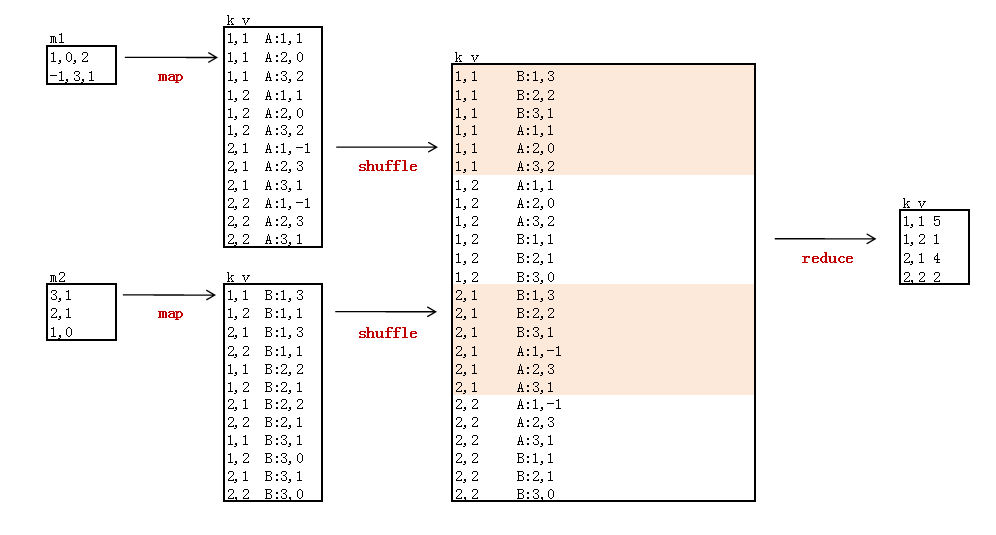
算法的实现思路:
图片和思路来自于http://blog.fens.me/hadoop-mapreduce-matrix/
-
新建2个矩阵数据文件:m1, m2
-
m1
1,0,2
-1,3,1
m2
3,1
2,1
1,0
-
新建启动程序:MainRun.java
-
新建MR程序:MartrixMultiply.java
MainRun.java
public class MainRun {
public static final String HDFS = "hdfs://10.103.240.160:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
martrixMultiply();
}
public static void martrixMultiply() {
Map<String, String> path = new HashMap<String, String>();
path.put("m1", "logfile/matrix/m1.csv");// 本地的数据文件
path.put("m2", "logfile/matrix/m2.csv");
path.put("input", HDFS + "/usr/hadoop/matrix");// HDFS的目录
path.put("input1", HDFS + "/usr/usr/matrix/m1");
path.put("input2", HDFS + "/usr/usr/matrix/m2");
path.put("output", HDFS + "/usr/hadoop/matrix/output");
try {
MartrixMultiply.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
}
MartrixMultiply.java
public class MartrixMultiply {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag; // m1 or m2
private int rowNumA = 2; // 矩阵A的行数,因为要在对B的矩阵处理中要用
private int colNumA = 3;// 矩阵A的列数
private int rolNumB = 3;
private int colNumB = 2;// 矩阵B的列数
private int rowIndexA = 1; // 矩阵A,当前在第几行
private int rowIndexB = 1; // 矩阵B,当前在第几行
private static final Text k = new Text();
private static final Text v = new Text();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getName();// 判断读的数据集
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] elements = value.toString().split(",");
/*
* i表示在这一行中,该元素是第一个元素 j表示该行应与B矩阵的哪一列进行相乘 k.set(rowIndexA + "," + (j
* + 1)); 行:是由rowIndexA决定的 列:是由该行与矩阵B相乘的那一列决定的
*/
if (flag.equals("m1")) {
// 对于每一个elements元素进行处理,elements.length=colNumA
for (int i = 0; i < colNumA; i++) {
for (int j = 0; j < colNumB; j++) {
k.set(rowIndexA + "," + (j + 1));
v.set("A" + ":" + (i + 1) + "," + elements[i]);
context.write(k, v);
}
}
rowIndexA++;
}
/*
* i表示在这一行中,该元素是第几个元素 j表示A矩阵的第几行与该矩阵进行相乘 k.set((j+1) + "," +
* (i+1))表示该元素的在C矩阵中位置 行:是由与该元素相乘的A矩阵的第几行决定的 列:是有该元素在B矩阵中第几列决定的
* rowIndexB决定了该元素在相乘得到的和中占第几个位置
*/
else if (flag.equals("m2")) {
for (int i = 0; i < colNumB; i++) {
for (int j = 0; j < rowNumA; j++) {
k.set((j + 1) + "," + (i + 1));
v.set("B:" + rowIndexB + "," + elements[i]);
context.write(k, v);
}
}
}
rowIndexB++;
}
}
public static class MyReducer extends
Reducer<Text, Text, Text, IntWritable> {
private static int[] a = new int[3];
private static int[] b = new int[3];
private static IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
for (Text value : values) {
String[] vs = value.toString().split(":");
if (vs[0].equals("A")) {
String[] ints = vs[1].toString().split(",");
a[Integer.parseInt(ints[0])-1] = Integer.parseInt(ints[1]);
} else {
String[] ints = vs[1].toString().split(",");
b[Integer.parseInt(ints[0])-1] = Integer.parseInt(ints[1]);
}
}
v.set(a[0] * b[0] + a[1] * b[1] + a[2] * b[2]);
context.write(key, v);
}
}
public static void run(Map<String, String> path) throws Exception {
String input = path.get("input");
String input1 = path.get("input1");
String input2 = path.get("input2");
String output = path.get("output");
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(input), conf);
final Path outPath = new Path(output);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
conf.set("hadoop.job.user", "hadoop");
// conf.set("mapred.job.tracker", "10.103.240.160:9001");
final Job job = new Job(conf);
FileInputFormat.setInputPaths(job, input);
job.setJarByClass(MartrixMultiply.class);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1);// 设置个数为1
FileOutputFormat.setOutputPath(job, outPath);
job.waitForCompletion(true);
}
}
分享到:





相关推荐
总的来说,这个Hadoop实现大矩阵乘法的案例是理解分布式计算和Hadoop MapReduce的绝佳实例。通过分析和运行提供的代码,学习者不仅可以掌握大矩阵乘法的分布式实现,还能深入理解Hadoop的工作原理和编程技巧,对于...
1、资源内容:基于Hadoop MapReduce的矩阵乘法 2、代码特点:内含运行结果,不会运行可私信,参数化编程、参数可方便更改、代码编程思路清晰、注释明细,都经过测试运行成功,功能ok的情况下才上传的。 3、适用对象...
最近在研究hadoop与mapReduce,网上教程只有个wordcount程序示范,太简单,故写了个相对复杂点的涉及到多个文件之间同时运算的矩阵乘法的代码用于实验与测试,上传供大家学习与参考。 调用方法: 执行:hadoop jar ...
本话题将深入探讨如何使用Hadoop MapReduce实现两个矩阵相乘的算法,这在数据分析、机器学习以及高性能计算中有着重要应用。 首先,理解矩阵相乘的基本原理至关重要。矩阵相乘不是简单的元素对元素相乘,而是对应...
总结,通过Hadoop MapReduce实现MatrixMultiply是将大规模矩阵运算分布式化的过程,它利用了并行计算的能力处理大量数据,有效地解决了单机环境下无法处理的大规模矩阵乘法问题。理解并掌握这一技术对于在大数据背景...
在“MapReduce实现大矩阵乘法”这个主题中,我们将深入探讨如何利用MapReduce模型解决大矩阵乘法的问题,这是一种高效处理大数据存储的有效方法。 **Map阶段** 在Map阶段,输入数据被分割成多个块(通常为HDFS中的...
Hadoop 提供了一种高效的方式来实现矩阵相乘,即使用 MapReduce 编程模型。 在 Hadoop 矩阵相乘中,Map 函数的主要任务是将输入矩阵分解成小块,并将其转换为键值对的形式。 Reduce 函数的主要任务是将这些键值对...
### Hadoop-MapReduce下的PageRank矩阵分块算法解析 #### 概述 PageRank算法作为Web结构挖掘领域的经典算法,在Google搜索引擎中的成功应用已经充分证明了其在评估网页重要性方面的价值。然而,传统的PageRank算法...
java 矩阵乘法的mapreduce程序实现是使用Hadoop的MapReduce框架来实现矩阵乘法的操作。矩阵乘法是一种基本的线性代数操作,用于计算两个矩阵的乘积。在大规模数据处理中,矩阵乘法是非常常见的操作,但是传统的矩阵...
实验中,我们使用 Hadoop 的 MapReduce 框架来实现矩阵相乘,并将结果保存到 HDFS 中。 知识点一:Hadoop 和 MapReduce 介绍 * Hadoop 是一种基于 Java 的大数据处理工具,用于处理大量数据的存储和处理。 * ...
5. **教程内容**:matrix-hadoop-tutorial-master目录下的代码很可能是实现Hadoop上的矩阵运算示例,包括矩阵加法、乘法、转置等基本操作,以及更复杂的算法,如奇异值分解(SVD)或矩阵求逆等。 6. **MapReduce...
通过实例详细解析了如何使用MapReduce实现经典的大数据处理任务,如Word Count、矩阵乘法和PageRank算法。此外,文章还探讨了Hadoop的高级特性,包括容错机制、高可用性和性能调优。 适合人群:熟悉基本编程知识和...
基于Hadoop的大矩阵列行分段乘算法,王伟,肖春娇,针对传统矩阵的乘法很难解决大数据下的矩阵乘问题,在Hadoop平台分析矩阵乘法问题的MapReduce处理过程,提出一种基于Hadoop的大矩阵列行
因此,研究如何在分布式环境下高效地实现高阶矩阵乘法变得尤为重要。 分布式并行算法是指在分布式系统中运行的算法,它们能够在多个处理节点上同时执行,通过通信和协同工作来完成计算任务。分布式并行算法的优势...
本文将深入探讨如何在MapReduce环境下,利用Hadoop 1.2.1版本实现矩阵乘法这一基础数学运算。 矩阵乘法是线性代数中的基本操作,对于大数据处理有着重要的应用,如机器学习、数据挖掘等领域。在传统的单机环境下,...
Hadoop-MapReduce的矩阵-矩阵乘法 该存储库仅适用于MapReduce程序。MV是矩阵向量乘法,而MM是矩阵矩阵乘法。 矩阵矢量乘法:此处矩阵和矢量的维数通过输入文件发送(不作为参数传递)。 MATRIX MATRIX乘法:在这里...
4、基于MapReduce的大矩阵乘法(java语言) 5、MapReduce基础Demo(java语言) 6、Hbase基础Demo(java语言) 7、HDFS基础Demo(java语言) - -------- 不懂运行,下载完可以私聊问,可远程教学 该资源内项目源码是...
这两个文件是关于如何在Hadoop环境下使用Java实现大规模矩阵乘法的示例。 首先,我们要理解矩阵乘法在大数据处理中的重要性。矩阵运算广泛应用于机器学习、数据挖掘和图像处理等众多领域,尤其是当处理的数据量非常...
根据题目要求,我们要实现矩阵相乘。MapReduce是一种分布式计算模型,它将大任务分解为小任务在集群中并行处理。在矩阵相乘的例子中,Map阶段负责将输入的矩阵拆分成行,Reducer阶段则处理这些行并将它们组合成结果...
关键词中提到的矩阵乘法是相似矩阵计算的基础,Hadoop和MapReduce是在该方法中使用的核心技术,而分布式计算则是实现高效计算的体系结构。这些概念和技术在当前大数据和云计算领域中扮演着重要的角色,也是IT专业...