡ„йҖҶеәҸзҺҜи§Ҷжӣҙж·ұе…Ҙзҡ„дёҖдәӣз»ҶиҠӮпјҢж¶үеҸҠеҲ°йҖҶеәҸзҺҜи§Ҷзҡ„еҢ№й…ҚеҺҹзҗҶе’ҢеҢ№й…ҚиҝҮзЁӢгҖӮеүҚйқўзҡ„дёӨзҜҮеҚҡе®ўдёӯиҷҪ然д№ҹжңүд»Ӣз»ҚпјҢдҪҶиҝҳдёҚеӨҹж·ұе…ҘпјҢеҸӮиҖғ жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”зҺҜи§Ҷ е’Ң жӯЈеҲҷеә”з”Ёд№ӢвҖ”вҖ”йҖҶеәҸзҺҜи§ҶжҺўзҙў гҖӮжң¬ж–Үе°Ҷд»ҘйҖҶеәҸзҺҜи§Ҷе’ҢеҸҚеҗ‘еј•з”Ёз»“еҗҲиҝҷз§ҚеӨҚжқӮеә”з”ЁеңәжҷҜпјҢеҜ№йҖҶеәҸзҺҜи§ҶиҝӣиЎҢж·ұе…ҘжҺўи®ЁгҖӮ
е…ҲжҠҠй—®йўҳз®ҖеҢ–е’ҢжҠҪиұЎдёҖдёӢпјҢдёҠйқўзҡ„жӯЈеҲҷдёӯз”ЁеҲ°дәҶе‘ҪеҗҚжҚ•иҺ·з»„е’Ңе‘ҪеҗҚжҚ•жҚүз»„зҡ„еҸҚеҗ‘еј•з”ЁпјҢиҝҷеңЁдёҖе®ҡзЁӢеәҰдёҠеўһеҠ дәҶй—®йўҳзҡ„еӨҚжқӮеәҰпјҢеҶҷжҲҗжҷ®йҖҡжҚ•иҺ·з»„пјҢ并且用вҖң/dвҖқд»ЈжӣҝиҢғеӣҙиҝҮеӨ§зҡ„вҖң.вҖқпјҢеҰӮдёӢ
вҖң(?<=(/d)/d*?)/1вҖқ
йңҖиҰҒеҢ№й…Қзҡ„еӯ—з¬ҰдёІпјҢжҠҪиұЎдёҖдёӢпјҢеҸ–дёӨз§Қе…ёеһӢеӯ—з¬ҰдёІеҰӮдёӢгҖӮ
жәҗеӯ—з¬ҰдёІдёҖпјҡ878
жәҗеӯ—з¬ҰдёІдәҢпјҡ9878
дёҺдёҠйқўжӯЈеҲҷиЎЁиҫҫејҸзұ»дјјпјҢжӯЈеҲҷиЎЁиҫҫејҸзӣёеә”зҡ„д№ҹжңүеӣӣз§ҚеҪўејҸ
жӯЈеҲҷиЎЁиҫҫејҸдёҖпјҡ(?<=(/d)/d*)/1
жӯЈеҲҷиЎЁиҫҫејҸдәҢпјҡ(?<=(/d)/d*?)/1
жӯЈеҲҷиЎЁиҫҫејҸдёүпјҡ(?<=(/d))/d*/1
жӯЈеҲҷиЎЁиҫҫејҸеӣӣпјҡ(?<=(/d))/d*?/1
е…ҲзңӢдёҖдёӢеҢ№й…Қз»“жһңпјҡ
string[] source = new string[] {"878", "9878" };
List<Regex> regs = new List<Regex>();
regs.Add(new Regex(@"(?<=(/d)/d*)/1"));
regs.Add(new Regex(@"(?<=(/d)/d*?)/1"));
regs.Add(new Regex(@"(?<=(/d))/d*/1"));
regs.Add(new Regex(@"(?<=(/d))/d*?/1"));
foreach (string s in source)
{
В В В В foreach (Regex r in regs)
В В В В {
В В В В В В В В В richTextBox2.Text += "жәҗеӯ—з¬ҰдёІпјҡ " + s.PadRight(8, ' ');
В В В В В В В В В richTextBox2.Text += "жӯЈеҲҷиЎЁиҫҫејҸпјҡ " + r.ToString().PadRight(18, ' ');
В В В В В В В В В richTextBox2.Text += "еҢ№й…Қз»“жһңпјҡ " + r.Match(s).Value + "/n------------------------/n";
В В В В }
В В В В richTextBox2.Text += "------------------------/n";
}
/*--------иҫ“еҮә--------
жәҗеӯ—з¬ҰдёІпјҡ 878В В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d)/d*)/1В В В еҢ№й…Қз»“жһңпјҡ 8
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 878В В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d)/d*?)/1В В еҢ№й…Қз»“жһңпјҡ
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 878В В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d))/d*/1В В В еҢ№й…Қз»“жһңпјҡ 78
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 878В В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d))/d*?/1В В еҢ№й…Қз»“жһңпјҡ 78
------------------------
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 9878В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d)/d*)/1В В В еҢ№й…Қз»“жһңпјҡ
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 9878В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d)/d*?)/1В В еҢ№й…Қз»“жһңпјҡ
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 9878В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d))/d*/1В В В еҢ№й…Қз»“жһңпјҡ 78
------------------------
жәҗеӯ—з¬ҰдёІпјҡ 9878В В В жӯЈеҲҷиЎЁиҫҫејҸпјҡ (?<=(/d))/d*?/1В В еҢ№й…Қз»“жһңпјҡ 78
------------------------
------------------------
*/
иҝҷдёӘз»“жһңд№ҹи®ёдјҡеҮәд№ҺеҫҲеӨҡдәәзҡ„ж„Ҹж–ҷд№ӢеӨ–пјҢеҲҡејҖе§ӢжҺҘи§ҰиҝҷдёӘй—®йўҳж—¶пјҢжҲ‘д№ҹдёҖж ·ж„ҹеҲ°иҝ·жғ‘пјҢж”ҫдәҶдёӨеӨ©еҗҺпјҢжүҚзҒөжңәдёҖи§ҰпјҢжғійҖҡдәҶй—®йўҳзҡ„е…ій”®жүҖеңЁпјҢдёӢйқўе°Ҷеұ•ејҖи®Ёи®әгҖӮ
еңЁжӯӨд№ӢеүҚпјҢеҸҜиғҪиҝҳйңҖиҰҒеҒҡдёӨзӮ№иҜҙжҳҺпјҡ
1гҖҒВ дёӢйқўи®Ёи®әзҡ„иҜқйўҳе·Із»ҸдёҺжң¬ж–ҮејҖе§ӢжҸҗеҲ°зҡ„й—®йўҳжІЎжңүеӨҡеӨ§е…іиҒ”дәҶпјҢжңҖеҲқзҡ„й—®йўҳдё»иҰҒжҳҜдёәдәҶеј•еҮәжң¬ж–Үзҡ„иҜқйўҳпјҢй—®йўҳжң¬иә«дёҚеңЁи®Ёи®әиҢғеӣҙд№ӢеҶ…пјҢиҖҢжң¬ж–Үд№ҹдё»иҰҒжҳҜзәҜзҗҶи®әзҡ„жҺўи®ЁгҖӮ
2гҖҒВ жң¬ж–ҮйҖӮеҗҲжңүдёҖе®ҡжӯЈеҲҷеҹәзЎҖзҡ„иҜ»иҖ…гҖӮеҰӮжһңжӮЁеҜ№дёҠйқўеҮ дёӘжӯЈеҲҷзҡ„еҢ№й…Қз»“жһңе’ҢеҢ№й…ҚиҝҮзЁӢж„ҹеҲ°иҙ№и§ЈпјҢжІЎе…ізі»пјҢдёӢйқўе°ұе°ҶдёәжӮЁи§Јжғ‘пјӣдҪҶжҳҜеҰӮжһңжӮЁеҜ№дёҠйқўеҮ дёӘжӯЈеҲҷдёӯе…ғеӯ—з¬Ұе’ҢиҜӯжі•д»ЈиЎЁзҡ„ж„Ҹд№үйғҪдёҚжё…жҘҡзҡ„иҜқпјҢиҝҳжҳҜе…Ҳд»ҺеҹәзЎҖзңӢиө·еҗ§гҖӮ
2В В В В В В йҖҶеәҸзҺҜи§ҶеҢ№й…ҚеҺҹзҗҶж·ұе…Ҙ
жӯЈеҲҷиЎЁиҫҫејҸдёҖпјҡ(?<=(/d)/d*)/1
жӯЈеҲҷиЎЁиҫҫејҸдәҢпјҡ(?<=(/d)/d*?)/1
жӯЈеҲҷиЎЁиҫҫејҸдёүпјҡ(?<=(/d))/d*/1
жӯЈеҲҷиЎЁиҫҫејҸеӣӣпјҡ(?<=(/d))/d*?/1
дёҠйқўзҡ„еҮ дёӘжӯЈеҲҷиЎЁиҫҫејҸпјҢеҸҜд»ҘжңҖз»ҲжҠҪиұЎдёәвҖң(?<=SubExp1)SubExp2вҖқиҝҷж ·зҡ„иЎЁиҫҫејҸпјҢеңЁеҒҡйҖҶеәҸзҺҜи§ҶеҺҹзҗҶеҲҶжһҗж—¶пјҢж №жҚ®вҖңSubExp1вҖқзҡ„зү№зӮ№пјҢеҸҜд»ҘеҪ’зәідёәдёүзұ»пјҡ
1гҖҒВ йҖҶеәҸзҺҜи§Ҷдёӯзҡ„еӯҗиЎЁиҫҫејҸвҖңSubExp1вҖқй•ҝеәҰеӣәе®ҡпјҢжӯЈеҲҷиЎЁиҫҫејҸдёүе’ҢеӣӣеұһдәҺиҝҷдёҖзұ»пјҢеҪ“然пјҢиҝҷдёҖзұ»йҮҢжҳҜеҢ…жӢ¬вҖң?вҖқиҝҷдёҖйҮҸиҜҚзҡ„пјҢдҪҶд№ҹд»…йҷҗдәҺиҝҷдёҖдёӘйҮҸиҜҚгҖӮ
2гҖҒВ йҖҶеәҸзҺҜи§Ҷдёӯзҡ„еӯҗиЎЁиҫҫејҸвҖңSubExp1вҖқй•ҝеәҰдёҚеӣәе®ҡпјҢе…¶дёӯеҢ…еҗ«еҝҪз•Ҙдјҳе…ҲйҮҸиҜҚпјҢеҰӮвҖң*?вҖқгҖҒвҖң+?вҖқгҖҒвҖң{m,}?вҖқзӯүпјҢд№ҹе°ұжҳҜйҖҡеёёжүҖиҜҙзҡ„йқһиҙӘе©ӘжЁЎејҸпјҢжӯЈеҲҷиЎЁиҫҫејҸдәҢеұһдәҺиҝҷдёҖзұ»гҖӮ
3гҖҒВ йҖҶеәҸзҺҜи§Ҷдёӯзҡ„еӯҗиЎЁиҫҫејҸвҖңSubExp1вҖқй•ҝеәҰдёҚеӣәе®ҡпјҢе…¶дёӯеҢ…еҗ«еҢ№й…Қдјҳе…ҲйҮҸиҜҚпјҢвҖң*вҖқгҖҒвҖң+вҖқгҖҒвҖң{m,}вҖқзӯүпјҢд№ҹе°ұжҳҜйҖҡеёёжүҖиҜҙзҡ„иҙӘе©ӘжЁЎејҸпјҢжӯЈеҲҷиЎЁиҫҫејҸдёҖеұһдәҺиҝҷдёҖзұ»гҖӮ
дёӢйқўй’ҲеҜ№иҝҷдёүзұ»жӯЈеҲҷиЎЁиҫҫејҸиҝӣиЎҢеҢ№й…ҚиҝҮзЁӢзҡ„еҲҶжһҗгҖӮ
2.1В В В В еӣәе®ҡй•ҝеәҰеӯҗиЎЁиҫҫејҸеҢ№й…ҚиҝҮзЁӢеҲҶжһҗ
2.1.1В жәҗеӯ—з¬ҰдёІдёҖ + жӯЈеҲҷиЎЁиҫҫејҸдёүеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдёҖпјҡ878
жӯЈеҲҷиЎЁиҫҫејҸдёүпјҡ(?<=(/d))/d*/1
йҰ–е…ҲеңЁдҪҚзҪ®0еӨ„ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖң(?<=(/d))вҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢй•ҝеәҰеӣәе®ҡпјҢеҸӘжңүдёҖдҪҚпјҢз”ұдҪҚзҪ®0еӨ„еҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢеӨұиҙҘпјҢвҖң(?<=(/d))вҖқеҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙ第дёҖиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®1еӨ„е°қиҜ•еҢ№й…ҚпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң(?<=(/d))вҖқпјҢеҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢжҺҘзқҖе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң(/d)вҖқпјҢжӣҙиҝӣдёҖжӯҘзҡ„е°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/dвҖқгҖӮвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеҢ№й…ҚвҖң8вҖқжҲҗеҠҹпјҢжӯӨж—¶вҖң(?<=(/d))вҖқеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жһңдёәдҪҚзҪ®1пјҢжҚ•иҺ·з»„1еҢ№й…ҚеҲ°зҡ„еҶ…е®№е°ұжҳҜвҖң8вҖқпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*вҖқгҖӮз”ұдәҺвҖң/d*вҖқдёәиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҢ№й…ҚдҪҚзҪ®1еҗҺйқўзҡ„вҖң7вҖқе’ҢвҖң8вҖқпјҢеҢ№й…ҚжҲҗеҠҹпјҢи®°еҪ•еӣһжәҜзҠ¶жҖҒпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң/1вҖқгҖӮз”ұдәҺеүҚйқўжҚ•иҺ·з»„1жҚ•иҺ·еҲ°зҡ„еҶ…е®№жҳҜвҖң8вҖқпјҢжүҖд»ҘвҖң/1вҖқиҰҒеҢ№й…ҚеҲ°вҖң8вҖқжүҚиғҪеҢ№й…ҚжҲҗеҠҹпјҢиҖҢжӯӨж—¶е·ІеҲ°иҫҫеӯ—з¬ҰдёІз»“е°ҫеӨ„пјҢеҢ№й…ҚеӨұиҙҘпјҢвҖң/d*вҖқеӣһжәҜпјҢи®©еҮәжңҖеҗҺзҡ„еӯ—з¬ҰвҖң8вҖқпјҢеҶҚе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/1вҖқпјҢ з”ұвҖң/1вҖқеҢ№й…ҚжңҖеҗҺзҡ„вҖң8вҖқжҲҗеҠҹпјҢжӯӨж—¶ж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚжҲҗеҠҹгҖӮз”ұдәҺвҖң(?<=(/d))вҖқеҸӘеҢ№й…ҚдҪҚзҪ®пјҢдёҚеҚ жңүеӯ—з¬ҰпјҢжүҖд»Ҙж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеҲ°зҡ„з»“жһңдёәвҖң78вҖқпјҢе…¶дёӯвҖң/d*вҖқеҢ№й…ҚеҲ°зҡ„жҳҜвҖң7вҖқпјҢвҖң/1вҖқеҢ№й…ҚеҲ°зҡ„жҳҜвҖң8вҖқгҖӮ
2.1.2В жәҗеӯ—з¬ҰдёІдәҢ + жӯЈеҲҷиЎЁиҫҫејҸдёүеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдәҢпјҡ9878
жӯЈеҲҷиЎЁиҫҫејҸдёүпјҡ(?<=(/d))/d*/1
иҝҷдёҖз»„еҗҲзҡ„еҢ№й…ҚиҝҮзЁӢпјҢдёҺ2.1.1иҠӮзҡ„еҢ№й…ҚиҝҮзЁӢеҹәжң¬зұ»дјјпјҢеҸӘдёҚиҝҮеӨҡдәҶдёҖиҪ®еҢ№й…Қе°қиҜ•иҖҢе·ІпјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°гҖӮ
2.1.3В жәҗеӯ—з¬ҰдёІдёҖ + жӯЈеҲҷиЎЁиҫҫејҸеӣӣеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдёҖпјҡ878
жӯЈеҲҷиЎЁиҫҫејҸеӣӣпјҡ(?<=(/d))/d*?/1
йҰ–е…ҲеңЁдҪҚзҪ®0еӨ„ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖң(?<=(/d))вҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢй•ҝеәҰеӣәе®ҡпјҢеҸӘжңүдёҖдҪҚпјҢз”ұдҪҚзҪ®0еӨ„еҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢеӨұиҙҘпјҢвҖң(?<=(/d))вҖқеҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙ第дёҖиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®1еӨ„е°қиҜ•еҢ№й…ҚпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң(?<=(/d))вҖқпјҢеҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢжҺҘзқҖе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң(/d)вҖқпјҢжӣҙиҝӣдёҖжӯҘзҡ„е°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/dвҖқгҖӮвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеҢ№й…ҚвҖң8вҖқжҲҗеҠҹпјҢжӯӨж—¶вҖң(?<=(/d))вҖқеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жҳҜжһңдёәдҪҚзҪ®1пјҢжҚ•иҺ·з»„1еҢ№й…ҚеҲ°зҡ„еҶ…е®№е°ұжҳҜвҖң8вҖқпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*?вҖқгҖӮз”ұдәҺвҖң/d*?вҖқдёәйқһиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҝҪз•ҘеҢ№й…ҚпјҢи®°еҪ•еӣһжәҜзҠ¶жҖҒпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң/1вҖқгҖӮз”ұдәҺеүҚйқўжҚ•иҺ·з»„1жҚ•иҺ·еҲ°зҡ„еҶ…е®№жҳҜвҖң8вҖқпјҢжүҖд»ҘвҖң/1вҖқиҰҒеҢ№й…ҚеҲ°вҖң8вҖқжүҚиғҪеҢ№й…ҚжҲҗеҠҹпјҢиҖҢжӯӨж—¶дҪҚзҪ®1еҗҺйқўзҡ„еӯ—з¬ҰжҳҜвҖң7вҖқпјҢеҢ№й…ҚеӨұиҙҘпјҢвҖң/d*?вҖқеӣһжәҜпјҢе°қиҜ•еҢ№й…ҚдҪҚзҪ®1еҗҺйқўзҡ„еӯ—з¬ҰвҖң7вҖқпјҢеҶҚе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/1вҖқпјҢ з”ұвҖң/1вҖқеҢ№й…ҚжңҖеҗҺзҡ„вҖң8вҖқжҲҗеҠҹпјҢжӯӨж—¶ж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚжҲҗеҠҹгҖӮз”ұдәҺвҖң(?<=(/d))вҖқеҸӘеҢ№й…ҚдҪҚзҪ®пјҢдёҚеҚ жңүеӯ—з¬ҰпјҢжүҖд»Ҙж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеҲ°зҡ„з»“жһңдёәвҖң78вҖқпјҢе…¶дёӯвҖң/d*?вҖқеҢ№й…ҚеҲ°зҡ„жҳҜвҖң7вҖқпјҢвҖң/1вҖқеҢ№й…ҚеҲ°зҡ„жҳҜжңҖеҗҺзҡ„вҖң8вҖқгҖӮ
иҝҷдёҺ2.1.1иҠӮз»„еҗҲзҡ„еҢ№й…ҚиҝҮзЁӢеҹәжң¬дёҖиҮҙпјҢеҸӘдёҚиҝҮе°ұжҳҜвҖң/d*вҖқе’ҢвҖң/d*?вҖқеҢ№й…ҚдёҺеӣһжәҜиҝҮзЁӢжңүжүҖеҢәеҲ«иҖҢе·ІгҖӮ
2.1.4В жәҗеӯ—з¬ҰдёІдәҢ + жӯЈеҲҷиЎЁиҫҫејҸеӣӣеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдәҢпјҡ9878
жӯЈеҲҷиЎЁиҫҫејҸеӣӣпјҡ(?<=(/d))/d*?/1
иҝҷдёҖз»„еҗҲзҡ„еҢ№й…ҚиҝҮзЁӢпјҢдёҺ2.1.3иҠӮзҡ„еҢ№й…ҚиҝҮзЁӢеҹәжң¬зұ»дјјпјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°гҖӮ
2.2В В В В йқһиҙӘе©ӘжЁЎејҸеӯҗиЎЁиҫҫејҸеҢ№й…ҚиҝҮзЁӢеҲҶжһҗ
2.2.1В жәҗеӯ—з¬ҰдёІдёҖ + жӯЈеҲҷиЎЁиҫҫејҸдәҢеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдёҖпјҡ878
жӯЈеҲҷиЎЁиҫҫејҸдәҢпјҡ(?<=(/d)/d*?)/1
йҰ–е…ҲеңЁдҪҚзҪ®0еӨ„ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖң(?<=(/d)/d*?)вҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢй•ҝеәҰдёҚеӣәе®ҡпјҢиҮіе°‘дёҖдҪҚпјҢз”ұдҪҚзҪ®0еӨ„еҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢеӨұиҙҘпјҢвҖң(?<=(/d)/d*?)вҖқеҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙ第дёҖиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®1еӨ„е°қиҜ•еҢ№й…ҚпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң(?<=(/d)/d*?)вҖқпјҢеҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢжҺҘзқҖе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң(/d)вҖқпјҢжӣҙиҝӣдёҖжӯҘзҡ„е°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/dвҖқгҖӮвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеҢ№й…ҚвҖң8вҖқжҲҗеҠҹпјҢе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*?вҖқпјҢз”ұдәҺвҖң/d*?вҖқдёәйқһиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҝҪз•ҘеҢ№й…ҚпјҢеҚідёҚеҢ№й…Қд»»дҪ•еҶ…е®№пјҢ并记еҪ•еӣһжәҜзҠ¶жҖҒпјҢжӯӨж—¶вҖң(/d)/d*?вҖқеҢ№й…ҚжҲҗеҠҹпјҢйӮЈд№ҲвҖң(?<=(/d)/d*?)вҖқд№ҹе°ұеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жһңдёәдҪҚзҪ®1пјҢз”ұдәҺжӯӨеӨ„зҡ„еӯҗиЎЁиҫҫејҸвҖң(/d)/d*?вҖқдёәйқһиҙӘе©ӘжЁЎејҸпјҢеҸ–еҫ—дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№еҗҺпјҢеҚідәӨеҮәжҺ§еҲ¶жқғпјҢеҗҢж—¶дёўејғжүҖжңүеӣһжәҜзҠ¶жҖҒгҖӮз”ұдәҺеүҚйқўжҚ•иҺ·з»„1жҚ•иҺ·еҲ°зҡ„еҶ…е®№жҳҜвҖң8вҖқпјҢжүҖд»ҘвҖң/1вҖқиҰҒеҢ№й…ҚеҲ°вҖң8вҖқжүҚиғҪеҢ№й…ҚжҲҗеҠҹпјҢиҖҢжӯӨж—¶дҪҚзҪ®1еҗҺйқўзҡ„еӯ—з¬ҰжҳҜвҖң7вҖқпјҢжӯӨж—¶е·Іж— еҸҜдҫӣеӣһжәҜзҡ„зҠ¶жҖҒпјҢж•ҙдёӘиЎЁиҫҫејҸеңЁдҪҚзҪ®1еӨ„еҢ№й…ҚеӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®2еӨ„е°қиҜ•еҢ№й…ҚпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң(?<=(/d)/d*?)вҖқпјҢеҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢжҺҘзқҖе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң(/d)вҖқпјҢжӣҙиҝӣдёҖжӯҘзҡ„е°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/dвҖқгҖӮвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеҢ№й…ҚвҖң7вҖқжҲҗеҠҹпјҢе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*?вҖқпјҢз”ұдәҺвҖң/d*?вҖқдёәйқһиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҝҪз•ҘеҢ№й…ҚпјҢеҚідёҚеҢ№й…Қд»»дҪ•еҶ…е®№пјҢ并记еҪ•еӣһжәҜзҠ¶жҖҒпјҢжӯӨж—¶вҖң(/d)/d*?вҖқеҢ№й…ҚжҲҗеҠҹпјҢйӮЈд№ҲвҖң(?<=(/d)/d*?)вҖқд№ҹе°ұеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жһңдёәдҪҚзҪ®2пјҢз”ұдәҺжӯӨеӨ„зҡ„еӯҗиЎЁиҫҫејҸвҖң(/d)/d*?вҖқдёәйқһиҙӘе©ӘжЁЎејҸпјҢеҸ–еҫ—дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№еҗҺпјҢеҚідәӨеҮәжҺ§еҲ¶жқғпјҢеҗҢж—¶дёўејғжүҖжңүеӣһжәҜзҠ¶жҖҒгҖӮз”ұдәҺеүҚйқўжҚ•иҺ·з»„1жҚ•иҺ·еҲ°зҡ„еҶ…е®№жҳҜвҖң7вҖқпјҢжүҖд»ҘвҖң/1вҖқиҰҒеҢ№й…ҚеҲ°вҖң7вҖқжүҚиғҪеҢ№й…ҚжҲҗеҠҹпјҢиҖҢжӯӨж—¶дҪҚзҪ®2еҗҺйқўзҡ„еӯ—з¬ҰжҳҜвҖң7вҖқпјҢжӯӨж—¶е·Іж— еҸҜдҫӣеӣһжәҜзҡ„зҠ¶жҖҒпјҢж•ҙдёӘиЎЁиҫҫејҸеңЁдҪҚзҪ®2еӨ„еҢ№й…ҚеӨұиҙҘгҖӮ
дҪҚзҪ®3еӨ„зҡ„еҢ№й…ҚиҝҮзЁӢд№ҹеҗҢж ·йҒ“зҗҶпјҢжңҖеҗҺвҖң/1вҖқеӣ ж— еӯ—з¬ҰеҸҜеҢ№й…ҚпјҢеҜјиҮҙж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеӨұиҙҘгҖӮ
жӯӨж—¶е·Іе°қиҜ•дәҶеӯ—з¬ҰдёІжүҖжңүдҪҚзҪ®пјҢеқҮеҢ№й…ҚеӨұиҙҘпјҢжүҖд»Ҙж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеӨұиҙҘпјҢжңӘеҸ–еҫ—д»»дҪ•жңүж•ҲеҢ№й…Қз»“жһңгҖӮ
2.2.2В жәҗеӯ—з¬ҰдёІдәҢ + жӯЈеҲҷиЎЁиҫҫејҸдәҢеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдёҖпјҡ9878
жӯЈеҲҷиЎЁиҫҫејҸдәҢпјҡ(?<=(/d)/d*?)/1
иҝҷдёҖз»„еҗҲзҡ„еҢ№й…ҚиҝҮзЁӢпјҢдёҺ2.2.1иҠӮзҡ„еҢ№й…ҚиҝҮзЁӢеҹәжң¬зұ»дјјпјҢиҝҷйҮҢдёҚеҶҚиөҳиҝ°гҖӮ
2.3В В В В иҙӘе©ӘжЁЎејҸеӯҗиЎЁиҫҫејҸеҢ№й…ҚиҝҮзЁӢеҲҶжһҗ
2.3.1В жәҗеӯ—з¬ҰдёІдёҖ + жӯЈеҲҷиЎЁиҫҫејҸдёҖеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдёҖпјҡ878
жӯЈеҲҷиЎЁиҫҫејҸдәҢпјҡ(?<=(/d)/d*)/1
йҰ–е…ҲеңЁдҪҚзҪ®0еӨ„ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖң(?<=(/d)/d*)вҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢй•ҝеәҰдёҚеӣәе®ҡпјҢиҮіе°‘дёҖдҪҚпјҢз”ұдҪҚзҪ®0еӨ„еҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢеӨұиҙҘпјҢвҖң(?<=(/d)/d*)вҖқеҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙ第дёҖиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®1еӨ„е°қиҜ•еҢ№й…ҚпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң(?<=(/d)/d*)вҖқпјҢеҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢжҺҘзқҖе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң(/d)вҖқпјҢжӣҙиҝӣдёҖжӯҘзҡ„е°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/dвҖқгҖӮвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеҢ№й…ҚвҖң8вҖқжҲҗеҠҹпјҢе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*вҖқпјҢз”ұдәҺвҖң/d*вҖқдёәиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҢ№й…ҚпјҢ并记еҪ•еӣһжәҜзҠ¶жҖҒпјҢдҪҶжӯӨж—¶е·ІжІЎжңүеҸҜз”ЁдәҺеҢ№й…Қзҡ„еӯ—з¬ҰпјҢжүҖд»ҘеҢ№й…ҚеӨұиҙҘпјҢеӣһжәҜпјҢдёҚеҢ№й…Қд»»дҪ•еҶ…е®№пјҢдёўејғеӣһжәҜзҠ¶жҖҒпјҢжӯӨж—¶вҖң(/d)/d*вҖқеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…ҚеҶ…е®№дёәвҖң8вҖқпјҢйӮЈд№ҲвҖң(?<=(/d)/d*)вҖқд№ҹе°ұеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жһңжҳҜдҪҚзҪ®1пјҢз”ұдәҺжӯӨеӨ„зҡ„еӯҗиЎЁиҫҫејҸдёәиҙӘе©ӘжЁЎејҸпјҢвҖң(/d)/d*вҖқеҸ–еҫ—дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№еҗҺпјҢйңҖиҰҒжҹҘжүҫжҳҜеҗҰиҝҳжңүжӣҙй•ҝеҢ№й…ҚпјҢжүҫеҲ°жңҖй•ҝеҢ№й…ҚеҗҺпјҢжүҚдјҡдәӨеҮәжҺ§еҲ¶жқғгҖӮеҶҚеҗ‘е·ҰжҹҘжүҫпјҢе·ІжІЎжңүеӯ—з¬ҰпјҢвҖң8вҖқе·ІжҳҜжңҖй•ҝеҢ№й…ҚпјҢжӯӨж—¶дәӨеҮәжҺ§еҲ¶жқғпјҢеҗҢж—¶дёўејғжүҖжңүеӣһжәҜзҠ¶жҖҒгҖӮз”ұдәҺеүҚйқўжҚ•иҺ·з»„1жҚ•иҺ·еҲ°зҡ„еҶ…е®№жҳҜвҖң8вҖқпјҢжүҖд»ҘвҖң/1вҖқиҰҒеҢ№й…ҚеҲ°вҖң8вҖқжүҚиғҪеҢ№й…ҚжҲҗеҠҹпјҢиҖҢжӯӨж—¶дҪҚзҪ®1еҗҺйқўзҡ„еӯ—з¬ҰжҳҜвҖң7вҖқпјҢжӯӨж—¶е·Іж— еҸҜдҫӣеӣһжәҜзҡ„зҠ¶жҖҒпјҢж•ҙдёӘиЎЁиҫҫејҸеңЁдҪҚзҪ®1еӨ„еҢ№й…ҚеӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®2еӨ„е°қиҜ•еҢ№й…ҚпјҢжҺ§еҲ¶жқғдәӨз»ҷвҖң(?<=(/d)/d*)вҖқпјҢеҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢжҺҘзқҖе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң(/d)вҖқпјҢжӣҙиҝӣдёҖжӯҘзҡ„е°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/dвҖқгҖӮвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеҢ№й…ҚвҖң7вҖқжҲҗеҠҹпјҢе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*вҖқпјҢз”ұдәҺвҖң/d*вҖқдёәиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҢ№й…ҚпјҢ并记еҪ•еӣһжәҜзҠ¶жҖҒпјҢдҪҶжӯӨж—¶е·ІжІЎжңүеҸҜз”ЁдәҺеҢ№й…Қзҡ„еӯ—з¬ҰпјҢжүҖд»ҘеҢ№й…ҚеӨұиҙҘпјҢеӣһжәҜпјҢдёҚеҢ№й…Қд»»дҪ•еҶ…е®№пјҢдёўејғеӣһжәҜзҠ¶жҖҒпјҢжӯӨж—¶вҖң(/d)/d*вҖқеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…ҚеҶ…е®№дёәвҖң7вҖқпјҢйӮЈд№ҲвҖң(?<=(/d)/d*)вҖқд№ҹе°ұеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жһңжҳҜдҪҚзҪ®2пјҢз”ұдәҺжӯӨеӨ„зҡ„еӯҗиЎЁиҫҫејҸдёәиҙӘе©ӘжЁЎејҸпјҢвҖң(/d)/d*вҖқеҸ–еҫ—дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№еҗҺпјҢйңҖиҰҒжҹҘжүҫжҳҜеҗҰиҝҳжңүжӣҙй•ҝеҢ№й…ҚпјҢжүҫеҲ°жңҖй•ҝеҢ№й…ҚеҗҺпјҢжүҚдјҡдәӨеҮәжҺ§еҲ¶жқғгҖӮеҶҚеҗ‘е·ҰжҹҘжүҫпјҢз”ұдҪҚзҪ®0еӨ„еҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢвҖң/dвҖқеҸ–еҫ—жҺ§еҲ¶жқғеҗҺпјҢеҢ№й…ҚдҪҚзҪ®0еӨ„зҡ„вҖң8вҖқжҲҗеҠҹпјҢе°ҶжҺ§еҲ¶жқғдәӨз»ҷвҖң/d*вҖқпјҢз”ұдәҺвҖң/d*вҖқдёәиҙӘе©ӘжЁЎејҸпјҢдјҡдјҳе…Ҳе°қиҜ•еҢ№й…ҚпјҢ并记еҪ•еӣһжәҜзҠ¶жҖҒпјҢеҢ№й…ҚдҪҚзҪ®1еӨ„зҡ„вҖң7вҖқжҲҗеҠҹпјҢжӯӨж—¶вҖң(/d)/d*вҖқеҢ№й…ҚжҲҗеҠҹпјҢйӮЈд№ҲвҖң(/d)/d*вҖқеҸҲжүҫеҲ°дәҶдёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№пјҢеҢ№й…ҚеҶ…е®№дёәвҖң87вҖқпјҢе…¶дёӯжҚ•иҺ·з»„1еҢ№й…ҚеҲ°зҡ„жҳҜвҖң8вҖқгҖӮеҶҚеҗ‘е·ҰжҹҘжүҫпјҢе·ІжІЎжңүеӯ—з¬ҰпјҢвҖң87вҖқе·ІжҳҜжңҖй•ҝеҢ№й…ҚпјҢжӯӨж—¶дәӨеҮәжҺ§еҲ¶жқғпјҢеҗҢж—¶дёўејғжүҖжңүеӣһжәҜзҠ¶жҖҒгҖӮз”ұдәҺеүҚйқўжҚ•иҺ·з»„1жҚ•иҺ·еҲ°зҡ„еҶ…е®№жҳҜвҖң8вҖқпјҢжүҖд»ҘвҖң/1вҖқеҢ№й…ҚдҪҚзҪ®2еӨ„зҡ„вҖң8вҖқеҢ№й…ҚжҲҗеҠҹпјҢжӯӨж—¶ж•ҙдёӘжңүиҫҫејҸеҢ№й…ҚжҲҗеҠҹгҖӮ
жј”зӨәдҫӢзЁӢдёӯз”Ёзҡ„жҳҜMatchпјҢеҸӘеҸ–дёҖж¬ЎеҢ№й…ҚйЎ№пјҢдәӢе®һдёҠеҰӮжһңз”Ёзҡ„жҳҜMatchesпјҢжӯЈеҲҷиЎЁиҫҫејҸжҳҜйңҖиҰҒе°қиҜ•жүҖжңүдҪҚзҪ®зҡ„пјҢеҜ№дәҺиҝҷдёҖз»„еҗҲпјҢеҗҢж ·йҒ“зҗҶпјҢеңЁдҪҚзҪ®3еӨ„пјҢз”ұдәҺвҖң/1вҖқжІЎжңүеӯ—з¬ҰеҸҜдҫӣеҢ№й…ҚпјҢжүҖд»ҘеҢ№й…ҚдёҖе®ҡжҳҜеӨұиҙҘзҡ„гҖӮ
иҮіжӯӨпјҢиҝҷдёҖз»„еҗҲзҡ„еҢ№й…Қе®ҢжҲҗпјҢжңүдёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№пјҢеҢ№й…Қз»“жһңдёәвҖң8вҖқпјҢеҢ№й…ҚејҖе§ӢдҪҚзҪ®дёәдҪҚзҪ®2пјҢд№ҹе°ұжҳҜеҢ№й…ҚеҲ°зҡ„еҶ…е®№дёә第дәҢдёӘвҖң8вҖқгҖӮ
2.3.2В жәҗеӯ—з¬ҰдёІдәҢ + жӯЈеҲҷиЎЁиҫҫејҸдёҖеҢ№й…ҚиҝҮзЁӢ
жәҗеӯ—з¬ҰдёІдәҢпјҡ9878
жӯЈеҲҷиЎЁиҫҫејҸдәҢпјҡ(?<=(/d)/d*)/1
йҰ–е…ҲеңЁдҪҚзҪ®0еӨ„ејҖе§Ӣе°қиҜ•еҢ№й…ҚпјҢз”ұвҖң(?<=(/d)/d*)вҖқеҸ–еҫ—жҺ§еҲ¶жқғпјҢй•ҝеәҰдёҚеӣәе®ҡпјҢиҮіе°‘дёҖдҪҚпјҢз”ұдҪҚзҪ®0еӨ„еҗ‘е·ҰжҹҘжүҫдёҖдҪҚпјҢеӨұиҙҘпјҢвҖң(?<=(/d)/d*)вҖқеҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙ第дёҖиҪ®еҢ№й…Қе°қиҜ•еӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®1еӨ„е°қиҜ•еҢ№й…ҚпјҢиҝҷдёҖиҪ®зҡ„еҢ№й…ҚиҝҮзЁӢдёҺ2.3.1иҠӮзҡ„з»„еҗҲеңЁдҪҚзҪ®1еӨ„зҡ„еҢ№й…ҚиҝҮзЁӢзұ»дјјпјҢеҸӘдёҚиҝҮвҖң(/d)/d*вҖқеҢ№й…ҚеҲ°зҡ„жҳҜвҖң9вҖқпјҢжҚ•иҺ·з»„1еҢ№й…ҚеҲ°зҡ„д№ҹжҳҜвҖң9вҖқпјҢеӣ жӯӨвҖң/1вҖқеҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙж•ҙдёӘиЎЁиҫҫејҸеңЁдҪҚзҪ®1еӨ„еҢ№й…ҚеӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®2еӨ„е°қиҜ•еҢ№й…ҚпјҢиҝҷдёҖиҪ®зҡ„еҢ№й…ҚиҝҮзЁӢдёҺ2.3.1иҠӮзҡ„з»„еҗҲеңЁдҪҚзҪ®2еӨ„зҡ„еҢ№й…ҚиҝҮзЁӢзұ»дјјгҖӮйҰ–е…ҲвҖң(/d)/d*вҖқжүҫеҲ°дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№пјҢеҢ№й…ҚеҲ°зҡ„еҶ…е®№жҳҜвҖң8вҖқпјҢжҚ•жҚүз»„1еҢ№й…ҚеҲ°зҡ„еҶ…е®№д№ҹжҳҜвҖң8вҖқпјҢжӯӨж—¶еҶҚеҗ‘е·Ұе°қиҜ•еҢ№й…ҚпјҢеҸҲжүҫеҲ°дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№пјҢеҢ№й…ҚеҲ°зҡ„еҶ…е®№жҳҜвҖң98вҖқпјҢжҚ•жҚүз»„1еҢ№й…ҚеҲ°зҡ„еҶ…е®№д№ҹжҳҜвҖң9вҖқпјҢеҶҚеҗ‘е·ҰжҹҘжүҫж—¶пјҢе·Іж— еӯ—з¬ҰпјҢжүҖд»ҘвҖң98вҖқе°ұжҳҜжңҖй•ҝеҢ№й…ҚйЎ№пјҢвҖң(?<=(/d)/d*)вҖқеҢ№й…ҚжҲҗеҠҹпјҢеҢ№й…Қз»“жһңжҳҜдҪҚзҪ®2гҖӮз”ұдәҺжӯӨж—¶жҚ•иҺ·з»„1еҢ№й…Қзҡ„еҶ…е®№жҳҜвҖң9вҖқпјҢжүҖд»ҘвҖң/1вҖқеңЁдҪҚзҪ®2еӨ„еҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙж•ҙдёӘиЎЁиҫҫејҸеңЁдҪҚзҪ®2еӨ„еҢ№й…ҚеӨұиҙҘгҖӮ
жӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®еҗ‘еүҚдј еҠЁпјҢз”ұдҪҚзҪ®3еӨ„е°қиҜ•еҢ№й…ҚпјҢиҝҷдёҖиҪ®зҡ„еҢ№й…ҚиҝҮзЁӢдёҺдёҠдёҖиҪ®еңЁдҪҚзҪ®2еӨ„зҡ„еҢ№й…ҚиҝҮзЁӢзұ»дјјгҖӮйҰ–е…ҲвҖң(/d)/d*вҖқжүҫеҲ°дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№вҖң7вҖқпјҢ继з»ӯеҗ‘е·Ұе°қиҜ•пјҢеҸҲжүҫеҲ°дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№вҖң87вҖқпјҢеҶҚеҗ‘е·Ұе°қиҜ•пјҢеҸҲжүҫеҲ°дёҖдёӘжҲҗеҠҹеҢ№й…ҚйЎ№вҖң987вҖқпјҢжӯӨж—¶е·ІдёәжңҖй•ҝеҢ№й…ҚпјҢдәӨеҮәжҺ§еҲ¶жқғпјҢ并丢ејғжүҖжңүеӣһжәҜзҠ¶жҖҒгҖӮжӯӨж—¶жҚ•иҺ·з»„1еҢ№й…Қзҡ„еҶ…е®№жҳҜвҖң9вҖқ жүҖд»ҘвҖң/1вҖқеңЁдҪҚзҪ®3еӨ„еҢ№й…ҚеӨұиҙҘпјҢеҜјиҮҙж•ҙдёӘиЎЁиҫҫејҸеңЁдҪҚзҪ®3еӨ„еҢ№й…ҚеӨұиҙҘгҖӮ
дҪҚзҪ®4еӨ„жңҖз»Ҳз”ұдәҺвҖң/1вҖқжІЎжңүеӯ—з¬ҰеҸҜдҫӣеҢ№й…ҚпјҢжүҖд»ҘеҢ№й…ҚдёҖе®ҡжҳҜеӨұиҙҘзҡ„гҖӮ
иҮіжӯӨеңЁжәҗеӯ—з¬ҰдёІжүҖжңүдҪҚзҪ®зҡ„еҢ№й…Қе°қиҜ•йғҪе·Іе®ҢжҲҗпјҢж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеӨұиҙҘпјҢжңӘжүҫеҲ°жҲҗеҠҹеҢ№й…ҚйЎ№гҖӮ
2.4В В В В е°Ҹз»“
д»ҘдёҠеҢ№й…ҚиҝҮзЁӢеҲҶжһҗпјҢзңӢдјјз№ҒеӨҚпјҢе…¶е®һжҠҠжҸЎд»ҘдёӢеҮ зӮ№е°ұеҸҜд»ҘдәҶгҖӮ
1гҖҒВ йҖҶеәҸзҺҜи§ҶдёӯеӯҗиЎЁиҫҫејҸдёәеӣәе®ҡй•ҝеәҰж—¶пјҢиҰҒд№ҲеҢ№й…ҚжҲҗеҠҹпјҢиҰҒд№ҲеҢ№й…ҚеӨұиҙҘпјҢжІЎд»Җд№ҲеҘҪиҜҙзҡ„гҖӮ
2гҖҒВ йҖҶеәҸзҺҜи§ҶдёӯеӯҗиЎЁиҫҫејҸдёәйқһиҙӘе©ӘжЁЎејҸж—¶пјҢеҸӘиҰҒжүҫеҲ°дёҖдёӘеҢ№й…ҚжҲҗеҠҹйЎ№пјҢеҚідәӨеҮәжҺ§еҲ¶жқғпјҢ并丢ејғжүҖжңүеҸҜдҫӣеӣһжәҜзҡ„зҠ¶жҖҒгҖӮ
3гҖҒВ йҖҶеәҸзҺҜи§ҶдёӯеӯҗиЎЁиҫҫејҸдёәиҙӘе©ӘжЁЎејҸж—¶пјҢеҸӘжңүжүҫеҲ°жңҖй•ҝеҢ№й…ҚжҲҗеҠҹйЎ№ж—¶пјҢжүҚдјҡеҚідәӨеҮәжҺ§еҲ¶жқғпјҢ并丢ејғжүҖжңүеҸҜдҫӣеӣһжәҜзҡ„зҠ¶жҖҒгҖӮ
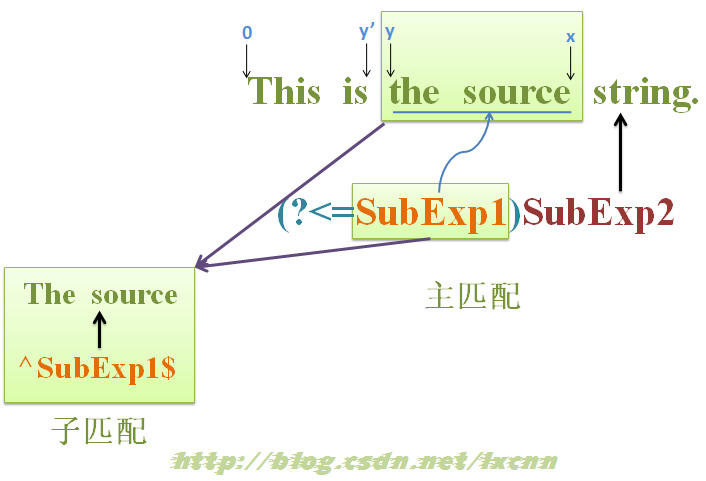
д№ҹе°ұжҳҜиҜҙпјҢеҜ№дәҺжӯЈеҲҷиЎЁиҫҫејҸвҖң(?<=SubExp1)SubExp2вҖқпјҢдёҖж—ҰвҖң(?<=SubExp1)вҖқдәӨеҮәжҺ§еҲ¶жқғпјҢйӮЈд№Ҳе®ғжүҖеҢ№й…Қзҡ„дҪҚзҪ®е°ұе·Іеӣәе®ҡпјҢвҖңSubExp1вҖқжүҖеҢ№й…Қзҡ„еҶ…е®№д№ҹе·Іеӣәе®ҡпјҢ并且没жңүеҸҜдҫӣеӣһжәҜзҡ„зҠ¶жҖҒдәҶгҖӮ
3В В В В В В йҖҶеәҸзҺҜи§ҶеҢ№й…ҚеҺҹзҗҶжҖ»з»“
еҶҚжқҘжҖ»з»“дёҖдёӢжӯЈеҲҷиЎЁиҫҫејҸвҖң(?<=SubExp1)SubExp2вҖқзҡ„еҢ№й…ҚиҝҮзЁӢеҗ§гҖӮйҖҶеәҸзҺҜи§Ҷзҡ„еҢ№й…ҚеҺҹзҗҶеӣҫеҰӮдёӢеӣҫжүҖзӨәгҖӮ
В
В
еӣҫ3-1 йҖҶеәҸзҺҜи§ҶеҢ№й…ҚеҺҹзҗҶеӣҫ
жӯЈеҲҷиЎЁиҫҫејҸвҖң(?<=SubExp1)SubExp2вҖқзҡ„еҢ№й…ҚиҝҮзЁӢпјҢеҸҜеҲҶдёәдё»еҢ№й…ҚжөҒзЁӢе’ҢеӯҗеҢ№й…ҚжөҒзЁӢдёӨдёӘжөҒзЁӢпјҢдё»еҢ№й…ҚжөҒзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
В 
В
еӣҫ3-2 дё»еҢ№й…ҚжөҒзЁӢеӣҫ
дё»еҢ№й…ҚжөҒзЁӢпјҡ
1гҖҒВ з”ұдҪҚзҪ®0еӨ„еҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢеңЁжүҫеҲ°ж»Ўи¶івҖң(?<=SubExp1)вҖқжңҖе°Ҹй•ҝеәҰиҰҒжұӮзҡ„дҪҚзҪ®еүҚпјҢеҢ№й…ҚдёҖе®ҡжҳҜеӨұиҙҘзҡ„пјҢзӣҙеҲ°жүҫеҲ°иҝҷж ·дёҖдёӘзҡ„дҪҚзҪ®xпјҢxж»Ўи¶івҖң(?<=SubExp1)вҖқжңҖе°Ҹй•ҝеәҰиҰҒжұӮпјӣ
2гҖҒВ д»ҺдҪҚзҪ®xеӨ„еҗ‘е·ҰжҹҘжүҫж»Ўи¶івҖңSubExp1вҖқжңҖе°Ҹй•ҝеәҰиҰҒжұӮзҡ„дҪҚзҪ®yпјӣ
3гҖҒВ з”ұвҖңSubExp1вҖқд»ҺдҪҚзҪ®yејҖе§Ӣеҗ‘еҸіе°қиҜ•еҢ№й…ҚпјҢжӯӨж—¶иҝӣе…ҘдёҖдёӘзӢ¬з«Ӣзҡ„еӯҗеҢ№й…ҚиҝҮзЁӢпјӣ
4гҖҒВ еҰӮжһңвҖңSubExp1вҖқеңЁдҪҚзҪ®yеӨ„еӯҗеҢ№й…ҚиҝҳйңҖиҰҒдёӢдёҖиҪ®еӯҗеҢ№й…ҚпјҢеҲҷеҶҚеҗ‘е·ҰжҹҘжүҫдёҖдёӘyвҖҷпјҢд№ҹе°ұжҳҜy-1йҮҚж–°иҝӣе…ҘзӢ¬з«Ӣзҡ„еӯҗеҢ№й…ҚиҝҮзЁӢпјҢеҰӮжӯӨеҫӘзҺҜпјҢзӣҙеҲ°дёҚеҶҚйңҖиҰҒдёӢдёҖиҪ®еӯҗеҢ№й…ҚпјҢеӯҗеҢ№й…ҚжҲҗеҠҹеҲҷиҝӣе…ҘжӯҘйӘӨ5пјҢжңҖз»ҲеҢ№й…ҚеӨұиҙҘеҲҷжҠҘе‘Ҡж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚеӨұиҙҘпјӣ
5гҖҒВ вҖң(?<=SubExp1)вҖқжҲҗеҠҹеҢ№й…ҚеҗҺпјҢжҺ§еҲ¶жқғдәӨз»ҷеҗҺйқўзҡ„еӯҗиЎЁиҫҫејҸвҖңSubExp2вҖқпјҢ继з»ӯе°қиҜ•еҢ№й…ҚпјҢзӣҙеҲ°ж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚжҲҗеҠҹжҲ–еӨұиҙҘпјҢжҠҘе‘ҠеңЁдҪҚзҪ®xеӨ„ж•ҙдёӘиЎЁиҫҫејҸеҢ№й…ҚжҲҗеҠҹжҲ–еӨұиҙҘпјӣ
6гҖҒВ еҰӮжңүеҝ…иҰҒпјҢ继з»ӯжҹҘжүҫдёӢдёҖдҪҚзҪ®xвҖҷпјҢ并ејҖе§Ӣж–°дёҖиҪ®е°қиҜ•еҢ№й…ҚгҖӮ
еӯҗеҢ№й…ҚжөҒзЁӢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
В

еӣҫ3-3 еӯҗеҢ№й…ҚжөҒзЁӢеӣҫ
еӯҗеҢ№й…ҚиҝҮзЁӢпјҡ
1гҖҒВ иҝӣе…ҘеӯҗеҢ№й…ҚеҗҺпјҢжәҗеӯ—з¬ҰдёІеҚіе·ІзЎ®е®ҡпјҢд№ҹе°ұжҳҜдҪҚзҪ®yе’ҢдҪҚзҪ®xд№Ӣй—ҙзҡ„еӯҗеӯ—з¬ҰдёІпјҢиҖҢжӯӨж—¶зҡ„жӯЈеҲҷиЎЁиҫҫејҸеҲҷеҸҳжҲҗдәҶвҖң^SubExp1$вҖқпјҢеӣ дёәеңЁиҝҷдёҖиҪ®еӯҗеҢ№й…ҚеҪ“дёӯпјҢдёҖж—ҰеҢ№й…ҚжҲҗеҠҹпјҢеҲҷеҢ№й…ҚејҖе§ӢдҪҚзҪ®дёҖе®ҡжҳҜyпјҢеҢ№й…Қз»“жқҹдҪҚзҪ®дёҖе®ҡжҳҜxпјӣ
2гҖҒВ еӯҗиЎЁиҫҫејҸй•ҝеәҰеӣәе®ҡж—¶пјҢиҰҒд№ҲеҢ№й…ҚжҲҗеҠҹпјҢиҰҒд№ҲеҢ№й…ҚеӨұиҙҘпјҢиҝ”еӣһеҢ№й…Қз»“жһңпјҢ并且дёҚйңҖиҰҒдёӢдёҖиҪ®еӯҗеҢ№й…Қпјӣ
3гҖҒВ еӯҗиЎЁиҫҫејҸй•ҝеәҰдёҚеӣәе®ҡж—¶пјҢеҢәеҲҶжҳҜйқһиҙӘе©ӘжЁЎејҸиҝҳжҳҜиҙӘе©ӘжЁЎејҸпјӣ
4гҖҒВ еҰӮжһңжҳҜйқһиҙӘе©ӘжЁЎејҸпјҢеҢ№й…ҚеӨұиҙҘпјҢжҠҘе‘ҠеӨұиҙҘпјҢ并且иҰҒжұӮиҝӣиЎҢдёӢдёҖиҪ®еӯҗеҢ№й…ҚпјӣеҢ№й…ҚжҲҗеҠҹпјҢдёўејғжүҖжңүеӣһжәҜзҠ¶жҖҒпјҢжҠҘе‘ҠжҲҗеҠҹпјҢ并且дёҚеҶҚйңҖиҰҒе°қиҜ•дёӢдёҖиҪ®еӯҗеҢ№й…Қпјӣ
5гҖҒВ еҰӮжһңжҳҜиҙӘе©ӘжЁЎејҸпјҢеҢ№й…ҚеӨұиҙҘпјҢжҠҘе‘ҠеӨұиҙҘпјҢ并且иҰҒжұӮиҝӣиЎҢдёӢдёҖиҪ®еӯҗеҢ№й…ҚпјӣеҢ№й…ҚжҲҗеҠҹпјҢдёўејғжүҖжңүеӣһжәҜзҠ¶жҖҒпјҢжҠҘе‘ҠжҲҗеҠҹпјҢи®°еҪ•жң¬ж¬ЎеҢ№й…ҚжҲҗеҠҹеҶ…е®№пјҢ并且иҰҒжұӮе°қиҜ•дёӢдёҖиҪ®еӯҗеҢ№й…ҚпјҢзӣҙеҲ°еҸ–еҫ—жңҖй•ҝеҢ№й…Қдёәжӯўпјӣ
еңЁзү№е®ҡзҡ„дёҖиҪ®еҢ№й…ҚдёӯпјҢxзҡ„дҪҚзҪ®жҳҜеӣәе®ҡзҡ„пјҢиҖҢйҖҶеәҸзҺҜи§Ҷдёӯзҡ„еӯҗиЎЁиҫҫејҸвҖңSubExp1вҖқпјҢеңЁжҠҘе‘ҠжңҖз»Ҳзҡ„еҢ№й…Қз»“жһңеүҚпјҢеҢ№й…ҚејҖе§Ӣзҡ„дҪҚзҪ®жҳҜдёҚеҸҜйў„зҹҘзҡ„пјҢйңҖиҰҒз»ҸиҝҮдёҖиҪ®д»ҘдёҠзҡ„еӯҗеҢ№й…ҚжүҚиғҪзЎ®е®ҡпјҢдҪҶеҢ№й…Қз»“жқҹзҡ„дҪҚзҪ®дёҖе®ҡжҳҜдҪҚзҪ®xгҖӮ
еҪ“然пјҢиҝҷеҸӘжҳҜй’ҲеҜ№зү№е®ҡзҡ„дёҖиҪ®еҢ№й…ҚиҖҢиЁҖзҡ„пјҢеҪ“иҝҷиҪ®еҢ№й…ҚеӨұиҙҘпјҢжӯЈеҲҷеј•ж“Һдј еҠЁиЈ…зҪ®дјҡеҗ‘еүҚдј еҠЁпјҢдҪҝx=x+1пјҢеҶҚиҝӣе…ҘдёӢдёҖиҪ®еҢ№й…Қе°қиҜ•пјҢзӣҙеҲ°ж•ҙдёӘиЎЁиҫҫејҸжҠҘе‘ҠеҢ№й…ҚжҲҗеҠҹжҲ–еӨұиҙҘдёәжӯўгҖӮ
иҮіжӯӨйҖҶеәҸзҺҜи§Ҷзҡ„еҢ№й…ҚеҺҹзҗҶе·Іеҹәжң¬дёҠеҲҶжһҗе®ҢдәҶпјҢеҪ“然пјҢиҝҳжңүжӣҙеӨҚжқӮзҡ„пјҢеҰӮвҖңSubExp1вҖқдёӯж—ўеҢ…еҗ«иҙӘе©ӘжЁЎејҸеӯҗиЎЁиҫҫејҸпјҢеҸҲеҢ…еҗ«йқһиҙӘе©ӘжЁЎејҸеӯҗиЎЁиҫҫејҸпјҢдҪҶж— и®әжҖҺж ·еӨҚжқӮпјҢйғҪжҳҜиҰҒйҒөеҫӘд»ҘдёҠеҢ№й…ҚеҺҹзҗҶзҡ„пјҢжүҖд»ҘеҸӘиҰҒзҗҶи§ЈдәҶд»ҘдёҠеҢ№й…ҚеҺҹзҗҶпјҢйҖҶеәҸзҺҜи§Ҷд№ҹе°ұжІЎд»Җд№Ҳз§ҳеҜҶеҸҜиЁҖдәҶгҖӮ
иҪ¬иҮӘпјҡhttp://blog.csdn.net/lxcnn/article/details/5126888


- 2011-07-06 16:59
- жөҸи§Ҳ 889
- иҜ„и®ә(0)
- еҲҶзұ»:зј–зЁӢиҜӯиЁҖ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
пјҲд»ҺзҪ‘дёҠиҖғиҝҮжқҘзҡ„пјҢ收и—Ҹпјү javascript жӯЈеҲҷиЎЁиҫҫејҸзҡ„иҙӘе©ӘдёҺйқһиҙӘе©Ә
2012-10-08 10:35 891д»ҘдёӢеҶ…е®№иҪ¬иҮӘпјҡhttp://www.cnitblog.com ... -
жӯЈеҲҷиЎЁиҫҫејҸеёёз”ЁйӘҢиҜҒ
2011-08-24 12:20 857еңЁеүҚеҸ°еҫҲеӨҡең°ж–№йңҖиҰҒйӘҢиҜҒиҫ“е…Ҙж јејҸпјҢдёәдәҶж–№дҫҝд»ҘеҗҺдҪҝз”ЁпјҢжҠҠеёёз”Ёзҡ„ж•ҙзҗҶ ... -
жӯЈеҲҷеҲӨж–ӯдёҖдёӘеӯ—з¬ҰдёІйҮҢжҳҜеҗҰеҢ…еҗ«дёҖдәӣиҜҚ
2011-08-16 16:53 3270д»ҠеӨ©йЎ№зӣ®йҮҢз”ЁеҲ°дәҶжӯЈеҲҷпјҢеҲӨж–ӯдёҖдёӘеӯ—з¬ҰдёІйҮҢжҳҜдёҚжҳҜеҢ…еҗ«иҝҷдәӣиҜҚпјҢиҜҚеҮә ... -
jsеҸ–еҪ“еүҚurlеҸӮж•°
2011-07-19 11:14 1954jsжІЎжңүжҸҗдҫӣеҸ–еҪ“еүҚurlеҸӮж•°зҡ„ж–№жі•пјҢеҸӘиғҪжҳҜиҮӘе·ұд»ҺдёӯжҲӘеҸ–дәҶпјҢеңЁ ... -
жӯЈеҲҷжүӢеҶҢ
2011-07-07 16:53 1031з»ҷеӨ§е®¶е…ұдә«дёӘжӯЈеҲҷжүӢеҶҢ В В В ж¬ўиҝҺжҹҘзңӢжң¬дәәеҚҡе®ўпјҡ ... -
[ ] еӯ—з¬Ұз»„(Character Classes) .
2011-07-06 17:31 829В []иғҪеӨҹеҢ№й…ҚжүҖеҢ…еҗ«зҡ„дёҖзі»еҲ—еӯ—з¬Ұдёӯзҡ„д»»ж„ҸдёҖдёӘгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢ[ ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”жҚ•иҺ·з»„пјҲcapture groupпјү .
2011-07-06 17:30 10071В В В В В В В жҰӮиҝ° 1.1В В В В д»Җд№ҲжҳҜжҚ•иҺ·з»„ ... -
жӯЈеҲҷиЎЁиҫҫејҸеӯҰд№ еҸӮиҖғ
2011-07-06 17:28 777жӯЈеҲҷиЎЁиҫҫејҸеӯҰд№ еҸӮиҖғ 1 ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”е°Ҹж•°зӮ№ .
2011-07-06 17:23 795е°Ҹж•°зӮ№еҸҜд»ҘеҢ№й…ҚйҷӨдәҶжҚўиЎҢз¬ҰвҖң/nвҖқд»ҘеӨ–зҡ„д»»ж„ҸдёҖдёӘеӯ—з¬Ұ В дёҖ ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”NFAеј•ж“ҺеҢ№й…ҚеҺҹзҗҶ .
2011-07-06 17:22 1002NFAеј•ж“ҺеҢ№й…ҚеҺҹзҗҶ 1В В В В ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”зҺҜи§Ҷ .
2011-07-06 17:21 573зҺҜи§ҶеҸӘиҝӣиЎҢеӯҗиЎЁиҫҫејҸзҡ„еҢ№й…ҚпјҢдёҚеҚ жңүеӯ—з¬ҰпјҢеҢ№й…ҚеҲ°зҡ„еҶ…е®№дёҚдҝқеӯҳеҲ°жңҖз»Ҳ ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”/b еҚ•иҜҚиҫ№з•Ң .
2011-07-06 17:20 8261В В В В В В В жҰӮиҝ° вҖң/bвҖқеҢ№й…ҚеҚ•иҜҚиҫ№з•ҢпјҢдёҚеҢ№й…Қд»»дҪ• ... -
жӯЈеҲҷеә”з”Ёд№ӢвҖ”вҖ”ж—ҘжңҹжӯЈеҲҷиЎЁиҫҫејҸ
2011-07-06 17:18 10761В В В В В В В жҰӮиҝ° йҰ–е…ҲйңҖиҰҒиҜҙжҳҺзҡ„дёҖзӮ№пјҢж— и®әжҳҜWin ... -
.NETжӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”.NETжӯЈеҲҷеҢ№й…ҚжЁЎејҸ .
2011-07-06 17:16 23381В В В В В В В жҰӮиҝ° еҢ№й…ҚжЁЎејҸжҢҮзҡ„жҳҜдёҖдәӣеҸҜд»Ҙж”№еҸҳжӯЈеҲҷиЎЁ ... -
.NETжӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”е№іиЎЎз»„ .
2011-07-06 17:14 18191В В В В В В В жҰӮиҝ° е№іиЎЎз»„жҳҜеҫ®иҪҜеңЁ.NETдёӯжҸҗеҮәзҡ„дёҖ ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”йқһжҚ•иҺ·з»„ .
2011-07-06 17:10 1370йқһжҚ•иҺ·з»„пјҡ(?:Expression) жҺҘи§ҰжӯЈеҲҷиЎЁиҫҫејҸдёҚд№…зҡ„ ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”еҸҚеҗ‘еј•з”Ё .
2011-07-06 17:09 13271В В В В В В В жҰӮиҝ° жҚ•иҺ·з»„жҚ•иҺ·еҲ°зҡ„еҶ…е®№пјҢдёҚд»…еҸҜд»ҘеңЁ ... -
.NETжӯЈеҲҷеҹәзЎҖвҖ”вҖ”.NETжӯЈеҲҷзұ»еҸҠж–№жі•еә”з”Ё .
2011-07-06 17:07 11091В В В В В В В жҰӮиҝ° еҲқеӯҰ ... -
NETжӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”жӯЈеҲҷ委жүҳ .
2011-07-06 17:05 8471В В В В В В В жҰӮиҝ° дёҖиҲ¬зҡ„жӯЈеҲҷжӣҝжҚўпјҢеҸӘиғҪеҜ№еҢ№й…Қзҡ„еӯҗдёІеҒҡ ... -
жӯЈеҲҷеҹәзЎҖд№ӢвҖ”вҖ”иҙӘе©ӘдёҺйқһиҙӘе©ӘжЁЎејҸ .
2011-07-06 17:03 9671В В В В В В В жҰӮиҝ° иҙӘе©Ә ...
зӣёе…іжҺЁиҚҗ
жӯЈеҲҷиЎЁиҫҫејҸжҳҜдёҖз§ҚејәеӨ§зҡ„ж–Үжң¬еӨ„зҗҶе·Ҙе…·пјҢз”ЁдәҺеңЁеӯ—з¬ҰдёІдёӯиҝӣиЎҢжЁЎејҸеҢ№й…Қе’ҢжҗңзҙўгҖӮ...йҖҡиҝҮйҳ…иҜ»гҖҠжӯЈеҲҷеҢ№й…ҚеҺҹзҗҶд№ӢвҖ”вҖ”йҖҶеәҸзҺҜи§Ҷж·ұе…Ҙ.pdfгҖӢиҝҷд»Ҫж–ҮжЎЈпјҢдҪ еҸҜд»Ҙжӣҙж·ұе…Ҙең°дәҶи§ЈиҝҷдёӘдё»йўҳпјҢжҺҢжҸЎйҖҶеәҸзҺҜи§ҶеңЁе®һйҷ…еә”з”Ёдёӯзҡ„жҠҖе·§е’Ңзӯ–з•ҘгҖӮ
еңЁвҖңжӯЈеҲҷеә”з”Ёд№ӢвҖ”вҖ”йҖҶеәҸзҺҜи§ҶжҺўзҙўвҖқиҝҷдёӘдё»йўҳдёӯпјҢжҲ‘们е°Ҷж·ұе…ҘжҺўи®ЁиҝҷдёӨдёӘжҰӮеҝөд»ҘеҸҠе®ғ们еңЁе®һйҷ…еә”з”Ёдёӯзҡ„д»·еҖјгҖӮ иӮҜе®ҡйҖҶеәҸзҺҜи§Ҷ(?)з”ЁдәҺзЎ®дҝқеҢ№й…Қзҡ„еӯ—з¬ҰдёІеүҚжңүжҹҗдёӘжЁЎејҸпјҢдҪҶдёҚдјҡеҢ…еҗ«иҝҷдёӘжЁЎејҸеңЁеҢ№й…Қз»“жһңеҶ…гҖӮдҫӢеҰӮпјҢеҰӮжһңдҪ жғіиҰҒеҢ№й…Қ...
еңЁNFAпјҲйқһзЎ®е®ҡжңүйҷҗиҮӘеҠЁжңәпјүеј•ж“ҺдёӯпјҢзҺҜи§Ҷзҡ„еҢ№й…ҚеҺҹзҗҶжҳҜйҖҡиҝҮжҺ§еҲ¶жқғзҡ„дј йҖ’е’ҢеӣһжәҜжқҘе®һзҺ°зҡ„гҖӮеҪ“зҺҜи§ҶиЎЁиҫҫејҸдёҚеҢ№й…Қж—¶пјҢдјҡиҝӣиЎҢеӣһжәҜж“ҚдҪңпјҢзӣҙеҲ°жүҫеҲ°еҢ№й…ҚжҲ–жңҖз»ҲзЎ®е®ҡеҢ№й…ҚеӨұиҙҘгҖӮеңЁдёҠиҝ°зҡ„HTMLж ҮзӯҫеҢ№й…ҚзӨәдҫӢдёӯпјҢж•ҙдёӘеҢ№й…ҚиҝҮзЁӢж¶үеҸҠеҲ°еҜ№...
жҺҢжҸЎзҺҜи§Ҷзҡ„еҺҹзҗҶпјҢе°Өе…¶жҳҜNFAпјҲйқһзЎ®е®ҡжҖ§жңүйҷҗиҮӘеҠЁжңәпјүеј•ж“Һзҡ„еҢ№й…ҚжңәеҲ¶пјҢжңүеҠ©дәҺж·ұе…ҘзҗҶи§ЈжӯЈеҲҷиЎЁиҫҫејҸзҡ„иҝҗиЎҢж–№ејҸгҖӮйҖҡиҝҮе®һдҫӢеҲҶжһҗпјҢжҲ‘们еҸҜд»ҘжӣҙеҘҪең°зҗҶи§ЈзҺҜи§ҶеңЁе®һйҷ…еә”з”Ёдёӯзҡ„дҪңз”ЁпјҢжҜ”еҰӮеңЁж–Үжң¬еӨ„зҗҶгҖҒж•°жҚ®жҸҗеҸ–е’ҢйӘҢиҜҒзӯүж–№йқўгҖӮ жҖ»д№Ӣ...
жӯӨзЁӢеәҸзҡ„еҲӣж–°д№ӢеӨ„еңЁдәҺз»“еҗҲдәҶеӯ—з¬ҰдёІйҖҶеәҸе’ҢжӯЈеҲҷиЎЁиҫҫејҸпјҢжңүж•Ҳең°жҸҗй«ҳдәҶиҜ»еҸ–еӨ§ж–Ү件жңҖеҗҺдёҖиЎҢзҡ„ж•ҲзҺҮпјҢеҮҸе°‘дәҶеҶ…еӯҳеҚ з”Ёе’ҢеӨ„зҗҶж—¶й—ҙгҖӮиҝҷеҜ№дәҺйңҖиҰҒйў‘з№ҒеӨ„зҗҶеӨ§йҮҸж–Үжң¬ж•°жҚ®зҡ„е·ҘзЁӢеә”з”Ёйқһеёёжңүз”ЁгҖӮ жҖ»зҡ„жқҘиҜҙпјҢйҖҡиҝҮеӯҰд№ иҝҷдёӘLabVIEWзЁӢеәҸ...
жң¬ж•ҷзЁӢдё»иҰҒеҸӮиҖғиҮӘзҪ‘дёҠжңҖжҷ®йҒҚзҡ„гҖҠжӯЈеҲҷиЎЁиҫҫејҸ30еҲҶй’ҹе…Ҙй—Ёж•ҷзЁӢгҖӢ...з”ұдәҺе…¬еҸёдҪҝз”Ёзҡ„JAVAе’ҢGROOVYеқҮдёҚж”ҜжҢҒиҝҷ2дёӘзү№жҖ§пјҲйҖҶеәҸзҺҜи§ҶдҪҝз”ЁдёҚзЎ®е®ҡйҮҸиҜҚд№ҹжҳҜдёҚж”ҜжҢҒзҡ„пјүпјҢеӣ жӯӨжҲ‘们дҪҝз”ЁдёҠ并дёҚдјҡжңүйҡңзўҚгҖӮ
жӯЈеҲҷиЎЁиҫҫејҸзҡ„зҺҜи§ҶеҠҹиғҪпјҢд№ҹиў«з§°дҪңйў„жҗңзҙўе’Ңйӣ¶е®Ҫж–ӯиЁҖпјҢжҳҜдёҖз§Қзү№ж®Ҡзҡ„жЁЎејҸеҢ№й…ҚиғҪеҠӣгҖӮзҺҜи§Ҷе…Ғи®ёжҲ‘们еңЁдёҚж¶ҲиҖ—еӯ—з¬Ұзҡ„жғ…еҶөдёӢжЈҖжҹҘжҹҗдёӘдҪҚзҪ®зҡ„еүҚеҗҺж–ҮпјҢд»ҺиҖҢе®һзҺ°жӣҙдёәеӨҚжқӮе’ҢзІҫзЎ®зҡ„еҢ№й…ҚгҖӮжҺҘдёӢжқҘпјҢжҲ‘们е°ҶиҜҰз»Ҷд»Ӣз»ҚжӯЈеҲҷиЎЁиҫҫејҸзҺҜи§Ҷзҡ„жҰӮеҝө...
д»ҘдёҠд»Ӣз»ҚдәҶжӯЈеҲҷиЎЁиҫҫејҸзҡ„дёҖдәӣй«ҳзә§жҠҖе·§е’ҢжҰӮеҝөпјҢеҢ…жӢ¬е…ғеӯ—з¬Ұзҡ„зҗҶи§ЈгҖҒзү№ж®Ҡз¬ҰеҸ·зҡ„еә”з”ЁгҖҒжӢ¬еҸ·зҡ„дҪҝз”ЁгҖҒзҺҜи§Ҷзҡ„дҪҝз”Ёд»ҘеҸҠеҢ№й…ҚжЁЎејҸзҡ„и®ҫе®ҡгҖӮжҺҢжҸЎиҝҷдәӣжҠҖе·§еҸҜд»Ҙеё®еҠ©ејҖеҸ‘иҖ…жӣҙзҒөжҙ»ең°зј–еҶҷеӨҚжқӮзҡ„жӯЈеҲҷиЎЁиҫҫејҸпјҢжҸҗй«ҳд»Јз Ғзҡ„ж•ҲзҺҮе’ҢеҸҜз»ҙжҠӨжҖ§гҖӮ
JavaжӯЈеҲҷиЎЁиҫҫејҸжҳҜејәеӨ§зҡ„ж–Үжң¬еӨ„зҗҶе·Ҙе…·пјҢе…¶дёӯзҡ„жӯЈеҲҷзҺҜи§Ҷе’ҢеҸҚеҗ‘еј•з”ЁеҠҹиғҪдҪҝеҫ—еҢ№й…ҚжӣҙдёәзІҫз»Ҷе’ҢзҒөжҙ»гҖӮзҺҜи§ҶпјҢеҸҲз§°йӣ¶е®Ҫж–ӯиЁҖпјҢжҳҜжӯЈеҲҷиЎЁиҫҫејҸдёӯзҡ„дёҖдёӘй«ҳзә§зү№жҖ§пјҢе®ғе…Ғи®ёжҲ‘们еңЁдёҚж¶ҲиҖ—еҢ№й…Қеӯ—з¬Ұзҡ„жғ…еҶөдёӢиҝӣиЎҢйў„жЈҖжҹҘпјҢзЎ®дҝқжҹҗдёӘдҪҚзҪ®еүҚеҗҺ...
" PLCзј–зЁӢе®һдҫӢд№Ӣе…ӯеҸ°з”өеҠЁжңәйЎәеәҸеҗҜеҠЁ-йҖҶеәҸеҒңжӯў" жң¬ж–Үе°ҶеҜ№PLCзј–зЁӢе®һдҫӢд№Ӣе…ӯеҸ°з”өеҠЁжңәйЎәеәҸеҗҜеҠЁ-йҖҶеәҸ...PLCзј–зЁӢе®һдҫӢд№Ӣе…ӯеҸ°з”өеҠЁжңәйЎәеәҸеҗҜеҠЁ-йҖҶеәҸеҒңжӯўжҳҜдёҖдёӘеӨҚжқӮзҡ„жҺ§еҲ¶зі»з»ҹпјҢйңҖиҰҒеҜ№PLCзј–зЁӢгҖҒз”өи·Ҝи®ҫи®Ўе’ҢжҺ§еҲ¶еҺҹзҗҶжңүж·ұе…Ҙзҡ„дәҶи§ЈгҖӮ
жң¬йЎ№зӣ®д»Ҙ"matlabдёӯж–ҮеҲҶиҜҚвҖ”вҖ”жңҖеӨ§жӯЈеҗ‘еҢ№й…Қжі•.rar"дёәдё»йўҳпјҢйҮҚзӮ№и®Ёи®әдәҶеҰӮдҪ•еңЁMATLABзҺҜеўғдёӯе®һзҺ°жңҖеӨ§жӯЈеҗ‘еҢ№й…Қз®—жі•иҝӣиЎҢдёӯж–ҮеҲҶиҜҚгҖӮ MATLABжҳҜдёҖз§Қе№ҝжіӣдҪҝз”Ёзҡ„ж•°еӯҰи®Ўз®—е’Ңзј–зЁӢзҺҜеўғпјҢе…¶ејәеӨ§зҡ„ж•°еҖји®Ўз®—е’ҢеҸҜи§ҶеҢ–еҠҹиғҪдҪҝе…¶жҲҗдёәз§‘з ”...
е®һйӘҢзҡ„дё»иҰҒзӣ®зҡ„жҳҜи®©еӯҰз”ҹзҶҹжӮүз®—жі•и®ҫи®Ўдёӯзҡ„дёҖдёӘж ёеҝғжҰӮеҝөвҖ”вҖ”йҖҶеәҸеҜ№пјҢ并йҖҡиҝҮе®һйҷ…зј–зЁӢеҠ ж·ұеҜ№еҪ’并жҺ’еәҸз®—жі•зҡ„зҗҶи§ЈгҖӮе®һйӘҢиҰҒжұӮеӯҰз”ҹиғҪеӨҹи®ҫ计并е®һзҺ°дёҖдёӘеҹәдәҺеҪ’并жҺ’еәҸзҡ„еҲҶжІ»з®—жі•жқҘз»ҹи®ЎдёҖдёӘжҺ’еҲ—дёӯзҡ„йҖҶеәҸеҜ№ж•°йҮҸпјҢ并记еҪ•е…·дҪ“зҡ„йҖҶеәҸ...
еңЁиӢұиҜӯеӯҰд№ дёӯпјҢиҜҚжұҮйҮҸзҡ„з§ҜзҙҜжҳҜиҮіе…ійҮҚиҰҒзҡ„пјҢиҖҢгҖҠиӢұиҜӯиҖғз ”иҜҚжұҮйҖҶеәҸеҚ•иҜҚиЎЁгҖӢжҸҗдҫӣдәҶдёҖз§ҚзӢ¬зү№зҡ„еӯҰд№ ж–№жі•вҖ”вҖ”йҖҶеәҸи®°еҝҶжі•пјҢж—ЁеңЁеё®еҠ©еӯҰз”ҹжӣҙй«ҳж•Ҳең°жҺҢжҸЎеӨ§йҮҸиҜҚжұҮгҖӮиҝҷз§Қж–№жі•йҖҡиҝҮе°ҶеҚ•иҜҚжҢүеӯ—жҜҚйҖҶеәҸжҺ’еҲ—пјҢжү“з ҙдәҶ常规зҡ„и®°еҝҶжЁЎејҸпјҢдҪҝ...