
郑昀 创建于2014/10/30 最后更新于2014/10/31
一)选型:Shib+Presto
应用场景:即席查询(Ad-hoc Query)
1.1.即席查询的目标
使用者是产品/运营/销售运营的数据分析师;要求数据分析师掌握查询SQL查询脚本编写技巧,掌握不同业务的数据存储在不同的数据集市里;不管他们的计算任务是提交给 数据库 还是 Hadoop,计算时间都可能会很长,不可能在线等待;所以,使用者提交了一个计算任务(PIG/SQL/Hive SQL),控制台告知任务已排队,给出大致的计算时间等友情提示, 这些作业的权重较低,使用者和管理员可以查看排队中的计算任务,包括已执行任务的执行时间、运行时长和运行结果;当计算任务有结果后,控制台界面有通知提示,或者发邮件提示,使用者可以在线查看和下载数据。
1.2.即席查询的当下技术选型
图形交互界面:Shib;
数据查询引擎:Facebook Presto。
1.3.为什么要更换数据查询引擎?
基于 MapReduce 的 Hadoop 适合数据批处理,但不适合即席查询场景。基于 InnoDB/MyISAM 存储引擎的 MySQL 自然也不适合。当然我们也观察过 InfiniDB/InfoBright 这种列式存储数据库引擎(仍基于MySQL),它们更适合基本不再变更的历史 归档数据,所以不太适合电商应用场景。
我们的鹰眼(Tracing)项目就曾折翼在即时查询上,后端的 HBase 扛不住在大数据量下的实时插入和查询。
『Hive 更适合于长时间的批处理查询分析,Impala、Shark、Stinger和Presto 适用于实时交互式SQL查询,它们给数据分析师提供了快速实验、验证想法的大数据分析工具。所以可以先使用 Hive 进行数据转换处理,之后使用这四个系统中的一个在 Hive 处理后的结果数据集上进行快速的数据分析。
Impala、Shark、Stinger和Presto四个系统都是类SQL实时大数据查询分析引擎,但是它们的技术侧重点完全不同。而且它们也不是为了替换Hive而生,Hive 在做数据仓库时是非常有价值的。这四个系统与Hive都是构建在Hadoop之上的数据查询工具,各有不同的侧重适应 面,但从客户端使用来看它们与Hive有很多的共同之处,如数据表元数据、Thrift接口、ODBC/JDBC驱动、SQL语法、灵活的文件格式、存储 资源池等。』——《开源大数据查询分析引擎现状,2014》
最终我们选择了 Presto。
FaceBook于2013年11月份开源了Presto,一个分布式SQL查询引擎,它被设计为用来专门进行高速、实时的数据分析。它支持标准的ANSI SQL,包括复杂查询、聚合(aggregation)、连接(join)和窗口函数(window functions)。Presto设计了一个简单的数据存储的抽象层,来满足在不同数据存储系统(包括HBase、HDFS、Scribe等)之上都可以使用SQL进行查询。
Presto 简化的架构如下图1所示,客户端将 SQL 查询发送到 Presto 的协调器。协调器会进行语法检查、分析和规划查询计划。调度器将执行的管道组合在一起,将任务分配给那些离数据最近的节点,然后监控执行过程。客户端从输 出段中将数据取出,这些数据是从更底层的处理段中依次取出的。
Presto 的运行模型与 Hive 有着本质的区别。Hive 将查询翻译成多阶段的 Map-Reduce 任务,一个接着一个地运行。 每一个任务从磁盘上读取输入数据并且将中间结果输出到磁盘上。然 而 Presto 引擎没有使用 Map-Reduce。它使用了一个定制的查询执行引擎和响应操作符来支持SQL的语法。除了改进的调度算法之外,所有的数据处理都是在内存中进行的。不 同的处理端通过网络组成处理的流水线。这样会避免不必要的磁盘读写和额外的延迟。这种流水线式的执行模型会在同一时间运行多个数据处理段,一旦数据可用的 时候就会将数据从一个处理段传入到下一个处理段。
这样的方式会大大的减少各种查询的端到端响应时间。
同时,Presto 设计了一个简单的数据存储抽象层,来满足在不同数据存储系统之上都可以使用 SQL 进行查询。存储连接器目前支持除 Hive/HDFS 外,还支持 HBase、Scribe 和定制开发的系统。
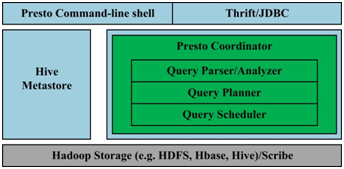
图1. Presto架构
1.4.在HUE和Shib之间选择了后者
HUE 大家可能都听说过。Shib 相对陌生一些,它是这么介绍自己的:WebUI for query engines: Hive and Presto。
潘高锋介绍了二者的优缺点。
HUE
开发语言:Python
优 点:Hue 是一个能够与 Apache Hadoop 交互的 Web 应用程序。一个开源的 Apache Hadoop UI。我们已经在生产环境使用Hue了,而且Hue在管理Hbase/Pig/Hive方面有很大的优势,它还附带了一个Oozie的应用程序,用于创建 和监控工作流程 。
缺点:Hue 是一个比较重的工具,改动起来涉及的东西会比较多,而且以后每次升级都可能会导致我们改动的功能要再修改 。
Shib
开发语言:Nodejs
优点:Shib 通过简单的配置就可以直接操作 hive 和 presto。代码量比较小,修改起来工作量少很多 。
缺点:对 Nodejs 不熟悉,有学习成本 。
最后我们选定了代码量和开发量相对较少的 Shib 。
1.5.即席查询的界面展示
登录 shib 后,选择数据仓库 presto-wowo_dw。编写 sql 的时候,可以把表结构的提示框移到一边,边写边参照,如下图所示。
图2 边查询边看数据结构
由于所有的查询都是异步的,所以可以在“我的查询”列表中看到自己的查询语句的执行状态和执行结果,这样不用自己在一直在查询界面等待了,如下图所示。
图3 我的查询
还可以把自己常用的查询语句保存到“书签”里,这是一个很实用的功能。
接下来就可以开发SQL查询结果站内通知机制以及更复杂的用户访问权限控制机制了。
二)选型:HUE+Oozie
应用场景:Hadoop集群计算任务调度和管理平台。
2.1.数据平台跑数据所面对的困难
电商数据平台的报表维度有很多种,有总体简报角度、运营角度、媒体投放角度等,也可以有商品、商户、用户、竞品等维度,还有日报、周报和月报之分。所以对 应了很多个计算任务。每一个计算任务可以视为一个工作流,毕竟计算过程是很复杂的、一环套一环。那么 HUE+Oozie 就是可视化管理和调度这些工作流的。
没有 Oozie 之前是什么样?
一,计算脚本被配置为定时任务,跑飞了只能从海量日志中大海捞针,不知道断在哪儿,只能手动清数据从头再跑。任务计算时间特别长,不知道当前跑到哪一步了,还需要多久能跑完。
二,难以精确控制任务A跑完了才能跑任务B,只能在不同定时任务之间留足够长的时间间隔,缺乏弹性。
2.2.Oozie是什么
Oozie是一种 Java Web 应用程序,它运行在 Tomcat 中,并使用数据库来存储以下内容:工作流定义、当前运行的工作流实例(包括实例的状态和变量)。
我们最欣赏它的三点:
- Oozie允许失败的工作流从任意点重新运行,这对于处理工作流中由于前一个耗时活动而出现瞬态错误的情况非常有用。
- 工作流执行过程可视化。
- 工作流的每一步的日志、错误信息都可以点击查看,并实时滚动,便于排查问题。
2.3.还是看截图吧
先选择HUE导航栏上的“Oozie Editor/Dashboard”,看到默认面板:
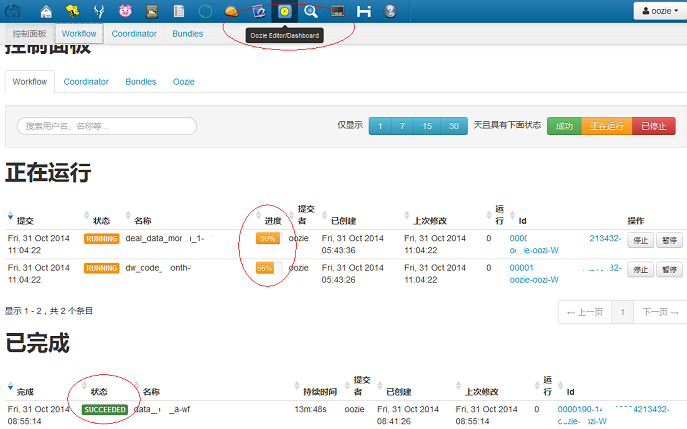
图5 oozie默认面板
点击某个工作流,进入详情页:
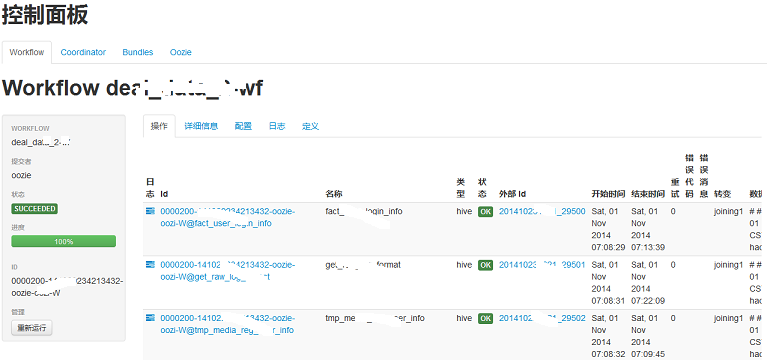
图6 工作流详情页
一个工作流的定义如下图7所示,XML格式的 hPDL。hPDL是一种很简洁的语言,只会使用少数流程控制和动作节点。控制节点会定义执行的流程,并包含工作流的起点和终点(start、end和 fail节点)以及控制工作流执行路径的机制(decision、fork和join节点)。
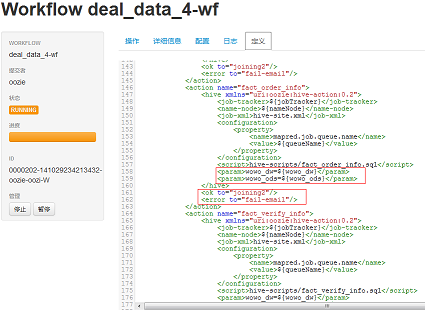
图7 工作流定义
现在,数据平台的各种计算任务都迁移到 Oozie 中,按照 hPDL 语言格式一一重新定义。
三)总结一下数据中心的各种技术选型
罗列如下,不再解释:
Apache Hadoop/Hive/HBase
Apache Pig
Flume/Kafka/Storm/Sqoop/awk
Facebook Presto
MySQL
HUE/Shib
Oozie
-over-



相关推荐
1、资源内容:基于spark sql引擎的即席查询服务+源代码+文档说明 2、代码特点:内含运行结果,不会运行可私信,参数化编程、参数可方便更改、代码编程思路清晰、注释明细,都经过测试运行成功,功能ok的情况下才上传...
【大数据项目之电商数仓(5即席查询Presto&Kylin)V4.0】 在大数据领域,为了高效地处理和分析海量数据,即席查询系统扮演着至关重要的角色。本篇主要讨论两个流行的即席查询工具——Presto和Kylin,它们在电商数仓...
总的来说,"大数据项目之电商数仓(5即席查询Presto&Kylin)V4.0"是一个全面展示如何利用现代大数据技术提升数据分析能力的实例。通过深入了解Presto和Kylin的工作原理及其在实际项目中的应用,我们可以更好地理解和...
其次,Spark SQL支持SQL接口,允许熟悉SQL的用户无需学习新的API就能进行数据查询。通过创建一个临时视图或数据表,用户可以使用标准SQL语句执行查询,这对于数据分析师和业务人员来说非常友好。 为了构建即席查询...
本文档是关于大数据项目之电商数仓的详细介绍,特别是关于Presto即席查询数据仓库的设计和实现。下面是从标题、描述、标签和部分内容中提炼出的知识点: Presto 概念 Presto 是一种开源的分布式SQL查询引擎,能够...
基于spark sql引擎的即席查询服务文档+源码+优秀项目+全部资料.zip 【备注】 1、该项目是个人高分项目源码,已获导师指导认可通过,答辩评审分达到95分 2、该资源内项目代码都经过测试运行成功,功能ok的情况下才...
传统的数据查询方式无法满足高速数据查询的需求,而即席查询技术的出现满足了这种需求。Spinach正是基于Spark SQL实现即席查询的解决方案,旨在满足企业对高速数据查询的需求。 2. Spark SQL的优点 Spark SQL是...
### Presto在优步:千万亿字节规模的...总之,通过引入Presto,优步不仅解决了大规模数据查询的速度问题,还实现了数据处理的统一化和高效性。这一变革对于优步来说意义重大,为未来的数据处理和分析奠定了坚实的基础。
程序员,在校生,程序员行业爱好者
这款工具一经推出便受到广泛关注,每天有超过1000名Facebook员工使用Presto来执行超过30000个查询任务,每日扫描的数据量更是达到了1PB以上。测试结果显示,Presto的平均性能是Hive等传统离线数据分析产品的10倍。 ...
即席查询(Ad-Hoc Query)是一种不固定的查询模式,查询模式相对不固定,数据没有(时间/成本)做过多预处理,数据暂时不知如何处理,交互式(Interactive),查询具有较高时效性。 二、为什么选择Spark Spark相比...
基于spark sql引擎的即席查询服务源代码+文档说明(大作业&课程设计),含有代码注释,满分大作业资源,新手也可看懂,期末大作业、课程设计、高分必看,下载下来,简单部署,就可以使用。该项目可以作为课程设计...
- **大数据量实时查询**:Presto能够在短时间内处理大量的数据查询请求,支持实时数据查询的需求。 - **Ad-hoc即席查询**:用户可以随时提出查询需求,Presto能够快速响应并返回结果。 - **数据抽取与导入**:利用...
大数据即席查询技术.pptx
Presto在Facebook主要应用于几个方面:数据仓库的即席(Ad-hoc)/交互式查询、数据仓库的批处理、用户面对产品的分析以及各种特殊存储系统的分析。 2. 数据仓库架构和工具 在数据仓库架构中,Presto与Hadoop生态...
trino-server-412.tar.gz 分布式多数据源即席查询引擎Trino安装包(preso) 下载地址 https://repo1.maven.org/maven2/io/trino/trino-server/412/trino-server-412.tar.gz
Baidu基于Spark SQL构建即席查询平台