Frontier是Heritrix最核心的组成部分之一,也是最复杂的组成部分.它主要功能是为处理链接的线程提供URL,并负责链接处理完成后的一些后续调度操作.并且为了提高效率,它在内部使用了Berkeley DB.本节将对它的内部机理进行详细解剖.
在Heritrix的官方文档上有一个Frontier的例子,虽然很简单,但是它却解释Frontier实现的基本原理.在这里就不讨论,有兴趣的读者可以参考相应文档.但是不得不提它的三个核心方法:
(1)next(int timeout):为处理线程提供一个链接.Heritrix的所有处理线程(ToeThread)都是通过调用该方法获取链接的.
(2)schedule(CandidateURI caURI):调度待处理的链接.
(3)finished(CrawlURI cURI):完成一个已处理的链接.
整体结构如下:
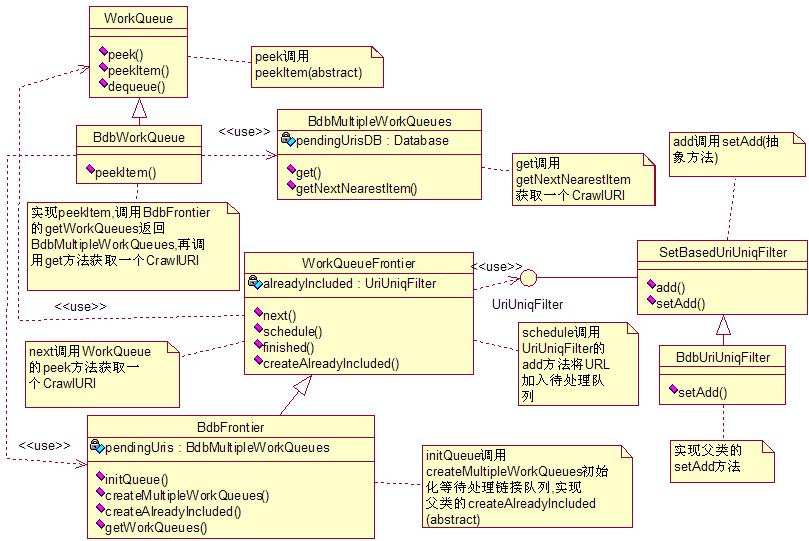
BdbMultipleWorkQueues:
它是对Berkeley DB的简单封装.在内部有一个Berkeley Database,存放所有待处理的链接.

 Code
Code
<!----> package org.archive.crawler.frontier;
package org.archive.crawler.frontier;
public class BdbMultipleWorkQueues
{
 //存放所有待处理的URL的数据库
//存放所有待处理的URL的数据库
private Database pendingUrisDB = null;
//由key获取一个链接
public CrawlURI get(DatabaseEntry headKey)
 throws DatabaseException {
throws DatabaseException {
DatabaseEntry result = new DatabaseEntry();
// From Linda Lee of sleepycat:
// "You want to check the status returned from Cursor.getSearchKeyRange
// to make sure that you have OperationStatus.SUCCESS. In that case,
// you have found a valid data record, and result.getData()
// (called by internally by the binding code, in this case) will be
// non-null. The other possible status return is
// OperationStatus.NOTFOUND, in which case no data record matched
// the criteria. "
//由key获取相应的链接
OperationStatus status = getNextNearestItem(headKey, result);
CrawlURI retVal = null;
if (status != OperationStatus.SUCCESS) {
LOGGER.severe("See '1219854 NPE je-2.0 "
+ "entryToObject '. OperationStatus "
'. OperationStatus "
+ " was not SUCCESS: "
+ status
+ ", headKey "
+ BdbWorkQueue.getPrefixClassKey(headKey.getData()));
return null;
 }
}
try {
retVal = (CrawlURI)crawlUriBinding.entryToObject(result);
} catch (RuntimeExceptionWrapper rw) {
LOGGER.log(
Level.SEVERE,
"expected object missing in queue " +
BdbWorkQueue.getPrefixClassKey(headKey.getData()),
rw);
return null;
}
retVal.setHolderKey(headKey);
return retVal;//返回链接
}
//从等处理列表获取一个链接
protected OperationStatus getNextNearestItem(DatabaseEntry headKey,
DatabaseEntry result) throws DatabaseException {
Cursor cursor = null;
OperationStatus status;
try {
//打开游标
cursor = this.pendingUrisDB.openCursor(null, null);
// get cap; headKey at this point should always point to
// a queue-beginning cap entry (zero-length value)
status = cursor.getSearchKey(headKey, result, null);
if(status!=OperationStatus.SUCCESS || result.getData().length > 0) {
// cap missing
throw new DatabaseException("bdb queue cap missing");
}
// get next item (real first item of queue)
status = cursor.getNext(headKey,result,null);
} finally {
if(cursor!=null) {
cursor.close();
}
}
return status;
}
/**
* Put the given CrawlURI in at the appropriate place.
* 添加URL到数据库
* @param curi
* @throws DatabaseException
*/
public void put(CrawlURI curi, boolean overwriteIfPresent)
throws DatabaseException {
DatabaseEntry insertKey = (DatabaseEntry)curi.getHolderKey();
if (insertKey == null) {
insertKey = calculateInsertKey(curi);
curi.setHolderKey(insertKey);
}
DatabaseEntry value = new DatabaseEntry();
crawlUriBinding.objectToEntry(curi, value);
// Output tally on avg. size if level is FINE or greater.
if (LOGGER.isLoggable(Level.FINE)) {
tallyAverageEntrySize(curi, value);
}
OperationStatus status;
if(overwriteIfPresent) {
//添加
status = pendingUrisDB.put(null, insertKey, value);
} else {
status = pendingUrisDB.putNoOverwrite(null, insertKey, value);
}
if(status!=OperationStatus.SUCCESS) {
LOGGER.severe("failed; "+status+ " "+curi);
}
}
 }
}
BdbWorkQueue:
代表一个链接队列,该队列中所有的链接都具有相同的键值.它实际上是通过调用BdbMultipleWorkQueues的get方法从等处理链接数据库中取得一个链接的.
Code
<!---->package org.archive.crawler.frontier;
public class BdbWorkQueue extends WorkQueue
implements Comparable, Serializabl
{
//获取一个URL
protected CrawlURI peekItem(final WorkQueueFrontier frontier)
throws IOException {
/**
* 关键:从BdbFrontier中返回pendingUris
*/
final BdbMultipleWorkQueues queues = ((BdbFrontier) frontier)
.getWorkQueues();
DatabaseEntry key = new DatabaseEntry(origin);
CrawlURI curi = null;
int tries = 1;
while(true) {
try {
//获取链接
curi = queues.get(key);
} catch (DatabaseException e) {
LOGGER.log(Level.SEVERE,"peekItem failure; retrying",e);
}
return curi;
}
}
WorkQueueFrontier:
实现了最核心的三个方法.
Code
<!---->public CrawlURI next()
throws InterruptedException, EndedException {
while (true) { // loop left only by explicit return or exception
long now = System.currentTimeMillis();
// Do common checks for pause, terminate, bandwidth-hold
preNext(now);
synchronized(readyClassQueues) {
int activationsNeeded = targetSizeForReadyQueues() - readyClassQueues.size();
while(activationsNeeded > 0 && !inactiveQueues.isEmpty()) {
activateInactiveQueue();
activationsNeeded--;
}
}
WorkQueue readyQ = null;
Object key = readyClassQueues.poll(DEFAULT_WAIT,TimeUnit.MILLISECONDS);
if (key != null) {
readyQ = (WorkQueue)this.allQueues.get(key);
}
if (readyQ != null) {
while(true) { // loop left by explicit return or break on empty
CrawlURI curi = null;
synchronized(readyQ) {
/**取出一个URL,最终从子类BdbFrontier的
* pendingUris中取出一个链接
*/
curi = readyQ.peek(this);
if (curi != null) {
// check if curi belongs in different queue
String currentQueueKey = getClassKey(curi);
if (currentQueueKey.equals(curi.getClassKey())) {
// curi was in right queue, emit
noteAboutToEmit(curi, readyQ);
//加入正在处理队列中
inProcessQueues.add(readyQ);
return curi; //返回
}
// URI's assigned queue has changed since it
// was queued (eg because its IP has become
// known). Requeue to new queue.
curi.setClassKey(currentQueueKey);
readyQ.dequeue(this);//出队列
decrementQueuedCount(1);
curi.setHolderKey(null);
// curi will be requeued to true queue after lock
// on readyQ is released, to prevent deadlock
} else {
// readyQ is empty and ready: it's exhausted
// release held status, allowing any subsequent
// enqueues to again put queue in ready
readyQ.clearHeld();
break;
}
}
if(curi!=null) {
// complete the requeuing begun earlier
sendToQueue(curi);
}
}
} else {
// ReadyQ key wasn't in all queues: unexpected
if (key != null) {
logger.severe("Key "+ key +
" in readyClassQueues but not allQueues");
}
}
if(shouldTerminate) {
// skip subsequent steps if already on last legs
throw new EndedException("shouldTerminate is true");
}
if(inProcessQueues.size()==0) {
// Nothing was ready or in progress or imminent to wake; ensure
// any piled-up pending-scheduled URIs are considered
this.alreadyIncluded.requestFlush();
}
}
}
//将URL加入待处理队列
public void schedule(CandidateURI caUri) {
// Canonicalization may set forceFetch flag. See
// #canonicalization(CandidateURI) javadoc for circumstance.
String canon = canonicalize(caUri);
if (caUri.forceFetch()) {
alreadyIncluded.addForce(canon, caUri);
} else {
alreadyIncluded.add(canon, caUri);
}
}
BdbFrontier:
继承了WorkQueueFrontier,是Heritrix唯一个具有实际意义的链接工厂.
Code
<!---->package org.archive.crawler.frontier;
public class BdbFrontier extends WorkQueueFrontier implements Serializable
{
/** 所有待抓取的链接*/
protected transient BdbMultipleWorkQueues pendingUris;
//初始化pendingUris,父类为抽象方法
protected void initQueue() throws IOException {
try {
this.pendingUris = createMultipleWorkQueues();
} catch(DatabaseException e) {
throw (IOException)new IOException(e.getMessage()).initCause(e);
}
}
private BdbMultipleWorkQueues createMultipleWorkQueues()
throws DatabaseException {
return new BdbMultipleWorkQueues(this.controller.getBdbEnvironment(),
this.controller.getBdbEnvironment().getClassCatalog(),
this.controller.isCheckpointRecover());
}
protected BdbMultipleWorkQueues getWorkQueues() {
return pendingUris;
}
}
BdbUriUniqFilter:
实际上是一个过滤器,它用来检查一个要进入等待队列的链接是否已经被抓取过.
Code
<!---->//添加URL
protected boolean setAdd(CharSequence uri) {
DatabaseEntry key = new DatabaseEntry();
LongBinding.longToEntry(createKey(uri), key);
long started = 0;
OperationStatus status = null;
try {
if (logger.isLoggable(Level.INFO)) {
started = System.currentTimeMillis();
}
//添加到数据库
status = alreadySeen.putNoOverwrite(null, key, ZERO_LENGTH_ENTRY);
if (logger.isLoggable(Level.INFO)) {
aggregatedLookupTime +=
(System.currentTimeMillis() - started);
}
} catch (DatabaseException e) {
logger.severe(e.getMessage());
}
if (status == OperationStatus.SUCCESS) {
count++;
if (logger.isLoggable(Level.INFO)) {
final int logAt = 10000;
if (count > 0 && ((count % logAt) == 0)) {
logger.info("Average lookup " +
(aggregatedLookupTime / logAt) + "ms.");
aggregatedLookupTime = 0;
}
}
}
//如果存在,返回false
if(status == OperationStatus.KEYEXIST) {
return false; // not added
} else {
return true;
}
}
分享到:





相关推荐
Heritrix 是一个由 java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。官网下载好像要翻墙,我下下来方便大家使用,这是3.4版本,配合heritrix-3.4.0-SNAPSHOT-dist.zip使用
Heritrix 1.14.4是该工具的一个版本,提供了两个压缩包:`heritrix-1.14.4.zip`和`heritrix-1.14.4-src.zip`。这两个文件分别包含了不同的内容,便于用户根据需求进行使用和开发。 `heritrix-1.14.4.zip` 包含了...
总的来说,Heritrix-1.14.4-src提供了深入了解网络爬虫工作原理的机会,同时也让用户有机会自定义和优化爬虫行为,以满足特定的业务需求。虽然这个版本可能没有最新版的特性,但对于学习和理解爬虫技术来说,仍然是...
在提供的压缩包中,有两个主要文件:"heritrix-1.14.4.zip" 和 "heritrix-1.14.4-src.zip"。前者是Heritrix的编译后的二进制版本,可以直接运行,而后者包含了源代码,对于希望定制或深入理解Heritrix工作原理的...
这个"heritrix-1.14.4"版本是Heritrix的特定发行版,提供了对互联网资源进行系统性抓取的功能,帮助用户构建自己的网络存档。 标题"heritrix-1.14.4"表明这是Heritrix的1.14.4版本,这是一个重要的标识,因为每个...
通过深入研究Heritrix-1.14.4的源代码,你可以学习到网络爬虫的基本架构,了解HTTP通信、网页解析、链接处理和数据存储等相关技术,这对于提升你的Web开发和数据抓取能力大有裨益。同时,这也是一个实践软件工程和...
1. **heritrix-3.1.0-dist.zip**:这是Heritrix的发行版,包含运行所需的所有文件,如Java可执行文件(JARs)、配置文件和文档。用户可以直接下载并运行此版本来启动爬虫服务,无需构建源代码。其中,`heritrix-...
- `heritrix-3.4.0-SNAPSHOT`目录:这是Heritrix的主目录,包含了所有运行所需的基本文件,如jar包、配置文件、文档等。 - `bin`子目录:存放启动和停止Heritrix的脚本,通常在Unix/Linux环境下使用`start.sh`和`...
3. **内容处理器**:这些组件负责解析和处理抓取到的网页内容,例如提取链接、识别元数据等。 4. **存储机制**:Heritrix支持多种存储选项,如文件系统、数据库或自定义存储解决方案,用于保存抓取的数据。 5. **...
heritrix-1.12.1-src.zip与heritrix 配置文档
"heritrix-1.14.4-docs.rar"这个压缩包包含了该版本的文档,帮助用户理解和使用Heritrix。 文档通常包括用户手册、开发者指南、API参考等,这些内容对于熟悉Heritrix的架构、配置和编程接口至关重要。由于文件较大...
Heritrix的压缩包"heritrix-1.14.2.zip"包含以下组件和文件: 1. **源代码**:包含了Heritrix的Java源代码,用户可以查看和修改这些代码以适应自己的需求。 2. **构建脚本**:如Ant或Maven脚本,用于编译和打包项目...
在提供的压缩包文件中,有两个主要的文件:`heritrix-3.1.0-dist.tar.gz`和`heritrix-3.1.0-src.tar.gz`。这两个文件分别包含了Heritrix的二进制发行版和源代码。 1. `heritrix-3.1.0-dist.tar.gz`: 这个文件是...
近期需要使用heritrix-1.14.4,配了半天才配好,这个是控制台执行版本. 注意:解压到相关目录,之后配置系统环境变量"HERITRIX_HOME"到该解压目录(Java环境已经配置好)。 使用控制台命令启动 : heritrix --admin=...
标题"heritrix-1.14.4 for linux"表明这是Heritrix的Linux兼容版本,版本号为1.14.4。在Linux操作系统上运行Heritrix,用户可以利用Linux系统的稳定性和高效性来处理大量的网络抓取任务。 描述中的"heritrix-1.14.4...
这个版本的源码和编译后的二进制文件分别以"heritrix-1.14.4.zip"和"heritrix-1.14.4-src.zip"的名义提供,允许用户进行深入研究、学习或二次开发。 在Heritrix中,爬虫的主要工作流程包括种子管理、URL过滤、内容...
在“heritrix-1.12.1.zip”这个压缩包中,用户可以找到Heritrix的1.12.1版本的源代码和其他相关文件,这为学习和自定义网络爬虫提供了宝贵的资源。 Heritrix的核心功能是模拟浏览器行为,遍历互联网上的链接,系统...
这个名为"Heritrix-User-Manual.rar_heritrix"的压缩包包含了Heritrix用户手册的PDF版本,是学习和操作Heritrix的重要资源。下面将详细介绍Heritrix的基本概念、安装步骤、任务创建以及任务分析。 1. **Heritrix...
"heritrix-1.14.3-src.zip"是一个包含了Heritrix 1.14.3版本源代码的压缩文件,对于那些希望深入理解其工作原理或者想要自定义功能的开发者来说,这是一个宝贵的资源。 Heritrix的核心设计基于模块化架构,允许...
在深入理解Heritrix-1.14.3之前,我们首先需要了解什么是网络爬虫以及它的工作原理。 网络爬虫,又称为网页蜘蛛,是一种自动化程序,它按照预设的规则在网络(尤其是万维网)上遍历并抓取信息。它通常从一个或几个...