
йғ‘жҳҖ еҹәдәҺеҲҳйҮ‘й‘«ж–ҮжЎЈ жңҖеҗҺжӣҙж–°дәҺ2014/12/1
е…ій”®иҜҚпјҡrecsysгҖҒжҺЁиҚҗиҜ„жөӢгҖҒEvaluation of Recommender SystemгҖҒpiwikгҖҒflumeгҖҒkafkaгҖҒstormгҖҒredisгҖҒmysql
жң¬ж–ҮжЎЈйҖӮз”Ёдәәе‘ҳпјҡз ”еҸ‘
В
жҺЁиҚҗзі»з»ҹеҸҜдёҚд»…д»…жҳҜеӣҙзқҖжҺЁиҚҗз®—жі•жү“иҪ¬
В е…ҲжҳҺзЎ®дёҖдёӢпјҢжҲ‘们еұһдәҺе·ҘдёҡйўҶеҹҹгҖӮеҫҲеӨҡеңЁеӯҰжңҜи®әж–ҮйҮҢиЎҢд№Ӣжңүж•Ҳзҡ„ж–°зү№еҘҮз®—жі•пјҢеңЁе·Ҙдёҡз•ҢжҳҜиЎҢдёҚйҖҡзҡ„гҖӮеҪ“е№ҙжҲ‘们еҒҡиҜӯд№үиҒҡеҗҲж—¶пјҢеҲҶиҜҚгҖҒиҒҡзұ»гҖҒзӣёдјјжҖ§и®Ўз®—гҖҒе®һдҪ“иҜҚиҜҶ еҲ«гҖҒжғ…ж„ҹеҲҶжһҗзӯүйўҶеҹҹжңҖз»ҲиҝҳйғҪйҮҮз”ЁдәҶе·Ҙдёҡз•ҢеҚҒеҮ е№ҙеүҚд№ғиҮідәҺеҮ еҚҒе№ҙеүҚе°ұжөҒиЎҢзҡ„жҲҗзҶҹз®—жі•гҖӮеҰӮжһңз®—жі•дёҚиғҪеҶіе®ҡе‘ҪиҝҗпјҢйӮЈд»Җд№ҲжҳҜе…ій”®е‘ўпјҹ
В В з®—жі•+规еҲҷеә“+дәәе·Ҙе№Ійў„пјҲж•ҙзҗҶиҜӯж–ҷгҖҒж ҮиҜҶгҖҒи°ғеҸӮж•°зӯүпјүпјҢеӨ§йғҪжҳҜи„Ҹжҙ»е„ҝзҙҜжҙ»е„ҝгҖӮ
В жҲ–иҖ…еҸ«пјҢзү№еҫҒ+з®—жі•+дәәе·Ҙе№Ійў„пјҢз”Ёзү№еҫҒзј©е°Ҹж•°жҚ®иҢғеӣҙжҲ–йҷҚз»ҙгҖӮ
В жҲ‘еңЁ2009е№ҙжӣҫз»ҸеҶҷйҒ“пјҡ
еңЁиҜӯд№үзҡ„дё–з•ҢйҮҢпјҢеҸҜд»Ҙиҝ‘дјјең°иҜҙпјҡдёҮдәӢдёҮзү©йғҪжҳҜзү№еҫҒжҸҗеҸ–гҖӮВ дҪ еҸӘиҰҒжүҫеҲ°зү№еҫҒпјҢдәӢжғ…е°ұеҘҪеҠһгҖӮвҖҰвҖҰвҖҰвҖҰдҪ жңҹжңӣжҜ•е…¶еҠҹдәҺдёҖеҪ№еҗ—пјҹиҮӘ然иҜӯиЁҖеӨ„зҗҶзҡ„зңҹе®һеә”з”ЁйҮҢжҳҜеҫҲйҡҫжңүд»Җд№ҲеңәжҷҜжүҫеҲ°дёҖдёӘйҖҡеҗғзү№еҫҒзҡ„гҖӮйғҪжҳҜдёҖеұӮдёҖеұӮзү№еҫҒеҸ еҠ зҡ„гҖӮВдёҖеұӮзү№еҫҒеҺ»жҺүдёҖйғЁеҲҶеһғеңҫж•°жҚ®гҖӮеҰӮжӯӨеҸҚеӨҚпјҢз»ҲжҲҗжӯЈжһңгҖӮжіЁж„Ҹж–№жі•и®әгҖӮ
В В жўҒж–ҢеңЁ2012е№ҙеҫ®еҚҡиҜҙйҒ“пјҡ
з»ҹи®ЎзІ—дё”зіҷпјҢд№ғеӨ§й”ӨгҖӮ规еҲҷз»ҶиҖҢзІҫпјҢд№ғе°Ҹй”ӨгҖӮе…ҲеӨ§еңәеҗҺз»ҶжЈӢгҖӮ
 规еҲҷеә“жҖҺд№ҲжқҘзҡ„пјҹеҫ—е»әи®ҫдёҖдәӣж–№дҫҝи§ӮжөӢзҡ„еӨ–еӣҙзі»з»ҹпјҢжүҚиғҪеҸ‘зҺ°зү№еҫҒгҖҒе»әз«Ӣ规еҲҷгҖҒи°ғж•ҙеҸӮж•°гҖҒи§ӮеҜҹж•ҲжһңгҖӮжүҖд»ҘдёҺжӯӨзұ»дјјпјҢеҒҡдәҶжҺЁиҚҗжңҚеҠЎеҗҺпјҢе°ұйңҖиҰҒжҺЁиҚҗж•ҲжһңиҜ„жөӢдәҶгҖӮ
В
жҺЁиҚҗиҜ„жөӢеә”з”ЁеңәжҷҜ
В В з”өе•ҶжҺЁиҚҗеңәжҷҜдёӢжңүйқһеёёжҳҺзЎ®зҡ„жҢҮж Үпјҡ
- жҺЁиҚҗдҪҚеұ•зӨәж¬Ўж•°гҖҒе•Ҷе“ҒжҠ•ж”ҫж¬Ўж•°пјӣ
- жҺЁиҚҗдҪҚеұ•зӨәзӮ№еҮ»зҺҮгҖҒе•Ҷе“ҒжҠ•ж”ҫзӮ№еҮ»зҺҮпјӣ
- жңҖйҮҚиҰҒзҡ„жҳҜдёӢеҚ•иҪ¬еҢ–зҺҮе’ҢжҲҗеҚ•иҪ¬еҢ–зҺҮпјҲжҲ–еҸ«ж”Ҝд»ҳиҪ¬еҢ–зҺҮпјүиҝҷдёӨдёӘзЎ¬жҢҮж ҮгҖӮ
В йӮЈд№ҲжҺЁиҚҗиҜ„жөӢзі»з»ҹеә”е…·еӨҮзҡ„еҠҹиғҪжңүпјҡ
- е®һж—¶пјҲиҮіе°‘жҳҜиҝ‘д№Һе®һж—¶пјүз»ҹи®ЎеҮ дёӘеұ•зӨәжҖ§жҢҮж Ү
- еҢәеҲҶзҪ‘з«ҷз«Ҝе’Ң移еҠЁе®ўжҲ·з«Ҝзҡ„жҺЁиҚҗеұ•зӨәж•Ҳжһң
- иҝӣдёҖжӯҘеҢәеҲҶдёҚеҗҢе®ўжҲ·з«ҜпјҢеҰӮ iOS е’Ң Android
- еӣҫ
- еӣҫ
- зңӢдәҶеҸҲзңӢ
- жөҸи§ҲиҝҮиҜҘе•Ҷе“Ғзҡ„з”ЁжҲ·иҙӯд№°дәҶ
- жӮЁеҸҜиғҪеҜ№д»ҘдёӢе•Ҷе“Ғж„ҹе…ҙи¶ЈпјҲзҢңдҪ е–ңж¬ўпјү
- е•Ҷе“Ғе‘Ёиҫ№е•Ҷе“ҒпјҲжіЁпјҡеҸӘиғҪжҳҜжң¬ең°з”ҹжҙ»жңҚеҠЎзұ»е•Ҷе“Ғпјү
- зӯҫеҲ°еј№зӘ—жҺЁиҚҗ
- е•Ҷе“Ғйҷ„иҝ‘й—Ёеә—
- й—Ёеә—е‘Ёиҫ№зҫҺйЈҹ
- йҷ„иҝ‘еҗғе–қзҺ©д№җ
- еӣҫ
- вҖҰвҖҰ
- зҰ»зәҝиҜ•йӘҢпјҡ
- еҒҡжі•пјҡд»Һж—Ҙеҝ—зі»з»ҹдёӯеҸ–еҫ—з”ЁжҲ·зҡ„иЎҢдёәж•°жҚ®пјҢ然еҗҺе°Ҷж•°жҚ®йӣҶеҲҶжҲҗи®ӯз»ғж•°жҚ®е’ҢжөӢиҜ•ж•°жҚ®пјҢжҜ”еҰӮ80%зҡ„и®ӯз»ғж•°жҚ®е’Ң20%зҡ„жөӢиҜ•ж•°жҚ®пјҲиҝҳеҸҜд»ҘдәӨеҸүйӘҢиҜҒпјүпјҢ然еҗҺеңЁи®ӯз»ғж•°жҚ®йӣҶдёҠи®ӯз»ғз”ЁжҲ·зҡ„е…ҙи¶ЈжЁЎеһӢпјҢеңЁжөӢиҜ•йӣҶдёҠиҝӣиЎҢжөӢиҜ•
- дјҳзӮ№пјҡе®ғдёҚйңҖиҰҒе®һйҷ…з”ЁжҲ·зҡ„дәӨдә’
- зјәзӮ№пјҡзҰ»зәҝе®һйӘҢеҸӘиғҪиҜ„жөӢдёҖдёӘеҫҲзӢӯзӘ„зҡ„ж•°жҚ®йӣҶеҲҮйқўпјҢдё»иҰҒжҳҜе…ідәҺз®—жі•йў„жөӢжҲ–иҖ…иҜ„дј°зҡ„еҮҶзЎ®жҖ§
- зӣ®зҡ„пјҡжҸҗеүҚиҝҮж»ӨжҺүжҖ§иғҪиҫғе·®зҡ„з®—жі•
- еҒҡжі•пјҡйҖҡиҝҮдёҖе®ҡзҡ„规еҲҷжҠҠз”ЁжҲ·йҡҸжңәеҲҶжҲҗеҮ з»„пјҢ并еҜ№дёҚеҗҢз»„зҡ„з”ЁжҲ·йҮҮз”ЁдёҚеҗҢзҡ„жҺЁиҚҗз®—жі•пјҢиҝҷж ·зҡ„иҜқиғҪеӨҹжҜ”иҫғе…¬е№іең°иҺ·еҫ—дёҚеҗҢз®—жі•еңЁе®һйҷ…еңЁзәҝж—¶зҡ„дёҖдәӣжҖ§иғҪжҢҮж Ү
- еӣҫ
- жҡҙйңІеҮәжқҘпјҢи®©жҲ‘们жүӢе·Ҙе°ұеҸҜд»ҘжҸҗдәӨпјҢзңӢзңӢж•Ҳжһң
В
жҺЁиҚҗиҜ„жөӢжҠҖжңҜйҖүеһӢ
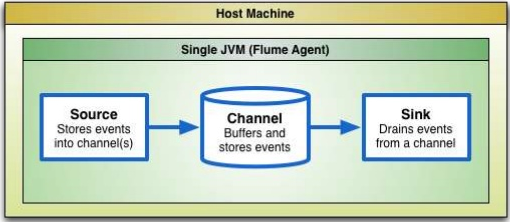
В иҜҙеҲ°е®һж—¶ж—Ҙеҝ—иҒҡеҗҲе’ҢеӨ„зҗҶпјҢиҝҳеҫ—жҳҜ flume+kafka+stormпјҢжүҖд»ҘжҠҖжңҜйҖүеһӢжҳҜпјҡ
В В Piwik+Flume+Kafka+Storm+Redis+MySQL
В
жҺЁиҚҗиҜ„жөӢж•°жҚ®жөҒиҪ¬жөҒзЁӢ
- ж•°жҚ®дёҠжҠҘпјҡвҖ”вҖ”Piwik
- дё»з«ҷжң¬иә«йғЁзҪІдәҶ ејҖжәҗжөҒйҮҸз»ҹи®Ўзі»з»ҹ PiwikпјҢжүҖд»ҘеңЁзҪ‘йЎөзҡ„еҗ„з§ҚжҺЁиҚҗдҪҚдёҠжҢү规еҲҷеҹӢзӮ№еҚіеҸҜ
- е®һдҫӢпјҡвҖңжөҸи§ҲиҝҮиҜҘе•Ҷе“Ғзҡ„з”ЁжҲ·иҝҳиҙӯд№°дәҶвҖқжҺЁиҚҗж Ҹ第дёҖдҪҚе•Ҷе“Ғзҡ„aе…ғзҙ еўһеҠ дәҶwweеұһжҖ§пјҡwwe="t:goods,w:rec,id:ae45c145d1045c9d51c270c066018685,rec:101_01_103"
- Piwik йӣҶзҫӨзҡ„жҜҸдёҖеҸ°жңҚеҠЎеҷЁдёҠйғҪйғЁзҪІдәҶВ Flume Agent
- agent дјҡеҗ‘В жҺЁиҚҗж•°жҚ®ж”¶йӣҶ Flume йӣҶзҫӨВ жҺЁйҖҒж—Ҙеҝ—пјҢиӯ¬еҰӮй…ҚзҪ®дёәжҜҸеўһеҠ дёҖиЎҢж—Ҙеҝ—е°ұжҺЁйҖҒпјҢжҲ–жҜҸ5еҲҶй’ҹжҺЁйҖҒдёҖж¬Ў
- жүӢжңәе®ўжҲ·з«Ҝзҡ„еҹӢзӮ№ж—Ҙеҝ—еҲҷеӯҳж”ҫеңЁж— зәҝжңҚеҠЎеҷЁз«Ҝзҡ„ MySQL дёӯпјҢжүҖд»ҘжҲ‘们用и„ҡжң¬жҜҸеҲҶй’ҹиҜ»еҸ–дёҖж¬Ўж•°жҚ®пјҢж”ҫеҲ° flume зҡ„зӣ‘жҺ§зӣ®еҪ•дёӢ
- з”ұдәҺж•°жҚ®йҮҮйӣҶйҖҹеәҰе’Ңж•°жҚ®еӨ„зҗҶйҖҹеәҰдёҚдёҖе®ҡеҢ№й…ҚпјҢеӣ жӯӨж·»еҠ дёҖдёӘж¶ҲжҒҜдёӯй—ҙ件 Linkedin KafkaВ дҪңдёәзј“еҶІ
- ж•°жҚ®жөҒиҪ¬ж–№ејҸдёә Flume Source-->Flume Channel-->Flume SinkпјҢйӮЈд№ҲжҲ‘们еҶҷдёҖдёӘВ Kafka SinkВ дҪңдёәж¶ҲжҒҜз”ҹдә§иҖ…пјҢе°Ҷ sink д»Һ channel йҮҢжҺҘ收еҲ°зҡ„ж—Ҙеҝ—ж•°жҚ®еҸ‘йҖҒз»ҷж¶ҲжҒҜж¶Ҳиҙ№иҖ…
-
 еӣҫ
еӣҫ
- Storm иҙҹиҙЈеҜ№йҮҮйӣҶеҲ°зҡ„ж•°жҚ®иҝӣиЎҢе®һж—¶и®Ўз®—
- Storm SpoutВ иҙҹиҙЈд»ҺеӨ–йғЁзі»з»ҹдёҚй—ҙж–ӯең°иҜ»еҸ–ж•°жҚ®пјҢ并组装жҲҗ tuple еҸ‘е°„еҮәеҺ»пјҢtuple иў«еҸ‘е°„еҗҺеңЁ Topology дёӯдј ж’ӯ
- жүҖд»ҘжҲ‘们иҰҒеҶҷдёҖдёӘВ Kafka SpoutВ дҪңдёәж¶ҲжҒҜж¶Ҳиҙ№иҖ…жӢүж—Ҙеҝ—ж•°жҚ®
- еҶҚеҶҷдәӣ Storm Bolt еӨ„зҗҶж•°жҚ®
-
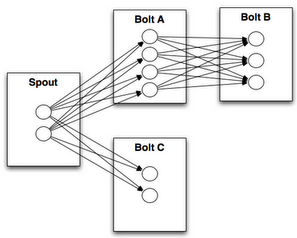 пјҢдёҖдёӘTopologyзҡ„з»“жһ„зӨәж„Ҹеӣҫ
пјҢдёҖдёӘTopologyзҡ„з»“жһ„зӨәж„Ҹеӣҫ
- Storm Bolt е®һж—¶еҲҶжһҗж•°жҚ®д№ӢеҗҺпјҢе°Ҷз»ҹи®Ўз»“жһңеҶҷе…Ҙ Redis
- иҜ„жөӢзі»з»ҹе®һж—¶ж•°жҚ®зӣҙжҺҘд»Һ Redis дёӯиҜ»еҸ–пјҢ并жҹҘиҜўдё»з«ҷж•°жҚ®еә“иҝҪиёӘжҲҗеҚ•жғ…еҶөпјҢеҗҢжӯҘеҲ° MySQL дёӯпјҢдҪңдёәжҠҘиЎЁеұ•зӨәж•°жҚ®жәҗ
В з®ҖиҖҢиЁҖд№ӢпјҢж•°жҚ®жҢүеҰӮдёӢж–№ејҸжөҒиҪ¬пјҡ
- piwik javascript
- piwik servers
- flume agent
- иҮӘе®ҡд№ү kafka sink
- иҮӘе®ҡд№ү kafka spout
- иҮӘе®ҡд№ү storm bolt
- redis
- иҜ„жөӢзі»з»ҹи®Ўз®—
- mysql
- иҜ„жөӢзі»з»ҹжҠҘиЎЁеұ•зӨә
В
Flume+Kafka+Stormеёёи§Ғй—®йўҳ
В иҷҪ然жҲ‘们зҡ„е®һж—¶жөҒйҮҸз»ҹи®Ўе’ҢжҺЁиҚҗиҜ„жөӢзі»з»ҹеқҮйҮҮз”ЁдәҶ flume+kafka+storm ж–№жЎҲпјҢдҪҶиҰҒжіЁж„ҸиҝҷдёӘж–№жЎҲд№ҹжңүдёҖдәӣе°Ҹеқ‘гҖӮдёӢйқўж‘ҳеҪ•дёҖдәӣ第дёүж–№зҡ„з»“и®әпјҡ
- еҰӮ жһңй…ҚзҪ®дёәжҜҸж–°еўһдёҖжқЎж—Ҙеҝ—е°ұйҮҮйӣҶпјҢйӮЈд№Ҳ flume еҲ° kafka зҡ„е®һж—¶ж•°жҚ®еҸҜиғҪдјҡз”ұдәҺеҚ•жқЎиҝҮеҝ«пјҢйҖ жҲҗ storm spout ж¶Ҳиҙ№ kafka ж¶ҲжҒҜйҖҹзҺҮи·ҹдёҚдёҠгҖӮ延时еҸҜд»ҘжҳҜж•°жҚ®еҸ‘е°„еҲ° stream дёӯеҗҺиҝӣиЎҢ hbase зҡ„и®Ўз®—ж“ҚдҪңеј•иө·зҡ„пјҲжіЁпјҡhbase зҡ„жҖ§иғҪзЎ®е®һе Әеҝ§пјҢдёҚйҖӮеҗҲиҝҷз§Қе®һж—¶ж•°жҚ®еӨ„зҗҶпјҢе°Өе…¶жҳҜеҠ дәҶиҫғеӨҡзҙўеј•д№ӢеҗҺпјүпјӣ
- еҸҜеҸӮиҖғзҡ„дёҖдёӘж•°жҚ®пјҡstorm еҚ•жқЎжөҒж°ҙзәҝзҡ„еӨ„зҗҶиғҪеҠӣеӨ§зәҰдёә 20000 tupe/s (жҜҸдёӘtupleеӨ§е°Ҹдёә1000еӯ—иҠӮ)пјӣ
- tuple иҝҮеӨҡпјҢдјҡз”ұдәҺ kafka зҡ„ message йңҖиҰҒ new String() иҝӣиЎҢиҺ·еҸ–пјҢдјҡжҠҘ gc зҡ„ејӮеёёпјӣ
- tuple еңЁ stream дёӯзҡ„еӨ§йҮҸе Ҷз§ҜпјҢйҖ жҲҗи¶…ж—¶иҮӘеҠЁеӣһи°ғ fail() зҡ„еҮҪж•°пјӣ
- еҸҜд»ҘиҝӣиЎҢеӨҡ tuple з»“жһ„зҡ„дјҳеҢ–пјҢжҠҠеӨҡдёӘ log жү“еҢ…жҲҗдёҖдёӘ tuple
- е°ұдёҖиҲ¬жғ…еҶөиҖҢиЁҖпјҢеҚ•жқЎеҸ‘е°„иғҪжүӣеҫ—дҪҸ
В
Kafka Sink ж¶ҲжҒҜз”ҹдә§иҖ…д»Јз ҒзүҮж®ө
|
KafkaSink.java
|
|
importВ kafka.javaapi.producer.Producer;
вҖҰвҖҰ
public classВ KafkaSinkВ extendsВ AbstractSinkВ implementsВ Configurable {
вҖҰвҖҰ
В privateВ Producer<String,В byte[]> producer;
вҖҰвҖҰ
В @Override
В publicВ Status process()В throwsВ EventDeliveryException {
В В ChannelВ channel = getChannel();
В Transaction tx = channel.getTransaction();
В В tryВ {
В В tx.begin();
В В EventВ e = channel.take();
В В ifВ (e ==В null) {
В В tx.rollback();
В В В returnВ Status.BACKOFF;
В В }
В В producer.send(newВ KeyedMessage<String,В byte[]>(topic, e.getBody()));
В В tx.commit();В
В В returnВ Status.READY;
В }В catchВ (ExceptionВ e) {
|
В
Kafka Spout ж¶ҲжҒҜж¶Ҳиҙ№иҖ…д»Јз ҒзүҮж®ө
spout жңүеӨҡдёӘпјҢжҲ‘们жҢ‘ kafka spout зңӢдёӢгҖӮ
|
KafkaSpout.java
|
|
public abstract classВ KafkaSpoutВ implementsВ IRichSpout {
вҖҰвҖҰ
В @Override
В publicВ voidВ activate() {
вҖҰвҖҰ
В В forВ (finalВ KafkaStream<byte[], byte[]> stream : streamList) {
В В executor.submit(newВ Runnable() {
В В В @Override
В В В public voidВ run() {
В В В ConsumerIterator<byte[],В byte[]> iterator = stream.iterator();
В В В В whileВ (iterator.hasNext()) {
В В В В ifВ (spoutPending.get() <= 0) {
В В В В sleep(1000);
В В В В В continue;
В В В В }
В В В В MessageAndMetadata<byte[],В byte[]> next = iterator.next();
В В В В byte[] message = next.message();
В В В В List<Object> tuple =В null;
В В В В tryВ {
В В В В В tuple = generateTuple(message);
В В В В }В catchВ (Exception e) {
В В В В e.printStackTrace();
В В В В }
В В В В if (tuple ==В nullВ || tuple.size() != outputFieldsLength) {
В В В В В continue;
В В В В }
В В В В collector.emit(tuple);
В В В В spoutPending.decrementAndGet();
В В В }
В В В }
|
В
Storm Bolt д»Јз ҒзүҮж®ө
жңүеӨҡдёӘиҮӘе®ҡд№ү boltпјҢжҢ‘дёҖдёӘзңӢдёӢгҖӮ
|
EvaluateBolt.java
|
|
public classВ EvaluateBoltВ extendsВ BaseBasicBolt {
вҖҰвҖҰ
В @Override
В public voidВ execute(Tuple input, BasicOutputCollector collector) {
вҖҰвҖҰ
В В ifВ (LogWebsiteSpout.PAGE_EVENT_BROWSE.equals(event)) {
В В ifВ (LogWebsiteSpout.PAGE_TYPE_GOODS.equals(pageType)) {
В В incrBaseStatistics(baseKeyMap, BROWSE_ALL, 1);
В В }В else ifВ (LogWebsiteSpout.PAGE_TYPE_PAY1.equals(pageType)) {
В В incrBaseStatistics(baseKeyMap, ORDER_ALL, 1);
В В }
В В String recDisplay = input.getStringByField(LogWebsiteSpout.FIELD_REC_DISPLAY);
В В recDisplayStatistics(recDisplay, time, pageType, baseKeyMap);
В }В else ifВ (LogWebsiteSpout.PAGE_EVENT_CLICK.equals(event)) {
В В String recType = input.getStringByField(LogWebsiteSpout.FIELD_REC_TYPE);
|
В
иҜ„жөӢжҢҮж Үе®ҡд№үпјҡ
- жҠ•ж”ҫзӮ№еҮ»зҺҮпјҡжҺЁиҚҗжөҸи§ҲйҮҸ/жҺЁиҚҗе•Ҷе“ҒжҠ•ж”ҫйҮҸ
- еұ•зҺ°зӮ№еҮ»зҺҮпјҡжҺЁиҚҗжөҸи§ҲйҮҸ/жҺЁиҚҗдҪҚеұ•зҺ°ж¬Ўж•°
- жҺЁиҚҗеұ•зӨәзҺҮ:пјҡжҺЁиҚҗдҪҚеұ•зӨәж¬Ўж•°/жҖ»жөҸи§ҲйҮҸ
- жҺЁиҚҗжөҸи§ҲйҮҸпјҡз»Ҹз”ұжҺЁиҚҗдә§з”ҹзҡ„жөҸи§ҲйҮҸ
- жҺЁиҚҗе•Ҷе“ҒжҠ•ж”ҫйҮҸпјҡжҺЁиҚҗдҪҚжҠ•ж”ҫзҡ„жҺЁиҚҗе•Ҷе“Ғж•°йҮҸпјҲеҰӮпјҡз”ЁжҲ·жөҸи§ҲAе•Ҷе“ҒпјҢйӮЈеңЁжөҸи§ҲжҲ–иҙӯд№°жҺЁиҚҗдҪҚдә§з”ҹзҡ„жҺЁиҚҗе•Ҷе“Ғдёә5дёӘпјҢеҲҷжҺЁиҚҗе•Ҷе“ҒжҠ•ж”ҫйҮҸ+5пјү
- жҺЁиҚҗдҪҚеұ•зҺ°ж¬Ўж•°пјҡеҰӮжһңжҺЁиҚҗдҪҚжңүжҺЁиҚҗе•Ҷе“Ғ并еұ•зӨәпјҢи®Ўж•°+1
В
-over-



зӣёе…іжҺЁиҚҗ
жҺЁиҚҗзі»з»ҹпјҲRecommendation SystemпјҢз®Җз§°RecSysпјүжҳҜдҝЎжҒҜиҝҮж»Өзі»з»ҹзҡ„дёҖз§ҚпјҢдё»иҰҒз”ЁдәҺдёӘжҖ§еҢ–жҺЁиҚҗпјҢеё®еҠ©з”ЁжҲ·еңЁжө·йҮҸдҝЎжҒҜдёӯеҸ‘зҺ°д»–们еҸҜиғҪж„ҹе…ҙи¶Јзҡ„еҶ…е®№жҲ–дә§е“ҒгҖӮRecSysеңЁз”өе•ҶгҖҒйҹід№җгҖҒз”өеҪұгҖҒж–°й—»зӯүеӨҡдёӘйўҶеҹҹйғҪжңүе№ҝжіӣеә”з”ЁпјҢжһҒеӨ§ең°...
JaniceWuoз”өеҪұжҺЁиҚҗйЎ№зӣ®еӨҚеҲ¶дёӯзҡ„й—®йўҳдёҺи§ЈеҶіж–№жЎҲ_CF recSys.zipJaniceWuoз”өеҪұжҺЁиҚҗйЎ№зӣ®еӨҚеҲ¶дёӯзҡ„й—®йўҳдёҺи§ЈеҶіж–№жЎҲ_CF recSys.zipJaniceWuoз”өеҪұжҺЁиҚҗйЎ№зӣ®еӨҚеҲ¶дёӯзҡ„й—®йўҳдёҺи§ЈеҶіж–№жЎҲ_CF recSys.zipJaniceWuoз”өеҪұжҺЁиҚҗйЎ№зӣ®еӨҚеҲ¶дёӯзҡ„...
еңЁжң¬иө„жәҗ"recsys-challenge2015.rar"дёӯпјҢеҢ…еҗ«дәҶдҪҝз”ЁPythonиҝӣиЎҢж•°жҚ®жҢ–жҺҳе’Ңжһ„е»әжҺЁиҚҗзі»з»ҹзҡ„дёҖдәӣе…ій”®и„ҡжң¬гҖӮиҝҷдәӣи„ҡжң¬еҜ№дәҺзҗҶи§Је’Ңе®һи·өжҺЁиҚҗзі»з»ҹз®—жі•жңүзқҖйҮҚиҰҒзҡ„д»·еҖјгҖӮи®©жҲ‘们йҖҗдёҖи§ЈжһҗжҜҸдёӘж–Ү件并жҺўи®Ёе…¶дёӯж¶үеҸҠзҡ„жҠҖжңҜе’ҢжҰӮеҝөгҖӮ 1....
Recsys-offlineжҳҜдёҖдёӘжҺЁиҚҗзі»з»ҹзҡ„зҰ»зәҝи®Ўз®—йғЁеҲҶпјҢеҹәзЎҖж•°жҚ®йҮҮз”ЁSwiftйҮҮйӣҶзҡ„ж•°жҚ®пјҢе®ғпјҡ 1.еҹәдәҺHadoopпјҢMahoutпјҢHBaseпјҢZookeeperејҖеҸ‘зҡ„2.зҺ°жңүзҡ„з®—жі•еҸӘж”ҜжҢҒеҲҶеёғејҸпјҢеҹәдәҺйЎ№зӣ®пјҢKmeansзҡ„жҺЁиҚҗ3.ж”ҜжҢҒз®ҖеҚ•зҡ„еҸҜй…ҚзҪ®4.ж”ҜжҢҒе®ҡж—¶...
#Recsys-еүҚз«ҜRecsys-frontend жҳҜдёҖдёӘжҳ“дәҺи®ҫзҪ®зҡ„еүҚз«ҜжҺЁиҚҗзі»з»ҹ (recsys)пјҢз”ұз»„еҗҲиҖҢжҲҗгҖӮ е®ғжҸҗдҫӣдәҶдёҖдёӘеҹәдәҺ HTML зҡ„еүҚз«ҜпјҢе…Ғи®ёжөҸи§ҲпјҲжңҖж–°пјүз”өеҪұзҡ„зӣ®еҪ•пјҢжҸҗдҫӣиҜ„зә§пјҢзӮ№еҮ»жҢүй’®и®Ўз®—е’ҢеҸҜи§ҶеҢ–еӨҡдёӘжҺЁиҚҗз®—жі•зҡ„жҺЁиҚҗз»“жһңгҖӮ жҹҘзңӢ...
еҹәдәҺCFзҡ„з”өеҪұжҺЁиҚҗпјҢдҪҝз”Ёж ҮеҮҶж•°жҚ®йӣҶMovieLinesпјҢеҲ©з”ЁPython3е®һзҺ°пјҢж–ҮжЎЈеҢ…жӢ¬пјҡMovieLinesж•°жҚ®йӣҶпјҢж•°жҚ®йў„еӨ„зҗҶзЁӢеәҸпјҢCFжҺЁиҚҗпјҢLFMжҺЁиҚҗпјҢPrankжҺЁиҚҗгҖӮдёҚйңҖи°ғиҜ•и§ЈеҺӢеҚіеҸҜдҪҝз”ЁпјҢдәІжөӢеҸҜз”ЁгҖӮи°ўи°ўеӨ§е®¶ж”ҜжҢҒ
иҜҘеӯҳеӮЁеә“еҢ…еҗ«жҲ‘们й’ҲеҜ№RecSys 2018жҢ‘жҲҳзҡ„и§ЈеҶіж–№жЎҲзҡ„Pythonжәҗд»Јз ҒгҖӮ иө„ж–ҷеҮҶеӨҮ дёәдәҶе°ҶжҲ‘们жҸҗдәӨзҡ„еҶ…е®№еӨҚеҲ¶еҲ°RecSys 2018жҢ‘жҲҳиөӣпјҢжӮЁйҰ–е…ҲйңҖиҰҒд»ҺиөӣдёӢиҪҪзҷҫдёҮж’ӯж”ҫеҲ—иЎЁж•°жҚ®йӣҶе’ҢжҢ‘жҲҳиөӣйӣҶгҖӮ иҝҷдёӨдёӘж•°жҚ®йӣҶеҲҶеҲ«и®°еҪ•дёәJSONж–Ү件е’Ң...
жң¬йЎ№зӣ®вҖңfc-recsys-lectureвҖқдё“жіЁдәҺдҪҝз”ЁжңәеҷЁеӯҰд№ жҠҖжңҜжһ„е»әжҺЁиҚҗеј•ж“ҺпјҢж—ЁеңЁеё®еҠ©з”ЁжҲ·еҸ‘зҺ°ж„ҹе…ҙи¶Јзҡ„еҶ…е®№жҲ–дә§е“ҒпјҢд»ҺиҖҢжҸҗеҚҮз”ЁжҲ·дҪ“йӘҢе’Ңе•Ҷдёҡд»·еҖјгҖӮиҝҷдёӘйЎ№зӣ®дёҺдёҖеңәе…ідәҺжҺЁиҚҗзі»з»ҹзҡ„и®Іеә§зҙ§еҜҶе…іиҒ”пјҢжҸҗдҫӣдәҶжәҗд»Јз Ғе’Ңзӣёе…іж•°жҚ®пјҢд»Ҙдҫҝ...
гҖҠжҺЁиҚҗзі»з»ҹе®һзҺ°вҖ”вҖ”ж·ұе…Ҙи§ЈжһҗRecSys-masterгҖӢ еңЁдҝЎжҒҜжҠҖжңҜйЈһйҖҹеҸ‘еұ•зҡ„д»ҠеӨ©пјҢжҺЁиҚҗзі»з»ҹпјҲRecommendation SystemпјҢз®Җз§°RecSysпјүе·Із»ҸжҲҗдёәдәҶдёӘжҖ§еҢ–дҝЎжҒҜжңҚеҠЎзҡ„ж ёеҝғжҠҖжңҜд№ӢдёҖпјҢе№ҝжіӣеә”з”ЁдәҺз”өе•ҶгҖҒйҹід№җгҖҒз”өеҪұзӯүдј—еӨҡйўҶеҹҹгҖӮRecSys-...
еңЁ2019е№ҙзҡ„жҺЁиҚҗзі»з»ҹжҢ‘жҲҳпјҲRecSys Challenge 2019пјүдёӯпјҢз ”з©¶иҖ…们е…ұдә«дәҶдёҖдёӘж•°жҚ®йӣҶпјҢд»ҘдҝғиҝӣжҺЁиҚҗз®—жі•зҡ„еҸ‘еұ•е’ҢиҜ„дј°гҖӮиҝҷдёӘж•°жҚ®йӣҶиў«з§°дёә"recsys-2019"пјҢе®ғеҢ…еҗ«дё°еҜҢзҡ„з”ЁжҲ·иЎҢдёәдҝЎжҒҜпјҢеҸҜд»Ҙз”ЁдәҺи®ӯз»ғе’ҢжөӢиҜ•жҺЁиҚҗжЁЎеһӢгҖӮ иҜҘжҢ‘жҲҳеә“...
гҖҗжҺЁиҚҗзі»з»ҹжҰӮиҝ°гҖ‘ жҺЁиҚҗзі»з»ҹжҳҜдҝЎжҒҜжҠҖжңҜйўҶеҹҹдёӯзҡ„дёҖдёӘйҮҚиҰҒеҲҶж”ҜпјҢе®ғдё»иҰҒиҙҹиҙЈеңЁжө·йҮҸдҝЎжҒҜдёӯдёәз”ЁжҲ·жҺЁиҚҗжңҖж„ҹе…ҙи¶ЈгҖҒжңҖжңүд»·еҖјзҡ„еҶ…е®№жҲ–дә§е“ҒгҖӮиҝҷзұ»зі»з»ҹе№ҝжіӣеә”з”ЁдәҺз”өе•ҶгҖҒз”өеҪұжҺЁиҚҗгҖҒйҹід№җжөҒеӘ’дҪ“зӯүеңәжҷҜпјҢйҖҡиҝҮеҲҶжһҗз”ЁжҲ·зҡ„еҺҶеҸІиЎҢдёәгҖҒ...
еңЁгҖҠжҺЁиҚҗзі»з»ҹејҖеҸ‘е®һжҲҳгҖӢдёҖд№ҰдёӯпјҢдҪңиҖ…й«ҳйҳіеӣўйҳҹж·ұе…Ҙжө…еҮәең°д»Ӣз»ҚдәҶжҺЁиҚҗзі»з»ҹзҡ„зҗҶи®әдёҺе®һи·өпјҢж¶өзӣ–дәҶд»Һж•°жҚ®йў„еӨ„зҗҶгҖҒжЁЎеһӢжһ„е»әеҲ°ж•ҲжһңиҜ„дј°зҡ„е…ЁиҝҮзЁӢгҖӮжң¬е®һи·өйЎ№зӣ®еҹәдәҺиҜҘд№ҰеҶ…е®№пјҢжҸҗдҫӣдәҶе®һйҷ…ж“ҚдҪңзҡ„е№іеҸ°пјҢеё®еҠ©ејҖеҸ‘иҖ…жӣҙеҘҪең°жҺҢжҸЎжҺЁиҚҗ...
иҜҘеӯҳеӮЁеә“еҢ…еҗ«з”ЁдәҺз”ҹжҲҗжңҖз»Ҳи§ЈеҶіж–№жЎҲзҡ„и„ҡжң¬гҖӮ еӣўйҳҹжҲҗе‘ҳпјҡ пјҢ пјҢ пјҢMaksym SemikinпјҢMeri Liis TreimannпјҢChristian SafkaгҖӮ дә§з”ҹжҸҗдәӨ жӯҘйӘӨ0пјҡеҲӣе»әдёҖдёӘж–°зҡ„CondaзҺҜеўғ并е®үиЈ…жүҖйңҖзҡ„еә“ create conda --name recsys ...
"RecSys-Book-Notes"жҳҜдёҖдёӘдё“жіЁдәҺжҺЁиҚҗзі»з»ҹйўҶеҹҹзҡ„еӯҰд№ иө„жәҗйӣҶеҗҲпјҢе…¶дёӯеҢ…еҗ«дәҶеӨҡдёӘзӣёе…ід№ҰзұҚзҡ„笔记е’ҢжҖқз»ҙеҜјеӣҫпјҢеё®еҠ©иҜ»иҖ…ж·ұе…ҘзҗҶи§ЈиҝҷдёҖйўҶеҹҹзҡ„ж ёеҝғжҰӮеҝөе’ҢжҠҖжңҜгҖӮ йҰ–е…ҲпјҢжҲ‘们关注еҲ°гҖҠPythonж•°жҚ®з§‘еӯҰжүӢеҶҢгҖӢгҖӮиҝҷжң¬д№ҰжҳҜPython...
жҺЁиҚҗзі»з»ҹпјҲRecommendation SystemпјҢз®Җз§°RecSysпјүжҳҜдҝЎжҒҜиҝҮж»Өзі»з»ҹзҡ„дёҖз§ҚпјҢе®ғж—ЁеңЁйў„жөӢз”ЁжҲ·еҸҜиғҪж„ҹе…ҙи¶Јзҡ„зү©е“ҒжҲ–жңҚеҠЎпјҢд»ҘжӯӨжҸҗдҫӣдёӘжҖ§еҢ–зҡ„жҺЁиҚҗгҖӮеңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢжҺЁиҚҗзі»з»ҹе·ІжҲҗдёәз”өеӯҗе•ҶеҠЎгҖҒзӨҫдәӨеӘ’дҪ“гҖҒеңЁзәҝеЁұд№җзӯүйўҶеҹҹзҡ„йҮҚиҰҒз»„жҲҗ...
Recsys-onlineжҳҜдёҖдёӘжҺЁиҚҗзі»з»ҹзҡ„еңЁзәҝи®Ўз®—йғЁеҲҶпјҢжҺҘ收пјҢеӯҳеӮЁж—Ҙеҝ—并з”ҹжҲҗз”ЁжҲ·йҰ–йҖүпјҢе®ғпјҡ 1.еҹәдәҺKafkaпјҢStormпјҢHBaseпјҢZookeeperејҖеҸ‘зҡ„2.жҖ»дҪ“еҸӘж”ҜжҢҒзҡ„жөҒзЁӢпјҡд»ҺKafkaдёӯиҜ»еҸ–ж•°жҚ®==> Stormж•°жҚ®еӨ„зҗҶ===> HBaseеӯҳеӮЁ еҪ“еүҚзүҲжң¬...
жң¬йЎ№зӣ®вҖң18a-RecSys-Wangshuyun-2015вҖқжҳҜдёҖдёӘе…Ҙй—Ёзә§еҲ«зҡ„жҺЁиҚҗзі»з»ҹиҜҫзЁӢдҪңдёҡпјҢж—ЁеңЁеё®еҠ©еҲқеӯҰиҖ…жҺҢжҸЎжҺЁиҚҗзі»з»ҹзҡ„еҹәжң¬еҺҹзҗҶе’Ңе®һзҺ°ж–№жі•гҖӮеңЁGitHubдёҠејҖжәҗпјҢе®ғжҸҗдҫӣдәҶйҖҗжӯҘеӯҰд№ е’Ңе®һи·өзҡ„жңәдјҡгҖӮ йЎ№зӣ®е·ҘдҪңеҲҶдёәдёүдёӘйғЁеҲҶпјҡWork1гҖҒWork2...
еңЁжӯӨдәӨдә’ејҸз ”и®ЁдјҡдёӯпјҢжҲ‘们е°Ҷд»Ӣз»Қе’Ңе®һи·өжңүе…іжҺЁиҚҗзі»з»ҹзҡ„жңҖйҮҚиҰҒжҰӮеҝөпјҢеҚідёӘжҖ§еҢ–дҪ“йӘҢиғҢеҗҺзҡ„еҠӣйҮҸгҖӮ еңЁз ”и®Ёдјҡз»“жқҹд№ӢеүҚпјҢжӮЁе°ҶиғҪеӨҹд»ҘйқһжӯЈејҸе’Ңдә’еҠЁзҡ„ж–№ејҸжһ„е»әе’ҢиҜ„дј°иҮӘе·ұзҡ„жҺЁиҚҗзі»з»ҹпјҢ并еңЁжҲ‘们зҡ„еҜјеёҲзҡ„её®еҠ©дёӢи®Ёи®әз»“жһңгҖӮ еҰӮжһңжӮЁ...
еңЁжң¬йЎ№зӣ®"RecSys-DAE-tensorflow"дёӯпјҢжҲ‘们关注зҡ„жҳҜеҲ©з”ЁTensorFlowжЎҶжһ¶жһ„е»әдёҖдёӘеҹәдәҺйҷҚеҷӘиҮӘзј–з ҒеҷЁ(Denoising Autoencoder, DAE)зҡ„жҺЁиҚҗзі»з»ҹгҖӮйҷҚеҷӘиҮӘзј–з ҒеҷЁжҳҜдёҖз§Қж·ұеәҰеӯҰд№ жЁЎеһӢпјҢе®ғеңЁдј з»ҹзҡ„иҮӘзј–з ҒеҷЁеҹәзЎҖдёҠеўһеҠ дәҶеҷӘеЈ°еӨ„зҗҶ...
recsys-nlp-graph йҖҡиҝҮзҹ©йҳөеҲҶи§ЈпјҲ第 1 йғЁеҲҶпјүд»ҘеҸҠ nlp е’ҢеӣҫеҪўжҠҖжңҜпјҲ第 2 йғЁеҲҶпјүеңЁз®ҖеҚ• recsys дёҠзҡ„дёӘдәәйЎ№зӣ®зҡ„жңӘи®°еҪ•д»Јз ҒгҖӮ дҪңдёәиҒҡдјҡзҡ„дёҖйғЁеҲҶиҝӣиЎҢеҲҶдә«гҖӮ зӣёе…іж–Үз« пјҡ 第 1 йғЁеҲҶпјҡ 第 2 йғЁеҲҶпјҡ и°ҲиҜқе’Ңе№»зҒҜзүҮпјҡ ж•°жҚ® ...