
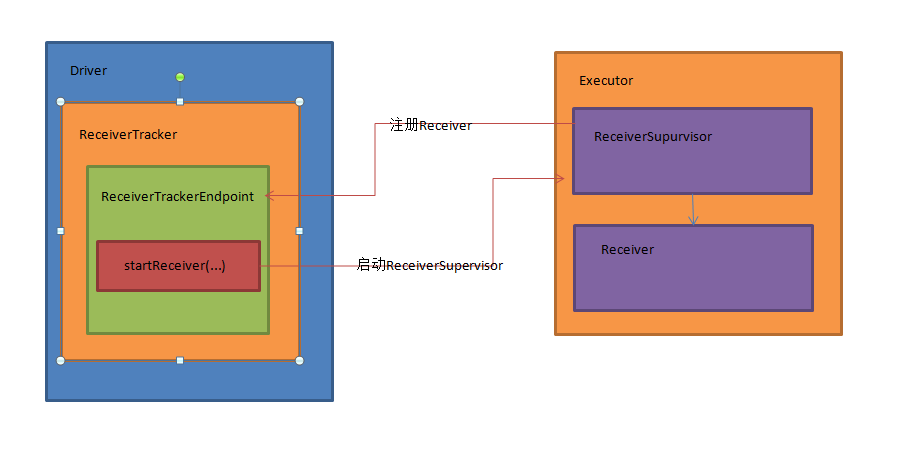
本文将详细解析ReceiverTracker的的架构设计和具体实现
一、ReceiverTracker的主要功能
ReceiverTracker的主要功能有:
1.在Executor上启动Receivers
2.接受Receiver的注册
3.借助ReceivedBlockTracker来管理Receiver接收数据的元数据
4.接受Receiver发送的各种消息,并作相应处理
5.更新Receiver接收数据的速率(也就是限流)
6.不断的等待Receivers的运行状态,只要Receivers停止运行,就重新启动Receiver。也就是Receiver的容错功能。
7.停止Receivers
8.汇报Receiver发送过来的错误信息
二、ReceiverTracker具体功能详解
2.1 启动receiver并管理receiver接收数据的元数据
首先,ReceiverTracker内部有一个ReceiverTrackerEndPoint通讯体endpoint变量,endpoint用来和Receiver和ReceiverTracker本身进行消息通讯。这个ReceiverTrackerEndPoint通讯体在ReceiverTracker启动时被初始化:
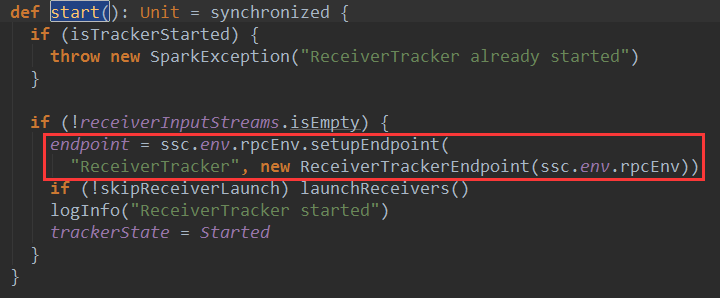
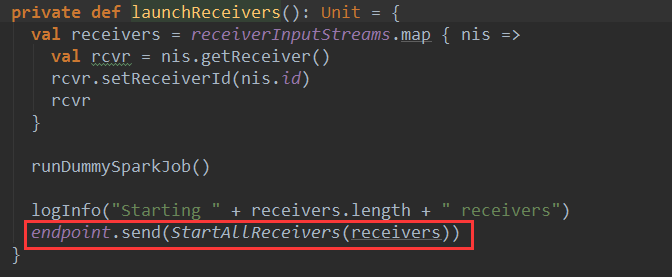
ReceiverTracker启动Receiver时候,向ReceiverTrackerEndPoint通讯体endpoint变量发送了StartAllReceivers(receivers)消息:
Receiver启动后会向ReceiverTracker注册,告诉ReceiverTracker自己启动成功:

代码中的trackerEndpoint就是ReceiverTracker中ReceiverTrackerEndPoint通讯体endpoint的引用。
Receiver会不断将接收的数据封装成Block,并将这些Block推送给BlockManager管理,在将这些Block推送给BlockManager之后,ReceiverSupervisor会将Block的元信息发送给ReceiverTracker的endpoint:
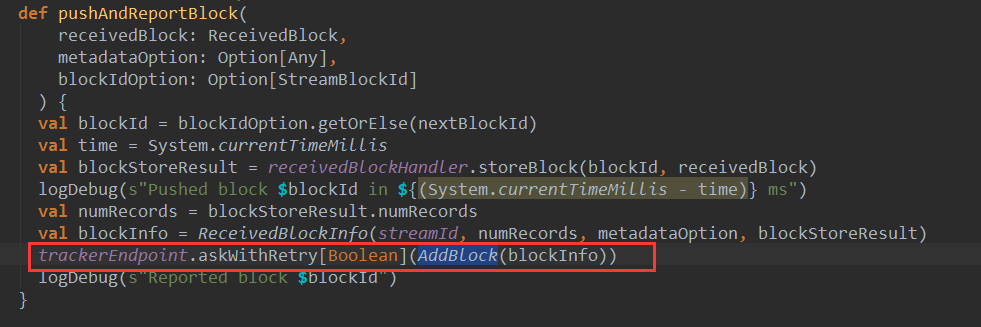
可以看到ReceiverSupervisor向ReceiverTracker的endpoint发送了AddBlock(blockInfo)消息:
ReceiverTracker收到AddBlock(blockInfo)消息后,会启动一个线程进行处理:
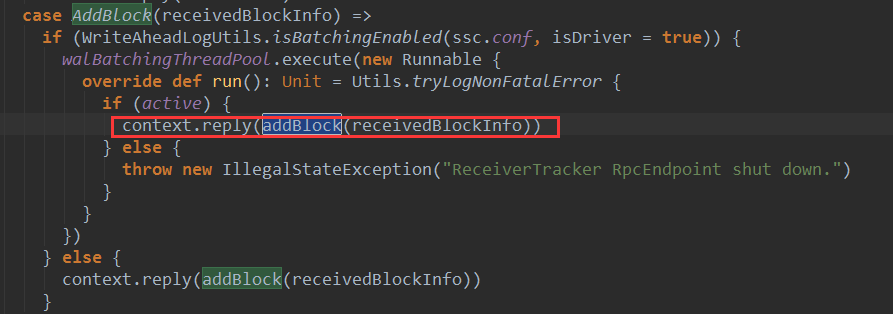
ReceiverTracker收到AddBlock(blockInfo)消息后,调用了addBlock(receiveedBlockInfo)方法进行处理,下面是addBlock的源码:

这里其实调用了receivedBlockTracker的addBlock方法,receivedBlockTracker是ReceivedBlockTracker对象,它是在ReceiverTracker实例化时候被创建:
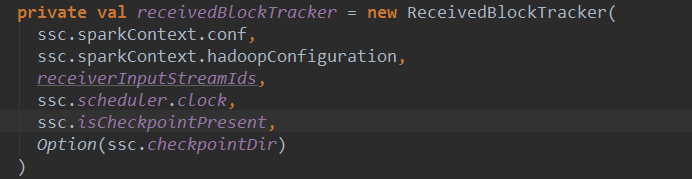
下面看一下ReceivedBlockTracker的addBlock方法:
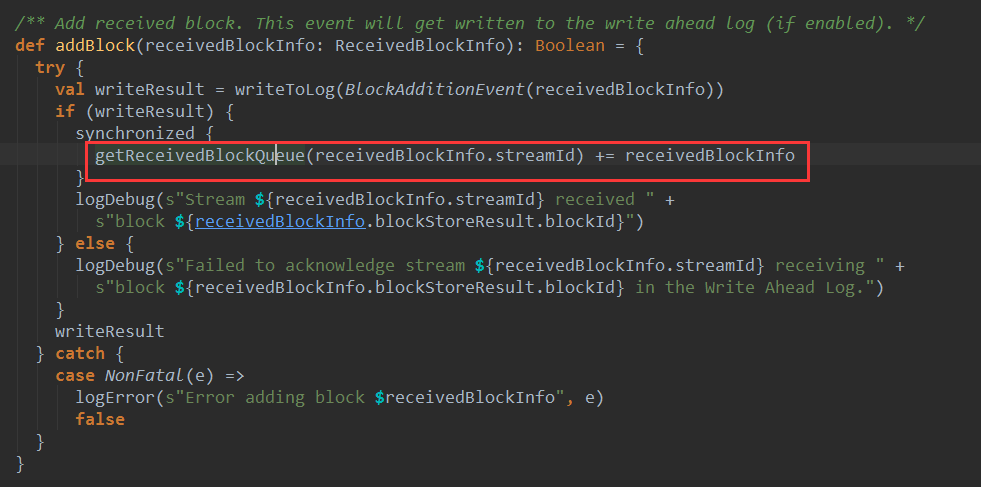
可以看到ReceivedBlockTracker的addBlock方法将block的元信息添加到了一个队队列中,最终是添加到一个叫做streamIdToUnallocatedBlockQueues的HashMap中,其中key是streamId,值是该streamid对应的block队列。

2.2 为Batch分配Block
当spark streaming应用程序动态生成job的时候,JobGenerator会调用generateJobs方法,在该方法中会为批处理分配已经接收的Block
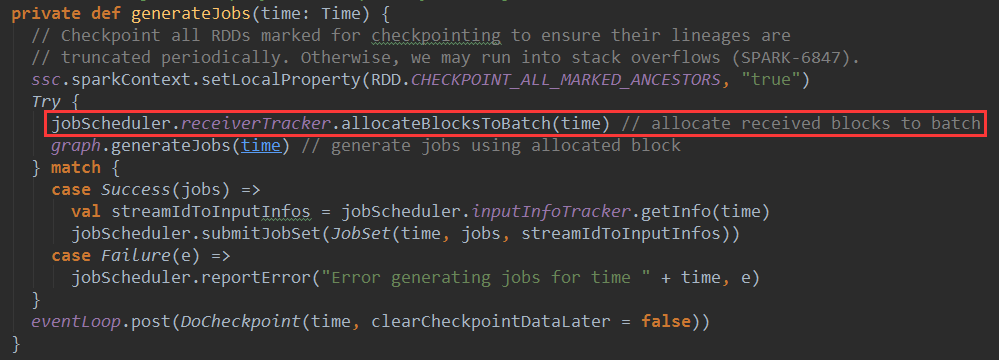
这里调用了jobScheduler中receiverTracker的allocatedBlockToBatch方法,这里的receiverTracker就是ReceiverTracker对象,下面看一下该方法的实现:
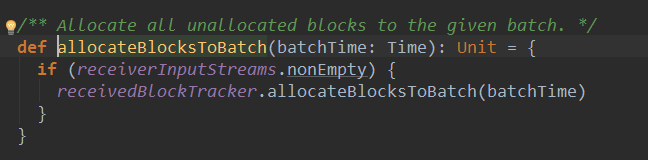
可以看到,最终调用了ReceivedBlockTracker的allocatedBlockToBatch方法:
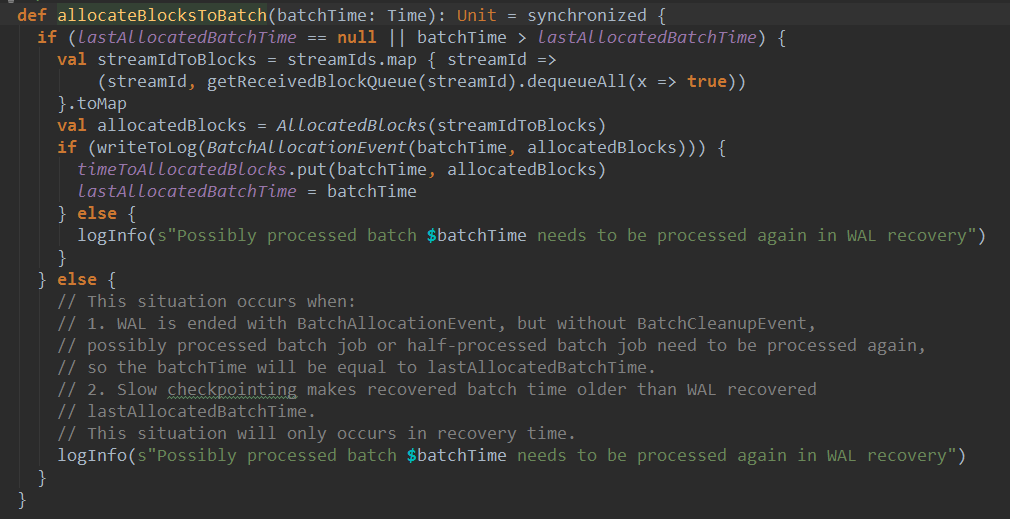
这里先根据streamId,从streamIdToUnallocatedBlockQueues中取出接收到的block队列,并将streamId和block队列封装成AllocatedBlocks,最后根据batchTime将其对应的AllocatedBlocks对象加入timeToAllocatedBlocks中,timeToAllocatedBlocks是一个HashMap:
这样Batch的Block就分配完成。
2.3 ReceiverTracker处理的其他消息
ReceiverTracker中ReceiverTrackerEndpoint的receive方法定义了各种消息的处理逻辑:
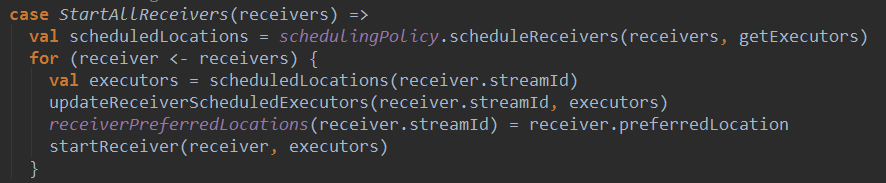
(1) 收到StartAllReceivers(receivers)消息后,ReceiverTracker会为receivers分配executor,并在executor上启动相应的receiver
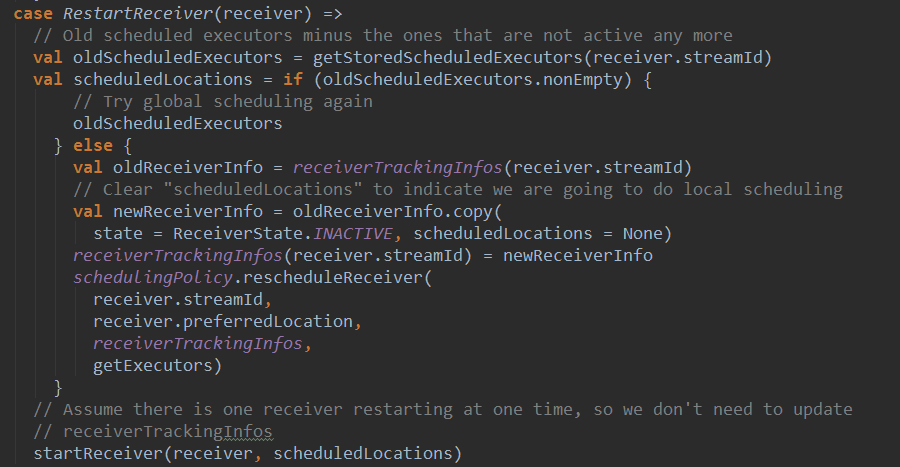
(2)当ReceiverTracker监控到receiver退出返回时,会给ReceiverTrackerEndpoint发送RestartTracker(receiver)消息。收到该消息后,会重新为receiver分配executor启动receiver(如果原来的executor运行正常就在原先的executor上重新启动,否则重新调度executor)。
(3)当Spark Streaming 的job结束后,JobScheduler会调用handleJobCompletion方法,最终会调用cleanupOldBlocksAndBatches方法给endpoint发送CleanupOldBlocks消息:

收到该消息后,会被路由到Receiver 进行Block的清理。
(4)UpdateReceiverRateLimit消息

收到UpdateReceiverRateLimit消息后,会将其路由到receiver,当receiver收到该消息后会调用BlockGenerator的update方法更新Block生成速率。
原创文章,转载请注明:转载自 听风居士博客(http://zhou-yuefei.iteye.com/)



相关推荐
1. **架构组件**:在Spark的主从架构中,包括Driver和Executor两种角色。Driver负责作业的分解和任务调度,而Executor则执行Driver分派的任务。对于资源管理和任务调度,Spark提供了独立模式(Standalone)、Yarn和...
《Apache Spark设计与实现》这本书可能会详细讲解Spark的架构设计,包括其核心组件如弹性分布式数据集(RDD)、Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图计算)。书中可能涵盖了以下知识点: 1...
Apache Spark Streaming是Apache Spark用于处理实时流数据的一个组件。它允许用户使用Spark的高度抽象概念处理实时数据流,并且可以轻松地与存储解决方案、批处理数据和机器学习算法集成。Spark Streaming提供了一种...
8. **Memory Management**:Spark利用内存存储中间结果以提升速度,通过Tungsten项目实现了自定义内存管理,包括堆内和堆外存储,以及垃圾收集优化。 9. **Spark容错机制**:Spark通过检查点和RDD lineage实现容错...
8. **Spark Streaming**:Spark Streaming构建在微批处理之上,通过将流数据划分为小批次处理,实现了低延迟的实时流处理。 9. **MLlib与Spark ML**:Spark提供了机器学习库MLlib,以及基于DataFrame的ML,支持各种...
《深入理解Spark核心思想与源码分析》这本书是Spark技术领域的深度探索,旨在帮助读者全面了解Spark的核心原理和实现机制。Spark作为一个分布式计算框架,以其高效、易用和多模态处理能力在大数据处理领域备受青睐。...
本篇文章将深入探讨Spark的核心组件、架构设计以及关键算法,帮助读者从源码层面了解Spark的强大功能。 1. **Spark架构概述** Spark基于弹性分布式数据集(RDD)的概念,它将数据划分为可并行操作的块,并在集群中...
8. Spark源码分析:书中可能涵盖了Spark源码的深度分析,帮助读者理解其内部工作机制,如调度系统、存储层次、容错机制等,这对于优化Spark应用和解决性能问题非常有价值。 9. 性能优化:Spark的性能优化是学习的...
在本提供的资源中,我们有一个已经编译完成的Spark 1.6.1版本的源码包,这对于想要深入理解Spark工作原理、进行二次开发或者进行性能优化的开发者来说非常有价值。 **Spark核心组件与架构** Spark的核心组件包括:...
Spark是Apache软件基金会下的一个开源大数据处理框架,其主要特点是高效、通用以及易于使用。Spark 2.4.4是该框架的一个稳定版本,它基于Hadoop 2.6进行构建,提供了对大规模数据集的强大处理能力。这个压缩包文件...
在博文链接中提到的iteye博客文章,虽然具体内容无法直接查看,但通常这样的博客会分享Spark的使用经验、源码解析或是特定功能的实现技巧。作者可能会讨论如何利用Spark SQL进行数据查询,或者深入到Spark的源码层面...
书中首先会介绍Spark的基本架构,包括其核心组件如Driver、Executor、Master和Worker节点,以及它们之间的交互关系。 Spark的核心编程模型是RDD(弹性分布式数据集),它是对不可变、分区的数据集的抽象。书中会...
本篇文章将主要探讨Spark 1.6.13的核心概念、架构以及源码中的关键组件。 1. **Spark核心概念** - **RDD(弹性分布式数据集)**:Spark的基础数据抽象,是不可变、分区的记录集合,可以在集群中并行操作。 - **...
《Spark核心思想与源码分析》是一份深入探讨Apache Spark技术的资料,旨在帮助读者理解Spark的内在工作原理,从而更好地应用和优化这个大数据处理框架。Spark作为一个分布式计算框架,以其高效、易用和可扩展性赢得...
Checkpoint 的应用Checkpoint 的应用非常广泛,例如在 SparkStreaming 任务中使用Checkpoint,可以快速恢复应用程序的状态。在 SparkCore 中,Checkpoint 可以用于关键点进行Checkpoint,便于故障恢复。Checkpoint ...
Spark是Apache软件基金会下的一个开源大数据处理框架,其核心组件包括Spark Core、Spark SQL、Spark Streaming、MLlib(机器学习库)和GraphX(图计算)。Spark以其高效、易用和可扩展性著称,尤其在内存计算方面,...
在这个压缩包中,"Dinky-1.0.0"很可能包含了Dinky平台的所有源码和相关资源文件,供用户学习、研究或进行毕业设计论文中的实际操作。源码通常由多个模块组成,包括但不限于核心计算引擎接口、数据输入输出模块、流...
2. **理解API**:Spark提供了丰富的API,如RDD(弹性分布式数据集)、DataFrame/Dataset以及Spark Streaming等,开发者需要熟悉这些接口,以便在插件中正确使用。 3. **实现插件逻辑**:这可能涉及重写或扩展Spark...