问题导读:
1.如何创建MR程序?
2.如何配置运行参数?
3.HADOOP_HOME为空会出现什么问题?
4.hadoop-common-2.2.0-bin-master/bin的作用是什么?
扩展:
4.winutils.exe是什么?

本文总结了两个例子,分别从不同角度。
一、eclipse中开发Hadoop2.x的Map/Reduce项目
本文演示如何在Eclipse中开发一个Map/Reduce项目:
1、环境说明
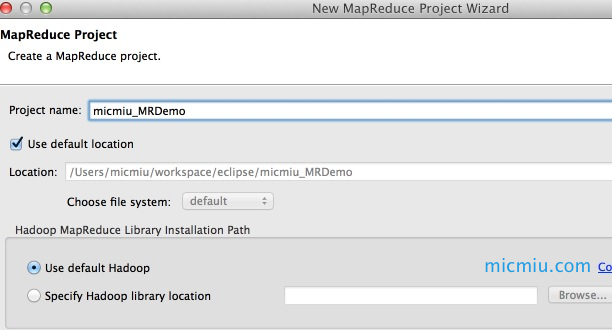
2、新建MR工程
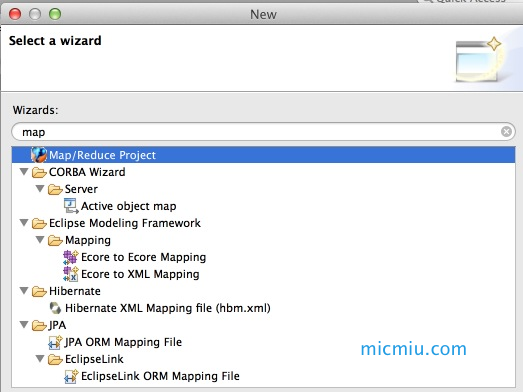
依次点击 File → New → Ohter… 选择 “Map/Reduce Project”,然后输入项目名称:micmiu_MRDemo,创建新项目:
<ignore_js_op style="word-wrap: break-word;">
<ignore_js_op style="word-wrap: break-word;">
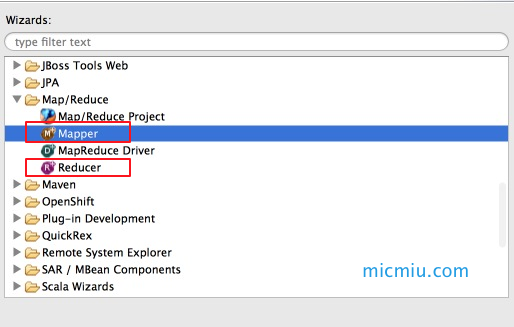
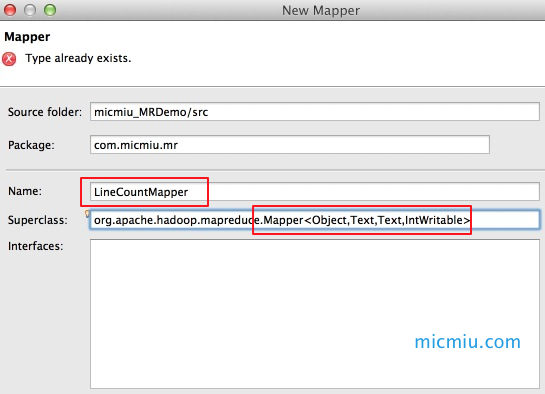
3、创建Mapper和Reducer
依次点击 File → New → Ohter… 选择Mapper,自动继承Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT>
<ignore_js_op style="word-wrap: break-word;">
<ignore_js_op style="word-wrap: break-word;">
创建Reducer的过程同Mapper,具体的业务逻辑自己实现即可。
本文就以官方自带的WordCount为例进行测试:
- package com.micmiu.mr;
- /**
- * Licensed to the Apache Software Foundation (ASF) under one
- * or more contributor license agreements. See the NOTICE file
- * distributed with this work for additional information
- * regarding copyright ownership. The ASF licenses this file
- * to you under the Apache License, Version 2.0 (the
- * "License"); you may not use this file except in compliance
- * with the License. You may obtain a copy of the License at
- *
- * http://www.apache.org/licenses/LICENSE-2.0
- *
- * Unless required by applicable law or agreed to in writing, software
- * distributed under the License is distributed on an "AS IS" BASIS,
- * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
- * See the License for the specific language governing permissions and
- * limitations under the License.
- */
- import java.io.IOException;
- import java.util.StringTokenizer;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.util.GenericOptionsParser;
- public class WordCount {
- public static class TokenizerMapper
- extends Mapper<Object, Text, Text, IntWritable>{
- private final static IntWritable one = new IntWritable(1);
- private Text word = new Text();
- public void map(Object key, Text value, Context context
- ) throws IOException, InterruptedException {
- StringTokenizer itr = new StringTokenizer(value.toString());
- while (itr.hasMoreTokens()) {
- word.set(itr.nextToken());
- context.write(word, one);
- }
- }
- }
- public static class IntSumReducer
- extends Reducer<Text,IntWritable,Text,IntWritable> {
- private IntWritable result = new IntWritable();
- public void reduce(Text key, Iterable<IntWritable> values,
- Context context
- ) throws IOException, InterruptedException {
- int sum = 0;
- for (IntWritable val : values) {
- sum += val.get();
- }
- result.set(sum);
- context.write(key, result);
- }
- }
- public static void main(String[] args) throws Exception {
- Configuration conf = new Configuration();
- String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
- if (otherArgs.length != 2) {
- System.err.println("Usage: wordcount <in> <out>");
- System.exit(2);
- }
- //conf.set("fs.defaultFS", "hdfs://192.168.6.77:9000");
- Job job = new Job(conf, "word count");
- job.setJarByClass(WordCount.class);
- job.setMapperClass(TokenizerMapper.class);
- job.setCombinerClass(IntSumReducer.class);
- job.setReducerClass(IntSumReducer.class);
- job.setOutputKeyClass(Text.class);
- job.setOutputValueClass(IntWritable.class);
- FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
- FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
复制代码
4、准备测试数据
micmiu-01.txt:
- Hi Michael welcome to Hadoop
- more see micmiu.com
复制代码
micmiu-02.txt:
- Hi Michael welcome to BigData
- more see micmiu.com
复制代码
micmiu-03.txt:
- Hi Michael welcome to Spark
- more see micmiu.com
复制代码
把 micmiu 打头的三个文件上传到hdfs:
- micmiu-mbp:Downloads micmiu$ hdfs dfs -copyFromLocal micmiu-*.txt /user/micmiu/test/input
- micmiu-mbp:Downloads micmiu$ hdfs dfs -ls /user/micmiu/test/input
- Found 3 items
- -rw-r--r-- 1 micmiu supergroup 50 2014-04-15 14:53 /user/micmiu/test/input/micmiu-01.txt
- -rw-r--r-- 1 micmiu supergroup 50 2014-04-15 14:53 /user/micmiu/test/input/micmiu-02.txt
- -rw-r--r-- 1 micmiu supergroup 49 2014-04-15 14:53 /user/micmiu/test/input/micmiu-03.txt
- micmiu-mbp:Downloads micmiu$
复制代码
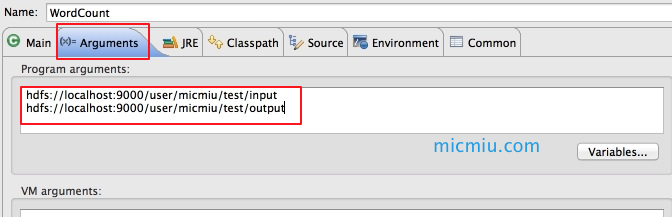
5、配置运行参数
Run As → Run Configurations… ,在Arguments中配置运行参数,例如程序的输入参数:
<ignore_js_op style="word-wrap: break-word;">
6、运行
Run As -> Run on Hadoop ,执行完成后可以看到如下信息:
<ignore_js_op style="word-wrap: break-word;">
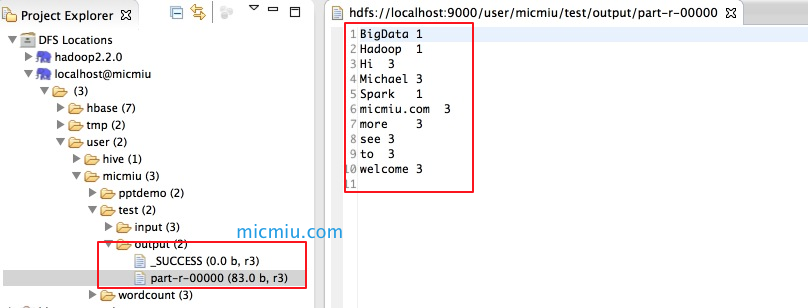
到此Eclipse中调用Hadoop2x本地伪分布式模式执行MR演示成功。
ps:调用集群环境MR运行一直失败,暂时没有找到原因。

上面说了一个整体的过程,下面详细描述了遇到的问题
二、Win7 Eclipse调试Centos Hadoop2.2-Mapreduce
1.搭建了一套Centos5.3 + Hadoop2.2 + Hbase0.96.1.1的开发环境,Win7 Eclipse调试MapReduce成功。
安装成功后,能顺利查看以下几个页面,就OK了。我的集群环境是200master,201-203slave。
dfs.http.address 192.168.1.200:50070
dfs.secondary.http.address 192.168.1.200:50090
dfs.datanode.http.address 192.168.1.201:50075
yarn.resourcemanager.webapp.address 192.168.1.200:50030
mapreduce.jobhistory.webapp.address 192.168.1.200:19888。这个好像访问不了。需要启动hadoop/sbin/mr-jobhistory-daemon.sh start historyserver才可以访问。
三. Hadoop2.x eclispe-plugin
需要注意一点的是,Hadoop installation directory里填写Win下的hadoop home地址,其目的在于创建MapReduce Project能从这个地方自动引入MapReduce需要的jar。
插件可以从下面下载:
四. 各种问题
1.上面一步完成后,创建一个MapReduce Project,运行时发现出问题了。
- java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries.
-
复制代码
跟代码就去发现是HADOOP_HOME的问题。如果HADOOP_HOME为空,必然fullExeName为null\bin\winutils.exe。解决方法很简单啦,乖乖的配置环境变量吧,不想重启电脑可以在MapReduce程序里加上System.setProperty("hadoop.home.dir", "...");暂时缓缓。org.apache.hadoop.util.Shell.java
- public static final String getQualifiedBinPath(String executable)
- throws IOException {
- // construct hadoop bin path to the specified executable
- String fullExeName = HADOOP_HOME_DIR + File.separator + "bin"
- + File.separator + executable;
- File exeFile = new File(fullExeName);
- if (!exeFile.exists()) {
- throw new IOException("Could not locate executable " + fullExeName
- + " in the Hadoop binaries.");
- }
- return exeFile.getCanonicalPath();
- }
- private static String HADOOP_HOME_DIR = checkHadoopHome();
- private static String checkHadoopHome() {
- // first check the Dflag hadoop.home.dir with JVM scope
- String home = System.getProperty("hadoop.home.dir");
- // fall back to the system/user-global env variable
- if (home == null) {
- home = System.getenv("HADOOP_HOME");
- }
- ...
- }
复制代码
2.这个时候得到完整的地址fullExeName,我机器上是D:\Hadoop\tar\hadoop-2.2.0\hadoop-2.2.0\bin\winutils.exe。继续执行代码又发现了错误
3.继续出问题
- at org.apache.hadoop.util.Shell.execCommand(Shell.java:661)
- at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:639)
- at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:435)
复制代码
继续跟代码org.apache.hadoop.util.Shell.java
- public static String[] getSetPermissionCommand(String perm, boolean recursive,
- String file) {
- String[] baseCmd = getSetPermissionCommand(perm, recursive);
- String[] cmdWithFile = Arrays.copyOf(baseCmd, baseCmd.length + 1);
- cmdWithFile[cmdWithFile.length - 1] = file;
- return cmdWithFile;
- }
- /** Return a command to set permission */
- public static String[] getSetPermissionCommand(String perm, boolean recursive) {
- if (recursive) {
- return (WINDOWS) ? new String[] { WINUTILS, "chmod", "-R", perm }
- : new String[] { "chmod", "-R", perm };
- } else {
- return (WINDOWS) ? new String[] { WINUTILS, "chmod", perm }
- : new String[] { "chmod", perm };
- }
- }
复制代码
cmdWithFile数组的内容为{"D:\Hadoop\tar\hadoop-2.2.0\hadoop-2.2.0\bin\winutils.exe", "chmod", "755", "xxxfile"},我把这个单独在cmd里执行了一下,发现
4.到了这里,已经看到曙光了,但问题又来了
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
复制代码
代码就去
- /** Windows only method used to check if the current process has requested
- * access rights on the given path. */
- private static native boolean access0(String path, int requestedAccess);
复制代码
显然缺少dll文件,还记得https://github.com/srccodes/hadoop-common-2.2.0-bin下载的东西吧,里面就有hadoop.dll,最好的方法就是用hadoop-common-2.2.0-bin-master/bin目录替换本地hadoop的bin目录,并在环境变量里配置PATH=HADOOP_HOME/bin,重启电脑。
5.终于看到了MapReduce的正确输出output99。
<ignore_js_op style="word-wrap: break-word; color: rgb(68, 68, 68); font-family: Tahoma, 'Microsoft Yahei', Simsun; font-size: 14px; line-height: 21px;">
五. 总结
hadoop eclipse插件不是必须的,其作用在我看来就是如下三点(这个是一个错误的认识,具体请参考http://zy19982004.iteye.com/blog/2031172)。study-hadoop是一个普通project,直接运行(不通过Run on Hadoop这只大象),一样可以调试到MapReduce。
对hadoop中的文件可视化。
创建MapReduce Project时帮你引入依赖的jar。
Configuration conf = new Configuration();时就已经包含了所有的配置信息。
还是自己下载hadoop2.2的源码编译好,应该是不会有任何问题的(没有亲测)。
六. 其它问题
1.还是
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
复制代码
代码跟到org.apache.hadoop.util.NativeCodeLoader.java去看
- static {
- // Try to load native hadoop library and set fallback flag appropriately
- if(LOG.isDebugEnabled()) {
- LOG.debug("Trying to load the custom-built native-hadoop library...");
- }
- try {
- System.loadLibrary("hadoop");
- LOG.debug("Loaded the native-hadoop library");
- nativeCodeLoaded = true;
- } catch (Throwable t) {
- // Ignore failure to load
- if(LOG.isDebugEnabled()) {
- LOG.debug("Failed to load native-hadoop with error: " + t);
- LOG.debug("java.library.path=" +
- System.getProperty("java.library.path"));
- }
- }
-
- if (!nativeCodeLoaded) {
- LOG.warn("Unable to load native-hadoop library for your platform... " +
- "using builtin-java classes where applicable");
- }
- }
复制代码
这里报错如下
- DEBUG org.apache.hadoop.util.NativeCodeLoader - Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: HADOOP_HOME\bin\hadoop.dll: Can't load AMD 64-bit .dll on a IA 32-bit platform
-
复制代码
怀疑是32位jdk的问题,替换成64位后,没问题了
- 2014-03-11 19:43:08,805 DEBUG org.apache.hadoop.util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
- 2014-03-11 19:43:08,812 DEBUG org.apache.hadoop.util.NativeCodeLoader - Loaded the native-hadoop library
复制代码
这里也解决了一个常见的警告
- WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
复制代码
http://www.aboutyun.com/thread-7541-1-1.html




相关推荐
然而,在Hadoop 2.x版本中,JobTracker被YARN(Yet Another Resource Negotiator)取代,YARN成为资源管理和任务调度的中心,而MapReduce的任务调度则由ResourceManager和ApplicationMaster协同完成。 为了方便开发...
安装完成后,开发者可以通过Eclipse的“New”菜单选择“Hadoop Map/Reduce Project”来创建一个新的Hadoop项目,接着就可以开始编写MapReduce代码了。在开发过程中,可以利用插件提供的各种功能进行测试和调试,从而...
在 Eclipse 中配置 Hadoop Installation Directory,打开 Window-->Preferences,发现 Hadoop Map/Reduce 选项,在这个选项里需要配置 Hadoop Installation Directory。 5. 配置 Map/Reduce Locations 在 Window--...
"Ubuntu下开发Eclipse下的Hadoop应用" 本文档详细记录了如何在Ubuntu下安装Eclipse,并如何在Eclipse中安装Hadoop插件,最后运行程序。下面将对标题、描述、标签和部分内容进行详细解释和分析。 标题: Ubuntu下...
- **项目集成**:允许在Eclipse中创建Hadoop项目,自动配置项目的构建路径和依赖项。 - **资源管理**:在Eclipse内浏览和管理HDFS上的文件和目录,包括上传、下载、删除等操作。 - **作业提交**:直接从IDE提交...
安装完成后,用户会在Eclipse的"New"菜单中看到"Hadoop Map/Reduce Project"选项,这标志着插件已成功安装并可使用。 使用Hadoop Eclipse Plugin,开发者可以进行以下操作: 1. **创建Hadoop项目**:选择“File” ...
在Windows平台上进行Hadoop的Map/Reduce开发可能会比在Linux环境下多一些挑战,但通过详细的步骤和理解Map/Reduce的工作机制,开发者可以有效地克服这些困难。以下是对标题和描述中涉及知识点的详细说明: **Hadoop...
在本例中,`hadoop-eclipse-plugin-2.6.0.jar`就是这样的一个插件,它允许开发人员在Eclipse中直接创建、管理和运行Hadoop MapReduce项目,无需离开IDE,极大地提高了开发效率。 安装此插件的过程如下: 1. **下载...
放到eclipse的plugins目录下。重启eclipse ...配置 Map/Reduce Master和DFS Mastrer,Host和Port配置成hdfs-site.xml与core-site.xml的设置一致即可。 如果连接成功,会出现hdfs上面的文件夹
Hadoop-Eclipse-Plugin-2.6.4版本是针对Hadoop 2.x系列的,因此,它支持YARN资源管理器,这使得在多用户、多任务的环境中,资源分配和调度更加合理。与早期版本相比,此版本的插件兼容性更强,性能更优,更易于在...
2. **配置Hadoop连接**:在Eclipse中,选择`Window -> Preferences -> Hadoop Map/Reduce -> Cluster`,点击`New`按钮,填写Hadoop集群的相关配置,包括HDFS的URL、JobTracker的地址等。 3. **创建Hadoop项目**:...
- 第二步:在Eclipse中,通过“Window”菜单选择“Preferences”,在左侧列表中找到“Hadoop Map/Reduce”,设置Hadoop的安装路径。 - 第三步:切换到“Map/Reduce”透视图,可以通过“Window”菜单的“Open ...
重启Eclipse后,你会发现在"File"菜单下多了"New" -> "Other" -> "Hadoop Map/Reduce Project"的选项,这就是Hadoop Eclipse Plugin所带来的变化。通过这个选项,你可以创建一个专门针对Hadoop的MapReduce项目,设置...
标题提及的"基于Eclipse的Hadoop应用开发环境配置"是指在Eclipse集成开发环境中设置一个用于开发Hadoop应用程序的环境。Hadoop是Apache软件基金会的一个开源分布式计算框架,它允许处理和存储大规模数据集。在...
大数据是当今的一个热门话题,相信搞JAVA的我们当然不能错过了,尤其是...hadoop可以不用eclipse插件也可以运行,但当然,对于我们初学的,有个插件肯定好很多,我们可以集中精力先让它跑起来,然后再慢慢去深入研究。
Eclipse 配置 Hadoop 及 MapReduce 开发指南 一、Eclipse 中配置 Hadoop 插件 配置 Hadoop 插件是使用 Eclipse 进行 MapReduce 开发的第一步。首先,需要安装 Eclipse 3.3.2 和 Hadoop 0.20.2-eclipse-plugin.jar ...
为了方便Hadoop开发者在Eclipse中进行Hadoop应用的开发和测试,出现了Hadoop2x-eclipse-plugin插件。这个插件允许开发者直接在Eclipse环境中创建、编译、运行和调试Hadoop MapReduce项目,极大地提升了开发效率。 ...
4. 完成安装后,重启Eclipse,即可在"File" -> "New"菜单中看到“Hadoop Map/Reduce Project”选项。 同时,`no.txt`文件可能是用于记录某些说明或注意事项的文本文件,但具体内容需要打开文件查看。在Hadoop开发中...
3. **Map/Reduce设置**:继续通过`Windows` -> `Show View` -> `Other`找到并搜索`Map/Reduce`相关的视图,选择后可看到更多关于Hadoop集群的信息。 4. **测试连接**:当以上步骤都已完成并且集群运行正常时,应该...
- 最后,在Eclipse中配置Map/Reduce的执行位置,这通常涉及到指定你的Hadoop集群的Master节点地址,如NameNode和ResourceManager的IP和端口。 通过以上步骤,你就可以在Windows 10的Eclipse环境中编写、测试和调试...