ssydxa219
- 浏览: 626260 次
- 性别:

- 来自: 杭州
-

文章分类
- 全部博客 (334)
- java core (12)
- struts2.x (2)
- spring (3)
- hibernate (8)
- jpa (6)
- maven (2)
- osgi (5)
- eclipse (4)
- struts2.x+spring2.x+hibernate 整合 (5)
- ebs (0)
- html (0)
- vaadin (1)
- css (0)
- jquery (0)
- javascript (0)
- svn (1)
- cvs (0)
- axas2.x (0)
- eclipse+maven (9)
- annotation (0)
- 基于OSGi的动态化系统搭建 (1)
- notenet (1)
- jboss eclipse (4)
- eclipse工具 (4)
- jdk1.6+maven3.0.3+nuxeo+svn+felix+cxf+spring+springDM (6)
- spring dm (1)
- Nexus介绍 (1)
- proxool listener (0)
- oracle (4)
- mysql (8)
- 搭建你的全文检索 (1)
- hibernatehibernatehibernate (0)
- cvsearchcvsearch (0)
- mycvseach (0)
- asdfasdfasdf (0)
- propertiey (0)
- hibernate annotation (0)
- libs (0)
- icam (2)
- start 数据库配置 (0)
- jboss (1)
- 让Eclipse启动时显示选择workspace的对话框 (1)
- table表头固定 (1)
- s2s3h4 (0)
- leaver (0)
- mycvsaerchddd (0)
- 关于jboss5.0.1部署 (4)
- bookmarks (0)
- PersistenceUnitDeployment (0)
- mycom (0)
- HKEY_CURRENT_USER = &H80000001 (0)
- syspath (1)
- css div (1)
- Dreamweaver CS5 (0)
- generate (0)
- mysql查看表结构命令 (1)
- LOG IN ERROR EMAIL TO SB (0)
- struts2 handle static resource (1)
- jsf (2)
- log4j (1)
- jbpm4.4 (2)
- down: jbpm4.4 (1)
- jstl1.2 (1)
- spring annotation (1)
- java design pattern (1)
- cache (1)
- ehcache (1)
- 11111 (0)
- myge (0)
- pom.xml (0)
- springquartz (0)
- OpenStack (9)
- hadoop (2)
- nginx (1)
- hadoop openstack (1)
- os (1)
- hadoop-2.6.0 zookeeper-3.4.6 hbase-0.98.9-hadoop2 集群 (5)
- hadoop2.7.0 ha Spark (2)
- tess (0)
- system (1)
- asdf (0)
- hbase (2)
- hbase create table error (1)
- ekl (1)
- gitignore (1)
- gitlab-ci.yml (1)
- shell (1)
- elasticsearch (2)
- Azkaban 3.0+ (1)
- centos用命令 (1)
- hive (1)
- kafka (1)
- CaptureBasic (0)
- CentOS7 (1)
- dev tools (1)
- README.md (1)
- Error (1)
- teamviewerd.service (1)
- scala (1)
- spark (1)
- standard (1)
- gitlab (1)
- IDEA (0)
- ApplicationContext (1)
- 传统数仓 (1)
- redis install (1)
- MYSQL AND COLUME (1)
- java版本选择 (1)
- hue (1)
- npm (1)
- es (1)
- 版本管理 (1)
- 升级npm版本 (1)
- git (1)
- 服务器参数设置 (1)
- 调大 IDEA 编译内存大小 (0)
- CentOS8安装GitLab (1)
- gitlab安装使用 (1)
最新评论
-
ssydxa219:
vim /etc/security/limits.confvi ...
ekl -
Gamehu520:
table中无数据
hbase 出现的问题 -
Xleer0102:
为什么都是只有问没有答,哭晕在厕所
hbase 出现的问题 -
jiajiao_5413:
itext table -
CoderDream:
不完整,缺com.tcs.org.demostic.pub.u ...
struts2.3.1.1+hibernate3.6.9Final+spring3.1.0+proxool+maven+annotation


# 码农规范
# 前言
- 如果这份规范中有不合理的地方,欢迎提issue/提PR等各种形式进行完善。
- 如果您有更好的代码风格未在本规范中列出,欢迎提issue/提PR等各种形式进行完善。
- 本规范最后一部分`业务规范`仅根据本人所在公司情况制定(java开发),请酌情考虑使用。
- 本project还在完善和验证中,希望和大家一起写出优雅而实用的代码。
- 大公司讲的流程&规范管理,小公司比较灵活。
# 常用开发工具统一下载
####必选
- JDK1.8 click the link & down the [jdk-8u192-linux-x64.rpm](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) file and install(rpm -ivh jdk-8u192-linux-x64.rpm) default dir /usr/java/.
- IntelliJ IDEA IDEA 2018 tar down [IntelliJ IDEA IDEA 2018 for linux](https://www.jetbrains.com/idea/download/download-thanks.html?platform=linux).
- IntelliJ IDEA IDEA 2018 exe down [IntelliJ IDEA IDEA 2018 for windows](https://www.jetbrains.com/idea/download/download-thanks.html?platform=windows).
- IntelliJ IDEA [IntelliJ IDEA 2018 注册码](http://idea.lanyus.com/)
- Download [Eclipse Technology](http://www.eclipse.org/downloads/)
- Download [Apache Maven 3.6.0](http://mirrors.hust.edu.cn/apache/maven/maven-3/3.6.0/binaries/apache-maven-3.6.0-bin.tar.gz)
- plz reg ...[Gitlab](https://t-git.51gjj.com/) windows下载git客户端[git.exe](https://git-scm.com/download/)
- Open the Haddop [WebHDFS](http://192.168.99.50:50070/dfshealth.html),plz copy (http://ddx:50070) .
- Open the YARN [MapReduce](http://192.168.99.52:8088),plz copy (http://ddy:8088) .
- Open the Hbase [Hbase Master](http://192.168.99.50:60010) & [Hbase RegionServer](http://192.168.99.52:16030) .
- Open the Spark [Spark Wen-UI](http://192.168.99.50:8080/),
- Open the NEXUS [Center Jianbing ](http://192.168.99.51:18081/nexus/content/repositories/central/)
####可选
- 下载 [【Xshell6免费版】](https://pan.baidu.com/s/1OlBSYFjdk9oDXot_V9VZUg#list/path=%2Fxshell6)
- 下载 [【EditPlus】](http://xzd.197946.com/editplus501764.zip)
- 下载 [【XMIND-windows】](https://pan.baidu.com/s/1LzCBfowvzaZaMq38tijbXA) 密码: i9tr
- 下载[【XMIND-centos】] wget https://www.xmind.net/xmind/downloads/xmind-8-update8-linux.zip -O xmind.zip
# 常用开发环境统一配置
1. hosts(windows: C:\Windows\System32\drivers\etc\hosts; linux:/etc/hosts)
- 192.168.99.50 ddx
- 192.168.99.52 ddy
- 192.168.99.51 ddz
2. ssh rsa, firewall
3. 环境变量
- Windows:
- centos:
export BASE_HOME=/d1/bin
export JAVA_HOME=/usr/java/jdk1.8.0_192-amd64
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
export SCALA_HOME=${BASE_HOME}/scala
export PATH=$PATH:${SCALA_HOME}/bin
export MAVEN_HOME=${BASE_HOME}/maven
export PATH=$PATH:${MAVEN_HOME}/bin
export ZOOKEEPER_HOME=${BASE_HOME}/zookeeper
export PATH=$PATH:${ZOOKEEPER_HOME}/bin
export HADOOP_HOME=${BASE_HOME}/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HBASE_HOME=${BASE_HOME}/hbase
export PATH=$PATH:${HBASE_HOME}/bin
export HIVE_HOME=${BASE_HOME}/hive
export PATH=$PATH:${hive_HOME}/bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SPARK_HOME=${BASE_HOME}/spark
export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
export SPARK_CLASSPATH=$HIVE_HOME/lib:$SPARK_CLASSPATH
# 常用开发文档目录统一管理
1. linux目录管理方式
2. linux目录命名结构和JAVA命名方式
3. 每一个目录下多要求一个README.MD这个文件,把自己要做的业务逻辑写进去
# 项目开发结构统一管理
[INFO] JianBing Cat 1.0.0 ................................. SUCCESS [ 0.481 s]
[INFO] cat-das ............................................ SUCCESS [ 0.010 s]
[INFO] cat-da-ods ......................................... SUCCESS [ 0.009 s]
[INFO] cat-da-od-msexp .................................... SUCCESS [ 7.915 s]
[INFO] cat-da-metas ....................................... SUCCESS [ 0.008 s]
[INFO] cat-da-meta-spiders ................................ SUCCESS [ 0.007 s]
[INFO] cat-da-meta-kafkas ................................. SUCCESS [ 0.116 s]
[INFO] cat-da-meta-kafka-server ........................... SUCCESS [ 5.878 s]
[INFO] cat-da-meta-kafka-producter ........................ SUCCESS [ 2.512 s]
[INFO] cat-da-meta-kafka-consumer ......................... SUCCESS [ 3.048 s]
[INFO] cat-da-meta-kafka-api .............................. SUCCESS [ 2.901 s]
[INFO] cat-das-ots ........................................ SUCCESS [ 42.776 s]
[INFO] cat-da-dws ......................................... SUCCESS [ 1.031 s]
[INFO] cat-da-dws-logdetail ............................... SUCCESS [ 0.008 s]
[INFO] cat-da-dws-logdetail-trace ......................... SUCCESS [ 16.119 s]
[INFO] cat-da-dms ......................................... SUCCESS [ 0.009 s]
[INFO] cat-da-mids ........................................ SUCCESS [ 0.006 s]
[INFO] cat-procs .......................................... SUCCESS [ 0.006 s]
[INFO] cat-bins ........................................... SUCCESS [ 0.006 s]
[INFO] cat-shares ......................................... SUCCESS [ 0.006 s]
[INFO] cat-share-utils .................................... SUCCESS [ 59.583 s]
[INFO] cat-bzs ............................................ SUCCESS [ 0.983 s]
[INFO] cat-times .......................................... SUCCESS [ 0.011 s]
[INFO] cat-ses ............................................ SUCCESS [ 0.009 s]
[INFO] cat-ais ............................................ SUCCESS [ 0.008 s]
[INFO] cat-etcs ........................................... SUCCESS [ 0.008 s]
[INFO] cat-apis ........................................... SUCCESS [ 0.008 s]
[INFO] cat-api-inside-reports ............................. SUCCESS [ 0.008 s]
[INFO] cat-api-outside-reports ............................ SUCCESS [ 0.009 s]
[INFO] cat-libs ........................................... SUCCESS [ 0.009 s]
[INFO] cat-lib-inside-reports ............................. SUCCESS [ 0.008 s]
[INFO] cat-lib-inside-report-drawdetail ................... SUCCESS [ 0.596 s]
[INFO] cat-lib-outside-reports ............................ SUCCESS [ 0.013 s]
[INFO] cat-lib-releases 1.0.0 ............................. SUCCESS [ 0.006 s]
[INFO] ------------------------------------------------------------------------
# 开发统一管理
## 一.命名规范
#### 1.【强制】 代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。
说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。注意,即使纯拼音命名方式也要避免采用。不会的单词请[谷歌翻译](https://translate.google.co.jp/)。
反例: `DaZhePromotion [打折] / getPingfenByName() [评分] / int 某变量 = 3`
正例: `alibaba / taobao / youku / hangzhou` 等国际通用的名称,可视同英文。
---
#### 2. 类名使用 UpperCamelCase 风格(首字母大写),必须遵从驼峰形式。
正例:`MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion `
反例:`macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion `
---
#### 3. 方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格(首字母小写),必须遵从驼峰形式。
正例: `localValue / getHttpMessage() / inputUserId`
---
#### 4. 【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例: `MAX_STOCK_COUNT`
反例: `MAX_COUNT`
---
#### 5. 【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式。
正例: 应用工具类包名为 com.java.open.util、类名为 MessageUtils(此规则参考spring 的框架结构)
---
#### 6. 杜绝完全不规范的缩写,避免望文不知义。
反例: `AbstractClass`“缩写”命名成 `AbsClass`;`condition`“缩写”命名成 `condi`,此类随意缩写严重降低了代码的可阅读性。
---
#### 7. 【推荐】如果使用到了设计模式,建议在类名中体现出具体模式。
说明:将设计模式体现在名字中,有利于阅读者快速理解架构设计思想。
正例:
```
public class OrderFactory;
public class LoginProxy;
public class ResourceObserver;
```
---
#### 8. 枚举类名建议带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。
说明:枚举其实就是特殊的常量类,且构造方法被默认强制是私有。
正例:枚举名字:`DealStatusEnum`,成员名称:`SUCCESS / UNKOWN_REASON`。
---
#### 9. 【强制】 代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
反例:` _name / __name / $Object / name_ / name$ / Object$`
---
#### 10. 【推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁性,并加上有效的 Javadoc 注释
#### 11. 源代码文件以文件内容中的最顶层的Java类命名,而且大小写敏感,文件扩展名为 .java,同时,文件的编码格式统一为UTF-8。
#### 12. 类的命名遵循大驼峰命名法UpperCamelCase,而方法名和变量名的命名遵循小驼峰命名法lowerCamelCase
常量名使用大写字母表示,单词之间以下划线分隔,例如static final int CONNECTION_TIMEOUT = 10000
---
# 二.常量定义
#### 1. 【强制】不允许出现任何魔法值(即未经定义的常量)直接出现在代码中。
反例:
```
String key = "Id#taobao_"+tradeId;
cache.put(key, value);
```
---
#### 2. 【强制】long 或者 Long 初始赋值时,必须使用大写的 L,不能是小写的 l,小写容易跟数字1 混淆,造成误解。
说明:Long a = 2l; 写的是数字的 21,还是 Long 型的 2?
---
#### 3. 【强制】不要使用一个常量类维护所有常量,应该按常量功能进行归类,分开维护。
如:缓存相关的常量放在类:CacheConsts 下;系统配置相关的常量放在类:ConfigConsts 下。
说明:大而全的常量类,非得使用查找功能才能定位到修改的常量,不利于理解和维护。
---
#### 4. 【推荐】常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包内共享常量、类内共享常量。
```
1) 跨应用共享常量:放置在二方库中,通常是 client.jar 中的 constant 目录下。
2) 应用内共享常量:放置在一方库的 modules 中的 constant 目录下。
反例:易懂变量也要统一定义成应用内共享常量,两位攻城师在两个类中分别定义了表示“是”的变量:
类 A 中:public static final String YES = "yes";
类 B 中:public static final String YES = "y";
A.YES.equals(B.YES),预期是 true,但实际返回为 false,导致产生线上问题。
3) 子工程内部共享常量:即在当前子工程的 constant 目录下。
4) 包内共享常量:即在当前包下单独的 constant 目录下。
5) 类内共享常量:直接在类内部 private static final 定义。
```
---
#### 5.【推荐】如果变量值仅在一个范围内变化,且带有名称之外的延伸属性,定义为枚举类。下面
正例中的数字就是延伸信息,表示星期几。
正例:
```
public Enum {
MONDAY(1),
TUESDAY(2),
WEDNESDAY(3),
THURSDAY(4),
FRIDAY(5),
SATURDAY(6),
SUNDAY(7);
}
```
# 三. 格式规约
#### 1. 【建议】缩进采用 4 个空格,禁止使用 tab 字符。
说明:如果使用 tab 缩进,必须设置 1 个 tab 为 4 个空格。IDEA 设置 tab 为 4 个空格时,请勿勾选 `Use tab character`;而在 eclipse 中,必须勾选 `insert spaces for tabs`。因为tab很容易造成代码对齐方式错乱,尤其在生成html文档的时候格式会乱掉。
---
#### 2. 【强制】单行字符数限制不超过 120 个,超出需要换行。
#### 3. Javadoc
标准的Javadoc常见的标记和含义如下:
```
/**
* Javadoc常见的标记
*
* @param 方法参数的说明
* @return 对方法返回值的说明
* @throws 方法抛出异常的藐视
* @version 模块的版本号
* @author 模块的作者
* @see 参考方向
* @deprecated 标记是否过时
*/
```
---
# 四. OOP规约
#### 1. 【强制】外部正在调用或者二方库依赖的接口,不允许修改方法签名,避免对接口调用方产生影响。接口过时必须加@Deprecated 注解,并清晰地说明采用的新接口或者新服务是什么。
---
#### 2. 【强制】定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值。
反例:POJO 类的 gmtCreate 默认值为 new Date(); , 但是这个属性在数据提取时并没有置入具体值,在更新其它字段时又附带更新了此字段,导致创建时间被修改成当前时间。
#### 3. 【强制】构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在 init 方法中。
---
#### 4. 【强制】POJO 类必须写 toString 方法。使用 IDE 的中工具:source> generate toString时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString。
说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排查问题。
---
#### 5. 【推荐】当一个类有多个构造方法,或者多个同名方法,这些方法应该按顺序放置在一起,便于阅读。
---
#### 6.【推荐】 类内方法定义顺序依次是:公有方法或保护方法 > 私有方法 > getter/setter方法。
说明:公有方法是类的调用者和维护者最关心的方法,首屏展示最好;
保护方法虽然只是子类关心,也可能是“模板设计模式”下的核心方法;
而私有方法外部一般不需要特别关心,是一个黑盒实现;
因为方法信息价值较低,所有 Service 和 DAO 的 getter/setter 方法放在类体最后。
---
#### 7. 【推荐】setter 方法中,参数名称与类成员变量名称一致,this.成员名 = 参数名。在getter/setter 方法中,不要增加业务逻辑,增加排查问题的难度。我曾天真的认为这种黑魔法很酷。
反例:
```
public Integer getData() {
if (true) {
return data + 100;
} else {
return data - 100;
}
}
```
---
#### 8. 【推荐】下列情况,声明成 final 会更有提示性:
1) 不需要重新赋值的变量,包括类属性、局部变量。
2) 对象参数前加 final,表示不允许修改引用的指向。
3) 类方法确定不允许被重写。
---
#### 9. 【推荐】类成员与方法访问控制从严:
1) 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。
2) 工具类不允许有 public 或 default 构造方法。
3) 类非 static 成员变量并且与子类共享,必须是 protected。
4) 类非 static 成员变量并且仅在本类使用,必须是 private。
5) 类 static 成员变量如果仅在本类使用,必须是 private。
6) 若是 static 成员变量,必须考虑是否为 final。
7) 类成员方法只供类内部调用,必须是 private。
8) 类成员方法只对继承类公开,那么限制为 protected。
说明:任何类、方法、参数、变量,严控访问范围。过于宽泛的访问范围,不利于模块解耦。
思考:如果是一个 private 的方法,想删除就删除,可是一个 public 的 service 方法,或者一个 public 的成员变量,删除一下,不得手心冒点汗吗?变量像自己的小孩,尽量在自己的视线内,变量作用域太大,如果无限制的到处跑,那么你会担心的。
---
# 四. 集合操作
#### 1. 【强制】不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator方式,如果并发操作,需要对 Iterator 对象加锁。
反例:
```
List<String> a = new ArrayList<String>();
a.add("1");
a.add("2");
for (String temp : a) {
if ("1".equals(temp)) {
a.remove(temp);
}
}
```
正例:
```
Iterator<String> it = a.iterator();
while (it.hasNext()) {
String temp = it.next();
if (删除元素的条件) {
it.remove();
}
}
```
---
# 五.异常处理
#### 1.【推荐】方法的返回值可以为 null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回 null 值。调用方需要进行 null 判断防止 NPE 问题。
---
#### 2. 【强制】对大段代码进行 try-catch,这是不负责任的表现。catch 时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的 catch 尽可能进行区分异常类型,再做对应的异常处理。
---
#### 3. 【强制】捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
---
# 六. 日志
#### 1. 【强制】直接return的情况下一定要打日志,不然根本无法判断代码没有执行还是在哪个位置被return了。
---
#### 2. 【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字 throws 往上抛出。
正例:logger.error(各类参数或者对象 toString + "_" + e.getMessage(), e);
---
#### 3. 【参考】可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。注意日志输出的级别,error 级别只记录系统逻辑出错、异常等重要的错误信息。如非必要,请不要在此场景打出 error 级别。
---
备注: 以上内容摘自<[阿里巴巴JAVA编程规范](阿里巴巴java编程规范2017版.pdf)>
---
# 7. 业务规范
#### 1. 【强制】写业务逻辑时,一定要把对应的需求链接贴在代码注释里,方便在和策划撕逼时方便决定谁该背锅。
```
// 月卡增幅 2017/01/04 http://192.168.1.88:8010/index.php?m=story&f=view&storyID=7775
if ((instanceConfig.getInstanceType() & 1) == 1) { // 个人BOSS
itemNum += extraAdd;
}
if (itemConfig.getCarrymax() > 0) {
int count = BagApiNew.getItemCount(bag, itemId) + StorageApi.getItemCount(rid, itemId);
if (count + itemNum >= itemConfig.getCarrymax()) {// 超出最大囤积上限的时候获得一部分
LOGGER.error("{}|{}|玩家领取副本【{}】奖励【itemId:{},itemNum:{},oldNum:{}】时超出上限【{}】", rid, role.get("name"), instanceConfig.getMapid(), itemId, itemNum, count, itemConfig.getCarrymax());
itemNum = itemConfig.getCarrymax() - count;
}
}
```
---
#### 2. 【强制】不要和策划口头定需求,有修改或者新增在需求里体现出来。
---
#### 3. 【强制】需求做完要自己先测试,未测出bug再打给策划。然后再和策划一起做最后bug排查和功能优化。严禁未经任何自查就扔给策划,除百你对改动的代码100%确认没有问题。
---
#### 4. 【强制】方法体一定要有注释并署名,方便找写该业务的人做BUG排查。
```
/**
* 请求打开困惑殿堂面板
*
* @param rid rid
* author: 小莫
* date: 2017-05-04 10:08
*/
public void reqOpenPanel(int rid) {
// code
}
```
---
#### 5. 【强制】方法体中决定不能出现数字(0除外),放在常量类中并加以注释。如果常量小于3个可以放在本类的顶部(参考常量定义-3)
```
package rpg.system.task.constant;
public interface TaskType {
int JIFENGFUMO = 4;
int CAIJI = 5;
int XIANGYAOFUMO = 8;
int BIG_BOSS = 10; //精英任务
int QIYUXUNHUAN = 11;
int JINDU = 12;
int TIAOZHAN = 13;
int TREASURE_BOWL = 14;// 聚宝盆
int QIYUSUIJI = 23;
int CANGYUE_ISLAND = 100;
}
```
---
#### 6. 【强制】类型和Map的key要定义常量类存放于业务模块。
正例:`uparm`模块 `constant`包中存放,以 `XxxConst`,`XxxField`命名。
```
├── uparm
│ ├── UparmManager.java
│ ├── bean
│ │ ├── ComposeBean.java
│ │ └── XilianBean.java
│ ├── constant
│ │ └── ArmFromConst.java
│ │ └── ArmField.java
│ ├── handler
│ │ ├── ReqAddQhFailNumHandler.java
│ │ ├── ReqDecomposeHandler.java
│ │ └── ReqZyqhHandler.java
```
`Field`内容例如:
```
public interface LimitTimeTaskField {
/**
* 任务接受状态
*/
int TASK_ACCEPT_STATE = 1;
/**
* 任务完成状态
*/
int TASK_COMPLETE_STATE = 2;
/**
* 限时任务消息
*/
String LIMIT_TIME_TASK_INFO = "LIMIT_TIME_TASK_INFO";
/**
* 分组id
*/
String LIMIT_TIME_TASK_GROUP_ID ="LIMIT_TIME_TASK_GROUP_ID";
}
```
#### 7. 【强制】在写业务逻辑的时候尽可能的考虑到发包情况(不要轻信客户端传过来的数据),并对发包请求进行拦截,防止非正常玩家通过BUG刷道具。
例:玩家领奖之后要给玩家存一个己领奖的flag,当再次请求的时候就不要重复发奖励了 。
# 相关资料
- [阿里巴巴Java开发手册v1.2.0-1.pdf](https://github.com/xiaomoinfo/JavaCodingStandards/blob/master/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4Java%E5%BC%80%E5%8F%91%E6%89%8B%E5%86%8Cv1.2.0-1.pdf)
- [阿里巴巴java编程规范2017版.pdf](https://github.com/xiaomoinfo/JavaCodingStandards/blob/master/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4java%E7%BC%96%E7%A8%8B%E8%A7%84%E8%8C%832017%E7%89%88.pdf)
- [Android & Java 书写简洁规范的代码](https://juejin.im/post/5971d6436fb9a06bad65659a?utm_source=gold_browser_extension)
## Gecco是什么
Gecco是一款用java语言开发的轻量化的易用的网络爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。同时Gecco基于十分开放的MIT开源协议,无论你是使用者还是希望共同完善Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请[star 或者 fork](https://gitee.com/xtuhcy/gecco)!
[参考手册](http://www.geccocrawler.com/)
## 主要特征
* [x] 简单易用,使用jquery风格的选择器抽取元素
* [x] 支持爬取规则的动态配置和加载
* [x] 支持页面中的异步ajax请求
* [x] 支持页面中的javascript变量抽取
* [x] 利用Redis实现分布式抓取,参考[gecco-redis](https://github.com/xtuhcy/gecco-redis)
* [x] 支持结合Spring开发业务逻辑,参考[gecco-spring](https://github.com/xtuhcy/gecco-spring)
* [x] 支持htmlunit扩展,参考[gecco-htmlunit](https://github.com/xtuhcy/gecco-htmlunit)
* [x] 支持插件扩展机制
* [x] 支持下载时UserAgent随机选取
* [x] 支持下载代理服务器随机选取
## 框架概述
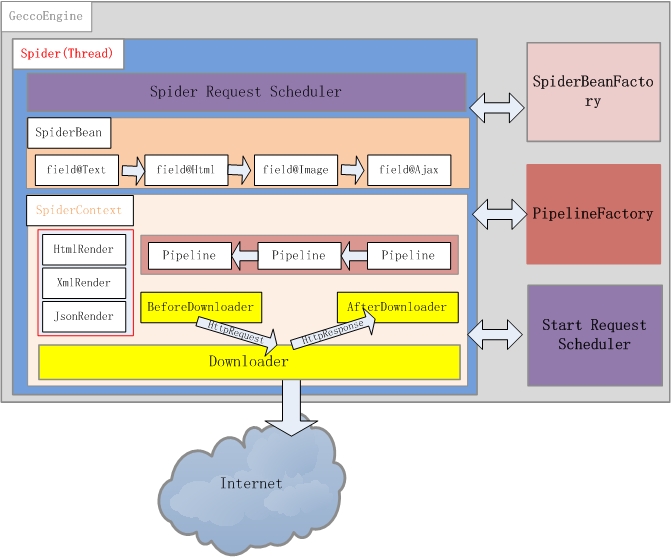
### GeccoEngine
> GeccoEngine是爬虫引擎,每个爬虫引擎最好是一个独立进程,在分布式爬虫场景下,建议每台爬虫服务器(物理机或者虚机)运行一个GeccoEngine。爬虫引擎包括Scheduler、Downloader、Spider、SpiderBeanFactory、PipelineFactory5个主要模块。
### Scheduler
> 通常爬虫需要一个有效管理下载地址的角色,Scheduler负责下载地址的管理。gecco对初始地址的管理使用StartScheduler,StartScheduler内部采用一个阻塞的FIFO的队列。初始地址通常会派生出很多其他待抓取的地址,派生出来的其他地址采用SpiderScheduler进行管理,SpiderScheduler内部采用线程安全的非阻塞FIFO队列。这种设计使的gecco对初始地址采用了深度遍历的策略,即一个线程抓取完一个初始地址后才会去抓取另外一个初始地址;对初始地址派生出来的地址,采用广度优先策略。
### Downloader
> Downloader负责从Scheduler中获取需要下载的请求,gecco默认采用httpclient4.x作为下载引擎。通过实现Downloader接口可以自定义自己的下载引擎。你也可以对每个请求定义BeforeDownload和AfterDownload,实现不同的请求下载的个性需求。
### SpiderBeanFactory
> Gecco将下载下来的内容渲染为SpiderBean,所有爬虫渲染的JavaBean都统一继承SpiderBean,SpiderBean又分为HtmlBean和JsonBean分别对应html页面的渲染和json数据的渲染。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext。上下文SpiderBeanContext会告知这个SpiderBean采用什么渲染器,采用那个下载器,渲染完成后采用哪些pipeline处理等相关上下文信息。
### PipelineFactory
> pipeline是SpiderBean渲染完成的后续业务处理单元,PipelineFactory是pipeline的工厂类,负责pipeline实例化。通过扩展PipelineFactory就可以实现和Spring等业务处理框架的整合。
### Spider
> Gecco框架最核心的类应该是Spider线程,一个爬虫引擎可以同时运行多个Spider线程。Spider描绘了这个框架运行的基本骨架,先从Scheduler获取请求,再通过SpiderBeanFactory匹配SpiderBeanClass,再通过SpiderBeanClass找到SpiderBean的上下文,下载网页并对SpiderBean做渲染,将渲染后的SpiderBean交个pipeline处理。
## 下载
### 通过Maven下载
```xml
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>x.x.x</version>
</dependency>
```

### 依赖项目
httpclient,jsoup,fastjson,reflections,cglib,rhino,log4j,jmxutils,commons-lang3
## 快速开始
```java
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -7127412585200687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("https://github.com/xtuhcy/gecco")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//非阻塞方式运行
.start();
}
}
```
## DynamicGecco
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热部署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的例子。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("https://github.com/{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("https://github.com/xtuhcy/gecco")
.run();
可以看到,DynamicGecco的方式相比传统的注解方式代码量大大减少,而且很酷的一点是DynamicGecco支持运行时定义和修改规则。
## 完整演示
[教您使用java爬虫gecco抓取JD全部商品信息(一)](http://my.oschina.net/u/2336761/blog/620158)
[教您使用java爬虫gecco抓取JD全部商品信息(二)](http://my.oschina.net/u/2336761/blog/620827)
[教您使用java爬虫gecco抓取JD全部商品信息(三)](http://my.oschina.net/u/2336761/blog/624683)
[集成Htmlunit下载页面](http://my.oschina.net/u/2336761/blog/631959)
[爬虫的监控](http://my.oschina.net/u/2336761/blog/644330)
[一个完整的例子,分页处理,结合spring,mysql入库](http://git.oschina.net/xiaomaoguai/gecco-demo)
## 交流联系
## 请作者喝杯咖啡
Gecco的发展离不开大家支持,扫一扫请作者喝杯咖啡~


## 开源协议
请遵守开源协议[MIT](https://raw.githubusercontent.com/xtuhcy/gecco/master/LICENSE)

# 码农规范
# 前言
- 如果这份规范中有不合理的地方,欢迎提issue/提PR等各种形式进行完善。
- 如果您有更好的代码风格未在本规范中列出,欢迎提issue/提PR等各种形式进行完善。
- 本规范最后一部分`业务规范`仅根据本人所在公司情况制定(java开发),请酌情考虑使用。
- 本project还在完善和验证中,希望和大家一起写出优雅而实用的代码。
- 大公司讲的流程&规范管理,小公司比较灵活。
# 常用开发工具统一下载
####必选
- JDK1.8 click the link & down the [jdk-8u192-linux-x64.rpm](https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html) file and install(rpm -ivh jdk-8u192-linux-x64.rpm) default dir /usr/java/.
- IntelliJ IDEA IDEA 2018 tar down [IntelliJ IDEA IDEA 2018 for linux](https://www.jetbrains.com/idea/download/download-thanks.html?platform=linux).
- IntelliJ IDEA IDEA 2018 exe down [IntelliJ IDEA IDEA 2018 for windows](https://www.jetbrains.com/idea/download/download-thanks.html?platform=windows).
- IntelliJ IDEA [IntelliJ IDEA 2018 注册码](http://idea.lanyus.com/)
- Download [Eclipse Technology](http://www.eclipse.org/downloads/)
- Download [Apache Maven 3.6.0](http://mirrors.hust.edu.cn/apache/maven/maven-3/3.6.0/binaries/apache-maven-3.6.0-bin.tar.gz)
- plz reg ...[Gitlab](https://t-git.51gjj.com/) windows下载git客户端[git.exe](https://git-scm.com/download/)
- Open the Haddop [WebHDFS](http://192.168.99.50:50070/dfshealth.html),plz copy (http://ddx:50070) .
- Open the YARN [MapReduce](http://192.168.99.52:8088),plz copy (http://ddy:8088) .
- Open the Hbase [Hbase Master](http://192.168.99.50:60010) & [Hbase RegionServer](http://192.168.99.52:16030) .
- Open the Spark [Spark Wen-UI](http://192.168.99.50:8080/),
- Open the NEXUS [Center Jianbing ](http://192.168.99.51:18081/nexus/content/repositories/central/)
####可选
- 下载 [【Xshell6免费版】](https://pan.baidu.com/s/1OlBSYFjdk9oDXot_V9VZUg#list/path=%2Fxshell6)
- 下载 [【EditPlus】](http://xzd.197946.com/editplus501764.zip)
- 下载 [【XMIND-windows】](https://pan.baidu.com/s/1LzCBfowvzaZaMq38tijbXA) 密码: i9tr
- 下载[【XMIND-centos】] wget https://www.xmind.net/xmind/downloads/xmind-8-update8-linux.zip -O xmind.zip
# 常用开发环境统一配置
1. hosts(windows: C:\Windows\System32\drivers\etc\hosts; linux:/etc/hosts)
- 192.168.99.50 ddx
- 192.168.99.52 ddy
- 192.168.99.51 ddz
2. ssh rsa, firewall
3. 环境变量
- Windows:
- centos:
export BASE_HOME=/d1/bin
export JAVA_HOME=/usr/java/jdk1.8.0_192-amd64
export CLASSPATH=.:${JAVA_HOME}/jre/lib/rt.jar:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar
export PATH=$PATH:${JAVA_HOME}/bin
export SCALA_HOME=${BASE_HOME}/scala
export PATH=$PATH:${SCALA_HOME}/bin
export MAVEN_HOME=${BASE_HOME}/maven
export PATH=$PATH:${MAVEN_HOME}/bin
export ZOOKEEPER_HOME=${BASE_HOME}/zookeeper
export PATH=$PATH:${ZOOKEEPER_HOME}/bin
export HADOOP_HOME=${BASE_HOME}/hadoop
export HADOOP_PREFIX=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_HOME=$HADOOP_HOME
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_INSTALL=$HADOOP_HOME
export HBASE_HOME=${BASE_HOME}/hbase
export PATH=$PATH:${HBASE_HOME}/bin
export HIVE_HOME=${BASE_HOME}/hive
export PATH=$PATH:${hive_HOME}/bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SPARK_HOME=${BASE_HOME}/spark
export PATH=$PATH:${SPARK_HOME}/bin:${SPARK_HOME}/sbin
export SPARK_CLASSPATH=$HIVE_HOME/lib:$SPARK_CLASSPATH
# 常用开发文档目录统一管理
1. linux目录管理方式
2. linux目录命名结构和JAVA命名方式
3. 每一个目录下多要求一个README.MD这个文件,把自己要做的业务逻辑写进去
# 项目开发结构统一管理
[INFO] JianBing Cat 1.0.0 ................................. SUCCESS [ 0.481 s]
[INFO] cat-das ............................................ SUCCESS [ 0.010 s]
[INFO] cat-da-ods ......................................... SUCCESS [ 0.009 s]
[INFO] cat-da-od-msexp .................................... SUCCESS [ 7.915 s]
[INFO] cat-da-metas ....................................... SUCCESS [ 0.008 s]
[INFO] cat-da-meta-spiders ................................ SUCCESS [ 0.007 s]
[INFO] cat-da-meta-kafkas ................................. SUCCESS [ 0.116 s]
[INFO] cat-da-meta-kafka-server ........................... SUCCESS [ 5.878 s]
[INFO] cat-da-meta-kafka-producter ........................ SUCCESS [ 2.512 s]
[INFO] cat-da-meta-kafka-consumer ......................... SUCCESS [ 3.048 s]
[INFO] cat-da-meta-kafka-api .............................. SUCCESS [ 2.901 s]
[INFO] cat-das-ots ........................................ SUCCESS [ 42.776 s]
[INFO] cat-da-dws ......................................... SUCCESS [ 1.031 s]
[INFO] cat-da-dws-logdetail ............................... SUCCESS [ 0.008 s]
[INFO] cat-da-dws-logdetail-trace ......................... SUCCESS [ 16.119 s]
[INFO] cat-da-dms ......................................... SUCCESS [ 0.009 s]
[INFO] cat-da-mids ........................................ SUCCESS [ 0.006 s]
[INFO] cat-procs .......................................... SUCCESS [ 0.006 s]
[INFO] cat-bins ........................................... SUCCESS [ 0.006 s]
[INFO] cat-shares ......................................... SUCCESS [ 0.006 s]
[INFO] cat-share-utils .................................... SUCCESS [ 59.583 s]
[INFO] cat-bzs ............................................ SUCCESS [ 0.983 s]
[INFO] cat-times .......................................... SUCCESS [ 0.011 s]
[INFO] cat-ses ............................................ SUCCESS [ 0.009 s]
[INFO] cat-ais ............................................ SUCCESS [ 0.008 s]
[INFO] cat-etcs ........................................... SUCCESS [ 0.008 s]
[INFO] cat-apis ........................................... SUCCESS [ 0.008 s]
[INFO] cat-api-inside-reports ............................. SUCCESS [ 0.008 s]
[INFO] cat-api-outside-reports ............................ SUCCESS [ 0.009 s]
[INFO] cat-libs ........................................... SUCCESS [ 0.009 s]
[INFO] cat-lib-inside-reports ............................. SUCCESS [ 0.008 s]
[INFO] cat-lib-inside-report-drawdetail ................... SUCCESS [ 0.596 s]
[INFO] cat-lib-outside-reports ............................ SUCCESS [ 0.013 s]
[INFO] cat-lib-releases 1.0.0 ............................. SUCCESS [ 0.006 s]
[INFO] ------------------------------------------------------------------------
# 开发统一管理
## 一.命名规范
#### 1.【强制】 代码中的命名严禁使用拼音与英文混合的方式,更不允许直接使用中文的方式。
说明:正确的英文拼写和语法可以让阅读者易于理解,避免歧义。注意,即使纯拼音命名方式也要避免采用。不会的单词请[谷歌翻译](https://translate.google.co.jp/)。
反例: `DaZhePromotion [打折] / getPingfenByName() [评分] / int 某变量 = 3`
正例: `alibaba / taobao / youku / hangzhou` 等国际通用的名称,可视同英文。
---
#### 2. 类名使用 UpperCamelCase 风格(首字母大写),必须遵从驼峰形式。
正例:`MarcoPolo / UserDO / XmlService / TcpUdpDeal / TaPromotion `
反例:`macroPolo / UserDo / XMLService / TCPUDPDeal / TAPromotion `
---
#### 3. 方法名、参数名、成员变量、局部变量都统一使用 lowerCamelCase 风格(首字母小写),必须遵从驼峰形式。
正例: `localValue / getHttpMessage() / inputUserId`
---
#### 4. 【强制】常量命名全部大写,单词间用下划线隔开,力求语义表达完整清楚,不要嫌名字长。
正例: `MAX_STOCK_COUNT`
反例: `MAX_COUNT`
---
#### 5. 【强制】包名统一使用小写,点分隔符之间有且仅有一个自然语义的英语单词。包名统一使用单数形式,但是类名如果有复数含义,类名可以使用复数形式。
正例: 应用工具类包名为 com.java.open.util、类名为 MessageUtils(此规则参考spring 的框架结构)
---
#### 6. 杜绝完全不规范的缩写,避免望文不知义。
反例: `AbstractClass`“缩写”命名成 `AbsClass`;`condition`“缩写”命名成 `condi`,此类随意缩写严重降低了代码的可阅读性。
---
#### 7. 【推荐】如果使用到了设计模式,建议在类名中体现出具体模式。
说明:将设计模式体现在名字中,有利于阅读者快速理解架构设计思想。
正例:
```
public class OrderFactory;
public class LoginProxy;
public class ResourceObserver;
```
---
#### 8. 枚举类名建议带上 Enum 后缀,枚举成员名称需要全大写,单词间用下划线隔开。
说明:枚举其实就是特殊的常量类,且构造方法被默认强制是私有。
正例:枚举名字:`DealStatusEnum`,成员名称:`SUCCESS / UNKOWN_REASON`。
---
#### 9. 【强制】 代码中的命名均不能以下划线或美元符号开始,也不能以下划线或美元符号结束。
反例:` _name / __name / $Object / name_ / name$ / Object$`
---
#### 10. 【推荐】接口类中的方法和属性不要加任何修饰符号(public 也不要加),保持代码的简洁性,并加上有效的 Javadoc 注释
#### 11. 源代码文件以文件内容中的最顶层的Java类命名,而且大小写敏感,文件扩展名为 .java,同时,文件的编码格式统一为UTF-8。
#### 12. 类的命名遵循大驼峰命名法UpperCamelCase,而方法名和变量名的命名遵循小驼峰命名法lowerCamelCase
常量名使用大写字母表示,单词之间以下划线分隔,例如static final int CONNECTION_TIMEOUT = 10000
---
# 二.常量定义
#### 1. 【强制】不允许出现任何魔法值(即未经定义的常量)直接出现在代码中。
反例:
```
String key = "Id#taobao_"+tradeId;
cache.put(key, value);
```
---
#### 2. 【强制】long 或者 Long 初始赋值时,必须使用大写的 L,不能是小写的 l,小写容易跟数字1 混淆,造成误解。
说明:Long a = 2l; 写的是数字的 21,还是 Long 型的 2?
---
#### 3. 【强制】不要使用一个常量类维护所有常量,应该按常量功能进行归类,分开维护。
如:缓存相关的常量放在类:CacheConsts 下;系统配置相关的常量放在类:ConfigConsts 下。
说明:大而全的常量类,非得使用查找功能才能定位到修改的常量,不利于理解和维护。
---
#### 4. 【推荐】常量的复用层次有五层:跨应用共享常量、应用内共享常量、子工程内共享常量、包内共享常量、类内共享常量。
```
1) 跨应用共享常量:放置在二方库中,通常是 client.jar 中的 constant 目录下。
2) 应用内共享常量:放置在一方库的 modules 中的 constant 目录下。
反例:易懂变量也要统一定义成应用内共享常量,两位攻城师在两个类中分别定义了表示“是”的变量:
类 A 中:public static final String YES = "yes";
类 B 中:public static final String YES = "y";
A.YES.equals(B.YES),预期是 true,但实际返回为 false,导致产生线上问题。
3) 子工程内部共享常量:即在当前子工程的 constant 目录下。
4) 包内共享常量:即在当前包下单独的 constant 目录下。
5) 类内共享常量:直接在类内部 private static final 定义。
```
---
#### 5.【推荐】如果变量值仅在一个范围内变化,且带有名称之外的延伸属性,定义为枚举类。下面
正例中的数字就是延伸信息,表示星期几。
正例:
```
public Enum {
MONDAY(1),
TUESDAY(2),
WEDNESDAY(3),
THURSDAY(4),
FRIDAY(5),
SATURDAY(6),
SUNDAY(7);
}
```
# 三. 格式规约
#### 1. 【建议】缩进采用 4 个空格,禁止使用 tab 字符。
说明:如果使用 tab 缩进,必须设置 1 个 tab 为 4 个空格。IDEA 设置 tab 为 4 个空格时,请勿勾选 `Use tab character`;而在 eclipse 中,必须勾选 `insert spaces for tabs`。因为tab很容易造成代码对齐方式错乱,尤其在生成html文档的时候格式会乱掉。
---
#### 2. 【强制】单行字符数限制不超过 120 个,超出需要换行。
#### 3. Javadoc
标准的Javadoc常见的标记和含义如下:
```
/**
* Javadoc常见的标记
*
* @param 方法参数的说明
* @return 对方法返回值的说明
* @throws 方法抛出异常的藐视
* @version 模块的版本号
* @author 模块的作者
* @see 参考方向
* @deprecated 标记是否过时
*/
```
---
# 四. OOP规约
#### 1. 【强制】外部正在调用或者二方库依赖的接口,不允许修改方法签名,避免对接口调用方产生影响。接口过时必须加@Deprecated 注解,并清晰地说明采用的新接口或者新服务是什么。
---
#### 2. 【强制】定义 DO/DTO/VO 等 POJO 类时,不要设定任何属性默认值。
反例:POJO 类的 gmtCreate 默认值为 new Date(); , 但是这个属性在数据提取时并没有置入具体值,在更新其它字段时又附带更新了此字段,导致创建时间被修改成当前时间。
#### 3. 【强制】构造方法里面禁止加入任何业务逻辑,如果有初始化逻辑,请放在 init 方法中。
---
#### 4. 【强制】POJO 类必须写 toString 方法。使用 IDE 的中工具:source> generate toString时,如果继承了另一个 POJO 类,注意在前面加一下 super.toString。
说明:在方法执行抛出异常时,可以直接调用 POJO 的 toString()方法打印其属性值,便于排查问题。
---
#### 5. 【推荐】当一个类有多个构造方法,或者多个同名方法,这些方法应该按顺序放置在一起,便于阅读。
---
#### 6.【推荐】 类内方法定义顺序依次是:公有方法或保护方法 > 私有方法 > getter/setter方法。
说明:公有方法是类的调用者和维护者最关心的方法,首屏展示最好;
保护方法虽然只是子类关心,也可能是“模板设计模式”下的核心方法;
而私有方法外部一般不需要特别关心,是一个黑盒实现;
因为方法信息价值较低,所有 Service 和 DAO 的 getter/setter 方法放在类体最后。
---
#### 7. 【推荐】setter 方法中,参数名称与类成员变量名称一致,this.成员名 = 参数名。在getter/setter 方法中,不要增加业务逻辑,增加排查问题的难度。我曾天真的认为这种黑魔法很酷。
反例:
```
public Integer getData() {
if (true) {
return data + 100;
} else {
return data - 100;
}
}
```
---
#### 8. 【推荐】下列情况,声明成 final 会更有提示性:
1) 不需要重新赋值的变量,包括类属性、局部变量。
2) 对象参数前加 final,表示不允许修改引用的指向。
3) 类方法确定不允许被重写。
---
#### 9. 【推荐】类成员与方法访问控制从严:
1) 如果不允许外部直接通过 new 来创建对象,那么构造方法必须是 private。
2) 工具类不允许有 public 或 default 构造方法。
3) 类非 static 成员变量并且与子类共享,必须是 protected。
4) 类非 static 成员变量并且仅在本类使用,必须是 private。
5) 类 static 成员变量如果仅在本类使用,必须是 private。
6) 若是 static 成员变量,必须考虑是否为 final。
7) 类成员方法只供类内部调用,必须是 private。
8) 类成员方法只对继承类公开,那么限制为 protected。
说明:任何类、方法、参数、变量,严控访问范围。过于宽泛的访问范围,不利于模块解耦。
思考:如果是一个 private 的方法,想删除就删除,可是一个 public 的 service 方法,或者一个 public 的成员变量,删除一下,不得手心冒点汗吗?变量像自己的小孩,尽量在自己的视线内,变量作用域太大,如果无限制的到处跑,那么你会担心的。
---
# 四. 集合操作
#### 1. 【强制】不要在 foreach 循环里进行元素的 remove/add 操作。remove 元素请使用 Iterator方式,如果并发操作,需要对 Iterator 对象加锁。
反例:
```
List<String> a = new ArrayList<String>();
a.add("1");
a.add("2");
for (String temp : a) {
if ("1".equals(temp)) {
a.remove(temp);
}
}
```
正例:
```
Iterator<String> it = a.iterator();
while (it.hasNext()) {
String temp = it.next();
if (删除元素的条件) {
it.remove();
}
}
```
---
# 五.异常处理
#### 1.【推荐】方法的返回值可以为 null,不强制返回空集合,或者空对象等,必须添加注释充分说明什么情况下会返回 null 值。调用方需要进行 null 判断防止 NPE 问题。
---
#### 2. 【强制】对大段代码进行 try-catch,这是不负责任的表现。catch 时请分清稳定代码和非稳定代码,稳定代码指的是无论如何不会出错的代码。对于非稳定代码的 catch 尽可能进行区分异常类型,再做对应的异常处理。
---
#### 3. 【强制】捕获异常是为了处理它,不要捕获了却什么都不处理而抛弃之,如果不想处理它,请将该异常抛给它的调用者。最外层的业务使用者,必须处理异常,将其转化为用户可以理解的内容。
---
# 六. 日志
#### 1. 【强制】直接return的情况下一定要打日志,不然根本无法判断代码没有执行还是在哪个位置被return了。
---
#### 2. 【强制】异常信息应该包括两类信息:案发现场信息和异常堆栈信息。如果不处理,那么通过关键字 throws 往上抛出。
正例:logger.error(各类参数或者对象 toString + "_" + e.getMessage(), e);
---
#### 3. 【参考】可以使用 warn 日志级别来记录用户输入参数错误的情况,避免用户投诉时,无所适从。注意日志输出的级别,error 级别只记录系统逻辑出错、异常等重要的错误信息。如非必要,请不要在此场景打出 error 级别。
---
备注: 以上内容摘自<[阿里巴巴JAVA编程规范](阿里巴巴java编程规范2017版.pdf)>
---
# 7. 业务规范
#### 1. 【强制】写业务逻辑时,一定要把对应的需求链接贴在代码注释里,方便在和策划撕逼时方便决定谁该背锅。
```
// 月卡增幅 2017/01/04 http://192.168.1.88:8010/index.php?m=story&f=view&storyID=7775
if ((instanceConfig.getInstanceType() & 1) == 1) { // 个人BOSS
itemNum += extraAdd;
}
if (itemConfig.getCarrymax() > 0) {
int count = BagApiNew.getItemCount(bag, itemId) + StorageApi.getItemCount(rid, itemId);
if (count + itemNum >= itemConfig.getCarrymax()) {// 超出最大囤积上限的时候获得一部分
LOGGER.error("{}|{}|玩家领取副本【{}】奖励【itemId:{},itemNum:{},oldNum:{}】时超出上限【{}】", rid, role.get("name"), instanceConfig.getMapid(), itemId, itemNum, count, itemConfig.getCarrymax());
itemNum = itemConfig.getCarrymax() - count;
}
}
```
---
#### 2. 【强制】不要和策划口头定需求,有修改或者新增在需求里体现出来。
---
#### 3. 【强制】需求做完要自己先测试,未测出bug再打给策划。然后再和策划一起做最后bug排查和功能优化。严禁未经任何自查就扔给策划,除百你对改动的代码100%确认没有问题。
---
#### 4. 【强制】方法体一定要有注释并署名,方便找写该业务的人做BUG排查。
```
/**
* 请求打开困惑殿堂面板
*
* @param rid rid
* author: 小莫
* date: 2017-05-04 10:08
*/
public void reqOpenPanel(int rid) {
// code
}
```
---
#### 5. 【强制】方法体中决定不能出现数字(0除外),放在常量类中并加以注释。如果常量小于3个可以放在本类的顶部(参考常量定义-3)
```
package rpg.system.task.constant;
public interface TaskType {
int JIFENGFUMO = 4;
int CAIJI = 5;
int XIANGYAOFUMO = 8;
int BIG_BOSS = 10; //精英任务
int QIYUXUNHUAN = 11;
int JINDU = 12;
int TIAOZHAN = 13;
int TREASURE_BOWL = 14;// 聚宝盆
int QIYUSUIJI = 23;
int CANGYUE_ISLAND = 100;
}
```
---
#### 6. 【强制】类型和Map的key要定义常量类存放于业务模块。
正例:`uparm`模块 `constant`包中存放,以 `XxxConst`,`XxxField`命名。
```
├── uparm
│ ├── UparmManager.java
│ ├── bean
│ │ ├── ComposeBean.java
│ │ └── XilianBean.java
│ ├── constant
│ │ └── ArmFromConst.java
│ │ └── ArmField.java
│ ├── handler
│ │ ├── ReqAddQhFailNumHandler.java
│ │ ├── ReqDecomposeHandler.java
│ │ └── ReqZyqhHandler.java
```
`Field`内容例如:
```
public interface LimitTimeTaskField {
/**
* 任务接受状态
*/
int TASK_ACCEPT_STATE = 1;
/**
* 任务完成状态
*/
int TASK_COMPLETE_STATE = 2;
/**
* 限时任务消息
*/
String LIMIT_TIME_TASK_INFO = "LIMIT_TIME_TASK_INFO";
/**
* 分组id
*/
String LIMIT_TIME_TASK_GROUP_ID ="LIMIT_TIME_TASK_GROUP_ID";
}
```
#### 7. 【强制】在写业务逻辑的时候尽可能的考虑到发包情况(不要轻信客户端传过来的数据),并对发包请求进行拦截,防止非正常玩家通过BUG刷道具。
例:玩家领奖之后要给玩家存一个己领奖的flag,当再次请求的时候就不要重复发奖励了 。
# 相关资料
- [阿里巴巴Java开发手册v1.2.0-1.pdf](https://github.com/xiaomoinfo/JavaCodingStandards/blob/master/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4Java%E5%BC%80%E5%8F%91%E6%89%8B%E5%86%8Cv1.2.0-1.pdf)
- [阿里巴巴java编程规范2017版.pdf](https://github.com/xiaomoinfo/JavaCodingStandards/blob/master/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4java%E7%BC%96%E7%A8%8B%E8%A7%84%E8%8C%832017%E7%89%88.pdf)
- [Android & Java 书写简洁规范的代码](https://juejin.im/post/5971d6436fb9a06bad65659a?utm_source=gold_browser_extension)
## Gecco是什么
Gecco是一款用java语言开发的轻量化的易用的网络爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只需要配置一些jquery风格的选择器就能很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对修改关闭、对扩展开放。同时Gecco基于十分开放的MIT开源协议,无论你是使用者还是希望共同完善Gecco的开发者,欢迎pull request。如果你喜欢这款爬虫框架请[star 或者 fork](https://gitee.com/xtuhcy/gecco)!
[参考手册](http://www.geccocrawler.com/)
## 主要特征
* [x] 简单易用,使用jquery风格的选择器抽取元素
* [x] 支持爬取规则的动态配置和加载
* [x] 支持页面中的异步ajax请求
* [x] 支持页面中的javascript变量抽取
* [x] 利用Redis实现分布式抓取,参考[gecco-redis](https://github.com/xtuhcy/gecco-redis)
* [x] 支持结合Spring开发业务逻辑,参考[gecco-spring](https://github.com/xtuhcy/gecco-spring)
* [x] 支持htmlunit扩展,参考[gecco-htmlunit](https://github.com/xtuhcy/gecco-htmlunit)
* [x] 支持插件扩展机制
* [x] 支持下载时UserAgent随机选取
* [x] 支持下载代理服务器随机选取
## 框架概述

### GeccoEngine
> GeccoEngine是爬虫引擎,每个爬虫引擎最好是一个独立进程,在分布式爬虫场景下,建议每台爬虫服务器(物理机或者虚机)运行一个GeccoEngine。爬虫引擎包括Scheduler、Downloader、Spider、SpiderBeanFactory、PipelineFactory5个主要模块。
### Scheduler
> 通常爬虫需要一个有效管理下载地址的角色,Scheduler负责下载地址的管理。gecco对初始地址的管理使用StartScheduler,StartScheduler内部采用一个阻塞的FIFO的队列。初始地址通常会派生出很多其他待抓取的地址,派生出来的其他地址采用SpiderScheduler进行管理,SpiderScheduler内部采用线程安全的非阻塞FIFO队列。这种设计使的gecco对初始地址采用了深度遍历的策略,即一个线程抓取完一个初始地址后才会去抓取另外一个初始地址;对初始地址派生出来的地址,采用广度优先策略。
### Downloader
> Downloader负责从Scheduler中获取需要下载的请求,gecco默认采用httpclient4.x作为下载引擎。通过实现Downloader接口可以自定义自己的下载引擎。你也可以对每个请求定义BeforeDownload和AfterDownload,实现不同的请求下载的个性需求。
### SpiderBeanFactory
> Gecco将下载下来的内容渲染为SpiderBean,所有爬虫渲染的JavaBean都统一继承SpiderBean,SpiderBean又分为HtmlBean和JsonBean分别对应html页面的渲染和json数据的渲染。SpiderBeanFactroy会根据请求的url地址,匹配相应的SpiderBean,同时生成该SpiderBean的上下文SpiderBeanContext。上下文SpiderBeanContext会告知这个SpiderBean采用什么渲染器,采用那个下载器,渲染完成后采用哪些pipeline处理等相关上下文信息。
### PipelineFactory
> pipeline是SpiderBean渲染完成的后续业务处理单元,PipelineFactory是pipeline的工厂类,负责pipeline实例化。通过扩展PipelineFactory就可以实现和Spring等业务处理框架的整合。
### Spider
> Gecco框架最核心的类应该是Spider线程,一个爬虫引擎可以同时运行多个Spider线程。Spider描绘了这个框架运行的基本骨架,先从Scheduler获取请求,再通过SpiderBeanFactory匹配SpiderBeanClass,再通过SpiderBeanClass找到SpiderBean的上下文,下载网页并对SpiderBean做渲染,将渲染后的SpiderBean交个pipeline处理。
## 下载
### 通过Maven下载
```xml
<dependency>
<groupId>com.geccocrawler</groupId>
<artifactId>gecco</artifactId>
<version>x.x.x</version>
</dependency>
```

### 依赖项目
httpclient,jsoup,fastjson,reflections,cglib,rhino,log4j,jmxutils,commons-lang3
## 快速开始
```java
@Gecco(matchUrl="https://github.com/{user}/{project}", pipelines="consolePipeline")
public class MyGithub implements HtmlBean {
private static final long serialVersionUID = -7127412585200687225L;
@RequestParameter("user")
private String user;//url中的{user}值
@RequestParameter("project")
private String project;//url中的{project}值
@Text
@HtmlField(cssPath=".repository-meta-content")
private String title;//抽取页面中的title
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(2) .social-count")
private int star;//抽取页面中的star
@Text
@HtmlField(cssPath=".pagehead-actions li:nth-child(3) .social-count")
private int fork;//抽取页面中的fork
@Html
@HtmlField(cssPath=".entry-content")
private String readme;//抽取页面中的readme
public String getReadme() {
return readme;
}
public void setReadme(String readme) {
this.readme = readme;
}
public String getUser() {
return user;
}
public void setUser(String user) {
this.user = user;
}
public String getProject() {
return project;
}
public void setProject(String project) {
this.project = project;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public int getStar() {
return star;
}
public void setStar(int star) {
this.star = star;
}
public int getFork() {
return fork;
}
public void setFork(int fork) {
this.fork = fork;
}
public static void main(String[] args) {
GeccoEngine.create()
//工程的包路径
.classpath("com.geccocrawler.gecco.demo")
//开始抓取的页面地址
.start("https://github.com/xtuhcy/gecco")
//开启几个爬虫线程
.thread(1)
//单个爬虫每次抓取完一个请求后的间隔时间
.interval(2000)
//循环抓取
.loop(true)
//使用pc端userAgent
.mobile(false)
//非阻塞方式运行
.start();
}
}
```
## DynamicGecco
DynamicGecco的目的是在不定义SpiderBean的情况下实现爬取规则的运行时配置。其实现原理是采用字节码编程,动态生成SpiderBean,而且通过自定义的GeccoClassLoader实现了抓取规则的热部署。下面是一个简单Demo,更复杂的Demo可以参考com.geccocrawler.gecco.demo.dynamic下的例子。
下面的代码实现了爬取规则的运行时配置:
DynamicGecco.html()
.gecco("https://github.com/{user}/{project}", "consolePipeline")
.requestField("request").request().build()
.stringField("user").requestParameter("user").build()
.stringField("project").requestParameter().build()
.stringField("title").csspath(".repository-meta-content").text(false).build()
.intField("star").csspath(".pagehead-actions li:nth-child(2) .social-count").text(false).build()
.intField("fork").csspath(".pagehead-actions li:nth-child(3) .social-count").text().build()
.stringField("contributors").csspath("ul.numbers-summary > li:nth-child(4) > a").href().build()
.register();
//开始抓取
GeccoEngine.create()
.classpath("com.geccocrawler.gecco.demo")
.start("https://github.com/xtuhcy/gecco")
.run();
可以看到,DynamicGecco的方式相比传统的注解方式代码量大大减少,而且很酷的一点是DynamicGecco支持运行时定义和修改规则。
## 完整演示
[教您使用java爬虫gecco抓取JD全部商品信息(一)](http://my.oschina.net/u/2336761/blog/620158)
[教您使用java爬虫gecco抓取JD全部商品信息(二)](http://my.oschina.net/u/2336761/blog/620827)
[教您使用java爬虫gecco抓取JD全部商品信息(三)](http://my.oschina.net/u/2336761/blog/624683)
[集成Htmlunit下载页面](http://my.oschina.net/u/2336761/blog/631959)
[爬虫的监控](http://my.oschina.net/u/2336761/blog/644330)
[一个完整的例子,分页处理,结合spring,mysql入库](http://git.oschina.net/xiaomaoguai/gecco-demo)
## 交流联系
## 请作者喝杯咖啡
Gecco的发展离不开大家支持,扫一扫请作者喝杯咖啡~


## 开源协议
请遵守开源协议[MIT](https://raw.githubusercontent.com/xtuhcy/gecco/master/LICENSE)
分享到:


发表评论

相关推荐
《Unity2018版本Standard Assets深度解析》 Unity3D作为一款强大的跨平台游戏开发引擎,其内置的Standard Assets库是开发者们不可或缺的资源集合。Standard Assets包含了各种预设的材质、粒子系统、动画、物理组件...
在Java Web开发中,"standard-1.1.2.jar"和"jstl-1.1.2.jar"是两个非常重要的库文件,它们主要用于处理JSP页面中的标签库。这两个库文件在使用时必须确保版本匹配,因为不同版本之间可能存在兼容性问题,不一致的...
开发工具 taglibs-standard-impl-1.2.5开发工具 taglibs-standard-impl-1.2.5开发工具 taglibs-standard-impl-1.2.5开发工具 taglibs-standard-impl-1.2.5开发工具 taglibs-standard-impl-1.2.5开发工具 taglibs-...
开发工具 taglibs-standard-spec-1.2.5开发工具 taglibs-standard-spec-1.2.5开发工具 taglibs-standard-spec-1.2.5开发工具 taglibs-standard-spec-1.2.5开发工具 taglibs-standard-spec-1.2.5开发工具 taglibs-...
"jakarta-taglibs-standard-1.1.2.rar"是一个包含Jakarta Taglibs标准版1.1.2版本的压缩包文件,这个版本在当时是广泛使用的。下面我们将深入探讨Jakarta Taglibs、标准标签库以及它们与Struts框架的关系。 Jakarta...
而`jstl.jar`和`standard.jar`是JSP开发中两个重要的库文件,主要用于提供JSTL(JavaServer Pages Standard Tag Library)标准标签库的支持。 JSTL是由Apache软件基金会的Tomcat项目开发的,它为JSP提供了一套标准...
### AHRI Standard 210/240:单元式空调及空气源热泵设备性能评级标准 #### 标准概述 AHRI Standard 210/240(前身为ARI Standard 210/240)是关于单元式空调及空气源热泵设备性能评级的标准,由美国空调、供暖与...
(一开始在替换的过程中想当然的用JSTL1.1.jar换JSTL1.2.jar,然后遗漏了standard-1.1.jar,耽搁了不少时间。) 经测试,tomcat6.0支持JSTL1.2版本,也支持JSTL1.1版本;tomcat5.5只支持JSTL1.1(JSTL1.1一下版本未...
**JSTL.jar和standard.jar包详解** 在Java Web开发中,JSTL(JavaServer Pages Standard Tag Library)和standard.jar是两个非常重要的组件,它们主要用于简化JSP页面的编程,提高代码的可读性和可维护性。这两个库...
SAP-17LSMW 使用 Standard Batch 导入 BOM SAP-17LSMW 是 SAP 系统中的一种数据导入工具,使用 Standard Batch 可以将批量数据导入到 SAP 系统中。以下是在 SAP-17LSMW 中使用 Standard Batch 导入 BOM(物料清单)...
JSTL的核心库是`jstl.jar`,它包含了一系列基础标签,而`standard.jar`(通常与`jakarta-standard.jar`一起被提及,但在这个案例中指的是`standard-1.1.2.jar`)则是JSTL的另一个必需组件,它提供了Servlet API的...
【RGSS-RTP Standard】是RPG Maker系列软件的一个核心组成部分,主要包含了制作角色扮演游戏时所需要的各种基础资源和脚本引擎。这个最新的版本是RPG Maker的重要更新,它提供了更完善的工具集,使得游戏开发者能够...
《JSP标准标签库——standard-1.1.2.jar详解》 在Java服务器页面(JSP)开发中,为了提高代码的可读性和可维护性,常常会使用标签库来替代部分脚本元素。其中,`standard-1.1.2.jar`是JSP标准标签库(JSTL)的一个...
**JSTL(JavaServer Pages Standard Tag Library)与Standard.jar** 在Java Web开发中,JSTL(JavaServer Pages Standard Tag Library)是一个重要的库,它提供了丰富的标签来简化JSP页面的编写,使得代码更加清晰...
《Jakarta Taglibs Standard 1.1.2:Java Web开发中的标签库解析》 Jakarta Taglibs Standard 1.1.2是Java Web开发中的一款重要组件,它为开发者提供了一套标准的标签库,使得在JSP(JavaServer Pages)页面中编写...
The C++ Standard Library provides a set of common classes and interfaces that greatly extend the core C++ language. Josuttis' book not only provides comprehensive documentation of each library ...
- **ASHRAE Standard Ventilation for Acceptable Indoor Air Quality ANSI/ASHRAE Standard 62.1-2007**:这段描述进一步明确了标准的具体名称和版本号,即ASHRAE 62.1-2007版,强调了其对可接受室内空气质量通风的...
Windows Server 2016 Standard操作系统安装指南 Windows Server 2016 Standard操作系统安装指南是微软公司发布的一款服务器操作系统,适用于企业级应用和数据中心环境。以下是该操作系统的安装指南,旨在帮助用户...
The C++ standard library provides a set of common classes and interfaces that greatly extend the core C++ language. The library, however, is not self-explanatory. To make full use of its components - ...
time for a new edition that covers C++11, the new C++ standard. Note that this means more than simply adding new libraries. C++ has changed. Almost all typical applications of parts of the library ...