我们在用矩阵处理真实数据的时候,一般都是非常稀疏矩阵,为了节省存储空间,通常只会存储非0的数据。
下面我们来做一个稀疏矩阵:
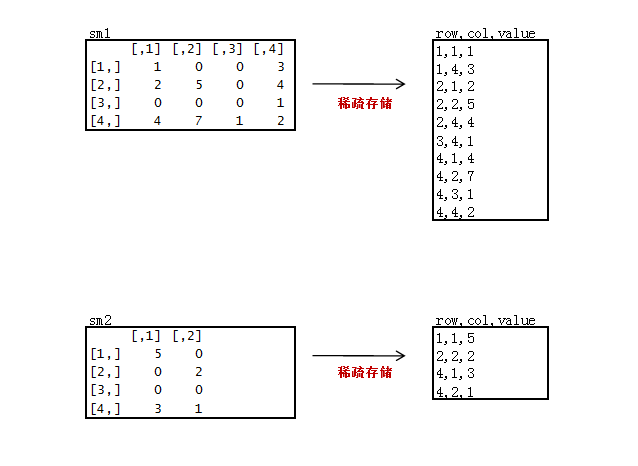
新建2个稀疏矩阵数据文件sm1.csv, sm2.csv
只存储非0的数据,3列存储,第一列“原矩阵行”,第二列“原矩阵列”,第三列“原矩阵值”。
sm1.csv
1,1,1
1,4,3
2,1,2
2,2,5
2,4,4
3,4,1
4,1,4
4,2,7
4,3,1
4,4,2
sm2.csv
1,1,5
2,2,2
4,1,3
4,2,1
代码:
package org.edu.bupt.xiaoye.sparsemartrix;
import java.io.IOException;
import java.net.URI;
import java.util.Map;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class SparseMartrixMultiply {
public static class MyMapper extends Mapper<LongWritable, Text, Text, Text> {
private String flag; // m1 or m2
private int rowNumA = 4; // 矩阵A的行数,因为要在对B的矩阵处理中要用
private int colNumA = 4;// 矩阵A的列数
private int rolNumB = 4;
private int colNumB = 2;// 矩阵B的列数
private static final Text k = new Text();
private static final Text v = new Text();
@Override
protected void setup(Context context) throws IOException,
InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getName();// 判断读的数据集
}
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String[] records = value.toString().split(",");
int x = Integer.parseInt(records[0]);
int y = Integer.parseInt(records[1]);
int num = Integer.parseInt(records[2]);
if (flag.equals("m1")) {
String[] vs = value.toString().split(",");
for (int j = 0; j < colNumB; j++) {
k.set(x + "," + (j + 1));
v.set("A" + ":" + y + "," + num);
context.write(k, v);
}
} else if (flag.equals("m2")) {
for (int j = 0; j < rowNumA; j++) {
k.set((j + 1) + "," + y);
v.set("B:" + x + "," + num);
context.write(k, v);
}
}
}
}
public static class MyReducer extends
Reducer<Text, Text, Text, IntWritable> {
private static IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
/*
* 这里和一般矩阵不同
* 一般矩阵中,当进行第二次reduce方法调用的时候,会对数组a和b的所有元素都重新赋值
* 而在稀疏矩阵中,不会对数组的所有元素重新赋值,从而会发生上次调用reduce方法残留的数组元素值对这一次reduce产生影响。
*/
int[] a = new int[4];
int[] b = new int[4];
for (Text value : values) {
String[] vs = value.toString().split(":");
if (vs[0].equals("A")) {
String[] ints = vs[1].toString().split(",");
a[Integer.parseInt(ints[0]) - 1] = Integer
.parseInt(ints[1]);
} else {
String[] ints = vs[1].toString().split(",");
b[Integer.parseInt(ints[0]) - 1] = Integer
.parseInt(ints[1]);
}
}
// 用矩阵A的行乘矩阵B的列
int sum = 0;
for (int i = 0; i < 4; i++) {
sum += a[i] * b[i];
}
v.set(sum);
context.write(key, v);
}
}
public static void run(Map<String, String> path) throws Exception {
String input = path.get("input");
String output = path.get("output");
Configuration conf = new Configuration();
final FileSystem fileSystem = FileSystem.get(new URI(input), conf);
final Path outPath = new Path(output);
if (fileSystem.exists(outPath)) {
fileSystem.delete(outPath, true);
}
conf.set("hadoop.job.user", "hadoop");
// conf.set("mapred.job.tracker", "10.103.240.160:9001");
final Job job = new Job(conf);
FileInputFormat.setInputPaths(job, input);
job.setMapperClass(MyMapper.class);
job.setReducerClass(MyReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(1);// 设置个数为1
FileOutputFormat.setOutputPath(job, outPath);
job.waitForCompletion(true);
}
}
驱动类:
package org.edu.bupt.xiaoye.sparsemartrix;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
public class MainRun {
public static final String HDFS = "hdfs://10.103.240.160:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) {
martrixMultiply();
}
public static void martrixMultiply() {
Map<String, String> path = new HashMap<String, String>();
path.put("input", HDFS + "/usr/hadoop/SparseMatrix");// HDFS的目录
path.put("output", HDFS + "/usr/hadoop/SparseMatrix/output");
try {
SparseMartrixMultiply.run(path);
} catch (Exception e) {
e.printStackTrace();
}
System.exit(0);
}
}这里注意需要注意的地方:
在reducer中定义数组a和b的时候,不要定义成MyMapper类成员。我就是因为这里定义成了成员变量导致出了错误调了好久。
/*
* 这里和一般矩阵不同
* 一般矩阵中,当进行第二次reduce方法调用的时候,会对数组a和b的所有元素都重新赋值
* 而在稀疏矩阵中,不会对数组的所有元素重新赋值,从而会发生上次调用reduce方法残留的数组元素值对这一次reduce产生影响。
*/
分享到:





相关推荐
因此,大数据计算引入了新的数据表示和计算方式,如分布式计算框架(如Hadoop MapReduce)、列式存储、稀疏矩阵等,这些技术可以高效地处理大规模数据。 标签中的“数组”是大数据处理中的基本数据结构。数组是一种...
这篇文章由来自复旦大学计算机科学学院的Qiuhong Li、Ke Dai、Wei Wang和Peng Wang撰写,提出了一个新的框架——LI-MR(Local Iteration MapReduce),用以改善可以由重复的矩阵-向量乘法描述的一类图操作符。...
5.找到两个巨大的稀疏矩阵相乘的结果矩阵 数据中的每一行都具有以下形式: A,0、172、5 在此,A是该行所属的矩阵。 0是行号。 172是列数 5是A [0] [172]处的值 采用工作链方法。 第一项工作是乘法,第二项工作...
内容概要:本文详细介绍了基于MATLAB GUI界面和卷积神经网络(CNN)的模糊车牌识别系统。该系统旨在解决现实中车牌因模糊不清导致识别困难的问题。文中阐述了整个流程的关键步骤,包括图像的模糊还原、灰度化、阈值化、边缘检测、孔洞填充、形态学操作、滤波操作、车牌定位、字符分割以及最终的字符识别。通过使用维纳滤波或最小二乘法约束滤波进行模糊还原,再利用CNN的强大特征提取能力完成字符分类。此外,还特别强调了MATLAB GUI界面的设计,使得用户能直观便捷地操作整个系统。 适合人群:对图像处理和深度学习感兴趣的科研人员、高校学生及从事相关领域的工程师。 使用场景及目标:适用于交通管理、智能停车场等领域,用于提升车牌识别的准确性和效率,特别是在面对模糊车牌时的表现。 其他说明:文中提供了部分关键代码片段作为参考,并对实验结果进行了详细的分析,展示了系统在不同环境下的表现情况及其潜在的应用前景。
嵌入式八股文面试题库资料知识宝典-计算机专业试题.zip
嵌入式八股文面试题库资料知识宝典-C and C++ normal interview_3.zip
内容概要:本文深入探讨了一款额定功率为4kW的开关磁阻电机,详细介绍了其性能参数如额定功率、转速、效率、输出转矩和脉动率等。同时,文章还展示了利用RMxprt、Maxwell 2D和3D模型对该电机进行仿真的方法和技术,通过外电路分析进一步研究其电气性能和动态响应特性。最后,文章提供了基于RMxprt模型的MATLAB仿真代码示例,帮助读者理解电机的工作原理及其性能特点。 适合人群:从事电机设计、工业自动化领域的工程师和技术人员,尤其是对开关磁阻电机感兴趣的科研工作者。 使用场景及目标:适用于希望深入了解开关磁阻电机特性和建模技术的研究人员,在新产品开发或现有产品改进时作为参考资料。 其他说明:文中提供的代码示例仅用于演示目的,实际操作时需根据所用软件的具体情况进行适当修改。
少儿编程scratch项目源代码文件案例素材-剑客冲刺.zip
少儿编程scratch项目源代码文件案例素材-几何冲刺 转瞬即逝.zip
内容概要:本文详细介绍了基于PID控制器的四象限直流电机速度驱动控制系统仿真模型及其永磁直流电机(PMDC)转速控制模型。首先阐述了PID控制器的工作原理,即通过对系统误差的比例、积分和微分运算来调整电机的驱动信号,从而实现转速的精确控制。接着讨论了如何利用PID控制器使有刷PMDC电机在四个象限中精确跟踪参考速度,并展示了仿真模型在应对快速负载扰动时的有效性和稳定性。最后,提供了Simulink仿真模型和详细的Word模型说明文档,帮助读者理解和调整PID控制器参数,以达到最佳控制效果。 适合人群:从事电力电子与电机控制领域的研究人员和技术人员,尤其是对四象限直流电机速度驱动控制系统感兴趣的读者。 使用场景及目标:适用于需要深入了解和掌握四象限直流电机速度驱动控制系统设计与实现的研究人员和技术人员。目标是在实际项目中能够运用PID控制器实现电机转速的精确控制,并提高系统的稳定性和抗干扰能力。 其他说明:文中引用了多篇相关领域的权威文献,确保了理论依据的可靠性和实用性。此外,提供的Simulink模型和Word文档有助于读者更好地理解和实践所介绍的内容。
嵌入式八股文面试题库资料知识宝典-2013年海康威视校园招聘嵌入式开发笔试题.zip
少儿编程scratch项目源代码文件案例素材-驾驶通关.zip
小区开放对周边道路通行能力影响的研究.pdf
内容概要:本文探讨了冷链物流车辆路径优化问题,特别是如何通过NSGA-2遗传算法和软硬时间窗策略来实现高效、环保和高客户满意度的路径规划。文中介绍了冷链物流的特点及其重要性,提出了软时间窗概念,允许一定的配送时间弹性,同时考虑碳排放成本,以达到绿色物流的目的。此外,还讨论了如何将客户满意度作为路径优化的重要评价标准之一。最后,通过一段简化的Python代码展示了遗传算法的应用。 适合人群:从事物流管理、冷链物流运营的专业人士,以及对遗传算法和路径优化感兴趣的科研人员和技术开发者。 使用场景及目标:适用于冷链物流企业,旨在优化配送路线,降低运营成本,减少碳排放,提升客户满意度。目标是帮助企业实现绿色、高效的物流配送系统。 其他说明:文中提供的代码仅为示意,实际应用需根据具体情况调整参数设置和模型构建。
少儿编程scratch项目源代码文件案例素材-恐怖矿井.zip
内容概要:本文详细介绍了基于STM32F030的无刷电机控制方案,重点在于高压FOC(磁场定向控制)技术和滑膜无感FOC的应用。该方案实现了过载、过欠压、堵转等多种保护机制,并提供了完整的源码、原理图和PCB设计。文中展示了关键代码片段,如滑膜观测器和电流环处理,以及保护机制的具体实现方法。此外,还提到了方案的移植要点和实际测试效果,确保系统的稳定性和高效性。 适合人群:嵌入式系统开发者、电机控制系统工程师、硬件工程师。 使用场景及目标:适用于需要高性能无刷电机控制的应用场景,如工业自动化设备、无人机、电动工具等。目标是提供一种成熟的、经过验证的无刷电机控制方案,帮助开发者快速实现并优化电机控制性能。 其他说明:提供的资料包括详细的原理图、PCB设计文件、源码及测试视频,方便开发者进行学习和应用。
基于有限体积法Godunov格式的管道泄漏检测模型研究.pdf
嵌入式八股文面试题库资料知识宝典-CC++笔试题-深圳有为(2019.2.28)1.zip
少儿编程scratch项目源代码文件案例素材-几何冲刺 V1.5.zip
Android系统开发_Linux内核配置_USB-HID设备模拟_通过root权限将Android设备转换为全功能USB键盘的项目实现_该项目需要内核支持configFS文件系统