
жЎҲдҫӢпјҡйҮҮйӣҶгҖҗдёңж–№иҙўеҜҢзҪ‘гҖ‘йҰ–йЎөж–°й—»еҲ—иЎЁдёӯзҡ„ж–°й—»
В
В
дёҖ.В зҪ‘з«ҷеҶ…е®№
1.В зҪ‘з«ҷжҲӘеӣҫиҜҙжҳҺ
жң¬ж•ҷзЁӢд»ҘйҮҮйӣҶвҖңдёңж–№иҙўеҜҢзҪ‘вҖқйҰ–йЎөж–°й—»еҲ—иЎЁдёӯзҡ„ж–°й—»пјҲжӯЈж–Үж•°жҚ®пјүдёәдҫӢпјҢеҰӮдёӢеӣҫгҖӮ
 дёңж–№иҙўеҜҢе®ҳзҪ‘
дёңж–№иҙўеҜҢе®ҳзҪ‘
В
2.В йҮҮйӣҶз»“жһңжҲӘеӣҫ
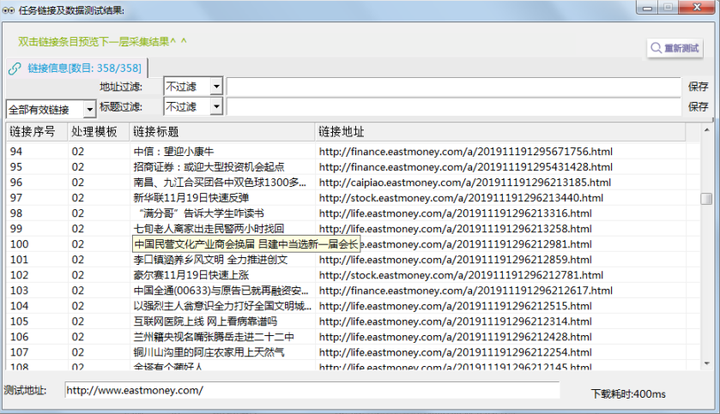 й“ҫжҺҘеҲ—иЎЁйҮҮйӣҶйў„и§Ҳ
й“ҫжҺҘеҲ—иЎЁйҮҮйӣҶйў„и§Ҳ
В
дәҢ.В ж“ҚдҪңж–№жі•
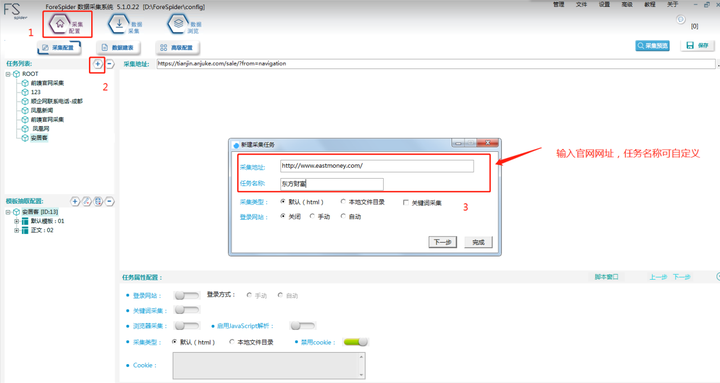
1.В ж–°е»әд»»еҠЎ
жҢүеӣҫзүҮж•°еӯ—жүҖзӨәпјҢ1-2-3е®ҢжҲҗж–°е»әд»»еҠЎзҡ„жӯҘйӘӨ
 ж–°е»әд»»еҠЎ
ж–°е»әд»»еҠЎ
В
Step1пјҡзӮ№еҮ»вҖңйҮҮйӣҶй…ҚзҪ®вҖқ
Step2пјҡзӮ№еҮ»гҖҗд»»еҠЎеҲ—иЎЁгҖ‘дёӯзҡ„вҖң+вҖқпјҢж–°е»әйҮҮйӣҶд»»еҠЎ
Step3пјҡеңЁеҰӮеӣҫзҡ„зәўжЎҶдёӯиҫ“е…ҘйҮҮйӣҶең°еқҖе’Ңд»»еҠЎеҗҚз§°пјҲеҸҜиҮӘе®ҡд№үпјүпјҢе®ҢжҲҗеҗҺзӮ№еҮ»вҖңдёӢдёҖжӯҘвҖқгҖӮ
В
йңҖиҰҒйҮҮйӣҶжӯЈж–Үж•°жҚ®пјҢжүҖд»ҘжӯӨеӨ„йңҖиҰҒеӢҫйҖүгҖҗй“ҫжҺҘеҲ—иЎЁгҖ‘пјҢеҰӮеӣҫпјҢжңҖеҗҺзӮ№еҮ»вҖңе®ҢжҲҗвҖқеҚіеҸҜгҖӮ
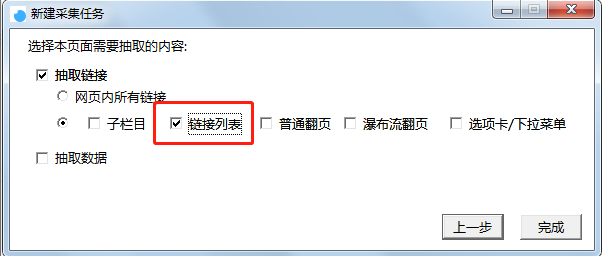 ж–°е»әйҮҮйӣҶд»»еҠЎ
ж–°е»әйҮҮйӣҶд»»еҠЎ
В
2.В й“ҫжҺҘжҠҪеҸ–й…ҚзҪ®
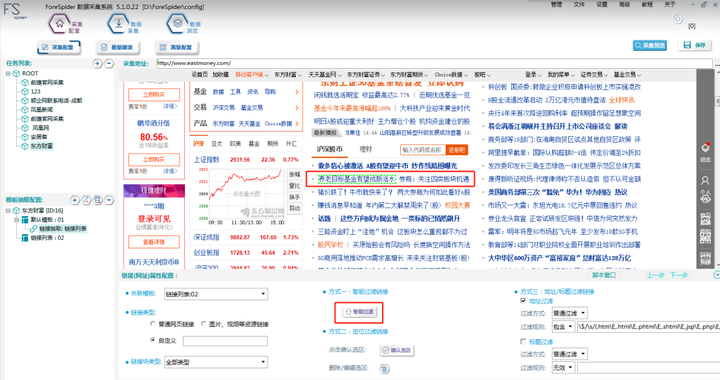
Step1пјҡеҶ…зҪ®жөҸи§ҲеҷЁжҳҫзӨәжҗңзҙўйЎөйқўеҗҺпјҢжҢүз…§жҸҗзӨәпјҡctrl+е·Ұй”®еҚ•еҮ»ж–Үз« ж ҮйўҳгҖӮ
Step2пјҡзӮ№еҮ»гҖҗжҷәиғҪиҝҮж»ӨгҖ‘жҢүй’®пјҢиҝҷж—¶еҸідҫ§зҡ„ең°еқҖиҝҮж»ӨдјҡжҳҫзӨәеҮәзӣёеә”зҡ„д»Јз ҒгҖӮ
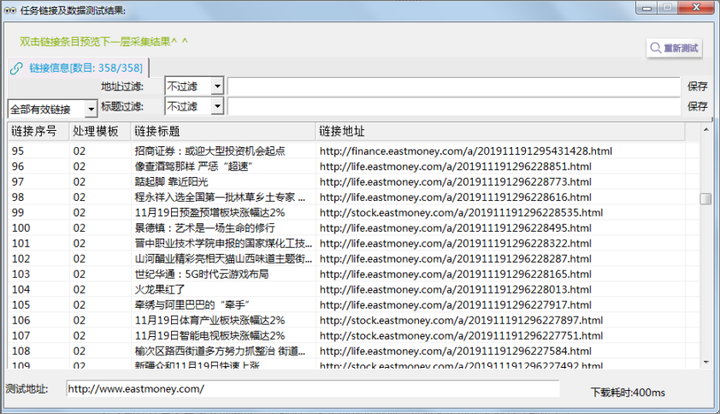
Step3пјҡжңҖеҗҺзӮ№еҮ»еҸідёҠи§’зҡ„гҖҗйҮҮйӣҶйў„и§ҲгҖ‘жҹҘзңӢжҳҜжңүеҶ…е®№пјҢеҰӮдёӢеӣҫпјҡ
В
3.В ж•°жҚ®жҠҪеҸ–
еңЁгҖҗж–°е»әд»»еҠЎгҖ‘дёӯиҫ“е…Ҙзҡ„зҪ‘еқҖеҸӘжҳҜжҲ‘们жғійҮҮйӣҶзҡ„йў„и§ҲйЎөйқўпјҢе…·дҪ“йҮҮйӣҶзҡ„жӯЈж–ҮеҶ…е®№пјҲж•°жҚ®пјүйңҖиҰҒиҝӣе…ҘиҜҰжғ…йЎөйқўгҖӮ
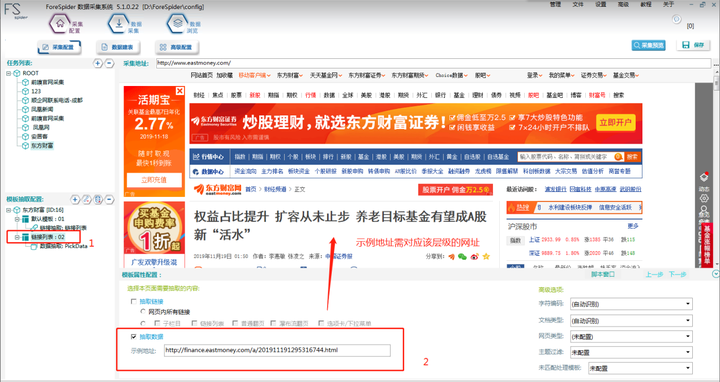
жҢүз…§еӣҫзӨәж•°жҚ®ж“ҚдҪңпјҡ
Step1пјҡеҸҢеҮ»е·Ұдҫ§зәўжЎҶдҪҚзҪ®пјҢеҸҜиҮӘе®ҡд№үеҗҚз§°гҖӮ
Step2пјҡеӢҫйҖүгҖҗжҠҪеҸ–ж•°жҚ®гҖ‘е°ҶеҜ№еә”зҡ„еұӮзә§й“ҫжҺҘеӨҚеҲ¶зІҳиҙҙеҲ°гҖҗзӨәдҫӢең°еқҖгҖ‘дёӯпјҢжңҖеҗҺзӮ№еҮ»вҖңдёӢдёҖжӯҘвҖқеҚіеҸҜе®ҢжҲҗгҖӮ
В
4.В й…ҚзҪ®иЎЁеҚ•
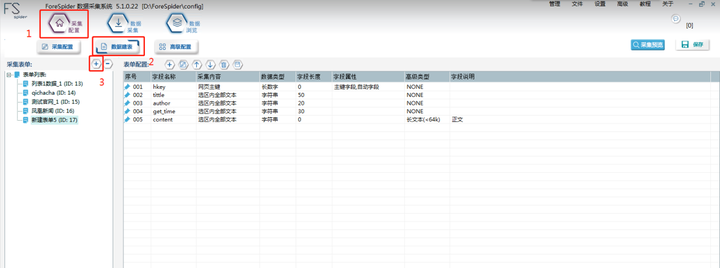
еҰӮеӣҫзӨәзӮ№еҮ»гҖҗж•°жҚ®е»әиЎЁгҖ‘пјҡ
Step1пјҡзӮ№еҮ»вҖңйҮҮйӣҶй…ҚзҪ®вҖқ
Step2пјҡйҖүжӢ©вҖңж•°жҚ®е»әиЎЁвҖқ
Step2пјҡзӮ№еҮ»вҖң+вҖқпјҢж–°е»әиЎЁеҚ•е№¶иҮӘе®ҡд№үеҗҚз§°пјҢиҝҷйҮҢеҸ–вҖңдёңж–№иҙўеҜҢвҖқ
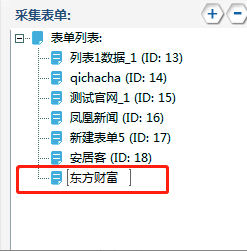
ж №жҚ®жүҖйңҖеҶ…е®№пјҢй…ҚзҪ®иЎЁеҚ•еӯ—ж®өпјҢжӯӨеӨ„й…ҚзҪ®дәҶеҢ…жӢ¬дё»й”®гҖҒж ҮйўҳгҖҒдҪңиҖ…гҖҒеҸ‘еёғж—¶й—ҙгҖҒж–Үз« еҶ…е®№зӯүзӯүгҖӮиЎЁеҚ•е»әз«ӢеҰӮдёӢпјҡ
 еҲӣе»әдё»й”®
еҲӣе»әдё»й”®
В
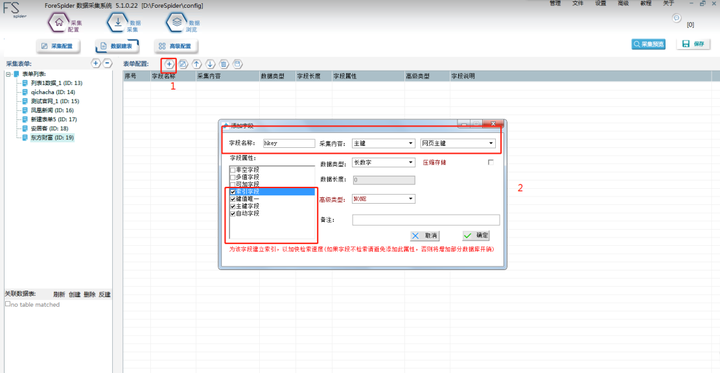
дё»й”®еҠЎеҝ…第дёҖдёӘеҲӣе»әпјҢе…¶еҗ«д№үдёәиҜҘиЎЁеҚ•жүҖеұһID
еӯ—ж®өеҗҚз§°пјҡhkey
йҮҮйӣҶеҶ…е®№ йҖүжӢ©вҖңдё»й”®вҖқ
ж•°жҚ®зұ»еһӢ йҖүжӢ©вҖңй•ҝж•°еӯ—вҖқ
еӯ—ж®өеұһжҖ§ йҖүжӢ© вҖңзҙўеј•еӯ—ж®өвҖқгҖҒвҖңеҒҘеҖје”ҜдёҖвҖқгҖҒвҖңдё»й”®еӯ—ж®өвҖқгҖҒвҖңе…Ёж–Үзҙўеј•вҖқ
жңҖеҗҺзӮ№еҮ»вҖңзЎ®е®ҡвҖқеҚіеҸҜгҖӮ
В
 еҲӣе»әеӯ—ж®ө1-ж Үйўҳ
еҲӣе»әеӯ—ж®ө1-ж Үйўҳ
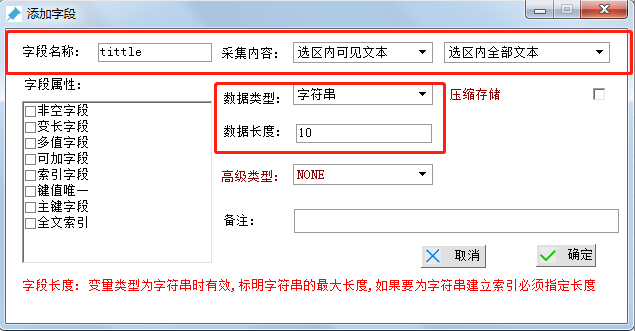
еӯ—ж®өеҗҚз§°пјҡtittle
йҮҮйӣҶеҶ…е®№ йҖүжӢ©вҖңйҖүеҢәеҶ…еҸҜи§Ғж–Үжң¬вҖқ
ж•°жҚ®зұ»еһӢ йҖүжӢ©вҖңеӯ—з¬ҰдёІвҖқ
ж•°жҚ®й•ҝеәҰ йҖүжӢ© иҢғеӣҙ10-20еҚіеҸҜпјҢжңҖеҗҺзӮ№еҮ»зЎ®е®ҡгҖӮпјҲеӨҮжіЁеҸҜйҡҸж„Ҹпјү
В
 еҲӣе»әеӯ—ж®ө2-дҪңиҖ…
еҲӣе»әеӯ—ж®ө2-дҪңиҖ…
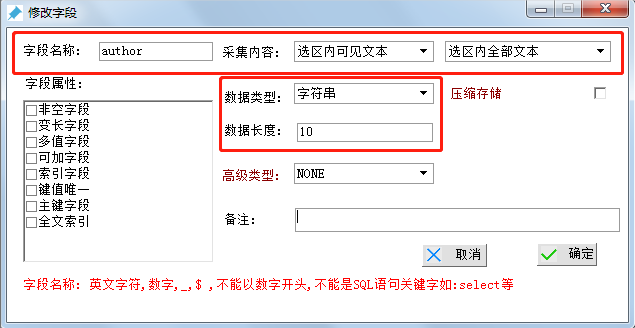
еӯ—ж®өеҗҚз§°пјҡauthor
йҮҮйӣҶеҶ…е®№ йҖүжӢ©вҖңйҖүеҢәеҶ…еҸҜи§Ғж–Үжң¬вҖқ
ж•°жҚ®зұ»еһӢ йҖүжӢ©вҖңеӯ—з¬ҰдёІвҖқ
ж•°жҚ®й•ҝеәҰ йҖүжӢ© иҢғеӣҙ10-20еҚіеҸҜпјҢжңҖеҗҺзӮ№еҮ»зЎ®е®ҡгҖӮпјҲеӨҮжіЁеҸҜйҡҸж„Ҹпјү
В
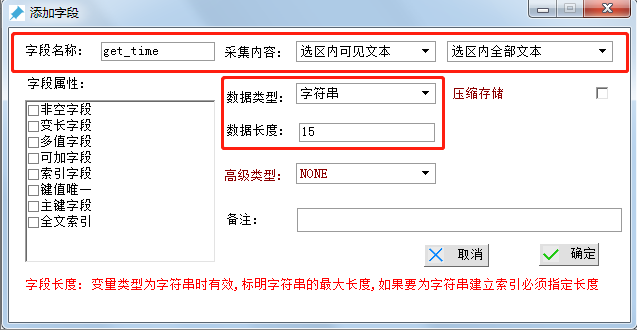 еҲӣе»әеӯ—ж®ө3-еҸ‘еёғж—¶й—ҙ
еҲӣе»әеӯ—ж®ө3-еҸ‘еёғж—¶й—ҙ
еӯ—ж®өеҗҚз§°пјҡget_timeпјҲжіЁж„ҸпјҡдёҖе®ҡжҳҜдёӢеҲ’зәҝпјү
йҮҮйӣҶеҶ…е®№ йҖүжӢ©вҖңйҖүеҢәеҶ…еҸҜи§Ғж–Үжң¬вҖқ
ж•°жҚ®зұ»еһӢ йҖүжӢ©вҖңеӯ—з¬ҰдёІвҖқ
ж•°жҚ®й•ҝеәҰ йҖүжӢ© иҢғеӣҙ10-20еҚіеҸҜпјҢжңҖеҗҺзӮ№еҮ»зЎ®е®ҡгҖӮпјҲеӨҮжіЁеҸҜйҡҸж„Ҹпјү
В
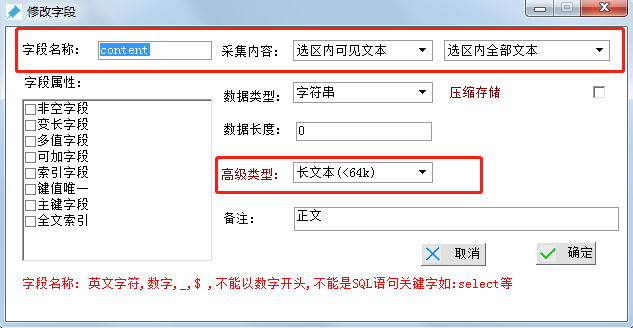 еҲӣе»әеӯ—ж®ө4-жӯЈж–Ү
еҲӣе»әеӯ—ж®ө4-жӯЈж–Ү
еӯ—ж®өеҗҚз§°пјҡcontent
йҮҮйӣҶеҶ…е®№ йҖүжӢ©вҖңйҖүеҢәеҶ…еҸҜи§Ғж–Үжң¬вҖқ
ж•°жҚ®зұ»еһӢ йҖүжӢ©вҖңеӯ—з¬ҰдёІвҖқ
жіЁж„ҸпјҢз”ұдәҺжӯЈж–ҮеҶ…е®№еҫҲеӨҡж— жі•з”Ёеӯ—з¬ҰдёІжқҘдј°йҮҸпјҢж•…иҝҷйҮҢйҖүжӢ©вҖңй«ҳзә§зұ»еһӢвҖқ-вҖңй•ҝж–Үжң¬<64kвҖқ
В
иЎЁеҚ•й…ҚзҪ®еӯ—ж®өиҮӘе®ҡд№үеҚіеҸҜпјҢеҰӮжңүеӨҡйңҖжұӮВ еҸҜжҢүдёҠиҝ°еҗҢж ·ж“ҚдҪңеҚіеҸҜгҖӮжңҖз»Ҳе‘ҲзҺ°еҰӮдёӢеӣҫпјҡ

В
5.В е…іиҒ”ж•°жҚ®иЎЁ
иЎЁеҚ•й…ҚзҪ®е®ҢжҜ•еҗҺпјҢйңҖиҰҒиҝӣиЎҢж•°жҚ®е…іиҒ”пјҢж“ҚдҪңеҰӮдёӢпјҡ

В
йҖүжӢ©жүҖйңҖзҡ„иЎЁеҚ•пјҢзӮ№еҮ»гҖҗеҲӣе»әгҖ‘жҢүй’®гҖӮ

еҲӣе»әиЎЁеҗҚз§°еҸҜйҡҸж„ҸеЎ«еҶҷпјҢйңҖжіЁж„Ҹ д»…еҸҜдҪҝз”ЁвҖңе…ЁиӢұж–ҮвҖқпјҢжңҖеҗҺзӮ№еҮ» зЎ®е®ҡ еҚіеҸҜе®ҢжҲҗгҖӮ
В
6.В жЁЎжқҝйў„и§Ҳ
йҖҡиҝҮйў„и§ҲпјҢеҸҜд»ҘдәҶи§Јй…ҚзҪ®жҳҜеҗҰиғҪеӨҹжӯЈзЎ®ең°йҮҮйӣҶеҲ°жүҖйңҖжӯЈж–Үж•°жҚ®гҖӮйј ж ҮеҸій”®еҗҺйҖүжӢ©гҖҗй“ҫжҺҘеҲ—иЎЁгҖ‘пјҢеҸҜд»ҘеҚ•зӢ¬йў„и§ҲжҹҗдёӘй“ҫжҺҘзҡ„ж•°жҚ®гҖӮ
 й“ҫжҺҘйў„и§Ҳ
й“ҫжҺҘйў„и§Ҳ
В
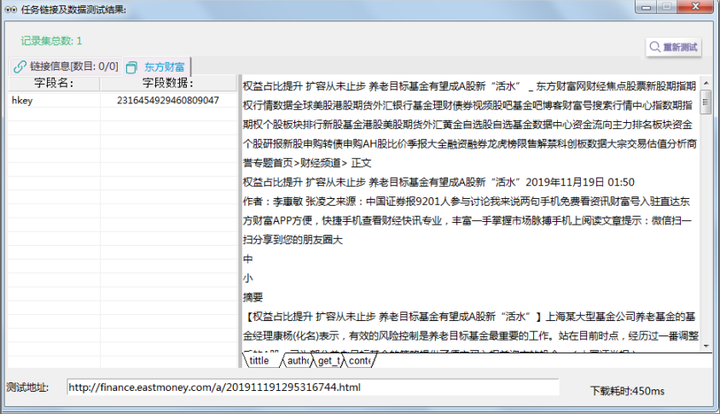 йў„и§Ҳз»“жһң
йў„и§Ҳз»“жһң
В
7.В зЎ®и®ӨйҖүеҢә
ж“ҚдҪңеҰӮдёӢеӣҫжүҖзӨәпјҡ
Step1пјҡеңЁе·Ұдҫ§вҖңдёңж–№иҙўеҜҢвҖқдёӢеұһеӯ—ж®өдёӯзӮ№еҮ»вҖңtittleвҖқ
Step2пјҡжүҫеҲ°ж ҮйўҳпјҲеӣҫдёӯж•°еӯ—2жүҖзӨәпјү并ctrl+е·Ұй”®зӮ№еҮ»йҖүдёӯиҜҘйҖүеҢә
Step3пјҡжңҖеҗҺзӮ№еҮ»вҖңзЎ®и®ӨйҖүеҢәвҖқеҚіеҸҜ

В
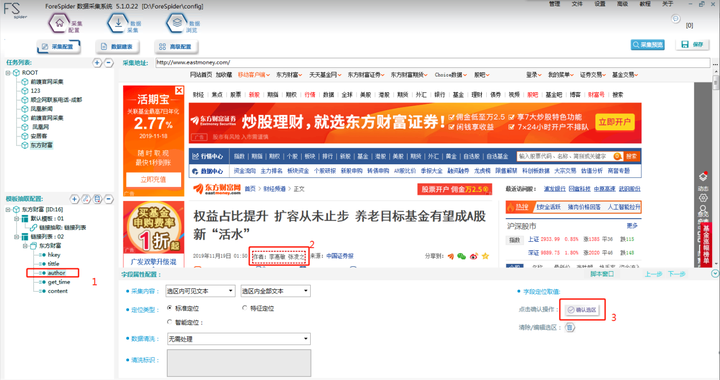
Step1пјҡеңЁе·Ұдҫ§вҖңдёңж–№иҙўеҜҢвҖқдёӢеұһеӯ—ж®өдёӯзӮ№еҮ»вҖңauthorвҖқ
Step2пјҡжүҫеҲ°ж–Үз« дҪңиҖ…пјҲеӣҫдёӯж•°еӯ—2жүҖзӨәпјү并ctrl+е·Ұй”®зӮ№еҮ»йҖүдёӯиҜҘйҖүеҢә
Step3пјҡжңҖеҗҺзӮ№еҮ»вҖңзЎ®и®ӨйҖүеҢәвҖқеҚіеҸҜ
В
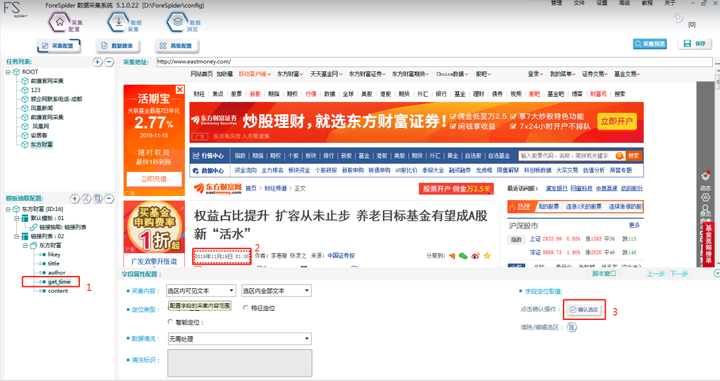
Step1пјҡеңЁе·Ұдҫ§вҖңдёңж–№иҙўеҜҢвҖқдёӢеұһеӯ—ж®өдёӯзӮ№еҮ»вҖңget_timeвҖқ
Step2пјҡжүҫеҲ°ж–Үз« дҪңиҖ…пјҲеӣҫдёӯж•°еӯ—2жүҖзӨәпјү并ctrl+е·Ұй”®зӮ№еҮ»йҖүдёӯиҜҘйҖүеҢә
Step3пјҡжңҖеҗҺзӮ№еҮ»вҖңзЎ®и®ӨйҖүеҢәвҖқеҚіеҸҜ
В
Step1пјҡеңЁе·Ұдҫ§вҖңдёңж–№иҙўеҜҢвҖқдёӢеұһеӯ—ж®өдёӯзӮ№еҮ»вҖңcontentвҖқ
Step2пјҡжүҫеҲ°ж–Үз« дҪңиҖ…пјҲеӣҫдёӯж•°еӯ—2жүҖзӨәпјү并shift+е·Ұй”®зӮ№еҮ»йҖүдёӯиҜҘйҖүеҢә
Step3пјҡжңҖеҗҺзӮ№еҮ»вҖңзЎ®и®ӨйҖүеҢәвҖқеҚіеҸҜ
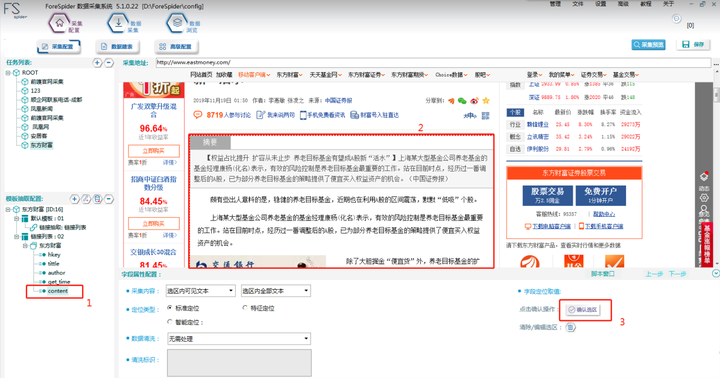
жіЁж„Ҹпјҡдё»й”®ж— йңҖзЎ®и®ӨйҖүеҢәпјҢж“ҚдҪңиҝҮзЁӢдёӯиҰҒйҡҸж—¶зӮ№еҮ»вҖңдҝқеӯҳвҖқпјҢе…»жҲҗиүҜеҘҪд№ жғҜгҖӮ
В
дёү.В йҮҮйӣҶж•°жҚ®
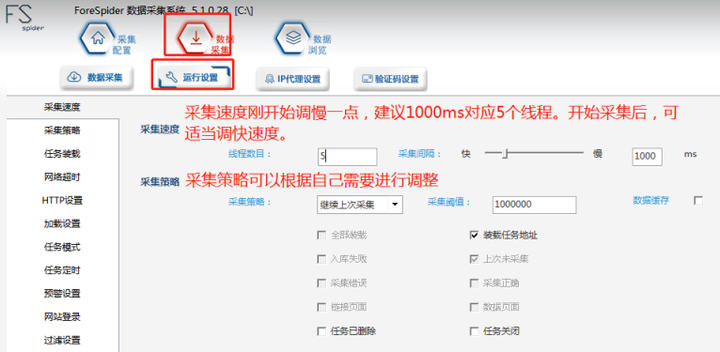
1.В иҝҗиЎҢи®ҫзҪ®
иҝҗиЎҢи®ҫзҪ®еӨ„еҸҜд»Ҙи®ҫзҪ®йҮҮйӣҶйҖҹеәҰгҖҒйҮҮйӣҶзӯ–з•ҘгҖҒд»»еҠЎиЈ…иҪҪзӯүгҖӮ
В
2.В йҖүжӢ©йҮҮйӣҶд»»еҠЎ
ж“ҚдҪңеҰӮдёӢеӣҫж•°еӯ—жүҖзӨәпјҡ
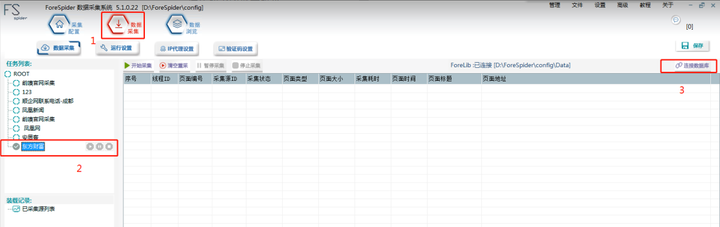
Step1пјҡйҖүжӢ©гҖҗж•°жҚ®йҮҮйӣҶгҖ‘
Step2пјҡеңЁгҖҗд»»еҠЎеҲ—иЎЁгҖ‘дёӯеӢҫйҖүйңҖиҰҒйҮҮйӣҶзҡ„д»»еҠЎпјҢеҸҜеӢҫйҖүеӨҡдёӘд»»еҠЎпјҢеҗҢж—¶йҮҮйӣҶгҖӮ
Step3пјҡзӮ№еҮ»вҖңиҝһжҺҘж•°жҚ®еә“вҖқйҖүжӢ©вҖңжү“ејҖвҖқпјҢжӯӨжӯҘйӘӨдёҚеҸҜйҒҝе…ҚпјҢеӣ дёәйҮҮйӣҶйңҖиҰҒе’Ңж•°жҚ®еә“иҝӣиЎҢе…іиҒ”гҖӮ
В
жіЁж„ҸпјҡйҮҮйӣҶејҖе§ӢеүҚпјҢеҠЎеҝ…дҝқиҜҒвҖңиЈ…иҪҪи®°еҪ•вҖқжҳҜз©әзҡ„гҖӮеҸҜзӮ№еҮ»еӣҫзӨәиҝӣиЎҢеҲ йҷӨпјҡ
В
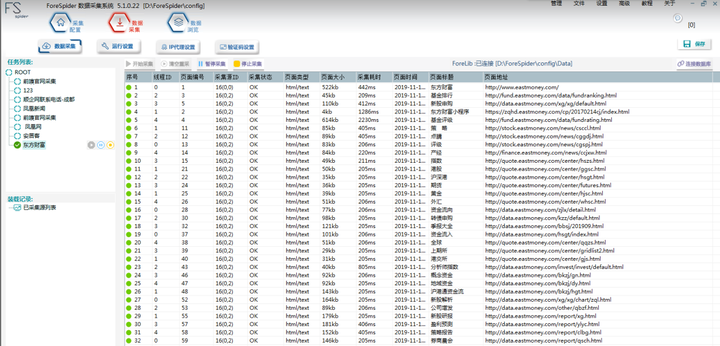
3.В ејҖе§ӢйҮҮйӣҶ
зӮ№еҮ»гҖҗејҖе§ӢйҮҮйӣҶгҖ‘пјҢзі»з»ҹејҖе§ӢиҝӣиЎҢйҮҮйӣҶгҖӮеү©дҪҷд»»еҠЎж•°дёә0ж—¶пјҢзі»з»ҹиҮӘеҠЁеҒңжӯўйҮҮйӣҶгҖӮз”ЁжҲ·д№ҹеҸҜд»ҘиҮӘе·ұжҡӮеҒңд»»еҠЎжҲ–еҒңжӯўд»»еҠЎпјҲеҒңжӯўд»»еҠЎдјҡйҮҠж”ҫд»»еҠЎпјҢеҶҚж¬ЎеҗҜеҠЁж—¶йҮҚж–°иЈ…иҪҪд»»еҠЎпјүгҖӮ
В
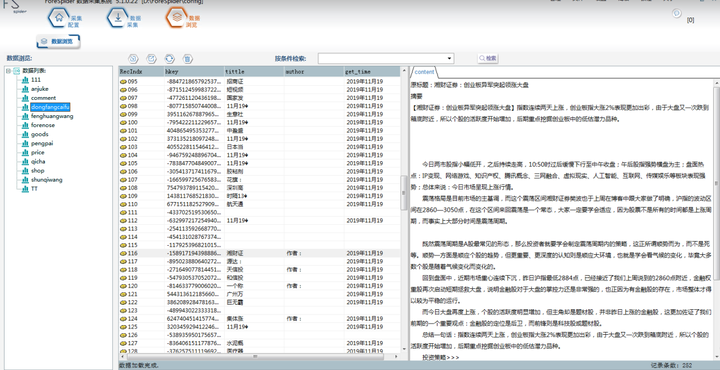
4.ж•°жҚ®жөҸи§Ҳ
йҮҮйӣҶдёҖж®өж—¶й—ҙд»ҘеҗҺпјҢзӮ№еҮ»гҖҗж•°жҚ®жөҸи§ҲгҖ‘пјҢеңЁж•°жҚ®еҲ—иЎЁдёӯйҖүдёӯеҜ№еә”зҡ„ж•°жҚ®иЎЁпјҢеҚіеҸҜжөҸи§ҲйҮҮйӣҶеҲ°зҡ„ж•°жҚ®пјҢзӮ№еҮ»гҖҗеҲ·ж–°гҖ‘жҢүй’®еҸҜд»ҘеҗҢжӯҘжҳҫзӨәж•°жҚ®гҖӮ
В
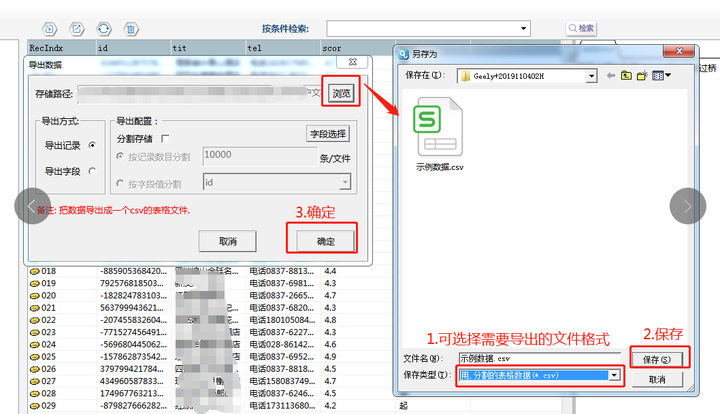
5.еҜјеҮәж•°жҚ®
зӮ№еҮ»гҖҗеҜјеҮәгҖ‘жҢүй’®пјҢйҖүжӢ©еҜјеҮәж–Үд»¶ж јејҸеҗҺдҝқеӯҳгҖӮ
 еҜјеҮәж•°жҚ®
еҜјеҮәж•°жҚ®
В
 еҜјеҮәж•°жҚ®
еҜјеҮәж•°жҚ®



зӣёе…іжҺЁиҚҗ
**еүҚе—…forespiderж•°жҚ®йҮҮйӣҶиҪҜ件иҜҰи§Ј** еңЁдҝЎжҒҜеҢ–ж—¶д»ЈпјҢж•°жҚ®зҡ„д»·еҖјдёҚиЁҖиҖҢе–»пјҢиҖҢй«ҳж•Ҳзҡ„ж•°жҚ®йҮҮйӣҶжҲҗдёәдјҒдёҡе’ҢдёӘдәәиҺ·еҸ–дҝЎжҒҜзҡ„е…ій”®гҖӮеүҚе—…forespiderж•°жҚ®йҮҮйӣҶиҪҜ件жӯЈжҳҜдёәи§ЈеҶіиҝҷдёҖйңҖжұӮиҖҢз”ҹпјҢе®ғжҳҜдёҖж¬ҫдё“дёәйқһдё“дёҡзј–зЁӢдәәе‘ҳи®ҫи®Ўзҡ„...
ForeSpiderзҲ¬иҷ«е·Ҙе…·иҪҜ件дҪҝз”Ёж•ҷзЁӢ дҪҝз”ЁForeSpiderзҲ¬иҷ«иҪҜ件жү№йҮҸйҮҮйӣҶдјҒдёҡдҝЎжҒҜе…¬зӨәзі»з»ҹ.zip
зҪ‘дёҠзҡ„дҫҝжҚ·зҲ¬иҷ«иҪҜ件пјҢеҸҜзӣҙжҺҘеңЁи®ёеӨҡзҪ‘з«ҷдёҠиҝӣиЎҢж•°жҚ®зҲ¬еҸ–
еңЁITиЎҢдёҡдёӯпјҢзҪ‘з»ңзҲ¬иҷ«пјҲSpiderпјүжҳҜдёҖз§ҚиҮӘеҠЁеҢ–зЁӢеәҸпјҢз”ЁдәҺд»Һдә’иҒ”зҪ‘дёҠжҠ“еҸ–еӨ§йҮҸж•°жҚ®пјҢд»ҘдҫҝеҲҶжһҗгҖҒеӯҳеӮЁжҲ–еҶҚеҲ©з”ЁгҖӮеңЁиҝҷдёӘзү№ж®Ҡзҡ„йЎ№зӣ®дёӯпјҢвҖңweibo_spider_spiderвҖқжҢҮзҡ„жҳҜдёҖдёӘй’ҲеҜ№еҫ®еҚҡе№іеҸ°е®ҡеҲ¶зҡ„зҲ¬иҷ«зЁӢеәҸпјҢе®ғиғҪжңүж•Ҳең°зҲ¬еҸ–еҫ®еҚҡ...
е®һйӘҢеҢ…еҗ«дәҶеҮ дёӘе…·дҪ“жӯҘйӘӨпјҢйҰ–е…ҲжҳҜзҲ¬иҷ«иҪҜ件еүҚе—…ForeSpiderзҡ„е®үиЈ…пјҢ然еҗҺжҳҜйў‘йҒ“зҡ„йҖүжӢ©пјҢжҺҘдёӢжқҘжҳҜзҪ‘йЎөж•°жҚ®зҡ„йҮҮйӣҶгҖӮиҝҷдәӣжӯҘйӘӨжҢҮеҜјеӯҰз”ҹеҰӮдҪ•еҮҶеӨҮе®һйӘҢзҺҜеўғпјҢд»ҘеҸҠеҰӮдҪ•ж“ҚдҪңзҲ¬иҷ«иҪҜ件пјҢйҖҗжӯҘж·ұе…ҘеҲ°ж•°жҚ®иҺ·еҸ–зҡ„е®һи·өдёӯгҖӮ зҹҘиҜҶзӮ№еӣӣпјҡ...
йЎ№зӣ®дёӯеҸҜиғҪеҢ…еҗ«дәҶж•°жҚ®еӯҳеӮЁзҡ„зӣёе…ійҖ»иҫ‘пјҢеҰӮе°ҶжҠ“еҸ–зҡ„зҪ‘йЎөеҶ…е®№еҶҷе…Ҙж–Ү件жҲ–дёҺж•°жҚ®еә“иҝӣиЎҢдәӨдә’гҖӮ **7. ејӮеёёеӨ„зҗҶ** зҪ‘з»ңзҲ¬иҷ«еңЁиҝҗиЎҢиҝҮзЁӢдёӯеҸҜиғҪдјҡйҒҮеҲ°еҗ„з§Қй—®йўҳпјҢеҰӮзҪ‘з»ңиҝһжҺҘй”ҷиҜҜгҖҒйЎөйқўз»“жһ„еҸҳеҢ–зӯүпјҢеӣ жӯӨпјҢејӮеёёеӨ„зҗҶжңәеҲ¶жҳҜеҝ…дёҚеҸҜе°‘...