
根据词频分析取tag
分析;把每个帖子进行分词,然后把词的出现频率倒序排列,取出前N个就作为TAG了。当然要一个板块一个板块的提取tag,如果把军事板块和情感板块的帖子混杂在一起提取tag,提取出来的tag相关性比较差一些,如果分开提取,相关性要好一些,整体效果好。好多时候做训练算法,语料很重要。先分词吧,自己写分词算法也是弄个词库,自己用正向最大匹配来分词,或者两个两个字的来当词,所以还不如直接用中科院那套呢,直接使用了隐式马尔可夫算法,效果虽说不是很好吧,也能满足需求了,对吧。具体测试代码、分词组件、词库下载见以下链接
http://www.cnblogs.com/edison1024/archive/2006/05/03/390832.html
得点了他那个广告才能显示下载地址,你就点吧,人家提供下载也不容易。分词后要去除停止词,停止词自己从网上搜索一份,如果不去除停止词,最后肯定是“了”,“的”,“我”等词出现的频率最高,你不会把这些常用词做tags吧,呵呵。当然NICTCLAS是可以标注词性的,你可以分词后把语气词、副词等虚词去了,这样更好一些,但我就懒得做了,直接分词、去除停止词两步。
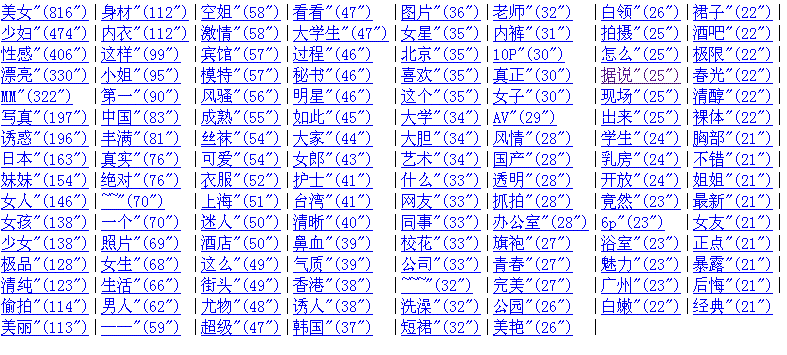
完了计算每个词出现的频率就好说了,弄一个全局的字典,每个词出现一次增加一个计数,第一次出现先添加到字典,并计数为0,最后把出现次数在某个阈值以上的词插入到数据库里,这就是你要的tag了,先来看一下我的效果吧(大家别笑哦,我是从一个美女贴图论坛提取了一些帖子的主题当语料的,为了不降低博客园的PR值,就贴图,不贴文字了)。
开始上代码
先贴分词
 namespace WawaSoft.Search.Common
namespace WawaSoft.Search.Common {
{ public sealed class WawaSplitWorder
public sealed class WawaSplitWorder { static List<string> _stopWords = new List<string>(); static NICTCLAS _nictclas; public static void Init() { try { //1、初始化分词器 _nictclas = new NICTCLAS(); _nictclas.OperateType = eOperateType.OnlySegment; _nictclas.OutputFormat = eOutputFormat.PKU; //2、加载停止词 using (StreamReader sr = new StreamReader("data\\StopWords.txt", Encoding.Default)) { string temp; while ((temp = sr.ReadLine()) != null) { _stopWords.Add(temp);
{ static List<string> _stopWords = new List<string>(); static NICTCLAS _nictclas; public static void Init() { try { //1、初始化分词器 _nictclas = new NICTCLAS(); _nictclas.OperateType = eOperateType.OnlySegment; _nictclas.OutputFormat = eOutputFormat.PKU; //2、加载停止词 using (StreamReader sr = new StreamReader("data\\StopWords.txt", Encoding.Default)) { string temp; while ((temp = sr.ReadLine()) != null) { _stopWords.Add(temp); } } } catch (Exception ex) { Trace.TraceError("初始化分词器错误:{0}", ex); } } /// <summary> /// 分词并去除停止词 /// </summary> /// <param name="input"></param> /// <returns></returns> public static IEnumerable<string> SplitWords(string input) { Console.WriteLine(input); //预处理,不处理那个分词组件有可能内存读写错误,那玩意儿写的不太健壮,容错性8行的说,呵呵 input = input.Replace("/", ""); input = input.Replace(".", ""); string result = string.Empty; List<string> ret = null; try { //1、分词 _nictclas.ParagraphProcessing(input, ref result); ret = new List<string>( result.Split(new string[] { " " }, StringSplitOptions.RemoveEmptyEntries)); //2、去除干扰词 List<string> needRemove = new List<string>(); foreach (string word in ret) { foreach (string s in _stopWords) { if (string.Compare(s, word, false) == 0) { needRemove.Add(word); break; } } } foreach (string removeWord in needRemove) { ret.Remove(removeWord); } } catch (Exception ex) { //错误的时候除了打出错误详细信息后打出出错的上下文,传入的参数,临时变量等有助于从trace里分析错误,要不死了也不知道怎么死的 Console.WriteLine("{0}\r\n{1}",input,ex); } return ret; } }
} } } catch (Exception ex) { Trace.TraceError("初始化分词器错误:{0}", ex); } } /// <summary> /// 分词并去除停止词 /// </summary> /// <param name="input"></param> /// <returns></returns> public static IEnumerable<string> SplitWords(string input) { Console.WriteLine(input); //预处理,不处理那个分词组件有可能内存读写错误,那玩意儿写的不太健壮,容错性8行的说,呵呵 input = input.Replace("/", ""); input = input.Replace(".", ""); string result = string.Empty; List<string> ret = null; try { //1、分词 _nictclas.ParagraphProcessing(input, ref result); ret = new List<string>( result.Split(new string[] { " " }, StringSplitOptions.RemoveEmptyEntries)); //2、去除干扰词 List<string> needRemove = new List<string>(); foreach (string word in ret) { foreach (string s in _stopWords) { if (string.Compare(s, word, false) == 0) { needRemove.Add(word); break; } } } foreach (string removeWord in needRemove) { ret.Remove(removeWord); } } catch (Exception ex) { //错误的时候除了打出错误详细信息后打出出错的上下文,传入的参数,临时变量等有助于从trace里分析错误,要不死了也不知道怎么死的 Console.WriteLine("{0}\r\n{1}",input,ex); } return ret; } } }
}
计算词频
class AutoGenTag{ //大字典,保存每个词的词频,key是词,value是词频 static Dictionary<string,int> _hashlist = new Dictionary<string, int>(10240); public static void Excute() { //1、取出帖子,越多越好,越多提取的准确性越高 IEnumerable<string> source = Dao.GetPostTitles(); foreach (string str in source) { //2、把每个帖子主题分词 IEnumerable<string> words = WawaSplitWorder.SplitWords(str); if(words == null) continue; //3、把每个词插入到大字典里,以前存在就把词频加1 foreach (string word in words) { if(_hashlist.ContainsKey(word)) { _hashlist[word]++; } else { _hashlist.Add(word,0); } } } //4、把大于某个阈值(这里是20)的词插入数据 foreach (KeyValuePair<string, int> pair in _hashlist) { //如果一次循环插入几万个词,SQLSERVE每秒提交的批会很高,有可能CPU瞬间很高,Sleep(0)能让CPU长得慢点儿,Sleep(1)也行,不过我不知道这两个的区别。或者直接 用sqlserver的bilkcopy性能也8错 Thread.Sleep(0); if (pair.Value > 20) { Console.WriteLine("{0}-{1}",pair.Key,pair.Value); Dao.addtags(pair.Key, pair.Value); } } }}



相关推荐
在IT行业中,"自动提取TAG"是一个重要的技术领域,它主要涉及到自然语言处理(NLP)和信息检索(IR)的结合。这个过程通常用于内容分析、数据挖掘和搜索引擎优化等多个场景,目的是从大量文本数据中自动识别出具有...
这是通过算法实现的,可能包括词频统计、TF-IDF(词频-逆文档频率)等方法,以确保提取的关键词既与文章内容紧密相关,又具有一定的独特性。关键词的正确选择和使用有助于搜索引擎更好地理解页面内容,从而提高搜索...
4. **数据提取**:插件可能包含了数据提取算法,自动从文章内容中识别出合适的标签。这可能涉及到自然语言处理(NLP)技术,如关键词提取、停用词过滤等,目的是自动化标签的创建过程,减轻用户手动输入标签的工作量...
这一算法的主要目的是从复杂的图像背景中识别并提取出矩形形状的物体,例如名片、试卷、矩形框等。在现代科技中,矩形检测算法被广泛应用在文档识别、自动驾驶、监控系统以及各种自动化设备中。 矩形检测算法通常...
北京邮电大学机器学习创新实践课程大作业,实现了类 jieba 库的中文分词与标记算法以及 TextRank 关键词提取算法 运行方法 python main.py 是否预测词性:--with_tag 是否采用有监督方法:--supervised 训练单元:...
1. **内容分析**:当用户在帝国ECMS7.5中发布或更新文章时,插件会自动读取并分析文章内容,提取出其中的核心词汇和短语。 2. **关键词生成**:基于内容分析的结果,插件使用算法(如TF-IDF)来识别最具有代表性的...
该项目的核心功能在于其对AprilTag算法的实现,该算法主要分为以下几个关键步骤: 1. **图像预处理**:首先,系统接收来自摄像头的原始图像,并对其进行灰度化、去噪等预处理操作,以便于后续的边缘检测和特征提取...
通过算法对Tag的检测和识别,机器人可以快速锁定自身的精确位置,尤其是在结构复杂或者动态变化的环境中,这种混合定位方法表现出了很高的稳定性和准确性。 移动机器人在电信设备中的应用,例如自动巡检,可以显著...
在IT行业中,SWF(ShockWave Flash)是一种广泛用于在线多媒体内容展示的文件格式,尤其在过去的网页...不过,有了适当的工具和理解,这一过程可以有效地自动化,使得我们能够方便地从SWF文件中获取所需的音频资源。
在本压缩包中,我们关注的核心主题是"数据分析和图标-批量为电商数据添加tag标签",这涉及到Python编程语言的应用,特别是在自动化处理、数据处理和网络爬虫方面。Python因其简洁的语法和丰富的库支持,成为了数据...
### RFID TAG IC 设计理论与应用 #### 一、引言 RFID(Radio Frequency Identification,射频识别)技术是一种利用无线电波进行非接触式自动识别的技术。它通过射频信号自动识别目标对象并获取相关数据,具有无须...
RFID数据挖掘技术的核心是利用数据挖掘算法从RFID数据中提取有用信息,其研究热点包括如何有效地挖掘RFID移动数据序列,以及如何处理和分析RFID数据。 文章提出的RFID数据挖掘算法针对RFID移动数据的特点,提出了一...
- **属性设置**:通过Property Inspector更改窗体属性,如Resize设为on允许调整大小,Units设为pixels指定单位,Tag命名窗体以方便引用。 2. **程序调试与运行** - **错误检查**:当程序出现问题时,可以在...
SLAM算法通常包括数据采集、特征提取、状态估计和地图更新等步骤。在大区域环境下,SLAM需要处理更复杂的环境变化和大量数据,对计算能力和算法效率有较高要求。 2. **视觉SLAM**:在大区域导航中,视觉SLAM是最...
音乐标签Web应用是一款基于Python开发的在线音乐分类与推荐系统,其主要功能是根据用户的听歌喜好,自动为音乐添加标签,实现个性化推荐。"music-tag-web.zip"这个压缩包包含该系统的源代码和相关文档,是理解并运行...
要实现自动获取关键词的功能,大概可以分成三步1,通过分词算法将标题和内容分别进行分割,提取出关键词和频度。当前主要的两个算法是中科院的ICTCLAS和隐马尔可夫模型。但这两个都太高端,有一定的门槛,且都是只...
这一步骤涉及到从互联网上搜集特定主题或分类的网页文件,通常需要利用网络爬虫技术自动化完成这一过程。其次,将网页文件转换为纯文本文件,是去除网页中的HTML标签等元信息的过程。这一步骤是为了提取出网页的正文...
这个"8winhttp"类可能实现了自动遍历这些标签,提取出链接和标题,为处理大量网页数据提供了便利。 【标签】: "一个从网页tag里面分析url和url标题的类8winhttp.rar" 的标签与标题相同,进一步强调了这个类的功能,...
这可能涉及到根据商品属性(如类别、价格、销量等)进行分类,或者使用某种算法(如聚类分析)来自动划分标签。 6. **NLP(自然语言处理)**:如果tag标签涉及到对商品描述的分析,那么NLP技术可能会被用到。例如,...