- 浏览: 245996 次
-

文章分类
最新评论
引自http://blog.csdn.net/javaman_chen/article/details/7241087
Hadoop的HDFS和MapReduce子框架主要是针对大数据文件来设计的,在小文件的处理上不但效率低下,而且十分消耗磁盘空间(每一个小文件占用一个Block,HDFS默认block大小为64M)。解决办法通常是选择一个容器,将这些小文件组织起来统一存储。HDFS提供了两种类型的容器,分别是SequenceFile和MapFile。
一、SequenceFile
SequenceFile的存储类似于Log文件,所不同的是Log File的每条记录的是纯文本数据,而SequenceFile的每条记录是可序列化的字符数组。
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value)
可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
Text 等同于Java中的String
IntWritable 等同于Java中的Int
BooleanWritable 等同于Java中的Boolean
.
.
在存储结构上,SequenceFile主要由一个Header后跟多条Record组成,如图所示:
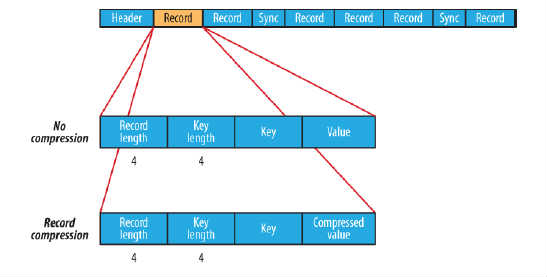
Header主要包含了Key classname,Value classname,存储压缩算法,用户自定义元数据等信息,此外,还包含了一些同步标识,用于快速定位到记录的边界。
每条Record以键值对的方式进行存储,用来表示它的字符数组可依次解析成:记录的长度、Key的长度、Key值和Value值,并且Value值的结构取决于该记录是否被压缩。
数据压缩有利于节省磁盘空间和加快网络传输,SeqeunceFile支持两种格式的数据压缩,分别是:record compression和block compression。
record compression如上图所示,是对每条记录的value进行压缩
block compression是将一连串的record组织到一起,统一压缩成一个block,如图所示:
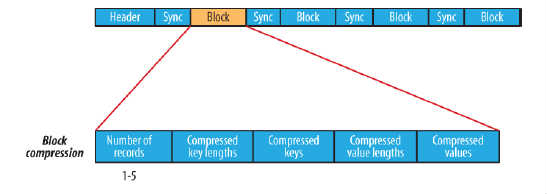
block信息主要存储了:块所包含的记录数、每条记录Key长度的集合、每条记录Key值的集合、每条记录Value长度的集合和每条记录Value值的集合
注:每个block的大小是可通过io.seqfile.compress.blocksize属性来指定的
示例:SequenceFile读/写 操作
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path seqFile=new Path("seqFile.seq");
- //Reader内部类用于文件的读取操作
- SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(value);
- }
- IOUtils.closeStream(reader);//关闭read流
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path seqFile=new Path("seqFile.seq");
- //Reader内部类用于文件的读取操作
- SequenceFile.Reader reader=new SequenceFile.Reader(fs,seqFile,conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- SequenceFile.Writer writer=new SequenceFile.Writer(fs,conf,seqFile,Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(value);
- }
- IOUtils.closeStream(reader);//关闭read流
二、MapFile
MapFile是排序后的SequenceFile,通过观察其目录结构可以看到MapFile由两部分组成,分别是data和index。
index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
需注意的是,MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
另外,与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
示例:MapFile读写操作
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path mapFile=new Path("mapFile.map");
- //Reader内部类用于文件的读取操作
- MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(key);
- }
- IOUtils.closeStream(reader);//关闭read流
- Configuration conf=new Configuration();
- FileSystem fs=FileSystem.get(conf);
- Path mapFile=new Path("mapFile.map");
- //Reader内部类用于文件的读取操作
- MapFile.Reader reader=new MapFile.Reader(fs,mapFile.toString(),conf);
- //Writer内部类用于文件的写操作,假设Key和Value都为Text类型
- MapFile.Writer writer=new MapFile.Writer(conf,fs,mapFile.toString(),Text.class,Text.class);
- //通过writer向文档中写入记录
- writer.append(new Text("key"),new Text("value"));
- IOUtils.closeStream(writer);//关闭write流
- //通过reader从文档中读取记录
- Text key=new Text();
- Text value=new Text();
- while(reader.next(key,value)){
- System.out.println(key);
- System.out.println(key);
- }
- IOUtils.closeStream(reader);//关闭read流
1.文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录
2.当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的




发表评论

-
大数据方面的文章
2013-07-29 17:01 868http://bbs.e-works.net.cn/forum ... -
Apache Pig中文教程(进阶)
2013-05-13 17:18 1767引自http://www.codelast.com/?p=42 ... -
hadoop视频
2013-05-10 09:35 803http://pan.baidu.com/share/li ... -
Apache Pig的一些基础概念及用法总结(1
2013-05-08 16:01 1107引自http://www.codelast.com/?p=3 ... -
hadoop动态增加删除节点
2013-04-28 09:54 1191在master的conf/hdfs-site.xml中加入 ... -
hadoop 比较好的博客
2013-04-27 17:35 733http://dongxicheng.org 好的书 h ... -
Hadoop错误一的解决猜测
2013-04-26 10:29 843如果出现:java.lang.NullPointerExc ... -
Reduce作业运行时错误:Too many fetch-failures
2013-04-24 21:19 5794root@ubuntu:/usr/local/hadoop# ... -
MultipleOutputFormat和MultipleOutputs
2013-01-04 17:26 991引自http://www.cnblogs.com/liangz ... -
hadoop各种输入方法(InputFormat)汇总
2013-01-04 17:02 1424引自http://www.blogjava.net/shenh ... -
Hadoop运行报错: java.lang.ClassNotFoundException解决方法
2012-12-27 16:44 12812在创建自定义的Mapper时候,编译正确,但上传到集群执 ... -
hadoop-1.1.0 rpm + centos 6.3 64 + JDK7 搭建全分布式集群的方法
2012-12-22 20:45 1257引自 http://blog.csdn.net/ireland ... -
HADOOP中DATANODE无法启动
2012-12-22 20:43 963摘要:该文档解决了多次格式化文件系统后,datanode ... -
Hadoop HDFS 编程
2012-12-18 17:38 878引自http://blog.csdn.net/lmc ... -
Hadoop -【IO专题-序列化机制】
2012-12-17 10:32 1095引自http://blog.sina.com.cn/s/ ... -
hadoop问题Type mismatch in value from map解决方法
2012-12-13 10:49 874hadoop问题Type mismatch in ... -
hadoop hbase svn site
2012-12-13 10:49 1000hadoop hbase svn site ... -
hadoop项目svn地址
2012-12-11 18:11 1060http://svn.apache.org/repos/asf ... -
在Eclipse中导入hadoop
2012-12-11 18:03 12430. 准备 (1) 需要有gcc、autoconf、 ... -
Hadoop实例WordCount程序一步一步运行
2012-12-11 16:32 1010虽说现在用Eclipse下开发Hadoop程序很方便了,但是命 ...
相关推荐
Spark-SequenceFile 及 MapFile 是 Hadoop 的两个重要组件,分别用于解决小文件处理效率低下的问题和提供高效的数据存储方式。下面将详细介绍这两个组件的概念、特点和应用。 一、SequenceFile SequenceFile 是一...
基于Hadoop的MapReduce作业集合 项目简介 本项目是一个基于Hadoop的MapReduce作业集合,涵盖了... 读取和写入SequenceFile和MapFile。 5. 序列化 使用Hadoop的序列化机制进行数据序列化和反序列化。 6. 设计模式
同时,本书还探讨了基于文件的数据结构,比如Avro、SequenceFile和MapFile。 书中还涉及了Hadoop生态系统中的其他技术,比如使用Hadoop Archiving保持HDFS集群的平衡,以及如何使用distcp进行并行复制。它还讨论了...
例如,Text用于纯文本数据,SequenceFile和MapFile用于键值对数据,AvroFile支持行式存储,而RCFile、ORCFile、Parquet和CarbonData等则用于列式存储,其中CarbonData具备索引功能,优化了查询性能。 总之,Hadoop...
对于小文件处理,可以通过归档策略如SequenceFile、MapFile、Har等方式提高效率。 12. Client在HDFS上写文件时,Namenode提供DataNode信息,Client将文件分割并按顺序写入每个DataNode。在上传文件过程中,数据副本...
- **文件结构**: 除了传统的文件系统外,Hadoop还支持一些特殊的数据结构,如SequenceFile和MapFile,这些结构可以更高效地存储和检索数据。 #### 五、MapReduce应用程序开发 - **配置API**: MapReduce应用程序...
即数据的输入输出处理,包括数据完整性的保障、各种本地文件系统和HDFS中数据完整性的实现、压缩技术及编解码器、MapReduce中压缩的使用、序列化和可写接口的使用,以及Avro、SequenceFile和MapFile等基于文件的数据...
Hadoop I/O是Hadoop处理数据的核心,包括数据压缩、序列化框架、自定义Writable实现以及基于文件的数据结构如SequenceFile和MapFile。数据压缩可以减少存储空间和网络传输的数据量,提高Hadoop处理数据的效率。序列...
Hadoop分布式存储层主要由HDFS(Hadoop Distributed File System)组成,支持多种数据存储格式,如文本、KV格式(如SequenceFile和MapFile)、行式存储(如AvroFile)和列式存储(如RCFile、ORCFile、Parquet和...
- SequenceFile和MapFile: - SequenceFile:无索引,按key排序。 - MapFile:带索引,同样按key排序。 #### 三、MapReduce应用开发 **3.1 开发环境** - 支持本地环境、伪分布式环境和完全分布式集群环境。 - 可...
- 详细说明了SequenceFile和MapFile等基于文件的数据结构。 5. **开发MapReduce应用程序** - **配置** - 讲解了如何配置MapReduce应用程序的相关参数。 #### 三、总结 本书全面而深入地介绍了Hadoop的核心...
- **文件结构**:本书还介绍了一些特殊类型的文件结构,如SequenceFile和MapFile,它们适用于不同的场景。 #### 六、MapReduce应用程序开发 - **配置API**:提供了详细的指南来配置MapReduce作业,包括如何设置输入...
- **文件结构**:Hadoop还支持特定类型的文件结构,如SequenceFile和MapFile,这些文件结构有助于优化数据读取性能。 #### 四、开发Hadoop应用程序 - **Configuration API** - 提供了配置应用程序参数的方法,...
通常对小文件的处理是使用sequenceFile文件或MapFile文件。这里选择使用sequenceFile文件处理栅格数据。在sequenceFile文件中,key值存放的为文件的路径,value的值存放的为图片的字节数组文件。栅格数据存放在的...
- **文件基数据结构**:Hadoop 支持多种文件基数据结构,如 SequenceFile 和 MapFile,这些结构有助于更高效地访问和处理大数据集。 #### 5. 进阶MapReduce主题 - **排序和连接数据**:MapReduce 可以用来对大型...
- **SequenceFile**:解释了SequenceFile的用途与特点。 - **MapFile**:介绍了MapFile的用法及其优势。 7. **第5章:开发MapReduce应用程序** - **配置API**:介绍了MapReduce应用程序的配置方式。 - **资源...
导出和SequenceFile 第16章 实例分析 Hadoop 在Last.fm的应用 Last.fm:社会音乐史上的革命 Hadoop a Last.fm 用Hadoop产生图表 Track Statistics程序 总结 Hadoop和Hive在Facebook的应用 概要介绍 Hadoop a ...
导出和SequenceFile 第16章 实例分析 Hadoop 在Last.fm的应用 Last.fm:社会音乐史上的革命 Hadoop a Last.fm 用Hadoop产生图表 Track Statistics程序 总结 Hadoop和Hive在Facebook的应用 概要...