
层次聚类(hierarchical clustering)可在不同层次上对数据集进行划分,形成树状的聚类结构。AggregativeClustering是一种常用的层次聚类算法。
其原理是:最初将每个对象看成一个簇,然后将这些簇根据某种规则被一步步合并,就这样不断合并直到达到预设的簇类个数。这里的关键在于:如何计算聚类簇之间的距离?
由于每个簇就是一个集合,因此需要给出集合之间的距离。给定聚类簇Ci,CjCi,Cj,有如下三种距离:
- 最小距离:
dmin(Ci,Cj)=minx⃗ i∈Ci,x⃗ j∈Cjdistance(x⃗ i,x⃗ j)dmin(Ci,Cj)=minx→i∈Ci,x→j∈Cjdistance(x→i,x→j)它是两个簇的样本对之间距离的最小值。
- 最大距离:
dmax(Ci,Cj)=maxx⃗ i∈Ci,x⃗ j∈Cjdistance(x⃗ i,x⃗ j)dmax(Ci,Cj)=maxx→i∈Ci,x→j∈Cjdistance(x→i,x→j)它是两个簇的样本对之间距离的最大值。
- 平均距离:
davg(Ci,Cj)=1|Ci||Cj|∑x⃗ i∈Ci∑x⃗ j∈Cjdistance(x⃗ i,x⃗ j)davg(Ci,Cj)=1|Ci||Cj|∑x→i∈Ci∑x→j∈Cjdistance(x→i,x→j)它是两个簇的样本对之间距离的平均值。
当该算法的聚类簇采用dmindmin时,称为单链接single-linkage算法,当该算法的聚类簇采用dmaxdmax时,称为单链接complete-linkage算法,当该算法的聚类簇采用davgdavg时,称为单链接average-linkage算法。
下面给出算法:
- 输入:
- 数据集D=D={x⃗ 1,x⃗ 2,...,x⃗ Nx→1,x→2,...,x→N}
- 聚类簇距离度量函数
- 聚类簇数量KK
- 输出:簇划分C=C={C1,C2,...,CKC1,C2,...,CK}
-
算法步骤如下:
- 初始化:将每个样本都作为一个簇
Ci=[x⃗ i],i=1,2,...,NCi=[x→i],i=1,2,...,N
- 迭代:终止条件为聚类簇的数量为K。迭代过程如下:
- 计算聚类簇之间的距离,找出距离最近的两个簇,将这两个簇合并。
- 计算聚类簇之间的距离,找出距离最近的两个簇,将这两个簇合并。
Python实战AgglomerativeClustering是scikit-learn提供的层级聚类算法模型,其原型为:
- 初始化:将每个样本都作为一个簇
class sklearn.cluster.AgglomerativeClustering(n_clusters=2, affinity=’euclidean’, memory=None, connectivity=None, compute_full_tree=’auto’, linkage=’ward’, pooling_func=<function mean>)- 1
参数
- n_clusters:一个整数,指定分类簇的数量
- connectivity:一个数组或者可调用对象或者None,用于指定连接矩阵
- affinity:一个字符串或者可调用对象,用于计算距离。可以为:’euclidean’,’l1’,’l2’,’mantattan’,’cosine’,’precomputed’,如果linkage=’ward’,则affinity必须为’euclidean’
- memory:用于缓存输出的结果,默认为不缓存
- n_components:在 v-0.18中移除
- compute_full_tree:通常当训练了n_clusters后,训练过程就会停止,但是如果compute_full_tree=True,则会继续训练从而生成一颗完整的树
- linkage:一个字符串,用于指定链接算法
- ‘ward’:单链接single-linkage,采用dmindmin
- ‘complete’:全链接complete-linkage算法,采用dmaxdmax
- ‘average’:均连接average-linkage算法,采用davgdavg
- pooling_func:一个可调用对象,它的输入是一组特征的值,输出是一个数
属性
- labels:每个样本的簇标记
- n_leaves_:分层树的叶节点数量
- n_components:连接图中连通分量的估计值
- children:一个数组,给出了每个非节点数量
方法
- fit(X[,y]):训练样本
- fit_predict(X[,y]):训练模型并预测每个样本的簇标记
from sklearn import cluster
from sklearn.metrics import adjusted_rand_score
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
"""
产生数据
"""
def create_data(centers,num=100,std=0.7):
X,labels_true = make_blobs(n_samples=num,centers=centers, cluster_std=std)
return X,labels_true
"""
数据作图
"""
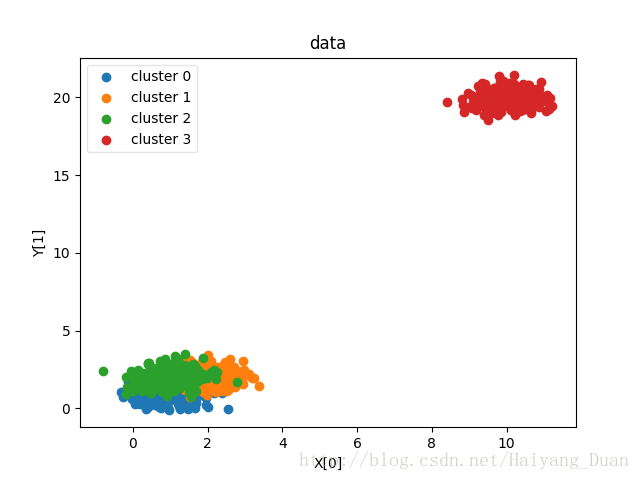
def plot_data(*data):
X,labels_true=data
labels=np.unique(labels_true)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
colors='rgbycm'
for i,label in enumerate(labels):
position=labels_true==label
ax.scatter(X[position,0],X[position,1],label="cluster %d"%label),
color=colors[i%len(colors)]
ax.legend(loc="best",framealpha=0.5)
ax.set_xlabel("X[0]")
ax.set_ylabel("Y[1]")
ax.set_title("data")
plt.show()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
这里写代码片
"""
测试函数
"""
def test_AgglomerativeClustering(*data):
X,labels_true=data
clst=cluster.AgglomerativeClustering()
predicted_labels=clst.fit_predict(X)
print("ARI:%s"% adjusted_rand_score(labels_true, predicted_labels))
"""
考察簇的数量对于聚类效果的影响
"""
def test_AgglomerativeClustering_nclusters(*data):
X,labels_true=data
nums=range(1,50)
ARIS=[]
for num in nums:
clst=cluster.AgglomerativeClustering(n_clusters=num)
predicted_lables=clst.fit_predict(X)
ARIS.append(adjusted_rand_score(labels_true, predicted_lables))
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
ax.plot(nums,ARIS,marker="+")
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
fig.suptitle("AgglomerativeClustering")
plt.show()
"""
考察链接方式对聚类结果的影响
"""
def test_agglomerativeClustering_linkage(*data):
X,labels_true=data
nums=range(1,50)
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
linkages=['ward','complete','average']
markers="+o*"
for i,linkage in enumerate(linkages):
ARIs=[]
for num in nums:
clst=cluster.AgglomerativeClustering(n_clusters=num,linkage=linkage)
predicted_labels=clst.fit_predict(X)
ARIs.append(adjusted_rand_score(labels_true, predicted_labels))
ax.plot(nums,ARIs,marker=markers[i],label="linkage:%s"%linkage)
ax.set_xlabel("n_clusters")
ax.set_ylabel("ARI")
ax.legend(loc="best")
fig.suptitle("AgglomerativeClustering")
plt.show()
centers=[[1,1],[2,2],[1,2],[10,20]]
X,labels_true=create_data(centers, 1000, 0.5)
test_AgglomerativeClustering(X,labels_true)
plot_data(X,labels_true)
test_AgglomerativeClustering_nclusters(X,labels_true)
test_agglomerativeClustering_linkage(X,labels_true)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
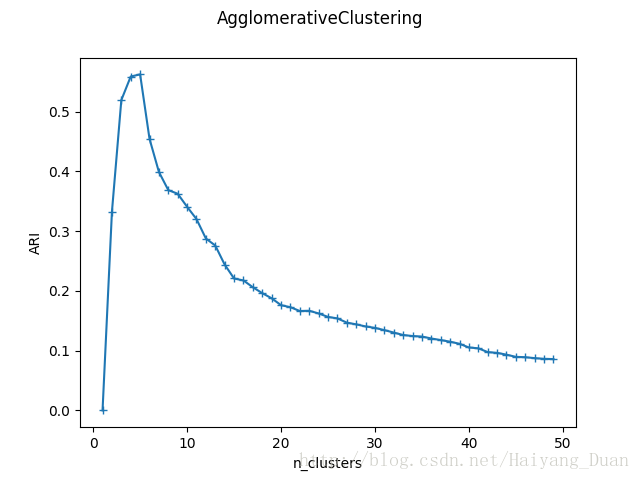
可以看到当n_clusters=4时,ARI指数最大,因为确实是从四个中心点产生的四个簇。
- 1
- 2
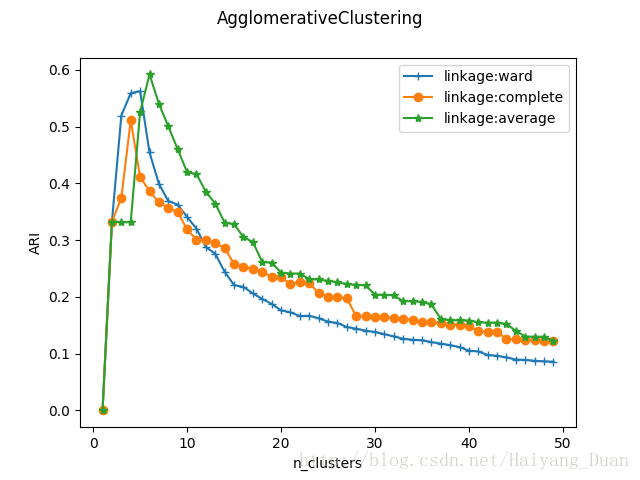
可以看到,三种链接方式随分类簇的数量的总体趋势相差无几。但是单链接方式ward的峰值最大


相关推荐
在Python机器学习领域,恶意代码聚类分析是一种重要的技术,用于识别、分类和理解大量复杂的恶意软件行为。这种分析方法可以有效地帮助安全专家们发现潜在的威胁模式,预测未来的攻击,并提升网络安全防御策略。以下...
在IT领域,尤其是在数据科学和机器学习中,层次聚类(Hierarchical Clustering)是一种广泛应用的无监督学习方法,用于将数据集中的对象组织成树状结构,即所谓的“聚类树”或“ dendrogram”。这个CS298项目的主题...
《聚类与推荐算法》是机器学习领域中的两个重要主题,它们在数据分析、人工智能和互联网行业中扮演着关键角色。Python作为最受欢迎的编程语言之一,因其简洁的语法和丰富的科学计算库,成为实现这些算法的理想工具。...
在数据挖掘和机器学习领域,层次聚类通常用于发现数据之间的内在关系,尤其适用于发现不同级别的聚类结构。这种算法分为两种类型:凝聚型(Agglomerative)和分裂型(Divisive)。在这个Python实现中,我们可能主要...
在数据分析和机器学习领域,聚类分析是一种无监督学习方法,用于发现数据集中的自然群体或类别,无需预先知道目标变量。在这个主题中,我们将深入探讨Python中的聚类分析,特别是层次化聚类(Hierarchical ...
在数据分析和机器学习领域,聚类算法是一种无监督学习方法,用于发现数据集中的内在结构,将相似的数据分组到一起。本主题将深入探讨两种常见的聚类算法:层次聚类(Hierarchical Clustering)和K-means聚类。它们在...
"rearndf"可能是一个拼写错误,正确的可能是"random forest",这是一种机器学习算法,但在标签中,它可能是对某种特定实现或数据集的引用。让我们深入探讨Python中的聚类算法以及可能与“python-d”相关的概念。 1....
在数据挖掘和机器学习领域,聚类是一种无监督学习方法,主要用于发现数据中的结构和模式,而无需预先指定类别。本篇将深入探讨两种常见的聚类算法:K-means聚类和层次聚类,并基于提供的实验代码进行解析。 一、K-...
在数据科学领域,聚类分析是一种无监督学习方法,用于发现数据集中的自然群体或类别。...通过这个压缩包中的源代码,你可以深入理解每种算法的实现细节,这对于提升数据分析和机器学习技能大有裨益。
### Python人工智能课程知识点提炼——聚类 #### 一、聚类概述 在机器学习与深度学习领域中,聚类作为一种重要的无监督学习方法,被广泛应用于数据挖掘、图像分析、生物信息学等多个领域。聚类的目标是将大量未知...
在数据分析和机器学习领域,K-Means是一种广泛使用的无监督学习算法,它主要用于执行聚类分析,即将数据集中的样本点自动分组到不同的类别中。K-Means算法的核心思想是通过迭代过程,不断调整样本点的所属类别,以...
然而,描述中提到的“机器学习的五种聚类算法包括训练数据,基于python实现”,可能是想强调在某些特定场景下,可能会使用带有标签的数据来初始化或优化聚类过程。以下是对几种常见的聚类算法的详细介绍,以及它们在...
这些Python脚本提供了实现这些步骤的基础,使得数据科学家和机器学习工程师能够更好地理解和操作聚类分析。通过深入理解这些概念和算法,我们可以更有效地探索数据的内在结构,发现潜在的模式,并为后续的分析和决策...
凝聚层次聚类(Agglomerative Clustering)是一种有监督的机器学习方法,主要应用于数据集的无标签数据分组,即聚类问题。它通过构建一个树状结构,称为谱系图或 dendrogram,来逐步合并相似的数据点,从而形成不同...
Python在数据处理、科学计算、机器学习等领域有着广泛的库支持,如NumPy、Pandas、Scikit-learn等,这些库提供了丰富的数据结构和高效的算法实现,极大地方便了聚类分析的实施。 文章提到的博客数据集聚类应用,...
在Python编程语言中,数据分析和机器学习领域广泛使用各种库来简化复杂的任务,其中包括聚类算法。本篇文章将深入探讨如何使用Python中的包进行聚类分析,主要关注层次聚类、K-Means聚类以及基于密度的聚类方法。 ...
本项目“基于Python数据可视化的机器学习中聚类算法的研究”聚焦于如何利用这些工具进行机器学习中的聚类算法研究。 聚类算法是无监督学习的一种,主要目的是将数据集中的样本分成不同的组,即“簇”,使得同一簇内...
4. **聚类算法**:在Python中,Scikit-learn库提供了多种聚类算法,如K-Means、DBSCAN(基于密度的聚类)、Agglomerative Clustering(层次聚类)等。K-Means是最常见的,它试图找到k个中心,使得每个样本到最近中心...
1. **Scikit-learn**: Python中最常用的机器学习库之一,提供了多种聚类算法,如K-Means、DBSCAN、Agglomerative Clustering等。这些算法不仅高效,而且易于使用。 2. **OpenCV**: 除了图像处理,OpenCV也支持一些...