我们在用矩阵处理真实数据的时候,一般都是非常稀疏矩阵,为了节省存储空间,通常只会存储非0的数据。
下面我们来做一个稀疏矩阵:
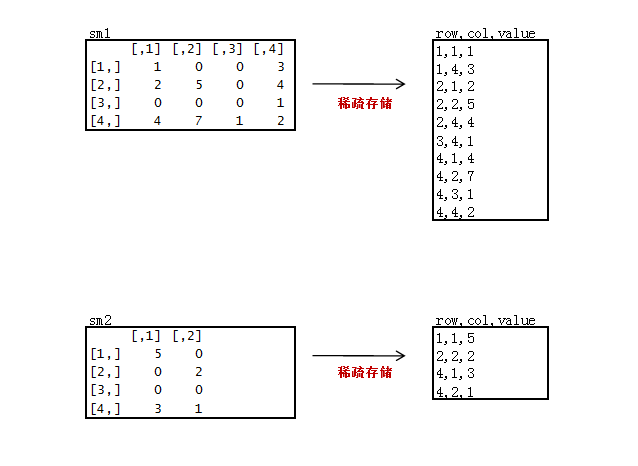
新建2个稀疏矩阵数据文件sm1.csv, sm2.csv
只存储非0的数据,3列存储,第一列“原矩阵行”,第二列“原矩阵列”,第三列“原矩阵值”。
sm1.csv
1,1,1
1,4,3
2,1,2
2,2,5
2,4,4
3,4,1
4,1,4
4,2,7
4,3,1
4,4,2
sm2.csv
1,1,5
2,2,2
4,1,3
4,2,1
代码:
package org.edu.bupt.xiaoye.sparsemartrix;
import java.io.IOException;
import java.net.URI;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SparseMartrixMultiply {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag; // m1 or m2
private int rowNumA = 4; // 矩阵A的行数,因为要在对B的矩阵处理中要用
private int colNumA = 4;// 矩阵A的列数
private int rolNumB = 4;
private int colNumB = 2;// 矩阵B的列数
private static final Text k = new Text();
private static final Text v = new Text();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getName();// 判断读的数据集
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] records = value.toString().split(",");
int x = Integer.parseInt(records[0]);
int y = Integer.parseInt(records[1]);
int num = Integer.parseInt(records[2]);
if (flag.equals("m1")) {
String[] vs = value.toString().split(",");
for (int j = 0; j < colNumB; j++) {
k.set(x + "," + (j + 1));
v.set("A" + ":" + y + "," + num);
context.write(k, v);
}
} else if (flag.equals("m2")) {
for (int j = 0; j < rowNumA; j++) {
k.set((j + 1) + "," + y);
v.set("B:" + x + "," + num);
context.write(k, v);
}
}
}
}
public static class MyReducer extends
Reducer<Text, Text, Text, IntWritable> {
private static IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
/*
* 这里和一般矩阵不同
* 一般矩阵中,当进行第二次reduce方法调用的时候,会对数组a和b的所有元素都重新赋值
* 而在稀疏矩阵中,不会对数组的所有元素重新赋值,从而会发生上次调用reduce方法残留的数组元素值对这一次reduce产生影响。
*/
int[] a = new int[4];
int[] b = new int[4];
for (Text value : values) {
String[] vs = value.toString().split(":");
if (vs[0].equals("A")) {
String[] ints = vs[1].toString().split(",");
a[Integer.parseInt(ints[0]) - 1] = Integer
.parseInt(ints[1]);
} else {
String[] ints = vs[1].toString().split(",");
b[Integer.parseInt(ints[0]) - 1] = Integer
.parseInt(ints[1]);
}
}
// 用矩阵A的行乘矩阵B的列
int sum = 0;
for (int i = 0; i < 4; i++) {
sum += a[i] * b[i];
}
v.set(sum);
context.write(key, v);
}
}
public static void run(Map<String, String> path) throws Exception {
String input = path.get("input");
String output = path.get("output");
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(input), conf);
final Path outPath = new Path(output);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
conf.set("hadoop.job.user", "hadoop");
// conf.set("mapred.job.tracker", "10.103.240.160:9001");
final Job job = new Job(conf);
FileInputFormat.setInputPaths(job, input);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1);// 设置个数为1
FileOutputFormat.setOutputPath(job, outPath);
job.waitForCompletion(true);
}
}
驱动类:
package org.edu.bupt.xiaoye.sparsemartrix;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
public class MainRun {
public static final String HDFS = "hdfs://10.103.240.160:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
martrixMultiply();
}
public static void martrixMultiply() {
Map<String, String> path = new HashMap<String, String>();
path.put("input", HDFS + "/usr/hadoop/SparseMatrix");// HDFS的目录
path.put("output", HDFS + "/usr/hadoop/SparseMatrix/output");
try {
SparseMartrixMultiply.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
}这里注意需要注意的地方:
在reducer中定义数组a和b的时候,不要定义成MyMapper类成员。我就是因为这里定义成了成员变量导致出了错误调了好久。
/*
* 这里和一般矩阵不同
* 一般矩阵中,当进行第二次reduce方法调用的时候,会对数组a和b的所有元素都重新赋值
* 而在稀疏矩阵中,不会对数组的所有元素重新赋值,从而会发生上次调用reduce方法残留的数组元素值对这一次reduce产生影响。
*/
分享到:





相关推荐
因此,大数据计算引入了新的数据表示和计算方式,如分布式计算框架(如Hadoop MapReduce)、列式存储、稀疏矩阵等,这些技术可以高效地处理大规模数据。 标签中的“数组”是大数据处理中的基本数据结构。数组是一种...
这篇文章由来自复旦大学计算机科学学院的Qiuhong Li、Ke Dai、Wei Wang和Peng Wang撰写,提出了一个新的框架——LI-MR(Local Iteration MapReduce),用以改善可以由重复的矩阵-向量乘法描述的一类图操作符。...
5.找到两个巨大的稀疏矩阵相乘的结果矩阵 数据中的每一行都具有以下形式: A,0、172、5 在此,A是该行所属的矩阵。 0是行号。 172是列数 5是A [0] [172]处的值 采用工作链方法。 第一项工作是乘法,第二项工作...
内容概要:本文主要探讨了SNS单模无芯光纤的仿真分析及其在通信和传感领域的应用潜力。首先介绍了模间干涉仿真的重要性,利用Rsoft beamprop模块模拟不同模式光在光纤中的传播情况,进而分析光纤的传输性能和模式特性。接着讨论了光纤传输特性的仿真,包括损耗、色散和模式耦合等参数的评估。随后,文章分析了光纤的结构特性,如折射率分布、包层和纤芯直径对性能的影响,并探讨了镀膜技术对光纤性能的提升作用。最后,进行了变形仿真分析,研究外部因素导致的光纤变形对其性能的影响。通过这些分析,为优化光纤设计提供了理论依据。 适合人群:从事光纤通信、光学工程及相关领域的研究人员和技术人员。 使用场景及目标:适用于需要深入了解SNS单模无芯光纤特性和优化设计的研究项目,旨在提高光纤性能并拓展其应用场景。 其他说明:本文不仅提供了详细的仿真方法和技术细节,还对未来的发展方向进行了展望,强调了SNS单模无芯光纤在未来通信和传感领域的重要地位。
发那科USM通讯程序socket-set
嵌入式八股文面试题库资料知识宝典-WIFI.zip
源码与image
内容概要:本文详细探讨了物流行业中路径规划与车辆路径优化(VRP)的问题,特别是针对冷链物流、带时间窗的车辆路径优化(VRPTW)、考虑充电桩的车辆路径优化(EVRP)以及多配送中心情况下的路径优化。文中不仅介绍了遗传算法、蚁群算法、粒子群算法等多种优化算法的理论背景,还提供了完整的MATLAB代码及注释,帮助读者理解这些算法的具体实现。此外,文章还讨论了如何通过MATLAB处理大量数据和复杂计算,以得出最优的路径方案。 适合人群:从事物流行业的研究人员和技术人员,尤其是对路径优化感兴趣的开发者和工程师。 使用场景及目标:适用于需要优化车辆路径的企业和个人,旨在提高配送效率、降低成本、确保按时交付货物。通过学习本文提供的算法和代码,读者可以在实际工作中应用这些优化方法,提升物流系统的性能。 其他说明:为了更好地理解和应用这些算法,建议读者参考相关文献和教程进行深入学习。同时,实际应用中还需根据具体情况进行参数调整和优化。
嵌入式八股文面试题库资料知识宝典-C and C++ normal interview_8.doc.zip
内容概要:本文介绍了基于灰狼优化算法(GWO)的城市路径规划优化问题(TSP),并通过Matlab实现了该算法。文章详细解释了GWO算法的工作原理,包括寻找猎物、围捕猎物和攻击猎物三个阶段,并提供了具体的代码示例。通过不断迭代优化路径,最终得到最优的城市路径规划方案。与传统TSP求解方法相比,GWO算法具有更好的全局搜索能力和较快的收敛速度,适用于复杂的城市环境。尽管如此,算法在面对大量城市节点时仍面临运算时间和参数设置的挑战。 适合人群:对路径规划、优化算法感兴趣的科研人员、学生以及从事交通规划的专业人士。 使用场景及目标:①研究和开发高效的路径规划算法;②优化城市交通系统,提升出行效率;③探索人工智能在交通领域的应用。 其他说明:文中提到的代码可以作为学习和研究的基础,但实际应用中需要根据具体情况调整算法参数和优化策略。
嵌入式八股文面试题库资料知识宝典-Intel3.zip
嵌入式八股文面试题库资料知识宝典-2019京东C++.zip
嵌入式八股文面试题库资料知识宝典-北京光桥科技有限公司面试题.zip
内容概要:本文详细探讨了十字形声子晶体的能带结构和传输特性。首先介绍了声子晶体作为新型周期性结构在物理学和工程学中的重要地位,特别是十字形声子晶体的独特结构特点。接着从散射体的形状、大小、排列周期等方面分析了其对能带结构的影响,并通过理论计算和仿真获得了能带图。随后讨论了十字形声子晶体的传输特性,即它对声波的调控能力,包括传播速度、模式和能量分布的变化。最后通过大量实验和仿真验证了理论分析的正确性,并得出结论指出散射体的材料、形状和排列方式对其性能有重大影响。 适合人群:从事物理学、材料科学、声学等相关领域的研究人员和技术人员。 使用场景及目标:适用于希望深入了解声子晶体尤其是十字形声子晶体能带与传输特性的科研工作者,旨在为相关领域的创新和发展提供理论支持和技术指导。 其他说明:文中还对未来的研究方向进行了展望,强调了声子晶体在未来多个领域的潜在应用价值。
嵌入式系统开发_USB主机控制器_Arduino兼容开源硬件_基于Mega32U4和MAX3421E芯片的USB设备扩展开发板_支持多种USB外设接入与控制的通用型嵌入式开发平台_
e2b8a-main.zip
少儿编程scratch项目源代码文件案例素材-火柴人跑酷(2).zip
内容概要:本文详细介绍了HarmonyOS分布式远程启动子系统,该系统作为HarmonyOS的重要组成部分,旨在打破设备间的界限,实现跨设备无缝启动、智能设备选择和数据同步与连续性等功能。通过分布式软总线和分布式数据管理技术,它能够快速、稳定地实现设备间的通信和数据同步,为用户提供便捷的操作体验。文章还探讨了该系统在智能家居、智能办公和教育等领域的应用场景,展示了其在提升效率和用户体验方面的巨大潜力。最后,文章展望了该系统的未来发展,强调其在技术优化和应用场景拓展上的无限可能性。 适合人群:对HarmonyOS及其分布式技术感兴趣的用户、开发者和行业从业者。 使用场景及目标:①理解HarmonyOS分布式远程启动子系统的工作原理和技术细节;②探索该系统在智能家居、智能办公和教育等领域的具体应用场景;③了解该系统为开发者提供的开发优势和实践要点。 其他说明:本文不仅介绍了HarmonyOS分布式远程启动子系统的核心技术和应用场景,还展望了其未来的发展方向。通过阅读本文,用户可以全面了解该系统如何通过技术创新提升设备间的协同能力和用户体验,为智能生活带来新的变革。
嵌入式八股文面试题库资料知识宝典-C and C++ normal interview_1.zip
少儿编程scratch项目源代码文件案例素材-激光反弹.zip