еүҚиЁҖ
В В дёҖиҲ¬иҖҢиЁҖпјҢж Үйўҳеҗ«жңүвҖңз§’жқҖвҖқпјҢвҖң99%вҖқпјҢвҖңеҸІдёҠжңҖе…Ё/жңҖејәвҖқзӯүиҜҚжұҮзҡ„еҫҖеҫҖйғҪи„ұдёҚдәҶе“—дј—еҸ–е® д№Ӣе«ҢпјҢдҪҶиҝӣдёҖжӯҘжқҘи®ІпјҢеҰӮжһңиҜ»иҖ…иҜ»зҪўжӯӨж–ҮпјҢеҚҙж— д»»дҪ•ж”¶иҺ·пјҢйӮЈд№ҲпјҢжҲ‘д№ҹз”ҳж„ҝиғҢиҙҹиҝҷж ·зҡ„зҪӘеҗҚпјҢ:-)пјҢеҗҢж—¶пјҢжӯӨж–ҮеҸҜд»ҘзңӢеҒҡжҳҜеҜ№иҝҷзҜҮж–Үз« пјҡеҚҒйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺеҚҒдёӘж–№жі•еӨ§жҖ»з»“зҡ„дёҖиҲ¬жҠҪиұЎжҖ§жҖ»з»“гҖӮ
В В жҜ•з«ҹеҸ—ж–Үз« е’ҢзҗҶи®әд№ӢйҷҗпјҢжң¬ж–Үе°Ҷж‘’ејғз»қеӨ§йғЁеҲҶзҡ„з»ҶиҠӮпјҢеҸӘи°Ҳж–№жі•/жЁЎејҸи®әпјҢдё”жіЁйҮҚз”ЁжңҖйҖҡдҝ—жңҖзӣҙзҷҪзҡ„иҜӯиЁҖйҳҗиҝ°зӣёе…ій—®йўҳгҖӮжңҖеҗҺпјҢжңүдёҖзӮ№еҝ…йЎ»ејәи°ғзҡ„жҳҜпјҢе…Ёж–ҮиЎҢж–ҮжҳҜеҹәдәҺйқўиҜ•йўҳзҡ„еҲҶжһҗеҹәзЎҖд№ӢдёҠзҡ„пјҢе…·дҪ“е®һи·өиҝҮзЁӢдёӯпјҢиҝҳжҳҜеҫ—е…·дҪ“жғ…еҶөе…·дҪ“еҲҶжһҗпјҢдё”еңәжҷҜд№ҹиҝңжҜ”жң¬ж–ҮжүҖиҝ°зҡ„д»»дҪ•дёҖз§Қжғ…еҶөеӨҚжқӮеҫ—еӨҡгҖӮ
В В OKпјҢиӢҘжңүд»»дҪ•й—®йўҳпјҢж¬ўиҝҺйҡҸж—¶дёҚеҗқиөҗж•ҷгҖӮи°ўи°ўгҖӮ
дҪ•и°“жө·йҮҸж•°жҚ®еӨ„зҗҶпјҹ
В В жүҖи°“жө·йҮҸж•°жҚ®еӨ„зҗҶпјҢж— йқһе°ұжҳҜеҹәдәҺжө·йҮҸж•°жҚ®дёҠзҡ„еӯҳеӮЁгҖҒеӨ„зҗҶгҖҒж“ҚдҪңгҖӮдҪ•и°“жө·йҮҸпјҢе°ұжҳҜж•°жҚ®йҮҸеӨӘеӨ§пјҢжүҖд»ҘеҜјиҮҙиҰҒд№ҲжҳҜж— жі•еңЁиҫғзҹӯж—¶й—ҙеҶ…иҝ…йҖҹи§ЈеҶіпјҢиҰҒд№ҲжҳҜж•°жҚ®еӨӘеӨ§пјҢеҜјиҮҙж— жі•дёҖж¬ЎжҖ§иЈ…е…ҘеҶ…еӯҳгҖӮ
В В В йӮЈи§ЈеҶіеҠһжі•е‘ў?й’ҲеҜ№ж—¶й—ҙпјҢжҲ‘们еҸҜд»ҘйҮҮз”Ёе·§еҰҷзҡ„з®—жі•жҗӯй…ҚеҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„пјҢеҰӮBloom filter/Hash/bit-map/е Ҷ/ж•°жҚ®еә“жҲ–еҖ’жҺ’зҙўеј•/trieж ‘пјҢй’ҲеҜ№з©әй—ҙпјҢж— йқһе°ұдёҖдёӘеҠһжі•пјҡеӨ§иҖҢеҢ–е°ҸпјҡеҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„пјҢдҪ дёҚжҳҜиҜҙ规模еӨӘеӨ§еҳӣпјҢйӮЈз®ҖеҚ•е•ҠпјҢе°ұжҠҠ规模еӨ§еҢ–дёә规模е°Ҹзҡ„пјҢеҗ„дёӘеҮ»з ҙдёҚе°ұе®ҢдәҶеҳӣгҖӮ
В В В иҮідәҺжүҖи°“зҡ„еҚ•жңәеҸҠйӣҶзҫӨй—®йўҳпјҢйҖҡдҝ—зӮ№жқҘи®ІпјҢеҚ•жңәе°ұжҳҜеӨ„зҗҶиЈ…иҪҪж•°жҚ®зҡ„жңәеҷЁжңүйҷҗ(еҸӘиҰҒиҖғиҷ‘cpuпјҢеҶ…еӯҳпјҢзЎ¬зӣҳзҡ„ж•°жҚ®дәӨдә’)пјҢиҖҢйӣҶзҫӨпјҢжңәеҷЁжңүеӨҡиҫҶпјҢйҖӮеҗҲеҲҶеёғејҸеӨ„зҗҶпјҢ并иЎҢи®Ўз®—(жӣҙеӨҡиҖғиҷ‘иҠӮзӮ№е’ҢиҠӮзӮ№й—ҙзҡ„ж•°жҚ®дәӨдә’)гҖӮ
В В В еҶҚиҖ…пјҢйҖҡиҝҮжң¬blogеҶ…зҡ„жңүе…іжө·йҮҸж•°жҚ®еӨ„зҗҶзҡ„ж–Үз« пјҡBig Data ProcessingпјҢжҲ‘们已з»ҸеӨ§иҮҙзҹҘйҒ“пјҢеӨ„зҗҶжө·йҮҸж•°жҚ®й—®йўҳпјҢж— йқһе°ұжҳҜпјҡ
В
- еҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„ + hashз»ҹи®Ў + е Ҷ/еҝ«йҖҹ/еҪ’并жҺ’еәҸпјӣ
- еҸҢеұӮжЎ¶еҲ’еҲҶ
- Bloom filter/Bitmapпјӣ
- Trieж ‘/ж•°жҚ®еә“/еҖ’жҺ’зҙўеј•пјӣ
- еӨ–жҺ’еәҸпјӣ
- еҲҶеёғејҸеӨ„зҗҶд№ӢHadoop/MapreduceгҖӮ
В В дёӢйқўпјҢжң¬ж–Ү第дёҖйғЁеҲҶгҖҒд»Һset/mapи°ҲеҲ°hashtable/hash_map/hash_setпјҢз®ҖиҰҒд»Ӣз»ҚдёӢset/map/multiset/multimapпјҢеҸҠhash_set/hash_map/hash_multiset/hash_multimapд№ӢеҢәеҲ«(дёҮдёҲй«ҳжҘје№іең°иө·пјҢеҹәзЎҖжңҖйҮҚиҰҒ)пјҢиҖҢжң¬ж–Ү第дәҢйғЁеҲҶпјҢеҲҷй’ҲеҜ№дёҠиҝ°йӮЈ6з§Қж–№жі•жЁЎејҸз»“еҗҲеҜ№еә”зҡ„жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳеҲҶеҲ«е…·дҪ“йҳҗиҝ°гҖӮ
В
第дёҖйғЁеҲҶгҖҒд»Һset/mapи°ҲеҲ°hashtable/hash_map/hash_set
В В зЁҚеҗҺжң¬ж–Ү第дәҢйғЁеҲҶдёӯе°ҶеӨҡж¬ЎжҸҗеҲ°hash_map/hash_setпјҢдёӢйқўзЁҚзЁҚд»Ӣз»ҚдёӢиҝҷдәӣе®№еҷЁпјҢд»ҘдҪңдёәеҹәзЎҖеҮҶеӨҮгҖӮдёҖиҲ¬жқҘиҜҙпјҢSTLе®№еҷЁеҲҶдёӨз§ҚпјҢ
- еәҸеҲ—ејҸе®№еҷЁ(vector/list/deque/stack/queue/heap)пјҢ
- е…іиҒ”ејҸе®№еҷЁгҖӮе…іиҒ”ејҸе®№еҷЁеҸҲеҲҶдёәset(йӣҶеҗҲ)е’Ңmap(жҳ е°„иЎЁ)дёӨеӨ§зұ»пјҢд»ҘеҸҠиҝҷдёӨеӨ§зұ»зҡ„иЎҚз”ҹдҪ“multiset(еӨҡй”®йӣҶеҗҲ)е’Ңmultimap(еӨҡй”®жҳ е°„иЎЁ)пјҢиҝҷдәӣе®№еҷЁеқҮд»ҘRB-treeе®ҢжҲҗгҖӮжӯӨеӨ–пјҢиҝҳжңү第3зұ»е…іиҒ”ејҸе®№еҷЁпјҢеҰӮhashtable(ж•ЈеҲ—иЎЁ)пјҢд»ҘеҸҠд»Ҙhashtableдёәеә•еұӮжңәеҲ¶е®ҢжҲҗзҡ„hash_set(ж•ЈеҲ—йӣҶеҗҲ)/hash_map(ж•ЈеҲ—жҳ е°„иЎЁ)/hash_multiset(ж•ЈеҲ—еӨҡй”®йӣҶеҗҲ)/hash_multimap(ж•ЈеҲ—еӨҡй”®жҳ е°„иЎЁ)гҖӮд№ҹе°ұжҳҜиҜҙпјҢset/map/multiset/multimapйғҪеҶ…еҗ«дёҖдёӘRB-treeпјҢиҖҢhash_set/hash_map/hash_multiset/hash_multimapйғҪеҶ…еҗ«дёҖдёӘhashtableгҖӮ
В В жүҖи°“е…іиҒ”ејҸе®№еҷЁпјҢзұ»дјје…іиҒ”ејҸж•°жҚ®еә“пјҢжҜҸ笔数жҚ®жҲ–жҜҸдёӘе…ғзҙ йғҪжңүдёҖдёӘй”®еҖј(key)е’ҢдёҖдёӘе®һеҖј(value)пјҢеҚіжүҖи°“зҡ„Key-Value(й”®-еҖјеҜ№)гҖӮеҪ“е…ғзҙ иў«жҸ’е…ҘеҲ°е…іиҒ”ејҸе®№еҷЁдёӯж—¶пјҢе®№еҷЁеҶ…йғЁз»“жһ„(RB-tree/hashtable)дҫҝдҫқз…§е…¶й”®еҖјеӨ§е°ҸпјҢд»Ҙжҹҗз§Қзү№е®ҡ规еҲҷе°ҶиҝҷдёӘе…ғзҙ ж”ҫзҪ®дәҺйҖӮеҪ“дҪҚзҪ®гҖӮ
В В В еҢ…жӢ¬еңЁйқһе…іиҒ”ејҸж•°жҚ®еә“дёӯпјҢжҜ”еҰӮпјҢеңЁMongoDBеҶ…пјҢж–ҮжЎЈ(document)жҳҜжңҖеҹәжң¬зҡ„ж•°жҚ®з»„з»ҮеҪўејҸпјҢжҜҸдёӘж–ҮжЎЈд№ҹжҳҜд»ҘKey-ValueпјҲй”®-еҖјеҜ№пјүзҡ„ж–№ејҸз»„з»Үиө·жқҘгҖӮдёҖдёӘж–ҮжЎЈеҸҜд»ҘжңүеӨҡдёӘKey-Valueз»„еҗҲпјҢжҜҸдёӘValueеҸҜд»ҘжҳҜдёҚеҗҢзҡ„зұ»еһӢпјҢжҜ”еҰӮStringгҖҒIntegerгҖҒListзӯүзӯүгҖӮВ
{ "name" : "July", В
В "sex" : "male", В
В В "age" : 23 } В
В
set/map/multiset/multimap
В В setпјҢеҗҢmapдёҖж ·пјҢжүҖжңүе…ғзҙ йғҪдјҡж №жҚ®е…ғзҙ зҡ„й”®еҖјиҮӘеҠЁиў«жҺ’еәҸпјҢеӣ дёәset/mapдёӨиҖ…зҡ„жүҖжңүеҗ„з§Қж“ҚдҪңпјҢйғҪеҸӘжҳҜиҪ¬иҖҢи°ғз”ЁRB-treeзҡ„ж“ҚдҪңиЎҢдёәпјҢдёҚиҝҮпјҢеҖјеҫ—жіЁж„Ҹзҡ„жҳҜпјҢдёӨиҖ…йғҪдёҚе…Ғи®ёдёӨдёӘе…ғзҙ жңүзӣёеҗҢзҡ„й”®еҖјгҖӮ
В В дёҚеҗҢзҡ„жҳҜпјҡsetзҡ„е…ғзҙ дёҚеғҸmapйӮЈж ·еҸҜд»ҘеҗҢж—¶жӢҘжңүе®һеҖј(value)е’Ңй”®еҖј(key)пјҢsetе…ғзҙ зҡ„й”®еҖје°ұжҳҜе®һеҖјпјҢе®һеҖје°ұжҳҜй”®еҖјпјҢиҖҢmapзҡ„жүҖжңүе…ғзҙ йғҪжҳҜpairпјҢеҗҢж—¶жӢҘжңүе®һеҖј(value)е’Ңй”®еҖј(key)пјҢpairзҡ„第дёҖдёӘе…ғзҙ иў«и§Ҷдёәй”®еҖјпјҢ第дәҢдёӘе…ғзҙ иў«и§Ҷдёәе®һеҖјгҖӮ
В В иҮідәҺmultiset/multimapпјҢ他们зҡ„зү№жҖ§еҸҠз”Ёжі•е’Ңset/mapе®Ңе…ЁзӣёеҗҢпјҢе”ҜдёҖзҡ„е·®еҲ«е°ұеңЁдәҺе®ғ们е…Ғи®ёй”®еҖјйҮҚеӨҚпјҢеҚіжүҖжңүзҡ„жҸ’е…Ҙж“ҚдҪңеҹәдәҺRB-treeзҡ„insert_equal()иҖҢйқһinsert_unique()гҖӮ
hash_set/hash_map/hash_multiset/hash_multimap
В В hash_set/hash_mapпјҢдёӨиҖ…зҡ„дёҖеҲҮж“ҚдҪңйғҪжҳҜеҹәдәҺhashtableд№ӢдёҠгҖӮдёҚеҗҢзҡ„жҳҜпјҢhash_setеҗҢsetдёҖж ·пјҢеҗҢж—¶жӢҘжңүе®һеҖје’Ңй”®еҖјпјҢдё”е®һиҙЁе°ұжҳҜй”®еҖјпјҢй”®еҖје°ұжҳҜе®һеҖјпјҢиҖҢhash_mapеҗҢmapдёҖж ·пјҢжҜҸдёҖдёӘе…ғзҙ еҗҢж—¶жӢҘжңүдёҖдёӘе®һеҖј(value)е’ҢдёҖдёӘй”®еҖј(key)пјҢжүҖд»Ҙе…¶дҪҝз”Ёж–№ејҸпјҢе’ҢдёҠйқўзҡ„mapеҹәжң¬зӣёеҗҢгҖӮдҪҶз”ұдәҺhash_set/hash_mapйғҪжҳҜеҹәдәҺhashtableд№ӢдёҠпјҢжүҖд»ҘдёҚе…·еӨҮиҮӘеҠЁжҺ’еәҸеҠҹиғҪгҖӮдёәд»Җд№Ҳ?еӣ дёәhashtableжІЎжңүиҮӘеҠЁжҺ’еәҸеҠҹиғҪгҖӮ
В В иҮідәҺhash_multiset/hash_multimapзҡ„зү№жҖ§дёҺдёҠйқўзҡ„multiset/multimapе®Ңе…ЁзӣёеҗҢпјҢе”ҜдёҖзҡ„е·®еҲ«е°ұжҳҜе®ғ们hash_multiset/hash_multimapзҡ„еә•еұӮе®һзҺ°жңәеҲ¶жҳҜhashtable(иҖҢmultiset/multimapпјҢдёҠйқўиҜҙдәҶпјҢеә•еұӮе®һзҺ°жңәеҲ¶жҳҜRB-tree)пјҢжүҖд»Ҙе®ғ们зҡ„е…ғзҙ йғҪдёҚдјҡиў«иҮӘеҠЁжҺ’еәҸпјҢдёҚиҝҮд№ҹйғҪе…Ғи®ёй”®еҖјйҮҚеӨҚгҖӮ
В В жүҖд»ҘпјҢз»јдёҠпјҢиҜҙзҷҪдәҶпјҢд»Җд№Ҳж ·зҡ„з»“жһ„еҶіе®ҡе…¶д»Җд№Ҳж ·зҡ„жҖ§иҙЁпјҢеӣ дёәset/map/multiset/multimapйғҪжҳҜеҹәдәҺRB-treeд№ӢдёҠпјҢжүҖд»ҘжңүиҮӘеҠЁжҺ’еәҸеҠҹиғҪпјҢиҖҢhash_set/hash_map/hash_multiset/hash_multimapйғҪжҳҜеҹәдәҺhashtableд№ӢдёҠпјҢжүҖд»ҘдёҚеҗ«жңүиҮӘеҠЁжҺ’еәҸеҠҹиғҪпјҢиҮідәҺеҠ дёӘеүҚзјҖmulti_ж— йқһе°ұжҳҜе…Ғи®ёй”®еҖјйҮҚеӨҚиҖҢе·ІгҖӮ
В В жӯӨеӨ–пјҢ
В В OKпјҢжҺҘдёӢжқҘпјҢиҜ·зңӢжң¬ж–Ү第дәҢйғЁеҲҶгҖҒеӨ„зҗҶжө·йҮҸж•°жҚ®й—®йўҳд№Ӣе…ӯжҠҠеҜҶеҢҷгҖӮ
В
第дәҢйғЁеҲҶгҖҒеӨ„зҗҶжө·йҮҸж•°жҚ®й—®йўҳд№Ӣе…ӯжҠҠеҜҶеҢҷ
еҜҶеҢҷдёҖгҖҒеҲҶиҖҢжІ»д№Ӣ/Hashжҳ е°„ + Hashз»ҹи®Ў + е Ҷ/еҝ«йҖҹ/еҪ’并жҺ’еәҸ
1гҖҒжө·йҮҸж—Ҙеҝ—ж•°жҚ®пјҢжҸҗеҸ–еҮәжҹҗж—Ҙи®ҝй—®зҷҫеәҰж¬Ўж•°жңҖеӨҡзҡ„йӮЈдёӘIPгҖӮ
  既然жҳҜжө·йҮҸж•°жҚ®еӨ„зҗҶпјҢйӮЈд№ҲеҸҜжғіиҖҢзҹҘпјҢз»ҷжҲ‘们зҡ„ж•°жҚ®йӮЈе°ұдёҖе®ҡжҳҜжө·йҮҸзҡ„гҖӮй’ҲеҜ№иҝҷдёӘж•°жҚ®зҡ„жө·йҮҸпјҢжҲ‘们еҰӮдҪ•зқҖжүӢе‘ў?еҜ№зҡ„пјҢж— йқһе°ұжҳҜеҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„ + hashз»ҹи®Ў + е Ҷ/еҝ«йҖҹ/еҪ’并жҺ’еәҸпјҢиҜҙзҷҪдәҶпјҢе°ұжҳҜе…Ҳжҳ е°„пјҢиҖҢеҗҺз»ҹи®ЎпјҢжңҖеҗҺжҺ’еәҸпјҡ
- еҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„пјҡй’ҲеҜ№ж•°жҚ®еӨӘеӨ§пјҢеҶ…еӯҳеҸ—йҷҗпјҢеҸӘиғҪжҳҜпјҡжҠҠеӨ§ж–Ү件еҢ–жҲҗ(еҸ–жЁЎжҳ е°„)е°Ҹж–Ү件пјҢеҚі16еӯ—ж–№й’ҲпјҡеӨ§иҖҢеҢ–е°ҸпјҢеҗ„дёӘеҮ»з ҙпјҢзј©е°Ҹ规模пјҢйҖҗдёӘи§ЈеҶі
- hashз»ҹи®ЎпјҡеҪ“еӨ§ж–Ү件иҪ¬еҢ–дәҶе°Ҹж–Ү件пјҢйӮЈд№ҲжҲ‘们дҫҝеҸҜд»ҘйҮҮ用常规зҡ„hash_map(ipпјҢvalue)жқҘиҝӣиЎҢйў‘зҺҮз»ҹи®ЎгҖӮ
- е Ҷ/еҝ«йҖҹжҺ’еәҸпјҡз»ҹи®Ўе®ҢдәҶд№ӢеҗҺпјҢдҫҝиҝӣиЎҢжҺ’еәҸ(еҸҜйҮҮеҸ–е ҶжҺ’еәҸ)пјҢеҫ—еҲ°ж¬Ўж•°жңҖеӨҡзҡ„IPгҖӮ
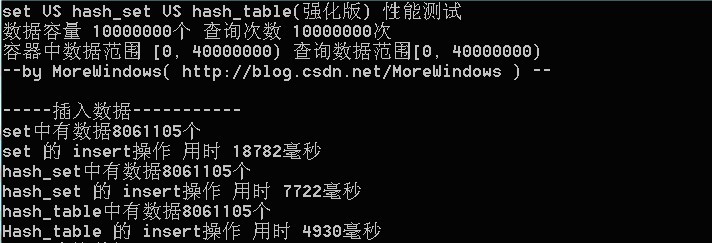
В В е…·дҪ“иҖҢи®әпјҢеҲҷжҳҜпјҡ вҖңйҰ–е…ҲжҳҜиҝҷдёҖеӨ©пјҢ并且жҳҜи®ҝй—®зҷҫеәҰзҡ„ж—Ҙеҝ—дёӯзҡ„IPеҸ–еҮәжқҘпјҢйҖҗдёӘеҶҷе…ҘеҲ°дёҖдёӘеӨ§ж–Ү件дёӯгҖӮжіЁж„ҸеҲ°IPжҳҜ32дҪҚзҡ„пјҢжңҖеӨҡжңүдёӘ2^32дёӘIPгҖӮеҗҢж ·еҸҜд»ҘйҮҮз”Ёжҳ е°„зҡ„ж–№жі•пјҢжҜ”еҰӮжЁЎ1000пјҢжҠҠж•ҙдёӘеӨ§ж–Ү件жҳ е°„дёә1000дёӘе°Ҹж–Ү件пјҢеҶҚжүҫеҮәжҜҸдёӘе°Ҹж–ҮдёӯеҮәзҺ°йў‘зҺҮжңҖеӨ§зҡ„IPпјҲеҸҜд»ҘйҮҮз”Ёhash_mapиҝӣиЎҢйў‘зҺҮз»ҹи®ЎпјҢ然еҗҺеҶҚжүҫеҮәйў‘зҺҮжңҖеӨ§зҡ„еҮ дёӘпјүеҸҠзӣёеә”зҡ„йў‘зҺҮгҖӮ然еҗҺеҶҚеңЁиҝҷ1000дёӘжңҖеӨ§зҡ„IPдёӯпјҢжүҫеҮәйӮЈдёӘйў‘зҺҮжңҖеӨ§зҡ„IPпјҢеҚідёәжүҖжұӮгҖӮвҖқ--еҚҒйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺеҚҒдёӘж–№жі•еӨ§жҖ»з»“гҖӮ
В В е…ідәҺжң¬йўҳпјҢиҝҳжңүеҮ дёӘй—®йўҳпјҢеҰӮдёӢпјҡ
В В В 1гҖҒHashеҸ–жЁЎжҳҜдёҖз§Қзӯүд»·жҳ е°„пјҢдёҚдјҡеӯҳеңЁеҗҢдёҖдёӘе…ғзҙ еҲҶж•ЈеҲ°дёҚеҗҢе°Ҹж–Ү件дёӯеҺ»зҡ„жғ…еҶөпјҢеҚіиҝҷйҮҢйҮҮз”Ёзҡ„жҳҜmod1000з®—жі•пјҢйӮЈд№ҲзӣёеҗҢзҡ„IPеңЁhashеҗҺпјҢеҸӘеҸҜиғҪиҗҪеңЁеҗҢдёҖдёӘж–Ү件дёӯпјҢдёҚеҸҜиғҪиў«еҲҶж•Јзҡ„гҖӮ
В В В 2гҖҒйӮЈеҲ°еә•д»Җд№ҲжҳҜhashжҳ е°„е‘ўпјҹз®ҖеҚ•жқҘиҜҙпјҢе°ұжҳҜдёәдәҶдҫҝдәҺи®Ўз®—жңәеңЁжңүйҷҗзҡ„еҶ…еӯҳдёӯеӨ„зҗҶbigж•°жҚ®пјҢд»ҺиҖҢйҖҡиҝҮдёҖз§Қжҳ е°„ж•ЈеҲ—зҡ„ж–№ејҸи®©ж•°жҚ®еқҮеҢҖеҲҶеёғеңЁеҜ№еә”зҡ„еҶ…еӯҳдҪҚзҪ®(еҰӮеӨ§ж•°жҚ®йҖҡиҝҮеҸ–дҪҷзҡ„ж–№ејҸжҳ е°„жҲҗе°Ҹж ‘еӯҳж”ҫеңЁеҶ…еӯҳдёӯпјҢжҲ–еӨ§ж–Ү件жҳ е°„жҲҗеӨҡдёӘе°Ҹж–Ү件)пјҢиҖҢиҝҷдёӘжҳ е°„ж•ЈеҲ—ж–№ејҸдҫҝжҳҜжҲ‘们йҖҡеёёжүҖиҜҙзҡ„hashеҮҪж•°пјҢи®ҫи®Ўзҡ„еҘҪзҡ„hashеҮҪж•°иғҪи®©ж•°жҚ®еқҮеҢҖеҲҶеёғиҖҢеҮҸе°‘еҶІзӘҒгҖӮе°Ҫз®Ўж•°жҚ®жҳ е°„еҲ°дәҶеҸҰеӨ–дёҖдәӣдёҚеҗҢзҡ„дҪҚзҪ®пјҢдҪҶж•°жҚ®иҝҳжҳҜеҺҹжқҘзҡ„ж•°жҚ®пјҢеҸӘжҳҜд»Јжӣҝе’ҢиЎЁзӨәиҝҷдәӣеҺҹе§Ӣж•°жҚ®зҡ„еҪўејҸеҸ‘з”ҹдәҶеҸҳеҢ–иҖҢе·ІгҖӮ
В В жӯӨеӨ–пјҢжңүдёҖжңӢеҸӢquicktestз”ЁpythonиҜӯиЁҖе®һи·өжөӢиҜ•дәҶдёӢжң¬йўҳпјҢең°еқҖеҰӮдёӢпјҡhttp://blog.csdn.net/quicktest/article/details/7453189гҖӮи°ўи°ўгҖӮOKпјҢжңүе…ҙи¶Јзҡ„пјҢиҝҳеҸҜд»ҘеҶҚдәҶи§ЈдёӢдёҖиҮҙжҖ§hashз®—жі•пјҢи§ҒblogеҶ…жӯӨж–Ү第дә”йғЁеҲҶпјҡhttp://blog.csdn.net/v_july_v/article/details/6879101гҖӮ
2гҖҒеҜ»жүҫзғӯй—ЁжҹҘиҜўпјҡжҗңзҙўеј•ж“ҺдјҡйҖҡиҝҮж—Ҙеҝ—ж–Ү件жҠҠз”ЁжҲ·жҜҸж¬ЎжЈҖзҙўдҪҝз”Ёзҡ„жүҖжңүжЈҖзҙўдёІйғҪи®°еҪ•дёӢжқҘпјҢжҜҸдёӘжҹҘиҜўдёІзҡ„й•ҝеәҰдёә1-255еӯ—иҠӮгҖӮ
В В В еҒҮи®ҫзӣ®еүҚжңүдёҖеҚғдёҮдёӘи®°еҪ•пјҲиҝҷдәӣжҹҘиҜўдёІзҡ„йҮҚеӨҚеәҰжҜ”иҫғй«ҳпјҢиҷҪ然жҖ»ж•°жҳҜ1еҚғдёҮпјҢдҪҶеҰӮжһңйҷӨеҺ»йҮҚеӨҚеҗҺпјҢдёҚи¶…иҝҮ3зҷҫдёҮдёӘгҖӮдёҖдёӘжҹҘиҜўдёІзҡ„йҮҚеӨҚеәҰи¶Ҡй«ҳпјҢиҜҙжҳҺжҹҘиҜўе®ғзҡ„з”ЁжҲ·и¶ҠеӨҡпјҢд№ҹе°ұжҳҜи¶Ҡзғӯй—ЁпјүпјҢиҜ·дҪ з»ҹи®ЎжңҖзғӯй—Ёзҡ„10дёӘжҹҘиҜўдёІпјҢиҰҒжұӮдҪҝз”Ёзҡ„еҶ…еӯҳдёҚиғҪи¶…иҝҮ1GгҖӮ
В В з”ұдёҠйқўз¬¬1йўҳпјҢжҲ‘们зҹҘйҒ“пјҢж•°жҚ®еӨ§еҲҷеҲ’дёәе°Ҹзҡ„пјҢдҪҶеҰӮжһңж•°жҚ®и§„жЁЎжҜ”иҫғе°ҸпјҢиғҪдёҖж¬ЎжҖ§иЈ…е…ҘеҶ…еӯҳе‘ў?жҜ”еҰӮиҝҷ第2йўҳпјҢиҷҪ然жңүдёҖеҚғдёҮдёӘQueryпјҢдҪҶжҳҜз”ұдәҺйҮҚеӨҚеәҰжҜ”иҫғй«ҳпјҢеӣ жӯӨдәӢе®һдёҠеҸӘжңү300дёҮзҡ„QueryпјҢжҜҸдёӘQuery255ByteпјҢеӣ жӯӨжҲ‘们еҸҜд»ҘиҖғиҷ‘жҠҠ他们йғҪж”ҫиҝӣеҶ…еӯҳдёӯеҺ»пјҢиҖҢзҺ°еңЁеҸӘжҳҜйңҖиҰҒдёҖдёӘеҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„пјҢеңЁиҝҷйҮҢпјҢHash Tableз»қеҜ№жҳҜжҲ‘们дјҳе…Ҳзҡ„йҖүжӢ©гҖӮжүҖд»ҘжҲ‘们ж”ҫејғеҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„зҡ„жӯҘйӘӨпјҢзӣҙжҺҘдёҠhashз»ҹи®ЎпјҢ然еҗҺжҺ’еәҸгҖӮSoпјҢ
- hashз»ҹи®Ўпјҡе…ҲеҜ№иҝҷжү№жө·йҮҸж•°жҚ®йў„еӨ„зҗҶ(з»ҙжҠӨдёҖдёӘKeyдёәQueryеӯ—дёІпјҢValueдёәиҜҘQueryеҮәзҺ°ж¬Ўж•°зҡ„HashTableпјҢеҚіhash_map(QueryпјҢValue)пјҢжҜҸж¬ЎиҜ»еҸ–дёҖдёӘQueryпјҢеҰӮжһңиҜҘеӯ—дёІдёҚеңЁTableдёӯпјҢйӮЈд№ҲеҠ е…ҘиҜҘеӯ—дёІпјҢ并且е°ҶValueеҖји®ҫдёә1пјӣеҰӮжһңиҜҘеӯ—дёІеңЁTableдёӯпјҢйӮЈд№Ҳе°ҶиҜҘеӯ—дёІзҡ„и®Ўж•°еҠ дёҖеҚіеҸҜгҖӮжңҖз»ҲжҲ‘们еңЁO(N)зҡ„ж—¶й—ҙеӨҚжқӮеәҰеҶ…з”ЁHashиЎЁе®ҢжҲҗдәҶз»ҹи®Ўпјӣ
- е ҶжҺ’еәҸпјҡ第дәҢжӯҘгҖҒеҖҹеҠ©е ҶиҝҷдёӘж•°жҚ®з»“жһ„пјҢжүҫеҮәTop KпјҢж—¶й—ҙеӨҚжқӮеәҰдёәNвҖҳlogKгҖӮеҚіеҖҹеҠ©е Ҷз»“жһ„пјҢжҲ‘们еҸҜд»ҘеңЁlogйҮҸзә§зҡ„ж—¶й—ҙеҶ…жҹҘжүҫе’Ңи°ғж•ҙ/移еҠЁгҖӮеӣ жӯӨпјҢз»ҙжҠӨдёҖдёӘK(иҜҘйўҳзӣ®дёӯжҳҜ10)еӨ§е°Ҹзҡ„е°Ҹж №е ҶпјҢ然еҗҺйҒҚеҺҶ300дёҮзҡ„QueryпјҢеҲҶеҲ«е’Ңж №е…ғзҙ иҝӣиЎҢеҜ№жҜ”жүҖд»ҘпјҢжҲ‘们жңҖз»Ҳзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜпјҡOпјҲNпјү + N'*OпјҲlogKпјүпјҢпјҲNдёә1000дёҮпјҢNвҖҷдёә300дёҮпјүгҖӮ
В В В еҲ«еҝҳдәҶиҝҷзҜҮж–Үз« дёӯжүҖиҝ°зҡ„е ҶжҺ’еәҸжҖқи·ҜпјҡвҖңз»ҙжҠӨkдёӘе…ғзҙ зҡ„жңҖе°Ҹе ҶпјҢеҚіз”Ёе®№йҮҸдёәkзҡ„жңҖе°Ҹе ҶеӯҳеӮЁжңҖе…ҲйҒҚеҺҶеҲ°зҡ„kдёӘж•°пјҢ并еҒҮи®ҫе®ғ们еҚіжҳҜжңҖеӨ§зҡ„kдёӘж•°пјҢе»әе Ҷиҙ№ж—¶OпјҲkпјүпјҢ并и°ғж•ҙе ҶпјҲиҙ№ж—¶OпјҲlogkпјүпјүеҗҺпјҢжңүk1>k2>...kminпјҲkminи®ҫдёәе°ҸйЎ¶е ҶдёӯжңҖе°Ҹе…ғзҙ пјүгҖӮ继з»ӯйҒҚеҺҶж•°еҲ—пјҢжҜҸж¬ЎйҒҚеҺҶдёҖдёӘе…ғзҙ xпјҢдёҺе ҶйЎ¶е…ғзҙ жҜ”иҫғпјҢиӢҘx>kminпјҢеҲҷжӣҙж–°е ҶпјҲз”Ёж—¶logkпјүпјҢеҗҰеҲҷдёҚжӣҙж–°е ҶгҖӮиҝҷж ·дёӢжқҘпјҢжҖ»иҙ№ж—¶OпјҲk*logk+пјҲn-kпјү*logkпјү=OпјҲn*logkпјүгҖӮжӯӨж–№жі•еҫ—зӣҠдәҺеңЁе ҶдёӯпјҢжҹҘжүҫзӯүеҗ„йЎ№ж“ҚдҪңж—¶й—ҙеӨҚжқӮеәҰеқҮдёәlogkгҖӮвҖқ--第дёүз« з»ӯгҖҒTop Kз®—жі•й—®йўҳзҡ„е®һзҺ°гҖӮ
В В В еҪ“然пјҢдҪ д№ҹеҸҜд»ҘйҮҮз”Ёtrieж ‘пјҢе…ій”®еӯ—еҹҹеӯҳиҜҘжҹҘиҜўдёІеҮәзҺ°зҡ„ж¬Ўж•°пјҢжІЎжңүеҮәзҺ°дёә0гҖӮжңҖеҗҺз”Ё10дёӘе…ғзҙ зҡ„жңҖе°ҸжҺЁжқҘеҜ№еҮәзҺ°йў‘зҺҮиҝӣиЎҢжҺ’еәҸгҖӮ
3гҖҒжңүдёҖдёӘ1GеӨ§е°Ҹзҡ„дёҖдёӘж–Ү件пјҢйҮҢйқўжҜҸдёҖиЎҢжҳҜдёҖдёӘиҜҚпјҢиҜҚзҡ„еӨ§е°ҸдёҚи¶…иҝҮ16еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶еӨ§е°ҸжҳҜ1MгҖӮиҝ”еӣһйў‘ж•°жңҖй«ҳзҡ„100дёӘиҜҚгҖӮ
В В В В з”ұдёҠйқўйӮЈдёӨдёӘдҫӢйўҳпјҢеҲҶиҖҢжІ»д№Ӣ + hashз»ҹи®Ў + е Ҷ/еҝ«йҖҹжҺ’еәҸиҝҷдёӘеҘ—и·ҜпјҢжҲ‘们已з»ҸејҖе§ӢжңүдәҶеұЎиҜ•дёҚзҲҪзҡ„ж„ҹи§үгҖӮдёӢйқўпјҢеҶҚжӢҝеҮ йҒ“еҶҚеӨҡеӨҡйӘҢиҜҒдёӢгҖӮиҜ·зңӢжӯӨ第3йўҳпјҡеҸҲжҳҜж–Ү件еҫҲеӨ§пјҢеҸҲжҳҜеҶ…еӯҳеҸ—йҷҗпјҢе’ӢеҠһ?иҝҳиғҪжҖҺд№ҲеҠһе‘ў?ж— йқһиҝҳжҳҜпјҡ
- еҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„пјҡйЎәеәҸиҜ»ж–Ү件дёӯпјҢеҜ№дәҺжҜҸдёӘиҜҚxпјҢеҸ–hash(x)%5000пјҢ然еҗҺжҢүз…§иҜҘеҖјеӯҳеҲ°5000дёӘе°Ҹж–Ү件пјҲи®°дёәx0,x1,...x4999пјүдёӯгҖӮиҝҷж ·жҜҸдёӘж–Ү件еӨ§жҰӮжҳҜ200kе·ҰеҸігҖӮеҰӮжһңе…¶дёӯзҡ„жңүзҡ„ж–Ү件超иҝҮдәҶ1MеӨ§е°ҸпјҢиҝҳеҸҜд»ҘжҢүз…§зұ»дјјзҡ„方法继з»ӯеҫҖдёӢеҲҶпјҢзӣҙеҲ°еҲҶи§Јеҫ—еҲ°зҡ„е°Ҹж–Ү件зҡ„еӨ§е°ҸйғҪдёҚи¶…иҝҮ1MгҖӮ
- hashз»ҹи®ЎпјҡеҜ№жҜҸдёӘе°Ҹж–Ү件пјҢйҮҮз”Ёtrieж ‘/hash_mapзӯүз»ҹи®ЎжҜҸдёӘж–Ү件дёӯеҮәзҺ°зҡ„иҜҚд»ҘеҸҠзӣёеә”зҡ„йў‘зҺҮгҖӮ
- е Ҷ/еҪ’并жҺ’еәҸпјҡеҸ–еҮәеҮәзҺ°йў‘зҺҮжңҖеӨ§зҡ„100дёӘиҜҚпјҲеҸҜд»Ҙз”Ёеҗ«100дёӘз»“зӮ№зҡ„жңҖе°Ҹе ҶпјүпјҢ并жҠҠ100дёӘиҜҚеҸҠзӣёеә”зҡ„йў‘зҺҮеӯҳе…Ҙж–Ү件пјҢиҝҷж ·еҸҲеҫ—еҲ°дәҶ5000дёӘж–Ү件гҖӮжңҖеҗҺе°ұжҳҜжҠҠиҝҷ5000дёӘж–Ү件иҝӣиЎҢеҪ’并пјҲзұ»дјјдәҺеҪ’并жҺ’еәҸпјүзҡ„иҝҮзЁӢдәҶгҖӮ
4гҖҒжө·йҮҸж•°жҚ®еҲҶеёғеңЁ100еҸ°з”өи„‘дёӯпјҢжғідёӘеҠһжі•й«ҳж•Ҳз»ҹи®ЎеҮәиҝҷжү№ж•°жҚ®зҡ„TOP10гҖӮ
В В жӯӨйўҳдёҺдёҠйқўз¬¬3йўҳзұ»дјјпјҢ
- е ҶжҺ’еәҸпјҡеңЁжҜҸеҸ°з”өи„‘дёҠжұӮеҮәTOP10пјҢеҸҜд»ҘйҮҮз”ЁеҢ…еҗ«10дёӘе…ғзҙ зҡ„е Ҷе®ҢжҲҗпјҲTOP10е°ҸпјҢз”ЁжңҖеӨ§е ҶпјҢTOP10еӨ§пјҢз”ЁжңҖе°Ҹе ҶпјүгҖӮжҜ”еҰӮжұӮTOP10еӨ§пјҢжҲ‘们йҰ–е…ҲеҸ–еүҚ10дёӘе…ғзҙ и°ғж•ҙжҲҗжңҖе°Ҹе ҶпјҢеҰӮжһңеҸ‘зҺ°пјҢ然еҗҺжү«жҸҸеҗҺйқўзҡ„ж•°жҚ®пјҢ并дёҺе ҶйЎ¶е…ғзҙ жҜ”иҫғпјҢеҰӮжһңжҜ”е ҶйЎ¶е…ғзҙ еӨ§пјҢйӮЈд№Ҳз”ЁиҜҘе…ғзҙ жӣҝжҚўе ҶйЎ¶пјҢ然еҗҺеҶҚи°ғж•ҙдёәжңҖе°Ҹе ҶгҖӮжңҖеҗҺе Ҷдёӯзҡ„е…ғзҙ е°ұжҳҜTOP10еӨ§гҖӮ
- жұӮеҮәжҜҸеҸ°з”өи„‘дёҠзҡ„TOP10еҗҺпјҢ然еҗҺжҠҠиҝҷ100еҸ°з”өи„‘дёҠзҡ„TOP10з»„еҗҲиө·жқҘпјҢе…ұ1000дёӘж•°жҚ®пјҢеҶҚеҲ©з”ЁдёҠйқўзұ»дјјзҡ„ж–№жі•жұӮеҮәTOP10е°ұеҸҜд»ҘдәҶгҖӮ
В В дёҠиҝ°з¬¬4йўҳзҡ„жӯӨи§Јжі•пјҢз»ҸиҜ»иҖ…еҸҚеә”жңүй—®йўҳпјҢеҰӮдёҫдёӘдҫӢеӯҗеҰӮжұӮ2дёӘж–Ү件дёӯзҡ„top2пјҢз…§дёҠиҝ°з®—жі•пјҢеҰӮжһң第дёҖдёӘж–Ү件йҮҢжңүпјҡ
  第дәҢдёӘж–Ү件йҮҢжңүпјҡ
В В В В В иҷҪ然第дёҖдёӘж–Ү件йҮҢеҮәжқҘtop2жҳҜbпјҲ50ж¬Ўпјү,aпјҲ49ж¬Ўпјү,第дәҢдёӘж–Ү件йҮҢеҮәжқҘtop2жҳҜcпјҲ11ж¬Ўпјү,dпјҲ10ж¬Ўпјү,然еҗҺ2дёӘtop2пјҡbпјҲ50ж¬ЎпјүaпјҲ49ж¬ЎпјүдёҺcпјҲ11ж¬ЎпјүdпјҲ10ж¬ЎпјүеҪ’并пјҢеҲҷз®—еҮәжүҖжңүзҡ„ж–Ү件зҡ„top2жҳҜb(50 ж¬Ў),a(49 ж¬Ў),дҪҶе®һйҷ…дёҠжҳҜa(58 ж¬Ў),b(51 ж¬Ў)гҖӮжҳҜеҗҰзңҹжҳҜеҰӮжӯӨе‘ў?иӢҘзңҹеҰӮжӯӨпјҢйӮЈдҪңдҪ•и§ЈеҶіе‘ўпјҹ
В В жӯЈеҰӮиҖҒжўҰжүҖиҝ°пјҡ
В В йҰ–е…ҲпјҢе…ҲжҠҠжүҖжңүзҡ„ж•°жҚ®йҒҚеҺҶдёҖйҒҚеҒҡдёҖж¬Ўhash(дҝқиҜҒзӣёеҗҢзҡ„ж•°жҚ®жқЎзӣ®еҲ’еҲҶеҲ°еҗҢдёҖеҸ°з”өи„‘дёҠиҝӣиЎҢиҝҗз®—)пјҢ然еҗҺж №жҚ®hashз»“жһңйҮҚж–°еҲҶеёғеҲ°100еҸ°з”өи„‘дёӯпјҢжҺҘдёӢжқҘзҡ„з®—жі•жҢүз…§д№ӢеүҚзҡ„еҚіеҸҜгҖӮ
В В жңҖеҗҺз”ұдәҺaеҸҜиғҪеҮәзҺ°еңЁдёҚеҗҢзҡ„з”өи„‘пјҢеҗ„жңүдёҖе®ҡзҡ„ж¬Ўж•°пјҢеҶҚеҜ№жҜҸдёӘзӣёеҗҢжқЎзӣ®иҝӣиЎҢжұӮе’ҢпјҲз”ұдәҺдёҠдёҖжӯҘйӘӨдёӯhashд№ӢеҗҺпјҢд№ҹж–№дҫҝжҜҸеҸ°з”өи„‘еҸӘйңҖиҰҒеҜ№иҮӘе·ұеҲҶеҲ°зҡ„жқЎзӣ®еҶ…иҝӣиЎҢжұӮе’ҢпјҢдёҚж¶үеҸҠеҲ°еҲ«зҡ„з”өи„‘пјҢ规模缩е°ҸпјүгҖӮ
5гҖҒжңү10дёӘж–Ү件пјҢжҜҸдёӘж–Ү件1GпјҢжҜҸдёӘж–Ү件зҡ„жҜҸдёҖиЎҢеӯҳж”ҫзҡ„йғҪжҳҜз”ЁжҲ·зҡ„queryпјҢжҜҸдёӘж–Ү件зҡ„queryйғҪеҸҜиғҪйҮҚеӨҚгҖӮиҰҒжұӮдҪ жҢүз…§queryзҡ„йў‘еәҰжҺ’еәҸгҖӮ
В В зӣҙжҺҘдёҠпјҡ
- hashжҳ е°„пјҡйЎәеәҸиҜ»еҸ–10дёӘж–Ү件пјҢжҢүз…§hash(query)%10зҡ„з»“жһңе°ҶqueryеҶҷе…ҘеҲ°еҸҰеӨ–10дёӘж–Ү件пјҲи®°дёәпјүдёӯгҖӮиҝҷж ·ж–°з”ҹжҲҗзҡ„ж–Ү件жҜҸдёӘзҡ„еӨ§е°ҸеӨ§зәҰд№ҹ1GпјҲеҒҮи®ҫhashеҮҪж•°жҳҜйҡҸжңәзҡ„пјүгҖӮ
- hashз»ҹи®ЎпјҡжүҫдёҖеҸ°еҶ…еӯҳеңЁ2Gе·ҰеҸізҡ„жңәеҷЁпјҢдҫқж¬ЎеҜ№з”Ёhash_map(query, query_count)жқҘз»ҹи®ЎжҜҸдёӘqueryеҮәзҺ°зҡ„ж¬Ўж•°гҖӮжіЁпјҡhash_map(query,query_count)жҳҜз”ЁжқҘз»ҹи®ЎжҜҸдёӘqueryзҡ„еҮәзҺ°ж¬Ўж•°пјҢдёҚжҳҜеӯҳеӮЁд»–们зҡ„еҖјпјҢеҮәзҺ°дёҖж¬ЎпјҢеҲҷcount+1гҖӮ
- е Ҷ/еҝ«йҖҹ/еҪ’并жҺ’еәҸпјҡеҲ©з”Ёеҝ«йҖҹ/е Ҷ/еҪ’并жҺ’еәҸжҢүз…§еҮәзҺ°ж¬Ўж•°иҝӣиЎҢжҺ’еәҸпјҢе°ҶжҺ’еәҸеҘҪзҡ„queryе’ҢеҜ№еә”зҡ„query_coutиҫ“еҮәеҲ°ж–Ү件дёӯпјҢиҝҷж ·еҫ—еҲ°дәҶ10дёӘжҺ’еҘҪеәҸзҡ„ж–Ү件пјҲи®°дёә
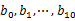 пјүгҖӮжңҖеҗҺпјҢеҜ№иҝҷ10дёӘж–Ү件иҝӣиЎҢеҪ’并жҺ’еәҸпјҲеҶ…жҺ’еәҸдёҺеӨ–жҺ’еәҸзӣёз»“еҗҲпјүгҖӮ
пјүгҖӮжңҖеҗҺпјҢеҜ№иҝҷ10дёӘж–Ү件иҝӣиЎҢеҪ’并жҺ’еәҸпјҲеҶ…жҺ’еәҸдёҺеӨ–жҺ’еәҸзӣёз»“еҗҲпјүгҖӮ
В В В йҷӨжӯӨд№ӢеӨ–пјҢжӯӨйўҳиҝҳжңүд»ҘдёӢдёӨдёӘж–№жі•пјҡ
В В В ж–№жЎҲ2пјҡдёҖиҲ¬queryзҡ„жҖ»йҮҸжҳҜжңүйҷҗзҡ„пјҢеҸӘжҳҜйҮҚеӨҚзҡ„ж¬Ўж•°жҜ”иҫғеӨҡиҖҢе·ІпјҢеҸҜиғҪеҜ№дәҺжүҖжңүзҡ„queryпјҢдёҖж¬ЎжҖ§е°ұеҸҜд»ҘеҠ е…ҘеҲ°еҶ…еӯҳдәҶгҖӮиҝҷж ·пјҢжҲ‘们е°ұеҸҜд»ҘйҮҮз”Ёtrieж ‘/hash_mapзӯүзӣҙжҺҘжқҘз»ҹи®ЎжҜҸдёӘqueryеҮәзҺ°зҡ„ж¬Ўж•°пјҢ然еҗҺжҢүеҮәзҺ°ж¬Ўж•°еҒҡеҝ«йҖҹ/е Ҷ/еҪ’并жҺ’еәҸе°ұеҸҜд»ҘдәҶгҖӮ
В В В ж–№жЎҲ3пјҡдёҺж–№жЎҲ1зұ»дјјпјҢдҪҶеңЁеҒҡе®ҢhashпјҢеҲҶжҲҗеӨҡдёӘж–Ү件еҗҺпјҢеҸҜд»ҘдәӨз»ҷеӨҡдёӘж–Ү件жқҘеӨ„зҗҶпјҢйҮҮз”ЁеҲҶеёғејҸзҡ„жһ¶жһ„жқҘеӨ„зҗҶпјҲжҜ”еҰӮMapReduceпјүпјҢжңҖеҗҺеҶҚиҝӣиЎҢеҗҲ并гҖӮ
6гҖҒ з»ҷе®ҡaгҖҒbдёӨдёӘж–Ү件пјҢеҗ„еӯҳж”ҫ50дәҝдёӘurlпјҢжҜҸдёӘurlеҗ„еҚ 64еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶жҳҜ4GпјҢи®©дҪ жүҫеҮәaгҖҒbж–Ү件е…ұеҗҢзҡ„urlпјҹ
В В еҸҜд»Ҙдј°и®ЎжҜҸдёӘж–Ү件е®үзҡ„еӨ§е°Ҹдёә5GГ—64=320GпјҢиҝңиҝңеӨ§дәҺеҶ…еӯҳйҷҗеҲ¶зҡ„4GгҖӮжүҖд»ҘдёҚеҸҜиғҪе°Ҷе…¶е®Ңе…ЁеҠ иҪҪеҲ°еҶ…еӯҳдёӯеӨ„зҗҶгҖӮиҖғиҷ‘йҮҮеҸ–еҲҶиҖҢжІ»д№Ӣзҡ„ж–№жі•гҖӮ
-
еҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„пјҡйҒҚеҺҶж–Ү件aпјҢеҜ№жҜҸдёӘurlжұӮеҸ–
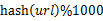 пјҢ然еҗҺж №жҚ®жүҖеҸ–еҫ—зҡ„еҖје°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000дёӘе°Ҹж–Ү件пјҲи®°дёә
пјҢ然еҗҺж №жҚ®жүҖеҸ–еҫ—зҡ„еҖје°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000дёӘе°Ҹж–Ү件пјҲи®°дёә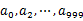 пјүдёӯгҖӮиҝҷж ·жҜҸдёӘе°Ҹж–Ү件зҡ„еӨ§зәҰдёә300MгҖӮйҒҚеҺҶж–Ү件bпјҢйҮҮеҸ–е’ҢaзӣёеҗҢзҡ„ж–№ејҸе°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000е°Ҹж–Ү件дёӯпјҲи®°дёә
пјүдёӯгҖӮиҝҷж ·жҜҸдёӘе°Ҹж–Ү件зҡ„еӨ§зәҰдёә300MгҖӮйҒҚеҺҶж–Ү件bпјҢйҮҮеҸ–е’ҢaзӣёеҗҢзҡ„ж–№ејҸе°ҶurlеҲҶеҲ«еӯҳеӮЁеҲ°1000е°Ҹж–Ү件дёӯпјҲи®°дёә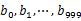 пјүгҖӮиҝҷж ·еӨ„зҗҶеҗҺпјҢжүҖжңүеҸҜиғҪзӣёеҗҢзҡ„urlйғҪеңЁеҜ№еә”зҡ„е°Ҹж–Ү件пјҲ
пјүгҖӮиҝҷж ·еӨ„зҗҶеҗҺпјҢжүҖжңүеҸҜиғҪзӣёеҗҢзҡ„urlйғҪеңЁеҜ№еә”зҡ„е°Ҹж–Ү件пјҲ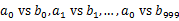 пјүдёӯпјҢдёҚеҜ№еә”зҡ„е°Ҹж–Ү件дёҚеҸҜиғҪжңүзӣёеҗҢзҡ„urlгҖӮ然еҗҺжҲ‘们еҸӘиҰҒжұӮеҮә1000еҜ№е°Ҹж–Ү件дёӯзӣёеҗҢзҡ„urlеҚіеҸҜгҖӮ
пјүдёӯпјҢдёҚеҜ№еә”зҡ„е°Ҹж–Ү件дёҚеҸҜиғҪжңүзӣёеҗҢзҡ„urlгҖӮ然еҗҺжҲ‘们еҸӘиҰҒжұӮеҮә1000еҜ№е°Ҹж–Ү件дёӯзӣёеҗҢзҡ„urlеҚіеҸҜгҖӮ
-
hashз»ҹи®ЎпјҡжұӮжҜҸеҜ№е°Ҹж–Ү件дёӯзӣёеҗҢзҡ„urlж—¶пјҢеҸҜд»ҘжҠҠе…¶дёӯдёҖдёӘе°Ҹж–Ү件зҡ„urlеӯҳеӮЁеҲ°hash_setдёӯгҖӮ然еҗҺйҒҚеҺҶеҸҰдёҖдёӘе°Ҹж–Ү件зҡ„жҜҸдёӘurlпјҢзңӢе…¶жҳҜеҗҰеңЁеҲҡжүҚжһ„е»әзҡ„hash_setдёӯпјҢеҰӮжһңжҳҜпјҢйӮЈд№Ҳе°ұжҳҜе…ұеҗҢзҡ„urlпјҢеӯҳеҲ°ж–Ү件йҮҢйқўе°ұеҸҜд»ҘдәҶгҖӮ
В В OKпјҢжӯӨ第дёҖз§Қж–№жі•пјҡеҲҶиҖҢжІ»д№Ӣ/hashжҳ е°„ + hashз»ҹи®Ў + е Ҷ/еҝ«йҖҹ/еҪ’并жҺ’еәҸпјҢеҶҚзңӢжңҖеҗҺ4йҒ“йўҳпјҢеҰӮдёӢпјҡ
7гҖҒжҖҺд№ҲеңЁжө·йҮҸж•°жҚ®дёӯжүҫеҮәйҮҚеӨҚж¬Ўж•°жңҖеӨҡзҡ„дёҖдёӘпјҹ
В В ж–№жЎҲ1пјҡе…ҲеҒҡhashпјҢ然еҗҺжұӮжЁЎжҳ е°„дёәе°Ҹж–Ү件пјҢжұӮеҮәжҜҸдёӘе°Ҹж–Ү件дёӯйҮҚеӨҚж¬Ўж•°жңҖеӨҡзҡ„дёҖдёӘпјҢ并记еҪ•йҮҚеӨҚж¬Ўж•°гҖӮ然еҗҺжүҫеҮәдёҠдёҖжӯҘжұӮеҮәзҡ„ж•°жҚ®дёӯйҮҚеӨҚж¬Ўж•°жңҖеӨҡзҡ„дёҖдёӘе°ұжҳҜжүҖжұӮпјҲе…·дҪ“еҸӮиҖғеүҚйқўзҡ„йўҳпјүгҖӮ
8гҖҒдёҠеҚғдёҮжҲ–дёҠдәҝж•°жҚ®пјҲжңүйҮҚеӨҚпјүпјҢз»ҹи®Ўе…¶дёӯеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„й’ұNдёӘж•°жҚ®гҖӮ
В В ж–№жЎҲ1пјҡдёҠеҚғдёҮжҲ–дёҠдәҝзҡ„ж•°жҚ®пјҢзҺ°еңЁзҡ„жңәеҷЁзҡ„еҶ…еӯҳеә”иҜҘиғҪеӯҳдёӢгҖӮжүҖд»ҘиҖғиҷ‘йҮҮз”Ёhash_map/жҗңзҙўдәҢеҸүж ‘/зәўй»‘ж ‘зӯүжқҘиҝӣиЎҢз»ҹи®Ўж¬Ўж•°гҖӮ然еҗҺе°ұжҳҜеҸ–еҮәеүҚNдёӘеҮәзҺ°ж¬Ўж•°жңҖеӨҡзҡ„ж•°жҚ®дәҶпјҢеҸҜд»Ҙ用第2йўҳжҸҗеҲ°зҡ„е ҶжңәеҲ¶е®ҢжҲҗгҖӮ
9гҖҒдёҖдёӘж–Үжң¬ж–Ү件пјҢеӨ§зәҰжңүдёҖдёҮиЎҢпјҢжҜҸиЎҢдёҖдёӘиҜҚпјҢиҰҒжұӮз»ҹи®ЎеҮәе…¶дёӯжңҖйў‘з№ҒеҮәзҺ°зҡ„еүҚ10дёӘиҜҚпјҢиҜ·з»ҷеҮәжҖқжғіпјҢз»ҷеҮәж—¶й—ҙеӨҚжқӮеәҰеҲҶжһҗгҖӮ
В В В ж–№жЎҲ1пјҡиҝҷйўҳжҳҜиҖғиҷ‘ж—¶й—ҙж•ҲзҺҮгҖӮз”Ёtrieж ‘з»ҹи®ЎжҜҸдёӘиҜҚеҮәзҺ°зҡ„ж¬Ўж•°пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜO(n*le)пјҲleиЎЁзӨәеҚ•иҜҚзҡ„е№іеҮҶй•ҝеәҰпјүгҖӮ然еҗҺжҳҜжүҫеҮәеҮәзҺ°жңҖйў‘з№Ғзҡ„еүҚ10дёӘиҜҚпјҢеҸҜд»Ҙз”Ёе ҶжқҘе®һзҺ°пјҢеүҚйқўзҡ„йўҳдёӯе·Із»Ҹи®ІеҲ°дәҶпјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜO(n*lg10)гҖӮжүҖд»ҘжҖ»зҡ„ж—¶й—ҙеӨҚжқӮеәҰпјҢжҳҜO(n*le)дёҺO(n*lg10)дёӯиҫғеӨ§зҡ„е“ӘдёҖдёӘгҖӮ
В
В В В 10. 1000дёҮеӯ—з¬ҰдёІпјҢе…¶дёӯжңүдәӣжҳҜйҮҚеӨҚзҡ„пјҢйңҖиҰҒжҠҠйҮҚеӨҚзҡ„е…ЁйғЁеҺ»жҺүпјҢдҝқз•ҷжІЎжңүйҮҚеӨҚзҡ„еӯ—з¬ҰдёІгҖӮиҜ·жҖҺд№Ҳи®ҫи®Ўе’Ңе®һзҺ°пјҹ
В
- ж–№жЎҲ1пјҡиҝҷйўҳз”Ёtrieж ‘жҜ”иҫғеҗҲйҖӮпјҢhash_mapд№ҹиЎҢгҖӮ
-
ж–№жЎҲ2пјҡfrom xjbzju:пјҢ1000wзҡ„ж•°жҚ®и§„жЁЎжҸ’е…Ҙж“ҚдҪңе®Ңе…ЁдёҚзҺ°е®һпјҢд»ҘеүҚиҜ•иҝҮеңЁstlдёӢ100wе…ғзҙ жҸ’е…Ҙsetдёӯе·Із»Ҹж…ўеҫ—дёҚиғҪеҝҚеҸ—пјҢи§үеҫ—еҹәдәҺhashзҡ„е®һзҺ°дёҚдјҡжҜ”зәўй»‘ж ‘еҘҪеӨӘеӨҡпјҢдҪҝз”Ёvector+sort+uniqueйғҪиҰҒеҸҜиЎҢи®ёеӨҡпјҢе»әи®®иҝҳжҳҜе…ҲhashжҲҗе°Ҹж–Ү件еҲҶејҖеӨ„зҗҶеҶҚз»јеҗҲгҖӮ
В В дёҠиҝ°ж–№жЎҲ2дёӯиҜ»иҖ…xbzjuзҡ„ж–№жі•и®©жҲ‘жғіеҲ°дәҶдёҖдәӣй—®йўҳпјҢеҚіжҳҜset/mapпјҢдёҺhash_set/hash_mapзҡ„жҖ§иғҪжҜ”иҫғ?е…ұи®Ў3дёӘй—®йўҳпјҢеҰӮдёӢпјҡ
-
1гҖҒhash_setеңЁеҚғдёҮзә§ж•°жҚ®дёӢпјҢinsertж“ҚдҪңдјҳдәҺset? иҝҷдҪҚblogпјҡhttp://t.cn/zOibP7t з»ҷзҡ„е®һи·өж•°жҚ®еҸҜйқ дёҚ?В
- 2гҖҒйӮЈmapе’Ңhash_mapзҡ„жҖ§иғҪжҜ”иҫғе‘ў? и°ҒеҒҡиҝҮзӣёе…іе®һйӘҢ?
В
В
- 3гҖҒйӮЈжҹҘиҜўж“ҚдҪңе‘ўпјҢеҰӮдёӢж®өж–Үеӯ—жүҖиҝ°?
В

В В жҲ–иҖ…е°Ҹж•°жҚ®йҮҸж—¶з”ЁmapпјҢжһ„йҖ еҝ«пјҢеӨ§ж•°жҚ®йҮҸж—¶з”Ёhash_map?
rbtree PK hashtable
В В жҚ®жңӢеҸӢв„–йӮҰеҚЎзҢ«в„–зҡ„еҒҡзҡ„зәўй»‘ж ‘е’Ңhash tableзҡ„жҖ§иғҪжөӢиҜ•дёӯеҸ‘зҺ°пјҡеҪ“ж•°жҚ®йҮҸеҹәжң¬дёҠintеһӢkeyж—¶пјҢhashВ tableжҳҜrbtreeзҡ„3-4еҖҚпјҢдҪҶhashВ tableдёҖиҲ¬дјҡжөӘиҙ№еӨ§жҰӮдёҖеҚҠеҶ…еӯҳгҖӮ
В В еӣ дёәhashВ tableжүҖеҒҡзҡ„иҝҗз®—е°ұжҳҜдёӘ%пјҢиҖҢrbtreeиҰҒжҜ”иҫғеҫҲеӨҡпјҢжҜ”еҰӮrbtreeиҰҒзңӢvalueзҡ„ж•°жҚ® пјҢжҜҸдёӘиҠӮзӮ№иҰҒеӨҡеҮә3дёӘжҢҮй’ҲпјҲжҲ–иҖ…еҒҸ移йҮҸпјү еҰӮжһңйңҖиҰҒе…¶д»–еҠҹиғҪпјҢжҜ”еҰӮпјҢз»ҹи®ЎжҹҗдёӘиҢғеӣҙеҶ…зҡ„keyзҡ„ж•°йҮҸпјҢе°ұйңҖиҰҒеҠ дёҖдёӘи®Ўж•°жҲҗе‘ҳгҖӮ
В В дё”1sВ rbtreeиғҪиҝӣиЎҢеӨ§жҰӮ50w+ж¬ЎжҸ’е…ҘпјҢhashВ tableеӨ§жҰӮжҳҜе·®дёҚеӨҡ200wж¬ЎгҖӮдёҚиҝҮеҫҲеӨҡзҡ„ж—¶еҖҷпјҢе…¶йҖҹеәҰеҸҜд»ҘеҝҚдәҶпјҢдҫӢеҰӮеҖ’жҺ’зҙўеј•е·®дёҚеӨҡд№ҹжҳҜиҝҷдёӘйҖҹеәҰпјҢиҖҢдё”еҚ•зәҝзЁӢпјҢдё”еҖ’жҺ’иЎЁзҡ„жӢүй“ҫй•ҝеәҰдёҚдјҡеӨӘеӨ§гҖӮжӯЈеӣ дёәеҹәдәҺж ‘зҡ„е®һзҺ°е…¶е®һдёҚжҜ”hashtableж…ўеҲ°е“ӘйҮҢеҺ»пјҢжүҖд»Ҙж•°жҚ®еә“зҡ„зҙўеј•дёҖиҲ¬йғҪжҳҜз”Ёзҡ„
B/B+ж ‘пјҢиҖҢдё”B+ж ‘иҝҳеҜ№зЈҒзӣҳеҸӢеҘҪ(Bж ‘иғҪжңүж•ҲйҷҚдҪҺе®ғзҡ„й«ҳеәҰпјҢжүҖд»ҘеҮҸе°‘зЈҒзӣҳдәӨдә’ж¬Ўж•°)гҖӮжҜ”еҰӮзҺ°еңЁйқһеёёжөҒиЎҢзҡ„NoSQLж•°жҚ®еә“пјҢеғҸ
MongoDBд№ҹжҳҜйҮҮз”Ёзҡ„Bж ‘зҙўеј•гҖӮе…ідәҺBж ‘зі»еҲ—пјҢиҜ·еҸӮиҖғжң¬blogеҶ…жӯӨзҜҮж–Үз« пјҡ
д»ҺBж ‘гҖҒB+ж ‘гҖҒB*ж ‘и°ҲеҲ°R ж ‘гҖӮ
В
В В OKпјҢжӣҙеӨҡиҜ·еҫ…еҗҺз»ӯе®һйӘҢи®әиҜҒгҖӮжҺҘдёӢжқҘпјҢе’ұ们жқҘзңӢ第дәҢз§Қж–№жі•пјҢеҸҢеұӮжҚ…еҲ’еҲҶгҖӮ
В
еҜҶеҢҷдәҢгҖҒеҸҢеұӮжЎ¶еҲ’еҲҶ
В
еҸҢеұӮжЎ¶еҲ’еҲҶ----е…¶е®һжң¬иҙЁдёҠиҝҳжҳҜеҲҶиҖҢжІ»д№Ӣзҡ„жҖқжғіпјҢйҮҚеңЁвҖңеҲҶвҖқзҡ„жҠҖе·§дёҠпјҒ
гҖҖгҖҖйҖӮз”ЁиҢғеӣҙпјҡ第kеӨ§пјҢдёӯдҪҚж•°пјҢдёҚйҮҚеӨҚжҲ–йҮҚеӨҚзҡ„ж•°еӯ—
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡеӣ дёәе…ғзҙ иҢғеӣҙеҫҲеӨ§пјҢдёҚиғҪеҲ©з”ЁзӣҙжҺҘеҜ»еқҖиЎЁпјҢжүҖд»ҘйҖҡиҝҮеӨҡж¬ЎеҲ’еҲҶпјҢйҖҗжӯҘзЎ®е®ҡиҢғеӣҙпјҢ然еҗҺжңҖеҗҺеңЁдёҖдёӘеҸҜд»ҘжҺҘеҸ—зҡ„иҢғеӣҙеҶ…иҝӣиЎҢгҖӮеҸҜд»ҘйҖҡиҝҮеӨҡж¬Ўзј©е°ҸпјҢеҸҢеұӮеҸӘжҳҜдёҖдёӘдҫӢеӯҗгҖӮ
гҖҖгҖҖжү©еұ•пјҡ
гҖҖгҖҖй—®йўҳе®һдҫӢпјҡ
11гҖҒ2.5дәҝдёӘж•ҙж•°дёӯжүҫеҮәдёҚйҮҚеӨҚзҡ„ж•ҙж•°зҡ„дёӘж•°пјҢеҶ…еӯҳз©әй—ҙдёҚи¶ід»Ҙе®№зәіиҝҷ2.5дәҝдёӘж•ҙж•°гҖӮ
гҖҖгҖҖжңүзӮ№еғҸйёҪе·ўеҺҹзҗҶпјҢж•ҙж•°дёӘж•°дёә2^32,д№ҹе°ұжҳҜпјҢжҲ‘们еҸҜд»Ҙе°Ҷиҝҷ2^32дёӘж•°пјҢеҲ’еҲҶдёә2^8дёӘеҢәеҹҹ(жҜ”еҰӮз”ЁеҚ•дёӘж–Ү件代表дёҖдёӘеҢәеҹҹ)пјҢ然еҗҺе°Ҷж•°жҚ®еҲҶзҰ»еҲ°дёҚеҗҢзҡ„еҢәеҹҹпјҢ然еҗҺдёҚеҗҢзҡ„еҢәеҹҹеңЁеҲ©з”Ёbitmapе°ұеҸҜд»ҘзӣҙжҺҘи§ЈеҶідәҶгҖӮд№ҹе°ұжҳҜиҜҙеҸӘиҰҒжңүи¶іеӨҹзҡ„зЈҒзӣҳз©әй—ҙпјҢе°ұеҸҜд»ҘеҫҲж–№дҫҝзҡ„и§ЈеҶігҖӮ
12гҖҒ5дәҝдёӘintжүҫе®ғ们зҡ„дёӯдҪҚж•°гҖӮ
гҖҖгҖҖиҝҷдёӘдҫӢеӯҗжҜ”дёҠйқўйӮЈдёӘжӣҙжҳҺжҳҫгҖӮйҰ–е…ҲжҲ‘们е°ҶintеҲ’еҲҶдёә2^16дёӘеҢәеҹҹпјҢ然еҗҺиҜ»еҸ–ж•°жҚ®з»ҹи®ЎиҗҪеҲ°еҗ„дёӘеҢәеҹҹйҮҢзҡ„ж•°зҡ„дёӘж•°пјҢд№ӢеҗҺжҲ‘д»¬ж №жҚ®з»ҹи®Ўз»“жһңе°ұеҸҜд»ҘеҲӨж–ӯдёӯдҪҚж•°иҗҪеҲ°йӮЈдёӘеҢәеҹҹпјҢеҗҢж—¶зҹҘйҒ“иҝҷдёӘеҢәеҹҹдёӯзҡ„第еҮ еӨ§ж•°еҲҡеҘҪжҳҜдёӯдҪҚж•°гҖӮ然еҗҺ第дәҢж¬Ўжү«жҸҸжҲ‘们еҸӘз»ҹи®ЎиҗҪеңЁиҝҷдёӘеҢәеҹҹдёӯзҡ„йӮЈдәӣж•°е°ұеҸҜд»ҘдәҶгҖӮ
гҖҖгҖҖе®һйҷ…дёҠпјҢеҰӮжһңдёҚжҳҜintжҳҜint64пјҢжҲ‘们еҸҜд»Ҙз»ҸиҝҮ3ж¬Ўиҝҷж ·зҡ„еҲ’еҲҶеҚіеҸҜйҷҚдҪҺеҲ°еҸҜд»ҘжҺҘеҸ—зҡ„зЁӢеәҰгҖӮеҚіеҸҜд»Ҙе…Ҳе°Ҷint64еҲҶжҲҗ2^24дёӘеҢәеҹҹпјҢ然еҗҺзЎ®е®ҡеҢәеҹҹзҡ„第еҮ еӨ§ж•°пјҢеңЁе°ҶиҜҘеҢәеҹҹеҲҶжҲҗ2^20дёӘеӯҗеҢәеҹҹпјҢ然еҗҺзЎ®е®ҡжҳҜеӯҗеҢәеҹҹзҡ„第еҮ еӨ§ж•°пјҢ然еҗҺеӯҗеҢәеҹҹйҮҢзҡ„ж•°зҡ„дёӘж•°еҸӘжңү2^20пјҢе°ұеҸҜд»ҘзӣҙжҺҘеҲ©з”Ёdirect addr tableиҝӣиЎҢз»ҹи®ЎдәҶгҖӮ
В
еҜҶеҢҷдёүпјҡBloom filter/Bitmap
Bloom filter
е…ідәҺд»Җд№ҲжҳҜBloom filterпјҢиҜ·еҸӮзңӢblogеҶ…жӯӨж–Үпјҡ
В
гҖҖгҖҖйҖӮз”ЁиҢғеӣҙпјҡеҸҜд»Ҙз”ЁжқҘе®һзҺ°ж•°жҚ®еӯ—е…ёпјҢиҝӣиЎҢж•°жҚ®зҡ„еҲӨйҮҚпјҢжҲ–иҖ…йӣҶеҗҲжұӮдәӨйӣҶ
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡ
гҖҖгҖҖеҜ№дәҺеҺҹзҗҶжқҘиҜҙеҫҲз®ҖеҚ•пјҢдҪҚж•°з»„+kдёӘзӢ¬з«ӢhashеҮҪж•°гҖӮе°ҶhashеҮҪж•°еҜ№еә”зҡ„еҖјзҡ„дҪҚж•°з»„зҪ®1пјҢжҹҘжүҫж—¶еҰӮжһңеҸ‘зҺ°жүҖжңүhashеҮҪж•°еҜ№еә”дҪҚйғҪжҳҜ1иҜҙжҳҺеӯҳеңЁпјҢеҫҲжҳҺжҳҫиҝҷдёӘиҝҮзЁӢ并дёҚдҝқиҜҒжҹҘжүҫзҡ„з»“жһңжҳҜ100%жӯЈзЎ®зҡ„гҖӮеҗҢж—¶д№ҹдёҚж”ҜжҢҒеҲ йҷӨдёҖдёӘе·Із»ҸжҸ’е…Ҙзҡ„е…ій”®еӯ—пјҢеӣ дёәиҜҘе…ій”®еӯ—еҜ№еә”зҡ„дҪҚдјҡзүөеҠЁеҲ°е…¶д»–зҡ„е…ій”®еӯ—гҖӮжүҖд»ҘдёҖдёӘз®ҖеҚ•зҡ„ж”№иҝӣе°ұжҳҜ counting Bloom filterпјҢз”ЁдёҖдёӘcounterж•°з»„д»ЈжӣҝдҪҚж•°з»„пјҢе°ұеҸҜд»Ҙж”ҜжҢҒеҲ йҷӨдәҶгҖӮ
гҖҖгҖҖиҝҳжңүдёҖдёӘжҜ”иҫғйҮҚиҰҒзҡ„й—®йўҳпјҢеҰӮдҪ•ж №жҚ®иҫ“е…Ҙе…ғзҙ дёӘж•°nпјҢзЎ®е®ҡдҪҚж•°з»„mзҡ„еӨ§е°ҸеҸҠhashеҮҪж•°дёӘж•°гҖӮеҪ“hashеҮҪж•°дёӘж•°k=(ln2)*(m/n)ж—¶й”ҷиҜҜзҺҮжңҖе°ҸгҖӮеңЁй”ҷиҜҜзҺҮдёҚеӨ§дәҺEзҡ„жғ…еҶөдёӢпјҢmиҮіе°‘иҰҒзӯүдәҺn*lg(1/E)жүҚиғҪиЎЁзӨәд»»ж„ҸnдёӘе…ғзҙ зҡ„йӣҶеҗҲгҖӮдҪҶmиҝҳеә”иҜҘжӣҙеӨ§дәӣпјҢеӣ дёәиҝҳиҰҒдҝқиҜҒbitж•°з»„йҮҢиҮіе°‘дёҖеҚҠдёә0пјҢеҲҷmеә”иҜҘ>=nlg(1/E)*lge еӨ§жҰӮе°ұжҳҜnlg(1/E)1.44еҖҚ(lgиЎЁзӨәд»Ҙ2дёәеә•зҡ„еҜ№ж•°)гҖӮ
гҖҖгҖҖдёҫдёӘдҫӢеӯҗжҲ‘们еҒҮи®ҫй”ҷиҜҜзҺҮдёә0.01пјҢеҲҷжӯӨж—¶mеә”еӨ§жҰӮжҳҜnзҡ„13еҖҚгҖӮиҝҷж ·kеӨ§жҰӮжҳҜ8дёӘгҖӮ
гҖҖгҖҖжіЁж„ҸиҝҷйҮҢmдёҺnзҡ„еҚ•дҪҚдёҚеҗҢпјҢmжҳҜbitдёәеҚ•дҪҚпјҢиҖҢnеҲҷжҳҜд»Ҙе…ғзҙ дёӘж•°дёәеҚ•дҪҚ(еҮҶзЎ®зҡ„иҜҙжҳҜдёҚеҗҢе…ғзҙ зҡ„дёӘж•°)гҖӮйҖҡеёёеҚ•дёӘе…ғзҙ зҡ„й•ҝеәҰйғҪжҳҜжңүеҫҲеӨҡbitзҡ„гҖӮжүҖд»ҘдҪҝз”Ёbloom filterеҶ…еӯҳдёҠйҖҡеёёйғҪжҳҜиҠӮзңҒзҡ„гҖӮ
гҖҖгҖҖжү©еұ•пјҡ
гҖҖгҖҖBloom filterе°ҶйӣҶеҗҲдёӯзҡ„е…ғзҙ жҳ е°„еҲ°дҪҚж•°з»„дёӯпјҢз”ЁkпјҲkдёәе“ҲеёҢеҮҪж•°дёӘж•°пјүдёӘжҳ е°„дҪҚжҳҜеҗҰе…Ё1иЎЁзӨәе…ғзҙ еңЁдёҚеңЁиҝҷдёӘйӣҶеҗҲдёӯгҖӮCounting bloom filterпјҲCBFпјүе°ҶдҪҚж•°з»„дёӯзҡ„жҜҸдёҖдҪҚжү©еұ•дёәдёҖдёӘcounterпјҢд»ҺиҖҢж”ҜжҢҒдәҶе…ғзҙ зҡ„еҲ йҷӨж“ҚдҪңгҖӮSpectral Bloom FilterпјҲSBFпјүе°Ҷе…¶дёҺйӣҶеҗҲе…ғзҙ зҡ„еҮәзҺ°ж¬Ўж•°е…іиҒ”гҖӮSBFйҮҮз”Ёcounterдёӯзҡ„жңҖе°ҸеҖјжқҘиҝ‘дјјиЎЁзӨәе…ғзҙ зҡ„еҮәзҺ°йў‘зҺҮгҖӮ
В
13гҖҒз»ҷдҪ A,BдёӨдёӘж–Ү件пјҢеҗ„еӯҳж”ҫ50дәҝжқЎURLпјҢжҜҸжқЎURLеҚ з”Ё64еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶жҳҜ4GпјҢи®©дҪ жүҫеҮәA,Bж–Ү件е…ұеҗҢзҡ„URLгҖӮеҰӮжһңжҳҜдёүдёӘд№ғиҮіnдёӘж–Ү件呢пјҹ
гҖҖгҖҖж №жҚ®иҝҷдёӘй—®йўҳжҲ‘们жқҘи®Ўз®—дёӢеҶ…еӯҳзҡ„еҚ з”ЁпјҢ4G=2^32еӨ§жҰӮжҳҜ40дәҝ*8еӨ§жҰӮжҳҜ340дәҝпјҢn=50дәҝпјҢеҰӮжһңжҢүеҮәй”ҷзҺҮ0.01з®—йңҖиҰҒзҡ„еӨ§жҰӮжҳҜ650дәҝдёӘbitгҖӮзҺ°еңЁеҸҜз”Ёзҡ„жҳҜ340дәҝпјҢзӣёе·®е№¶дёҚеӨҡпјҢиҝҷж ·еҸҜиғҪдјҡдҪҝеҮәй”ҷзҺҮдёҠеҚҮдәӣгҖӮеҸҰеӨ–еҰӮжһңиҝҷдәӣurlipжҳҜдёҖдёҖеҜ№еә”зҡ„пјҢе°ұеҸҜд»ҘиҪ¬жҚўжҲҗipпјҢеҲҷеӨ§еӨ§з®ҖеҚ•дәҶгҖӮ
В В еҗҢж—¶пјҢдёҠж–Үзҡ„第5йўҳпјҡз»ҷе®ҡaгҖҒbдёӨдёӘж–Ү件пјҢеҗ„еӯҳж”ҫ50дәҝдёӘurlпјҢжҜҸдёӘurlеҗ„еҚ 64еӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶жҳҜ4GпјҢи®©дҪ жүҫеҮәaгҖҒbж–Ү件е…ұеҗҢзҡ„urlпјҹеҰӮжһңе…Ғи®ёжңүдёҖе®ҡзҡ„й”ҷиҜҜзҺҮпјҢеҸҜд»ҘдҪҝз”ЁBloom filterпјҢ4GеҶ…еӯҳеӨ§жҰӮеҸҜд»ҘиЎЁзӨә340дәҝbitгҖӮе°Ҷе…¶дёӯдёҖдёӘж–Ү件дёӯзҡ„urlдҪҝз”ЁBloom filterжҳ е°„дёәиҝҷ340дәҝbitпјҢ然еҗҺжҢЁдёӘиҜ»еҸ–еҸҰеӨ–дёҖдёӘж–Ү件зҡ„urlпјҢжЈҖжҹҘжҳҜеҗҰдёҺBloom filterпјҢеҰӮжһңжҳҜпјҢйӮЈд№ҲиҜҘurlеә”иҜҘжҳҜе…ұеҗҢзҡ„urlпјҲжіЁж„ҸдјҡжңүдёҖе®ҡзҡ„й”ҷиҜҜзҺҮпјүгҖӮ
Bitmap
В
В
В В дёӢйқўе…ідәҺBitmapзҡ„еә”з”ЁпјҢзӣҙжҺҘдёҠйўҳпјҢеҰӮдёӢ第9гҖҒ10йҒ“пјҡ
В В В В В 14гҖҒеңЁ2.5дәҝдёӘж•ҙж•°дёӯжүҫеҮәдёҚйҮҚеӨҚзҡ„ж•ҙж•°пјҢжіЁпјҢеҶ…еӯҳдёҚи¶ід»Ҙе®№зәіиҝҷ2.5дәҝдёӘж•ҙж•°гҖӮ
В В ж–№жЎҲ1пјҡйҮҮз”Ё2-BitmapпјҲжҜҸдёӘж•°еҲҶй…Қ2bitпјҢ00иЎЁзӨәдёҚеӯҳеңЁпјҢ01иЎЁзӨәеҮәзҺ°дёҖж¬ЎпјҢ10иЎЁзӨәеӨҡж¬ЎпјҢ11ж— ж„Ҹд№үпјүиҝӣиЎҢпјҢе…ұйңҖеҶ…еӯҳ2^32 * 2 bit=1 GBеҶ…еӯҳпјҢиҝҳеҸҜд»ҘжҺҘеҸ—гҖӮ然еҗҺжү«жҸҸиҝҷ2.5дәҝдёӘж•ҙж•°пјҢжҹҘзңӢBitmapдёӯзӣёеҜ№еә”дҪҚпјҢеҰӮжһңжҳҜ00еҸҳ01пјҢ01еҸҳ10пјҢ10дҝқжҢҒдёҚеҸҳгҖӮжүҖжҸҸе®ҢдәӢеҗҺпјҢжҹҘзңӢbitmapпјҢжҠҠеҜ№еә”дҪҚжҳҜ01зҡ„ж•ҙж•°иҫ“еҮәеҚіеҸҜгҖӮ
В В ж–№жЎҲ2пјҡд№ҹеҸҜйҮҮз”ЁдёҺ第1йўҳзұ»дјјзҡ„ж–№жі•пјҢиҝӣиЎҢеҲ’еҲҶе°Ҹж–Ү件зҡ„ж–№жі•гҖӮ然еҗҺеңЁе°Ҹж–Ү件дёӯжүҫеҮәдёҚйҮҚеӨҚзҡ„ж•ҙж•°пјҢ并жҺ’еәҸгҖӮ然еҗҺеҶҚиҝӣиЎҢеҪ’并пјҢжіЁж„ҸеҺ»йҷӨйҮҚеӨҚзҡ„е…ғзҙ гҖӮ
В В В В В 15гҖҒи…ҫи®ҜйқўиҜ•йўҳпјҡз»ҷ40дәҝдёӘдёҚйҮҚеӨҚзҡ„unsigned intзҡ„ж•ҙж•°пјҢжІЎжҺ’иҝҮеәҸзҡ„пјҢ然еҗҺеҶҚз»ҷдёҖдёӘж•°пјҢеҰӮдҪ•еҝ«йҖҹеҲӨж–ӯиҝҷдёӘж•°жҳҜеҗҰеңЁйӮЈ40дәҝдёӘж•°еҪ“дёӯпјҹ
В В ж–№жЎҲ1пјҡfrome ooпјҢз”ЁдҪҚеӣҫ/Bitmapзҡ„ж–№жі•пјҢз”іиҜ·512Mзҡ„еҶ…еӯҳпјҢдёҖдёӘbitдҪҚд»ЈиЎЁдёҖдёӘunsigned intеҖјгҖӮиҜ»е…Ҙ40дәҝдёӘж•°пјҢи®ҫзҪ®зӣёеә”зҡ„bitдҪҚпјҢиҜ»е…ҘиҰҒжҹҘиҜўзҡ„ж•°пјҢжҹҘзңӢзӣёеә”bitдҪҚжҳҜеҗҰдёә1пјҢдёә1иЎЁзӨәеӯҳеңЁпјҢдёә0иЎЁзӨәдёҚеӯҳеңЁгҖӮ
еҜҶеҢҷеӣӣгҖҒTrieж ‘/ж•°жҚ®еә“/еҖ’жҺ’зҙўеј•
Trieж ‘
гҖҖгҖҖйҖӮз”ЁиҢғеӣҙпјҡж•°жҚ®йҮҸеӨ§пјҢйҮҚеӨҚеӨҡпјҢдҪҶжҳҜж•°жҚ®з§Қзұ»е°ҸеҸҜд»Ҙж”ҫе…ҘеҶ…еӯҳ
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡе®һзҺ°ж–№ејҸпјҢиҠӮзӮ№еӯ©еӯҗзҡ„иЎЁзӨәж–№ејҸ
гҖҖгҖҖжү©еұ•пјҡеҺӢзј©е®һзҺ°гҖӮ
гҖҖгҖҖй—®йўҳе®һдҫӢпјҡ
- дёҠйқўзҡ„第2йўҳпјҡеҜ»жүҫзғӯй—ЁжҹҘиҜўпјҡжҹҘиҜўдёІзҡ„йҮҚеӨҚеәҰжҜ”иҫғй«ҳпјҢиҷҪ然жҖ»ж•°жҳҜ1еҚғдёҮпјҢдҪҶеҰӮжһңйҷӨеҺ»йҮҚеӨҚеҗҺпјҢдёҚи¶…иҝҮ3зҷҫдёҮдёӘпјҢжҜҸдёӘдёҚи¶…иҝҮ255еӯ—иҠӮгҖӮ
- дёҠйқўзҡ„第5йўҳпјҡжңү10дёӘж–Ү件пјҢжҜҸдёӘж–Ү件1GпјҢжҜҸдёӘж–Ү件зҡ„жҜҸдёҖиЎҢйғҪеӯҳж”ҫзҡ„жҳҜз”ЁжҲ·зҡ„queryпјҢжҜҸдёӘж–Ү件зҡ„queryйғҪеҸҜиғҪйҮҚеӨҚгҖӮиҰҒдҪ жҢүз…§queryзҡ„йў‘еәҰжҺ’еәҸгҖӮ
- 1000дёҮеӯ—з¬ҰдёІпјҢе…¶дёӯжңүдәӣжҳҜзӣёеҗҢзҡ„(йҮҚеӨҚ),йңҖиҰҒжҠҠйҮҚеӨҚзҡ„е…ЁйғЁеҺ»жҺүпјҢдҝқз•ҷжІЎжңүйҮҚеӨҚзҡ„еӯ—з¬ҰдёІгҖӮиҜ·й—®жҖҺд№Ҳи®ҫи®Ўе’Ңе®һзҺ°пјҹ
- дёҠйқўзҡ„第8йўҳпјҡдёҖдёӘж–Үжң¬ж–Ү件пјҢеӨ§зәҰжңүдёҖдёҮиЎҢпјҢжҜҸиЎҢдёҖдёӘиҜҚпјҢиҰҒжұӮз»ҹи®ЎеҮәе…¶дёӯжңҖйў‘з№ҒеҮәзҺ°зҡ„еүҚ10дёӘиҜҚгҖӮе…¶и§ЈеҶіж–№жі•жҳҜпјҡз”Ёtrieж ‘з»ҹи®ЎжҜҸдёӘиҜҚеҮәзҺ°зҡ„ж¬Ўж•°пјҢж—¶й—ҙеӨҚжқӮеәҰжҳҜO(n*le)пјҲleиЎЁзӨәеҚ•иҜҚзҡ„е№іеҮҶй•ҝеәҰпјүпјҢ然еҗҺжҳҜжүҫеҮәеҮәзҺ°жңҖйў‘з№Ғзҡ„еүҚ10дёӘиҜҚгҖӮ
В
В В жӣҙеӨҡжңүе…іTrieж ‘зҡ„д»Ӣз»ҚпјҢиҜ·еҸӮи§ҒжӯӨж–Үпјҡд»ҺTrieж ‘пјҲеӯ—е…ёж ‘пјүи°ҲеҲ°еҗҺзјҖж ‘гҖӮ
ж•°жҚ®еә“зҙўеј•
гҖҖгҖҖйҖӮз”ЁиҢғеӣҙпјҡеӨ§ж•°жҚ®йҮҸзҡ„еўһеҲ ж”№жҹҘ
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡеҲ©з”Ёж•°жҚ®зҡ„и®ҫи®Ўе®һзҺ°ж–№жі•пјҢеҜ№жө·йҮҸж•°жҚ®зҡ„еўһеҲ ж”№жҹҘиҝӣиЎҢеӨ„зҗҶгҖӮ
еҖ’жҺ’зҙўеј•(Inverted index)
гҖҖгҖҖйҖӮз”ЁиҢғеӣҙпјҡжҗңзҙўеј•ж“ҺпјҢе…ій”®еӯ—жҹҘиҜў
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡдёәдҪ•еҸ«еҖ’жҺ’зҙўеј•пјҹдёҖз§Қзҙўеј•ж–№жі•пјҢиў«з”ЁжқҘеӯҳеӮЁеңЁе…Ёж–ҮжҗңзҙўдёӢжҹҗдёӘеҚ•иҜҚеңЁдёҖдёӘж–ҮжЎЈжҲ–иҖ…дёҖз»„ж–ҮжЎЈдёӯзҡ„еӯҳеӮЁдҪҚзҪ®зҡ„жҳ е°„гҖӮ
гҖҖд»ҘиӢұж–ҮдёәдҫӢпјҢдёӢйқўжҳҜиҰҒиў«зҙўеј•зҡ„ж–Үжң¬пјҡ
В В T0 = "it is what it is"
В В T1 = "what is it"
В В T2 = "it is a banana"
В В жҲ‘们е°ұиғҪеҫ—еҲ°дёӢйқўзҡ„еҸҚеҗ‘ж–Ү件зҙўеј•пјҡ
В В "a": В В В {2}
В В "banana": {2}
В В "is": В В {0, 1, 2}
В В "it": В В {0, 1, 2}
В В "what": В {0, 1}
гҖҖжЈҖзҙўзҡ„жқЎд»¶"what","is"е’Ң"it"е°ҶеҜ№еә”йӣҶеҗҲзҡ„дәӨйӣҶгҖӮ
гҖҖгҖҖжӯЈеҗ‘зҙўеј•ејҖеҸ‘еҮәжқҘз”ЁжқҘеӯҳеӮЁжҜҸдёӘж–ҮжЎЈзҡ„еҚ•иҜҚзҡ„еҲ—иЎЁгҖӮжӯЈеҗ‘зҙўеј•зҡ„жҹҘиҜўеҫҖеҫҖж»Ўи¶іжҜҸдёӘж–ҮжЎЈжңүеәҸйў‘з№Ғзҡ„е…Ёж–ҮжҹҘиҜўе’ҢжҜҸдёӘеҚ•иҜҚеңЁж ЎйӘҢж–ҮжЎЈдёӯзҡ„йӘҢиҜҒиҝҷж ·зҡ„жҹҘиҜўгҖӮеңЁжӯЈеҗ‘зҙўеј•дёӯпјҢж–ҮжЎЈеҚ жҚ®дәҶдёӯеҝғзҡ„дҪҚзҪ®пјҢжҜҸдёӘж–ҮжЎЈжҢҮеҗ‘дәҶдёҖдёӘе®ғжүҖеҢ…еҗ«зҡ„зҙўеј•йЎ№зҡ„еәҸеҲ—гҖӮд№ҹе°ұжҳҜиҜҙж–ҮжЎЈжҢҮеҗ‘дәҶе®ғеҢ…еҗ«зҡ„йӮЈдәӣеҚ•иҜҚпјҢиҖҢеҸҚеҗ‘зҙўеј•еҲҷжҳҜеҚ•иҜҚжҢҮеҗ‘дәҶеҢ…еҗ«е®ғзҡ„ж–ҮжЎЈпјҢеҫҲе®№жҳ“зңӢеҲ°иҝҷдёӘеҸҚеҗ‘зҡ„е…ізі»гҖӮ
гҖҖгҖҖжү©еұ•пјҡ
гҖҖгҖҖй—®йўҳе®һдҫӢпјҡж–ҮжЎЈжЈҖзҙўзі»з»ҹпјҢжҹҘиҜўйӮЈдәӣж–Ү件еҢ…еҗ«дәҶжҹҗеҚ•иҜҚпјҢжҜ”еҰӮеёёи§Ғзҡ„еӯҰжңҜи®әж–Үзҡ„е…ій”®еӯ—жҗңзҙўгҖӮ
В В е…ідәҺеҖ’жҺ’зҙўеј•зҡ„еә”з”ЁпјҢжӣҙеӨҡиҜ·еҸӮи§Ғпјҡ
В
еҜҶеҢҷдә”гҖҒеӨ–жҺ’еәҸ
гҖҖгҖҖйҖӮз”ЁиҢғеӣҙпјҡеӨ§ж•°жҚ®зҡ„жҺ’еәҸпјҢеҺ»йҮҚ
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡеӨ–жҺ’еәҸзҡ„еҪ’并方法пјҢзҪ®жҚўйҖүжӢ©иҙҘиҖ…ж ‘еҺҹзҗҶпјҢжңҖдјҳеҪ’е№¶ж ‘
гҖҖгҖҖжү©еұ•пјҡ
гҖҖгҖҖй—®йўҳе®һдҫӢпјҡ
гҖҖгҖҖ1).жңүдёҖдёӘ1GеӨ§е°Ҹзҡ„дёҖдёӘж–Ү件пјҢйҮҢйқўжҜҸдёҖиЎҢжҳҜдёҖдёӘиҜҚпјҢиҜҚзҡ„еӨ§е°ҸдёҚи¶…иҝҮ16дёӘеӯ—иҠӮпјҢеҶ…еӯҳйҷҗеҲ¶еӨ§е°ҸжҳҜ1MгҖӮиҝ”еӣһйў‘ж•°жңҖй«ҳзҡ„100дёӘиҜҚгҖӮ
гҖҖгҖҖиҝҷдёӘж•°жҚ®е…·жңүеҫҲжҳҺжҳҫзҡ„зү№зӮ№пјҢиҜҚзҡ„еӨ§е°Ҹдёә16дёӘеӯ—иҠӮпјҢдҪҶжҳҜеҶ…еӯҳеҸӘжңү1MеҒҡhashжҳҺжҳҫдёҚеӨҹпјҢжүҖд»ҘеҸҜд»Ҙз”ЁжқҘжҺ’еәҸгҖӮеҶ…еӯҳеҸҜд»ҘеҪ“иҫ“е…Ҙзј“еҶІеҢәдҪҝз”ЁгҖӮ
В В е…ідәҺеӨҡи·ҜеҪ’并算法еҸҠеӨ–жҺ’еәҸзҡ„е…·дҪ“еә”з”ЁеңәжҷҜпјҢиҜ·еҸӮи§ҒblogеҶ…жӯӨж–Үпјҡ
В
еҜҶеҢҷе…ӯгҖҒеҲҶеёғејҸеӨ„зҗҶд№ӢMapreduce
В В В MapReduceжҳҜдёҖз§Қи®Ўз®—жЁЎеһӢпјҢз®ҖеҚ•зҡ„иҜҙе°ұжҳҜе°ҶеӨ§жү№йҮҸзҡ„е·ҘдҪңпјҲж•°жҚ®пјүеҲҶи§ЈпјҲMAPпјүжү§иЎҢпјҢ然еҗҺеҶҚе°Ҷз»“жһңеҗҲ并жҲҗжңҖз»Ҳз»“жһңпјҲREDUCEпјүгҖӮиҝҷж ·еҒҡзҡ„еҘҪеӨ„жҳҜеҸҜд»ҘеңЁд»»еҠЎиў«еҲҶи§ЈеҗҺпјҢеҸҜд»ҘйҖҡиҝҮеӨ§йҮҸжңәеҷЁиҝӣиЎҢ并иЎҢи®Ўз®—пјҢеҮҸе°‘ж•ҙдёӘж“ҚдҪңзҡ„ж—¶й—ҙгҖӮдҪҶеҰӮжһңдҪ иҰҒжҲ‘еҶҚйҖҡдҝ—зӮ№д»Ӣз»ҚпјҢйӮЈд№ҲпјҢиҜҙзҷҪдәҶпјҢMapreduceзҡ„еҺҹзҗҶе°ұжҳҜдёҖдёӘеҪ’并жҺ’еәҸгҖӮ
В В В В йҖӮз”ЁиҢғеӣҙпјҡж•°жҚ®йҮҸеӨ§пјҢдҪҶжҳҜж•°жҚ®з§Қзұ»е°ҸеҸҜд»Ҙж”ҫе…ҘеҶ…еӯҳ
гҖҖгҖҖеҹәжң¬еҺҹзҗҶеҸҠиҰҒзӮ№пјҡе°Ҷж•°жҚ®дәӨз»ҷдёҚеҗҢзҡ„жңәеҷЁеҺ»еӨ„зҗҶпјҢж•°жҚ®еҲ’еҲҶпјҢз»“жһңеҪ’зәҰгҖӮ
гҖҖгҖҖжү©еұ•пјҡ
гҖҖгҖҖй—®йўҳе®һдҫӢпјҡ
- The canonical example application of MapReduce is a process to count the appearances of each different word in a set of documents:
- жө·йҮҸж•°жҚ®еҲҶеёғеңЁ100еҸ°з”өи„‘дёӯпјҢжғідёӘеҠһжі•й«ҳж•Ҳз»ҹи®ЎеҮәиҝҷжү№ж•°жҚ®зҡ„TOP10гҖӮ
- дёҖе…ұжңүNдёӘжңәеҷЁпјҢжҜҸдёӘжңәеҷЁдёҠжңүNдёӘж•°гҖӮжҜҸдёӘжңәеҷЁжңҖеӨҡеӯҳO(N)дёӘ数并еҜ№е®ғ们ж“ҚдҪңгҖӮеҰӮдҪ•жүҫеҲ°N^2дёӘж•°зҡ„дёӯж•°(median)пјҹ
В
В В жӣҙеӨҡе…·дҪ“йҳҗиҝ°иҜ·еҸӮи§ҒblogеҶ…пјҡ
е…¶е®ғжЁЎејҸ/ж–№жі•и®әпјҢз»“еҗҲж“ҚдҪңзі»з»ҹзҹҘиҜҶ
В В иҮіжӯӨпјҢе…ӯз§ҚеӨ„зҗҶжө·йҮҸж•°жҚ®й—®йўҳзҡ„жЁЎејҸ/ж–№жі•е·Із»Ҹйҳҗиҝ°е®ҢжҜ•гҖӮжҚ®и§ӮеҜҹпјҢиҝҷж–№йқўзҡ„йқўиҜ•йўҳж— еӨ–д№Һд»ҘдёҠдёҖз§ҚжҲ–е…¶еҸҳеҪўпјҢ然йўҳзӣ®дёәдҪ•еҸ–дёәжҳҜпјҡз§’жқҖ99%зҡ„жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳпјҢиҖҢдёҚжҳҜ100%е‘ўгҖӮOKпјҢз»ҷиҜ»иҖ…зңӢжңҖеҗҺдёҖйҒ“йўҳпјҢеҰӮдёӢпјҡ
В В йқһеёёеӨ§зҡ„ж–Ү件пјҢиЈ…дёҚиҝӣеҶ…еӯҳгҖӮжҜҸиЎҢдёҖдёӘintзұ»еһӢж•°жҚ®пјҢзҺ°еңЁиҰҒдҪ йҡҸжңәеҸ–100дёӘж•°гҖӮ
В В жҲ‘们еҸ‘зҺ°дёҠиҝ°иҝҷйҒ“йўҳпјҢж— и®әжҳҜд»ҘдёҠд»»дҪ•дёҖз§ҚжЁЎејҸ/ж–№жі•йғҪдёҚеҘҪеҒҡпјҢйӮЈжңүд»Җд№ҲеҘҪзҡ„еҲ«зҡ„ж–№жі•е‘ўпјҹжҲ‘们еҸҜд»ҘзңӢзңӢпјҡж“ҚдҪңзі»з»ҹеҶ…еӯҳеҲҶйЎөзі»з»ҹи®ҫи®Ў(иҜҙзҷҪдәҶпјҢе°ұжҳҜжҳ е°„+е»әзҙўеј•)гҖӮ
В В Windows 2000дҪҝз”ЁеҹәдәҺеҲҶйЎөжңәеҲ¶зҡ„иҷҡжӢҹеҶ…еӯҳгҖӮжҜҸдёӘиҝӣзЁӢжңү4GBзҡ„иҷҡжӢҹең°еқҖз©әй—ҙгҖӮеҹәдәҺеҲҶйЎөжңәеҲ¶пјҢиҝҷ4GBең°еқҖз©әй—ҙзҡ„дёҖдәӣйғЁеҲҶиў«жҳ е°„дәҶзү©зҗҶеҶ…еӯҳпјҢдёҖдәӣйғЁеҲҶжҳ е°„зЎ¬зӣҳдёҠзҡ„дәӨжҚўж–Ү 件пјҢдёҖдәӣйғЁеҲҶд»Җд№Ҳд№ҹжІЎжңүжҳ е°„гҖӮзЁӢеәҸдёӯдҪҝз”Ёзҡ„йғҪжҳҜ4GBең°еқҖз©әй—ҙдёӯзҡ„иҷҡжӢҹең°еқҖгҖӮиҖҢи®ҝй—®зү©зҗҶеҶ…еӯҳпјҢйңҖиҰҒдҪҝз”Ёзү©зҗҶең°еқҖгҖӮ е…ідәҺд»Җд№ҲжҳҜзү©зҗҶең°еқҖе’ҢиҷҡжӢҹең°еқҖпјҢиҜ·зңӢпјҡ
- зү©зҗҶең°еқҖ (physical address): ж”ҫеңЁеҜ»еқҖжҖ»зәҝдёҠзҡ„ең°еқҖгҖӮж”ҫеңЁеҜ»еқҖжҖ»зәҝдёҠпјҢеҰӮжһңжҳҜиҜ»пјҢз”өи·Ҝж №жҚ®иҝҷдёӘең°еқҖжҜҸдҪҚзҡ„еҖје°ұе°Ҷзӣёеә”ең°еқҖзҡ„зү©зҗҶеҶ…еӯҳдёӯзҡ„ж•°жҚ®ж”ҫеҲ°ж•°жҚ®жҖ»зәҝдёӯдј иҫ“гҖӮеҰӮжһңжҳҜеҶҷпјҢз”өи·Ҝж №жҚ®иҝҷдёӘ ең°еқҖжҜҸдҪҚзҡ„еҖје°ұе°Ҷзӣёеә”ең°еқҖзҡ„зү©зҗҶеҶ…еӯҳдёӯж”ҫе…Ҙж•°жҚ®жҖ»зәҝдёҠзҡ„еҶ…е®№гҖӮзү©зҗҶеҶ…еӯҳжҳҜд»Ҙеӯ—иҠӮ(8дҪҚ)дёәеҚ•дҪҚзј–еқҖзҡ„гҖӮВ
- иҷҡжӢҹең°еқҖ (virtual address): 4GиҷҡжӢҹең°еқҖз©әй—ҙдёӯзҡ„ең°еқҖпјҢзЁӢеәҸдёӯдҪҝз”Ёзҡ„йғҪжҳҜиҷҡжӢҹең°еқҖгҖӮВ дҪҝз”ЁдәҶеҲҶйЎөжңәеҲ¶д№ӢеҗҺпјҢ4Gзҡ„ең°еқҖз©әй—ҙиў«еҲҶжҲҗдәҶеӣәе®ҡеӨ§е°Ҹзҡ„йЎөпјҢжҜҸдёҖйЎөжҲ–иҖ…иў«жҳ е°„еҲ°зү©зҗҶеҶ…еӯҳпјҢжҲ–иҖ…иў«жҳ е°„еҲ°зЎ¬зӣҳдёҠзҡ„дәӨжҚўж–Ү件дёӯпјҢжҲ–иҖ…жІЎжңүжҳ е°„д»»дҪ•дёңиҘҝгҖӮеҜ№дәҺдёҖ иҲ¬зЁӢеәҸжқҘиҜҙпјҢ4Gзҡ„ең°еқҖз©әй—ҙпјҢеҸӘжңүдёҖе°ҸйғЁеҲҶжҳ е°„дәҶзү©зҗҶеҶ…еӯҳпјҢеӨ§зүҮеӨ§зүҮзҡ„йғЁеҲҶжҳҜжІЎжңүжҳ е°„д»»дҪ•дёңиҘҝгҖӮзү©зҗҶеҶ…еӯҳд№ҹиў«еҲҶйЎөпјҢжқҘжҳ е°„ең°еқҖз©әй—ҙгҖӮеҜ№дәҺ32bitзҡ„ Win2kпјҢйЎөзҡ„еӨ§е°ҸжҳҜ4Kеӯ—иҠӮгҖӮCPUз”ЁжқҘжҠҠиҷҡжӢҹең°еқҖиҪ¬жҚўжҲҗзү©зҗҶең°еқҖзҡ„дҝЎжҒҜеӯҳж”ҫеңЁеҸ«еҒҡйЎөзӣ®еҪ•е’ҢйЎөиЎЁзҡ„з»“жһ„йҮҢгҖӮВ
В В зү©зҗҶеҶ…еӯҳеҲҶйЎөпјҢдёҖдёӘзү©зҗҶйЎөзҡ„еӨ§е°Ҹдёә4Kеӯ—иҠӮпјҢ第0дёӘзү©зҗҶйЎөд»Һзү©зҗҶең°еқҖ 0x00000000 еӨ„ејҖе§ӢгҖӮз”ұдәҺйЎөзҡ„еӨ§е°Ҹдёә4KBпјҢе°ұжҳҜ0x1000еӯ—иҠӮпјҢжүҖд»Ҙ第1йЎөд»Һзү©зҗҶең°еқҖ 0x00001000 еӨ„ејҖе§ӢгҖӮ第2йЎөд»Һзү©зҗҶең°еқҖ 0x00002000 еӨ„ејҖе§ӢгҖӮеҸҜд»ҘзңӢеҲ°з”ұдәҺйЎөзҡ„еӨ§е°ҸжҳҜ4KBпјҢжүҖд»ҘеҸӘйңҖиҰҒ32bitзҡ„ең°еқҖдёӯй«ҳ20bitжқҘеҜ»еқҖзү©зҗҶйЎөгҖӮВ
В В иҝ”еӣһдёҠйқўжҲ‘们зҡ„йўҳзӣ®пјҡйқһеёёеӨ§зҡ„ж–Ү件пјҢиЈ…дёҚиҝӣеҶ…еӯҳгҖӮжҜҸиЎҢдёҖдёӘintзұ»еһӢж•°жҚ®пјҢзҺ°еңЁиҰҒдҪ йҡҸжңәеҸ–100дёӘж•°гҖӮй’ҲеҜ№жӯӨйўҳпјҢжҲ‘们еҸҜд»ҘеҖҹйүҙдёҠиҝ°ж“ҚдҪңзі»з»ҹдёӯеҶ…еӯҳеҲҶйЎөзҡ„и®ҫи®Ўж–№жі•пјҢеҒҡеҮәеҰӮдёӢи§ЈеҶіж–№жЎҲпјҡ
В В ж“ҚдҪңзі»з»ҹдёӯзҡ„ж–№жі•пјҢе…Ҳз”ҹжҲҗ4Gзҡ„ең°еқҖиЎЁпјҢеңЁжҠҠиҝҷдёӘиЎЁеҲ’еҲҶдёәе°Ҹзҡ„4Mзҡ„е°Ҹж–Ү件еҒҡдёӘзҙўеј•пјҢдәҢзә§зҙўеј•гҖӮ30дҪҚеүҚеҚҒдҪҚиЎЁзӨә第еҮ дёӘ4Mж–Ү件пјҢеҗҺ20дҪҚиЎЁзӨәеңЁиҝҷдёӘ4Mж–Ү件зҡ„第еҮ дёӘпјҢзӯүзӯүпјҢеҹәдәҺkey valueжқҘи®ҫи®ЎеӯҳеӮЁпјҢз”ЁkeyжқҘе»әзҙўеј•гҖӮ
В В дҪҶеҰӮжһңзҺ°еңЁеҸӘжңү10000дёӘж•°пјҢ然еҗҺжҖҺд№ҲеҺ»йҡҸжңәд»ҺиҝҷдёҖдёҮдёӘж•°йҮҢйқўйҡҸжңәеҸ–100дёӘж•°пјҹиҜ·иҜ»иҖ…жҖқиҖғгҖӮ
жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳд№ӢжңҖ新收йӣҶ
-
з®—жі•дёҺзЁӢеәҸи®ҫи®ЎдёҖгҖҒ
зҪ‘йЎөзҲ¬иҷ«еңЁжҠ“еҸ–зҪ‘йЎөж—¶пјҢд»ҺжҢҮе®ҡзҡ„URLз«ҷзӮ№е…ҘеҸЈејҖе§ӢзҲ¬еҸ–иҝҷдёӘз«ҷзӮ№дёҠзҡ„жүҖжңүURL linkпјҢжҠ“еҸ–еҲ°дёӢдёҖзә§linkеҜ№еә”зҡ„йЎөйқўеҗҺпјҢеҗҢж ·еҜ№йЎөйқўдёҠзҡ„linkиҝӣиЎҢжҠ“еҸ–д»ҺиҖҢе®ҢжҲҗж·ұеәҰйҒҚеҺҶгҖӮдёәз®ҖеҢ–й—®йўҳпјҢжҲ‘们еҒҮи®ҫжҜҸдёӘйЎөйқўдёҠиҮіеӨҡеҸӘжңүдёҖдёӘlinkпјҢеҰӮд»Һwww.baidu.com/a.htmlй“ҫжҺҘеҲ°www.baidu.com/b.htmlеҶҚй“ҫеҲ°www.baidu.com/x.htmlпјҢеҪ“зҲ¬иҷ«жҠ“еҸ–еҲ°жҹҗдёӘйЎөйқўж—¶пјҢжңүеҸҜиғҪеҶҚй“ҫеӣһwww.baidu.com/b.htmlпјҢд№ҹжңүеҸҜиғҪзҲ¬еҸ–еҲ°дёҖдёӘдёҚеёҰд»»дҪ•linkзҡ„з»ҲжһҒйЎөйқўгҖӮеҪ“жҠ“еҸ–еҲ°зӣёеҗҢзҡ„URLжҲ–дёҚеҢ…еҗ«д»»дҪ•linkзҡ„з»ҲжһҒйЎөйқўж—¶еҚіе®ҢжҲҗзҲ¬еҸ–гҖӮзҲ¬иҷ«еңЁжҠ“еҸ–еҲ°иҝҷдәӣйЎөйқўеҗҺе»әз«ӢдёҖдёӘеҚ•еҗ‘й“ҫиЎЁпјҢз”ЁжқҘи®°еҪ•жҠ“еҸ–еҲ°зҡ„йЎөйқўпјҢеҰӮпјҡa.html->b.html->x.html...->NULLгҖӮ
й—®пјҡеҜ№дәҺзҲ¬иҷ«еҲҶеҲ«д»Һwww.baidu.com/x1.htmlе’Ңwww.baidu.com/x2.htmlдёӨдёӘе…ҘеҸЈејҖе§ӢиҺ·еҫ—дёӨдёӘеҚ•еҗ‘й“ҫиЎЁпјҢеҫ—еҲ°иҝҷдёӨдёӘеҚ•еҗ‘й“ҫиЎЁеҗҺпјҢеҰӮдҪ•еҲӨж–ӯ他们жҳҜеҗҰжҠ“еҸ–еҲ°дәҶзӣёеҗҢзҡ„URLпјҹпјҲеҒҮи®ҫйЎөйқўURLдёҠзҷҫдәҝпјҢеӯҳеӮЁиө„жәҗжңүйҷҗпјҢж— жі•з”Ёhashж–№жі•еҲӨж–ӯжҳҜеҗҰеҢ…еҗ«зӣёеҗҢзҡ„URLпјү
иҜ·е…ҲжҸҸиҝ°зӣёеә”зҡ„з®—жі•пјҢеҶҚз»ҷеҮәзӣёеә”зҡ„д»Јз Ғе®һзҺ°гҖӮпјҲеҸӘйңҖз»ҷеҮәеҲӨж–ӯж–№жі•д»Јз ҒпјҢж— йңҖзҲ¬иҷ«д»Јз ҒпјүгҖӮ
дёҫдёӘдҫӢеӯҗеҲҷжҳҜпјҡ
В a,b,c,d,e,f,g
h,i,j,k,d,e,f,gВ
--2012зҷҫеәҰе®һд№ з”ҹжӢӣиҒҳ笔иҜ•йўҳпјҡ
http://blog.csdn.net/hackbuteer1/article/details/7542774гҖӮ
еҸӮиҖғж–ҮзҢ®
- еҚҒйҒ“жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳдёҺеҚҒдёӘж–№жі•еӨ§жҖ»з»“пјӣ
- жө·йҮҸж•°жҚ®еӨ„зҗҶйқўиҜ•йўҳйӣҶй”ҰдёҺBit-mapиҜҰи§Јпјӣ
- еҚҒдёҖгҖҒд»ҺеӨҙеҲ°е°ҫеҪ»еә•и§ЈжһҗHashиЎЁз®—жі•пјӣ
-
жө·йҮҸж•°жҚ®еӨ„зҗҶд№ӢBloom FilterиҜҰи§Јпјӣ
-
д»ҺTrieж ‘пјҲеӯ—е…ёж ‘пјүи°ҲеҲ°еҗҺзјҖж ‘пјӣ
- 第дёүз« з»ӯгҖҒTop Kз®—жі•й—®йўҳзҡ„е®һзҺ°пјӣ
- 第еҚҒз« гҖҒеҰӮдҪ•з»ҷ10^7дёӘж•°жҚ®йҮҸзҡ„зЈҒзӣҳж–Ү件жҺ’еәҸпјӣ
- д»ҺBж ‘гҖҒB+ж ‘гҖҒB*ж ‘и°ҲеҲ°R ж ‘пјӣ
-
第дәҢеҚҒдёүгҖҒеӣӣз« пјҡжқЁж°Ҹзҹ©йҳөжҹҘжүҫпјҢеҖ’жҺ’зҙўеј•е…ій”®иҜҚHashдёҚйҮҚеӨҚзј–з Ғе®һи·өпјӣ
-
第дәҢеҚҒе…ӯз« пјҡеҹәдәҺз»ҷе®ҡзҡ„ж–ҮжЎЈз”ҹжҲҗеҖ’жҺ’зҙўеј•зҡ„зј–з ҒдёҺе®һи·өпјӣ
-
д»ҺHadhoopжЎҶжһ¶дёҺMapReduceжЁЎејҸдёӯи°Ҳжө·йҮҸж•°жҚ®еӨ„зҗҶпјӣ
- 第еҚҒе…ӯ~第дәҢеҚҒз« пјҡе…ЁжҺ’еҲ—пјҢи·іеҸ°йҳ¶пјҢеҘҮеҒ¶жҺ’еәҸпјҢ第дёҖдёӘеҸӘеҮәзҺ°дёҖж¬Ўзӯүй—®йўҳпјӣ
-
http://blog.csdn.net/v_JULY_v/article/category/774945пјӣ
жң¬ж–ҮиҪ¬иҮӘпјҡhttp://blog.csdn.net/v_july_v/article/details/7382693
еЈ°жҳҺпјҡITeyeж–Үз« зүҲжқғеұһдәҺдҪңиҖ…пјҢеҸ—жі•еҫӢдҝқжҠӨгҖӮжІЎжңүдҪңиҖ…д№Ұйқўи®ёеҸҜдёҚеҫ—иҪ¬иҪҪгҖӮ