
通过【链接列表】采集网站中的【正文数据】
案例:安居客二手房列表页链接,加翻页
一. 网站内容
1. 网站截图说明
本教程以采集“二手房”列表页链接内的正文数据为例,故链接入口应该为“二手房”板块的网址(https://tianjin.anjuke.com/sale/?from=navigation)
Step1:点击官网,找到“二手房”点进进入,如下图红框所示:
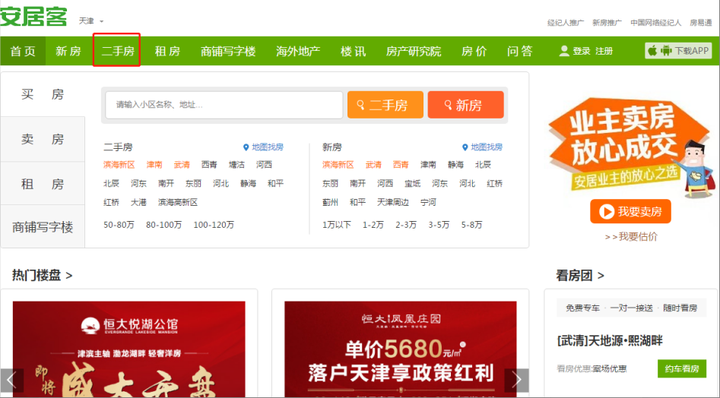
Step2: 进入“二手房”复制该链接,如红框所示:

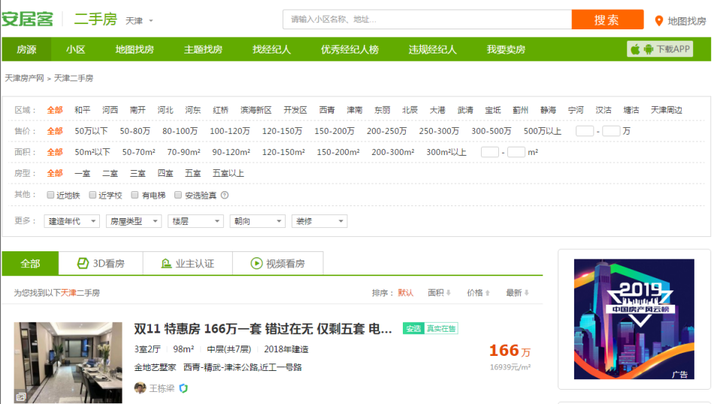 官网-二手房
官网-二手房
2. 采集结果截图
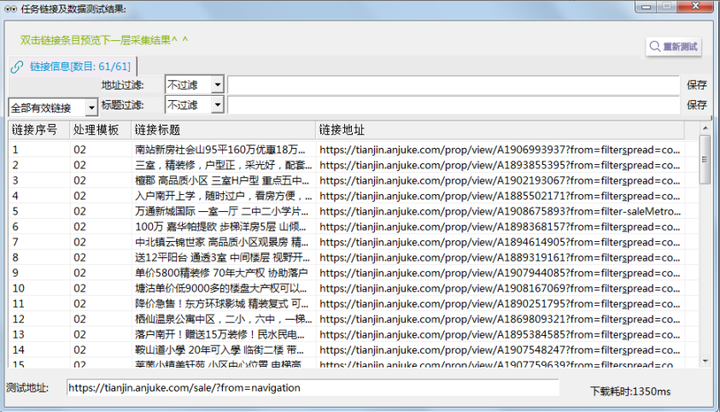 链接列表采集预览
链接列表采集预览
二 . 操作方法
1. 新建任务
按图片数字所示,1-2-3完成新建任务的步骤
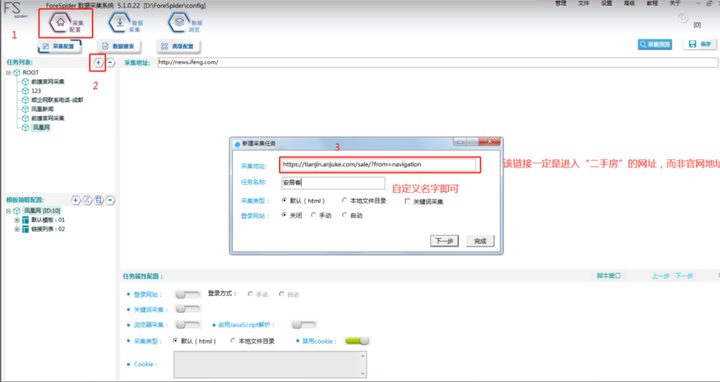 新建任务
新建任务
点击“下一步”,需要采集正文数据,所以此处需要勾选【链接列表】和【普通翻页】,如图,最后点击“完成”即可。
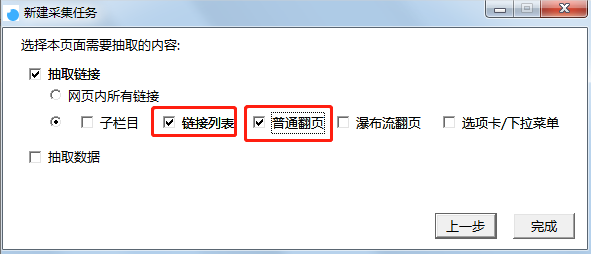 新建采集任务
新建采集任务
2. 链接抽取配置
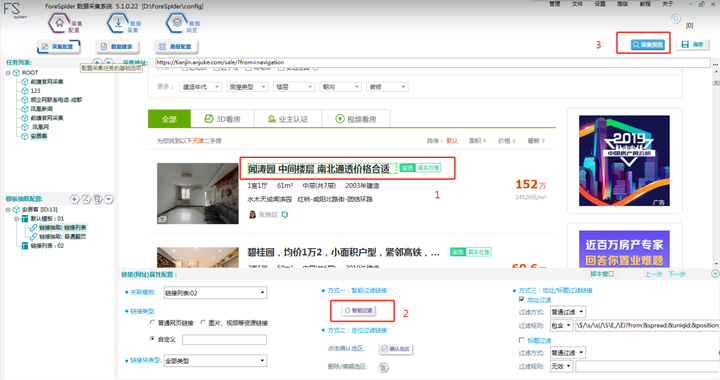
Step1:内置浏览器显示搜索页面后,按照提示:ctrl+左键单击文章标题。
Step2:点击【智能过滤】按钮,这时右侧的地址过滤会显示出相应的代码。
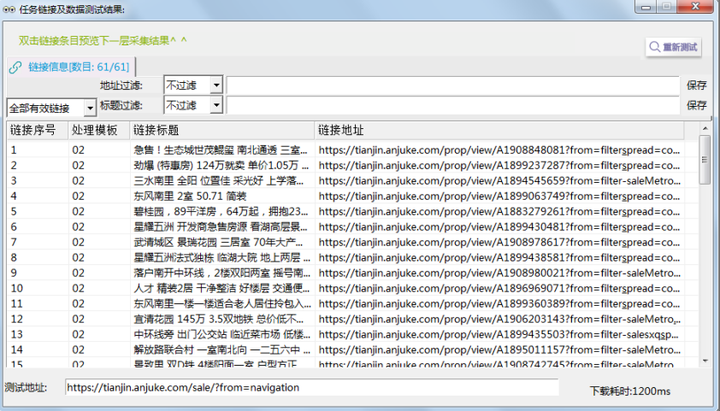
Step3:最后点击右上角的【采集预览】查看是有内容,如下图:
3. 翻页配置
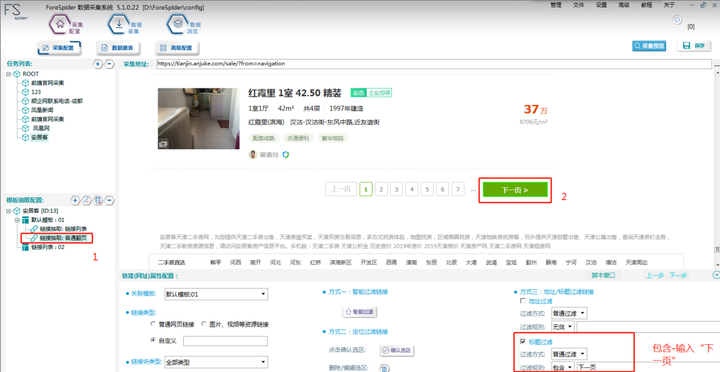
采集页内含其它多链接,这时需要将翻页进行配置,以便将该页面内所有链接内容都可抽取出来。
按照图示数据操作:
Step1:点击左侧“链接抽取:普通翻页”
Step2:Ctrl+鼠标左键点击“下一页”
Step3:点击右下角,选择“标题过滤”,过滤规则选择“包含”,手动输入“下一页”即可。
4. 翻页采集预览
接第3步,点击右上角【采集预览】查看是否可生成如下图的链接和数据。
注:下图的预览内含所有下一页包含的链接
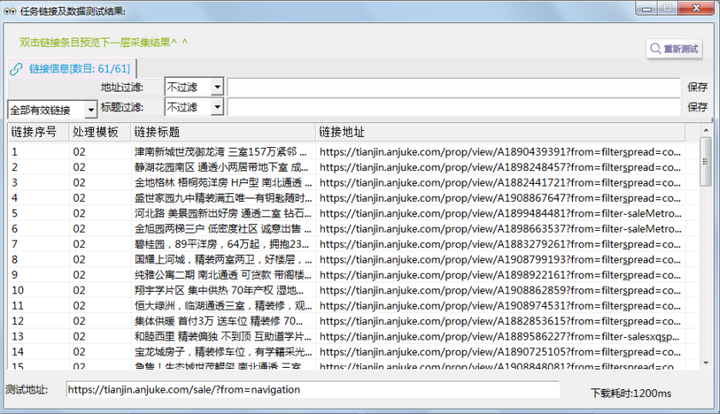 生成预览
生成预览
5. 数据抽取
在【新建任务】中输入的网址只是我们想采集的预览页面,具体采集的正文内容(数据)需要进入详情页面。
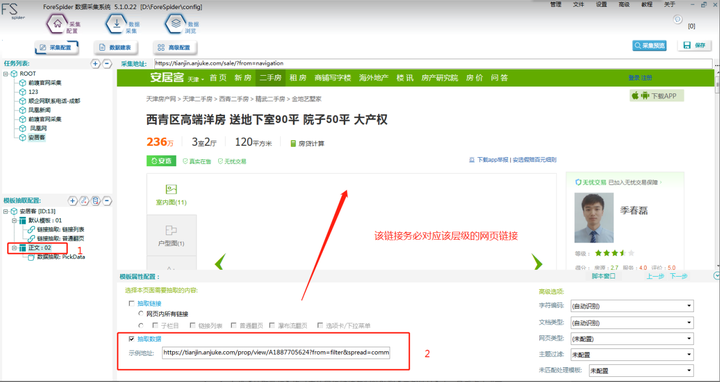
按照图示数据操作:
Step1:双击左侧红框位置,可自定义名称,这里我们取“正文”。
Step2:勾选【抽取数据】将对应的层级链接复制粘贴到【示例地址】中,最后点击“下一步”即可完成。(https://tianjin.anjuke.com/prop/view/A1887705624?from=filter&spread=commsearch_p&uniqid=pc5dd256fa182d89.39922172&position=1&kwtype=filter&now_time=1574065914)
6. 配置表单
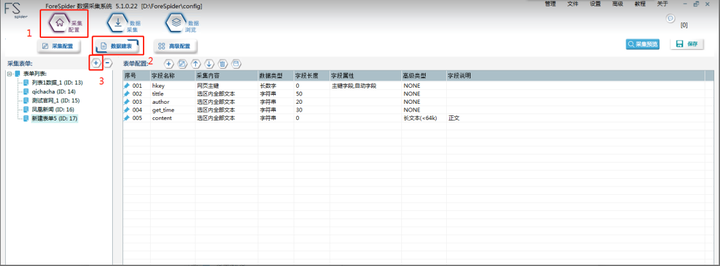
如图示点击【数据建表】:
Step1:点击“采集配置”-“数据建表”
Step2:点击“+”,新建表单并自定义名称,这里取“安居客”
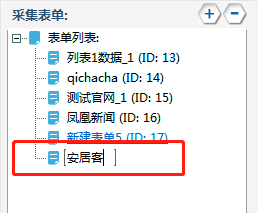
根据所需内容,配置表单字段,此处配置了包括主键、房屋信息、房屋编号、发布时间、文章内容等等。表单建立如下:
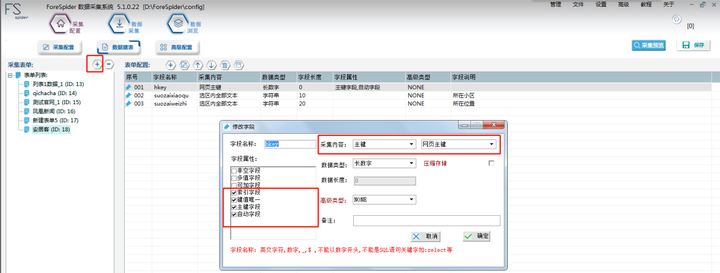 创建主键
创建主键
主键务必第一个创建,其含义为该表单所属ID
字段名称:hkey
采集内容 选择“主键”
数据类型 选择“长数字”
字段属性 选择 “索引字段”、“健值唯一”、“主键字段”、“全文索引”
最后点击“确定”即可。
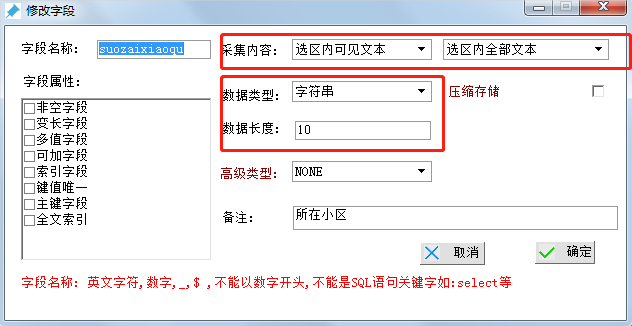 创建字段1-所在小区
创建字段1-所在小区
字段名称:suozaixiaoqu(所在小区 拼音)
采集内容 选择“选区内可见文本”
数据类型 选择“字符串”
数据长度 选择 范围10-20即可,最后点击确定。(备注可随意)
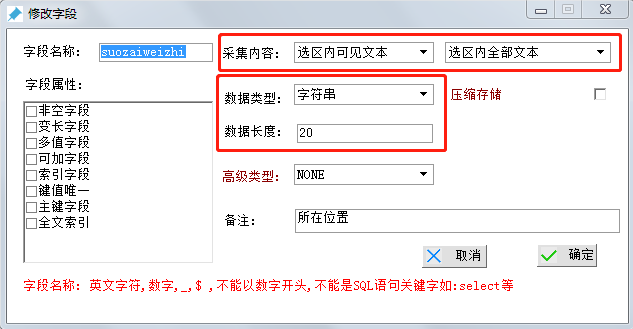 创建字段2-所在位置
创建字段2-所在位置
字段名称:suozaiweizhi(所在位置 拼音)
采集内容 选择“选区内可见文本”
数据类型 选择“字符串”
数据长度 选择 范围10-20即可,最后点击确定。(备注可随意)
表单配置字段自定义即可,如有多需求 可按上述同样操作即可。最终呈现如下图:
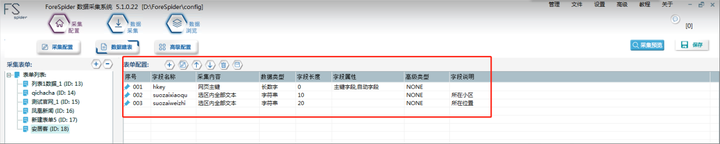
7. 关联数据表
表单配置完毕后,需要进行数据关联,操作如下:

选择所需的表单,点击【创建】按钮

创建表名称可随意填写,需注意 仅可使用“全英文”
8. 模板预览
通过预览,可以了解配置是否能够正确地采集到所需正文数据。鼠标右键后选择【链接列表】,可以单独预览某个链接的数据。
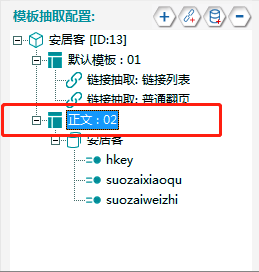 链接预览
链接预览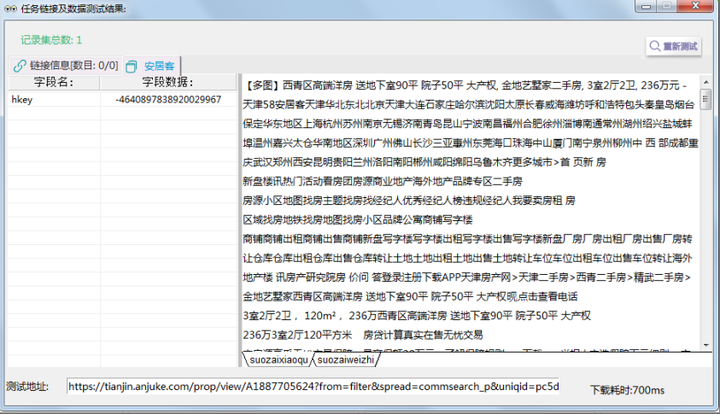 预览结果
预览结果
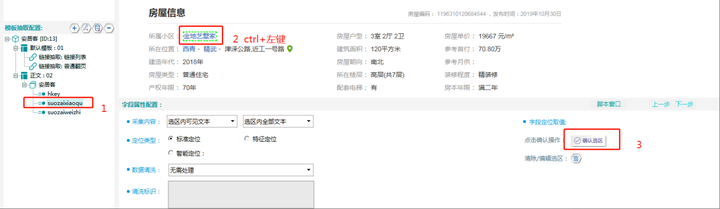
9. 确认选区
操作如下图所示:
Step1:在左侧“安客居”下属字段中点击“suozaixiaoqu”
Step2:找到“所属小区”对应信息“金城艺术家”并ctrl+左键点击选中该选区
Step3:最后点击“确认选区”即可
Step1:在左侧“安客居”下属字段中点击“suozaiweizhi”
Step2:找到“所属位置”对应信息“西青-精武-津来公路,近工一号路”并ctrl+左键点击选中该选区
Step3:最后点击“确认选区”即可
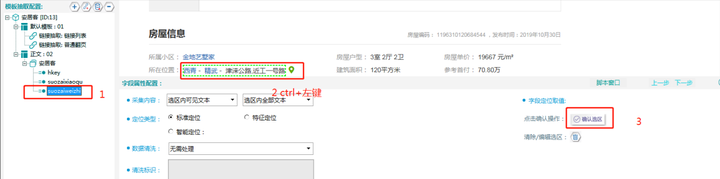
注意:主键无需确认选区,操作过程中要随时点击“保存”,养成良好习惯。
三. 采集数据
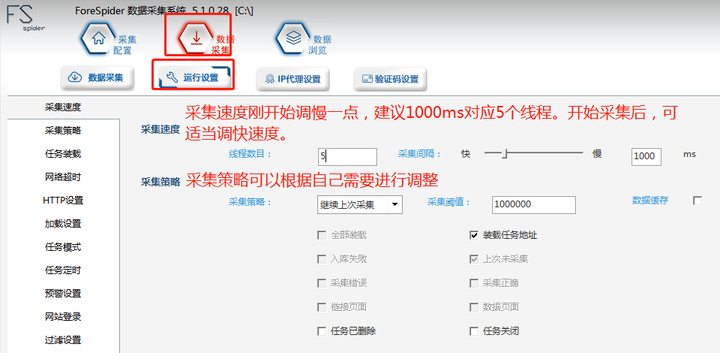
1. 运行设置
运行设置处可以设置采集速度、采集策略、任务装载等。
2. 选择采集任务
操作如下图数字所示:
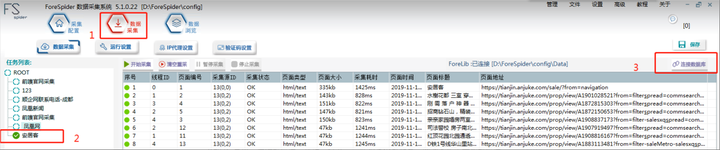
Step1:选择【数据采集】
Step2:在【任务列表】中勾选需要采集的任务,可勾选多个任务,同时采集。
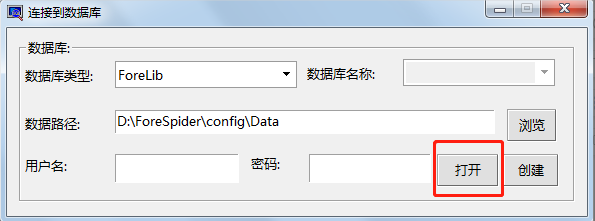
Step3:点击“连接数据库”选择“打开”,此步骤不可避免,因为采集需要和数据库进行关联。
3. 开始采集
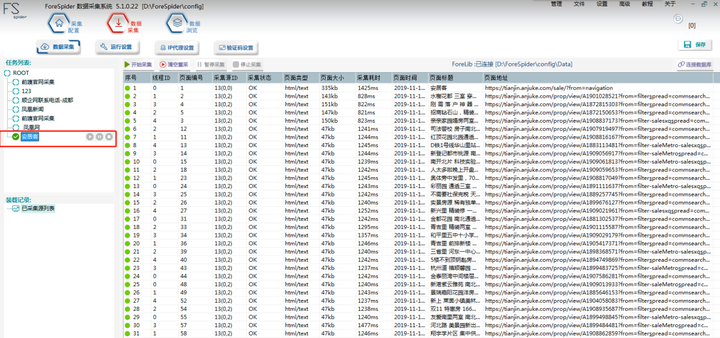
点击【开始采集】,系统开始进行采集。剩余任务数为0时,系统自动停止采集。用户也可以自己暂停任务或停止任务(停止任务会释放任务,再次启动时重新装载任务)。
4. 数据浏览
采集一段时间以后,点击【数据浏览】,在数据列表中选中对应的数据表,即可浏览采集到的数据,点击【刷新】按钮可以同步显示数据。
 数据浏览
数据浏览
5. 导出数据
点击【导出】按钮,选择导出文件格式后保存。
 导出数据
导出数据
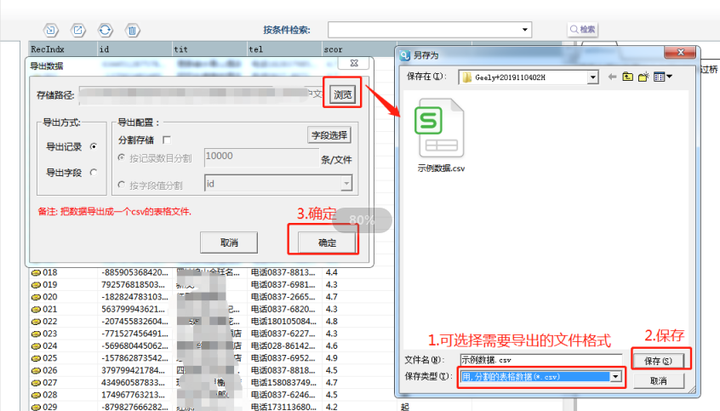 导出数据
导出数据



相关推荐
**前嗅forespider数据采集软件详解** 在信息化时代,数据的价值不言而喻,而高效的数据采集成为企业和个人获取信息的关键。前嗅forespider数据采集软件正是为解决这一需求而生,它是一款专为非专业编程人员设计的...
ForeSpider爬虫工具软件使用教程 使用ForeSpider爬虫软件批量采集企业信息公示系统.zip
在IT行业中,网络爬虫(Spider)是一种自动化程序,用于从互联网上抓取大量数据,以便分析、存储或再利用。在这个特殊的项目中,“weibo_spider_spider”指的是一个针对微博平台定制的爬虫程序,它能有效地爬取微博...
网上的便捷爬虫软件,可直接在许多网站上进行数据爬取
项目中可能包含了数据存储的相关逻辑,如将抓取的网页内容写入文件或与数据库进行交互。 **7. 异常处理** 网络爬虫在运行过程中可能会遇到各种问题,如网络连接错误、页面结构变化等,因此,异常处理机制是必不可少...