
转:http://tianzt.blog.51cto.com/459544/171759
是一个或多个数据文件的集合,所有的数据对象都存放在指定的表空间中,但主要存放的是表, 所以称作表空间。
当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区。表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表。
1、表的大小超过2GB。
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能。
范围分区将数据基于范围映射到每一个分区,这个范围是你在创建分区时指定的分区键决定的。这种分区方式是最为常用的,并且分区键经常采用日期。举个例子:你可能会将销售数据按照月份进行分区。
(
CUSTOMER_ID NUMBER NOT NULL PRIMARY KEY,
FIRST_NAME VARCHAR2(30) NOT NULL,
LAST_NAME VARCHAR2(30) NOT NULL,
PHONE VARCHAR2(15) NOT NULL,
EMAIL VARCHAR2(80),
STATUS CHAR(1)
)
PARTITION BY RANGE (CUSTOMER_ID)
(
PARTITION CUS_PART1 VALUES LESS THAN (100000) TABLESPACE CUS_TS01,
PARTITION CUS_PART2 VALUES LESS THAN (200000) TABLESPACE CUS_TS02
)
(
ORDER_ID NUMBER(7) NOT NULL,
ORDER_DATE DATE,
TOTAL_AMOUNT NUMBER,
CUSTOTMER_ID NUMBER(7),
PAID CHAR(1)
)
PARTITION BY RANGE (ORDER_DATE)
(
(
idd INT PRIMARY KEY ,
iNAME VARCHAR(10),
grade INT
)
PARTITION BY RANGE (grade)
(
PARTITION part1 VALUES LESS THEN (1000) TABLESPACE Part1_tb,
PARTITION part2 VALUES LESS THEN (MAXVALUE) TABLESPACE Part2_tb
);
(
PROBLEM_ID NUMBER(7) NOT NULL PRIMARY KEY,
DESCRIPTION VARCHAR2(2000),
CUSTOMER_ID NUMBER(7) NOT NULL,
DATE_ENTERED DATE NOT NULL,
STATUS VARCHAR2(20)
)
PARTITION BY LIST (STATUS)
(
PARTITION PROB_ACTIVE VALUES ('ACTIVE') TABLESPACE PROB_TS01,
PARTITION PROB_INACTIVE VALUES ('INACTIVE') TABLESPACE PROB_TS02
(
id INT PRIMARY KEY ,
name VARCHAR (20),
area VARCHAR (10)
)
PARTITION BY LIST (area)
(
PARTITION part1 VALUES ('guangdong','beijing') TABLESPACE Part1_tb,
PARTITION part2 VALUES ('shanghai','nanjing') TABLESPACE Part2_tb
);
这类分区是在列值上使用散列算法,以确定将行放入哪个分区中。当列的值没有合适的条件时,建议使用散列分区。
(
COL NUMBER(8),
INF VARCHAR2(100)
)
PARTITION BY HASH (COL)
(
PARTITION PART01 TABLESPACE HASH_TS01,
PARTITION PART02 TABLESPACE HASH_TS02,
PARTITION PART03 TABLESPACE HASH_TS03
)
(
empno NUMBER (4),
ename VARCHAR2 (30),
sal NUMBER
)
PARTITION BY HASH (empno) PARTITIONS 8
STORE IN (emp1,emp2,emp3,emp4,emp5,emp6,emp7,emp8);
这种分区是基于范围分区和列表分区,表首先按某列进行范围分区,然后再按某列进行列表分区,分区之中的分区被称为子分区。
(
(
SUBPARTITION P1SUB1 VALUES ('ACTIVE') TABLESPACE rptfact2009,
SUBPARTITION P1SUB2 VALUES ('INACTIVE') TABLESPACE rptfact2009
),
PARTITION P2 VALUES LESS THAN (TO_DATE('2003-03-01','YYYY-MM-DD')) TABLESPACE rptfact2009
(
SUBPARTITION P2SUB1 VALUES ('ACTIVE') TABLESPACE rptfact2009,
SUBPARTITION P2SUB2 VALUES ('INACTIVE') TABLESPACE rptfact2009
)
)
(
transaction_id number primary key,
item_id number(8) not null,
item_description varchar2(300),
transaction_date date
)
partition by range(transaction_date)subpartition by hash(transaction_id) subpartitions 3 store in (dinya_space01,dinya_space02,dinya_space03)
(
partition part_01 values less than(to_date(‘2006-01-01’,’yyyy-mm-dd’)),
partition part_02 values less than(to_date(‘2010-01-01’,’yyyy-mm-dd’)),
partition part_03 values less than(maxvalue)
);
一、添加分区
以下代码给SALES表添加了一个P3分区
以下代码删除了P3表分区:
截断某个分区是指删除某个分区中的数据,并不会删除分区,也不会删除其它分区中的数据。当表中即使只有一个分区时,也可以截断该分区。通过以下代码截断分区:
合并分区是将相邻的分区合并成一个分区,结果分区将采用较高分区的界限,值得注意的是,不能将分区合并到界限较低的分区。以下代码实现了P1 P2分区的合并:
拆分分区将一个分区拆分两个新分区,拆分后原来分区不再存在。注意不能对HASH类型的分区进行拆分。
结合分区是将散列分区中的数据接合到其它分区中,当散列分区中的数据比较大时,可以增加散列分区,然后进行接合,值得注意的是,接合分区只能用于散列分区中。通过以下代码进行接合分区:
以下代码将P21更改为P2
跨分区查询
***********************************************
转:http://blog.csdn.net/tianlesoftware/article/details/4717318
一. 分区表理论知识
Oracle提供了分区技术以支持VLDB(Very Large DataBase)。分区表通过对分区列的判断,把分区列不同的记录,放到不同的分区中。分区完全对应用透明。
Oracle的分区表可以包括多个分区,每个分区都是一个独立的段(SEGMENT),可以存放到不同的表空间中。查询时可以通过查询表来访问各个分区中的数据,也可以通过在查询时直接指定分区的方法来进行查询。
When to Partition a Table什么时候需要分区表,官网的2个建议如下:
(1)Tables greater than 2GB should always be considered for partitioning.
(2)Tables containing historical data, in which new data is added into the newest partition. A typical example is a historical table where only the current month's data is updatable and the other 11 months are read only.
在oracle 10g中最多支持:1024k-1个分区:
Tables can be partitioned into up to 1024K-1 separate partitions
联机文档上有关分区表和索引的说明:
Partitioned Tables and Indexes
http://download.oracle.com/docs/cd/B19306_01/server.102/b14220/partconc.htm#sthref2604
分区提供以下优点:
(1)由于将数据分散到各个分区中,减少了数据损坏的可能性;
(2)可以对单独的分区进行备份和恢复;
(3)可以将分区映射到不同的物理磁盘上,来分散IO;
(4)提高可管理性、可用性和性能。
Oracle 10g提供了以下几种分区类型:
(1)范围分区(range);
(2)哈希分区(hash);
(3)列表分区(list);
(4)范围-哈希复合分区(range-hash);
(5)范围-列表复合分区(range-list)。
Range分区:
Range分区是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中。
如按照时间划分,2010年1月的数据放到a分区,2月的数据放到b分区,在创建的时候,需要指定基于的列,以及分区的范围值。
在按时间分区时,如果某些记录暂无法预测范围,可以创建maxvalue分区,所有不在指定范围内的记录都会被存储到maxvalue所在分区中。
如:
create table pdba (id number, time date) partition by range (time)
(
partition p1 values less than (to_date('2010-10-1', 'yyyy-mm-dd')),
partition p2 values less than (to_date('2010-11-1', 'yyyy-mm-dd')),
partition p3 values less than (to_date('2010-12-1', 'yyyy-mm-dd')),
partition p4 values less than (maxvalue)
)
Hash分区:
对于那些无法有效划分范围的表,可以使用hash分区,这样对于提高性能还是会有一定的帮助。hash分区会将表中的数据平均分配到你指定的几个分区中,列所在分区是依据分区列的hash值自动分配,因此你并不能控制也不知道哪条记录会被放到哪个分区中,hash分区也可以支持多个依赖列。
如:
create table test
(
transaction_id number primary key,
item_id number(8) not null
)
partition by hash(transaction_id)
(
partition part_01 tablespace tablespace01,
partition part_02 tablespace tablespace02,
partition part_03 tablespace tablespace03
);
在这里,我们指定了每个分区的表空间。
List分区:
List分区也需要指定列的值,其分区值必须明确指定,该分区列只能有一个,不能像range或者hash分区那样同时指定多个列做为分区依赖列,但它的单个分区对应值可以是多个。
在分区时必须确定分区列可能存在的值,一旦插入的列值不在分区范围内,则插入/更新就会失败,因此通常建议使用list分区时,要创建一个default分区存储那些不在指定范围内的记录,类似range分区中的maxvalue分区。
在根据某字段,如城市代码分区时,可以指定default,把非分区规则的数据,全部放到这个default分区。
如:
create table custaddr
(
id varchar2(15 byte) not null,
areacode varchar2(4 byte)
)
partition by list (areacode)
( partition t_list025 values ('025'),
partition t_list372 values ('372') ,
partition t_list510 values ('510'),
partition p_other values (default)
)
组合分区:
如果某表按照某列分区之后,仍然较大,或者是一些其它的需求,还可以通过分区内再建子分区的方式将分区再分区,即组合分区的方式。
组合分区呢在10g中有两种:range-hash,range-list。注意顺序,根分区只能是range分区,子分区可以是hash分区或list分区。
如:
create table test
(
transaction_id number primary key,
transaction_date date
)
partition by range(transaction_date) subpartition by hash(transaction_id)
subpartitions 3 store in (tablespace01,tablespace02,tablespace03)
(
partition part_01 values less than(to_date(’2009-01-01’,’yyyy-mm-dd’)),
partition part_02 values less than(to_date(’2010-01-01’,’yyyy-mm-dd’)),
partition part_03 values less than(maxvalue)
);
create table emp_sub_template (deptno number, empname varchar(32), grade number)
partition by range(deptno) subpartition by hash(empname)
subpartition template
(subpartition a tablespace ts1,
subpartition b tablespace ts2,
subpartition c tablespace ts3,
subpartition d tablespace ts4
)
(partition p1 values less than (1000),
partition p2 values less than (2000),
partition p3 values less than (maxvalue)
);
create table quarterly_regional_sales
(deptno number, item_no varchar2(20),
txn_date date, txn_amount number, state varchar2(2))
tablespace ts4
partition by range (txn_date)
subpartition by list (state)
(partition q1_1999 values less than (to_date('1-apr-1999','dd-mon-yyyy'))
(subpartition q1_1999_northwest values ('or', 'wa'),
subpartition q1_1999_southwest values ('az', 'ut', 'nm'),
subpartition q1_1999_northeast values ('ny', 'vm', 'nj'),
subpartition q1_1999_southeast values ('fl', 'ga'),
subpartition q1_1999_northcentral values ('sd', 'wi'),
subpartition q1_1999_southcentral values ('ok', 'tx')
),
partition q2_1999 values less than ( to_date('1-jul-1999','dd-mon-yyyy'))
(subpartition q2_1999_northwest values ('or', 'wa'),
subpartition q2_1999_southwest values ('az', 'ut', 'nm'),
subpartition q2_1999_northeast values ('ny', 'vm', 'nj'),
subpartition q2_1999_southeast values ('fl', 'ga'),
subpartition q2_1999_northcentral values ('sd', 'wi'),
subpartition q2_1999_southcentral values ('ok', 'tx')
),
partition q3_1999 values less than (to_date('1-oct-1999','dd-mon-yyyy'))
(subpartition q3_1999_northwest values ('or', 'wa'),
subpartition q3_1999_southwest values ('az', 'ut', 'nm'),
subpartition q3_1999_northeast values ('ny', 'vm', 'nj'),
subpartition q3_1999_southeast values ('fl', 'ga'),
subpartition q3_1999_northcentral values ('sd', 'wi'),
subpartition q3_1999_southcentral values ('ok', 'tx')
),
partition q4_1999 values less than ( to_date('1-jan-2000','dd-mon-yyyy'))
(subpartition q4_1999_northwest values ('or', 'wa'),
subpartition q4_1999_southwest values ('az', 'ut', 'nm'),
subpartition q4_1999_northeast values ('ny', 'vm', 'nj'),
subpartition q4_1999_southeast values ('fl', 'ga'),
subpartition q4_1999_northcentral values ('sd', 'wi'),
subpartition q4_1999_southcentral values ('ok', 'tx')
)
);
在Oracle 11g中,组合分区功能这块有所增强,又增加了range-range,list-range,
list-list,list-hash,并且 11g里面还支持Interval分区和虚拟列分区。
这块可以参考Blog:
Oracle 11g 新特性简介
http://blog.csdn.net/tianlesoftware/archive/2010/01/06/5134819.aspx
分区表 之 Interval分区 和 虚拟列 按星期分区表
http://blog.csdn.net/tianlesoftware/archive/2010/06/10/5662337.aspx
二. 普通表转分区表方法
将普通表转换成分区表有4种方法:
1. Export/import method
2. Insert with a subquery method
3. Partition exchange method
4. DBMS_REDEFINITION
具体参考:
How to Partition a Non-partitioned Table [ID 1070693.6]
http://blog.csdn.net/tianlesoftware/archive/2011/03/02/6218704.aspx
逻辑导出导入这里就不做说明,我们看看其他三种方法。
2.1 插入: Insert with a subquery method
这种方法就是使用insert 来实现。 当然在创建分区表的时候可以一起插入数据,也可以创建好后在insert 进去。 这种方法采用DDL语句,不产生UNDO,只产生少量REDO,建表完成后数据已经在分布到各个分区中。
SQL> select count(*) from dba;
COUNT(*)
----------
2713235
SQL> alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
会话已更改。
SQL> select time_fee from dba where rownum<5;
TIME_FEE
-------------------
2011-02-17 19:29:09
2011-02-17 19:29:15
2011-02-17 19:29:18
2011-02-17 19:29:20
SQL>
2.1.1 Oracle 11g的Interval
在11g里的Interval创建,这种方法对没有写全的分区会自动创建。 比如我这里只写了1月日期,如果插入的数据有其他月份的,会自动生成对应的分区。
/* Formatted on 2011/03/02 15:41:09 (QP5 v5.115.810.9015) */
CREATE TABLE intervaldave
PARTITION BY RANGE (time_fee)
INTERVAL ( NUMTOYMINTERVAL (1, 'MONTH') )
(PARTITION part1
VALUES LESS THAN (TO_DATE ('01/12/2010', 'MM/DD/YYYY')))
AS
SELECT ID, TIME_FEE FROM DAVE;
SQL> select table_name,partition_name from user_tab_partitions where table_name='INTERVALDAVE';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
INTERVALDAVE PART1
INTERVALDAVE SYS_P24
INTERVALDAVE SYS_P25
INTERVALDAVE SYS_P26
INTERVALDAVE SYS_P33
INTERVALDAVE SYS_P27
INTERVALDAVE SYS_P28
2.1.2 Oracle 10g 版本
在10g里面,我需要写全所有的分区。
sql> create table pdba (id, time) partition by range (time)
2 (partition p1 values less than (to_date('2010-10-1', 'yyyy-mm-dd')),
3 partition p2 values less than (to_date('2010-11-1', 'yyyy-mm-dd')),
4 partition p3 values less than (to_date('2010-12-1', 'yyyy-mm-dd')),
5 partition p4 values less than (maxvalue))
6 as select id, time_fee from dba;
表已创建。
SQL> select table_name,partition_name from user_tab_partitions where table_name='PDBA';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
PDBA P1
PDBA P2
PDBA P3
PDBA P4
sql> select count(*) from pdba partition (p1);
count(*)
----------
1718285
sql> select count(*) from pdba partition (p2);
count(*)
----------
183667
sql> select count(*) from pdba partition (p3);
count(*)
----------
188701
sql> select count(*) from pdba partition (p4);
count(*)
----------
622582
sql>
现在分区表已经建好了,但是表名不一样,需要用rename对表重命名一下:
SQL> rename dba to dba_old;
表已重命名。
SQL> rename pdba to dba;
表已重命名。
SQL> select table_name,partition_name from user_tab_partitions where table_name='DBA';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
DBA P1
DBA P2
DBA P3
DBA P4
2.2 . 交换分区:Partition exchange method
这种方法只是对数据字典中分区和表的定义进行了修改,没有数据的修改或复制,效率最高。适用于包含大数据量的表转到分区表中的一个分区的操作。尽量在闲时进行操作。
交换分区的操作步骤如下:
1. 创建分区表,假设有2个分区,P1,P2.
2. 创建表A存放P1规则的数据。
3. 创建表B 存放P2规则的数据。
4. 用表A 和P1 分区交换。 把表A的数据放到到P1分区
5. 用表B 和p2 分区交换。 把表B的数据存放到P2分区。
创建分区表:
sql> create table p_dba
2 (id number,time date)
3 partition by range(time)
4 (
5 partition p1 values less than (to_date('2010-09-1', 'yyyy-mm-dd')),
6 partition p2 values less than (to_date('2010-11-1', 'yyyy-mm-dd'))
7 );
表已创建。
注意:我这里只创建了2个分区,没有创建存放其他数据的分区。
创建2个分别对应分区的基表:
SQL> CREATE TABLE dba_p1 as SELECT id,time_fee FROM dba_old WHERE time_fee<TO_DATE('2010-09-1', 'YYYY-MM-DD');
表已创建。
SQL> CREATE TABLE dba_p2 as SELECT id,time_fee FROM dba_old WHERE time_fee<TO_DATE('2010-11-1', 'YYYY-MM-DD') and time_fee>TO_DATE('2010-09-1', 'YYYY-MM-DD');
表已创建。
SQL> select count(*) from dba_p1;
COUNT(*)
----------
1536020
SQL> select count(*) from dba_p2;
COUNT(*)
----------
365932
SQL>
讲2个基表与2个分区进行交换:
SQL> alter table p_dba exchange partition p1 with table dba_p1;
表已更改。
SQL> alter table p_dba exchange partition p2 with table dba_p2;
表已更改。
查询2个分区:
SQL> select count(*) from p_dba partition(p1);
COUNT(*)
----------
1536020
SQL> select count(*) from p_dba partition(p2);
COUNT(*)
----------
365932
注意:数据和之前的基表一致。
查询原来的2个基表:
SQL> select count(*) from dba_p2;
COUNT(*)
----------
0
SQL> select count(*) from dba_p1;
COUNT(*)
----------
0
注意: 2个基表的数据变成成0。
在这里我们看一个问题,一般情况下,我们在创建分区表的时候,都会有一个其他分区,用来存放不匹配分区规则的数据。 在这个例子中,我只创建了2个分区,没有创建maxvalue分区。 现在我来插入一条不满足规则的数据,看结果:
SQL> insert into p_dba values(999999,to_date('2012-12-29','yyyy-mm-dd'));
insert into p_dba values(999999,to_date('2012-12-29','yyyy-mm-dd'))
*
第 1 行出现错误:
ORA-14400: 插入的分区关键字未映射到任何分区
SQL> insert into p_dba values(999999,to_date('2009-12-29','yyyy-mm-dd'));
已创建 1 行。
SQL> select * from p_dba where id=999999;
ID TIME
---------- --------------
999999 29-12月-09
SQL> alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';
会话已更改。
SQL> select * from p_dba where id=999999;
ID TIME
---------- -------------------
999999 2009-12-29 00:00:00
SQL>
通过这个测试可以清楚,如果插入的数据不满足分区规则,会报ORA-14400错误。
2.3 . 使用在线重定义:DBMS_REDEFINITION
在线重定义能保证数据的一致性,在大部分时间内,表都可以正常进行DML操作。只在切换的瞬间锁表,具有很高的可用性。这种方法具有很强的灵活性,对各种不同的需要都能满足。而且,可以在切换前进行相应的授权并建立各种约束,可以做到切换完成后不再需要任何额外的管理操作。
关于DBMS_REDEFINITION的介绍,参考官方连接:
http://download.oracle.com/docs/cd/B19306_01/appdev.102/b14258/d_redefi.htm#CBBFDJBC
关于用在线重定义创建分区表,参考:
How To Partition Existing Table Using DBMS_Redefinition [ID 472449.1]
http://blog.csdn.net/tianlesoftware/archive/2011/03/02/6218693.aspx
这个功能只在9.2.0.4以后的版本才有,在线重定义表具有以下功能:
(1)修改表的存储参数;
(2)将表转移到其他表空间;
(3)增加并行查询选项;
(4)增加或删除分区;
(5)重建表以减少碎片;
(6)将堆表改为索引组织表或相反的操作;
(7)增加或删除一个列。
使用在线重定义的一些限制条件:
(1) There must be enough space to hold two copies of the table.
(2) Primary key columns cannot be modified.
(3) Tables must have primary keys.
(4) Redefinition must be done within the same schema.
(5) New columns added cannot be made NOT NULL until after the redefinition operation.
(6) Tables cannot contain LONGs, BFILEs or User Defined Types.
(7) Clustered tables cannot be redefined.
(8) Tables in the SYS or SYSTEM schema cannot be redefined.
(9) Tables with materialized view logs or materialized views defined on them cannot be redefined.
(10) Horizontal sub setting of data cannot be performed during the redefinition.
在Oracle 10.2.0.4和11.1.0.7 版本下,在线重定义可能会遇到如下bug:
Bug 7007594 - ORA-600 [12261]
http://blog.csdn.net/tianlesoftware/archive/2011/03/02/6218681.aspx
在线重定义的大致操作流程如下:
(1)创建基础表A,如果存在,就不需要操作。
(2)创建临时的分区表B。
(3)开始重定义,将基表A的数据导入临时分区表B。
(4)结束重定义,此时在DB的 Name Directory里,已经将2个表进行了交换。即此时基表A成了分区表,我们创建的临时分区表B 成了普通表。 此时我们可以删除我们创建的临时表B。它已经是普通表。
下面看一个示例:
1. 创建基本表和索引
sql> conn icd/icd;
已连接。
sql> create table unpar_table (
2 id number(10) primary key,
3 create_date date
4 );
表已创建。
sql> insert into unpar_table select rownum, created from dba_objects;
已创建72288行。
sql> create index create_date_ind on unpar_table(create_date);
索引已创建。
sql> commit;
提交完成。
2. 收集表的统计信息
sql> exec dbms_stats.gather_table_stats('icd', 'unpar_table', cascade => true);
pl/sql 过程已成功完成。
3. 创建临时分区表
sql> create table par_table (id number primary key, time date) partition by range (time)
2 (partition p1 values less than (to_date('2004-7-1', 'yyyy-mm-dd')),
3 partition p2 values less than (to_date('2005-1-1', 'yyyy-mm-dd')),
4 partition p3 values less than (to_date('2005-7-1', 'yyyy-mm-dd')),
5 partition p4 values less than (maxvalue));
表已创建。
4. 进行重定义操作
4.1 检查重定义的合理性
sql> exec dbms_redefinition.can_redef_table('icd', 'unpar_table');
pl/sql 过程已成功完成。
4.2 如果4.1 没有问题,开始重定义,这个过程可能要等一会。
这里要注意:如果分区表和原表列名相同,可以用如下方式进行:
SQL> BEGIN
DBMS_REDEFINITION.start_redef_table(
uname => 'ICD',
orig_table => 'unpar_table',
int_table => 'par_table');
END;
/
如果分区表的列名和原表不一致,那么在开始重定义的时候,需要重新指定映射关系:
SQL> EXEC DBMS_REDEFINITION.START_REDEF_TABLE(
'ICD',
'unpar_table',
'par_table',
'ID ID, create_date TIME', -- 在这里指定新的映射关系
DBMS_REDEFINITION.CONS_USE_PK);
这一步操作结束后,数据就已经同步到这个临时的分区表里来了。
4.3 同步新表,这是可选的操作
SQL> BEGIN
2 dbms_redefinition.sync_interim_table(
3 uname => 'ICD',
4 orig_table => 'unpar_table',
5 int_table => 'par_table');
6 END;
7 /
PL/SQL 过程已成功完成。
4.4 创建索引,在线重定义只重定义数据,索引还需要单独建立。
sql> create index create_date_ind2 on par_table(time);
索引已创建。
4.5 收集新表的统计信息
sql> exec dbms_stats.gather_table_stats('icd', 'par_table', cascade => true);
pl/sql 过程已成功完成。
4.6 结束重定义
SQL> BEGIN
2 dbms_redefinition.finish_redef_table(
3 uname => 'ICD',
4 orig_table => 'unpar_table',
5 int_table => 'par_table');
6 END;
7 /
PL/SQL 过程已成功完成。
结束重定义的意义:
基表unpar_table 和临时分区表par_table 进行了交换。 此时临时分区表par_table成了普通表,我们的基表unpar_table成了分区表。
我们在重定义的时候,基表unpar_table是可以进行DML操作的。 只有在2个表进行切换的时候会有短暂的锁表。
5. 删除临时表
SQL> DROP TABLE par_table;
表已删除。
6. 索引重命名
SQL> ALTER INDEX create_date_ind2 RENAME TO create_date_ind;
索引已更改。
7. 验证
sql> select partitioned from user_tables where table_name = 'UNPAR_TABLE';
par
---
yes
sql> select partition_name from user_tab_partitions where table_name = 'UNPAR_TABLE';
partition_name
------------------------------
p1
p2
p3
p4
sql> select count(*) from unpar_table;
count(*)
----------
72288
sql> select count(*) from unpar_table partition (p4);
count(*)
----------
72288
sql>
三. 分区表的其他操作
3.1 添加新的分区
添加新的分区有2中情况:
(1)原分区里边界是maxvalue或者default。 这种情况下,我们需要把边界分区drop掉,加上新分区后,在添加上新的分区。 或者采用split,对边界分区进行拆分。
(2)没有边界分区的。 这种情况下,直接添加分区就可以了。
以边界分区添加新分区示例:
(1)分区表和索引的信息如下:
SQL> create table custaddr
2 (
3 id varchar2(15 byte) not null,
4 areacode varchar2(4 byte)
5 )
6 partition by list (areacode)
7 (
8 partition t_list556 values ('556') tablespace icd_service,
9 partition p_other values (default)tablespace icd_service
10 );
表已创建。
SQL> create index ix_custaddr_id on custaddr(id)
2 local (
3 partition t_list556 tablespace icd_service,
4 partition p_other tablespace icd_service
5 );
索引已创建。
(2)插入几条测试数据:
SQL> insert into custaddr values('1','556');
已创建 1 行。
SQL> insert into custaddr values('2','551');
已创建 1 行。
SQL> insert into custaddr values('3','555');
已创建 1 行。
SQL> commit;
提交完成。
SQL> select * from custaddr;
ID AREA
--------------- ----
1 556
2 551
3 555
SQL> select * from custaddr partition(t_list556);
ID AREA
--------------- ----
1 556
SQL>
(3)删除default分区
sql> alter table custaddr drop partition p_other;
表已更改。
sql> select table_name,partition_name from user_tab_partitions where table_name='CUSTADDR';
table_name partition_name
------------------------------ ------------------------------
custaddr t_list556
(4)添加新分区
SQL> alter table custaddr add partition t_list551 values('551') tablespace icd_service;
表已更改。
SQL> select table_name,partition_name from user_tab_partitions where table_name='CUSTADDR';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
CUSTADDR T_LIST556
CUSTADDR T_LIST551
(5)添加default 分区
SQL> alter table custaddr add partition p_other values (default) tablespace icd_service;
表已更改。
SQL> select table_name,partition_name from user_tab_partitions where table_name='CUSTADDR';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
CUSTADDR T_LIST556
CUSTADDR T_LIST551
CUSTADDR P_OTHER
(6)对于局部索引,oracle会自动增加一个局部分区索引。验证一下:
sql> select owner,index_name,table_name,partitioning_type from dba_part_indexes where index_name='ix_custaddr_id';
owner index_name table_name
---------------------- ------------------------------ ------------------
icd ix_custaddr_id custaddr
sql> select index_owner,index_name,partition_name from dba_ind_partitions where index_name='ix_custaddr_id';
index_owner index_name partition_name
------------------------------ ------------------------------ ------------------
icd ix_custaddr_id p_other
icd ix_custaddr_id t_list551
icd ix_custaddr_id t_list556
分区索引自动创建了。
3.2 split 分区拆分
在3.1 中,我们说明了可以使用split的方式来添加分区。 这里我们用split方法继续上面的实验。
sql> alter table custaddr split partition p_other values('552') into (partition t_list552 tablespace icd_service, partition p_other tablespace icd_service);
表已更改。
--注意这里红色的地方,如果是Range类型的,使用at,List使用Values。
SQL> select table_name,partition_name from user_tab_partitions where table_name='CUSTADDR';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
CUSTADDR T_LIST556
CUSTADDR T_LIST551
CUSTADDR T_LIST552
CUSTADDR P_OTHER
SQL> select index_owner,index_name,partition_name from dba_ind_partitions where index_name='IX_CUSTADDR_ID';
index_owner index_name partition_name
------------------------------ ------------------------------ ------------------
icd ix_custaddr_id p_other
icd ix_custaddr_id t_list551
icd ix_custaddr_id t_list552
icd ix_custaddr_id t_list556
注意:分区表会自动维护局部分区索引。全局索引会失效,需要进行rebuild。
3.3 合并分区Merge
相邻的分区可以merge为一个分区,新分区的下边界为原来边界值较低的分区,上边界为原来边界值较高的分区,原先的局部索引相应也会合并,全局索引会失效,需要rebuild。
SQL> alter table custaddr merge partitions t_list552,p_other into partition p_other;
表已更改。
SQL> select index_owner,index_name,partition_name from dba_ind_partitions where index_name='IX_CUSTADDR_ID';
index_owner index_name partition_name
-------------------- ------------------------------ ------------------
icd ix_custaddr_id p_other
icd ix_custaddr_id t_list551
icd ix_custaddr_id t_list556
SQL> select table_name,partition_name from user_tab_partitions where table_name='CUSTADDR';
table_name partition_name
------------------------------ ------------------------------
custaddr t_list556
custaddr t_list551
custaddr p_other
3.4 . 移动分区
SQL> alter table custaddr move partition P_OTHER tablespace system;
表已更改。
SQL> alter table custaddr move partition P_OTHER tablespace icd_service;
表已更改。
注意:分区移动会自动维护局部分区索引,oracle不会自动维护全局索引,所以需要我们重新rebuild分区索引,具体需要rebuild哪些索引,可以通过dba_part_indexes,dba_ind_partitions去判断。
SQL> Select index_name,status From user_indexes Where table_name='CUSTADDR';
INDEX_NAME STATUS
------------------------------ --------
IX_CUSTADDR_ID N/A
3.5. Truncate分区
SQL> select * from custaddr partition(T_LIST556);
ID AREA
--------------- ----
1 556
SQL> alter table custaddr truncate partition(T_LIST556);
表被截断。
SQL> select * from custaddr partition(T_LIST556);
未选定行
说明:
Truncate相对delete操作很快,数据仓库中的大量数据的批量数据加载可能会有用到;截断分区同样会自动维护局部分区索引,同时会使全局索引unusable,需要重建
3.6. Drop分区
SQL> alter table custaddr drop partition T_LIST551;
表已更改。
SQL> select table_name,partition_name from user_tab_partitions where table_name='CUSTADDR';
TABLE_NAME PARTITION_NAME
------------------------------ ------------------------------
CUSTADDR T_LIST556
CUSTADDR P_OTHER
同样会自动维护局部分区索引,同时会使全局索引unusable,需要重建
四. 分区表的索引
分区索引分为本地(local index)索引和全局索引(global index)。局部索引比全局索引容易管理, 而全局索引比较快。
与索引有关的表:
dba_part_indexes 分区索引的概要统计信息,可以得知每个表上有哪些分区索引,分区索引的类型(local/global)
dba_ind_partitions 每个分区索引的分区级统计信息
dba_indexes/dba_part_indexes 可以得到每个表上有哪些非分区索引
Local索引肯定是分区索引,Global索引可以选择是否分区,如果分区,只能是有前缀的分区索引。
分区索引分2类:有前缀(prefix)的分区索引和无前缀(nonprefix)的分区索引:
(1)有前缀的分区索引指包含了分区键,并且将其作为引导列的索引。
如:
create index i_id_global on PDBA(id) global --引导列
2 partition by range(id) --分区键
3 (partition p1 values less than (200),
4 partition p2 values less than (maxvalue)
5 );
这里的ID 就是分区键,并且分区键id 也是索引的引导列。
(2)无前缀的分区索引的列不是以分区键开头,或者不包含分区键列。
如:
create index ix_custaddr_local_id_p on custaddr(id)
local (
partition t_list556 tablespace icd_service,
partition p_other tablespace icd_service
)
这个分区是按照areacode来的。但是索引的引导列是ID。 所以它就是非前缀分区索引。
全局分区索引不支持非前缀的分区索引,如果创建,报错如下:
SQL> create index i_time_global on PDBA(id) global --索引引导列
2 partition by range(time) --分区建
3 (partition p1 values less than (TO_DATE('2010-12-1', 'YYYY-MM-DD')),
4 partition p2 values less than (maxvalue)
5 );
partition by range(time)
*
第 2 行出现错误:
ORA-14038: GLOBAL 分区索引必须加上前缀
4.1 Local 本地索引
对于local索引,当表的分区发生变化时,索引的维护由Oracle自动进行。
注意事项:
(1) 局部索引一定是分区索引,分区键等同于表的分区键。
(2) 前缀和非前缀索引都可以支持索引分区消除,前提是查询的条件中包含索引分区键。
(3) 局部索引只支持分区内的唯一性,无法支持表上的唯一性,因此如果要用局部索引去给表做唯一性约束,则约束中必须要包括分区键列。
(4) 局部分区索引是对单个分区的,每个分区索引只指向一个表分区;全局索引则不然,一个分区索引能指向n个表分区,同时,一个表分区,也可能指向n个索引分区,对分区表中的某个分区做truncate或者move,shrink等,可能会影响到n个全局索引分区,正因为这点,局部分区索引具有更高的可用性。
(5) 位图索引必须是局部分区索引。
(6) 局部索引多应用于数据仓库环境中。
(7) B树索引和位图索引都可以分区,但是HASH索引不可以被分区。
示例:
sql> create index ix_custaddr_local_id on custaddr(id) local;
索引已创建。
和下面SQL 效果相同,因为local索引就是分区索引:
create index ix_custaddr_local_id_p on custaddr(id)
local (
partition t_list556 tablespace icd_service,
partition p_other tablespace icd_service
)
SQL> create index ix_custaddr_local_areacode on custaddr(areacode) local;
索引已创建。
验证2个索引的类型:
SQL> select index_name,table_name,partitioning_type,locality,ALIGNMENT from user_part_indexes where table_name='CUSTADDR';
index_name table_name partition locali alignment
------------------------------ ---------- --------- ------ ------------
ix_custaddr_local_areacode custaddr list local prefixed
ix_custaddr_local_id custaddr list local non_prefixed
因为我们的custaddr表是按areacode进行分区的,所以索引ix_custaddr_local_areacode是有前缀的索引(prefixed)。而ix_custaddr_local_id是非前缀索引。
4.2 Global索引
对于global索引,可以选择是否分区,而且索引的分区可以不与表分区相对应。全局分区索引只能是B树索引,到目前为止(10gR2),oracle只支持有前缀的全局索引。
另外oracle不会自动的维护全局分区索引,当我们在对表的分区做修改之后,如果对分区进行维护操作时不加上update global indexes的话,通常会导致全局索引的INVALDED,必须在执行完操作后 REBUILD。
注意事项:
(1)全局索引可以分区,也可以是不分区索引,全局索引必须是前缀索引,即全局索引的索引列必须是以索引分区键作为其前几列。
(2)全局索引可以依附于分区表;也可以依附于非分区表。
(3)全局分区索引的索引条目可能指向若干个分区,因此,对于全局分区索引,即使只截断一个分区中的数据,都需要rebulid若干个分区甚至是整个索引。
(4)全局索引多应用于oltp系统中。
(5)全局分区索引只按范围或者散列分区,hash分区是10g以后才支持。
(6) oracle9i以后对分区表做move或者truncate的时可以用update global indexes语句来同步更新全局分区索引,用消耗一定资源来换取高度的可用性。
(7) 表用a列作分区,索引用b做局部分区索引,若where条件中用b来查询,那么oracle会扫描所有的表和索引的分区,成本会比分区更高,此时可以考虑用b做全局分区索引。
注意:Oracle只支持2中类型的全局分区索引:
range partitioned 和 Hash Partitioned.
官网的说明如下:
Global Partitioned Indexes
Oracle offers two types of global partitioned index: range partitioned and hash partitioned.
(1)Global Range Partitioned Indexes
Global range partitioned indexes are flexible in that the degree of partitioning and the partitioning key are independent from the table's partitioning method. They are commonly used for OLTP environments and offer efficient access to any individual record.
The highest partition of a global index must have a partition bound, all of whose values are MAXVALUE. This ensures that all rows in the underlying table can be represented in the index. Global prefixed indexes can be unique or nonunique.
You cannot add a partition to a global index because the highest partition always has a partition bound of MAXVALUE. If you wish to add a new highest partition, use the ALTER INDEX SPLIT PARTITION statement. If a global index partition is empty, you can explicitly drop it by issuing the ALTER INDEX DROP PARTITION statement. If a global index partition contains data, dropping the partition causes the next highest partition to be marked unusable. You cannot drop the highest partition in a global index.
(2)Global Hash Partitioned Indexes
Global hash partitioned indexes improve performance by spreading out contention when the index is monotonically growing. In other words, most of the index insertions occur only on the right edge of an index.
(3)Maintenance of Global Partitioned Indexes
By default, the following operations on partitions on a heap-organized table mark all global indexes as unusable:
ADD (HASH)
COALESCE (HASH)
DROP
EXCHANGE
MERGE
MOVE
SPLIT
TRUNCATE
示例1 全局索引,全局索引对所有分区类型都支持:
sql> create index ix_custaddr_ global_id on custaddr(id) global;
索引已创建。
示例2:全局分区索引,只支持Range 分区和Hash 分区:
(1)创建2个测试分区表:
sql> create table pdba (id number, time date) partition by range (time)
2 (
3 partition p1 values less than (to_date('2010-10-1', 'yyyy-mm-dd')),
4 partition p2 values less than (to_date('2010-11-1', 'yyyy-mm-dd')),
5 partition p3 values less than (to_date('2010-12-1', 'yyyy-mm-dd')),
6 partition p4 values less than (maxvalue)
7 );
表已创建。
SQL> create table Thash
2 (
3 id number primary key,
4 item_id number(8) not null
5 )
6 partition by hash(id)
7 (
8 partition part_01,
9 partition part_02,
10 partition part_03
11 );
表已创建。
(2)创建分区索引
示例2:全局分区索引
SQL> create index i_id_global on PDBA(id) global
2 partition by range(id)
3 (partition p1 values less than (200),
4 partition p2 values less than (maxvalue)
5 );
索引已创建。
--这个是有前缀的分区索引。
SQL> create index i_time_global on PDBA(id) global
2 partition by range(time)
3 (partition p1 values less than (TO_DATE('2010-12-1', 'YYYY-MM-DD')),
4 partition p2 values less than (maxvalue)
5 );
partition by range(time)
*
第 2 行出现错误:
ORA-14038: GLOBAL 分区索引必须加上前缀
SQL> create index i_time_global on PDBA(time) global
2 partition by range(time)
3 (partition p1 values less than (TO_DATE('2010-12-1', 'YYYY-MM-DD')),
4 partition p2 values less than (maxvalue)
5 );
索引已创建。
--有前缀的分区索引
SQL> select index_name,table_name,partitioning_type,locality,ALIGNMENT from user_part_indexes where table_name='PDBA';
index_name table_name partition locali alignment
------------------------------ ---------- --------- ------ ------------
i_id_global pdba range global prefixed
i_time_global pdba range global prefixed
SQL> CREATE INDEX ix_hash ON PDBA (id,time) GLOBAL
2 PARTITION BY HASH (id)
3 (PARTITION p1,
4 PARTITION p2,
5 PARTITION p3,
6 PARTITION p4);
索引已创建。
只要索引的引导列包含分区键,就是有前缀的分区索引。
4.3 索引重建问题
(1)分区索引
对于分区索引,不能整体进行重建,只能对单个分区进行重建。语法如下:
Alter index idx_name rebuild partition index_partition_name [online nologging]
说明:
online:表示重建的时候不会锁表。
nologging:表示建立索引的时候不生成日志,加快速度。
如果要重建分区索引,只能drop表原索引,在重新创建:
SQL>create index loc_xxxx_col on xxxx(col) local tablespace SYSTEM;
这个操作要求较大的临时表空间和排序区。
示例:
SQL> select index_name,partition_name from user_ind_partitions where index_name='I_TIME_GLOBAL';
INDEX_NAME PARTITION_NAME
------------------------------ ------------------------------
I_TIME_GLOBAL P1
I_TIME_GLOBAL P2
SQL> alter index I_TIME_GLOBAL rebuild partition p1 online nologging;
索引已更改。
SQL> alter index I_TIME_GLOBAL rebuild partition p2 online nologging;
索引已更改。
(2)全局索引
Oracle 会自动维护分区索引,对于全局索引,如果在对分区表操作时,没有指定update index,则会导致全局索引失效,需要重建。
SQL> select owner,index_name,table_name,status from dba_indexes where INDEX_NAME='IX_PDBA_GLOBAL';
owner index_name table_name status
------------------------------ ------------------------------ ---------- -------
sys ix_pdba_global pdba valid
删除一个分区:
SQL> alter table pdba drop partition p2;
表已更改。
SQL> select owner,index_name,table_name,status from dba_indexes where INDEX_NAME='IX_PDBA_GLOBAL';
owner index_name table_name status
------------------------------ ------------------------------ ---------- -------
sys ix_pdba_global pdba valid
split 分区:
SQL> alter table pdba split partition P4 at(TO_DATE('2010-12-21 00:00:00','YYYY-MM-DD HH24:MI:SS')) into (partition P4, partition P5);
表已更改。
SQL> select owner,index_name,table_name,status from dba_indexes where INDEX_NAME='IX_PDBA_GLOBAL';
owner index_name table_name status
------------------------------ ------------------------------ ---------- -------
sys ix_pdba_global pdba valid
drop 分区时使用update indexes
SQL> alter table pdba drop partition P4 UPDATE INDEXES;
表已更改。
SQL> select owner,index_name,table_name,status from dba_indexes where INDEX_NAME='IX_PDBA_GLOBAL';
owner index_name table_name status
---------------------- ------------------------------ ---------- -------
sys ix_pdba_global pdba valid
做了几个drop分区操作,全局索引没有失效,有点奇怪。 不过如果在生产环境中,还是小心点。
重建全局索引命令如下:
Alter index idx_name rebuild [online nologging]
示例:
SQL> Alter index ix_pdba_global rebuild online nologging;
索引已更改。
补充一点,分区表存储空间的问题:
SQL> select table_name,partition_name,tablespace_name from user_tab_partitions where table_name='DBA';
TABLE_NAME PARTITION_NAME TABLESPACE_NAME
---------- ------------------------------ ------------------------------
DBA P1 SYSTEM
DBA P2 SYSTEM
DBA P3 SYSTEM
DBA P4 SYSTEM
通过user_tab_partitions 表可以查看到每个分区对应的tablesapce_name. 但是,如果通过all_tables 表,却查不到分区表对应表空间的信息。
分区表:
SQL> select owner,table_name,tablespace_name,cluster_name from all_tables where table_name='DBA';
OWNER TABLE_NAME TABLESPACE_NAME CLUSTER_NAME
----- ---------- ------------------------------ -----------------------------------------------------
SYS DBA
普通表:
SQL> select owner,table_name,tablespace_name,cluster_name from all_tables where table_name='DAVE';
OWNER TABLE_NAME TABLESPACE_NAME CLUSTER_NAME
----- ---------- ------------------------------ ---------------------------------------------------
SYS DAVE SYSTEM
转:http://www.blogjava.net/rabbit/archive/2013/01/08/393955.html
深入学习Oracle分区表及分区索引
关于分区表和分区索引(About Partitioned Tables and Indexes)对于10gR2而言,基本上可以分成几类:
• Range(范围)分区
• Hash(哈希)分区
• List(列表)分区
• 以及组合分区:Range-Hash,Range-List。
对于表而言(常规意义上的堆组织表),上述分区形式都可以应用(甚至可以对某个分区指定compress属性),只不过分区依赖列不能是lob,long之类数据类型,每个表的分区或子分区数的总数不能超过1023个。
对于索引组织表,只能够支持普通分区方式,不支持组合分区,常规表的限制对于索引组织表同样有效,除此之外呢,还有一些其实的限制,比如要求索引组织表的分区依赖列必须是主键才可以等。
注:本篇所有示例仅针对常规表,即堆组织表!
对于索引,需要区分创建的是全局索引,或本地索引:
l 全局索引(global index):即可以分区,也可以不分区。即可以建range分区,也可以建hash分区,即可建于分区表,又可创建于非分区表上,就是说,全局索引是完全独立的,因此它也需要我们更多的维护操作。
l 本地索引(local index):其分区形式与表的分区完全相同,依赖列相同,存储属性也相同。对于本地索引,其索引分区的维护自动进行,就是说你add/drop/split/truncate表的分区时,本地索引会自动维护其索引分区。
Oracle建议如果单个表超过2G就最好对其进行分区,对于大表创建分区的好处是显而易见的,这里不多论述why,而将重点放在when以及how。
ORACLE对于分区表方式其实就是将表分段存储,一般普通表格是一个段存 储,而分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那几个内部,然后在分区内部去查找数据,一个分区一 般保证四十多万条数据就比较正常了,但是分区表并非乱建立,而其维护性也相对较为复杂一点,而索引的创建也是有点讲究的,这些以下尽量阐述详细即可。
range分区方式,也算是最常用的分区方式,其通过某字段或几个字段的组合的值,从小到大,按照指定的范围说明进行分区,我们在INSERT数据的时候就会存储到指定的分区中。
List分区方式,一般是在range基础上做的二级分区较多,是一种列举方式进行分区,一般讲某些地区、状态或指定规则的编码等进行划分。
Hash分区方式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE会自动去根据一套HASH算法去划分分区,只需要告诉ORACLE要分几个区即可。
WHEN
一、When使用Range分区
Range分区呢是应用范围比较广的表分区方式,它是以列的值的范围来做为分区的划分条件,将记录存放到列值所在的range分区中,比如按照 时间划分,2008年1季度的数据放到a分区,08年2季度的数据放到b分区,因此在创建的时候呢,需要你指定基于的列,以及分区的范围值,如果某些记录 暂无法预测范围,可以创建maxvalue分区,所有不在指定范围内的记录都会被存储到maxvalue所在分区中,并且支持指定多列做为依赖列,后面在 讲how的时候会详细谈到。
二、When使用Hash分区
通常呢,对于那些无法有效划分范围的表,可以使用hash分区,这样对于提高性能还是会有一定的帮助。hash分区会将表中的数据平均分配到你 指定的几个分区中,列所在分区是依据分区列的hash值自动分配,因此你并不能控制也不知道哪条记录会被放到哪个分区中,hash分区也可以支持多个依赖 列。
三、When使用List分区
List分区与range分区和hash分区都有类似之处,该分区与range分区类似的是也需要你指定列的值,但这又不同与range分区的 范围式列值---其分区值必须明确指定,也不同与hash分区---通过明确指定分区值,你能控制记录存储在哪个分区。它的分区列只能有一个,而不能像 range或者hash分区那样同时指定多个列做为分区依赖列,不过呢,它的单个分区对应值可以是多个。
你在分区时必须确定分区列可能存在的值,一旦插入的列值不在分区范围内,则插入/更新就会失败,因此通常建议使用list分区时,要创建一个default分区存储那些不在指定范围内的记录,类似range分区中的maxvalue分区。
四、When使用组合分区
如果某表按照某列分区之后,仍然较大,或者是一些其它的需求,还可以通过分区内再建子分区的方式将分区再分区,即组合分区的方式。
组合分区呢在10g中有两种:range-hash,range-list。注意顺序哟,根分区只能是range分区,子分区可以是hash分区或list分区。
提示:11g在组合分区功能这块有所增强,又推出了range-range,list-range,list-list,list-hash, 这就相当于除hash外三种分区方式的笛卡尔形式都有了。为什么会没有hash做为根分区的组合分区形式呢,再仔细回味一下第二点,你一定能够想明 白~~。
深入学习Oracle分区表及分区索引(2)
一、如何创建
如果想对某个表做分区,必须在创建表时就指定分区,我们可以对一个包含分区的表中的分区做修改,但不能直接将一个未分区的表修改成分区表(起码在10g是不行的,当然你可能会说,可以通过在线重定义的方式,但是这不是直接哟,这也是借助临时表间接实现的)。
创建表或索引的语法就不说了,大家肯定比我还熟悉,而想在建表(索引)同时指定分区也非常容易,只需要把创建分区的子句放到";"前就行啦,同 时需要注意表的row movement属性,它用来控制是否允许修改列值所造成的记录移动至其它分区存储,有enable|disable两种状态,默认是disable row movement,当disable时,如果记录要被更新至其它分区,则更新语句会报错。
下面分别演示不同分区方式的表和索引的创建:
1、创建range分区
语法如下,需要我们指定的有:
l column:分区依赖列(如果是多个,以逗号分隔);
l partition:分区名称;
l values less than:后跟分区范围值(如果依赖列有多个,范围对应值也应是多个,中间以逗号分隔);
l tablespace_clause:分区的存储属性,例如所在表空间等属性(可为空),默认继承基表所在表空间的属性。
① 创建一个标准的range分区表:
JSSWEB> create table t_partition_range (id number,name varchar2(50))
partition by range(id)(
partition t_range_p1 values less than (10) tablespace tbspart01,
partition t_range_p2 values less than (20) tablespace tbspart02,
partition t_range_p3 values less than (30) tablespace tbspart03,
partition t_range_pmax values less than (maxvalue) tablespace tbspart04
);
表已创建。
要查询创建分区的信息,可以通过查询user_part_tables,user_tab_partitions两个数据字典(索引分区、组织分区等信息也有对应的数据字典,后续示例会逐步提及)。
user_part_tables:记录分区的表的信息;
user_tab_partitions:记录表的分区的信息。
例如:
JSSWEB> select table_name,partitioning_type,partition_count
From user_part_tables where table_name='T_PARTITION_RANGE';
JSSWEB> select partition_name,high_value,tablespace_name
from user_tab_partitions where table_name='T_PARTITION_RANGE'
order by partition_position;
② 创建global索引range分区:
JSSWEB> create index idx_parti_range_id on t_partition_range(id)
2 global partition by range(id)(
3 partition i_range_p1 values less than (10) tablespace tbspart01,
4 partition i_range_p2 values less than (40) tablespace tbspart02,
5 partition i_range_pmax values less than (maxvalue) tablespace tbspart03);
索引已创建。
由上例可以看出,创建global索引的分区与创建表的分区语句格式完全相同,而且其分区形式与索引所在表的分区形式没有关联关系。
注意:我们这里借助上面的表t_partition_range来演示创建range分区的global索引,并不表示range分区的表,只能创建range分区的global索引,只要你想,也可以为其创建hash分区的global索引。
查询索引的分区信息可以通过user_part_indexes、user_ind_partitions两个数据字典:
JSSWEB> select index_name, partitioning_type, partition_count
2 From user_part_indexes
3 where index_name = 'IDX_PARTI_RANGE_ID';
③ Local分区索引的创建最简单,例如:
仍然借助t_partition_range表来创建索引
--首先删除之前创建的global索引
JSSWEB> drop index IDX_PARTI_RANGE_ID;
索引已删除。
JSSWEB> create index IDX_PARTI_RANGE_ID on T_PARTITION_RANGE(id) local;
索引已创建。
查询相关数据字典:
JSSWEB> select index_name, partitioning_type, partition_count
2 From user_part_indexes
3 where index_name = 'IDX_PARTI_RANGE_ID';
JSSWEB> select partition_name, high_value, tablespace_name
2 from user_ind_partitions
3 where index_name = 'IDX_PARTI_RANGE_ID'
4 order by partition_position;
可以看出,local索引的分区完全继承表的分区的属性,包括分区类型,分区的范围值即不需指定也不能更改,这就是前面说的:local索引的分区维护完全依赖于其索引所在表。
不过呢分区名称,以及分区所在表空间等信息是可以自定义的,例如:
SQL> create index IDX_PART_RANGE_ID ON T_PARTITION_RANGE(id) local (
2 partition i_range_p1 tablespace tbspart01,
3 partition i_range_p2 tablespace tbspart01,
4 partition i_range_p3 tablespace tbspart02,
5 partition i_range_pmax tablespace tbspart02
6 );
索引已创建。
SQL> select index_name, partitioning_type, partition_count
2 From user_part_indexes
3 where index_name = 'IDX_PART_RANGE_ID';
SQL> select partition_name, high_value, tablespace_name
2 from user_ind_partitions
3 where index_name = 'IDX_PART_RANGE_ID'
4 order by partition_position;
创建hash分区
语法如下:[图:hash_partitioning.gif]
语法看起来比range复杂,其实使用起来比range更简单,这里需要我们指定的有:
l column:分区依赖列(支持多个,中间以逗号分隔);
l partition:指定分区,有两种方式:
n 直接指定分区名,分区所在表空间等信息
n 只指定分区数量,和可供使用的表空间。
2、创建hash分区
JSSWEB> create table t_partition_hash (id number,name varchar2(50))
2 partition by hash(id)(
3 partition t_hash_p1 tablespace tbspart01,
4 partition t_hash_p2 tablespace tbspart02,
5 partition t_hash_p3 tablespace tbspart03);
表已创建。
要实现同样效果,你还可以这样:
JSSWEB> create table t_partition_hash2 (id number,name varchar2(50))
2 partition by hash(id)
3 partitions 3 store in(tbspart01,tbspart02,tbspart03);
表已创建。
这就是上面说的,直接指定分区数量和可供使用的表空间。
提示:这里分区数量和可供使用的表空间数量之间没有直接对应关系。分区数并不一定要等于表空间数。
要查询表的分区信息,仍然是通过user_part_tables,user_tab_partitions两个数据字典,这里不再举例。
① Global索引hash分区
Hash分区索引的子句与hash分区表的创建子句完全相同,例如:
JSSWEB> create index idx_part_hash_id on t_partition_hash(id)
2 global partition by hash(id)
3 partitions 3 store in(tbspart01,tbspart02,tbspart03);
索引已创建。
查询索引的分区信息也仍是通过user_part_indexes、user_ind_partitions两个数据字典,不再举例。
② 创建Local索引
在前面学习range分区时,我们已经对Local索引的特性做了非常清晰的概述,因此这里也不再举例,如有疑问,建议再仔细复习range分区的相关示例,如果还有疑问,当面问我好了:)
综上:
Ø 对于global索引分区而言,在10g中只能支持range分区和hash分区,因此后续示例中不会再提及。
Ø 对于local索引分区而言,其分区形式完全依赖于索引所在表的分区形式,不管从创建语法还是理解难度均无技术含量,因此后续也不再提供示例。
Ø 注意,在创建索引时如果不显式指定global或local,则默认是global。
Ø 注意,在创建global索引时如果不显式指定分区子句,则默认不分区(废话)。
3、分区应用:
一般一张表超过2G的大小,ORACLE是推荐使用分区表的,分区一般都需要 创建索引,说到分区索引,就可以分为:全局索引、分区索引,即:global索引和local索引,前者为默认情况下在分区表上创建索引时的索引方式,并 不对索引进行分区(索引也是表结构,索引大了也需要分区,关于索引以后专门写点)而全局索引可修饰为分区索引,但是和local索引有所区别,前者的分区 方式完全按照自定义方式去创建,和表结构完全无关,所以对于分区表的全局索引有以下两幅网上常用的图解:
3.1、对于分区表的不分区索引(这个有点绕,不过就是表分区,但其索引不分区):
创建语法(直接创建即可):
CREATE INDEX <index_name> ON <partition_table_name>(<column_name>);
3.2、对于分区表的分区索引:
创建语法为:
CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1)
GLOBAL PARTITION BY RANGE(COL1)(
PARTITION IDX_P1 values less than (1000000),
PARTITION IDX_P2 values less than (2000000),
PARTITION IDX_P3 values less than (MAXVALUE)
);
3.3、LOCAL索引结构:
创建语法为:
CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1) LOCAL;
也可按照分区表的的分区结构给与一一定义,索引的分区将得到重命名。
分区上的位图索引只能为LOCAL索引,不能为GLOBAL全局索引。
3.4、对比索引方式:
一般使用LOCAL索引较为方便,而且维护代价较低,并且LOCAL索引是在分区的基础上去创建索引,类似于在一个子表内部去创建索引,这样开销主要是区 分分区上,很规范的管理起来,在OLAP系统中应用很广泛;而相对的GLOBAL索引是全局类型的索引,根据实际情况可以调整分区的类别,而并非按照分区 结构一一定义,相对维护代价较高一些,在OLTP环境用得相对较多,这里所谓OLTP和OLAP也是相对的,不是特殊的项目,没有绝对的划分概念,在应用 过程中依据实际情况而定,来提高整体的运行性能。
4、常用视图:
1、查询当前用户下有哪些是分区表:
SELECT * FROM USER_PART_TABLES;
2、查询当前用户下有哪些分区索引:
SELECT * FROM USER_PART_INDEXES;
3、查询当前用户下分区索引的分区信息:
SELECT * FROM USER_IND_PARTITIONS T
WHERE T.INDEX_NAME=?
4、查询当前用户下分区表的分区信息:
SELECT * FROM USER_TAB_PARTITIONS T
WHERE T.TABLE_NAME=?;
5、查询某分区下的数据量:
SELECT COUNT(*) FROM TABLE_PARTITION PARTITION(TAB_PARTOTION_01);
6、查询索引、表上在那些列上创建了分区:
SELECT * FROM USER_PART_KEY_COLUMNS;
7、查询某用户下二级分区的信息(只有创建了二级分区才有数据):
SELECT * FROM USER_TAB_SUBPARTITIONS;
5、维护操作:
5.1、删除分区
ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03;
如果是全局索引,因为全局索引的分区结构和表可以不一致,若不一致的情况下,会导致整个全局索引失效,在删除分区的时候,语句修改为:
ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03 UPDATE GLOBAL INDEXES;
5.2、分区合并(从中间删除掉一个分区,或者两个分区需要合并后减少分区数量)
合并分区和删除中间的RANGE有点像,但是合并分区是不会删除数据的,对于LIST、HASH分区也是和RANGE分区不一样的,其语法为:
ALTER TABLE TABLE_PARTITION MERGE PARTITIONS TAB_PARTOTION_01,TAB_PARTOTION_02 INTO PARTITION MERGED_PARTITION;
5.3、分隔分区(一般分区从扩展分区从分隔)
ALTER TABLE TABLE_PARTITION SPLIT PARTITION TAB_PARTOTION_OTHERE AT(2500000)
INTO (PARTITION TAB_PARTOTION_05,PARTITION TAB_PARTOTION_OTHERE);
5.4、创建新的分区(分区数据若不能提供范围,则插入时会报错,需要增加分区来扩大范围)
一般有扩展分区的是都是用分隔的方式,若上述创建表时没有创建TAB_PARTOTION_OTHER分区时,在插入数据较大时(按照上述建立规则,超过1800000就应该创建新的分区来存储),就可以创建新的分区,如:
为了试验,我们将扩展分区先删除掉再创建新的分区(因为ORACLE要求,分区的数据不允许重叠,即按照分区字段同样的数据不能同时存储在不同的分区中):
ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_OTHER;
ALTER TABLE TABLE_PARTITION ADD PARTITION TAB_PARTOTION_06 VALUES LESS THAN(2500000);
在分区下创建新的子分区大致如下(RANGE分区,若为LIST或HASH分区,将创建方式修改为对应的方式即可):
ALTER TABLE <table_name> MODIFY PARTITION <partition_name> ADD SUBPARTITION <user_define_subpartition_name> VALUES LESS THAN(....);
5.5、修改分区名称(修改相关的属性信息)
ALTER TABLE TABLE_PARTITION RENAME PARTITION MERGED_PARTITION TO MERGED_PARTITION02;
5.6、交换分区(快速交换数据,其实是交换段名称指针)
首先创建一个交换表,和原表结构相同,如果有数据,必须符合所交换对应分区的条件:
CREATE TABLE TABLE_PARTITION_2
AS SELECT * FROM TABLE_PARTITION WHERE 1=2;
然后将第一个分区的数据交换出去:
ALTER TABLE TABLE_PARTITION EXCHANGE PARTITION TAB_PARTOTION_01
WITH TABLE TABLE_PARTITION_2 INCLUDING INDEXES;
此时会发现第一个分区的数据和表TABLE_PARTITION_2做了瞬间交换,比TRUNCATE还要快,因为这个过程没有进行数据转存,只是段名称的修改过程,和实际的数据量没有关系。
如果是子分区也可以与外部的表进行交换,只需要将关键字修改为:SUBPARTITION 即可。
5.7、清空分区数据
ALTER TABLE <table_name> TRUNCATE PARTITION <partition_name>;
ALTER TABLE <table_name> TRUNCATE subpartition <subpartition_name>;
6、磁盘碎片压缩
对分区表的某分区进行磁盘压缩,当对分区内部数据进行了大量的UPDATE、DELETE操作后,一定时间需要进行磁盘压缩,否则在查询时,若通过FULL SCAN扫描数据,将会把空块也会扫描到,对表进行磁盘压缩需要进行行迁移操作,所以首先需要操作:
ALTER TABLE <table_name> ENABLE ROW MOVEMENT ;
对分区表的某分区压缩语法为:
ALTER TABLE <table_name>
modify partition <partition_name> shrink space;
对普通表压缩:
ALTER TABLE <table_name> shrink space;
对于索引也需要进行压缩,索引也是表:
ALTER INDEX <index_name> shrink space;
7、分区表重新分析以及索引重新分析
对表进行压缩后,需要对表和索引进行重新分析,对表进行重新分析,一般有两种方式:
在ORACLE 10G以前,使用:
BEGIN
dbms_stats.gather_table_stats(USER,UPPER('<table_name>'));
END;
ORACLE 10G后,可以使用:
ANALYZE TABLE <table_name> COMPUTE STATISTICS;
索引重新分析,将上述两种方式分别修改一下,如第一种可以使用:gather_index_stats,而第二种修改为:ANALYZE INDEX即可,不过一般比较常用的是重新编译:
对于分区表并进行了索引分区的情况,需要对每个分区的索引进行重新编译,这里以LOCAL索引为例子(其每个索引的分区和表分区结构相同,默认分区名称和表分区名称相同):
ALTER INDEX <index_name> REBUILD PARTITION <partition_name>;
对于全局索引,根据全局索引锁定义的分区名称修改即可,若没有分区,和普通单表索引重新编译方式相同:
ALTER INDEX <index_name> REBUILD;
1、关联对象重新编译
上述对表、索引进行重新编译,尤其对表进行了压缩后会产生行迁移,这个过程可能会导致一些视图、过程对象的失效,此时要将其重新编译一次。
2、扩展:HASH分区中,如果创建了新的分区,可以将其进行重新HASH分布:
ALTER TABLE <table_name> COALESCA PARTITION
8、回归总结:何时建分区,分区类别,索引,如何对应SQL
1、创建时机
上述已经说明,2G以上的表,ORACLE推荐创建分区。
分区的方式根据实际情况而定,才能提高整体性能。
分区的字段一定要是经常用以提取数据的字段,否则会在提取过程中导致遍历多个分区,这样比没有分区还要慢。
分区字段要选择合适,数据较为均匀分布到各个分区,不要太多也不要太少,而且根据分区字段可以很快定位到分区范围。
一般情况下,尽量然业务操作在同一个分区内部完成。
2、分区类别
分区主要有RANGE、LIST、HASH;
RANGE通过值的范围分区,也是最常用的分区,这种分区注意在一种变长数字字符串中,很多人会导致认为是数字类型,而按照数字区分区,这样会分布十分不均匀的现象发生。
LIST是列举方式进行分区,一般作为二级分区而存在(当然也可以自己分区,ORACLE 11G后在分区上也可以作为主分区而存在),在RANGE基础上,若数据需要继续分区,并且在RANGE基础上数据量较为固定,只是较大,可以按照一定规则进一步分区。
HASH只指定分区个数,分区细节由ORACLE完成,增加HASH分区可以重新分布数据。
注意:分区字段不能使用函数转换后在分区,如,将某数字字符串字段,先TO_NUMER(COL_NAME)后分区。
3、索引类别
大致分:GLOBAL索引和LOCAL索引,钱和可以分:GLOBAL不分区索引,和GLOBAL分区索引。
GLOBAL不分区索引一般不太推荐,因为是用一颗大的索引树来映射一个表,这个过程,这样速度不见得比不分区快。
GLOBAL分区索引,查找数据若通过要通过索引,是先定位了索引内部的分区,然后在这个分区索引中找到ROWID,然后回表提取数据。
LOCAL索引是和分区的个数逐个对应的,可以说先定位分区表的分区也可以说先定位索引的分区,因为他们是一一对应的,找到对应分区后,分区内部索引数据集合。
4、对应应用
分区表、索引、分区索引,要利用其性能优势,最基本就是要提取数据时,要通过它首先将数据的范围缩小到一个即使做全盘扫描也不会太慢的情况。
所以SQL一定要有分区上的这个字段的一个WHERE条件,将数据迅速定位到分区内部,而且尽量定位到一个分区里面(这个和创建分区的规则有关系)。
建立分区本身不提要性能,要用好才可提高性能,在必要的RAC集群中,若存在多分区提取数据,适当采用并行提取可以提高提取的速度。
对于索引部分,这里也只提到分区索引的创建方式以及常见索引的维护方式,对于索引原理理解后会更容易认识到提取数据时的技巧。
9、实战
分区表和一般表一样可以建立索引,分区表可以创建局部索引和全局索引。当分区中出现许多事务并且要保证所有分区中的数据记录的唯一性时采用全局索引。
1 局部索引分区的建立:
SQL> create index dinya_idx_t on dinya_test(item_id)
2 local
3 (
4 partition idx_1 tablespace dinya_space01,
5 partition idx_2 tablespace dinya_space02,
6 partition idx_3 tablespace dinya_space03
7 );
Index created.
SQL>
看查询的执行计划,从下面的执行计划可以看出,系统已经使用了索引:
SQL> select * from dinya_test partition(part_01) t where t.item_id=12;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=187)
1 0 TABLE ACCESS (BY LOCAL INDEX ROWID) OF 'DINYA_TEST' (Cost=
2 Card=1 Bytes=187)
2 1 INDEX (RANGE SCAN) OF 'DINYA_IDX_T' (NON-UNIQUE) (Cost=1
Card=1)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
4 consistent gets
0 physical reads
0 redo size
334 bytes sent via SQL*Net to client
309 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
1 sorts (memory)
0 sorts (disk)
2 rows processed
SQL>
2 全局索引分区的建立。
全局索引建立时global 子句允许指定索引的范围值,这个范围值为索引字段的范围值:
SQL> create index dinya_idx_t on dinya_test(item_id)
2 global partition by range(item_id)
3 (
4 partition idx_1 values less than (1000) tablespace dinya_space01,
5 partition idx_2 values less than (10000) tablespace dinya_space02,
6 partition idx_3 values less than (maxvalue) tablespace dinya_space03
7 );
Index created.
SQL>
本例中对表的item_id字段建立索引分区,当然也可以不指定索引分区名直接对整个表建立索引,如:
SQL> create index dinya_idx_t on dinya_test(item_id);
Index created.
SQL>
同样的,对全局索引根据执行计划可以看出索引已经可以使用:
SQL> select * from dinya_test t where t.item_id=12;
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=3 Bytes=561)
1 0 TABLE ACCESS (BY GLOBAL INDEX ROWID) OF 'DINYA_TEST' (Cost
=2 Card=3 Bytes=561)
2 1 INDEX (RANGE SCAN) OF 'DINYA_IDX_T' (NON-UNIQUE) (Cost=1
Card=3)
Statistics
----------------------------------------------------------
5 recursive calls
0 db block gets
10 consistent gets
0 physical reads
0 redo size
420 bytes sent via SQL*Net to client
309 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
3 sorts (memory)
0 sorts (disk)
5 rows processed
SQL>
其实分区的管理很简单,难点在于分区方式的选择和分区表上面索引的选择。
Global Index全局索引和Local Index局部索引,Global partitioned index和global nonpartitioned index,
选择多,就越迷惑。
转:http://blog.csdn.net/xieyuooo/article/details/5437126
ORACLE对于分区表方式其实就是将表分段存储,一般普通表格是一个段存储,而分区表会分成多个段,所以查找数据过程都是先定位根据查询条件定位分区范围,即数据在那个分区或那几个内部,然后在分区内部去查找数据,一个分区一般保证四十多万条数据就比较正常了,但是分区表并非乱建立,而其维护性也相对较为复杂一点,而索引的创建也是有点讲究的,这些以下尽量阐述详细即可。
1、类型说明:
range分区方式,也算是最常用的分区方式,其通过某字段或几个字段的组合的值,从小到大,按照指定的范围说明进行分区,我们在INSERT数据的时候就会存储到指定的分区中。
List分区方式,一般是在range基础上做的二级分区较多,是一种列举方式进行分区,一般讲某些地区、状态或指定规则的编码等进行划分。
Hash分区方式,它没有固定的规则,由ORACLE管理,只需要将值INSERT进去,ORACLE会自动去根据一套HASH算法去划分分区,只需要告诉ORACLE要分几个区即可。
分区可以进行两两组合,ORACLE 11G以前两两组合都必须以range作为一级分区的开头,ORACLE目前最多支持2级别分区,但这个级别已经够我们使用了。
我这只以最简单的分区方式创建分区来说明问题,就拿range分区来说明问题吧(基本创建语句如下):
- CREATE TABLE TABLE_PARTITION(
- COL1 NUMBER,
- COL2 VARCHAR2(10)
- )
- partition by range(COL1)(
- partition TAB_PARTOTION_01 values less than (450000),
- partition TAB_PARTOTION_02 values less than (900000),
- partition TAB_PARTOTION_03 values less than (1350000),
- partition TAB_PARTOTION_04 values less than (1800000),
- partition TAB_PARTOTION_OTHER values less THAN (MAXVALUE)
- );
这个分区表创建了四个定长分区,理想情况下,存储450000条数据,扩展分区是超过这个数额的分区,当发现扩展分区有数据的时候,可以进行将扩展分区做SPLIT操作,这个后面说明,这里先说一下一些常用的分区表查询功能,我们先插入一些数据进去。
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(1,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(23,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(449000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(450000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(1350000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(900000,'数据测试');
- INSERT INTO TABLE_PARTITION(COL1,COL2)
- VALUES(1800000-1,'数据测试');
- COMMIT;
为了检测哪些分区中有哪些数据分别按照分区去查询数据(应用开发中基本不会用到,因为不会把分区写死)
- SQL> SELECT * FROM TABLE_PARTITION partition(TAB_PARTOTION_01);
- COL1 COL2
- ---------- ---------------
- 1 数据测试
- 23 数据测试
- 449000 数据测试
说明第一个分区有:1、23、44900这些数据,也就是插入时,ORACLE是自己去找分区的,其实分区这种子表管理自己也可以通过程序去完成,ORACLE给你提供了一套,就可以自己去完成了。其余的数据就自己查了,都是一个道理。
2、分区应用:
一般一张表超过2G的大小,ORACLE是推荐使用分区表的,分区一般都需要创建索引,说到分区索引,就可以分为:全局索引、分区索引,即:global索引和local索引,前者为默认情况下在分区表上创建索引时的索引方式,并不对索引进行分区(索引也是表结构,索引大了也需要分区,关于索引以后专门写点)而全局索引可修饰为分区索引,但是和local索引有所区别,前者的分区方式完全按照自定义方式去创建,和表结构完全无关,所以对于分区表的全局索引有以下两幅网上常用的图解:
2.1、对于分区表的不分区索引(这个有点绕,不过就是表分区,但其索引不分区):
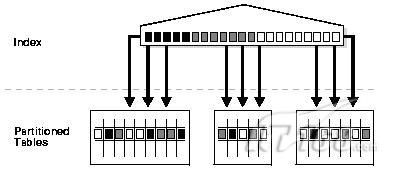
创建语法(直接创建即可):
CREATE INDEX <index_name> ON <partition_table_name>(<column_name>);
2.2、对于分区表的分区索引:
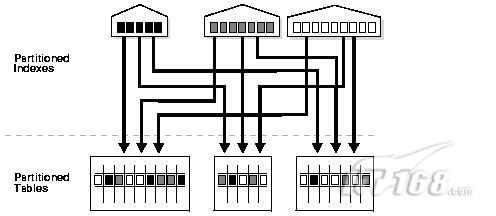
创建语法为:
- CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1)
- GLOBAL PARTITION BY RANGE(COL1)(
- PARTITION IDX_P1 values less than (1000000),
- PARTITION IDX_P2 values less than (2000000),
- PARTITION IDX_P3 values less than (MAXVALUE)
- );
2.3、LOCAL索引结构:
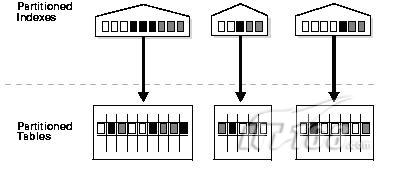
创建语法为:
- CREATE INDEX INX_TAB_PARTITION_COL1 ON TABLE_PARTITION(COL1) LOCAL;
也可按照分区表的的分区结构给与一一定义,索引的分区将得到重命名。
分区上的位图索引只能为LOCAL索引,不能为GLOBAL全局索引。
2.4、对比索引方式:
一般使用LOCAL索引较为方便,而且维护代价较低,并且LOCAL索引是在分区的基础上去创建索引,类似于在一个子表内部去创建索引,这样开销主要是区分分区上,很规范的管理起来,在OLAP系统中应用很广泛;而相对的GLOBAL索引是全局类型的索引,根据实际情况可以调整分区的类别,而并非按照分区结构一一定义,相对维护代价较高一些,在OLTP环境用得相对较多,这里所谓OLTP和OLAP也是相对的,不是特殊的项目,没有绝对的划分概念,在应用过程中依据实际情况而定,来提高整体的运行性能。
3、常用视图:
- 1、查询当前用户下有哪些是分区表:
- SELECT * FROM USER_PART_TABLES;
- 2、查询当前用户下有哪些分区索引:
- SELECT * FROM USER_PART_INDEXES;
- 3、查询当前用户下分区索引的分区信息:
- SELECT * FROM USER_IND_PARTITIONS T
- WHERE T.INDEX_NAME=?
- 4、查询当前用户下分区表的分区信息:
- SELECT * FROM USER_TAB_PARTITIONS T
- WHERE T.TABLE_NAME=?;
- 5、查询某分区下的数据量:
- SELECT COUNT(*) FROM TABLE_PARTITION PARTITION(TAB_PARTOTION_01);
- 6、查询索引、表上在那些列上创建了分区:
- SELECT * FROM USER_PART_KEY_COLUMNS;
- 7、查询某用户下二级分区的信息(只有创建了二级分区才有数据):
- SELECT * FROM USER_TAB_SUBPARTITIONS;
4、维护操作:
4.1、删除分区
- ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03;
- 如果是全局索引,因为全局索引的分区结构和表可以不一致,若不一致的情况下,会导致整个全局索引失效,在删除分区的时候,语句修改为:
- ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_03 UPDATE GLOBAL INDEXES
4.2、分区合并(从中间删除掉一个分区,或者两个分区需要合并后减少分区数量)
合并分区和删除中间的RANGE有点像,但是合并分区是不会删除数据的,对于LIST、HASH分区也是和RANGE分区不一样的,其语法为:
- ALTER TABLE TABLE_PARTITION MERGE PARTITIONS TAB_PARTOTION_01,TAB_PARTOTION_02 INTO PARTITION MERGED_PARTITION;
4.3、分隔分区(一般分区从扩展分区从分隔)
- ALTER TABLE TABLE_PARTITION SPLIT PARTITION TAB_PARTOTION_OTHERE AT(2500000)
- INTO (PARTITION TAB_PARTOTION_05,PARTITION TAB_PARTOTION_OTHERE);
4.4、创建新的分区(分区数据若不能提供范围,则插入时会报错,需要增加分区来扩大范围)
一般有扩展分区的是都是用分隔的方式,若上述创建表时没有创建TAB_PARTOTION_OTHER分区时,在插入数据较大时(按照上述建立规则,超过1800000就应该创建新的分区来存储),就可以创建新的分区,如:
为了试验,我们将扩展分区先删除掉再创建新的分区(因为ORACLE要求,分区的数据不允许重叠,即按照分区字段同样的数据不能同时存储在不同的分区中):
- ALTER TABLE TABLE_PARTITION DROP PARTITION TAB_PARTOTION_OTHER;
- ALTER TABLE TABLE_PARTITION ADD PARTITION TAB_PARTOTION_06 VALUES LESS THAN(2500000);
在分区下创建新的子分区大致如下(RANGE分区,若为LIST或HASH分区,将创建方式修改为对应的方式即可):
- ALTER TABLE <table_name> MODIFY PARTITION <partition_name> ADD SUBPARTITION <user_define_subpartition_name> VALUES LESS THAN(....);
4.5、修改分区名称(修改相关的属性信息)
- ALTER TABLE TABLE_PARTITION RENAME PARTITION MERGED_PARTITION TO MERGED_PARTITION02;
4.6、交换分区(快速交换数据,其实是交换段名称指针)
首先创建一个交换表,和原表结构相同,如果有数据,必须符合所交换对应分区的条件:
- CREATE TABLE TABLE_PARTITION_2
- AS SELECT * FROM TABLE_PARTITION WHERE 1=2;
然后将第一个分区的数据交换出去:
- ALTER TABLE TABLE_PARTITION EXCHANGE PARTITION TAB_PARTOTION_01
- WITH TABLE TABLE_PARTITION_2 INCLUDING INDEXES;
此时会发现第一个分区的数据和表TABLE_PARTITION_2做了瞬间交换,比TRUNCATE还要快,因为这个过程没有进行数据转存,只是段名称的修改过程,和实际的数据量没有关系。
如果是子分区也可以与外部的表进行交换,只需要将关键字修改为:SUBPARTITION 即可。
4.7、清空分区数据
- ALTER TABLE <table_name> TRUNCATE PARTITION <partition_name>;
- ALTER TABLE <table_name> TRUNCATE subpartition <subpartition_name>;
9、磁盘碎片压缩
对分区表的某分区进行磁盘压缩,当对分区内部数据进行了大量的UPDATE、DELETE操作后,一定时间需要进行磁盘压缩,否则在查询时,若通过FULL SCAN扫描数据,将会把空块也会扫描到,对表进行磁盘压缩需要进行行迁移操作,所以首先需要操作:
- ALTER TABLE <table_name> ENABLE ROW MOVEMENT ;
- 对分区表的某分区压缩语法为:
- ALTER TABLE <table_name>
- modify partition <partition_name> shrink space;
- 对普通表压缩:
- ALTER TABLE <table_name> shrink space;
- 对于索引也需要进行压缩,索引也是表:
- ALTER INDEX <index_name> shrink space;
10、分区表重新分析以及索引重新分析
对表进行压缩后,需要对表和索引进行重新分析,对表进行重新分析,一般有两种方式:
在ORACLE 10G以前,使用:
- BEGIN
- dbms_stats.gather_table_stats(USER,UPPER('<table_name>'));
- END;
- ORACLE 10G后,可以使用:
- ANALYZE TABLE <table_name> COMPUTE STATISTICS;
索引重新分析,将上述两种方式分别修改一下,如第一种可以使用:gather_index_stats,而第二种修改为:ANALYZE INDEX即可,不过一般比较常用的是重新编译:
对于分区表并进行了索引分区的情况,需要对每个分区的索引进行重新编译,这里以LOCAL索引为例子(其每个索引的分区和表分区结构相同,默认分区名称和表分区名称相同):
- ALTER INDEX <index_name> REBUILD PARTITION <partition_name>;
- 对于全局索引,根据全局索引锁定义的分区名称修改即可,若没有分区,和普通单表索引重新编译方式相同:
- ALTER INDEX <index_name> REBUILD;
11、关联对象重新编译
上述对表、索引进行重新编译,尤其对表进行了压缩后会产生行迁移,这个过程可能会导致一些视图、过程对象的失效,此时要将其重新编译一次。
12、扩展:HASH分区中,如果创建了新的分区,可以将其进行重新HASH分布:
- ALTER TABLE <table_name> COALESCA PARTITION
5、回归总结:何时建分区,分区类别,索引,如何对应SQL
1、创建时机
上述已经说明,2G以上的表,ORACLE推荐创建分区。
分区的方式根据实际情况而定,才能提高整体性能。
分区的字段一定要是经常用以提取数据的字段,否则会在提取过程中导致遍历多个分区,这样比没有分区还要慢。
分区字段要选择合适,数据较为均匀分布到各个分区,不要太多也不要太少,而且根据分区字段可以很快定位到分区范围。
一般情况下,尽量然业务操作在同一个分区内部完成。
2、分区类别
分区主要有RANGE、LIST、HASH;
RANGE通过值的范围分区,也是最常用的分区,这种分区注意在一种变长数字字符串中,很多人会导致认为是数字类型,而按照数字区分区,这样会分布十分不均匀的现象发生。
LIST是列举方式进行分区,一般作为二级分区而存在(当然也可以自己分区,ORACLE 11G后在分区上也可以作为主分区而存在),在RANGE基础上,若数据需要继续分区,并且在RANGE基础上数据量较为固定,只是较大,可以按照一定规则进一步分区。
HASH只指定分区个数,分区细节由ORACLE完成,增加HASH分区可以重新分布数据。
注意:分区字段不能使用函数转换后在分区,如,将某数字字符串字段,先TO_NUMER(COL_NAME)后分区。
3、索引类别
大致分:GLOBAL索引和LOCAL索引,钱和可以分:GLOBAL不分区索引,和GLOBAL分区索引。
GLOBAL不分区索引一般不太推荐,因为是用一颗大的索引树来映射一个表,这个过程,这样速度不见得比不分区快。
GLOBAL分区索引,查找数据若通过要通过索引,是先定位了索引内部的分区,然后在这个分区索引中找到ROWID,然后回表提取数据。
LOCAL索引是和分区的个数逐个对应的,可以说先定位分区表的分区也可以说先定位索引的分区,因为他们是一一对应的,找到对应分区后,分区内部索引数据集合。
4、对应应用
分区表、索引、分区索引,要利用其性能优势,最基本就是要提取数据时,要通过它首先将数据的范围缩小到一个即使做全盘扫描也不会太慢的情况。
所以SQL一定要有分区上的这个字段的一个WHERE条件,将数据迅速定位到分区内部,而且尽量定位到一个分区里面(这个和创建分区的规则有关系)。
建立分区本身不提要性能,要用好才可提高性能,在必要的RAC集群中,若存在多分区提取数据,适当采用并行提取可以提高提取的速度。
对于索引部分,这里也只提到分区索引的创建方式以及常见索引的维护方式,对于索引原理理解后会更容易认识到提取数据时的技巧。



相关推荐
Oracle数据库中的表分区是数据库管理的一种高级技术,它允许我们将大型表分解成更小、更易管理和查询的部分,从而提高数据存储和检索的效率。在本文中,我们将深入探讨Oracle表分区的各个方面,包括其重要性、类型、...
Oracle 表分区是一种高效的数据管理策略,用于处理大数据量的表,以提升查询性能和数据库的可维护性。本文将详细介绍Oracle表分区的概念、作用、优缺点,以及各种类型的分区和操作方法。 首先,理解表空间和分区表...
### Oracle表分区详解 #### 1. 表空间及分区表的概念 - **表空间**: - **定义**:表空间是Oracle数据库中的逻辑存储单元,由一个或多个数据文件组成,用于存储数据库对象(如表、索引等)。在逻辑上,表空间为...
Oracle数据库中的表分区是数据库设计中的一个重要概念,它允许我们将大型数据表划分为较小、更易管理和查询的部分。本文将深入探讨Oracle表分区的详细知识,包括其原理、类型、优势以及如何在实际操作中应用。 一、...
Oracle数据库表分区技术是数据库管理中的一项高级功能,它允许将大表划分为更小、更易管理的部分,称为分区。在Oracle中,表空间是由一个或多个数据文件组成的集合,是数据库中用于存储数据的对象。 表分区对于大型...
### Oracle表分区详解 #### 一、表空间与分区表概念 **表空间**:在Oracle数据库中,表空间是一个或多个数据文件的集合。所有数据对象(如表、索引等)都存放在特定的表空间中。由于主要存放的是表,因此被称为...
### Oracle 分区表详解 #### 一、Oracle 分区简介 Oracle 的分区技术是一种用于管理和优化超大型表和索引的有效手段。通过将一个大型的表或者索引分割成多个较小且可管理的部分,分区技术能够显著提升数据库的性能...
虽然存储介质和数据处理技术的发展也很快,但是仍然不能满足用户的需求,为了使用户的大量的数据在读写操作和查询中速度更快,Oracle提供了对表和索引进行分区的技术,以改善大型应用系统的性能。
Oracle分区表是Oracle数据库中的一种高级特性,它允许大型表和索引被划分为更小、更易于管理的部分,称为分区。这些分区可以在物理上存放在不同的表空间中,甚至可以分布在不同的磁盘上。Oracle数据库的分区技术,...
### Oracle表分区详解 在Oracle数据库管理中,为了提高数据处理效率、降低系统维护成本以及增强数据可用性,Oracle提供了多种表分区技术。本文将详细解释四种主要的表分区方式:范围分区、散列分区、列表分区和复合...
### Oracle表自动按月分区步骤详解 #### 一、背景介绍 在大数据处理与分析领域,数据库表的性能优化显得尤为重要。特别是在面对大量历史数据时,合理地利用表分区技术可以显著提高查询效率,减少资源消耗。Oracle...
本文将深入探讨Oracle分区表和分区索引的概念、应用场景和实现方式。 1. 使用分区的场景: - 数据量超过2GB的大表,因为大文件在32位操作系统上可能存在限制,并且备份时间较长。 - 包含历史数据的表,如将新数据...
Oracle数据库中的表空间和分区表是数据库管理和优化的重要概念,尤其在处理大量数据时显得尤为重要。表空间是一个逻辑存储单元,由一个或多个物理数据文件组成,用于存储数据库对象,如表、索引等。分区表则是Oracle...
Oracle分区技术提供了强大的工具来管理和优化大型表和索引。通过合理选择分区策略和正确使用分区管理功能,可以显著提高数据库性能并降低管理复杂性。在实际应用中,应根据具体的业务需求和技术环境灵活运用这些分区...
### Oracle数据库表分区实例 #### 一、Oracle表分区简介 在Oracle数据库中,表分区是一种将大型表物理地划分为多个较小部分的技术。通过合理地利用分区技术,可以显著提高查询性能,简化数据管理任务,并加快数据...