- 浏览: 1058920 次
- 性别:

- 来自: 北京
-

文章分类
- 全部博客 (538)
- 奇文共赏 (36)
- spring (13)
- hibernate (10)
- AOP/Aspectj (9)
- spring security (7)
- lucence (5)
- compass (3)
- jbmp (2)
- jboss rule(drools) (0)
- birt (1)
- jasper (1)
- cxf (3)
- flex (98)
- webgis (6)
- 设计模式 (1)
- 代码重构 (2)
- log4j (1)
- tomcat (9)
- 神品音乐 (1)
- 工作计划 (2)
- appfuse (1)
- svn (4)
- 寻章摘句 (3)
- eclipse (10)
- arcgis api for flex (1)
- 算法 (5)
- opengis-cs (1)
- bug心得 (13)
- 图标 (1)
- software&key (14)
- java (17)
- 搞笑视频 (13)
- sqlserver (9)
- postgresql (1)
- postgis (0)
- geoserver (5)
- 日子 (50)
- 水晶报表 (1)
- 绝对电影 (3)
- Alternativa3D (1)
- 酷站大全 (10)
- c++ (5)
- oracle (17)
- oracle spatial (25)
- flashbuilder4 (3)
- TweenLite (1)
- DailyBuild (6)
- 华山论贱 (5)
- 系统性能 (5)
- 经典古文 (6)
- SOA/SCA/OSGI (6)
- jira (2)
- Hadoop生态圈(hadoop/hbase/pig/hive/zookeeper) (37)
- 风水 (1)
- linux操作基础 (17)
- 经济 (4)
- 茶 (3)
- JUnit (1)
- C# dotNet (1)
- netbeans (1)
- Java2D (1)
- QT4 (1)
- google Test/Mock/AutoTest (3)
- maven (1)
- 3d/OSG (1)
- Eclipse RCP (3)
- CUDA (1)
- Access control (0)
- http://linux.chinaunix.net/techdoc/beginner/2008/01/29/977725.shtml (1)
- redis (1)
最新评论
-
dove19900520:
朋友,你确定你的标题跟文章内容对应???
tomcat控制浏览器不缓存 -
wussrc:
我只想说牛逼,就我接触过的那点云计算的东西,仔细想想还真是这么 ...
别样解释云计算,太TM天才跨界了 -
hw_imxy:
endpoint="/Hello/messagebr ...
flex+java代码分两个工程 -
gaohejie:
rsrsdgrfdh坎坎坷坷
Flex 与 Spring 集成 -
李涤尘:
谢谢。不过说得有点太罗嗦了。
Oracle数据库数据的导入及导出(转)
对hadoop task进行profiling的几种方法整理
http://blog.csdn.net/AE86_FC/archive/2010/10/22/5957793.aspx
在hadoop中,当一个job的调试完成,执行成功后,job的开发者接下来该思考的问题通常就是:如何将job跑的更快,更加高效,更节省资源呢?这个话题其实是一个老生常谈的话题了,很多有经验的工程师,开发人员和机构都分享过类似的经验。通常来说,应用程序千变万化,程序逻辑也不尽相同,程序的执行瓶颈通常也不尽相同,有的job是IO密集型的作业,那么优化其算法效率意义就不大,而有的job是CPU密集型的,那么对其中间结果压缩,或者调整类似io.sort.mb,io.sort.factor等参数也就没有什么太大作用,优化程序算法肯定会有更大收益。 所以在大多数情况下,写job,调试job,测试,上线运行,这套开发mapreduce应用程序的流程通常很多开发团队都走的很顺。但这并不是最难的,事情到这里也还远远不算完,程序哪里不高效,哪里消耗过多资源,哪里是瓶颈,如何优化,这一系列的问题,根据在下的经验,是开发团队考虑的相对不多的地方。 通常应用程序的开发者发现自己的hadoop job跑的不够高效,不够快的时候,第一时间想到的,是给hadoop平台的开发团队写邮件,说你hadoop平台又怎么怎么样,害的我的job跑的不够高效,然后在邮件的最后还附加上一句:“请hadoop平台开发团队多多考虑用户的建议和用户体验,优化hadoop,满足我这个什么什么job的需求,不然我就 @#¥%#¥%#”。而其实大部分情况下,只要稍微关注一下自己的程序,稍微进行一些优化,作业的执行效率就会高很多。说到这里内心又开始有些激动,还是言归正传吧…… 刚才说到作业效率和瓶颈的问题,怎么发现作业的瓶颈呢?用户怎么知道他的作业的在哪个阶段最耗时,哪个地方最耗内存呢?其实hadoop提供了用户tunning自己job的方法,其中profiling tasks就是其中一种。 和debug task一样,profiling一个运行在分布式hadoop环境下的mapredeuce job是比较困难的。但在hadoop中,是可以让用户针对某些tasks进行profiling采集的,当这些task执行完后,将这些profiling日志保存的文件发送到作业的提交client机器上,然后用户就可以用自己熟悉的工具来分析这些profiling日志,进行tasks执行瓶颈的分析。 使用方法: 在JobConf中,有几个配置选项是可以用来控制task profiling行为的。比如对一个job,想要开启对其tasks的profiling功能,并设置profiling相应的HPROF参数,可以按如下方式: conf.setProfileEnabled(true); 第一行表示打开profiling task的功能,该功能默认情况下是关闭的。调用该接口相当于设置配置选项 mapred.task.profile=true,可以利用这种方式在hadoop job提交命令行上动态指定。 第二行是通过conf接口来设置对tasks进行HPROF 的profiling的采集参数,采用profiling enable的方式运行的tasks,会采用每个task一个独立的JVM的运行方式运行(即使enable了job的jvm reuse功能)。HPROF相关的采集参数设置,可以见其他资料。该选项也可以通过设置 mapred.task.profile.params 选项来指定。 第三行表示对job的哪些tasks需要进行profiling采集,第一true参数表示采集的是map tasks的性能数据,false的话表示采集reduce的性能数据,第二个参数表示只采集编号为0,1,2的tasks的数据,(默认为0-2)。如果想要采集除2,3,5编号的tasks,可以设置该参数为: 0-1,4,6- Example 还是拿wordcount来举例,提交job命令如下: bin/hadoop jar hadoop-examples-0.20.2-luoli.jar wordcount \ 这样,当job运行时,就会对前三个task进行profiling的采集,采集信息包括cpu的采样信息,内存分配的信息数据,stack trace 6层的堆栈信息。这里需要注意的是,由于前三个tasks被进行了HPROF的性能采样,所以这几个tasks的执行效率会受到一定的影响,profiling的信息越详细,性能影响就越大。如下图,前三个map就明显比其他的map运行的要慢很多。 不过这种运行方式通常都不是线上运行方式,而是用来进行优化调试,所以关系不大。 而当job运行完成后,这三个tasks对应的profiling日志也会会传到提交机器上,供用户分析判断。如下图: 与此同时,tasks在tasktracker上也将这些profiling日志信息记录到了一个profile.out的日志文件中,该文件通常位于tasktracker机器上的上${HADOOP_HOME}/logs/userlogs/${attempt_id}下,和该task的stderr,stdout,syslog保存在同一个目录下,如下图: 该文件中的内容,还可以通过taskdetails.jsp的页面查看到。如下图: 有了这些信息,相信对于任何一位hadoop应用程序的开发者来说,就拥有了足够的定位job瓶颈的信息了。MR的应用程序开发同学,请优化您的job吧~~对hadoop task进行profiling的几种方法整理
conf.setProfileParams("-agentlib:hprof=cpu=samples,heap=sites,depth=6," +
"force=n,thread=y,verbose=n,file=%s");
conf.setProfileTaskRange(true, "0-2");
-D mapred.reduce.tasks=10 \
-D keep.failed.task.files=fales \
-D mapred.task.profile=true \
-D mapred.task.profile.params="-agentlib:hprof=cpu=samples,heap=sites,depth=6,force=n,thread=y,verbose=n,file=%s" \
$input \
$output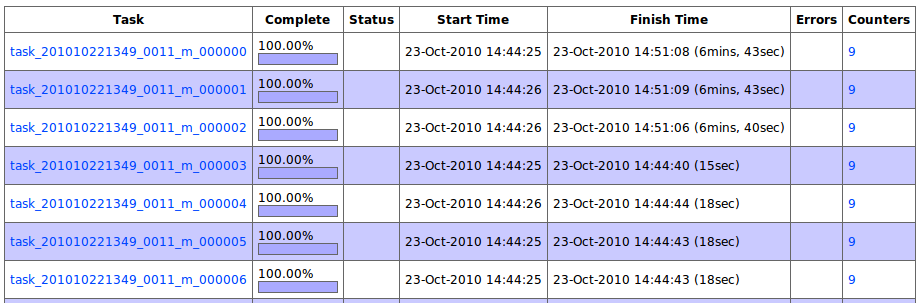





发表评论

-
一网打尽当下NoSQL类型、适用场景及使用公司
2014-12-28 20:56 986一网打尽当下NoSQL类型、适用场景及使用公司 http:// ... -
别样解释云计算,太TM天才跨界了
2014-02-25 09:41 2468http://mp.weixin.qq.com/s?__bi ... -
Build, Install, Configure and Run Apache Hadoop 2.2.0 in Microsoft Windows OS
2013-12-09 11:17 2566http://www.srccodes.com/p/arti ... -
hadoop的超时设置
2013-06-23 11:47 2441from http://blog.163.com/zheng ... -
hadoop与panasas
2012-12-26 09:53 894在应用的场景中,hadoop当然希望使用全部的本地硬盘,但是对 ... -
程序开过多线程,导致hadoop作业无法运行成功
2012-10-23 16:14 7080Exception in thread "Threa ... -
mount盘异常,导致hadoop作业无法发送
2012-10-23 16:12 967异常信息 2012-10-23 21:10:42,18 ... -
HDFS quota 設定
2012-08-02 16:22 5554http://fenriswolf.me/2012/04/04 ... -
hadoop常用的指令
2011-10-09 16:50 1720hadoop job -kill jobid 可以整个的杀掉 ... -
Hadoop基准测试
2011-08-08 10:04 1293http://www.michael-noll.com/ ... -
Hadoop Job Scheduler作业调度器
2011-05-21 11:02 2544http://hi.baidu.com/zhengxiang3 ... -
hadoop指定某个文件的blocksize,而不改变整个集群的blocksize
2011-03-20 17:20 2122文件上传的时候,使用下面的命令即可 hadoop f ... -
Hadoop Job Tuning
2011-02-28 15:53 833http://www.searchtb.com/2010/12 ... -
如何在不重启整个hadoop集群的情况下,增加新的节点
2011-02-25 10:12 14341.在namenode 的conf/slaves文件中增加新的 ... -
如何对hadoop作业的某个task进行debug单步跟踪
2011-02-10 21:56 2097http://blog.csdn.net/AE86_FC/ar ... -
hadoop 0.20 程式開發 eclipse plugin
2011-01-26 19:36 2284http://trac.nchc.org.tw/cloud/w ... -
hadoop-0.21.0-eclipse-plugin无法在eclipse中运行解决方案
2011-01-26 09:47 3616LINUX下将hadoop-0.21自带的hadoop ecl ... -
How to Benchmark a Hadoop Cluster
2011-01-19 22:15 2881How to Benchmark a Hadoop Clu ... -
json在线格式化
2010-12-21 16:23 2453http://jsonformatter.curiouscon ... -
Hadoop的mapred TaskTracker端源码概览
2010-11-14 11:24 1303http://jiwenke.iteye.com/blog/3 ...
相关推荐
本文将对MapTask类的源代码进行分析,了解其内部机制和实现细节。 MapTask类的成员变量和方法 --------------------------- MapTask类的成员变量包括split和splitClass。split是InputSplit对象的串行化结果,用于...
在本项目中,我们主要探讨的是如何利用SpringBoot与Hadoop进行数据操作,以及如何解决在IE浏览器中通过Servlet访问Hadoop存储的图片时出现显示源码的问题。下面将详细阐述这两个关键知识点。 首先,SpringBoot是...
【标题】:“Hadoop+Lucene的几种结合形式” 【描述】:“Hadoop+Lucene的结合使用,包括与Solr、SolrCloud的对比分析” 【知识点详解】: 一、Lucene简介 Lucene是一个由Apache软件基金会的Jakarta项目开发的...
本文档介绍了一种基于多元线性回归模型的Hadoop集群节点性能计算方法,该方法可以对Hadoop集群节点的性能进行准确的评估和优化。 什么是Hadoop集群节点性能计算? Hadoop集群节点性能计算是指对Hadoop集群中每个...
Hadoop汇总整理 Hadoop 是一个分布式系统,核心组件包括 HDFS(分布式文件系统)和 MapReduce(映射-化简运算程序)。Hadoop 有三种模式:独立模式、伪分布模式、完全分布模式。Hadoop 主要由 NameNode(核心)、...
Hadoop使用常见问题以及解决方法.doc Hadoop使用常见问题以及解决方法.doc
6. "基于Hadoop分布式计算架构的海量数据分析.pdf":这里可能会讨论使用Hadoop进行大数据分析的具体方法和技术,如数据预处理、数据挖掘等。 7. "The hadoop distributed file system Architecture and design.pdf...
4. **Hadoop实例**:实例可能包括如何使用Hadoop进行数据导入、数据清洗、数据转换、数据分析等操作。例如,可能有一个实例是使用Hadoop处理日志文件,分析用户行为;或者使用MapReduce计算大规模数据集的统计指标,...
Hive提供了一种基于SQL的查询语言——HQL(Hive Query Language),用于对存储在Hadoop上的大型数据集进行批处理分析。Hive将SQL语句转化为MapReduce任务执行,简化了大数据分析的工作。 【Pig】: Pig是高级数据...
在Hadoop框架中,`Task`类是处理数据的核心组件之一,它包括`MapTask`和`ReduceTask`两种类型,分别负责数据的映射处理和归约处理。本文将深入剖析`Task`类中的内部类及其辅助类,旨在理解这些类如何协同工作以支持...
下面我们将深入探讨Hadoop的核心组件、安装与配置,以及如何在Windows环境下使用Eclipse进行开发。 1. **Hadoop核心组件**: Hadoop主要由两个核心组件组成:Hadoop Distributed File System (HDFS) 和 MapReduce...
Hadoop_进行分布式并行编程.doc Hadoop_进行分布式并行编程.doc
例如,`org.apache.hadoop.mapred.MapTask`和`org.apache.hadoop.mapreduce.ReduceTask`分别对应Map和Reduce任务的实现,开发者可以通过阅读这些源码了解任务执行的详细流程。 7. **工具集成**:有许多开源工具可以...
Hadoop搭建手册以及三种集群模式配置
如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop进行数据分析.zip 如何使用hadoop...
社会网络分析(Social Network Analysis, SNA)是一种研究个体间关系及其对个人和社会结构影响的方法。它可以帮助我们理解人际关系网的结构,如哪些人是网络中的关键节点,信息如何在网络中流动,以及网络中的群组或...
资源名称:linux hadoop搭建手册以及三种集群模式配置内容简介: linux hadoop搭建手册以及三种集群模式配置前半部分主要讲述了环境配置 环境配置环境配置;后半部分主要讲述Hadoop集群有三种运行模式,分别为单机...
Hadoop 是一种大数据处理技术,它可以对大量数据进行处理和分析。但是在使用 Hadoop 过程中,我们经常会遇到一些错误和问题,本文将为您提供一些常见的 Hadoop 故障解决方法。 一、Shuffle Error: Exceeded MAX_...