- 浏览: 305620 次
- 性别:

- 来自: 北京
-

ÊñáÁ´ÝÂàÜÁ±ª
- 全部博客 (227)
- javascript (47)
- java (70)
- jquery (7)
- 正则 (24)
- css (11)
- 设计模式 (14)
- 其他 (25)
- php (4)
- freemarker (4)
- 新浪微博接口 (1)
- phpcms (2)
- java,tomcat (1)
- Fckeditor (2)
- mysql (2)
- 数据库表设计 (1)
- uploadify (1)
- jeecms (3)
- js (1)
- jboss (3)
- joomla (1)
- struts2 (2)
- 空间 (1)
社区版块
- 我的资讯 ( 0)
- 我的论坛 ( 0)
- 我的问答 ( 2)
存档分类
- 2015-08 ( 1)
- 2015-01 ( 1)
- 2014-04 ( 2)
- 更多存档...
最新评论
-
全站唯一是我么:
请问下该功能的jdk版本是1.4的么,还是以上的?
JavaÂÆûÁé∞ÁªôÂõæÁâáÊ∑ªÂäÝÊ∞¥Âç∞ -
JanneÔºö
ËØ∑ÈóÆ,‰ΩÝËߣÂÜ≥ËøôÈóÆÈ¢òÊ≤°?ÊòØÊÄé‰πàÂõû‰∫ã?Êà뉪䧩‰πüÈÅáÂà∞‰∫Ü,Ê≤°ËߣÂÜ≥
myeclipse6.5中使用jax-ws启动tomcat报错问题 -
xuedongÔºö
studypi ÂÜôÈÅì‰ΩÝÊòØÊÄé‰πàÂíåÊñ∞ʵ™ÁöÑÊäÄÊúØËÅîÁ≥ªÁöÑÔºüËÉΩÂëäËØâ‰∏ĉ∏ãÊàëÂêó ...
Êñ∞ʵ™ÂæÆÂçöÁ¨¨‰∏âÊñπÊé•Âè£Ë∞ÉÁî®Â≠¶‰πÝ -
studypiÔºö
‰ΩÝÊòØÊÄé‰πàÂíåÊñ∞ʵ™ÁöÑÊäÄÊúØËÅîÁ≥ªÁöÑÔºüËÉΩÂëäËØâ‰∏ĉ∏ãÊàëÂêóÔºåË∞¢Ë∞¢
Êñ∞ʵ™ÂæÆÂçöÁ¨¨‰∏âÊñπÊé•Âè£Ë∞ÉÁî®Â≠¶‰πÝ -
dove19900520Ôºö
有用,呵呵
IE,Firefox都不放弃(兼容性问题总结)
正则基础之——贪婪与非贪婪模式 .
- 博客分类:
- 正则
1¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配,而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。
属于贪婪模式的量词,也叫做匹配优先量词,包括:
“{m,n}”、“{m,}”、“?”、“*”和“+”。
Âú®‰∏ĉ∫õ‰ΩøÁî®NFAºïÊìéÁöÑËØ≠ˮĉ∏≠ÔºåÂú®ÂåπÈÖ牺òÂÖàÈáèËØçÂêéÂä݉∏ä‚Äú?‚ÄùÔºåÂç≥ÂèòÊàê±û‰∫éÈùûË¥™Â©™Ê®°ÂºèÁöÑÈáèËØçÔºå‰πüÂè´ÂÅöÂøΩÁºòÂÖàÈáèËØçÔºåÂåÖÊã¨Ôºö
“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
从正则语法的角度来讲,被匹配优先量词修饰的子表达式使用的就是贪婪模式,如“(Expression)+”;被忽略优先量词修饰的子表达式使用的就是非贪婪模式,如“(Expression)+?”。
ÂØπ‰∫éË¥™Â©™Ê®°ÂºèÔºåÂêÑÁßçÊñáÊ°£ÁöÑÂè´Ê≥ïÂü∫Êú¨‰∏ÄËá¥Ôºå‰ΩÜÊòØÂØπ‰∫éÈùûË¥™Â©™Ê®°ÂºèÔºåÊúâÁöÑÂè´ÊáíÊÉ∞Ê®°ÂºèÊàñÊÉ∞ÊÄßÊ®°ÂºèÔºåÊúâÁöÑÂè´Âãâº∫Ê®°ÂºèÔºåÂÖ∂ÂÆûÂè´‰ªÄ‰πàÊóÝÊâÄË∞ìÔºåÂè™Ë¶ÅÊéåÊè°ÂéüÁêÜÂíåÁî®Ê≥ïÔºåËÉΩ§üËøêÁî®Ëá™Â¶Ç‰πüÂ∞±Êò؉∫Ü„Älj∏™‰∫∫‰πÝÊÉ؉ΩøÁî®Ë¥™Â©™‰∏éÈùûË¥™Â©™ÁöÑÂè´Ê≥ïÔºåÊâĉª•Êñá‰∏≠ÈÉΩ‰ºö‰ΩøÁî®ËøôÁßçÂè´Ê≥ïËøõ˰剪ãÁªç„ÄÇ
2¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý Ë¥™Â©™‰∏éÈùûË¥™Â©™Ê®°ÂºèÂåπÈÖçÂéüÁêÜ
对于贪婪与非贪婪模式,可以从应用和原理两个角度进行理解,但如果想真正掌握,还是要从匹配原理来理解的。
先从应用的角度,回答一下“什么是贪婪与非贪婪模式?”
2.1¬Ý¬Ý¬Ý¬Ý ‰ªéÂ∫îÁî®ËßíÂ∫¶ÂàÜÊûêË¥™Â©™‰∏éÈùûË¥™Â©™Ê®°Âºè
2.1.1¬Ý ‰ªÄ‰πàÊòØË¥™Â©™‰∏éÈùûË¥™Â©™Ê®°Âºè
先看一个例子
举例:
源字符串:aa<div>test1</div>bb<div>test2</div>cc
正则表达式一:<div>.*</div>
匹配结果一:<div>test1</div>bb<div>test2</div>
正则表达式二:<div>.*?</div>
匹配结果二:<div>test1</div>(这里指的是一次匹配结果,所以没包括<div>test2</div>)
ÊÝπÊçƉ∏äÈù¢ÁöщæãÂ≠êԺ剪éÂåπÈÖçË°å‰∏∫‰∏äÂàÜÊûê‰∏ĉ∏ãԺ剪ÄÊòØË¥™Â©™‰∏éÈùûË¥™Â©™Ê®°Âºè„ÄÇ
Ê≠£ÂàôË°®Ëææºè‰∏ÄÈááÁî®ÁöÑÊòØË¥™Â©™Ê®°ÂºèÔºåÂú®ÂåπÈÖçÂà∞Á¨¨‰∏ĉ∏™‚Äú</div>‚ÄùÊó∂Â∑≤ÁªèÂè؉ª•‰ΩøÊ雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäüÔºå‰ΩÜÊòØÁ∫éÈááÁî®ÁöÑÊòØË¥™Â©™Ê®°ÂºèÔºåÊâĉª•‰ªçÁÑ∂˶ÅÂêëÂè≥Â∞ùËØïÂåπÈÖçÔºåÊü•ÁúãÊòØÂê¶ËøòÊúâÊõ¥ÈïøÁöÑÂè؉ª•ÊàêÂäüÂåπÈÖçÁöÑÂ≠ê‰∏≤ÔºåÂåπÈÖçÂà∞Á¨¨‰∫å‰∏™‚Äú</div>‚ÄùÂêéÔºåÂêëÂè≥ÂÜçÊ≤°ÊúâÂè؉ª•ÊàêÂäüÂåπÈÖçÁöÑÂ≠ê‰∏≤ÔºåÂåπÈÖçÁªìÊùüÔºåÂåπÈÖçÁªìÊûú‰∏∫‚Äú<div>test1</div>bb<div>test2</div>‚Äù„ÄÇÂΩìÁÑ∂ÔºåÂÆûÈôÖÁöÑÂåπÈÖçËøáÁ®ãÂπ∂‰∏çÊòØËøôÊÝ∑ÁöÑÔºåÂêéÈù¢ÁöÑÂåπÈÖçÂéüÁê܉ºöËضÁªÜ‰ªãÁªç„ÄÇ
‰ªÖ‰ªéÂ∫îÁî®ËßíÂ∫¶ÂàÜÊûêÔºåÂè؉ª•ËøôÊÝ∑ËƧ‰∏∫ÔºåË¥™Â©™Ê®°ÂºèÔºåÂ∞±ÊòØÂú®Ê雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäüÁöÑÂâçÊèê‰∏ãÔºåÂ∞ΩÂèØËÉΩ§öÁöÑÂåπÈÖçÔºå‰πüÂ∞±ÊòØÊâÄË∞ìÁöÑ‚ÄúË¥™Â©™‚ÄùÔºåÈÄö‰øóÁÇπËÆ≤ÔºåÂ∞±ÊòØÁúãÂà∞ÊÉ≥˶ÅÁöÑÔºåÊúâ§öÂ∞ëÂ∞±Êç°Â§öÂ∞ëÔºåÈô§ÈùûÂÜç‰πüÊ≤°ÊúâÊÉ≥˶ÅÁöщ∫Ü„ÄÇ
正则表达式二采用的是非贪婪模式,在匹配到第一个“</div>”时使整个表达式匹配成功,由于采用的是非贪婪模式,所以结束匹配,不再向右尝试,匹配结果为“<div>test1</div>”。
‰ªÖ‰ªéÂ∫îÁî®ËßíÂ∫¶ÂàÜÊûêÔºåÂè؉ª•ËøôÊÝ∑ËƧ‰∏∫ÔºåÈùûË¥™Â©™Ê®°ÂºèÔºåÂ∞±ÊòØÂú®Ê雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäüÁöÑÂâçÊèê‰∏ãÔºåÂ∞ΩÂèØËÉΩÂ∞ëÁöÑÂåπÈÖçÔºå‰πüÂ∞±ÊòØÊâÄË∞ìÁöÑ‚ÄúÈùûË¥™Â©™‚ÄùÔºåÈÄö‰øóÁÇπËÆ≤ÔºåÂ∞±ÊòØÊâæÂà∞‰∏ĉ∏™ÊÉ≥˶ÅÁöÑÊç°Ëµ∑Êù•Â∞±Ë°å‰∫ÜÔºåËá≥‰∫éËøòÊúâÊ≤°ÊúâÊ≤°Êç°ÁöÑÂ∞±‰∏çÁÆ°‰∫Ü„ÄÇ
2.1.2¬Ý ÂÖ≥‰∫éÂâçÊèêÊù°‰ª∂ÁöÑËØ¥Êòé
在上面从应用角度分析贪婪与非贪婪模式时,一直提到的一个前提条件就是“整个表达式匹配成功”,为什么要强调这个前提,我们看下下面的例子。
正则表达式三:<div>.*</div>bb
匹配结果三:<div>test1</div>bb
‰øÆÈ•∞‚Äú.‚ÄùÁöщªçÁÑ∂ÊòØÂåπÈÖ牺òÂÖàÈáèËØç‚Äú*‚ÄùÔºåÊâĉª•ËøôÈáåËøòÊòØË¥™Â©™Ê®°ÂºèÔºåÂâçÈù¢ÁöÑ‚Äú<div>.*</div>‚Äù‰ªçÁÑ∂Âè؉ª•ÂåπÈÖçÂà∞‚Äú<div>test1</div>bb<div>test2</div>‚ÄùÔºå‰ΩÜÊòØÁ∫éÂêéÈù¢ÁöÑ‚Äúbb‚ÄùÊóÝÊ≥ïÂåπÈÖçÊàêÂäüÔºåËøôÊó∂‚Äú<div>.*</div>‚ÄùÂøÖÈ°ªËÆ©Âá∫Â∑≤ÂåπÈÖçÁöÑ‚Äúbb<div>test2</div>‚ÄùԺ剪•‰ΩøÊ雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäü„ÄÇËøôÊó∂Ê雷∏™Ë°®ËææºèÂåπÈÖçÁöÑÁªìÊûú‰∏∫‚Äú<div>test1</div>bb‚ÄùÔºå‚Äú<div>.*</div>‚ÄùÂåπÈÖçÁöÑÂÜÖÂÆπ‰∏∫‚Äú<div>test1</div>‚Äù„ÄÇÂè؉ª•ÁúãÂà∞ÔºåÂú®‚ÄúÊ雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäü‚ÄùÁöÑÂâçÊèê‰∏ãÔºåË¥™Â©™Ê®°ÂºèÊâçÁúüÊ≠£ÁöÑÂΩ±ÂìçÁùÄÂ≠êË°®ËææºèÁöÑÂåπÈÖçË°å‰∏∫Ôºå¶ÇÊûúÊ雷∏™Ë°®ËææºèÂåπÈÖ秱˥•ÔºåË¥™Â©™Ê®°ÂºèÂ虉ºöÂΩ±ÂìçÂåπÈÖçËøáÁ®ãÔºåÂØπÂåπÈÖçÁªìÊûúÁöÑÂΩ±ÂìçÊó݉ªéË∞à˵∑„ÄÇ
ÈùûË¥™Â©™Ê®°Âºè‰πüÂ≠òÂú®ÂêåÊÝ∑ÁöÑÈóÆÈ¢òÔºåÊù•Áúã‰∏ãÈù¢ÁöщæãÂ≠ê„ÄÇ
正则表达式四:<div>.*?</div>cc
匹配结果四:<div>test1</div>bb<div>test2</div>cc
ËøôÈáåÈááÁî®ÁöÑÊòØÈùûË¥™Â©™Ê®°ÂºèÔºåÂâçÈù¢ÁöÑ‚Äú<div>.*?</div>‚Äù‰ªçÁÑ∂ÊòØÂåπÈÖçÂà∞‚Äú<div>test1</div>‚Äù‰∏∫Ê≠¢ÔºåÊ≠§Êó∂ÂêéÈù¢ÁöÑ‚Äúcc‚ÄùÊóÝÊ≥ïÂåπÈÖçÊàêÂäüÔºå˶ÅʱǂÄú<div>.*?</div>‚ÄùÂøÖÈ°ªÁªßÁª≠ÂêëÂè≥Â∞ùËØïÂåπÈÖçÔºåÁõ¥Âà∞ÂåπÈÖçÂÜÖÂÆπ‰∏∫‚Äú<div>test1</div>bb<div>test2</div>‚ÄùÊó∂ÔºåÂêéÈù¢ÁöÑ‚Äúcc‚ÄùÊâçËÉΩÂåπÈÖçÊàêÂäüÔºåÊ雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäüÔºåÂåπÈÖçÁöÑÂÜÖÂÆπ‰∏∫‚Äú<div>test1</div>bb<div>test2</div>cc‚ÄùÔºåÂÖ∂‰∏≠‚Äú<div>.*?</div>‚ÄùÂåπÈÖçÁöÑÂÜÖÂÆπ‰∏∫‚Äú<div>test1</div>bb<div>test2</div>‚Äù„ÄÇÂè؉ª•ÁúãÂà∞ÔºåÂú®‚ÄúÊ雷∏™Ë°®ËææºèÂåπÈÖçÊàêÂäü‚ÄùÁöÑÂâçÊèê‰∏ãÔºåÈùûË¥™Â©™Ê®°ÂºèÊâçÁúüÊ≠£ÁöÑÂΩ±ÂìçÁùÄÂ≠êË°®ËææºèÁöÑÂåπÈÖçË°å‰∏∫Ôºå¶ÇÊûúÊ雷∏™Ë°®ËææºèÂåπÈÖ秱˥•ÔºåÈùûË¥™Â©™Ê®°ÂºèÊóÝÊ≥ïÂΩ±ÂìçÂ≠êË°®ËææºèÁöÑÂåπÈÖçË°å‰∏∫„ÄÇ
2.1.3¬Ý Ë¥™Â©™ËøòÊòØÈùûË¥™Â©™‚Äî‚ÄîÂ∫îÁî®ÁöÑÊäâÊã©
ÈÄöËøáÂ∫îÁî®ËßíÂ∫¶ÁöÑÂàÜÊûêÔºåÂ∑≤Âü∫Êú¨‰∫ÜËߣ‰∫ÜË¥™Â©™‰∏éÈùûË¥™Â©™Ê®°ÂºèÁöÑÁâπÊÄßÔºåÈÇ£‰πàÂú®ÂÆûÈôÖÂ∫îÁ∏≠ÔºåÁ©∂Á´üÊòØÈÄâÊã©Ë¥™Â©™Ê®°ÂºèÔºåËøòÊòØÈùûË¥™Â©™Ê®°ÂºèÂë¢ÔºåËøô˶ÅÊÝπÊçÆÈúÄʱÇÊù•Á°ÆÂÆö„ÄÇ
ÂØπ‰∫é‰∏ĉ∫õÁÆÄÂçïÁöÑÈúÄʱÇÔºåÊØî¶ÇÊ∫êÂ≠óÁ¨¶‰∏∫‚Äúaa<div>test1</div>bb‚ÄùÔºåÈÇ£‰πàÂèñÂæódivÊÝáÁ≠æÔºå‰ΩøÁî®Ë¥™Â©™‰∏éÈùûË¥™Â©™Ê®°ÂºèÈÉΩÂè؉ª•ÂèñÂæóÊÉ≥˶ÅÁöÑÁªìÊûúÔºå‰ΩøÁî®Â왉∏ÄÁßçÊàñËÆ∏ÂÖ≥Á≥ª‰∏ç§߄ÄÇ
‰ΩÜÊòØÂ∞±2.1.1‰∏≠ÁöщæãÂ≠êÊù•ËØ¥ÔºåÂÆûÈôÖÂ∫îÁ∏≠Ôºå‰∏ÄËਉ∏Äʨ°Âè™ÈúÄ˶ÅÂèñÂæó‰∏ĉ∏™ÈÖçÂØπÂá∫Áé∞ÁöÑdivÊÝáÁ≠æÔºå‰πüÂ∞±ÊòØÈùûË¥™Â©™Ê®°ÂºèÂåπÈÖçÂà∞ÁöÑÂÜÖÂÆπÔºåË¥™Â©™Ê®°ÂºèÊâÄÂåπÈÖçÂà∞ÁöÑÂÜÖÂÆπÈÄöÂ∏∏Âπ∂‰∏çÊòØÊà뉪¨ÊâÄÈúÄ˶ÅÁöÑ„ÄÇ
那为什么还要有贪婪模式的存在呢,从应用角度很难给出满意的解答了,这就需要从匹配原理的角度去分析贪婪与非贪婪模式。
2.2¬Ý¬Ý¬Ý¬Ý ‰ªéÂåπÈÖçÂéüÁêÜËßíÂ∫¶ÂàÜÊûêË¥™Â©™‰∏éÈùûË¥™Â©™Ê®°Âºè
如果想真正了解什么是贪婪模式,什么是非贪婪模式,分别在什么情况下使用,各自的效率如何,那就不能仅仅从应用角度分析,而要充分了解贪婪与非贪婪模式的匹配原理。
2.2.1¬Ý ‰ªéÂü∫Êú¨ÂåπÈÖçÂéüÁêÜË∞à˵∑
NFA引擎基本匹配原理参考:正则基础之——NFA引擎匹配原理。
这里主要针对贪婪与非贪婪模式涉及到的匹配原理进行介绍。先看一下贪婪模式简单的匹配过程。
源字符串:"Regex"
正则表达式:".*"
¬Ý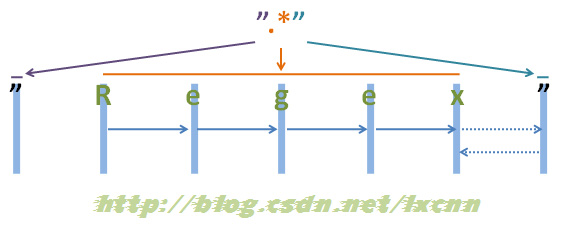
¬Ý
Âõæ2-1
注:为了能够看清晰匹配过程,上面的空隙留得较大,实际源字符串为“”Regex””,下同。
来看一下匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*”。
“.*”取得控制权后,由于“*”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到结尾的“””,匹配成功,由于此时已匹配到字符串的结尾,所以“.*”结束匹配,将控制权交给正则表达式最后的“"”。
“"”取得控制权后,由于已经在字符串结束位置,匹配失败,向前查找可供回溯的状态,控制权交给“.*”,由“.*”让出一个字符,也就是字符串结尾处的“””,再把控制权交给正则表达式最后的“"”,由“"”匹配字符串结尾处的“"”,匹配成功。
此时整个正则表达式匹配成功,其中“.*”匹配的内容为“Regex”,匹配过程中进行了一次回溯。
接下来看一下非贪婪模式简单的匹配过程。
源字符串:"Regex"
正则表达式:".*?"
¬Ý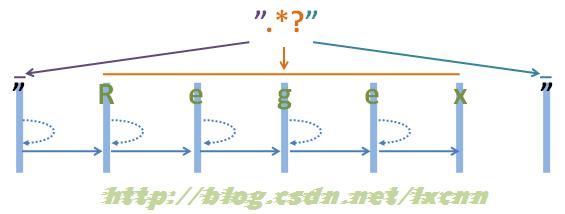
¬Ý
Âõæ2-2
看一下非贪婪模式的匹配过程。首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“.*?”。
“.*?”取得控制权后,由于“*?”是忽略优先量词,在可匹配可不匹配的情况下,优先尝试不匹配,由于“*”等价于“{0,}”,所以在忽略优先的情况下,可以不匹配任何内容。从位置1处尝试忽略匹配,也就是不匹配任何内容,将控制权交给正则表达式最后的“””。
“"”取得控制权后,从位置1处尝试匹配,由“"”匹配位置1处的“R”,匹配失败,向前查找可供回溯的状态,控制权交给“.*?”,由“.*?”吃进一个字符,匹配位置1处的“R”,再把控制权交给正则表达式最后的“"”。
“"”取得控制权后,从位置2处尝试匹配,由“"”匹配位置1处的“e”,匹配失败,向前查找可供回溯的状态,重复以上过程,直到由“.*?”匹配到“x”为止,再把控制权交给正则表达式最后的“"”。
“"”取得控制权后,从位置6处尝试匹配,由“"”匹配字符串最后的“"”,匹配成功。
此时整个正则表达式匹配成功,其中“.*?”匹配的内容为“Regex”,匹配过程中进行了五次回溯。
2.2.2¬Ý Ë¥™Â©™ËøòÊòØÈùûË¥™Â©™‚Äî‚ÄîÂåπÈÖçÊïàÁéáÁöÑÊäâÊã©
通过匹配原理的分析,可以看到,在匹配成功的情况下,贪婪模式进行了更少的回溯,而回溯的过程,需要进行控制权的交接,让出已匹配内容或匹配未匹配内容,并重新尝试匹配,在很大程度上降低匹配效率,所以贪婪模式与非贪婪模式相比,存在匹配效率上的优势。
‰ΩÜ2.2.1‰∏≠ÁöщæãÂ≠êԺ剪։ªÖÊò؉∏ĉ∏™ÁÆÄÂçïÁöÑÂ∫îÁî®ÔºåËتËÄÖÁúãÂà∞ËøôÈáåÊó∂ÔºåÊòØÂ궉ºöÂ≠òÂú®ËøôÊÝ∑ÁöÑÁñëÈóÆÔºåË¥™Â©™Ê®°ÂºèÂ∞±‰∏ÄÂÆöÊØîÈùûË¥™Â©™Ê®°ÂºèÂåπÈÖçÊïàÁéáÈ´òÂêóÔºüÁ≠îÊ°àÊòØÂê¶ÂÆöÁöÑ„ÄÇ
举例:
需求:取得两个“"”中的子串,其中不能再包含“"”。
正则表达式一:".*"
正则表达式二:".*?"
情况一:当贪婪模式匹配到更多不需要的内容时,可能存在比非贪婪模式更多的回溯。比如源字符串为“The word "Regex" means regular expression.”。
ÊÉÖÂܵ‰∫åÔºöË¥™Â©™Ê®°ÂºèÊóÝÊ≥ïʪ°Ë∂≥ÈúÄʱDŽÄÇÊØî¶ÇÊ∫êÂ≠óÁ¨¶‰∏≤‰∏∫‚ÄúThe phrase "regular expression" is called "Regex" for short.‚Äù„ÄÇ
对于情况一,正则表达式一采用的贪婪模式,“.*”会一直匹配到字符串结束位置,控制权交给最后的“””,匹配不成功后,再进行回溯,由于多匹配的内容“means regular expression.”远远超过需匹配内容本身,所以采用正则表达式一时,匹配效率会比使用正则表达式二的非贪婪模式低。
对于情况二,正则表达式一匹配到的是“"regular expression" is called "Regex"”,连需求都不满足,自然也谈不上什么匹配效率的高低了。
‰ª•‰∏ä‰∏§ÁßçÊÉÖÂܵÊòØÊôÆÈÅçÂ≠òÂú®ÁöÑÔºåÈÇ£‰πàÊò؉∏çÊò؉∏∫‰∫Üʪ°Ë∂≥ÈúÄʱÇÔºåÂèàÂֺȰæÊïàÁéáÔºåÂ∞±Âè™ËÉΩ‰ΩøÁî®ÈùûË¥™Â©™Ê®°Âºè‰∫ÜÂë¢ÔºüÂΩìÁÑ∂‰∏çÊòØÔºåÊÝπÊçÆÂÆûÈôÖÊÉÖÂܵԺåÂèòÊõ¥ÂåπÈÖ牺òÂÖàÈáèËØç‰øÆÈ•∞ÁöÑÂ≠êË°®ËææºèÔºå‰∏ç‰ΩÜÂè؉ª•Êª°Ë∂≥ÈúÄʱÇÔºåËøòÂè؉ª•ÊèêÈ´òÂåπÈÖçÊïàÁéá„ÄÇ
源字符串:"Regex"
给出正则表达式三:"[^"]*"
看一下正则表达式三的匹配过程。
¬Ý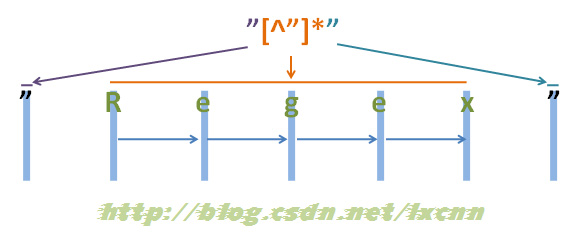
¬Ý
Âõæ2-3
首先由第一个“"”取得控制权,匹配位置0位的“"”,匹配成功,控制权交给“[^"]*”。
“[^"]*”取得控制权后,由于“*”是匹配优先量词,在可匹配可不匹配的情况下,优先尝试匹配。从位置1处的“R”开始尝试匹配,匹配成功,继续向右匹配,匹配位置2处的“e”,匹配成功,继续向右匹配,直到匹配到“x”,匹配成功,再匹配结尾的“””时,匹配失败,将控制权交给正则表达式最后的“"”。
“””取得控制权后,匹配字符串结尾处的“””,匹配成功。
此时整个正则表达式匹配成功,其中“[^"]*”匹配的内容为“Regex”,匹配过程中没有进行回溯。
Â∞ÜÈáèËØç‰øÆÈ•∞ÁöÑÂ≠êË°®ËææºèÁî±ËåÉÂõ¥ËæɧßÁöÑ‚Äú.‚ÄùÔºåÊç¢Êàê‰∫ÜÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑ‚Äú[^"]‚ÄùÔºå‰ΩøÁî®ÁöщªçÊòØË¥™Â©™Ê®°ÂºèÔºåÂæàÂÆåÁæéÁöÑËߣÂÜ≥‰∫ÜÈúÄʱÇÂíåÊïàÁéáÈóÆÈ¢ò„ÄÇÂΩìÁÑ∂ÔºåÁ∫éËøô‰∏ÄÂåπÈÖçËøáÁ®ãÊ≤°ÊúâËøõË°åÂõûÊ∫ØÔºåÊâĉª•‰πü‰∏çÈúÄ˶ÅËÆ∞ÂΩïÂõûÊ∫ØÁä∂ÊÄÅÔºåËøôÊÝ∑Â∞±Âè؉ª•‰ΩøÁî®Âõ∫ÂåñÂàÜÁªÑÔºåÂØπÊ≠£ÂàôÂÅöËøõ‰∏ÄÊ≠•ÁöщºòÂåñ„ÄÇ
给出正则表达式四:"(?>[^"]*)"
Âõ∫ÂåñÂàÜÁªÑÂπ∂‰∏çÊòØÊâÄÊúâËØ≠Ë®ÄÈÉΩÊîØÊåÅÁöÑÔºå¶Ç.NETÊîØÊåÅÔºåËÄåJavaÂ∞±‰∏çÊîØÊåÅÔºå‰ΩÜÊòØÂú®Java‰∏≠Âç¥Âè؉ª•‰ΩøÁî®Êõ¥ÁÆÄÂçïÁöÑÂçÝÊú≺òÂÖàÈáèËØçÊù•‰ª£ÊõøÔºö"[^"]*+"„ÄÇ
3¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý Ë¥™Â©™ËøòÊòØÈùûË¥™Â©™Ê®°Âºè‚Äî‚ÄîÂÜçË∞àÂåπÈÖçÊïàÁéá
一般来说,贪婪与非贪婪模式,如果量词修饰的子表达式相同,比如“.*”和“.*?”,它们的应用场景通常是不同的,所以效率上一般不具有可比性。
而对于改变量词修饰的子表达式,以满足需求时,比如把“.*”改为“[^"]*”,由于修饰的子表达式已不同,也不具有直接的可对比性。但是在相同的子表达式,又都可以满足需求的情况下,比如“[^"]*”和“[^"]*?”,贪婪模式的匹配效率通常要高些。
同时还有一个事实就是,非贪婪模式可以实现的,通过优化量词修饰的子表达式的贪婪模式都可以实现,而贪婪模式可以实现的一些优化效果,却未必是非贪婪模式可以实现的。
贪婪模式还有一点优势,就是在匹配失败时,贪婪模式可以更快速的报告失败,从而提升匹配效率。下面将全面考察贪婪与非贪婪模式的匹配效率。
3.1¬Ý¬Ý¬Ý¬Ý ÊïàÁéáÊèêÂçá‚Äî‚ÄîʺîËøõËøáÁ®ã
在了解了贪婪与非贪婪模式的匹配基本原理之后,我们再来重新看一下正则效率提升的演进过程。
需求:取得两个“"”中的子串,其中不能再包含“"”。
源字符串:The phrase "regular expression" is called "Regex" for short.
正则表达式一:".*"
正则表达式一匹配的内容为“"regular expression" is called "Regex"”,不符合要求。
提出正则表达式二:".*?"
首先“"”取得控制权,由位置0位开始尝试匹配,直到位置11处匹配成功,控制权交给“.*?”,匹配过程同2.2.1中非贪婪模式的匹配过程。“.*?”匹配的内容为“Regex”,匹配过程中进行了四次回溯。
如何消除回溯带来的匹配效率的损失,就是使用更小范围的子表达式,采用贪婪模式,提出正则表达式三:"[^"]*"
首先“"”取得控制权,由位置0位开始尝试匹配,直到位置11处匹配成功,控制权交给“[^"]*”,匹配过程同2.2.2节中非贪婪模式的匹配过程。“[^"]*”匹配的内容为“Regex”,匹配过程中没有进行回溯。
3.2¬Ý¬Ý¬Ý¬Ý ÊïàÁéáÊèêÂçá‚Äî‚ÄîÊõ¥Âø´ÁöÑÊä•Âë䧱˥•
以上讨论的是匹配成功的演进过程,而对于一个正则表达式,在匹配失败的情况下,如果能够以最快的速度报告匹配失败,也会提升匹配效率,这或许是我们设计正则过程中最容易忽略的。而在源字符串数据量非常大,或正则表达式比较复杂的情况下,是否能够快速报告匹配失败,将对匹配效率产生直接的影响。
下面将构建匹配失败的正则表达式,对匹配过程进行分析。
以下匹配过程分析中,源字符串统一为:The phrase "regular expression" is called "Regex" for short.
3.2.1¬Ý ÈùûË¥™Â©™Ê®°ÂºèÂåπÈÖ秱˥•ËøáÁ®ãÂàÜÊûê
¬Ý
¬Ý
Âõæ3-1
构建匹配失败的非贪婪模式的正则表达式:".*?"@
由于最后的“@”的存在,这个正则表达式最后一定是匹配失败的,那么看一下匹配过程。
ȶñÂÖàÁÄú"‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÔºåÁΩçÁΩÆ0§ÑºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖ秱˥•ÔºåÁõ¥Âà∞Âõæ‰∏≠ÊÝáÁ§∫ÁöÑA§ÑÂåπÈÖçÊàêÂäüÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú.*?‚Äù„ÄÇ
‚Äú.*?‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÂêéÔºåÁî±AÂêéÈù¢ÁöщΩçÁΩƺÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÁ∫éÊòØÈùûË¥™Â©™Ê®°ÂºèÔºåȶñÂÖàÂøΩÁï•ÂåπÈÖçÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚ÄùÔºåÂêåÊó∂ËÆ∞ÂΩï‰∏ĉ∏ãÂõûÊ∫ØÁä∂ÊÄÅ„ÄÇ‚Äú"‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÂêéÔºåÁî±AÂêéÈù¢ÁöщΩçÁΩƺÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖçÂ≠óÁ¨¶‚Äúr‚Äù§±Ë¥•ÔºåÊü•ÊâæÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú.*?‚ÄùÔºåÁÄú.*?‚ÄùÂåπÈÖçÂ≠óÁ¨¶‚Äúr‚Äù„ÄÇÈáç§牪•‰∏äËøáÁ®ãÔºåÁõ¥Âà∞‚Äú.*?‚ÄùÂåπÈÖç‰∫ÜB§ÑÂâçÈù¢ÁöÑÂ≠óÁ¨¶‚Äún‚ÄùÔºå‚Äú"‚ÄùÂåπÈÖç‰∫ÜB§ÑÁöÑÂ≠óÁ¨¶‚Äú‚Äù‚ÄùÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú@‚Äù„ÄÇÁÄú@‚ÄùÂåπÈÖçÊ镉∏ãÊù•ÁöÑÁ©∫Êݺ‚Äú ‚ÄùÔºåÂåπÈÖ秱˥•ÔºåÊü•ÊâæÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú.*?‚ÄùÔºåÁÄú.*?‚ÄùÂåπÈÖçÁ©∫Êݺ„ÄÇÁªßÁª≠Èáç§牪•‰∏äÂåπÈÖçËøáÁ®ãÔºåÁõ¥Âà∞ÁÄú.*?‚ÄùÂåπÈÖçÂà∞Â≠óÁ¨¶‰∏≤ÁªìÊùü‰ΩçÁΩÆÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚Äù„ÄÇÁ∫éÂ∑≤ÁªèÊòØÂ≠óÁ¨¶‰∏≤ÁªìÊùü‰ΩçÁΩÆÔºåÂåπÈÖ秱˥•ÔºåÊä•ÂëäÊ雷∏™Ë°®ËææºèÂú®‰ΩçÁΩÆ11§ÑÂåπÈÖ秱˥•Ôºå‰∏ÄËΩÆÂåπÈÖçÂ∞ùËØïÁªìÊùü„ÄÇ
Ê≠£ÂàôºïÊì鉺ÝÂä®Ë£ÖÁΩƉΩøÊ≠£ÂàôÂêëÂâ牺ÝÂä®ÔºåËøõÂÖ•‰∏ã‰∏ÄËΩÆÂ∞ùËØï„ÄÇÂêéÁª≠ÂåπÈÖçËøáÁ®ã‰∏éÁ¨¨‰∏ÄËΩÆÂ∞ùËØïÂåπÈÖçËøáÁ®ãÂü∫Êú¨Á±ª‰ººÔºåÂè؉ª•ÂèÇËÄÉÂõæ3-1„ÄÇ
‰ªéÂåπÈÖçËøáÁ®ã‰∏≠Âè؉ª•ÁúãÂà∞ÔºåÈùûË¥™Â©™Ê®°ÂºèÁöÑÂåπÈÖ秱˥•ËøáÁ®ãÔºåÂá݉πéÊØè‰∏ÄÊ≠•ÈÉΩ‰º¥ÈöèÁùÄÂõûÊ∫ØËøáÁ®ãÔºåÂØπÂåπÈÖçÊïàÁéáÁöÑÂΩ±ÂìçÊòØÂæà§ßÁöÑ„ÄÇ
3.2.2¬Ý Ë¥™Â©™Ê®°ÂºèÂåπÈÖ秱˥•ËøáÁ®ãÂàÜÊûê‚Äî‚Äî§ßËåÉÂõ¥Â≠êË°®Ëææºè
¬Ý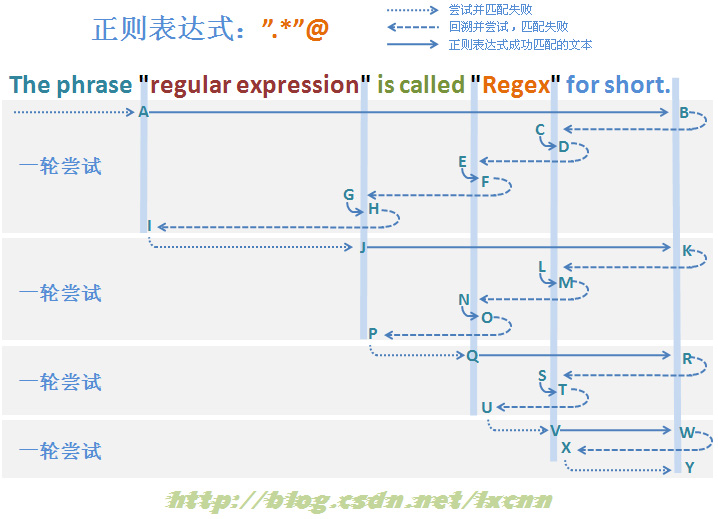
¬Ý
Âõæ3-2
PSÔºö‰ª•‰∏äÂàÜÊûêËøáÁ®ãÂõæÁ§∫ÂèÇËÄɉ∫Ü„ÄäÁ≤æÈÄöÊ≠£ÂàôË°®Ëææºè„Äã‰∏ĉπ¶Áõ∏ÂÖ≥Á´ÝËäÇÂõæÁ§∫„ÄÇ
构建匹配失败的贪婪模式的正则表达式:".*"@
其中量词修饰的子表达式为匹配范围较大的“.”,由于最后的“@”的存在,这个正则表达式最后也是一定匹配失败的,看一下匹配过程。
ȶñÂÖàÁÄú"‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÔºåÁΩçÁΩÆ0§ÑºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖ秱˥•ÔºåÁõ¥Âà∞Âõæ‰∏≠ÊÝáÁ§∫ÁöÑA§ÑÂåπÈÖçÊàêÂäüÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú.*‚Äù„ÄÇ
‚Äú.*‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÂêéÔºåÁî±AÂêéÈù¢ÁöщΩçÁΩƺÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÁ∫éÊòØË¥™Â©™Ê®°ÂºèԺ剺òÂåñÂ∞ùËØïÂåπÈÖçÔºå‰∏ÄÁõ¥ÂåπÈÖçÂà∞Â≠óÁ¨¶‰∏≤ÁöÑÁªìÊùü‰ΩçÁΩÆÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚Äù„ÄÇ‚Äú"‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÂêéÔºåÁ∫éÂ∑≤ÁªèÊòØÂ≠óÁ¨¶‰∏≤ÁöÑÁªìÊùü‰ΩçÁΩÆÔºåÂåπÈÖ秱˥•ÔºåÊü•ÊâæÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú.*‚ÄùÔºåÁÄú.*‚ÄùËÆ©Âá∫Â∑≤ÂåπÈÖçÂ≠óÁ¨¶‚Äú.‚Äù„ÄÇÈáç§牪•‰∏äËøáÁ®ãÔºåÁõ¥Âà∞ÂêéÈù¢‚Äú"‚ÄùÂåπÈÖç‰∫ÜC§ÑÂêéÈù¢ÁöÑÂ≠óÁ¨¶‚Äú‚Äù‚ÄùÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú@‚Äù„ÄÇÁÄú@‚ÄùÂåπÈÖçÊ镉∏ãÊù•D§ÑÁöÑÁ©∫Êݺ‚Äú ‚ÄùÔºåÂåπÈÖ秱˥•ÔºåÊü•ÊâæÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú.*‚ÄùÔºåÁÄú.*‚ÄùËÆ©Âá∫Â∑≤ÂåπÈÖçÊñáÊú¨„ÄÇÁªßÁª≠Èáç§牪•‰∏äÂåπÈÖçËøáÁ®ãÔºåÁõ¥Âà∞ÁÄú.*‚ÄùËÆ©Âá∫ÊâÄÊúâÂ∑≤ÂåπÈÖçÁöÑÊñáÊú¨Âà∞I§ÑÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚Äù„ÄÇ‚Äú"‚ÄùÂåπÈÖ秱˥•ÔºåÁ∫éÂ∑≤ÁªèÊ≤°ÊúâÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊä•ÂëäÊ雷∏™Ë°®ËææºèÂú®‰ΩçÁΩÆ11§ÑÂåπÈÖ秱˥•Ôºå‰∏ÄËΩÆÂåπÈÖçÂ∞ùËØïÁªìÊùü„ÄÇ
Ê≠£ÂàôºïÊì鉺ÝÂä®Ë£ÖÁΩƉΩøÊ≠£ÂàôÂêëÂâ牺ÝÂä®ÔºåËøõÂÖ•‰∏ã‰∏ÄËΩÆÂ∞ùËØï„ÄÇÂêéÁª≠ÂåπÈÖçËøáÁ®ã‰∏éÁ¨¨‰∏ÄËΩÆÂ∞ùËØïÂåπÈÖçËøáÁ®ãÂü∫Êú¨Á±ª‰ººÔºåÂè؉ª•ÂèÇËÄÉÂõæ3-2„ÄÇ
从匹配过程中可以看到,大范围子表达式贪婪模式的匹配失败过程,从总体上看,与非贪婪模式没有什么区别,最终进行的回溯次数与非贪婪模式基本一致,对匹配效率的影响仍然很大。
3.2.3¬Ý Ë¥™Â©™Ê®°ÂºèÂåπÈÖ秱˥•ËøáÁ®ãÂàÜÊûê‚Äî‚ÄîÊîπËøõÁöÑÂ≠êË°®Ëææºè
¬Ý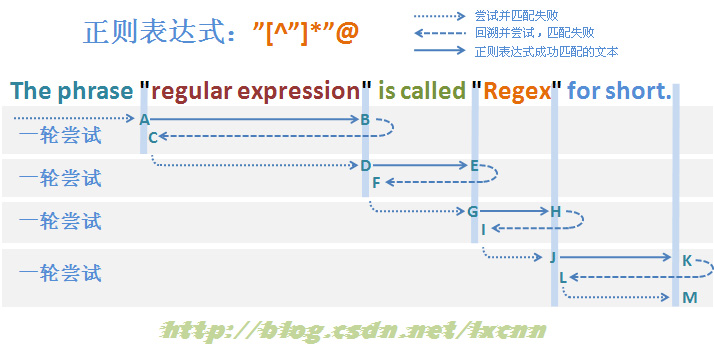
¬Ý
Âõæ3-3
构建匹配失败的贪婪模式的正则表达式:"[^"]*"@
其中量词修饰的子表达式,改为匹配范围较小的排除型字符组“[^"]”,由于最后的“@”的存在,这个正则表达式最后也是一定匹配失败的,看一下匹配过程。
ȶñÂÖàÁÄú"‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÔºåÁΩçÁΩÆ0§ÑºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖ秱˥•ÔºåÁõ¥Âà∞Âõæ‰∏≠ÊÝáÁ§∫ÁöÑA§ÑÂåπÈÖçÊàêÂäüÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú[^"]*‚Äù„ÄÇ
‚Äú[^"]*‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÂêéÔºåÁî±AÂêéÈù¢ÁöщΩçÁΩƺÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÁ∫éÊòØË¥™Â©™Ê®°ÂºèԺ剺òÂÖàÂ∞ùËØïÂåπÈÖçÔºå‰∏ÄÁõ¥ÂåπÈÖçÂà∞B§ÑÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚Äù„ÄÇ‚Äú"‚ÄùÂåπÈÖçÊ镉∏ãÊù•ÁöÑÁöÑÂ≠óÁ¨¶‚Äú"‚ÄùÔºåÂåπÈÖçÊàêÂäüÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú@‚Äù„ÄÇÁÄú@‚ÄùÂåπÈÖçÊ镉∏ãÊù•ÁöÑÁ©∫Êݺ‚Äú ‚ÄùÔºåÂåπÈÖ秱˥•ÔºåÊü•ÊâæÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú[^"]*‚ÄùÔºåÁÄú[^"]*‚ÄùËÆ©Âá∫Â∑≤ÂåπÈÖçÊñáÊú¨„ÄÇÁªßÁª≠Èáç§牪•‰∏äÂåπÈÖçËøáÁ®ãÔºåÁõ¥Âà∞ÁÄú[^"]*‚ÄùËÆ©Âá∫ÊâÄÊúâÂ∑≤ÂåπÈÖçÁöÑÊñáÊú¨Âà∞C§ÑÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚Äù„ÄÇ‚Äú"‚ÄùÂåπÈÖ秱˥•ÔºåÁ∫éÂ∑≤ÁªèÊ≤°ÊúâÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊä•ÂëäÊ雷∏™Ë°®ËææºèÂú®‰ΩçÁΩÆ11§ÑÂåπÈÖ秱˥•Ôºå‰∏ÄËΩÆÂåπÈÖçÂ∞ùËØïÁªìÊùü„ÄÇ
Ê≠£ÂàôºïÊì鉺ÝÂä®Ë£ÖÁΩƉΩøÊ≠£ÂàôÂêëÂâ牺ÝÂä®ÔºåËøõÂÖ•‰∏ã‰∏ÄËΩÆÂ∞ùËØï„ÄÇÂêéÁª≠ÂåπÈÖçËøáÁ®ã‰∏éÁ¨¨‰∏ÄËΩÆÂ∞ùËØïÂåπÈÖçËøáÁ®ãÂü∫Êú¨Á±ª‰ººÔºåÂè؉ª•ÂèÇËÄÉÂõæ3-3„ÄÇ
从匹配过程中可以看到,使用了排除型字符组的贪婪模式的匹配失败过程,从总体上看,大量减少了每轮回溯的次数,可以有效的提升匹配效率。
3.2.4¬Ý Ë¥™Â©™Ê®°ÂºèÂåπÈÖ秱˥•ËøáÁ®ãÂàÜÊûê‚Äî‚ÄîÂõ∫ÂåñÂàÜÁªÑ
ÈÄöËøá3.2.3ËäÇÁöÑÂàÜÊûêÂè؉ª•Áü•ÈÅìÔºåÁ∫é‚Äú[^"]*‚Äù‰ΩøÁ∫ÜÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑÔºåÈÇ£‰πàÂõæ3-3‰∏≠ÔºåÂú®AÂíåB‰πãÈó¥Ë¢´ÂåπÈÖçÂà∞ÁöÑÂ≠óÁ¨¶ÔºåÂ∞±‰∏ÄÂÆö‰∏牺öÊòØÂ≠óÁ¨¶‚Äú"‚ÄùÔºåÊâĉª•BÂà∞C‰πãÈó¥ÂõûÊ∫ØËøáÁ®ãÂ∞±Êòاö‰ΩôÁöÑÔºå‰πüÂ∞±ÊòØËØ¥Âú®Ëøô‰πãÈó¥ÁöÑÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÂÆåÂÖ®Âè؉ª•‰∏çËÆ∞ÂΩï„ÄÇ.NET‰∏≠Âè؉ª•‰ΩøÁî®Âõ∫ÂåñÂàÜÁªÑÔºåJava‰∏≠Âè؉ª•‰ΩøÁî®ÂçÝÊú≺òÂÖàÈáèËØçÊù•ÂÆûÁé∞Ëøô‰∏ÄÊïàÊûú„ÄÇ
¬Ý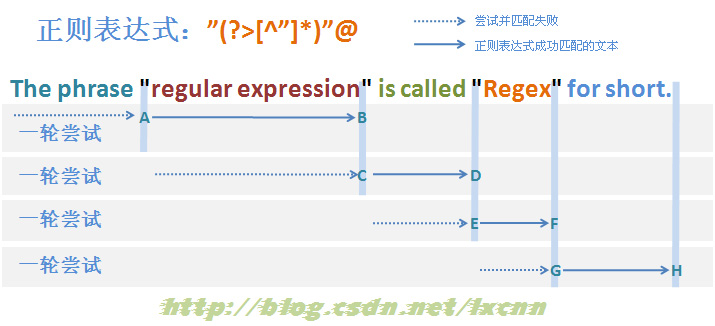
¬Ý
Âõæ3-4
ȶñÂÖàÁÄú"‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÔºåÁΩçÁΩÆ0§ÑºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖ秱˥•ÔºåÁõ¥Âà∞Âõæ‰∏≠ÊÝáÁ§∫ÁöÑA§ÑÂåπÈÖçÊàêÂäüÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äú(?>[^"]*)‚Äù„ÄÇ
‚Äú(?>[^"]*)‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÂêéÔºåÁî±AÂêéÈù¢ÁöщΩçÁΩƺÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÁ∫éÊòØË¥™Â©™Ê®°ÂºèԺ剺òÂÖàÂ∞ùËØïÂåπÈÖçÔºå‰∏ÄÁõ¥ÂåπÈÖçÂà∞B§ÑÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú"‚ÄùÔºåÂú®Ëøô‰∏ÄÂåπÈÖçËøáÁ®ã‰∏≠Ôºå‰∏çËÆ∞ÂΩª‰ΩïÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅ„ÄÇ‚Äú"‚ÄùÂåπÈÖçÊ镉∏ãÊù•ÁöÑÂ≠óÁ¨¶‚Äú‚Äù‚ÄùÔºåÂåπÈÖçÊàêÂäüÔºåÂ∞ÜÊéßÂà∂Êùɉ∫§Áªô‚Äú@‚Äù„ÄÇÁÄú@‚ÄùÂåπÈÖçÊ镉∏ãÊù•ÁöÑÁ©∫Êݺ‚Äú ‚ÄùÔºåÂåπÈÖ秱˥•ÔºåÊü•ÊâæÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÁ∫éÂ∑≤ÁªèÊ≤°ÊúâÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊä•ÂëäÊ雷∏™Ë°®ËææºèÂú®‰ΩçÁΩÆ11§ÑÂåπÈÖ秱˥•Ôºå‰∏ÄËΩÆÂåπÈÖçÂ∞ùËØïÁªìÊùü„ÄÇ
Ê≠£ÂàôºïÊì鉺ÝÂä®Ë£ÖÁΩƉΩøÊ≠£ÂàôÂêëÂâ牺ÝÂä®ÔºåËøõÂÖ•‰∏ã‰∏ÄËΩÆÂ∞ùËØï„ÄÇÂêéÁª≠ÂåπÈÖçËøáÁ®ã‰∏éÁ¨¨‰∏ÄËΩÆÂ∞ùËØïÂåπÈÖçËøáÁ®ãÂü∫Êú¨Á±ª‰ººÔºåÂè؉ª•ÂèÇËÄÉÂõæ3-4„ÄÇ
从匹配过程中可以看到,使用了固化分组的贪婪模式的匹配失败过程,没有涉及到回溯,可以最大限度的提升匹配效率。
3.3¬Ý¬Ý¬Ý¬Ý ÈùûË¥™Â©™Ê®°ÂºèÂêëË¥™Â©™Ê®°ÂºèÁöÑËΩ¨Êç¢
使用匹配范围较大的子表达式时,贪婪模式与非贪婪模式匹配到的内容会有所不同,但是通过优化子表达式,非贪婪模式可以实现的匹配,贪婪模式都可以实现。
ÊØî¶ÇÂú®ÂÆûÈôÖÂ∫îÁ∏≠ÔºåÂåπÈÖçimgÊÝáÁ≠æÁöÑÂÜÖÂÆπ„ÄÇ
举例:
ÈúÄʱÇÔºöÂèñÂæóimgÊÝáÁ≠æ‰∏≠ÁöÑÂõæÁâáÂú∞ÂùÄÔºåsrc=ÂêéÂõ∫ÂÆö‰∏∫‚Äú‚Äù‚Äù
源字符串:<img class="test" src="/img/logo.gif" title="测试" />
正则表达式一:<img/b.*?src="(.*?)".*?>
ÂåπÈÖçÁªìÊûú‰∏≠ÔºåÊçïËé∑ÁªÑ1ÁöÑÂÜÖÂÆπÂç≥‰∏∫ÂõæÁâáÂú∞ÂùÄ„ÄÇÂè؉ª•ÁúãÂà∞ÔºåËøô‰∏™‰æãÂ≠ê‰∏≠‰ΩøÁî®ÁöÑÈÉΩÊòØÈùûË¥™Â©™Ê®°ÂºèÔºåËÄåÊÝπÊçƉ∏äÈù¢Á´ÝËäÇÁöÑÂàÜÊûêÔºåÂêéÈù¢‰∏§‰∏™ÈùûË¥™Â©™Ê®°ÂºèÈÉΩÂè؉ª•‰ΩøÁî®ÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑÔºåÂ∞ÜÈùûË¥™Â©™Ê®°ÂºèËΩ¨Ê碉∏∫Ë¥™Â©™Ê®°Âºè„ÄÇ
正则表达式二:<img/b.*?src="([^"]*)"[^>]*>
Ê≥®Ôºö‚Äúsrc="‚Ķ"‚ÄùÂíåÊÝáÁ≠æÁªìÊùüÊÝáËÆ∞Á¨¶‚Äú>‚Äù‰πãÈó¥ÁöѱûÊÄ߉∏≠Ôºå‰πüÂèØËÉΩÂá∫Áé∞Â≠óÁ¨¶‚Äú>‚ÄùÔºå‰ΩÜÈÇ£ÊòØÊûÅÁ´ØÊÉÖÂܵԺåËøôÈáå‰∏ç‰∫àËÆ®ËÆ∫„ÄÇ
Âêé‰∏§Â§ÑÈùûË¥™Â©™Ê®°ÂºèÔºåÂè؉ª•ÈÄöËøáÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑËΩ¨Ê碉∏∫Ë¥™Â©™Ê®°ÂºèÔºåÊèêÈ´òÂåπÈÖçÊïàÁéáÔºåËÄå‚Äúsrc=‚ÄùÂâçÁöÑÈùûË¥™Â©™Ê®°ÂºèÔºåÁ∫é˶ÅÊéíÈô§ÁöÑÊò؉∏ĉ∏™Â≠óÁ¨¶Â∫èÂàó‚Äúsrc=‚ÄùÔºåËÄå‰∏çÊòØÂçïÁã¨ÁöÑÊüê‰∏ĉ∏™ÊàñÂá݉∏™Â≠óÁ¨¶ÔºåÊâĉª•‰∏çËÉΩ‰ΩøÁî®ÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑ„ÄÇÂΩìÁÑ∂‰πü‰∏çÊòØÊ≤°ÊúâÂäûÊ≥ïÔºåÂè؉ª•‰ΩøÁî®È°∫Â∫èÁéØËßÜÊù•ËææÂà∞Ëøô‰∏ÄÊïàÊûú„ÄÇ
正则表达式三:<img/b(?:(?!src=).)*src="([^"]*)"[^>]*>
‚Äú(?!src=).‚ÄùË°®Á§∫ËøôÊÝ∑‰∏ĉ∏™Â≠óÁ¨¶Ôºå‰ªéÂÆɺÄÂßãÔºåÂè≥‰æ߉∏çËÉΩÊòØÂ≠óÁ¨¶Â∫èÂàó‚Äúsrc=‚ÄùÔºåËÄå‚Äú(?:(?!src=).)*‚ÄùÂ∞±Ë°®Á§∫Á¨¶Âêà‰∏äÈù¢ËßÑÂàôÁöÑÂ≠óÁ¨¶ÔºåÊúâ0‰∏™ÊàñÊóÝÈôê§ö‰∏™„ÄÇËøôÊÝ∑Â∞±ËææÂà∞ÊéíÈô§Â≠óÁ¨¶Â∫èÂàóÁöÑÁõÆÁöÑÔºåÂÆûÁé∞ÁöÑÊïàÊûúÂêåÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑ‰∏ÄÊÝ∑ÔºåÂ虉∏çËøáÊéíÈô§ÂûãÂ≠óÁ¨¶ÁªÑÊéíÈô§ÁöÑÊò؉∏ĉ∏™Êàñ§ö‰∏™Â≠óÁ¨¶ÔºåËÄåËøôÁßçÁéØËßÜÁªìÊûÑÊéíÈô§ÁöÑÊò؉∏ĉ∏™Êàñ§ö‰∏™ÊúâÂ∫èÁöÑÂ≠óÁ¨¶Â∫èÂàó„ÄÇ
‰ΩÜÊò؉ª•È°∫Â∫èÁéØËßÜÁöÑÊñπºèÊéíÈô§Â≠óÁ¨¶Â∫èÂàóÔºåÁ∫éÂú®ÂåπÈÖçÊØè‰∏ĉ∏™Â≠óÁ¨¶Êó∂ÔºåÈÉΩ˶ÅËøõË°åËæɧöÁöÑÂà§Êñ≠ÔºåÊâĉª•Áõ∏ÂØπ‰∫éÈùûË¥™Â©™Ê®°ÂºèÔºåÊòØÊèêÂçáÊïàÁéáËøòÊòØÈôç‰ΩéÊïàÁéáÔºå˶ÅÊÝπÊçÆÂÆûÈôÖÊÉÖÂܵËøõË°åÂàÜÊûê„ÄÇÂØπ‰∫éÁÆÄÂçïÁöÑÊ≠£ÂàôË°®ËææºèÔºåÊàñÊòØÁÆÄÂçïÁöÑÊ∫êÂ≠óÁ¨¶‰∏≤Ôºå‰∏ÄËà¨Êù•ËØ¥ÊòØÈùûË¥™Â©™Ê®°ÂºèÊïàÁéáÈ´ò‰∫õÔºåËÄåÂØπ‰∫éÊï∞ÈáèËæɧßÊ∫êÂ≠óÁ¨¶‰∏≤ÔºåÊàñÊòاçÊùÇÁöÑÊ≠£ÂàôË°®ËææºèÔºå‰∏ÄËà¨Êù•ËØ¥ÊòØË¥™Â©™Ê®°ÂºèÊïàÁéáÈ´ò‰∫õ„ÄÇ
ÊØî¶lj∏äÈù¢ÂèñÂæóimgÊÝáÁ≠æ‰∏≠ÁöÑÂõæÁâáÂú∞ÂùÄÈúÄʱÇÔºåÂü∫Êú¨‰∏äÁî®Ê≠£ÂàôË°®Ëææ‰∫åÂ∞±Âè؉ª•‰∫ÜÔºõÂØπ‰∫é§çÊùÇÁöÑÂ∫îÁî®Ôºå¶ÇÂπ≥Ë°°ÁªÑ‰∏≠ÔºåÂ∞±ÈúÄ˶ʼnΩøÁî®ÁªìÂêàÁéØËßÜÁöÑË¥™Â©™Ê®°Âºè‰∫Ü„ÄÇ
‰ª•ÂåπÈÖçµå•ódivÊÝáÁ≠æÁöÑÂπ≥Ë°°ÁªÑ‰∏∫‰æãÔºö
Regex reg = new Regex(@"(?isx)¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬Ý¬Ý¬Ý¬Ý¬Ý #ÂåπÈÖçÊ®°ÂºèÔºåÂøΩÁï•Â§ßÂ∞èÂÜôÔºå‚Äú.‚ÄùÂåπÈÖ牪ªÊÑèÂ≠óÁ¨¶
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý <div[^>]*>¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý #ºÄÂßãÊÝáËÆ∞‚Äú<div...>‚Äù
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý (?>¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý #ÂàÜÁªÑÊûÑÈÄÝÔºåÁî®Êù•ÈôêÂÆöÈáèËØç‚Äú*‚Äù‰øÆÈ•∞ËåÉÂõ¥
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬Ý¬Ý¬Ý<div[^>]*>¬Ý (?<Open>)¬Ý¬Ý #ÂëΩÂêçÊçïËé∑ÁªÑÔºåÈÅáÂà∞ºÄÂßãÊÝáËÆ∞ÔºåÂÖ•ÊÝàÔºåOpenËÆ°Êï∞ÂäÝ1
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý |¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý #ÂàÜÊîØÁªìÊûÑ
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý </div>¬Ý (?<-Open>)¬Ý¬Ý¬Ý¬Ý¬Ý #Áã≠‰πâÂπ≥Ë°°ÁªÑÔºåÈÅáÂà∞ÁªìÊùüÊÝáËÆ∞ÔºåÂá∫ÊÝàÔºåOpenËÆ°Êï∞Âáè1
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý |¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý #ÂàÜÊîØÁªìÊûÑ
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý (?:(?!</?div/b).)*¬Ý¬Ý¬Ý¬Ý¬Ý #Âè≥‰æ߉∏ç‰∏∫ºÄÂßãÊàñÁªìÊùüÊÝáËÆ∞ÁöщªªÊÑèÂ≠óÁ¨¶
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý )*¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý #‰ª•‰∏äÂ≠ê‰∏≤Âá∫Áé∞0ʨ°Êàñ‰ªªÊÑè§öʨ°
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý (?(Open)(?!))¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý #Âà§Êñ≠ÊòØÂê¶ËøòÊúâ'OPEN'ÔºåÊúâÂàôËØ¥Êòé‰∏çÈÖçÂØπԺ剪ĉπàÈÉΩ‰∏çÂåπÈÖç
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý </div>¬Ý¬Ý¬Ý ¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý#ÁªìÊùüÊÝáËÆ∞‚Äú</div>‚Äù
¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ");
‚Äú(?:(?!</?div/b).)*‚ÄùËøôÈáå‰ΩøÁî®ÁöÑÂ∞±ÊòØÁªìÂêàÁéØËßÜÁöÑË¥™Â©™Ê®°ÂºèÔºåËôΩÁÑ∂ÊØèÂåπ‰∏ĉ∏™Â≠óÁ¨¶ÈÉΩ˶ÅÂÅöÂæà§öÂà§Êñ≠Ôºå‰ΩÜËøôÁßçÂà§Êñ≠ÊòØÂü∫‰∫éÂ≠óÁ¨¶ÁöÑÔºåÈÄüÂ∫¶ÂæàÂø´ÔºåËÄå¶ÇÊûúËøôÈáå‰ΩøÁî®ÈùûË¥™Â©™Ê®°ÂºèÔºåÈÇ£‰πàÊØèʨ°Ë¶ÅÂÅöÁöÑÂ∞±ÊòØÂàÜÊîØÁªìÊûÑ‚Äú|‚ÄùÁöÑÂà§Êñ≠‰∫ÜÔºåËÄåÂàÜÊîØÁªìÊûÑÊòØÈùûÂ∏∏ÂΩ±ÂìçÂåπÈÖçÊïàÁéáÁöÑÔºåÂÖ∂‰ª£‰ª∑ËøúËøúÈ´ò‰∫éÂØπÁ°ÆÂÆöÂ≠óÁ¨¶ÁöÑÂà§Êñ≠„ÄÇËÄåÂè¶Â§ñ‰∏ĉ∏™ÂéüÂõÝÔºåÂ∞±ÊòØË¥™Â©™Ê®°ÂºèÂè؉ª•ÁªìÂêàÂõ∫ÂåñÂàÜÁªÑÊù•ÊèêÂçáÊïàÁéáÔºåËÄåÂØπÈùûË¥™Â©™Ê®°Âºè‰ΩøÁî®Âõ∫ÂåñÂàÜÁªÑÂç¥ÊòØÊ≤°ÊúâÊÑè‰πâÁöÑ„ÄÇ
4¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý Ë¥™Â©™‰∏éÈùûË¥™Â©™‚Äî‚ÄîÊúÄÂêéÁöÑÂõûÈ°æ
4.1¬Ý¬Ý¬Ý¬Ý ‰∏ĉ∏™‰æãÂ≠êÁöÑÂåπÈÖçÂéüÁêÜÂõûÈ°æ
再回过头来看一下2.1.1节例子中正则,前面从应用角度进行了分析,但讨论过匹配原理后会发现,匹配过程并不是那么简单的,下面从匹配原理角度分析的匹配过程。
¬Ý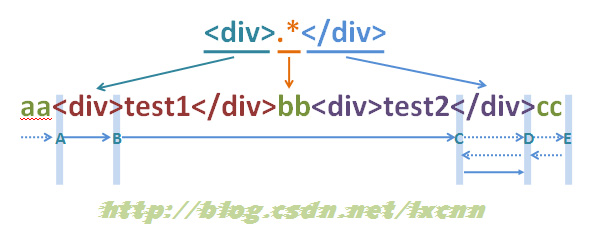
¬Ý
Âõæ4-1
ȶñÂÖàÁÄú<‚ÄùÂèñÂæóÊéßÂà∂ÊùÉÔºåÁΩçÁΩÆ0‰ΩçºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖçÂ≠óÁ¨¶‚Äúa‚ÄùÔºåÂåπÈÖ秱˥•ÔºåÁ¨¨‰∏ÄËΩÆÂåπÈÖçÁªìÊùü„ÄÇÁ¨¨‰∫åËΩÆÂåπÈÖ牪é‰ΩçÁΩÆ1ºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂêåÊÝ∑ÂåπÈÖ秱˥•„ÄÇÁ¨¨‰∏âËΩƉªé‰ΩçÁΩÆ3ºÄÂßãÂ∞ùËØïÂåπÈÖçÔºåÂåπÈÖçÂ≠óÁ¨¶‚Äú<‚ÄùÔºåÂåπÈÖçÊàêÂäüÔºåÊéßÂà∂Êùɉ∫§Áªô‚Äúd‚Äù„ÄÇ
“d”尝试匹配字符“d”,匹配成功,控制权交给“i”。重复以上过程,直到由“>”匹配到字符“>”,控制权交给“.*”。
“.*”属于贪婪模式,将从B处后的字符“t”开始,一直匹配到E处,也就是字符串结束位置,将控制权交给“<”。
“<”从字符串结束位置尝试匹配,匹配失败,向前查找可供回溯的状态,把控制权交给“.*”,由“.*”让出一个字符“c”,把控制权再交给“<”,尝试匹配,匹配失败,向前查找可供回溯的状态。一直重复以上过程,直到“.*”让出已匹配的字符“<”,实际上也就是让出了已匹配的子串“</div>cc”为止,“<”才匹配字符“<”成功,控制权交给“/”。
接下来由“/”、“d”、“i”、“v”分别匹配对应的字符成功,此时整个正则表达式匹配完毕。
4.2¬Ý¬Ý¬Ý¬Ý Ë¥™Â©™‰∏éÈùûË¥™Â©™‚Äî‚ÄîÈáèËØçÁöÑÁªÜËäÇ
4.2.1¬Ý Âå∫Èó¥ÈáèËØçÁöÑÈùûË¥™Â©™Ê®°Âºè
ÂâçÈù¢ÊèêÂà∞ÁöÑÈùûË¥™Â©™Ê®°ÂºèÔºå‰∏ÄÁõ¥ÈÉΩÊò؉ΩøÁî®ÁöÑ‚Äú*?‚ÄùÔºåËÄåÊ≤°ÊúâÊ∂âÂèäÂà∞ÂÖ∂ÂÆÉÁöÑÂå∫Èó¥ÈáèËØçÔºåÂØπ‰∫é‚Äú*?‚ÄùÂíå‚Äú+?‚ÄùËøôÊÝ∑ÁöÑÈùûË¥™Â©™Ê®°ÂºèÔºå§ß§öÊï∞Êé•Ë߶ËøáÊ≠£ÂàôË°®ËææºèÁöщ∫∫ÈÉΩÂè؉ª•ÁêÜËߣԺå‰ΩÜÊòØÂØπ‰∫éÂå∫Èó¥ÈáèËØçÁöÑÈùûË¥™Â©™Ê®°ÂºèÔºåÊØî¶ǂÄú{m,n}?‚ÄùÔºå˶ʼnπàÊòØÊ≤°ËßÅËøáÔºå˶ʼnπàÊò؉∏çÁêÜËߣԺå‰∏ªË¶ÅÊòØËøôÁßçÂ∫îÁî®Âú∫ÊôØÈùûÂ∏∏Â∞ëÔºåÊâĉª•Ë¢´ÂøΩÁ∫Ü„ÄÇ
首先需要明确的一点,就是量词“{m,n}”是匹配优先量词,虽然它有了上限,但是在达到上限之前,能够匹配,还是要尽可能多的匹配的。而“{m,n}?”就是对应的忽略优先量词了,在可匹配可不匹配的情况下,尽可能少的匹配。
接下来举一个例子说明这种非贪婪模式的应用。
举例(参考 限制字符长度与最小匹配):
需求:如何限制在长度为100的字符串中,从头匹配到最先出现的abc
csdn.{1,100}abc ËøôÊÝ∑ÂÜôÊòØÊúħßÂåπÈÖç(1-100‰∏™Â≠óÁ¨¶‰∏≤‰∏≠ÔºåÊàëÈúÄ˶ÅÊúÄÂ∞èÁöÑ)
比如csdnfddabckjdsfjabc,匹配结果应为:csdnfddabc
正则表达式:csdn.{1,100}?abc
ÊàñËÆ∏ÂØπËøô‰∏™‰æãÂ≠êËøòÊúâ‰∫∫‰∏çÊòØÂæàÁêÜËߣԺå‰ΩÜÊòØÊÉ≥ÊÉ≥ÔºåÂÖ∂ÂÆû‚Äú*‚ÄùÂ∞±Á≠≪∑‰∫é‚Äú{0,}‚ÄùÔºå‚Äú+‚ÄùÂ∞±Á≠≪∑‰∫é‚Äú{1,}‚ÄùÔºå‚Äú*?‚Äù‰πüÂ∞±ÊòØ‚Äú{0,}?‚ÄùÔºåÊäΩ˱°Âá∫Êù•‰πüÂ∞±ÊòØ‚Äú{m,}?‚ÄùÔºåÂç≥‰∏äÈôê‰∏∫ÊóÝÁ©∑§߄ÄǶÇÊûú‰∏äÈôê‰∏∫‰∏ĉ∏™Âõ∫ÂÆöÂĺԺåÈÇ£Â∞±ÊòØ‚Äú{m,n}?‚ÄùÔºåËøôÊÝ∑Â∫îËØ•‰πüÂ∞±Âè؉ª•ÁêÜËߣ‰∫Ü„ÄÇ
‚Äú{m}‚ÄùÊ≤°ÊúâÊîæÂú®ÂåπÈÖ牺òÂÖàÈáèËØç‰∏≠ÔºåÂêåÊÝ∑ÁöÑÔºå‚Äú{m}?‚ÄùËôΩÁÑ∂Ë¢´ÈÉ®ÂàÜËØ≠Ë®ÄÊâÄÊîØÊåÅÔºå‰ΩÜÊò؉πüÊ≤°ÊúâÊîæÂú®ÂøΩÁºòÂÖàÈáèËØç‰∏≠Ôºå‰∏ªË¶ÅÊòØÂõ݉∏∫Ëøô‰∏§ÁßçÈáèËØçÔºåÂÆûÁé∞ÁöÑÊïàÊûúÊò؉∏ÄÊÝ∑ÁöÑÔºåÂè™ÊúâË¢´‰øÆÈ•∞ÁöÑÂ≠êË°®ËææºèÂåπÈÖçmʨ°ÊâçËÉΩÂåπÈÖçÊàêÂäüÔºå‰∏îÊ≤°ÊúâÂè؉æõÂõûÊ∫ØÁöÑÁä∂ÊÄÅÔºåÊâĉª•‰πü‰∏çÂ≠òÂú®ÊòØÂåπÈÖ牺òÂÖàËøòÊòØÂøΩÁºòÂÖàÁöÑÈóÆÈ¢òÔºå‰πüÂ∞±‰∏çÂú®Êú¨ÊñáÁöÑËÆ®ËÆ∫ËåÉÂõ¥ÂÜÖ„Älj∫ãÂÆû‰∏äÂç≥‰ΩøËÆ®ËÆ∫‰πüÊ≤°ÊúâÊÑè‰πâÁöÑÔºåÂè™Ë¶ÅÁü•ÈÅìÂÆɉª¨ÁöÑÂåπÈÖçË°å‰∏∫‰πüÂ∞±Êò؉∫Ü„ÄÇ
4.2.2¬Ý ÂøΩÁºòÂÖàÈáèËØçÁöÑÂåπÈÖç‰∏ãÈôê
ÂØπ‰∫éÂåπÈÖ牺òÂÖàÈáèËØçÁöÑÂåπÈÖç‰∏ãÈôêÂæà•ΩÁêÜËߣԺå‚Äú?‚ÄùÁ≠≪∑‰∫é‚Äú{0,1}‚ÄùÔºåÂÆɉøÆÈ•∞ÁöÑÂ≠êË°®ËææºèÔºåÊúÄÂ∞ëÂåπÈÖç0ʨ°ÔºåÊúħöÂåπÈÖç1ʨ°Ôºõ‚Äú*‚ÄùÁ≠≪∑‰∫é‚Äú{0,}‚ÄùÔºåÂÆɉøÆÈ•∞ÁöÑÂ≠êË°®ËææºèÔºåÊúÄÂ∞ëÂåπÈÖç0ʨ°ÔºåÊúħöÂåπÈÖçÊóÝÁ©∑§öʨ°Ôºõ‚Äú+‚ÄùÁ≠≪∑‰∫é‚Äú{1,}‚ÄùÔºåÂÆɉøÆÈ•∞ÁöÑÂ≠êË°®ËææºèÔºåÊúÄÂ∞ëÂåπÈÖç1ʨ°ÔºåÊúħöÂåπÈÖçÊóÝÁ©∑§öʨ°„ÄÇ
对于忽略优先量词的下限,也是容易忽略的。
“??”也是忽略优先量词,被修饰的子表达式使用的也是非贪婪模式,“??”修饰的子表达式,最少匹配0次,最多匹配1次。在匹配过程中,遵循非贪婪模式匹配原则,先不匹配,即匹配0次,记录回溯状态,只有不得不匹配时,才去尝试匹配。
‚Äú*?‚Äù‰øÆÈ•∞ÁöÑÂ≠êË°®ËææºèÔºåÊúÄÂ∞ëÂåπÈÖç0ʨ°ÔºåÊúħöÂåπÈÖçÊóÝÁ©∑§öʨ°Ôºõ‚Äú+?‚Äù‰øÆÈ•∞ÁöÑÂ≠êË°®ËææºèÔºåÊúÄÂ∞ëÂåπÈÖç1ʨ°ÔºåÊúħöÂåπÈÖçÊóÝÁ©∑§öʨ°Ôºå‚Äú+?‚ÄùËôΩÁÑ∂‰ΩøÁî®ÁöÑÊòØÈùûË¥™Â©™Ê®°ÂºèÔºåÂú®ÂåπÈÖçËøáÁ®ã‰∏≠ÔºåȶñÂÖà˶ÅÂåπÈÖç‰∏ĉ∏™Â≠óÁ¨¶Ôºå‰πãÂêéÊâçÊòØÂøΩÁï•ÂåπÈÖçÁöÑÔºåËøô‰∏ÄÁÇπ‰πüÈúÄ˶ÅÊ≥®ÊÑè„ÄÇ
4.3¬Ý¬Ý¬Ý¬Ý Ë¥™Â©™‰∏éÈùûË¥™Â©™Ê®°ÂºèÂ∞èÁªì
√ò¬Ý ‰ªéËØ≠Ê≥ïËßíÂ∫¶ÁúãË¥™Â©™‰∏éÈùûË¥™Â©™
被匹配优先量词修饰的子表达式,使用的是贪婪模式;被忽略优先量词修饰的子表达式,使用的是非贪婪模式。
匹配优先量词包括:“{m,n}”、“{m,}”、“?”、“*”和“+”。
忽略优先量词包括:“{m,n}?”、“{m,}?”、“??”、“*?”和“+?”。
√ò¬Ý ‰ªéÂ∫îÁî®ËßíÂ∫¶ÁúãË¥™Â©™‰∏éÈùûË¥™Â©™
贪婪与非贪婪模式影响的是被量词修饰的子表达式的匹配行为,贪婪模式在整个表达式匹配成功的前提下,尽可能多的匹配;而非贪婪模式在整个表达式匹配成功的前提下,尽可能少的匹配。非贪婪模式只被部分NFA引擎所支持。
√ò¬Ý ‰ªéÂåπÈÖçÂéüÁêÜËßíÂ∫¶ÁúãË¥™Â©™‰∏éÈùûË¥™Â©™
ËÉΩËææÂà∞ÂêåÊÝ∑ÂåπÈÖçÁªìÊûúÁöÑË¥™Â©™‰∏éÈùûË¥™Â©™Ê®°ÂºèÔºåÈÄöÂ∏∏ÊòØË¥™Â©™Ê®°ÂºèÁöÑÂåπÈÖçÊïàÁéáËæÉÈ´ò„ÄÇ
所有的非贪婪模式,都可以通过修改量词修饰的子表达式,转换为贪婪模式。
贪婪模式可以与固化分组结合,提升匹配效率,而非贪婪模式却不可以。
转自:http://blog.csdn.net/lxcnn/article/details/4756030


- 2011-07-06 17:03
- 浏览 994
- 评论(0)
- 分类:编程语言
- 查看更多
发表评论

-
(从网上考过来的,收藏) javascript 正则表达式的贪婪与非贪婪
2012-10-08 10:35 936以下内容转自:http://www.cnitblog.com ... -
正则表达式常用验证
2011-08-24 12:20 879Âú®ÂâçÂè∞Âæà§öÂú∞ÊñπÈúÄ˶ÅÈ™åËØÅËæìÂÖ•ÊݺºèÔºå‰∏∫‰∫ÜÊñπ‰æø‰ª•Âêé‰ΩøÁî®ÔºåÊääÂ∏∏Áî®ÁöÑÊï¥ÁêÜ ... -
正则判断一个字符串里是否包含一些词
2011-08-16 16:53 3305今天项目里用到了正则,判断一个字符串里是不是包含这些词,词出 ... -
js取当前url参数
2011-07-19 11:14 1984js没有提供取当前url参数的方法,只能是自己从中截取了,在 ... -
正则手册
2011-07-07 16:53 1049Áªô§ßÂÆ∂ÂÖ±‰∫´‰∏™Ê≠£ÂàôÊâãÂÜå ¬Ý ¬Ý ¬Ý ʨ¢ËøéÊü•ÁúãÊú¨‰∫∫ÂçöÂÆ¢Ôºö ... -
[ ] 字符组(Character Classes) .
2011-07-06 17:31 861¬Ý[]ËÉΩ§üÂåπÈÖçÊâÄÂåÖÂê´Áöщ∏ÄÁ≥ªÂàóÂ≠óÁ¨¶‰∏≠ÁöщªªÊÑè‰∏ĉ∏™„ÄÇÈúÄ˶ÅÊ≥®ÊÑèÁöÑÊòØÔºå[ ... -
正则基础之——捕获组(capture group) .
2011-07-06 17:30 10531¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ 1.1¬Ý¬Ý¬Ý¬Ý ‰ªÄ‰πàÊòØÊçïËé∑ÁªÑ ... -
Ê≠£ÂàôË°®ËææºèÂ≠¶‰πÝÂèÇËÄÉ
2011-07-06 17:28 809Ê≠£ÂàôË°®ËææºèÂ≠¶‰πÝÂèÇËÄÉ 1 ... -
正则基础之——小数点 .
2011-07-06 17:23 820Â∞èÊï∞ÁÇπÂè؉ª•ÂåπÈÖçÈô§‰∫ÜÊç¢Ë°åÁ¨¶‚Äú/n‚Äù‰ª•Â§ñÁöщªªÊÑè‰∏ĉ∏™Â≠óÁ¨¶ ¬Ý ‰∏Ä ... -
正则基础之——NFA引擎匹配原理 .
2011-07-06 17:22 1031NFAºïÊìéÂåπÈÖçÂéüÁêÜ 1¬Ý¬Ý¬Ý¬ ... -
正则基础之——环视 .
2011-07-06 17:21 603ÁéØËßÜÂè™ËøõË°åÂ≠êË°®ËææºèÁöÑÂåπÈÖçÔºå‰∏çÂçÝÊúâÂ≠óÁ¨¶ÔºåÂåπÈÖçÂà∞ÁöÑÂÜÖÂÆπ‰∏ç‰øùÂ≠òÂà∞ÊúÄÁªà ... -
正则基础之——/b 单词边界 .
2011-07-06 17:20 8481¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ ‚Äú/b‚ÄùÂåπÈÖçÂçïËØçËæπÁïåÔºå‰∏çÂåπÈÖ牪ª‰Ωï ... -
正则应用之——日期正则表达式
2011-07-06 17:18 11081¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ ȶñÂÖàÈúÄ˶ÅËØ¥ÊòéÁöщ∏ÄÁÇπÔºåÊóÝËÆ∫ÊòØWin ... -
.NET正则基础之——.NET正则匹配模式 .
2011-07-06 17:16 23801¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ ÂåπÈÖçÊ®°ÂºèÊåáÁöÑÊò؉∏ĉ∫õÂè؉ª•ÊîπÂèòÊ≠£ÂàôË°® ... -
.NET正则基础之——平衡组 .
2011-07-06 17:14 18471¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ Âπ≥Ë°°ÁªÑÊòØÂæÆËΩØÂú®.NET‰∏≠ÊèêÂá∫Áöщ∏Ä ... -
正则基础之——非捕获组 .
2011-07-06 17:10 1398非捕获组:(?:Expression) 接触正则表达式不久的 ... -
正则基础之——反向引用 .
2011-07-06 17:09 13721¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ ÊçïËé∑ÁªÑÊçïËé∑Âà∞ÁöÑÂÜÖÂÆπÔºå‰∏牪ÖÂè؉ª•Âú® ... -
.NET正则基础——.NET正则类及方法应用 .
2011-07-06 17:07 11291¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ ÂàùÂ≠¶ ... -
NET正则基础之——正则委托 .
2011-07-06 17:05 8701¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝʶÇËø∞ ‰∏ÄËà¨ÁöÑÊ≠£ÂàôÊõøÊç¢ÔºåÂè™ËÉΩÂØπÂåπÈÖçÁöÑÂ≠ê‰∏≤ÂÅö ... -
正则应用之——逆序环视探索
2011-07-06 17:01 12411¬Ý¬Ý¬Ý¬Ý¬Ý¬Ý ¬ÝÈóÆÈ¢òºïÂá∫ ÂâçÂáݧ©Âú®CSDNËÆ∫ÂùõÈÅáÂà∞ËøôÊÝ∑ ...
相关推荐
在正则表达式的世界里,贪婪与非贪婪模式是两种重要的匹配策略,它们决定了正则表达式在查找匹配时的行为。这两个概念对于任何想要深入理解正则表达式的开发者来说至关重要。 首先,我们来理解一下“贪婪”模式。...
Âú®"Ê≠£ÂàôË°®Ëææºè‚Äî‚ÄîË¥™Â©™ÈùûË¥™Â©™Ê®°Âºè.pdf"ÊñáÊ°£‰∏≠Ôºå‰ΩÝÂ∞܉ºöÊõ¥Ê∑±ÂÖ•Âú∞Â≠¶‰πÝÂà∞¶ljΩïÂú®‰∏çÂêåÊÉÖÂܵ‰∏ãÁŵʥªËøêÁî®Ë¥™Â©™ÂíåÈùûË¥™Â©™Ê®°ÂºèÔºåËøôÂåÖÊ㨉Ω܉∏çÈôê‰∫éÁºñÁ®ã‰∏≠ÁöÑÂÆû‰æãÂàÜÊûêԺ剪•Âèä¶ljΩïÁªìÂêàÂÖ∂‰ªñÊ≠£ÂàôË°®ËææºèÂÖÉÂ≠óÁ¨¶ÂíåÊìç‰ΩúÁ¨¶Êù•Êª°Ë∂≥Êõ¥Â§çÊùÇÁöÑÂåπÈÖçÈúÄʱÇ...
### Ê≠£ÂàôË°®Ëææºè‚Äî‚ÄîÈÄíÂΩíÂåπÈÖç‰∏éÈùûË¥™Â©™ÂåπÈÖç #### ‰∏Ä„ÄÅÈÄíÂΩíÂåπÈÖç Âú®Ê≠£ÂàôË°®Ëææºè‰∏≠ÔºåÈÄíÂΩíÂåπÈÖçÊò؉∏ĉ∏™Èáç˶ÅÁöÑʶÇÂøµÔºåÂÆɉ∏ªË¶ÅÁ∫é§ÑÁêÜÈÇ£‰∫õÂÖ∑Êúâµå•óÁªìÊûÑÁöÑÊï∞ÊçÆÔºå‰æã¶ÇÊï∞Â≠¶Â֨ºè‰∏≠ÁöÑÊã¨Âè∑ÂåπÈÖçÊàñHTMLÊÝáÁ≠æÁöÑÂåπÈÖç„ÄÇ ##### 1.1 µå•ó...
Ë¥™Â©™Ê®°ÂºèÔºàȪòËƧԺ≺öÂ∞ΩÂèØËÉΩ§öÂú∞ÂåπÈÖçÔºåÈùûË¥™Â©™Ê®°ÂºèÂè؉ª•ÈÄöËøáÂú®Êï∞ÈáèËØçÂêéÂäÝ`?`Êù•ÂÆûÁé∞Ôºå¶Ç`[a-zA-Z]{3,5}?`„ÄÇ 2. **Â≠óÁ¨¶ÂåπÈÖç**Ôºö - `[ ]`ÔºöÂ≠óÁ¨¶ÈõÜÔºåÂåπÈÖçÂÖ∂‰∏≠ÁöщªªÊÑè‰∏ĉ∏™Â≠óÁ¨¶„ÄÇ - `[^ ]`ÔºöÂèçÂêëÂ≠óÁ¨¶ÈõÜÔºåÂåπÈÖç‰∏çÂú®Êã¨Âè∑ÂÜÖÁöÑ...
‰æã¶ÇÔºö<H1>Chapter 1 - ‰ªãÁªçÊ≠£ÂàôË°®Ëææºè</H1> Ë¥™Â©™Ê®°ÂºèÂåπÈÖçÁªìÊûúÔºö<H1>Chapter 1 - ‰ªãÁªçÊ≠£ÂàôË°®Ëææºè</H1> ÈùûË¥™Â©™Ôºö¶ÇÊûúÊÇ®Âè™ÈúÄ˶ÅÂåπÈÖçºÄÂßãÂí剪ãÁªçH1 ÊÝáËÆ∞Ôºå‰∏ãÈù¢ÁöÑÈùûË¥™Â©™Ë°®ËææºèÂè™ÂåπÈÖç„ÄÇ 5. ÂÆö‰ΩçÁ¨¶ÔºöÂÆö‰ΩçÁ¨¶ËÉΩ§üÂ∞ÜÊ≠£ÂàôË°®Ëææºè...
ÊúÄÂêéÔºåÊ≠£ÂàôË°®ËææºèËøòÊúâÈùûË¥™Â©™ÂíåË¥™Â©™‰∏§ÁßçÂåπÈÖçÊ®°Âºè„ÄÇȪòËƧÊÉÖÂܵ‰∏ãÔºåÊ≠£ÂàôË°®ËææºèÈááÁî®Ë¥™Â©™ÂåπÈÖçÔºåÂ∞ΩÂèØËÉΩ§öÁöÑÂåπÈÖçÂ≠óÁ¨¶ÔºõËÄåÂä݉∏ä"?",¶Ç"a*"Âèò‰∏∫"a*?"ÔºåÂàô‰ºöÈááÁî®ÈùûË¥™Â©™Ê®°ÂºèÔºåÂ∞ΩÂèØËÉΩÂ∞ëÁöÑÂåπÈÖçÂ≠óÁ¨¶„ÄÇ "Á¨îËÆ∞.txt"‰∏≠ÂèØËÉΩ‰ºöÊ∂µÁõñËøô‰∫õ...
### 正则表达式之道 —— Java中的应用与实践 #### 一、引言 正则表达式是一种强大的文本处理工具,它可以帮助开发者快速高效地完成字符串的匹配、搜索、替换等工作。对于Java开发者而言,掌握正则表达式的用法尤...
Python中的正则表达式是处理文本模式匹配的强大工具,它允许程序员通过简洁的语法来查找、替换或提取字符串中的特定模式。以下是对正则表达式关键概念的详细解释: 1. **简介**: - 正则表达式是用于描述字符串...
Âõõ„ÄÅË¥™Â©™‰∏éÈùûË¥™Â©™ÂåπÈÖç ȪòËƧÊÉÖÂܵ‰∏ãÔºåÊ≠£ÂàôË°®ËææºèÂåπÈÖçÂ∞ΩÂèØËÉΩ§öÁöÑÂ≠óÁ¨¶ÔºåËøôÁß∞‰∏∫Ë¥™Â©™ÂåπÈÖç„ÄÇËã•ÊÉ≥ËÆ©‚Äú.‚ÄùÂåπÈÖçÂ∞ΩÂèØËÉΩÂ∞ëÁöÑÂ≠óÁ¨¶ÔºåÂè؉ª•‰ΩøÁî®ÈùûË¥™Â©™ÈôêÂÆöÁ¨¶`?`Ôºå¶Ç`'.'?`„ÄÇËøôÊÝ∑Ôºå`'..'?`‰ºöÂåπÈÖçÂçï‰∏™ÊàñÈõ∂‰∏™`.`ÂêéÈù¢ÁöÑÂ≠óÁ¨¶„ÄÇ ‰∫î„ÄÅÂÖÉ...
贪婪与懒惰是正则表达式中的一种语法,用于指定某个模式的贪婪或懒惰匹配。例如,使用正则表达式.*可以匹配任何字符的任意次重复。 15. 处理选项 处理选项是正则表达式中的一种语法,用于指定某个模式的处理选项。...
1. 贪婪与懒惰:默认情况下,正则表达式是贪婪的,会尽可能多地匹配字符。使用`?`可以使匹配变得懒惰,仅匹配最少量的字符。 2. 前瞻和后顾:预查可以确保某部分文本前面或后面存在特定的模式,而不会实际包含这部分...
JavaÈÄöËøá`java.util.regex`ÂåÖ‰∏≠Áöщ∏§‰∏™ÊÝ∏ÂøÉÁ±ª‚Äî‚Äî`Pattern`Âíå`Matcher`‚Äî‚ÄîÊèê‰æõ‰∫ÜÂØπÊ≠£ÂàôË°®ËææºèÁöÑÊîØÊåÅ„ÄÇ 1. **Pattern** Á±ªÔºöÂÆÉË¥üË¥£ÁºñËØëÊ≠£ÂàôË°®ËææºèÂ≠óÁ¨¶‰∏≤‰∏∫Ê®°ÂºèÂØπ˱°„ÄÇËøô‰∏™Ê®°ÂºèÂØπ˱°Âè؉ª•Ë¢´Áî®Êù•Âàõª∫§ö‰∏™`Matcher`ÂÆû‰æãÔºå...
- 使用非贪婪匹配:默认情况下,正则表达式是贪婪的,会匹配尽可能多的字符。使用`?`符号可以设置为非贪婪匹配,只匹配最少的字符。 - 注意性能开销:尽管正则表达式强大,但过度使用可能导致性能下降,尤其是对大...
在计算机科学中,正则表达式被用来描述一组字符串——所有符合某个模式的字符串集合。 #### 二、正则表达式的语言特性 正则表达式本质上是一门“小语言”,它由一系列特殊字符和普通字符组成,用于定义字符串模式...
### 正则表达式的基础语法 #### 概述 正则表达式是一种强大的文本处理工具,可以在字符串中执行复杂的搜索和替换操作。它提供了一种描述字符串模式的方式,这种模式可以用来检查一个字符串是否符合某种特定类型的...
Âú®ÁºñÁ®ãÈ¢ÜÂüüÔºåC#ËØ≠Ë®ÄÊèê‰æõ‰∫܉∏ÄÁßçº∫§ßÁöÑÂ∑•ÂÖ∑‚Äî‚ÄîÊ≠£ÂàôË°®ËææºèÔºåÁ∫é§ÑÁêÜÂ≠óÁ¨¶‰∏≤ÂíåÈ™åËØÅÊï∞ÊçÆÊݺºè„ÄÇÊ≠£ÂàôË°®ËææºèÊò؉∏ÄÁßçÊ®°ÂºèÂåπÈÖçËØ≠Ë®ÄÔºåÂÆÉËÉΩ§üÂ∏ÆÂä©Êà뉪¨ÊúâÊïàÂú∞Ê£ÄÊü•„ÄÅÊü•Êâæ„ÄÅÊõøÊç¢ÂíåÊèêÂèñÊñáÊú¨„ÄÇÂú®C#‰∏≠ÔºåÊà뉪¨Âè؉ª•‰ΩøÁî®System.Text....
元字符是正则表达式中最基本的概念之一,它们具有特殊的含义,用来描述特定的模式。 - **`.`**:匹配任何单个字符(除了换行符)。 - **`\b`**:匹配单词边界,即单词的开始或结束的位置。 - **`^`**:匹配字符串的...
ÔºâÔºå‰ΩøÂÖ∂ÂèòÊàêÈùûË¥™Â©™Ê®°ÂºèÔºåÂ∞ΩÂèØËÉΩÂ∞ëÂú∞ÂåπÈÖçÂ≠óÁ¨¶„Äljæã¶ÇÔºå`/<.*?>/g`ÂèØËÉΩÂåπÈÖçÊ雷∏™HTMLÊÝáÁ≠æÔºå‰ΩÜ`/<.*??>/g`Â虉ºöÂåπÈÖçÊÝáÁ≠æÂÜÖÈÉ®ÁöÑÂÜÖÂÆπ„ÄÇ Âõõ„ÄÅÂÆûÁî®Â∑•ÂÖ∑ 1. JavaScriptÁöÑ`String`ÂØπ˱°Êèê‰æõ‰∫ÜÂæà§ö‰∏éÊ≠£ÂàôË°®ËææºèÁõ∏ÂÖ≥ÁöÑÂÜÖÁΩÆÊñπÊ≥ïÔºå...
1. 匹配算法:正则表达式引擎通常使用两种匹配算法——DFA(确定有限状态自动机)和NFA(非确定有限状态自动机)。DFA效率高,但不支持所有正则表达式特性;NFA支持更多特性,但可能需要更多步骤。 2. 编译与解析:...