
前置条件
已经成功安装配置Hadoop和Mysql数据库服务器,如果将数据导入或从Hbase导出,还应该已经成功安装配置Hbase。
下载sqoop和Mysql的JDBC驱动
sqoop-1.2.0-CDH3B4.tar.gz :http://archive.cloudera.com/cdh/3/sqoop-1.2.0-CDH3B4.tar.gz
mysql-connector-java-5.1.28
安装sqoop
[hadoop@appserver ~]$ tar -zxvf sqoop-1.2.0-CDH3B4.tar.gz
配置环境变量
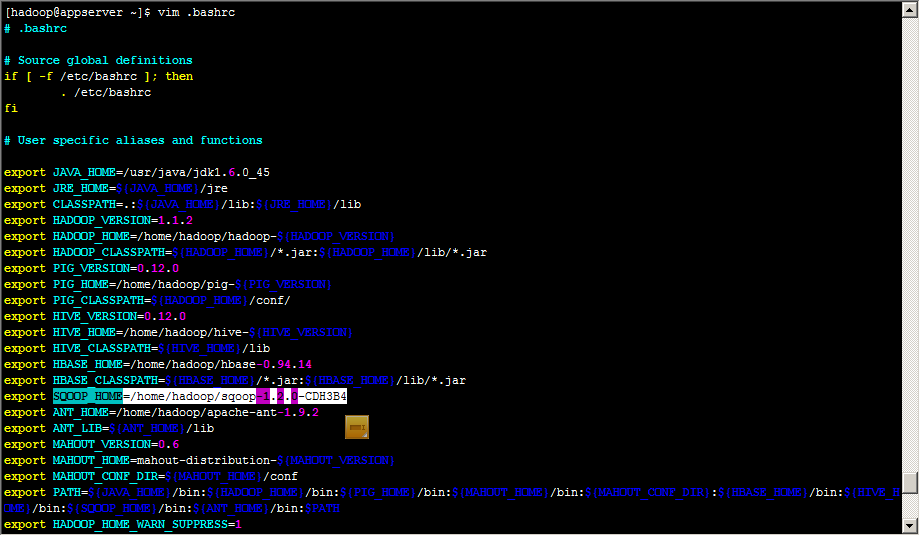
拷贝Hadoop核心包和MYSQL驱动包到sqoop的lib目录
[hadoop@appserver ~]$ cp hadoop-1.1.2/hadoop-core-1.1.2.jar sqoop-1.2.0-CDH3B4/lib/
[hadoop@appserver ~]$ cp mysql-connector-java-5.1.28-bin.jar sqoop-1.2.0-CDH3B4/lib/

配置sqoop-1.2.0-CDH3B4/bin/configure-sqoop文件
注释掉hbase和zookeeper检查(除非准备使用HABASE等HADOOP组件)
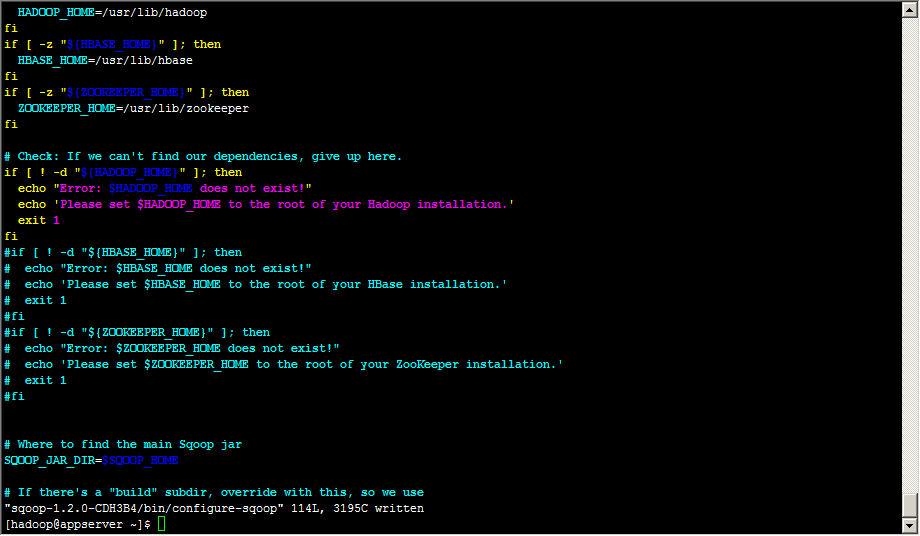
启动hadoop集群
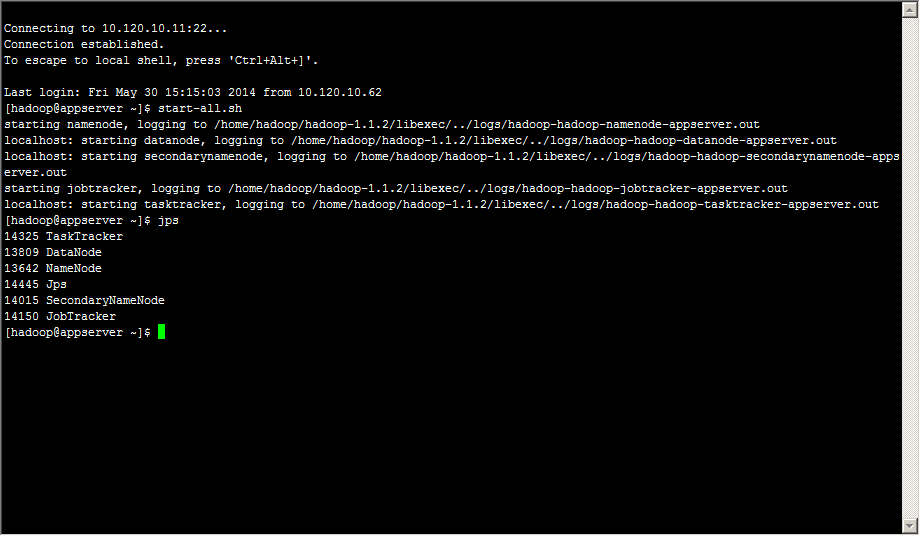
启动mysql
创建sqoop用户
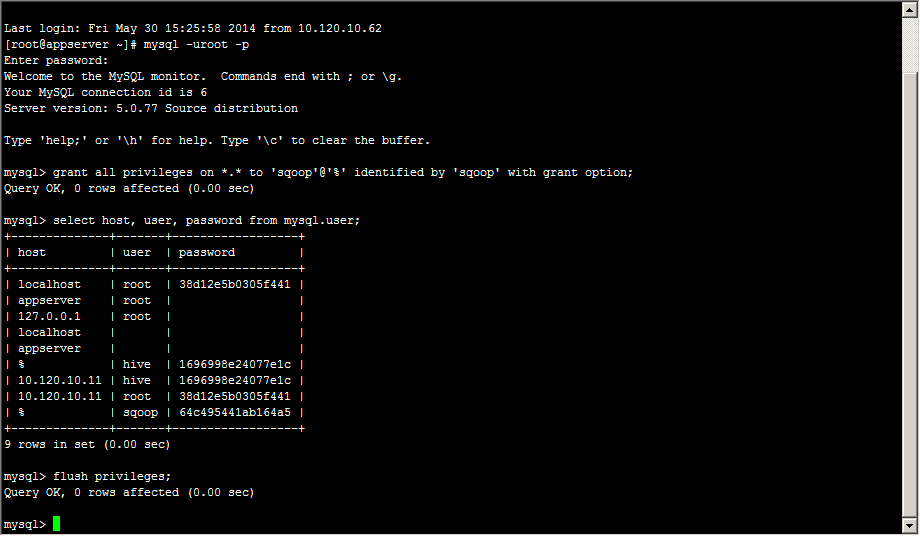
建立sqoop库,test表,并构造测试数据
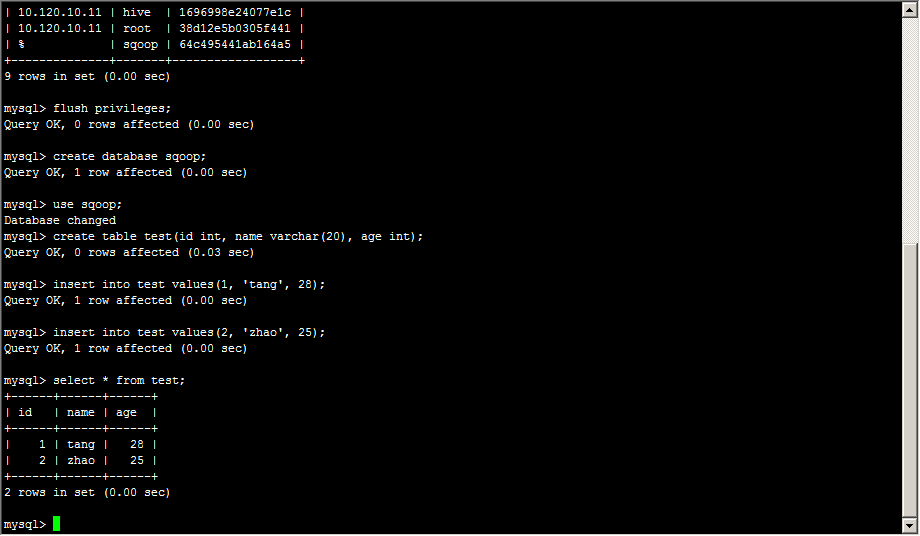
测试sqoop连接
[hadoop@appserver ~]$ sqoop list-databases --connect jdbc:mysql://10.120.10.11:3306/ --username sqoop --password sqoop
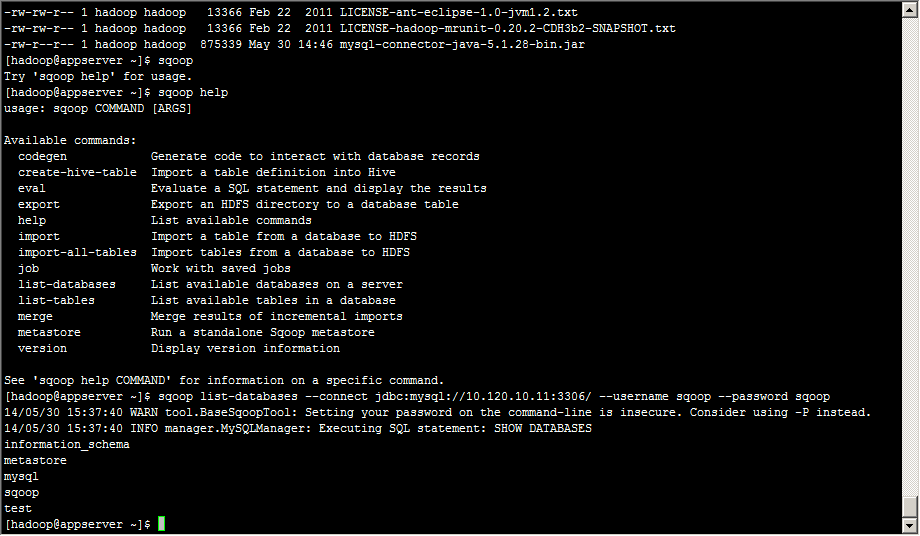
列出mysql中所有数据库的名称
从mysql导入到hdfs中
sqoop ##sqoop命令
import ##表示导入
--connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
--username sqoop ##连接mysql的用户名
--password sqoop ##连接mysql的密码
--table test ##从mysql导出的表名称
--fields-terminated-by '\t' ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
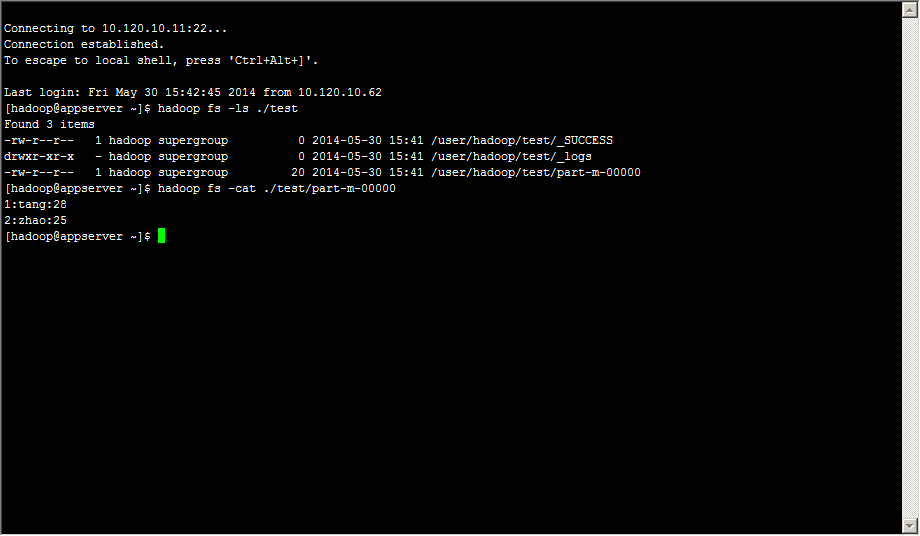
[hadoop@appserver ~]$ sqoop import --connect jdbc:mysql://10.120.10.11:3306/sqoop --username sqoop --password sqoop --table test --fields-terminated-by ':' -m 1

Hadoop中查看导入结果
从hdfs导出到mysql中
sqoop
export ##表示数据从hive复制到mysql中
--connect jdbc:mysql://ip:3306/sqoop
--username sqoop
--password sqoop
--table test ##mysql中的表,即将被导入的表名称
--export-dir '/user/root/aa/part-m-00000' ##hive中被导出的文件
--fields-terminated-by '\t' ##hive中被导出的文件字段的分隔符
[hadoop@appserver ~]$ sqoop export --connect jdbc:mysql://10.120.10.11:3306/sqoop --username sqoop --password sqoop --table test --export-dir '/user/hadoop/test/part-m-00000' --fields-terminated-by ':' -m 1
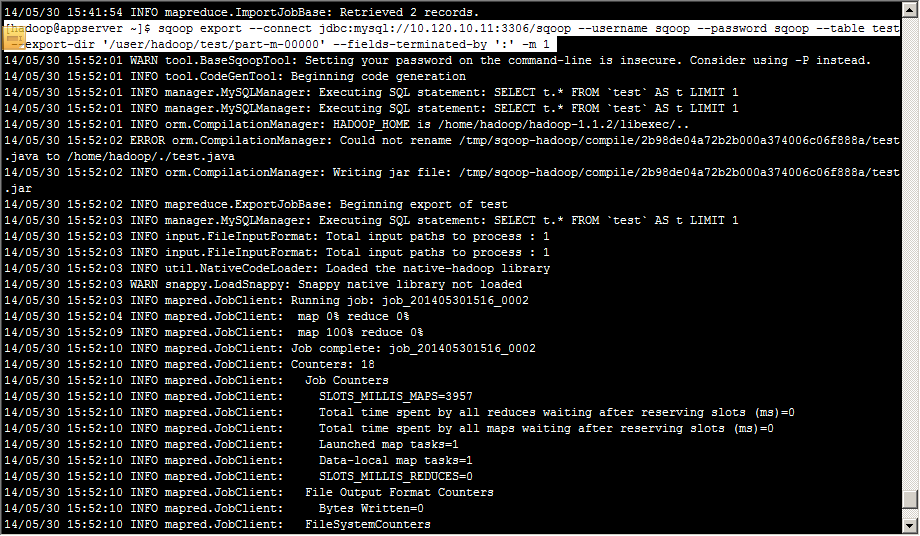
Mysql中查看导出结果

从Mysql导入到Hbase中
参数说明:
Ø hbase_tablename指定要导成hbase的表名
Ø key_col_name指定mysql数据库表中哪一列作为hbase新表的rowkey
Ø col_fam_name是除rowkey之外的所有列的列族名
[hadoop@appserver ~]$ sqoop import --connect jdbc:mysql://10.120.10.11:3306/sqoop --username sqoop --password sqoop --table test --hbase-create-table --hbase-table mysql_sqoop_test --column-family info --hbase-row-key id -m 1
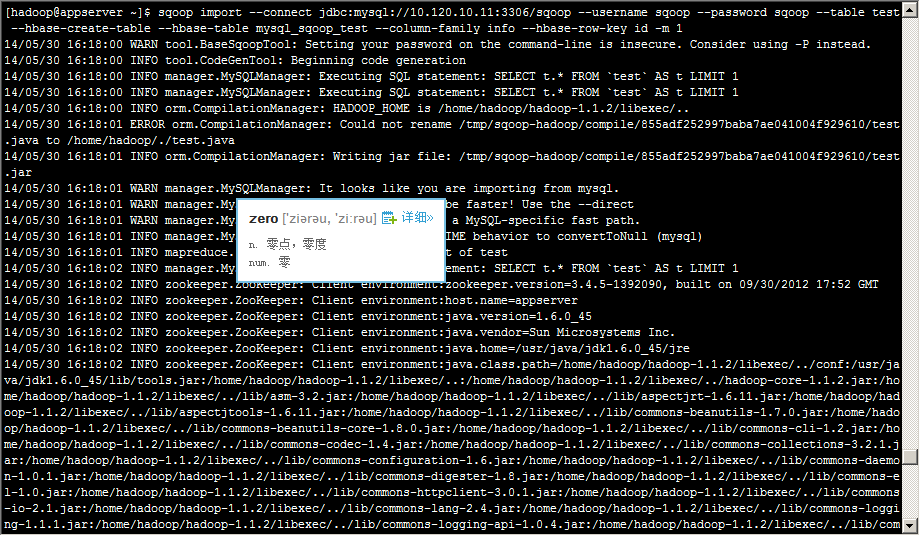
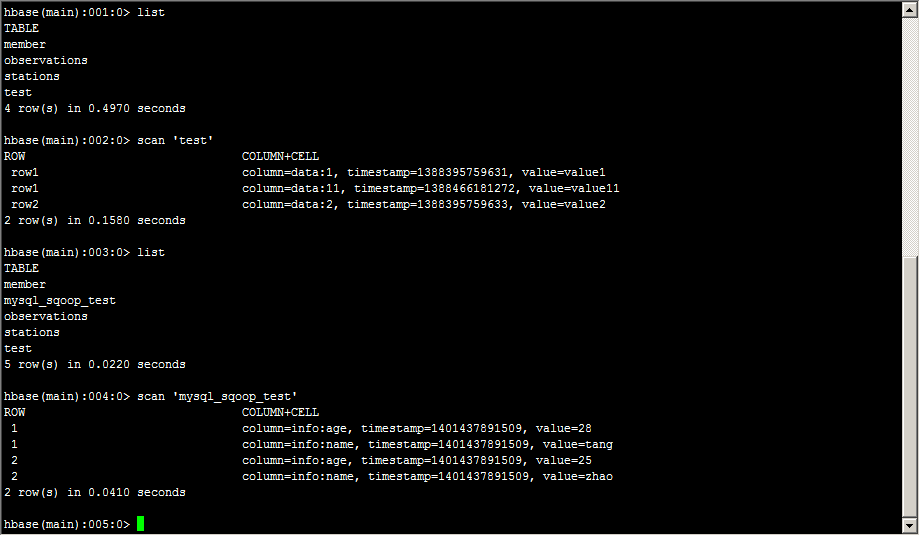
在Hbase中查看结果



相关推荐
本文将深入探讨三个关键组件:hadoop.dll、hadoop.exp和winutils.exe,以及它们在64位系统中的应用。这些组件主要用于在Windows平台上搭建和运行Hadoop。 首先,hadoop.dll是一个动态链接库(DLL)文件,它是Hadoop...
Hadoop In Action 中文第二版 卷二 rar
《Hadoop权威指南中文版(第二版)》与《Hadoop in Action》及《Pro Hadoop》这三本书是深入理解和掌握Hadoop生态系统的关键资源。Hadoop作为一个分布式计算框架,其核心是解决大规模数据处理的问题,它允许在廉价...
hadoop.exp
HIGHLIGHT Hadoop in Action is an example-rich tutorial that shows developers how to implement data-intensive distributed computing using Hadoop and the Map- Reduce framework. DESCRIPTION Hadoop is an ...
标题 "hadoop_mysql-libs.rar 在linux用" 暗示了这个压缩包包含的是与在Linux环境下使用Hadoop和MySQL相关的库文件。Hadoop是一个开源的分布式计算框架,而MySQL是一个广泛使用的开源关系型数据库管理系统。它们经常...
Hadoop硬实战:Hadoop in Practice
Sams Teach Yourself Hadoop in 24 Hours 英文epub 本资源转载自网络,如有侵权,请联系上传者或csdn删除 查看此书详细信息请在美国亚马逊官网搜索此书
PART 2 - Hadoop in Action CHAPTER 4 Writing basic MapReduce programs CHAPTER 5 Advanced MapReduce CHAPTER 6 Programming practices CHAPTER 7 Cookbook CHAPTER 8 Managing Hadoop PART 3 - Hadoop Gone Wild...
Moving Hadoop to The Cloud 英文epub 本资源转载自网络,如有侵权,请联系上传者或csdn删除 本资源转载自网络,如有侵权,请联系上传者或csdn删除
### Hadoop in Action #### 知识点一:Hadoop 的简介与背景 - **定义**:Hadoop 是一个能够处理大规模数据集的开源软件框架,最初由Apache Software Foundation开发。它通过分布式计算来实现对大数据的有效管理和...
Hadoop、hive 、MySQL
《Hadoop in Action》是一本深入探讨Hadoop及其生态系统核心组件的权威书籍,主要涵盖了分布式存储系统HDFS(Hadoop Distributed File System)和并行计算框架MapReduce。这本书旨在帮助读者理解Hadoop的工作原理,...
《Hadoop In Practice》是一本深入探讨Hadoop及其生态系统实践应用的专业书籍,旨在帮助读者掌握在实际工作中使用Hadoop的技巧和策略。本书涵盖了Hadoop的核心组件,包括HDFS(Hadoop分布式文件系统)和MapReduce,...