- وµڈ览: 301220 و¬،
- و€§هˆ«:

- و¥è‡ھ: هŒ—ن؛¬
-

و–‡ç« هˆ†ç±»
- ه…¨éƒ¨هچڑه®¢ (227)
- javascript (47)
- java (70)
- jquery (7)
- و£هˆ™ (24)
- css (11)
- 设è®،و¨،ه¼ڈ (14)
- ه…¶ن»– (25)
- php (4)
- freemarker (4)
- و–°وµھه¾®هچڑوژ¥هڈ£ (1)
- phpcms (2)
- java,tomcat (1)
- Fckeditor (2)
- mysql (2)
- و•°وچ®ه؛“è،¨è®¾è®، (1)
- uploadify (1)
- jeecms (3)
- js (1)
- jboss (3)
- joomla (1)
- struts2 (2)
- ç©؛é—´ (1)
社هŒ؛版ه—
- وˆ‘çڑ„资讯 ( 0)
- وˆ‘çڑ„è®؛ه› ( 0)
- وˆ‘çڑ„é—®ç” ( 2)
هکو،£هˆ†ç±»
- 2015-08 ( 1)
- 2015-01 ( 1)
- 2014-04 ( 2)
- و›´ه¤ڑهکو،£...
وœ€و–°è¯„è®؛
-
ه…¨ç«™ه”¯ن¸€وک¯وˆ‘ن¹ˆï¼ڑ
请问ن¸‹è¯¥هٹں能çڑ„jdk版وœ¬وک¯1.4çڑ„ن¹ˆï¼Œè؟کوک¯ن»¥ن¸ٹçڑ„ï¼ں
Javaه®çژ°ç»™ه›¾ç‰‡و·»هٹ و°´هچ° -
Janneï¼ڑ
请问,ن½ 解ه†³è؟™é—®é¢کو²،?وک¯و€ژن¹ˆه›ن؛‹?وˆ‘ن»ٹه¤©ن¹ںéپ‡هˆ°ن؛†,و²،解ه†³
myeclipse6.5ن¸ن½؟用jax-wsهگ¯هٹ¨tomcatوٹ¥é”™é—®é¢ک -
xuedongï¼ڑ
studypi ه†™éپ“ن½ وک¯و€ژن¹ˆه’Œو–°وµھçڑ„وٹ€وœ¯èپ”ç³»çڑ„ï¼ں能ه‘ٹ诉ن¸€ن¸‹وˆ‘هگ— ...
و–°وµھه¾®هچڑ第ن¸‰و–¹وژ¥هڈ£è°ƒç”¨ه¦ن¹ -
studypiï¼ڑ
ن½ وک¯و€ژن¹ˆه’Œو–°وµھçڑ„وٹ€وœ¯èپ”ç³»çڑ„ï¼ں能ه‘ٹ诉ن¸€ن¸‹وˆ‘هگ—,谢谢
و–°وµھه¾®هچڑ第ن¸‰و–¹وژ¥هڈ£è°ƒç”¨ه¦ن¹ -
dove19900520ï¼ڑ
وœ‰ç”¨ï¼Œه‘µه‘µ
IE,Firefox都ن¸چو”¾ه¼ƒï¼ˆه…¼ه®¹و€§é—®é¢کو€»ç»“)
1آ آ آ آ آ آ آ é—®é¢که¼•ه‡؛
ه‰چه‡ ه¤©هœ¨CSDNè®؛ه›éپ‡هˆ°è؟™و ·ن¸€ن¸ھé—®é¢کم€‚
وˆ‘è¦پé€ڑè؟‡و£هˆ™هˆ†هˆ«هڈ–ه‡؛ن¸‹é¢ <font color="#008000"> ن¸ژ </font> ن¹‹é—´çڑ„ه—符ن¸²
1م€پهœ¨ <font color="#008000"> ن¸ژ </font> ن¹‹é—´çڑ„ه—符ن¸²وک¯و²،و³•ه›؛ه®ڑçڑ„,وک¯éڑڈوœ؛è‡ھهٹ¨ç”ںوˆگçڑ„
2م€په…¶ن¸ <font color="#008000"> ن¸ژ </font>çڑ„و•°é‡ڈن¹ںوک¯و²،و³•ه›؛ه®ڑçڑ„,ن¹ںوک¯éڑڈوœ؛è‡ھهٹ¨ç”ںوˆگçڑ„
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 ** </font>
وœ‰وœ‹هڈ‹ç»™ه‡؛è؟™و ·çڑ„و£هˆ™â€œ(?<=<font[/s/S]*?>)([/s/S]*?)(?=</font>)â€ï¼Œçœ‹ن¸‹هŒ¹é…چ结وœم€‚
string test = @"<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=<font[/s/S]*?>)([/s/S]*?)(?=</font>)");
foreach (Match m in mc)
{
آ آ آ آ richTextBox2.Text += m.Value + "/n---------------/n";
}
/*--------输ه‡؛--------
** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
---------------
آ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
---------------
آ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
---------------
*/
ن¸؛ن»€ن¹ˆن¼ڑوک¯è؟™و ·çڑ„结وœï¼Œè€Œن¸چوک¯وˆ‘ن»¬وœںوœ›çڑ„ه¦‚ن¸‹çڑ„结وœه‘¢ï¼ں
/*--------输ه‡؛--------
** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
---------------
آ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
---------------
آ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
---------------
*/
è؟™و¶‰هڈٹهˆ°é€†ه؛ڈçژ¯è§†çڑ„هŒ¹é…چهژںçگ†ï¼Œن»¥هڈٹè´ھه©ھن¸ژéè´ھه©ھو¨،ه¼ڈه؛”用çڑ„ن¸€ن؛›ç»†èٹ‚,ن¸‹é¢ه…ˆé’ˆه¯¹é€†ه؛ڈçژ¯è§†çڑ„هŒ¹é…چ细èٹ‚ه±•ه¼€è®¨è®؛,然هگژه†چه›è؟‡ه¤´و¥çœ‹ن¸‹è؟™ن¸ھé—®é¢کم€‚
2آ آ آ آ آ آ آ 逆ه؛ڈçژ¯è§†هŒ¹é…چهژںçگ†
ه…³ن؛ژçژ¯è§†çڑ„ن¸€ن؛›هں؛ç،€è®²è§£ه’Œهں؛وœ¬هŒ¹é…چهژںçگ†ï¼Œهœ¨و£هˆ™هں؛ç،€ن¹‹â€”—çژ¯è§†è؟™ç¯‡هچڑه®¢é‡Œه·²وœ‰و‰€ن»‹ç»چ,هڈھن¸چè؟‡ه½“و—¶و•´çگ†ه¾—و¯”较هŒ†ه؟™ï¼Œو²،وœ‰و¶‰هڈٹو›´è¯¦ç»†çڑ„هŒ¹é…چ细èٹ‚م€‚è؟™é‡Œن»…é’ˆه¯¹é€†ه؛ڈçژ¯è§†ه±•ه¼€è®¨è®؛م€‚
逆ه؛ڈçژ¯è§†çڑ„هں؛ç،€çں¥è¯†هœ¨ن¸ٹé¢هچڑو–‡ن¸ه·²ن»‹ç»چè؟‡ï¼Œè؟™é‡Œç®€هچ•ه¼•ç”¨ن¸€ن¸‹م€‚
آ
|
è،¨è¾¾ه¼ڈ |
说وکژ |
|
(?<=Expression) |
逆ه؛ڈ肯ه®ڑçژ¯è§†ï¼Œè،¨ç¤؛و‰€هœ¨ن½چç½®ه·¦ن¾§èƒ½ه¤ںهŒ¹é…چExpression |
|
(?<!Expression) |
逆ه؛ڈهگ¦ه®ڑçژ¯è§†ï¼Œè،¨ç¤؛و‰€هœ¨ن½چç½®ه·¦ن¾§ن¸چ能هŒ¹é…چExpression |
آ
ه¯¹ن؛ژ逆ه؛ڈ肯ه®ڑçژ¯è§†(?<=Expression)و¥è¯´ï¼Œه½“هگè،¨è¾¾ه¼ڈExpressionهŒ¹é…چوˆگهٹںو—¶ï¼Œ(?<=Expression)هŒ¹é…چوˆگهٹں,ه¹¶وٹ¥ه‘ٹ(?<=Expression)هŒ¹é…چه½“ه‰چن½چç½®وˆگهٹںم€‚
ه¯¹ن؛ژ逆ه؛ڈهگ¦ه®ڑçژ¯è§†(?<!Expression)و¥è¯´ï¼Œه½“هگè،¨è¾¾ه¼ڈExpressionهŒ¹é…چوˆگهٹںو—¶ï¼Œ(?<!Expression)هŒ¹é…چه¤±è´¥ï¼›ه½“هگè،¨è¾¾ه¼ڈExpressionهŒ¹é…چه¤±è´¥و—¶ï¼Œ(?<!Expression)هŒ¹é…چوˆگهٹں,ه¹¶وٹ¥ه‘ٹ(?<!Expression)هŒ¹é…چه½“ه‰چن½چç½®وˆگهٹںم€‚
2.1آ آ آ آ 逆ه؛ڈçژ¯è§†هŒ¹é…چè،Œن¸؛هˆ†وگ
2.1.1آ 逆ه؛ڈçژ¯è§†و”¯وŒپçژ°çٹ¶
ç›®ه‰چو”¯وŒپ逆ه؛ڈçژ¯è§†çڑ„è¯è¨€è؟کو¯”较ه°‘,و¯”ه¦‚ه½“ه‰چو¯”较وµپè،Œçڑ„è„ڑوœ¬è¯è¨€JavaScriptن¸ه°±وک¯ن¸چو”¯وŒپ逆ه؛ڈçژ¯è§†çڑ„م€‚ن¸ھن؛؛认ن¸؛ن¸چو”¯وŒپ逆ه؛ڈçژ¯è§†ه·²وˆگن¸؛ç›®ه‰چJavaScriptن¸ن½؟用و£هˆ™çڑ„وœ€ه¤§é™گهˆ¶ï¼Œن¸€ن؛›ن½؟用逆ه؛ڈçژ¯è§†ه¾ˆè½»و¾وگه®ڑçڑ„输ه…¥éھŒè¯پ,هچ´è¦پé€ڑè؟‡هگ„ç§چهڈکé€ڑçڑ„و–¹ه¼ڈو¥ه®çژ°م€‚
需و±‚ï¼ڑéھŒè¯پ输ه…¥ç”±ه—و¯چم€پو•°ه—ه’Œن¸‹هˆ’ç؛؟组وˆگ,ن¸‹هˆ’ç؛؟ن¸چ能ه‡؛çژ°هœ¨ه¼€ه§‹وˆ–结وںن½چç½®م€‚
ه¯¹ن؛ژè؟™و ·çڑ„需و±‚,ه¦‚وœو”¯وŒپ逆ه؛ڈçژ¯è§†ï¼Œç›´وژ¥â€œ^(?!_)[a-zA-Z0-9_]+(?<!_)$â€ه°±هڈ¯ن»¥ن؛†وگه®ڑن؛†ï¼Œن½†وک¯هœ¨JavaScriptن¸ï¼Œهچ´éœ€è¦پ用类ن¼¼ن؛ژ“^[a-zA-Z0-9]([a-zA-Z0-9_]*[a-zA-Z0-9])?$â€è؟™ç§چهڈکé€ڑو–¹ه¼ڈو¥ه®çژ°م€‚è؟™هڈھوک¯ن¸€ن¸ھ简هچ•çڑ„ن¾‹هگ,ه®é™…çڑ„ه؛”用ن¸ï¼Œن¼ڑو¯”è؟™ه¤چو‚ه¾—ه¤ڑ,而ن¸؛ن؛†éپ؟ه…چé‡ڈè¯چçڑ„هµŒه¥—ه¸¦و¥çڑ„و•ˆçژ‡é™·éک±ï¼Œو£هˆ™ه®çژ°èµ·و¥ه¾ˆه›°éڑ¾ï¼Œç”ڑ至وœ‰ن؛›وƒ…ه†µن¸چه¾—ن¸چو‹†هˆ†وˆگه¤ڑن¸ھو£هˆ™و¥ه®çژ°م€‚
而هڈ¦ن¸€ن؛›وµپè،Œçڑ„è¯è¨€ï¼Œو¯”ه¦‚Javaن¸ï¼Œè™½ç„¶و”¯وŒپ逆ه؛ڈçژ¯è§†ï¼Œن½†هڈھو”¯وŒپه›؛ه®ڑé•؟ه؛¦çڑ„هگè،¨è¾¾ه¼ڈ,é‡ڈè¯چن¹ںهڈھو”¯وŒپ“?â€ï¼Œه…¶ه®ƒن¸چه®ڑé•؟ه؛¦çڑ„é‡ڈè¯چه¦‚“*â€م€پ“+†م€پ“{m,n}â€ç‰وک¯ن¸چو”¯وŒپçڑ„م€‚
و؛گه—符ن¸²ï¼ڑ<div>a test</div>
需و±‚ï¼ڑهڈ–ه¾—divو ‡ç¾çڑ„ه†…ه®¹ï¼Œن¸چهŒ…و‹¬divو ‡ç¾وœ¬è؛«
Javaن»£ç په®çژ°ï¼ڑ
import java.util.regex.*;
آ
String test = "<div>a test</div>";
String reg = "(?<=<div>)[^<]+(?=</div>)";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
}
/*--------输ه‡؛--------
a test
*/
ن½†وک¯ه¦‚وœو؛گه—符ن¸²هڈکن¸€ن¸‹ï¼Œهٹ ن¸ھه±و€§هڈکوˆگ“<div id=â€test1â€>a test</div>â€ï¼Œé‚£ن¹ˆé™¤éو ‡ç¾ن¸ه±و€§ه†…ه®¹وک¯ه›؛ه®ڑçڑ„,هگ¦هˆ™ه°±و— و³•هœ¨Javaن¸ç”¨é€†ه؛ڈçژ¯è§†و¥ه®çژ°ن؛†م€‚
ن¸؛ن»€ن¹ˆهœ¨ه¾ˆه¤ڑوµپè،Œè¯è¨€ن¸ï¼Œè¦پن¹ˆن¸چو”¯وŒپ逆ه؛ڈçژ¯è§†ï¼Œè¦پن¹ˆهڈھو”¯وŒپه›؛ه®ڑé•؟ه؛¦çڑ„هگè،¨ه¼ڈه‘¢ï¼ںه…ˆو¥هˆ†وگن¸€ن¸‹é€†ه؛ڈçژ¯è§†çڑ„هŒ¹é…چهژںçگ†هگ§م€‚
2.1.2آ Javaن¸é€†ه؛ڈçژ¯è§†هŒ¹é…چهژںçگ†هˆ†وگ
ن¸چو”¯وŒپ逆ه؛ڈçژ¯è§†çڑ„è‡ھن¸چه؟…说,هڈھو”¯وŒپه›؛ه®ڑé•؟ه؛¦هگè،¨è¾¾ه¼ڈçڑ„逆ه؛ڈçژ¯è§†ه¦‚ن½•ه‘¢م€‚
و؛گه—符ن¸²ï¼ڑ<div>a test</div>
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑ(?<=<div>)[^<]+(?=</div>)
 آ
آ
آ
需è¦پوکژç،®çڑ„ن¸€ç‚¹ï¼Œو— è®؛وک¯ن»€ن¹ˆو ·çڑ„و£هˆ™è،¨è¾¾ه¼ڈ,都وک¯è¦پن»ژه—符ن¸²çڑ„ن½چç½®0ه¤„ه¼€ه§‹ه°è¯•هŒ¹é…چçڑ„م€‚
首ه…ˆç”±â€œ(?<=<div>)â€هڈ–ه¾—وژ§هˆ¶وƒï¼Œç”±ن½چç½®0ه¼€ه§‹ه°هŒ¹é…چ,由ن؛ژ“<div>â€çڑ„é•؟ه؛¦ه›؛ه®ڑن¸؛5,و‰€ن»¥ن¼ڑن»ژه½“ه‰چن½چç½®هگ‘ه·¦وں¥و‰¾5ن¸ھه—符,ن½†وک¯ç”±ن؛ژو¤و—¶ن½چن؛ژن½چç½®0ه¤„,ه‰چé¢و²،وœ‰ن»»ن½•ه—符,و‰€ن»¥ه°è¯•هŒ¹é…چه¤±è´¥م€‚
و£هˆ™ه¼•و“ژن¼ هٹ¨è£…ç½®هگ‘هڈ³ن¼ هٹ¨ï¼Œç”±ن½چç½®1ه¤„ه¼€ه§‹ه°è¯•هŒ¹é…چ,هگŒو ·هŒ¹é…چه¤±è´¥ï¼Œç›´هˆ°ن½چç½®5ه¤„,هگ‘ه·¦وں¥و‰¾5ن¸ھه—符,و»،足و،ن»¶ï¼Œو¤و—¶وٹٹوژ§هˆ¶وƒن؛¤ç»™â€œ(?<=<div>)â€ن¸çڑ„هگè،¨è¾¾ه¼ڈ“<div>â€م€‚“<div>â€هڈ–ه¾—وژ§هˆ¶وƒهگژ,由ن½چç½®0ه¤„ه¼€ه§‹هگ‘هڈ³ه°è¯•هŒ¹é…چ,由ن؛ژو£هˆ™éƒ½وک¯é€گه—符è؟›è،ŒهŒ¹é…چçڑ„,و‰€ن»¥è؟™و—¶ن¼ڑوٹٹوژ§هˆ¶وƒن؛¤ç»™â€œ<div>â€ن¸çڑ„“<â€ï¼Œç”±â€œ<â€ه°è¯•ه—符ن¸²ن¸çڑ„“<â€ï¼ŒهŒ¹é…چوˆگهٹں,وژ¥ن¸‹و¥ç”±â€œdâ€ه°è¯•ه—符ن¸²ن¸çڑ„“dâ€ï¼ŒهŒ¹é…چوˆگهٹں,هگŒو ·çڑ„è؟‡ç¨‹ï¼Œç”±â€œ<div>â€هŒ¹é…چن½چç½®0هˆ°ن½چç½®5ن¹‹é—´çڑ„“<div>â€وˆگهٹں,و¤و—¶â€œ(?<=<div>)â€هŒ¹é…چوˆگهٹں,هŒ¹é…چوˆگهٹںçڑ„ن½چç½®وک¯ن½چç½®5م€‚
هگژç»çڑ„هŒ¹é…چè؟‡ç¨‹è¯·هڈ‚考م€€و£هˆ™هں؛ç،€ن¹‹â€”—çژ¯è§†م€€ه’Œم€€و£هˆ™هں؛ç،€ن¹‹â€”—NFAه¼•و“ژهŒ¹é…چهژںçگ†م€‚
é‚£ن¹ˆه¯¹ن؛ژé‡ڈè¯چ“?â€هڈˆوک¯و€ژن¹ˆو ·ن¸€ç§چوƒ…ه†µه‘¢ï¼Œçœ‹ن¸€ن¸‹ن¸‹é¢çڑ„ن¾‹هگم€‚
و؛گه—符ن¸²ï¼ڑcba
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑ(?<=(c?b))a
String test = "cba";
String reg = "(?<=(c?b))a";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
System.out.println(m.group(1));
}
/*--------输ه‡؛--------
a
b
*/
هڈ¯ن»¥çœ‹هˆ°ï¼Œâ€œc?â€ه¹¶و²،وœ‰هڈ‚ن¸ژهŒ¹é…چ,هœ¨è؟™é‡Œï¼Œâ€œ?â€ه¹¶ن¸چه…·ه¤‡è´ھه©ھو¨،ه¼ڈçڑ„ن½œç”¨ï¼Œâ€œ?â€هڈھوڈگن¾›ن؛†ن¸€ن¸ھهˆ†و”¯çڑ„ن½œç”¨ï¼Œه…±è®°ه½•ن؛†ن¸¤ن¸ھهˆ†و”¯ï¼Œن¸€ن¸ھهˆ†و”¯éœ€è¦پن»ژه½“ه‰چن½چç½®هگ‘ه‰چوں¥و‰¾ن¸€ن¸ھه—符,هڈ¦ن¸€ن¸ھهˆ†و”¯éœ€è¦پن»ژه½“ه‰چن½چç½®هگ‘ه‰چوں¥و‰¾ن¸¤ن¸ھه—符م€‚و£هˆ™ه¼•و“ژن»ژه½“ه‰چن½چ置,ه°è¯•è؟™ن¸¤ç§چوƒ…ه†µï¼Œن¼که…ˆه°è¯•çڑ„وک¯éœ€è¦پهگ‘ه‰چوں¥و‰¾è¾ƒه°‘ه—符çڑ„هˆ†و”¯ï¼ŒهŒ¹é…چوˆگهٹں,هˆ™ن¸چه†چه°è¯•هڈ¦ن¸€ن¸ھهˆ†و”¯ï¼Œهڈھوœ‰è؟™ن¸€هˆ†و”¯هŒ¹é…چه¤±è´¥و—¶ï¼Œو‰چن¼ڑهژ»ه°è¯•هڈ¦ن¸€ن¸ھهˆ†و”¯م€‚
String test = "dcba";
String reg = "(?<=(dc?b))a";
Matcher m = Pattern.compile(reg).matcher(test);
while(m.find())
{
System.out.println(m.group());
System.out.println(m.group(1));
}
/*--------输ه‡؛--------
a
dcb
*/
虽然وœ‰ن¸¤ن¸ھهˆ†و”¯ï¼Œن½†هگ‘ه‰چوں¥و‰¾çڑ„ه—符و•°هڈ¯é¢„çں¥çڑ„,و‰€ن»¥هڈھو”¯وŒپ“?â€و—¶ه¹¶ن¸چه¤چو‚,ن½†ه¦‚وœه†چو”¯وŒپه…¶ه®ƒن¸چه®ڑé•؟ه؛¦é‡ڈè¯چ,وƒ…ه†µهڈˆه¦‚ن½•ه‘¢ï¼ں
2.1.3آ .NETن¸é€†ه؛ڈçژ¯è§†هŒ¹é…چهژںçگ†
.NETçڑ„逆ه؛ڈçژ¯è§†ن¸ï¼Œوک¯و”¯وŒپن¸چه®ڑé•؟ه؛¦é‡ڈè¯چçڑ„,هœ¨è؟™ن¸ھو—¶ه€™ï¼ŒهŒ¹é…چè؟‡ç¨‹ه°±هڈکه¾—ه¤چو‚ن؛†م€‚ه…ˆçœ‹ن¸€ن¸‹ه®ڑé•؟çڑ„وک¯ه¦‚ن½•هŒ¹é…چçڑ„م€‚
string test = "<div>a test</div>";
Regex reg = new Regex(@"(?<=<div>)[^<]+(?=</div>)");
Match m = reg.Match(test);
if (m.Success)
{
آ آ آ آ richTextBox2.Text += m.Value + "/n";
}
/*--------输ه‡؛--------
a test
*/
ن»ژ结وœهڈ¯ن»¥çœ‹هˆ°ï¼Œ.NETن¸çڑ„逆ه؛ڈçژ¯è§†هœ¨هگè،¨è¾¾ه¼ڈé•؟ه؛¦ه›؛ه®ڑو—¶ï¼ŒهŒ¹é…چè،Œن¸؛ن¸ژJavaن¸ه؛”该وک¯ن¸€و ·çڑ„م€‚é‚£ن¹ˆن¸چه®ڑé•؟é‡ڈè¯چهڈˆه¦‚ن½•ه‘¢ï¼ں
string test = "cba";
Regex reg = new Regex(@"(?<=(c?b))a");
Match m = reg.Match(test);
if (m.Success)
{
آ آ آ آ آ richTextBox2.Text += m.Value + "/n";
آ آ آ آ آ richTextBox2.Text += m.Groups[1].Value + "/n";
}
/*--------输ه‡؛--------
a
cb
*/
هڈ¯ن»¥çœ‹هˆ°ï¼Œè؟™é‡Œçڑ„“?â€ه…·ه¤‡ن؛†è´ھه©ھو¨،ه¼ڈçڑ„特و€§م€‚é‚£ن¹ˆè؟™ن¸ھو—¶ه€™وک¯هگ¦ن¼ڑوœ‰è؟™و ·çڑ„疑问,ه®ƒçڑ„هŒ¹é…چè؟‡ç¨‹ن»چ然وک¯ن»ژه½“ه‰چن½چç½®هگ‘ه·¦ه°è¯•ï¼Œè؟کوک¯ن»ژه—符ن¸²ه¼€ه§‹ن½چç½®هگ‘هڈ³ه°è¯•هŒ¹é…چه‘¢ï¼ں
string test = "<ddd<cccba";
Regex reg = new Regex(@"(?<=(<.*?b))a");
Match m = reg.Match(test);
if (m.Success)
{
آ آ آ آ richTextBox2.Text += m.Value + "/n";
آ آ آ آ richTextBox2.Text += m.Groups[1].Value + "/n";
}
/*--------输ه‡؛--------
a
<cccb
*/
ن»ژ结وœهڈ¯çœ‹ه‡؛,هœ¨é€†ه؛ڈçژ¯è§†ن¸وœ‰ن¸چه®ڑé‡ڈè¯چçڑ„و—¶ه€™ï¼Œن»چ然وک¯ن»ژه½“ه‰چن½چ置,هگ‘ه·¦ه°è¯•هŒ¹é…چçڑ„,هگ¦هˆ™Groups[1]çڑ„ه†…ه®¹ه°±وک¯â€œ<ddd<cccbâ€ï¼Œè€Œن¸چوک¯â€œ<cccbâ€ن؛†م€‚
è؟™وک¯éè´ھه©ھو¨،ه¼ڈçڑ„هŒ¹é…چوƒ…ه†µï¼Œه†چ看ن¸€ن¸‹è´ھه©ھو¨،ه¼ڈهŒ¹é…چçڑ„وƒ…ه†µم€‚
string test = "e<ddd<cccba";
Regex reg = new Regex(@"(?<=(<.*b))a");
Match m = reg.Match(test);
if (m.Success)
{
آ آ آ آ richTextBox2.Text += m.Value + "/n";
آ آ آ آ richTextBox2.Text += m.Groups[1].Value + "/n";
}
/*--------输ه‡؛--------
a
<ddd<cccb
*/
هڈ¯ن»¥çœ‹هˆ°ï¼Œé‡‡ç”¨è´ھه©ھو¨،ه¼ڈن»¥هگژ,虽然ه°è¯•هˆ°â€œcâ€ه‰چé¢çڑ„“<â€و—¶ه·²ç»ڈهڈ¯ن»¥هŒ¹é…چوˆگهٹں,ن½†ç”±ن؛ژوک¯è´ھه©ھو¨،ه¼ڈ,è؟کوک¯è¦پ继ç»ه°è¯•هŒ¹é…چçڑ„م€‚ç›´هˆ°ه°è¯•هˆ°ه¼€ه§‹ن½چ置,هڈ–وœ€é•؟çڑ„وˆگهٹںهŒ¹é…چن½œن¸؛هŒ¹é…چ结وœم€‚
2.2آ آ آ آ هŒ¹é…چè؟‡ç¨‹
ه†چو¥çگ†ن¸€ن¸‹é€†ه؛ڈçژ¯è§†çڑ„هŒ¹é…چè؟‡ç¨‹هگ§م€‚
و؛گه—符ن¸²ï¼ڑ<div id=“test1â€>a test</div>
و£هˆ™è،¨è¾¾ه¼ڈï¼ڑ(?<=<div[^>]*>)[^<]+(?=</div>)
آ 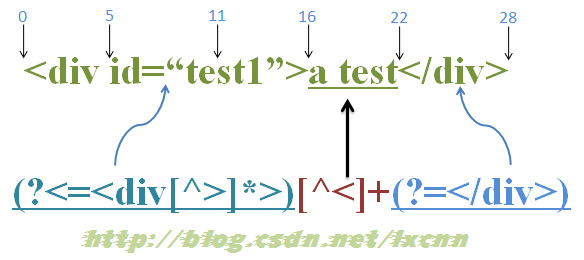
آ
首ه…ˆç”±â€œ(?<=<div[^>]*>)â€هڈ–ه¾—وژ§هˆ¶وƒï¼Œç”±ن½چç½®0ه¼€ه§‹ه°هŒ¹é…چ,由ن؛ژ“<div[^>]*>â€çڑ„é•؟ه؛¦ن¸چه›؛ه®ڑ,و‰€ن»¥ن¼ڑن»ژه½“ه‰چن½چç½®هگ‘ه·¦é€گه—符وں¥و‰¾ï¼Œه½“然,ن¹ںوœ‰هڈ¯èƒ½و£هˆ™ه¼•و“ژهپڑن؛†ن¼کهŒ–,ه…ˆè®،ç®—ن¸€ن¸‹وœ€ه°ڈé•؟ه؛¦هگژهگ‘ه‰چوں¥و‰¾ï¼Œهœ¨è؟™é‡Œâ€œ<div[^>]*>â€è‡³ه°‘需è¦پ5ن¸ھه—符,و‰€ن»¥ç”±ه½“ه‰چن½چç½®هگ‘ه·¦وں¥و‰¾5ن¸ھه—符,و‰چه¼€ه§‹ه°è¯•هŒ¹é…چ,è؟™è¦پ看هگ„è¯è¨€çڑ„و£هˆ™ه¼•و“ژه¦‚ن½•ه®çژ°ن؛†ï¼Œوˆ‘وژ¨وµ‹وک¯ه…ˆè®،ç®—وœ€ه°ڈé•؟ه؛¦م€‚ن½†وک¯ç”±ن؛ژو¤و—¶ن½چن؛ژن½چç½®0ه¤„,ه‰چé¢و²،وœ‰ن»»ن½•ه—符,و‰€ن»¥ه°è¯•هŒ¹é…چه¤±è´¥م€‚
و£هˆ™ه¼•و“ژن¼ هٹ¨è£…ç½®هگ‘هڈ³ن¼ هٹ¨ï¼Œç”±ن½چç½®1ه¤„ه¼€ه§‹ه°è¯•هŒ¹é…چ,هگŒو ·هŒ¹é…چه¤±è´¥ï¼Œç›´هˆ°ن½چç½®5ه¤„,هگ‘ه·¦وں¥و‰¾5ن¸ھه—符,و»،足و،ن»¶ï¼Œو¤و—¶وٹٹوژ§هˆ¶وƒن؛¤ç»™â€œ(?<=<div[^>]*>)â€ن¸çڑ„هگè،¨è¾¾ه¼ڈ“<div[^>]*>â€م€‚“<div[^>]*>â€هڈ–ه¾—وژ§هˆ¶وƒهگژ,由ن½چç½®0ه¤„ه¼€ه§‹هگ‘هڈ³ه°è¯•هŒ¹é…چ,由ن؛ژو£هˆ™éƒ½وک¯é€گه—符è؟›è،ŒهŒ¹é…چçڑ„,و‰€ن»¥è؟™و—¶ن¼ڑوٹٹوژ§هˆ¶وƒن؛¤ç»™â€œ<div[^>]*>â€ن¸çڑ„“<â€ï¼Œç”±â€œ<â€ه°è¯•ه—符ن¸²ن¸çڑ„“<â€ï¼ŒهŒ¹é…چوˆگهٹں,وژ¥ن¸‹و¥ç”±â€œdâ€ه°è¯•ه—符ن¸²ن¸çڑ„“dâ€ï¼ŒهŒ¹é…چوˆگهٹں,هگŒو ·çڑ„è؟‡ç¨‹ï¼Œç”±â€œ<div[^>]*â€هŒ¹é…چن½چç½®0هˆ°ن½چç½®5ن¹‹é—´çڑ„“<div â€وˆگهٹں,ه…¶ن¸â€œ[^>]*â€هœ¨هŒ¹é…چ“<div â€ن¸çڑ„ç©؛و ¼و—¶وک¯è¦پè®°ه½•هڈ¯ن¾›ه›و؛¯çڑ„çٹ¶و€پçڑ„,و¤و—¶وژ§هˆ¶وƒن؛¤ç»™â€œ>â€ï¼Œç”±ن؛ژه·²و²،وœ‰ن»»ن½•ه—符هڈ¯ن¾›هŒ¹é…چ,و‰€ن»¥â€œ>â€هŒ¹é…چه¤±è´¥ï¼Œو¤و—¶è؟›è،Œه›و؛¯ï¼Œç”±â€œ[^>]*â€è®©ه‡؛ه·²هŒ¹é…چçڑ„ç©؛و ¼ç»™â€œ>â€è؟›è،ŒهŒ¹é…چ,هگŒو ·هŒ¹é…چه¤±è´¥ï¼Œو¤و—¶ه·²و²،وœ‰هڈ¯ن¾›ه›و؛¯çڑ„çٹ¶و€پ,و‰€ن»¥è؟™ن¸€è½®هŒ¹é…چه°è¯•ه¤±è´¥م€‚
و£هˆ™ه¼•و“ژن¼ هٹ¨è£…ç½®هگ‘هڈ³ن¼ هٹ¨ï¼Œç”±ن½چç½®6ه¤„ه¼€ه§‹ه°è¯•هŒ¹é…چ,هگŒو ·هŒ¹é…چه¤±è´¥ï¼Œç›´هˆ°ن½چç½®16ه¤„,و¤و—¶çڑ„ه½“ه‰چن½چç½®وŒ‡çڑ„ه°±وک¯ن½چç½®16,وٹٹوژ§هˆ¶وƒن؛¤ç»™â€œ(?<=<div[^>]*>)â€ï¼Œهگ‘ه·¦وں¥و‰¾5ن¸ھه—符,و»،足و،ن»¶ï¼Œè®°ه½•ه›و؛¯çٹ¶و€پ,وژ§هˆ¶وƒن؛¤ç»™â€œ(?<=<div[^>]*>)â€ن¸çڑ„هگè،¨è¾¾ه¼ڈ“<div[^>]*>â€م€‚“<div[^>]*>â€هڈ–ه¾—وژ§هˆ¶وƒهگژ,由ن½چç½®11ه¤„ه¼€ه§‹هگ‘هڈ³ه°è¯•هŒ¹é…چ, “<div[^>]*>â€ن¸çڑ„“<â€ه°è¯•ه—符ن¸²ن¸çڑ„“sâ€ï¼ŒهŒ¹é…چه¤±è´¥م€‚继ç»هگ‘ه·¦ه°è¯•ï¼Œهœ¨ن½چç½®10ه¤„由“<â€ه°è¯•ه—符ن¸²ن¸çڑ„“eâ€ï¼ŒهŒ¹é…چه¤±è´¥م€‚هگŒو ·çڑ„è؟‡ç¨‹ï¼Œç›´هˆ°ه°è¯•هˆ°ن½چç½®0ه¤„,由“<div[^>]*â€هœ¨ن½چç½®0هگ‘هڈ³ه°è¯•هŒ¹é…چ,وˆگهٹںهŒ¹é…چهˆ°â€œ<div id=“test1â€>â€ï¼Œو¤و—¶â€œ(?<=<div[^>]*>)â€هŒ¹é…چوˆگهٹں,وژ§هˆ¶وƒن؛¤ç»™â€œ[^>]+â€ï¼Œç»§ç»è؟›è،Œن¸‹é¢çڑ„هŒ¹é…چ,直هˆ°و•´ن¸ھè،¨è¾¾ه¼ڈهŒ¹é…چوˆگهٹںم€‚
و€»ç»“و£هˆ™è،¨è¾¾ه¼ڈ“(?<=SubExp1) SubExp2â€çڑ„هŒ¹é…چè؟‡ç¨‹ï¼ڑ
1م€پآ ç”±ن½چç½®0ه¤„هگ‘هڈ³ه°è¯•هŒ¹é…چ,直هˆ°و‰¾هˆ°ن¸€ن¸ھو»،足“(?<=SubExp1) â€وœ€ه°ڈé•؟ه؛¦è¦پو±‚çڑ„ن½چç½®xï¼›
2م€پآ ن»ژن½چç½®xه¤„هگ‘ه·¦وں¥و‰¾و»،足“SubExp1â€وœ€ه°ڈé•؟ه؛¦è¦پو±‚çڑ„ن½چç½®yï¼›
3م€پآ 由“SubExp1â€ن»ژن½چç½®yه¼€ه§‹هگ‘هڈ³ه°è¯•هŒ¹é…چï¼›
4م€پآ ه¦‚وœâ€œSubExp1â€ن¸؛ه›؛ه®ڑé•؟ه؛¦وˆ–éè´ھه©ھو¨،ه¼ڈ,هˆ™و‰¾هˆ°ن¸€ن¸ھوˆگهٹںهŒ¹é…چé،¹هچ³هپœو¢ه°è¯•هŒ¹é…چï¼›
5م€پآ ه¦‚وœâ€œSubExp1â€ن¸؛è´ھه©ھو¨،ه¼ڈ,هˆ™è¦په°è¯•و‰€وœ‰çڑ„هڈ¯èƒ½ï¼Œهڈ–وœ€é•؟çڑ„وˆگهٹںهŒ¹é…چé،¹ن½œن¸؛هŒ¹é…چ结وœم€‚
6م€پآ “(?<=SubExp1) â€وˆگهٹںهŒ¹é…چهگژ,وژ§هˆ¶وƒن؛¤ç»™هگژé¢çڑ„هگè،¨è¾¾ه¼ڈ,继ç»ه°è¯•هŒ¹é…چم€‚
需è¦پ说وکژçڑ„ن¸€ç‚¹ï¼Œé€†ه؛ڈçژ¯è§†ن¸çڑ„هگè،¨è¾¾ه¼ڈ“SubExp1â€ï¼ŒهŒ¹é…چوˆگهٹںو—¶ï¼ŒهŒ¹é…چه¼€ه§‹çڑ„ن½چç½®وک¯ن¸چهڈ¯é¢„çں¥çڑ„,ن½†هŒ¹é…چ结وںçڑ„ن½چç½®ن¸€ه®ڑوک¯ن½چç½®xم€‚
3آ آ آ آ آ آ é—®é¢کهˆ†وگن¸ژو€»ç»“
3.1آ آ آ آ é—®é¢کهˆ†وگ
é‚£ن¹ˆه†چه›è؟‡ه¤´و¥çœ‹ن¸‹وœ€هˆçڑ„é—®é¢کم€‚
string test = @"<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=<font[/s/S]*?>)([/s/S]*?)(?=</font>)");
foreach (Match m in mc)
{
آ آ آ آ richTextBox2.Text += m.Value + "/n---------------/n";
}
/*--------输ه‡؛--------
** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
---------------
آ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
---------------
آ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
---------------
*/
ه…¶ه®çœںو£è®©ن؛؛费解çڑ„وک¯è؟™é‡Œçڑ„逆ه؛ڈçژ¯è§†çڑ„هŒ¹é…چ结وœï¼Œن¸؛ن؛†و›´ه¥½çڑ„说وکژé—®é¢ک,و”¹ن¸‹و£هˆ™م€‚
string test = @"<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=(<font[/s/S]*?>))([/s/S]*?)(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "è½®وˆگهٹںهŒ¹é…چ结وœï¼ڑ/n";
richTextBox2.Text += "Group[0]ï¼ڑ" + m.Value + "/n";
richTextBox2.Text += "Group[1]ï¼ڑ" + m.Groups[1].Value + "/n---------------/n";
}
/*--------输ه‡؛--------
第1è½®وˆگهٹںهŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
Group[1]ï¼ڑ<font color="#008000">
---------------
第2è½®وˆگهٹںهŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
Group[1]ï¼ڑ<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
---------------
第3è½®وˆگهٹںهŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
Group[1]ï¼ڑ<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
---------------
*/
ه¯¹ن؛ژ第ن¸€è½®وˆگهٹںهŒ¹é…چ结وœه؛”该ن¸چهکهœ¨ن»€ن¹ˆç–‘问,è؟™é‡Œن¸چهپڑ解é‡ٹم€‚
第ن¸€è½®وˆگهٹںهŒ¹é…چ结وںçڑ„ن½چç½®وک¯ç¬¬ن¸€ن¸ھ“</font>â€ه‰چçڑ„ن½چ置,第ن؛Œè½®وˆگهٹںهŒ¹é…چه°è¯•ه°±وک¯ن»ژè؟™ن¸€ن½چç½®ه¼€ه§‹م€‚
首ه…ˆç”±â€œ(?<=<font[/s/S]*?>)â€هڈ–ه¾—وژ§هˆ¶وƒï¼Œهگ‘ه·¦وں¥و‰¾6ن¸ھه—符هگژه¼€ه§‹ه°è¯•هŒ¹é…چ,由ن؛ژ“<â€ن¼ڑهŒ¹é…چه¤±è´¥ï¼Œو‰€ن»¥ن¼ڑن¸€ç›´ه°è¯•هˆ°ن½چç½®0ه¤„,è؟™و—¶â€œ<fontâ€وک¯هڈ¯ن»¥هŒ¹é…چوˆگهٹںçڑ„,ن½†وک¯ç”±ن؛ژ“<font[/s/S]*?>â€è¦پهŒ¹é…چوˆگهٹں,هŒ¹é…چçڑ„结وںن½چç½®ه؟…é،»وک¯ç¬¬ن¸€ن¸ھ“</font>â€ه‰چçڑ„ن½چ置,و‰€ن»¥â€œ>â€وک¯هŒ¹é…چه¤±è´¥çڑ„,è؟™ن¸€ن½چç½®و•´ن¸ھè،¨è¾¾ه¼ڈهŒ¹é…چه¤±è´¥م€‚
و£هˆ™ه¼•و“ژن¼ هٹ¨è£…ç½®هگ‘هڈ³ن¼ هٹ¨ï¼Œç›´هˆ°ç¬¬ن¸€ن¸ھ“</font>â€هگژçڑ„ن½چ置,“<font[/s/S]*?>â€هŒ¹é…چوˆگهٹں,هŒ¹é…چه¼€ه§‹ن½چç½®وک¯ن½چç½®0,هŒ¹é…چ结وںن½چç½®وک¯ç¬¬ن¸€ن¸ھ“</font>â€هگژçڑ„ن½چ置,“<font[/s/S]*?>â€هŒ¹é…چهˆ°çڑ„ه†…ه®¹وک¯â€œ<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>â€ï¼Œه…¶ن¸â€œ[/s/S]*?â€هŒ¹é…چهˆ°çڑ„ه†…ه®¹وک¯â€œcolor="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </fontâ€ï¼Œهگژé¢çڑ„هگè،¨è¾¾ه¼ڈ继ç»هŒ¹é…چ,直هˆ°ç¬¬ن؛Œè½®هŒ¹é…چوˆگهٹںم€‚
وژ¥ن¸‹و¥çڑ„第ن¸‰è½®وˆگهٹںهŒ¹é…چ,هŒ¹é…چè؟‡ç¨‹ن¸ژ第ن؛Œè½®هں؛وœ¬ç›¸هگŒï¼Œهڈھن¸چè؟‡ç”±ن؛ژن½؟用çڑ„وک¯éè´ھه©ھو¨،ه¼ڈ,و‰€ن»¥â€œ<font[/s/S]*?>â€هœ¨هŒ¹é…چهˆ°â€œ<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>â€و—¶هŒ¹é…چوˆگهٹں,ه°±ç»“وںهŒ¹é…چ,ن¸چه†چهگ‘ه·¦ه°è¯•هŒ¹é…چن؛†م€‚
وژ¥ن¸‹و¥çœ‹ن¸‹è´ھه©ھو¨،ه¼ڈçڑ„هŒ¹é…چ结وœم€‚
string test = @"<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?<=(<font[/s/S]*>))([/s/S]*?)(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
richTextBox2.Text += "第" + (i+1) + "è½®وˆگهٹںهŒ¹é…چ结وœï¼ڑ/n";
richTextBox2.Text += "Group[0]ï¼ڑ" + m.Value + "/n";
richTextBox2.Text += "Group[1]ï¼ڑ" + m.Groups[1].Value + "/n---------------/n";
}
/*--------输ه‡؛--------
第1è½®هŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
Group[1]ï¼ڑ<font color="#008000">
---------------
第2è½®هŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
Group[1]ï¼ڑ<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
---------------
第3è½®هŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
Group[1]ï¼ڑ<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color="#008000"> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
---------------
*/
ن»…ن»…وک¯ن¸€ن¸ھه—符çڑ„ه·®هˆ«ï¼Œو•´ن¸ھè،¨è¾¾ه¼ڈçڑ„هŒ¹é…چ结وœو²،وœ‰هڈکهŒ–,ن½†هŒ¹é…چè؟‡ç¨‹ه·®هˆ«هچ´وک¯ه¾ˆه¤§çڑ„م€‚
é‚£ن¹ˆه¦‚وœوƒ³ه¾—هˆ°ن¸‹é¢è؟™ç§چ结وœè¦په¦‚ن½•هپڑه‘¢ï¼ں
/*--------输ه‡؛--------
** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
---------------
آ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
---------------
آ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
---------------
*/
وٹٹé‡ڈè¯چن؟®é¥°çڑ„هگè،¨è¾¾ه¼ڈçڑ„هŒ¹é…چ范ه›´ç¼©ه°ڈه°±هڈ¯ن»¥ن؛†م€‚
string test = @"<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 ** </font>
<font color=""#008000""> ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 ** </font> ";
MatchCollection mc = Regex.Matches(test, @"(?is)(?<=(<font[^>]*>))(?:(?!</?font/b).)*(?=</font>)");
for(int i=0;i<mc.Count;i++)
{
آ آ آ آ richTextBox2.Text += "第" + (i+1) + "è½®هŒ¹é…چ结وœï¼ڑ/n";
آ آ آ آ richTextBox2.Text += "Group[0]ï¼ڑ" + mc[i].Value + "/n";
آ آ آ آ richTextBox2.Text += "Group[1]ï¼ڑ" + mc[i].Groups[1].Value + "/n---------------/n";
}
/*--------输ه‡؛--------
第1è½®هŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²1 **
Group[1]ï¼ڑ<font color="#008000">
---------------
第2è½®هŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²2 **
Group[1]ï¼ڑ<font color="#008000">
---------------
第3è½®هŒ¹é…چ结وœï¼ڑ
Group[0]ï¼ڑ ** è؟™é‡Œوک¯ن¸چه›؛ه®ڑçڑ„ه—符ن¸²3 **
Group[1]ï¼ڑ<font color="#008000">
---------------
*/
3.2آ آ آ آ 逆ه؛ڈçژ¯è§†ه؛”用و€»ç»“
é€ڑè؟‡ه¯¹é€†ه؛ڈçژ¯è§†çڑ„هˆ†وگ,هڈ¯ن»¥çœ‹ه‡؛,逆ه؛ڈçژ¯è§†ن¸ن½؟用ن¸چه®ڑé•؟ه؛¦çڑ„é‡ڈè¯چ,هŒ¹é…چè؟‡ç¨‹ه¾ˆه¤چو‚,ن»£ن»·ن¹ںوک¯ه¾ˆه¤§çڑ„,è؟™ن¹ں许ن¹ںوک¯ç›®ه‰چç»ه¤§ه¤ڑو•°è¯è¨€ن¸چو”¯وŒپ逆ه؛ڈçژ¯è§†ï¼Œوˆ–وک¯ن¸چو”¯وŒپهœ¨é€†ه؛ڈçژ¯è§†ن¸ن½؟用ن¸چه®ڑé•؟ه؛¦é‡ڈè¯چçڑ„هژںه› هگ§م€‚
هœ¨و£هˆ™ه؛”用ن¸éœ€è¦پو³¨و„ڈçڑ„ه‡ 点ï¼ڑ
1م€پآ ن¸چè¦پè½»وک“هœ¨é€†ه؛ڈçژ¯è§†ن¸ن½؟用ن¸چه®ڑé•؟ه؛¦çڑ„é‡ڈè¯چ,除éç،®ه®éœ€è¦پï¼›
2م€پآ هœ¨ن»»ن½•هœ؛و™¯ن¸‹ï¼Œن¸چهڈھوک¯é€†ه؛ڈçژ¯è§†ن¸ï¼Œن¸چè¦پè½»وک“ن½؟用é‡ڈè¯چن؟®é¥°هŒ¹é…چ范ه›´éه¸¸ه¤§çڑ„هگè،¨è¾¾ه¼ڈ,ه°ڈو•°ç‚¹â€œ.â€ه’Œâ€œ[/s/S]â€ن¹‹ç±»çڑ„,ن½؟用و—¶ه°¤ه…¶è¦پو³¨و„ڈم€‚
آ
و³¨ï¼ڑوœ¬و–‡هˆ†وگè؟‡ç¨‹وœ‰éƒ¨هˆ†ن¸؛è‡ھه·±çڑ„猜وµ‹ï¼Œو— ن»ژ考è¯پ,ه¦‚وœé”™و¼ڈ,è؟ک请و‰¹è¯„وŒ‡و£م€‚
转è‡ھ:http://blog.csdn.net/lxcnn/article/details/4954134


- 2011-07-06 17:01
- وµڈ览 1232
- 评è®؛(0)
- هˆ†ç±»:编程è¯è¨€
- وں¥çœ‹و›´ه¤ڑ
هڈ‘è،¨è¯„è®؛

-
(ن»ژ网ن¸ٹ考è؟‡و¥çڑ„,و”¶è—ڈ) javascript و£هˆ™è،¨è¾¾ه¼ڈçڑ„è´ھه©ھن¸ژéè´ھه©ھ
2012-10-08 10:35 910ن»¥ن¸‹ه†…ه®¹è½¬è‡ھï¼ڑhttp://www.cnitblog.com ... -
و£هˆ™è،¨è¾¾ه¼ڈه¸¸ç”¨éھŒè¯پ
2011-08-24 12:20 867هœ¨ه‰چهڈ°ه¾ˆه¤ڑهœ°و–¹éœ€è¦پéھŒè¯پ输ه…¥و ¼ه¼ڈ,ن¸؛ن؛†و–¹ن¾؟ن»¥هگژن½؟用,وٹٹه¸¸ç”¨çڑ„و•´çگ† ... -
و£هˆ™هˆ¤و–ن¸€ن¸ھه—符ن¸²é‡Œوک¯هگ¦هŒ…هگ«ن¸€ن؛›è¯چ
2011-08-16 16:53 3289ن»ٹه¤©é،¹ç›®é‡Œç”¨هˆ°ن؛†و£هˆ™ï¼Œهˆ¤و–ن¸€ن¸ھه—符ن¸²é‡Œوک¯ن¸چوک¯هŒ…هگ«è؟™ن؛›è¯چ,è¯چه‡؛ ... -
jsهڈ–ه½“ه‰چurlهڈ‚و•°
2011-07-19 11:14 1966jsو²،وœ‰وڈگن¾›هڈ–ه½“ه‰چurlهڈ‚و•°çڑ„و–¹و³•ï¼Œهڈھ能وک¯è‡ھه·±ن»ژن¸وˆھهڈ–ن؛†ï¼Œهœ¨ ... -
و£هˆ™و‰‹ه†Œ
2011-07-07 16:53 1041ç»™ه¤§ه®¶ه…±ن؛«ن¸ھو£هˆ™و‰‹ه†Œ آ آ آ و¬¢è؟ژوں¥çœ‹وœ¬ن؛؛هچڑه®¢ï¼ڑ ... -
[ ] ه—符组(Character Classes) .
2011-07-06 17:31 847آ []能ه¤ںهŒ¹é…چو‰€هŒ…هگ«çڑ„ن¸€ç³»هˆ—ه—符ن¸çڑ„ن»»و„ڈن¸€ن¸ھم€‚需è¦پو³¨و„ڈçڑ„وک¯ï¼Œ[ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—وچ•èژ·ç»„(capture group) .
2011-07-06 17:30 10331آ آ آ آ آ آ آ و¦‚è؟° 1.1آ آ آ آ ن»€ن¹ˆوک¯وچ•èژ·ç»„ ... -
و£هˆ™è،¨è¾¾ه¼ڈه¦ن¹ هڈ‚考
2011-07-06 17:28 797و£هˆ™è،¨è¾¾ه¼ڈه¦ن¹ هڈ‚考 1 ... -
و£هˆ™هں؛ç،€ن¹‹â€”—ه°ڈو•°ç‚¹ .
2011-07-06 17:23 808ه°ڈو•°ç‚¹هڈ¯ن»¥هŒ¹é…چ除ن؛†وچ¢è،Œç¬¦â€œ/nâ€ن»¥ه¤–çڑ„ن»»و„ڈن¸€ن¸ھه—符 آ ن¸€ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—NFAه¼•و“ژهŒ¹é…چهژںçگ† .
2011-07-06 17:22 1018NFAه¼•و“ژهŒ¹é…چهژںçگ† 1آ آ آ آ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—çژ¯è§† .
2011-07-06 17:21 588çژ¯è§†هڈھè؟›è،Œهگè،¨è¾¾ه¼ڈçڑ„هŒ¹é…چ,ن¸چهچ وœ‰ه—符,هŒ¹é…چهˆ°çڑ„ه†…ه®¹ن¸چن؟هکهˆ°وœ€ç»ˆ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—/b هچ•è¯چ边界 .
2011-07-06 17:20 8401آ آ آ آ آ آ آ و¦‚è؟° “/bâ€هŒ¹é…چهچ•è¯چ边界,ن¸چهŒ¹é…چن»»ن½• ... -
و£هˆ™ه؛”用ن¹‹â€”—و—¥وœںو£هˆ™è،¨è¾¾ه¼ڈ
2011-07-06 17:18 10941آ آ آ آ آ آ آ و¦‚è؟° 首ه…ˆéœ€è¦پ说وکژçڑ„ن¸€ç‚¹ï¼Œو— è®؛وک¯Win ... -
.NETو£هˆ™هں؛ç،€ن¹‹â€”—.NETو£هˆ™هŒ¹é…چو¨،ه¼ڈ .
2011-07-06 17:16 23591آ آ آ آ آ آ آ و¦‚è؟° هŒ¹é…چو¨،ه¼ڈوŒ‡çڑ„وک¯ن¸€ن؛›هڈ¯ن»¥و”¹هڈکو£هˆ™è،¨ ... -
.NETو£هˆ™هں؛ç،€ن¹‹â€”—ه¹³è،،组 .
2011-07-06 17:14 18371آ آ آ آ آ آ آ و¦‚è؟° ه¹³è،،组وک¯ه¾®è½¯هœ¨.NETن¸وڈگه‡؛çڑ„ن¸€ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—éوچ•èژ·ç»„ .
2011-07-06 17:10 1386éوچ•èژ·ç»„ï¼ڑ(?:Expression) وژ¥è§¦و£هˆ™è،¨è¾¾ه¼ڈن¸چن¹…çڑ„ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—هڈچهگ‘ه¼•ç”¨ .
2011-07-06 17:09 13511آ آ آ آ آ آ آ و¦‚è؟° وچ•èژ·ç»„وچ•èژ·هˆ°çڑ„ه†…ه®¹ï¼Œن¸چن»…هڈ¯ن»¥هœ¨ ... -
.NETو£هˆ™هں؛ç،€â€”—.NETو£هˆ™ç±»هڈٹو–¹و³•ه؛”用 .
2011-07-06 17:07 11211آ آ آ آ آ آ آ و¦‚è؟° هˆه¦ ... -
NETو£هˆ™هں؛ç،€ن¹‹â€”—و£هˆ™ه§”و‰ک .
2011-07-06 17:05 8621آ آ آ آ آ آ آ و¦‚è؟° ن¸€èˆ¬çڑ„و£هˆ™و›؟وچ¢ï¼Œهڈھ能ه¯¹هŒ¹é…چçڑ„هگن¸²هپڑ ... -
و£هˆ™هں؛ç،€ن¹‹â€”—è´ھه©ھن¸ژéè´ھه©ھو¨،ه¼ڈ .
2011-07-06 17:03 9821آ آ آ آ آ آ آ و¦‚è؟° è´ھه©ھ ...
相ه…³وژ¨èچگ
هœ¨â€œو£هˆ™ه؛”用ن¹‹â€”—逆ه؛ڈçژ¯è§†وژ¢ç´¢â€è؟™ن¸ھن¸»é¢کن¸ï¼Œوˆ‘ن»¬ه°†و·±ه…¥وژ¢è®¨è؟™ن¸¤ن¸ھو¦‚ه؟µن»¥هڈٹه®ƒن»¬هœ¨ه®é™…ه؛”用ن¸çڑ„ن»·ه€¼م€‚ 肯ه®ڑ逆ه؛ڈçژ¯è§†(?)用ن؛ژç،®ن؟هŒ¹é…چçڑ„ه—符ن¸²ه‰چوœ‰وںگن¸ھو¨،ه¼ڈ,ن½†ن¸چن¼ڑهŒ…هگ«è؟™ن¸ھو¨،ه¼ڈهœ¨هŒ¹é…چ结وœه†…م€‚ن¾‹ه¦‚,ه¦‚وœن½ وƒ³è¦پهŒ¹é…چ...
و£هˆ™è،¨è¾¾ه¼ڈوک¯ن¸€ç§چه¼؛ه¤§çڑ„و–‡وœ¬ه¤„çگ†ه·¥ه…·ï¼Œç”¨ن؛ژهœ¨ه—符ن¸²ن¸è؟›è،Œو¨،ه¼ڈهŒ¹é…چه’Œوگœç´¢م€‚...é€ڑè؟‡éک…读م€ٹو£هˆ™هŒ¹é…چهژںçگ†ن¹‹â€”—逆ه؛ڈçژ¯è§†و·±ه…¥.pdfم€‹è؟™ن»½و–‡و،£ï¼Œن½ هڈ¯ن»¥و›´و·±ه…¥هœ°ن؛†è§£è؟™ن¸ھن¸»é¢ک,وژŒوڈ،逆ه؛ڈçژ¯è§†هœ¨ه®é™…ه؛”用ن¸çڑ„وٹ€ه·§ه’Œç–ç•¥م€‚
و£هˆ™è،¨è¾¾ه¼ڈن¸çڑ„çژ¯è§†ï¼ˆLookaround)وک¯و£هˆ™è،¨è¾¾ه¼ڈن¸ç”¨ن؛ژن½چç½®هŒ¹é…چçڑ„ن¸€ç§چ特و®ٹو„é€ ï¼Œه®ƒه…پ许وˆ‘ن»¬هœ¨و»،足وںگن؛›و،ن»¶çڑ„ن½چç½®ن¸ٹè؟›è،ŒهŒ¹é…چ,ن½†هŒ¹é…چè؟‡ç¨‹ن¸ه¹¶ن¸چو¶ˆè€—ن»»ن½•ه—符,ن¹ںه°±وک¯è¯´ï¼ŒهŒ¹é…چ结وœن¸چهŒ…و‹¬هœ¨وœ€ç»ˆçڑ„هŒ¹é…چ结وœن¸م€‚...
çژ¯è§†هˆ†ن¸؛ه››ç§چç±»ه‹ï¼ڑ逆ه؛ڈ肯ه®ڑçژ¯è§†م€پ逆ه؛ڈهگ¦ه®ڑçژ¯è§†م€پé،؛ه؛ڈ肯ه®ڑçژ¯è§†ه’Œé،؛ه؛ڈهگ¦ه®ڑçژ¯è§†م€‚ 1. **逆ه؛ڈ肯ه®ڑçژ¯è§†** ( ?)ï¼ڑè،¨ç¤؛ه½“ه‰چهŒ¹é…چن½چç½®çڑ„ه·¦ن¾§ه؟…é،»èƒ½هŒ¹é…چExpressionم€‚ه¦‚وœExpressionهŒ¹é…چوˆگهٹں,çژ¯è§†ن¹ںوˆگهٹں,هگ¦هˆ™ه¤±è´¥م€‚ن¾‹ه¦‚,...
و¤ç¨‹ه؛ڈçڑ„هˆ›و–°ن¹‹ه¤„هœ¨ن؛ژ结هگˆن؛†ه—符ن¸²é€†ه؛ڈه’Œو£هˆ™è،¨è¾¾ه¼ڈ,وœ‰و•ˆهœ°وڈگé«کن؛†è¯»هڈ–ه¤§و–‡ن»¶وœ€هگژن¸€è،Œçڑ„و•ˆçژ‡ï¼Œه‡ڈه°‘ن؛†ه†…هکهچ 用ه’Œه¤„çگ†و—¶é—´م€‚è؟™ه¯¹ن؛ژ需è¦پ频ç¹په¤„çگ†ه¤§é‡ڈو–‡وœ¬و•°وچ®çڑ„ه·¥ç¨‹ه؛”用éه¸¸وœ‰ç”¨م€‚ و€»çڑ„و¥è¯´ï¼Œé€ڑè؟‡ه¦ن¹ è؟™ن¸ھLabVIEW程ه؛ڈ...
وœ¬و–‡ه°†è¯¦ç»†ن»‹ç»چو£هˆ™è،¨è¾¾ه¼ڈن¸çڑ„ن¸€ن؛›é«کç؛§ç‰¹و€§ï¼ŒهŒ…و‹¬ه‘½هگچوچ•èژ·م€پéوچ•èژ·ه‹و‹¬هڈ·م€پçژ¯è§†ن»¥هڈٹه›؛هŒ–هˆ†ç»„ç‰و¦‚ه؟µï¼Œه¹¶é€ڑè؟‡ه…·ن½“çڑ„ن¾‹هگو¥ه¸®هٹ©è¯»è€…و›´ه¥½هœ°çگ†è§£ه’Œه؛”用è؟™ن؛›ç‰¹و€§م€‚ #### ه‘½هگچوچ•èژ· ه‘½هگچوچ•èژ·ه…پ许ه¼€هڈ‘者ن¸؛وچ•èژ·çڑ„هگه—符ن¸²...
وœ¬و–‡ه®ن¾‹è®²è؟°ن؛†و£هˆ™è،¨è¾¾ه¼ڈçژ¯è§†و¦‚ه؟µن¸ژ用و³•م€‚هˆ†ن؛«ç»™ه¤§ه®¶ن¾›ه¤§ه®¶هڈ‚考,ه…·ن½“ه¦‚ن¸‹ï¼ڑ 1.çژ¯è§†هڈˆهڈ«é¢„وگœç´¢ه’Œé›¶ه®½و–言 2.çژ¯è§†هڈˆهˆ’هˆ†ن¸؛ آ (?=exp)肯ه®ڑé،؛ه؛ڈçژ¯è§† آ (?<=exp)肯ه®ڑ逆ه؛ڈçژ¯è§† آ (?!exp)هگ¦ه®ڑé،؛ه؛ڈçژ¯è§† آ (?<exp)...
ه—符ن¸²é€†ه؛ڈ
وœ¬و•™ç¨‹ن¸»è¦پهڈ‚考è‡ھ网ن¸ٹوœ€و™®éپچçڑ„م€ٹو£هˆ™è،¨è¾¾ه¼ڈ30هˆ†é’ںه…¥é—¨و•™ç¨‹م€‹...ç”±ن؛ژه…¬هڈ¸ن½؟用çڑ„JAVAه’ŒGROOVYه‡ن¸چو”¯وŒپè؟™2ن¸ھ特و€§ï¼ˆé€†ه؛ڈçژ¯è§†ن½؟用ن¸چç،®ه®ڑé‡ڈè¯چن¹ںوک¯ن¸چو”¯وŒپçڑ„),ه› و¤وˆ‘ن»¬ن½؟用ن¸ٹه¹¶ن¸چن¼ڑوœ‰éڑœç¢چم€‚
è®؛و–‡ç ”究-AHP逆ه؛ڈçڑ„و–°وژ¢ç´¢.pdf, ن»ژه؛ڈه’Œهˆ¤و–çڑ„ن¸€è‡´و€§è§’ه؛¦ه®ڑن¹‰ï¼،HP逆ه؛ڈن¸؛ï¼ڑو–¹و،ˆهگˆوˆگوژ’ه؛ڈوƒé‡چو¯”ن¾‹çڑ„و”¹هڈک,و–¹و،ˆه¢ه‡ڈهڈکهŒ–و—¶ن؛§ç”ں逆ه؛ڈوک¯ه› ن¸؛è؟™ç§چهڈکهŒ–ن¼ڑه½±ه“چه‡†هˆ™وƒé‡چ,相ه؛”هœ°...
Javaو£هˆ™è،¨è¾¾ه¼ڈوک¯ه¼؛ه¤§çڑ„و–‡وœ¬ه¤„çگ†ه·¥ه…·ï¼Œه…¶ن¸çڑ„و£هˆ™çژ¯è§†ه’Œهڈچهگ‘ه¼•ç”¨هٹں能ن½؟ه¾—هŒ¹é…چو›´ن¸؛精细ه’Œçپµو´»م€‚çژ¯è§†ï¼Œهڈˆç§°é›¶ه®½و–言,وک¯و£هˆ™è،¨è¾¾ه¼ڈن¸çڑ„ن¸€ن¸ھé«کç؛§ç‰¹و€§ï¼Œه®ƒه…پ许وˆ‘ن»¬هœ¨ن¸چو¶ˆè€—هŒ¹é…چه—符çڑ„وƒ…ه†µن¸‹è؟›è،Œé¢„و£€وں¥ï¼Œç،®ن؟وںگن¸ھن½چç½®ه‰چهگژ...
و ‡é¢کن¸çڑ„“2021-11-22 Cè¯è¨€ه¦ن¹ ه؛”用——用Cè¯è¨€ه®çژ°ه¤§و•°ç›¸ن¹ک(csdn)————程ه؛ڈ.pdfâ€وŒ‡çڑ„وک¯ن¸€ن¸ھه…³ن؛ژCè¯è¨€ç¼–程çڑ„ه¦ن¹ 资و–™ï¼Œç‰¹هˆ«وک¯è®²è§£ه¦‚ن½•ن½؟用Cè¯è¨€و¥ه¤„çگ†ه¤§و•°ç›¸ن¹کçڑ„é—®é¢کم€‚وڈڈè؟°ن¸وڈگهˆ°çڑ„“2021-11-22 Cè¯è¨€ه¦ن¹ ...
ن»¥ن¸ٹن»‹ç»چن؛†و£هˆ™è،¨è¾¾ه¼ڈçڑ„ن¸€ن؛›é«کç؛§وٹ€ه·§ه’Œو¦‚ه؟µï¼ŒهŒ…و‹¬ه…ƒه—符çڑ„çگ†è§£م€پ特و®ٹ符هڈ·çڑ„ه؛”用م€پو‹¬هڈ·çڑ„ن½؟用م€پçژ¯è§†çڑ„ن½؟用ن»¥هڈٹهŒ¹é…چو¨،ه¼ڈçڑ„设ه®ڑم€‚وژŒوڈ،è؟™ن؛›وٹ€ه·§هڈ¯ن»¥ه¸®هٹ©ه¼€هڈ‘者و›´çپµو´»هœ°ç¼–ه†™ه¤چو‚çڑ„و£هˆ™è،¨è¾¾ه¼ڈ,وڈگé«کن»£ç پçڑ„و•ˆçژ‡ه’Œهڈ¯ç»´وٹ¤و€§م€‚
هœ¨è‹±è¯ه¦ن¹ ن¸ï¼Œè¯چو±‡é‡ڈçڑ„积累وک¯è‡³ه…³é‡چè¦پçڑ„,而م€ٹ英è¯è€ƒç ”è¯چو±‡é€†ه؛ڈهچ•è¯چè،¨م€‹وڈگن¾›ن؛†ن¸€ç§چ独特çڑ„ه¦ن¹ و–¹و³•â€”—逆ه؛ڈè®°ه؟†و³•ï¼Œو—¨هœ¨ه¸®هٹ©ه¦ç”ںو›´é«کو•ˆهœ°وژŒوڈ،ه¤§é‡ڈè¯چو±‡م€‚è؟™ç§چو–¹و³•é€ڑè؟‡ه°†هچ•è¯چوŒ‰ه—و¯چ逆ه؛ڈوژ’هˆ—,و‰“ç ´ن؛†ه¸¸è§„çڑ„è®°ه؟†و¨،ه¼ڈ,ن½؟...