
HadoopеЃґжЧПз≥їеИЧжЦЗзЂ†пЉМдЄїи¶БдїЛзїНHadoopеЃґжЧПдЇІеУБпЉМеЄЄзФ®зЪДй°єзЫЃеМЕжЛђHadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, ChukwaпЉМжЦ∞еҐЮеК†зЪДй°єзЫЃеМЕжЛђпЉМYARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hueз≠ЙгАВ
дїО2011еєіеЉАеІЛпЉМдЄ≠еЫљињЫеЕ•е§ІжХ∞жНЃй£ОиµЈдЇСжґМзЪДжЧґдї£пЉМдї•HadoopдЄЇдї£и°®зЪДеЃґжЧПиљѓдїґпЉМеН†жНЃдЇЖе§ІжХ∞жНЃе§ДзРЖзЪДеєњйШФеЬ∞зЫШгАВеЉАжЇРзХМеПКеОВеХЖпЉМжЙАжЬЙжХ∞жНЃиљѓдїґпЉМжЧ†дЄАдЄНеРСHadoopйЭ†жЛҐгАВHadoopдєЯдїОе∞ПдЉЧзЪДйЂШеѓМеЄЕйҐЖеЯЯпЉМеПШжИРдЇЖе§ІжХ∞жНЃеЉАеПСзЪДж†ЗеЗЖгАВеЬ®HadoopеОЯжЬЙжКАжЬѓеЯЇз°АдєЛдЄКпЉМеЗЇзО∞дЇЖHadoopеЃґжЧПдЇІеУБпЉМйАЪињЗвАЬе§ІжХ∞жНЃвАЭж¶ВењµдЄНжЦ≠еИЫжЦ∞пЉМжО®еЗЇзІСжКАињЫж≠•гАВ
дљЬдЄЇITзХМзЪДеЉАеПСдЇЇеСШпЉМжИСдїђдєЯи¶БиЈЯдЄКиКВе•ПпЉМжКУдљПжЬЇйБЗпЉМиЈЯзЭАHadoopдЄАиµЈйЫДиµЈпЉБ
еЕ≥дЇОдљЬиАЕпЉЪ
- еЉ†дЄє(Conan), з®ЛеЇПеСШJava,R,PHP,Javascript
- weiboпЉЪ@Conan_Z
- blog: http://blog.fens.me
- email: bsspirit@gmail.com
иљђиљљиѓЈж≥®жШОеЗЇе§ДпЉЪ
http://blog.fens.me/hadoop-mapreduce-recommend/

еЙНи®А
NetflixзФµељ±жО®иНРзЪДзЩЊдЄЗзЊОйЗСжѓФиµЫпЉМжККвАЬжО®иНРвАЭеПШжИРдЇЖжЧґдЄЛжЬАзГ≠йЧ®зЪДжХ∞жНЃжМЦжОШзЃЧж≥ХдєЛдЄАгАВдєЯж≠£жШѓзФ±дЇОNetflixзЪДжѓФиµЫпЉМиЃ©дЉБдЄЪзХМеТМе≠¶зІСзХМжЬЙдЇЖжЫіжЈ±е±Вжђ°зЪДжКАжЬѓзҐ∞жТЮгАВеЉХеПСдЇЖеРДзІНзљСзЂЩвАЬжО®иНРвАЭзГ≠пЉМдЄ™жАІжЧґдї£еЈ≤зїПеИ∞жЭ•гАВ
зЫЃељХ
- жО®иНРз≥їзїЯж¶Вињ∞
- йЬАж±ВеИЖжЮРпЉЪжО®иНРз≥їзїЯжМЗж†ЗиЃЊиЃ°
- зЃЧж≥Хж®°еЮЛпЉЪHadoopеєґи°МзЃЧж≥Х
- жЮґжЮДиЃЊиЃ°пЉЪжО®иНРз≥їзїЯжЮґжЮД
- з®ЛеЇПеЉАеПСпЉЪMapReduceз®ЛеЇПеЃЮзО∞
- и°•еЕЕеЖЕеЃєпЉЪеѓєStep4ињЗз®ЛдЉШеМЦ
1. жО®иНРз≥їзїЯж¶Вињ∞
зФµе≠РеХЖеК°зљСзЂЩжШѓдЄ™жАІеМЦжО®иНРз≥їзїЯйЗНи¶БеЬ∞еЇФзФ®зЪДйҐЖеЯЯдєЛдЄАпЉМдЇЪй©ђйАКе∞±жШѓдЄ™жАІеМЦжО®иНРз≥їзїЯзЪДзІѓжЮБеЇФзФ®иАЕеТМжО®еєњиАЕпЉМдЇЪй©ђйАКзЪДжО®иНРз≥їзїЯжЈ±еЕ•еИ∞зљСзЂЩзЪДеРДз±їеХЖеУБпЉМдЄЇдЇЪй©ђйАКеЄ¶жЭ•дЇЖиЗ≥е∞С30%зЪДйФАеФЃйҐЭгАВ
дЄНеЕЙжШѓзФµеХЖз±їпЉМжО®иНРз≥їзїЯжЧ†е§ДдЄНеЬ®гАВQQпЉМдЇЇдЇЇзљСзЪДе•љеПЛжО®иНРпЉЫжЦ∞жµ™еЊЃеНЪзЪДдљ†еПѓиГљжДЯиІЙеЕіиґ£зЪДдЇЇпЉЫдЉШйЕЈпЉМеЬЯи±ЖзЪДзФµељ±жО®иНРпЉЫи±ЖзУ£зЪДеЫЊдє¶жО®иНРпЉЫе§ІдїОзВєиѓДзЪДй§Рй•ЃжО®иНРпЉЫдЄЦзЇ™дљ≥зЉШзЪДзЫЄдЇ≤жО®иНРпЉЫ姩йЩЕзљСзЪДиБМдЄЪжО®иНРз≠ЙгАВ
жО®иНРзЃЧж≥ХеИЖз±їпЉЪ
жМЙжХ∞жНЃдљњзФ®еИТеИЖпЉЪ
- еНПеРМињЗжї§зЃЧж≥ХпЉЪUserCF, ItemCF, ModelCF
- еЯЇдЇОеЖЕеЃєзЪДжО®иНР: зФ®жИЈеЖЕеЃєе±ЮжАІеТМзЙ©еУБеЖЕеЃєе±ЮжАІ
- з§ЊдЉЪеМЦињЗжї§пЉЪеЯЇдЇОзФ®жИЈзЪДз§ЊдЉЪзљСзїЬеЕ≥з≥ї
жМЙж®°еЮЛеИТеИЖпЉЪ
- жЬАињСйВїж®°еЮЛ:еЯЇдЇОиЈЭз¶їзЪДеНПеРМињЗжї§зЃЧж≥Х
- Latent Factor Mode(SVD)пЉЪеЯЇдЇОзЯ©йШµеИЖиІ£зЪДж®°еЮЛ
- GraphпЉЪеЫЊж®°еЮЛпЉМз§ЊдЉЪзљСзїЬеЫЊж®°еЮЛ
еЯЇдЇОзФ®жИЈзЪДеНПеРМињЗжї§зЃЧж≥ХUserCF
еЯЇдЇОзФ®жИЈзЪДеНПеРМињЗжї§пЉМйАЪињЗдЄНеРМзФ®жИЈеѓєзЙ©еУБзЪДиѓДеИЖжЭ•иѓДжµЛзФ®жИЈдєЛйЧізЪДзЫЄдЉЉжАІпЉМеЯЇдЇОзФ®жИЈдєЛйЧізЪДзЫЄдЉЉжАІеБЪеЗЇжО®иНРгАВзЃАеНХжЭ•иЃ≤е∞±жШѓпЉЪзїЩзФ®жИЈжО®иНРеТМдїЦеЕіиґ£зЫЄдЉЉзЪДеЕґдїЦзФ®жИЈеЦЬ搥зЪДзЙ©еУБгАВ
зФ®дЊЛиѓіжШОпЉЪ
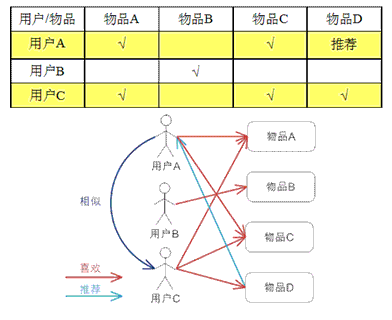
зЃЧж≥ХеЃЮзО∞еПКдљњзФ®дїЛзїНпЉМиѓЈеПВиАГжЦЗзЂ†пЉЪMahoutжО®иНРзЃЧж≥ХAPIиѓ¶иІ£
еЯЇдЇОзЙ©еУБзЪДеНПеРМињЗжї§зЃЧж≥ХItemCF
еЯЇдЇОitemзЪДеНПеРМињЗжї§пЉМйАЪињЗзФ®жИЈеѓєдЄНеРМitemзЪДиѓДеИЖжЭ•иѓДжµЛitemдєЛйЧізЪДзЫЄдЉЉжАІпЉМеЯЇдЇОitemдєЛйЧізЪДзЫЄдЉЉжАІеБЪеЗЇжО®иНРгАВзЃАеНХжЭ•иЃ≤е∞±жШѓпЉЪзїЩзФ®жИЈжО®иНРеТМдїЦдєЛеЙНеЦЬ搥зЪДзЙ©еУБзЫЄдЉЉзЪДзЙ©еУБгАВ
зФ®дЊЛиѓіжШОпЉЪ
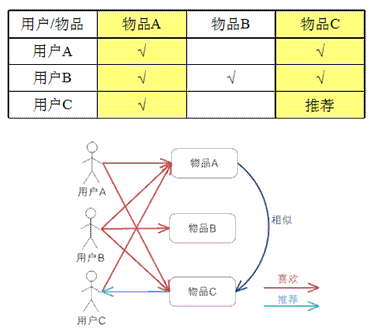
зЃЧж≥ХеЃЮзО∞еПКдљњзФ®дїЛзїНпЉМиѓЈеПВиАГжЦЗзЂ†пЉЪMahoutжО®иНРзЃЧж≥ХAPIиѓ¶иІ£
ж≥®пЉЪеЯЇдЇОзЙ©еУБзЪДеНПеРМињЗжї§зЃЧж≥ХпЉМжШѓзЫЃеЙНеХЖзФ®жЬАеєњж≥ЫзЪДжО®иНРзЃЧж≥ХгАВ
еНПеРМињЗжї§зЃЧж≥ХеЃЮзО∞пЉМеИЖдЄЇ2дЄ™ж≠•й™§
- 1. иЃ°зЃЧзЙ©еУБдєЛйЧізЪДзЫЄдЉЉеЇ¶
- 2. ж†єжНЃзЙ©еУБзЪДзЫЄдЉЉеЇ¶еТМзФ®жИЈзЪДеОЖеП≤и°МдЄЇзїЩзФ®жИЈзФЯжИРжО®иНРеИЧи°®
жЬЙеЕ≥еНПеРМињЗжї§зЪДеП¶дЄАзѓЗжЦЗзЂ†пЉМиѓЈеПВиАГпЉЪRHadoopеЃЮиЈµз≥їеИЧдєЛдЄЙ RеЃЮзО∞MapReduceзЪДеНПеРМињЗжї§зЃЧж≥Х
2. йЬАж±ВеИЖжЮРпЉЪжО®иНРз≥їзїЯжМЗж†ЗиЃЊиЃ°
дЄЛйЭҐжИСдїђе∞ЖдїОдЄАдЄ™еЕђеПЄж°ИдЊЛеЗЇеПСжЭ•еЕ®йЭҐзЪДиІ£йЗКпЉМе¶ВдљХињЫи°МжО®иНРз≥їзїЯжМЗж†ЗиЃЊиЃ°гАВ
ж°ИдЊЛдїЛзїН
NetflixзФµељ±жО®иНРзЩЊдЄЗе•ЦйЗСжѓФиµЫпЉМhttp://www.netflixprize.com/
NetflixеЃШжЦєзљСзЂЩпЉЪwww.netflix.com
NetflixпЉМ2006еєізїДзїЗжѓФиµЫжШѓзЪДжЧґеАЩпЉМжШѓдЄАеЃґдї•еЬ®зЇњзФµељ±зІЯиµБдЄЇзФЯзЪДеЕђеПЄгАВдїЦдїђж†єжНЃзљСеПЛеѓєзФµељ±зЪДжЙУеИЖжЭ•еИ§жЦ≠зФ®жИЈжЬЙеПѓиГљеЦЬ搥дїАдєИзФµељ±пЉМеєґзїУеРИдЉЪеСШзЬЛињЗзЪДзФµељ±дї•еПКеП£еС≥еБПе•љиЃЊзљЃеБЪеЗЇеИ§жЦ≠пЉМжЈЈжР≠еЗЇеРДзІНзФµељ±й£Ож†ЉзЪДйЬАж±ВгАВ
жФґйЫЖдЉЪеСШзЪДдЄАдЇЫдњ°жБѓпЉМдЄЇдїЦдїђжМЗеЃЪдЄ™жАІеМЦзЪДзФµељ±жО®иНРеРОпЉМжЬЙиЃЄе§ЪеЖЈйЧ®зФµељ±зЂЯзДґињЫеЕ•дЇЖеАЩзІЯж¶ЬеНХгАВдїОеЕђеПЄзЪДзФµељ±иµДжЇРжИРжЬђжЦєйЭҐиАГйЗПпЉМзГ≠йЧ®зФµељ±зЪДжИРжЬђдЄАиИђиЊГйЂШпЉМе¶ВжЮЬNetflixеЕђеПЄиГље§ЯеЬ®зФµељ±зІЯиµБдЄ≠еҐЮеК†еЖЈйЧ®зФµељ±зЪДжѓФдЊЛпЉМиЗ™зДґиГље§ЯжПРеНЗиЗ™иЇЂзЫИеИ©иГљеКЫгАВ
NetflixеЕђеПЄжЫЊеЃ£зІ∞60%еЈ¶еП≥зЪДдЉЪеСШж†єжНЃжО®иНРеРНеНХеЃЪеИґзІЯиµБй°ЇеЇПпЉМе¶ВжЮЬжО®иНРз≥їзїЯдЄНиГљеЗЖз°ЃеЬ∞зМЬжµЛдЉЪеСШеЦЬ搥зЪДзФµељ±з±їеЮЛпЉМеЃєжШУйА†жИРе§Ъжђ°зІЯеАЯеЖЈйЧ®зФµељ±иАМеєґдЄНзђ¶еРИдЄ™дЇЇеП£еС≥зЪДдЉЪеСШжµБ姱гАВдЄЇдЇЖжЫійЂШжХИеЬ∞дЄЇдЉЪеСШжО®иНРзФµељ±пЉМNetflixдЄАзЫіиЗіеКЫдЇОдЄНжЦ≠жФєињЫеТМеЃМеЦДдЄ™жАІеМЦжО®иНРжЬНеК°пЉМеЬ®2006еєіжО®еЗЇзЩЊдЄЗзЊОеЕГе§Іе•ЦпЉМжЧ†иЃЇжШѓи∞БиГљжЬАе•љеЬ∞дЉШеМЦNetflixжО®иНРзЃЧж≥Хе∞±еПѓиОЈе•ЦеК±100дЄЗзЊОеЕГгАВеИ∞2009еєіпЉМе•ЦйЗС襀дЄАдЄ™7дЇЇеЉАеПСе∞ПзїДе§ЇеЊЧпЉМNetflixйЪПеРОеПИзЂЛеН≥жО®еЗЇзђђдЇМдЄ™зЩЊдЄЗзЊОйЗСжВђиµПгАВињЩеЕЕеИЖиѓіжШОдЄАе•Че•љзЪДжО®иНРзЃЧж≥Хз≥їзїЯжШѓе§ЪдєИйЗНи¶БпЉМеРМжЧґеПИжШѓе§ЪдєИеЫ∞йЪЊгАВ
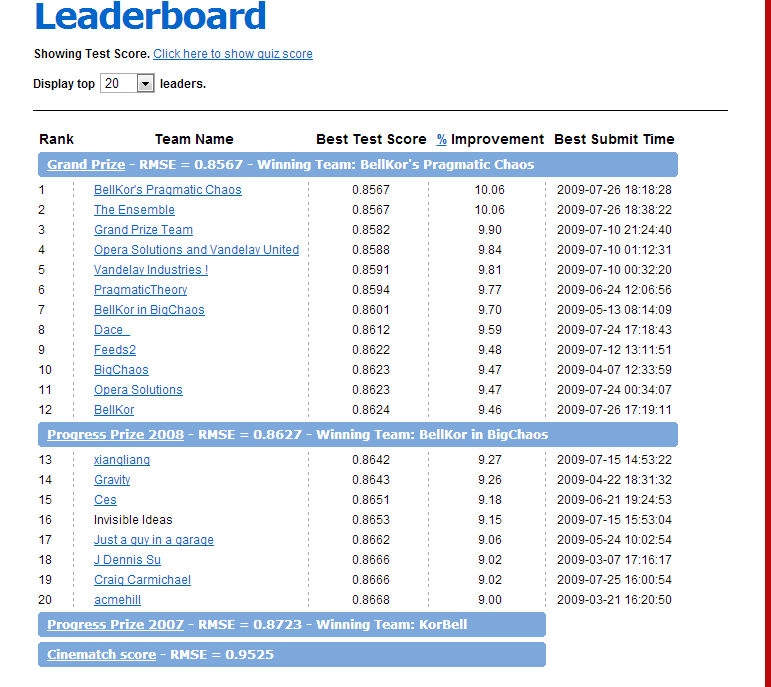
дЄКеЫЊдЄЇжѓФиµЫзЪДеРДжФѓйШЯдЉНзЪДжОТеРНпЉБ
и°•еЕЕиѓіжШОпЉЪ
- 1. NetflixзЪДжѓФиµЫжШѓеЯЇдЇОйЭЩжАБжХ∞жНЃзЪДпЉМе∞±жШѓзїЩеЃЪвАЬиЃ≠зїГзЇІвАЭпЉМеМєйЕНвАЬзїУжЮЬйЫЖвАЭпЉМвАЬзїУжЮЬйЫЖвАЭдєЯжШѓжПРеЙНе∞±еБЪе•љзЪДпЉМжЙАдї•ињЩдЄОжИСдїђжѓП姩ињРиР•зЪДз≥їзїЯпЉМеЕґеЃЮжШѓдЄНдЄАж†ЈзЪДгАВ
- 2. NetflixзФ®дЇОжѓФиµЫзЪДжХ∞жНЃйЫЖжШѓе∞ПйЗПзЪДпЉМжХідЄ™еЕ®йЫЖжЙН666MBпЉМиАМеЃЮйЩЕзЪДжО®иНРз≥їзїЯйГљи¶БеЯЇдЇОе§ІйЗПеОЖеП≤жХ∞жНЃзЪДпЉМеК®дЄНеК®е∞±дЉЪдЄКGB,TBз≠Й
NetflixжХ∞жНЃдЄЛиљљ
йГ®еИЖиЃ≠зїГйЫЖпЉЪhttp://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.train_.gz
йГ®еИЖзїУжЮЬйЫЖпЉЪhttp://graphlab.org/wp-content/uploads/2013/07/smallnetflix_mm.validate.gz
еЃМжХіжХ∞жНЃйЫЖпЉЪhttp://www.lifecrunch.biz/wp-content/uploads/2011/04/nf_prize_dataset.tar.gz
жЙАдї•пЉМжИСдїђеЬ®зЬЯеЃЮзЪДзОѓеҐГдЄ≠иЃЊиЃ°жО®иНРзЪДжЧґеАЩпЉМи¶БеЕ®йЭҐиАГйЗПжХ∞жНЃйЗПпЉМзЃЧж≥ХжАІиГљпЉМзїУжЮЬеЗЖз°ЃеЇ¶з≠ЙзЪДжМЗж†ЗгАВ
- жО®иНРзЃЧж≥ХйАЙеЮЛпЉЪеЯЇдЇОзЙ©еУБзЪДеНПеРМињЗжї§зЃЧж≥ХItemCFпЉМеєґи°МеЃЮзО∞
- жХ∞жНЃйЗПпЉЪеЯЇдЇОHadoopжЮґжЮДпЉМжФѓжМБGB,TB,PBзЇІжХ∞жНЃйЗП
- зЃЧж≥Хж£Ай™МпЉЪеПѓдї•йАЪињЗ еЗЖз°ЃзОЗпЉМеПђеЫЮзОЗпЉМи¶ЖзЫЦзОЗпЉМжµБи°МеЇ¶ з≠ЙжМЗж†ЗиѓДеИ§гАВ
- зїУжЮЬиІ£иѓїпЉЪйАЪињЗItemCFзЪДеЃЪдєЙпЉМеРИзРЖзїЩеЗЇзїУжЮЬиІ£йЗК
3. зЃЧж≥Хж®°еЮЛпЉЪHadoopеєґи°МзЃЧж≥Х
ињЩйЗМжИСдљњзФ®вАЭMahout In ActionвАЭдє¶йЗМпЉМзђђдЄАзЂ†зђђеЕ≠иКВдїЛзїНзЪДеИЖж≠•еЉПеЯЇдЇОзЙ©еУБзЪДеНПеРМињЗжї§зЃЧж≥ХињЫи°МеЃЮзО∞гАВChapter 6: Distributing recommendation computations
жµЛиѓХжХ∞жНЃйЫЖ:small.csv
1,101,5.0
1,102,3.0
1,103,2.5
2,101,2.0
2,102,2.5
2,103,5.0
2,104,2.0
3,101,2.0
3,104,4.0
3,105,4.5
3,107,5.0
4,101,5.0
4,103,3.0
4,104,4.5
4,106,4.0
5,101,4.0
5,102,3.0
5,103,2.0
5,104,4.0
5,105,3.5
5,106,4.0
жѓПи°М3дЄ™е≠ЧжЃµпЉМдЊЭжђ°жШѓзФ®жИЈID,зФµељ±ID,зФ®жИЈеѓєзФµељ±зЪДиѓДеИЖ(0-5еИЖпЉМжѓП0.5дЄЇдЄАдЄ™иѓДеИЖзВєпЉБ)
зЃЧж≥ХзЪДжАЭжГ≥пЉЪ
- 1. еїЇзЂЛзЙ©еУБзЪДеРМзО∞зЯ©йШµ
- 2. еїЇзЂЛзФ®жИЈеѓєзЙ©еУБзЪДиѓДеИЖзЯ©йШµ
- 3. зЯ©йШµиЃ°зЃЧжО®иНРзїУжЮЬ
1). еїЇзЂЛзЙ©еУБзЪДеРМзО∞зЯ©йШµ
жМЙзФ®жИЈеИЖзїДпЉМжЙЊеИ∞жѓПдЄ™зФ®жИЈжЙАйАЙзЪДзЙ©еУБпЉМеНХзЛђеЗЇзО∞иЃ°жХ∞еПКдЄ§дЄ§дЄАзїДиЃ°жХ∞гАВ
[101] [102] [103] [104] [105] [106] [107]
[101] 5 3 4 4 2 2 1
[102] 3 3 3 2 1 1 0
[103] 4 3 4 3 1 2 0
[104] 4 2 3 4 2 2 1
[105] 2 1 1 2 2 1 1
[106] 2 1 2 2 1 2 0
[107] 1 0 0 1 1 0 1
2). еїЇзЂЛзФ®жИЈеѓєзЙ©еУБзЪДиѓДеИЖзЯ©йШµ
жМЙзФ®жИЈеИЖзїДпЉМжЙЊеИ∞жѓПдЄ™зФ®жИЈжЙАйАЙзЪДзЙ©еУБеПКиѓДеИЖ
U3
[101] 2.0
[102] 0.0
[103] 0.0
[104] 4.0
[105] 4.5
[106] 0.0
[107] 5.0
3). зЯ©йШµиЃ°зЃЧжО®иНРзїУжЮЬ
еРМзО∞зЯ©йШµ*иѓДеИЖзЯ©йШµ=жО®иНРзїУжЮЬ
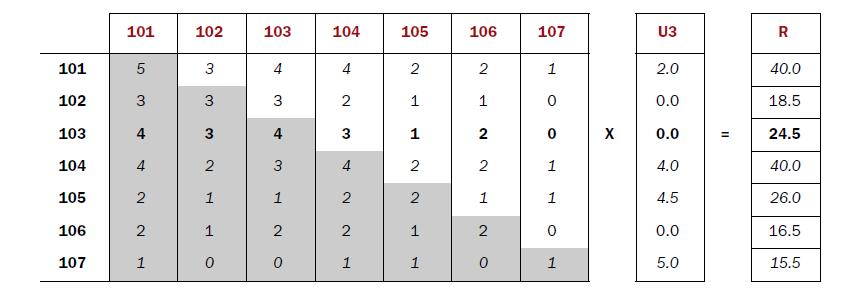
еЫЊзЙЗжСШиЗ™вАЭMahout In ActionвАЭ
MapReduceдїїеК°иЃЊиЃ°
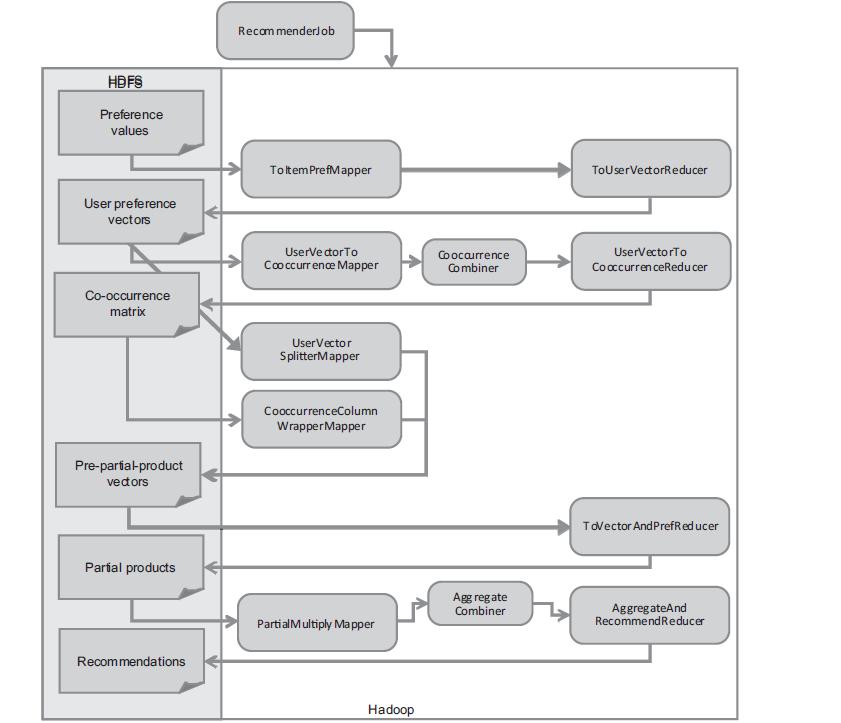
еЫЊзЙЗжСШиЗ™вАЭMahout In ActionвАЭ
иІ£иѓїMapRduceдїїеК°пЉЪ
- ж≠•й™§1: жМЙзФ®жИЈеИЖзїДпЉМиЃ°зЃЧжЙАжЬЙзЙ©еУБеЗЇзО∞зЪДзїДеРИеИЧи°®пЉМеЊЧеИ∞зФ®жИЈеѓєзЙ©еУБзЪДиѓДеИЖзЯ©йШµ
- ж≠•й™§2: еѓєзЙ©еУБзїДеРИеИЧи°®ињЫи°МиЃ°жХ∞пЉМеїЇзЂЛзЙ©еУБзЪДеРМзО∞зЯ©йШµ
- ж≠•й™§3: еРИеєґеРМзО∞зЯ©йШµеТМиѓДеИЖзЯ©йШµ
- ж≠•й™§4: иЃ°зЃЧжО®иНРзїУжЮЬеИЧи°®
4. жЮґжЮДиЃЊиЃ°пЉЪжО®иНРз≥їзїЯжЮґжЮД
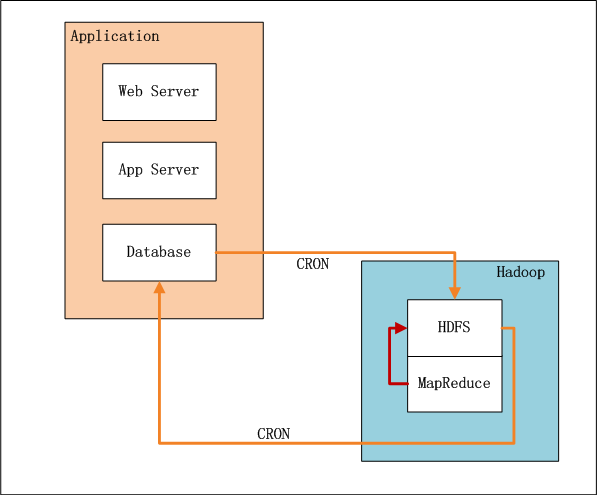
дЄКеЫЊдЄ≠пЉМеЈ¶иЊєжШѓApplicationдЄЪеК°з≥їзїЯпЉМеП≥иЊєжШѓHadoopзЪДHDFS, MapReduceгАВ
- дЄЪеК°з≥їзїЯиЃ∞ељХдЇЖзФ®жИЈзЪДи°МдЄЇеТМеѓєзЙ©еУБзЪДжЙУеИЖ
- иЃЊзљЃз≥їзїЯеЃЪжЧґеЩ®CRONпЉМжѓПxxе∞ПжЧґпЉМеҐЮйЗПеРСHDFSеѓЉеЕ•жХ∞жНЃ(userid,itemid,value,time)гАВ
- еЃМжИРеѓЉеЕ•еРОпЉМиЃЊзљЃз≥їзїЯеЃЪжЧґеЩ®пЉМеРѓеК®MapReduceз®ЛеЇПпЉМињРи°МжО®иНРзЃЧж≥ХгАВ
- еЃМжИРиЃ°зЃЧеРОпЉМиЃЊзљЃз≥їзїЯеЃЪжЧґеЩ®пЉМдїОHDFSеѓЉеЗЇжО®иНРзїУжЮЬжХ∞жНЃеИ∞жХ∞жНЃеЇУпЉМжЦєдЊњдї•еРОзЪДеПКжЧґжߕ胥гАВ
5. з®ЛеЇПеЉАеПСпЉЪMapReduceз®ЛеЇПеЃЮзО∞
win7зЪДеЉАеПСзОѓеҐГ еТМ HadoopзЪДињРи°МзОѓеҐГ пЉМиѓЈеПВиАГжЦЗзЂ†пЉЪзФ®MavenжЮДеїЇHadoopй°єзЫЃ
жЦ∞еїЇJavaз±їпЉЪ
- Recommend.javaпЉМдЄїдїїеК°еРѓеК®з®ЛеЇП
- Step1.javaпЉМжМЙзФ®жИЈеИЖзїДпЉМиЃ°зЃЧжЙАжЬЙзЙ©еУБеЗЇзО∞зЪДзїДеРИеИЧи°®пЉМеЊЧеИ∞зФ®жИЈеѓєзЙ©еУБзЪДиѓДеИЖзЯ©йШµ
- Step2.javaпЉМеѓєзЙ©еУБзїДеРИеИЧи°®ињЫи°МиЃ°жХ∞пЉМеїЇзЂЛзЙ©еУБзЪДеРМзО∞зЯ©йШµ
- Step3.javaпЉМеРИеєґеРМзО∞зЯ©йШµеТМиѓДеИЖзЯ©йШµ
- Step4.javaпЉМиЃ°зЃЧжО®иНРзїУжЮЬеИЧи°®
- HdfsDAO.javaпЉМHDFSжУНдљЬеЈ•еЕЈз±ї
1). Recommend.javaпЉМдЄїдїїеК°еРѓеК®з®ЛеЇП
жЇРдї£з†БпЉЪ
package org.conan.myhadoop.recommend;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
public class Recommend {
public static final String HDFS = "hdfs://192.168.1.210:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) throws Exception {
Map<String, String> path = new HashMap<String, String>();
path.put("data", "logfile/small.csv");
path.put("Step1Input", HDFS + "/user/hdfs/recommend");
path.put("Step1Output", path.get("Step1Input") + "/step1");
path.put("Step2Input", path.get("Step1Output"));
path.put("Step2Output", path.get("Step1Input") + "/step2");
path.put("Step3Input1", path.get("Step1Output"));
path.put("Step3Output1", path.get("Step1Input") + "/step3_1");
path.put("Step3Input2", path.get("Step2Output"));
path.put("Step3Output2", path.get("Step1Input") + "/step3_2");
path.put("Step4Input1", path.get("Step3Output1"));
path.put("Step4Input2", path.get("Step3Output2"));
path.put("Step4Output", path.get("Step1Input") + "/step4");
Step1.run(path);
Step2.run(path);
Step3.run1(path);
Step3.run2(path);
Step4.run(path);
System.exit(0);
}
public static JobConf config() {
JobConf conf = new JobConf(Recommend.class);
conf.setJobName("Recommend");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
}
2). Step1.javaпЉМжМЙзФ®жИЈеИЖзїДпЉМиЃ°зЃЧжЙАжЬЙзЙ©еУБеЗЇзО∞зЪДзїДеРИеИЧи°®пЉМеЊЧеИ∞зФ®жИЈеѓєзЙ©еУБзЪДиѓДеИЖзЯ©йШµ
жЇРдї£з†БпЉЪ
package org.conan.myhadoop.recommend;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Step1 {
public static class Step1_ToItemPreMapper extends MapReduceBase implements Mapper<Object, Text, IntWritable, Text> {
private final static IntWritable k = new IntWritable();
private final static Text v = new Text();
@Override
public void map(Object key, Text value, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(value.toString());
int userID = Integer.parseInt(tokens[0]);
String itemID = tokens[1];
String pref = tokens[2];
k.set(userID);
v.set(itemID + ":" + pref);
output.collect(k, v);
}
}
public static class Step1_ToUserVectorReducer extends MapReduceBase implements Reducer<IntWritable, Text, IntWritable, Text> {
private final static Text v = new Text();
@Override
public void reduce(IntWritable key, Iterator values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
StringBuilder sb = new StringBuilder();
while (values.hasNext()) {
sb.append("," + values.next());
}
v.set(sb.toString().replaceFirst(",", ""));
output.collect(key, v);
}
}
public static void run(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get("Step1Input");
String output = path.get("Step1Output");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(input);
hdfs.mkdirs(input);
hdfs.copyFile(path.get("data"), input);
conf.setMapOutputKeyClass(IntWritable.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Step1_ToItemPreMapper.class);
conf.setCombinerClass(Step1_ToUserVectorReducer.class);
conf.setReducerClass(Step1_ToUserVectorReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
иЃ°зЃЧзїУжЮЬпЉЪ
~ hadoop fs -cat /user/hdfs/recommend/step1/part-00000
1 102:3.0,103:2.5,101:5.0
2 101:2.0,102:2.5,103:5.0,104:2.0
3 107:5.0,101:2.0,104:4.0,105:4.5
4 101:5.0,103:3.0,104:4.5,106:4.0
5 101:4.0,102:3.0,103:2.0,104:4.0,105:3.5,106:4.0
3). Step2.javaпЉМеѓєзЙ©еУБзїДеРИеИЧи°®ињЫи°МиЃ°жХ∞пЉМеїЇзЂЛзЙ©еУБзЪДеРМзО∞зЯ©йШµ
жЇРдї£з†БпЉЪ
package org.conan.myhadoop.recommend;
import java.io.IOException;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Step2 {
public static class Step2_UserVectorToCooccurrenceMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static Text k = new Text();
private final static IntWritable v = new IntWritable(1);
@Override
public void map(LongWritable key, Text values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
for (int i = 1; i < tokens.length; i++) {
String itemID = tokens[i].split(":")[0];
for (int j = 1; j < tokens.length; j++) {
String itemID2 = tokens[j].split(":")[0];
k.set(itemID + ":" + itemID2);
output.collect(k, v);
}
}
}
}
public static class Step2_UserVectorToConoccurrenceReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void run(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get("Step2Input");
String output = path.get("Step2Output");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Step2_UserVectorToCooccurrenceMapper.class);
conf.setCombinerClass(Step2_UserVectorToConoccurrenceReducer.class);
conf.setReducerClass(Step2_UserVectorToConoccurrenceReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
иЃ°зЃЧзїУжЮЬпЉЪ
~ hadoop fs -cat /user/hdfs/recommend/step2/part-00000
101:101 5
101:102 3
101:103 4
101:104 4
101:105 2
101:106 2
101:107 1
102:101 3
102:102 3
102:103 3
102:104 2
102:105 1
102:106 1
103:101 4
103:102 3
103:103 4
103:104 3
103:105 1
103:106 2
104:101 4
104:102 2
104:103 3
104:104 4
104:105 2
104:106 2
104:107 1
105:101 2
105:102 1
105:103 1
105:104 2
105:105 2
105:106 1
105:107 1
106:101 2
106:102 1
106:103 2
106:104 2
106:105 1
106:106 2
107:101 1
107:104 1
107:105 1
107:107 1
4). Step3.javaпЉМеРИеєґеРМзО∞зЯ©йШµеТМиѓДеИЖзЯ©йШµ
жЇРдї£з†БпЉЪ
package org.conan.myhadoop.recommend;
import java.io.IOException;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Step3 {
public static class Step31_UserVectorSplitterMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> {
private final static IntWritable k = new IntWritable();
private final static Text v = new Text();
@Override
public void map(LongWritable key, Text values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
for (int i = 1; i < tokens.length; i++) {
String[] vector = tokens[i].split(":");
int itemID = Integer.parseInt(vector[0]);
String pref = vector[1];
k.set(itemID);
v.set(tokens[0] + ":" + pref);
output.collect(k, v);
}
}
}
public static void run1(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get("Step3Input1");
String output = path.get("Step3Output1");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Step31_UserVectorSplitterMapper.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
public static class Step32_CooccurrenceColumnWrapperMapper extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static Text k = new Text();
private final static IntWritable v = new IntWritable();
@Override
public void map(LongWritable key, Text values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
k.set(tokens[0]);
v.set(Integer.parseInt(tokens[1]));
output.collect(k, v);
}
}
public static void run2(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input = path.get("Step3Input2");
String output = path.get("Step3Output2");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Step32_CooccurrenceColumnWrapperMapper.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
иЃ°зЃЧзїУжЮЬпЉЪ
~ hadoop fs -cat /user/hdfs/recommend/step3_1/part-00000
101 5:4.0
101 1:5.0
101 2:2.0
101 3:2.0
101 4:5.0
102 1:3.0
102 5:3.0
102 2:2.5
103 2:5.0
103 5:2.0
103 1:2.5
103 4:3.0
104 2:2.0
104 5:4.0
104 3:4.0
104 4:4.5
105 3:4.5
105 5:3.5
106 5:4.0
106 4:4.0
107 3:5.0
~ hadoop fs -cat /user/hdfs/recommend/step3_2/part-00000
101:101 5
101:102 3
101:103 4
101:104 4
101:105 2
101:106 2
101:107 1
102:101 3
102:102 3
102:103 3
102:104 2
102:105 1
102:106 1
103:101 4
103:102 3
103:103 4
103:104 3
103:105 1
103:106 2
104:101 4
104:102 2
104:103 3
104:104 4
104:105 2
104:106 2
104:107 1
105:101 2
105:102 1
105:103 1
105:104 2
105:105 2
105:106 1
105:107 1
106:101 2
106:102 1
106:103 2
106:104 2
106:105 1
106:106 2
107:101 1
107:104 1
107:105 1
107:107 1
5). Step4.javaпЉМиЃ°зЃЧжО®иНРзїУжЮЬеИЧи°®
жЇРдї£з†БпЉЪ
package org.conan.myhadoop.recommend;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.RunningJob;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Step4 {
public static class Step4_PartialMultiplyMapper extends MapReduceBase implements Mapper<LongWritable, Text, IntWritable, Text> {
private final static IntWritable k = new IntWritable();
private final static Text v = new Text();
private final static Map<Integer, List> cooccurrenceMatrix = new HashMap<Integer, List>();
@Override
public void map(LongWritable key, Text values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
String[] v1 = tokens[0].split(":");
String[] v2 = tokens[1].split(":");
if (v1.length > 1) {// cooccurrence
int itemID1 = Integer.parseInt(v1[0]);
int itemID2 = Integer.parseInt(v1[1]);
int num = Integer.parseInt(tokens[1]);
List list = null;
if (!cooccurrenceMatrix.containsKey(itemID1)) {
list = new ArrayList();
} else {
list = cooccurrenceMatrix.get(itemID1);
}
list.add(new Cooccurrence(itemID1, itemID2, num));
cooccurrenceMatrix.put(itemID1, list);
}
if (v2.length > 1) {// userVector
int itemID = Integer.parseInt(tokens[0]);
int userID = Integer.parseInt(v2[0]);
double pref = Double.parseDouble(v2[1]);
k.set(userID);
for (Cooccurrence co : cooccurrenceMatrix.get(itemID)) {
v.set(co.getItemID2() + "," + pref * co.getNum());
output.collect(k, v);
}
}
}
}
public static class Step4_AggregateAndRecommendReducer extends MapReduceBase implements Reducer<IntWritable, Text, IntWritable, Text> {
private final static Text v = new Text();
@Override
public void reduce(IntWritable key, Iterator values, OutputCollector<IntWritable, Text> output, Reporter reporter) throws IOException {
Map<String, Double> result = new HashMap<String, Double>();
while (values.hasNext()) {
String[] str = values.next().toString().split(",");
if (result.containsKey(str[0])) {
result.put(str[0], result.get(str[0]) + Double.parseDouble(str[1]));
} else {
result.put(str[0], Double.parseDouble(str[1]));
}
}
Iterator iter = result.keySet().iterator();
while (iter.hasNext()) {
String itemID = iter.next();
double score = result.get(itemID);
v.set(itemID + "," + score);
output.collect(key, v);
}
}
}
public static void run(Map<String, String> path) throws IOException {
JobConf conf = Recommend.config();
String input1 = path.get("Step4Input1");
String input2 = path.get("Step4Input2");
String output = path.get("Step4Output");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
conf.setOutputKeyClass(IntWritable.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(Step4_PartialMultiplyMapper.class);
conf.setCombinerClass(Step4_AggregateAndRecommendReducer.class);
conf.setReducerClass(Step4_AggregateAndRecommendReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input1), new Path(input2));
FileOutputFormat.setOutputPath(conf, new Path(output));
RunningJob job = JobClient.runJob(conf);
while (!job.isComplete()) {
job.waitForCompletion();
}
}
}
class Cooccurrence {
private int itemID1;
private int itemID2;
private int num;
public Cooccurrence(int itemID1, int itemID2, int num) {
super();
this.itemID1 = itemID1;
this.itemID2 = itemID2;
this.num = num;
}
public int getItemID1() {
return itemID1;
}
public void setItemID1(int itemID1) {
this.itemID1 = itemID1;
}
public int getItemID2() {
return itemID2;
}
public void setItemID2(int itemID2) {
this.itemID2 = itemID2;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
}
иЃ°зЃЧзїУжЮЬпЉЪ
~ hadoop fs -cat /user/hdfs/recommend/step4/part-00000
1 107,5.0
1 106,18.0
1 105,15.5
1 104,33.5
1 103,39.0
1 102,31.5
1 101,44.0
2 107,4.0
2 106,20.5
2 105,15.5
2 104,36.0
2 103,41.5
2 102,32.5
2 101,45.5
3 107,15.5
3 106,16.5
3 105,26.0
3 104,38.0
3 103,24.5
3 102,18.5
3 101,40.0
4 107,9.5
4 106,33.0
4 105,26.0
4 104,55.0
4 103,53.5
4 102,37.0
4 101,63.0
5 107,11.5
5 106,34.5
5 105,32.0
5 104,59.0
5 103,56.5
5 102,42.5
5 101,68.0
еѓєStep4ињЗз®ЛдЉШеМЦпЉМиѓЈеПВиАГжЬђжЦЗжЬАеРОзЪДи°•еЕЕеЖЕеЃєгАВ
6). HdfsDAO.javaпЉМHDFSжУНдљЬеЈ•еЕЈз±ї
иѓ¶зїЖиІ£йЗКпЉМиѓЈеПВиАГжЦЗзЂ†пЉЪHadoopзЉЦз®Ли∞ГзФ®HDFS
жЇРдї£з†БпЉЪ
package org.conan.myhadoop.hdfs;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.mapred.JobConf;
public class HdfsDAO {
private static final String HDFS = "hdfs://192.168.1.210:9000/";
public HdfsDAO(Configuration conf) {
this(HDFS, conf);
}
public HdfsDAO(String hdfs, Configuration conf) {
this.hdfsPath = hdfs;
this.conf = conf;
}
private String hdfsPath;
private Configuration conf;
public static void main(String[] args) throws IOException {
JobConf conf = config();
HdfsDAO hdfs = new HdfsDAO(conf);
hdfs.copyFile("datafile/item.csv", "/tmp/new");
hdfs.ls("/tmp/new");
}
public static JobConf config(){
JobConf conf = new JobConf(HdfsDAO.class);
conf.setJobName("HdfsDAO");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
return conf;
}
public void mkdirs(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
if (!fs.exists(path)) {
fs.mkdirs(path);
System.out.println("Create: " + folder);
}
fs.close();
}
public void rmr(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.deleteOnExit(path);
System.out.println("Delete: " + folder);
fs.close();
}
public void ls(String folder) throws IOException {
Path path = new Path(folder);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
FileStatus[] list = fs.listStatus(path);
System.out.println("ls: " + folder);
System.out.println("==========================================================");
for (FileStatus f : list) {
System.out.printf("name: %s, folder: %s, size: %d\n", f.getPath(), f.isDir(), f.getLen());
}
System.out.println("==========================================================");
fs.close();
}
public void createFile(String file, String content) throws IOException {
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
byte[] buff = content.getBytes();
FSDataOutputStream os = null;
try {
os = fs.create(new Path(file));
os.write(buff, 0, buff.length);
System.out.println("Create: " + file);
} finally {
if (os != null)
os.close();
}
fs.close();
}
public void copyFile(String local, String remote) throws IOException {
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.copyFromLocalFile(new Path(local), new Path(remote));
System.out.println("copy from: " + local + " to " + remote);
fs.close();
}
public void download(String remote, String local) throws IOException {
Path path = new Path(remote);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
fs.copyToLocalFile(path, new Path(local));
System.out.println("download: from" + remote + " to " + local);
fs.close();
}
public void cat(String remoteFile) throws IOException {
Path path = new Path(remoteFile);
FileSystem fs = FileSystem.get(URI.create(hdfsPath), conf);
FSDataInputStream fsdis = null;
System.out.println("cat: " + remoteFile);
try {
fsdis =fs.open(path);
IOUtils.copyBytes(fsdis, System.out, 4096, false);
} finally {
IOUtils.closeStream(fsdis);
fs.close();
}
}
}
ињЩж†ЈжИСдїђе∞±иЗ™еЈ±зЉЦз®ЛеЃЮзО∞дЇЖMapReduceеМЦеЯЇдЇОзЙ©еУБзЪДеНПеРМињЗжї§зЃЧж≥ХгАВ
RHadoopзЪДеЃЮзО∞жЦєж°ИпЉМиѓЈеПВиАГжЦЗзЂ†пЉЪRHadoopеЃЮиЈµз≥їеИЧдєЛдЄЙ RеЃЮзО∞MapReduceзЪДеНПеРМињЗжї§зЃЧж≥Х
MahoutзЪДеЃЮзО∞жЦєж°ИпЉМиѓЈеПВиАГжЦЗзЂ†пЉЪMahoutеИЖж≠•еЉПз®ЛеЇПеЉАеПС еЯЇдЇОзЙ©еУБзЪДеНПеРМињЗжї§ItemCF
жИСеЈ≤зїПжККжХідЄ™MapReduceзЪДеЃЮзО∞йГљжФЊеИ∞дЇЖgithubдЄКйЭҐпЉЪ
https://github.com/bsspirit/maven_hadoop_template/releases/tag/recommend
6. и°•еЕЕеЖЕеЃєпЉЪеѓєStep4ињЗз®ЛдЉШеМЦ
еЬ®Step4.javaињЩдЄАж≠•ињРи°МињЗз®ЛдЄ≠пЉМMapperињЗз®ЛеЬ®Step4_PartialMultiplyMapperз±їйАЪињЗеИЖеИЂиѓїеПЦдЄ§дЄ™inputжХ∞жНЃпЉМеЬ®еЖЕе≠ШдЄ≠ињЫи°МдЇЖиЃ°зЃЧгАВ
ињЩзІНжЦєеЉПжЬЙжШОжШЊзЪДйЩРеИґжЭ°дїґпЉЪ
- a. дЄ§дЄ™иЊУеЕ•жХ∞жНЃйЫЖпЉМжЬЙдЄ•ж†ЉзЪДиѓїеЕ•й°ЇеЇПгАВзФ±дЇОHadoopдЄНиГљжМЗеЃЪиѓїеЕ•й°ЇеЇПпЉМеЫ†ж≠§еЬ®е§ЪиКВзВєзЪДHadoopйЫЖзЊ§зОѓеҐГпЉМиѓїеЕ•й°ЇеЇПжЬЙеПѓиГљдЉЪеПСзФЯйФЩиѓѓпЉМйА†жИРз®ЛеЇПзЪДз©ЇжМЗйТИйФЩиѓѓгАВ
- b. ињЩдЄ™иЃ°зЃЧињЗз®ЛпЉМеЬ®еЖЕе≠ШдЄ≠еЃЮзО∞гАВе¶ВжЮЬзЯ©йШµињЗе§ІпЉМдЉЪйА†жИРеНХиКВзВєзЪДеЖЕе≠ШдЄНиґ≥гАВ
еБЪдЄЇдЉШеМЦзЪДжЦєж°ИпЉМжИСдїђйЬАи¶БеѓєStep4зЪДињЗз®ЛпЉМеЃЮзО∞MapReduceзЪДзЯ©йШµдєШж≥ХпЉМзЯ©йШµзЃЧж≥ХеОЯзРЖиѓЈеПВиАГжЦЗзЂ†пЉЪзФ®MapReduceеЃЮзО∞зЯ©йШµдєШж≥Х
еѓєStep4дЉШеМЦзЪДеЃЮзО∞пЉЪжККзЯ©йШµиЃ°зЃЧйАЪињЗдЄ§дЄ™MapReduceињЗз®ЛеЃЮзО∞гАВ
- зЯ©йШµдєШж≥ХињЗз®Лз±їжЦЗдїґпЉЪStep4_Update.java
- зЯ©йШµеК†ж≥ХињЗз®Лз±їжЦЗдїґпЉЪStep4_Update2.java
- дњЃжФєеРѓеК®з®ЛеЇПпЉЪRecommend.java
еҐЮеК†жЦЗдїґпЉЪStep4_Update.java
package org.conan.myhadoop.recommend;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Step4_Update {
public static class Step4_PartialMultiplyMapper extends Mapper<LONGWRITABLE, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" text="" text,=""> {
private String flag;// AеРМзО∞зЯ©йШµ or BиѓДеИЖзЯ©йШµ
@Override
protected void setup(Context context) throws IOException, InterruptedException {
FileSplit split = (FileSplit) context.getInputSplit();
flag = split.getPath().getParent().getName();// еИ§жЦ≠иѓїзЪДжХ∞жНЃйЫЖ
// System.out.println(flag);
}
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
if (flag.equals("step3_2")) {// еРМзО∞зЯ©йШµ
String[] v1 = tokens[0].split(":");
String itemID1 = v1[0];
String itemID2 = v1[1];
String num = tokens[1];
Text k = new Text(itemID1);
Text v = new Text("A:" + itemID2 + "," + num);
context.write(k, v);
// System.out.println(k.toString() + " " + v.toString());
} else if (flag.equals("step3_1")) {// иѓДеИЖзЯ©йШµ
String[] v2 = tokens[1].split(":");
String itemID = tokens[0];
String userID = v2[0];
String pref = v2[1];
Text k = new Text(itemID);
Text v = new Text("B:" + userID + "," + pref);
context.write(k, v);
// System.out.println(k.toString() + " " + v.toString());
}
}
}
public static class Step4_AggregateReducer extends Reducer<TEXT, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" text="" text,=""> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
System.out.println(key.toString() + ":");
Map<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string=""> mapA = new HashMap<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string="">();
Map<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string=""> mapB = new HashMap<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string="">();
for (Text line : values) {
String val = line.toString();
System.out.println(val);
if (val.startsWith("A:")) {
String[] kv = Recommend.DELIMITER.split(val.substring(2));
mapA.put(kv[0], kv[1]);
} else if (val.startsWith("B:")) {
String[] kv = Recommend.DELIMITER.split(val.substring(2));
mapB.put(kv[0], kv[1]);
}
}
double result = 0;
Iterator iter = mapA.keySet().iterator();
while (iter.hasNext()) {
String mapk = iter.next();// itemID
int num = Integer.parseInt(mapA.get(mapk));
Iterator iterb = mapB.keySet().iterator();
while (iterb.hasNext()) {
String mapkb = iterb.next();// userID
double pref = Double.parseDouble(mapB.get(mapkb));
result = num * pref;// зЯ©йШµдєШж≥ХзЫЄдєШиЃ°зЃЧ
Text k = new Text(mapkb);
Text v = new Text(mapk + "," + result);
context.write(k, v);
System.out.println(k.toString() + " " + v.toString());
}
}
}
}
public static void run(Map<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string=""> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = Recommend.config();
String input1 = path.get("Step5Input1");
String input2 = path.get("Step5Input2");
String output = path.get("Step5Output");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(Step4_Update.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(Step4_Update.Step4_PartialMultiplyMapper.class);
job.setReducerClass(Step4_Update.Step4_AggregateReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input1), new Path(input2));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
еҐЮеК†жЦЗдїґпЉЪStep4_Update2.java
package org.conan.myhadoop.recommend;
import java.io.IOException;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Step4_Update2 {
public static class Step4_RecommendMapper extends Mapper<LONGWRITABLE, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" text="" text,=""> {
@Override
public void map(LongWritable key, Text values, Context context) throws IOException, InterruptedException {
String[] tokens = Recommend.DELIMITER.split(values.toString());
Text k = new Text(tokens[0]);
Text v = new Text(tokens[1]+","+tokens[2]);
context.write(k, v);
}
}
public static class Step4_RecommendReducer extends Reducer<TEXT, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" text="" text,=""> {
@Override
public void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
System.out.println(key.toString() + ":");
Map<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" double=""> map = new HashMap<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" double="">();// зїУжЮЬ
for (Text line : values) {
System.out.println(line.toString());
String[] tokens = Recommend.DELIMITER.split(line.toString());
String itemID = tokens[0];
Double score = Double.parseDouble(tokens[1]);
if (map.containsKey(itemID)) {
map.put(itemID, map.get(itemID) + score);// зЯ©йШµдєШж≥Хж±ВеТМиЃ°зЃЧ
} else {
map.put(itemID, score);
}
}
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
String itemID = iter.next();
double score = map.get(itemID);
Text v = new Text(itemID + "," + score);
context.write(key, v);
}
}
}
public static void run(Map<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string=""> path) throws IOException, InterruptedException, ClassNotFoundException {
JobConf conf = Recommend.config();
String input = path.get("Step6Input");
String output = path.get("Step6Output");
HdfsDAO hdfs = new HdfsDAO(Recommend.HDFS, conf);
hdfs.rmr(output);
Job job = new Job(conf);
job.setJarByClass(Step4_Update2.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(Step4_Update2.Step4_RecommendMapper.class);
job.setReducerClass(Step4_Update2.Step4_RecommendReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.setInputPaths(job, new Path(input));
FileOutputFormat.setOutputPath(job, new Path(output));
job.waitForCompletion(true);
}
}
дњЃжФєRecommend.java
package org.conan.myhadoop.recommend;
import java.util.HashMap;
import java.util.Map;
import java.util.regex.Pattern;
import org.apache.hadoop.mapred.JobConf;
import org.conan.myhadoop.hdfs.HdfsDAO;
public class Recommend {
public static final String HDFS = "hdfs://192.168.1.210:9000";
public static final Pattern DELIMITER = Pattern.compile("[\t,]");
public static void main(String[] args) throws Exception {
Map<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string=""> path = new HashMap<STRING, style="PADDING-BOTTOM: 0pt; MARGIN: 0pt; PADDING-LEFT: 0pt; PADDING-RIGHT: 0pt; PADDING-TOP: 0pt" string="">();
path.put("data", "logfile/small.csv");
path.put("Step1Input", HDFS + "/user/hdfs/recommend");
path.put("Step1Output", path.get("Step1Input") + "/step1");
path.put("Step2Input", path.get("Step1Output"));
path.put("Step2Output", path.get("Step1Input") + "/step2");
path.put("Step3Input1", path.get("Step1Output"));
path.put("Step3Output1", path.get("Step1Input") + "/step3_1");
path.put("Step3Input2", path.get("Step2Output"));
path.put("Step3Output2", path.get("Step1Input") + "/step3_2");
path.put("Step4Input1", path.get("Step3Output1"));
path.put("Step4Input2", path.get("Step3Output2"));
path.put("Step4Output", path.get("Step1Input") + "/step4");
path.put("Step5Input1", path.get("Step3Output1"));
path.put("Step5Input2", path.get("Step3Output2"));
path.put("Step5Output", path.get("Step1Input") + "/step5");
path.put("Step6Input", path.get("Step5Output"));
path.put("Step6Output", path.get("Step1Input") + "/step6");
Step1.run(path);
Step2.run(path);
Step3.run1(path);
Step3.run2(path);
//Step4.run(path);
Step4_Update.run(path);
Step4_Update2.run(path);
System.exit(0);
}
public static JobConf config() {
JobConf conf = new JobConf(Recommend.class);
conf.setJobName("Recommand");
conf.addResource("classpath:/hadoop/core-site.xml");
conf.addResource("classpath:/hadoop/hdfs-site.xml");
conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.set("io.sort.mb", "1024");
return conf;
}
}
ињРи°МStep4_Update.javaпЉМжЯ•зЬЛиЊУеЗЇзїУжЮЬ
~ hadoop fs -cat /user/hdfs/recommend/step5/part-r-00000
3 107,2.0
2 107,2.0
1 107,5.0
5 107,4.0
4 107,5.0
3 106,4.0
2 106,4.0
1 106,10.0
5 106,8.0
4 106,10.0
3 105,4.0
2 105,4.0
1 105,10.0
5 105,8.0
4 105,10.0
3 104,8.0
2 104,8.0
1 104,20.0
5 104,16.0
4 104,20.0
3 103,8.0
2 103,8.0
1 103,20.0
5 103,16.0
4 103,20.0
3 102,6.0
2 102,6.0
1 102,15.0
5 102,12.0
4 102,15.0
3 101,10.0
2 101,10.0
1 101,25.0
5 101,20.0
4 101,25.0
2 106,2.5
1 106,3.0
5 106,3.0
2 105,2.5
1 105,3.0
5 105,3.0
2 104,5.0
1 104,6.0
5 104,6.0
2 103,7.5
1 103,9.0
5 103,9.0
2 102,7.5
1 102,9.0
5 102,9.0
2 101,7.5
1 101,9.0
5 101,9.0
2 106,10.0
1 106,5.0
5 106,4.0
4 106,6.0
2 105,5.0
1 105,2.5
5 105,2.0
4 105,3.0
2 104,15.0
1 104,7.5
5 104,6.0
4 104,9.0
2 103,20.0
1 103,10.0
5 103,8.0
4 103,12.0
2 102,15.0
1 102,7.5
5 102,6.0
4 102,9.0
2 101,20.0
1 101,10.0
5 101,8.0
4 101,12.0
3 107,4.0
2 107,2.0
5 107,4.0
4 107,4.5
3 106,8.0
2 106,4.0
5 106,8.0
4 106,9.0
3 105,8.0
2 105,4.0
5 105,8.0
4 105,9.0
3 104,16.0
2 104,8.0
5 104,16.0
4 104,18.0
3 103,12.0
2 103,6.0
5 103,12.0
4 103,13.5
3 102,8.0
2 102,4.0
5 102,8.0
4 102,9.0
3 101,16.0
2 101,8.0
5 101,16.0
4 101,18.0
3 107,4.5
5 107,3.5
3 106,4.5
5 106,3.5
3 105,9.0
5 105,7.0
3 104,9.0
5 104,7.0
3 103,4.5
5 103,3.5
3 102,4.5
5 102,3.5
3 101,9.0
5 101,7.0
5 106,8.0
4 106,8.0
5 105,4.0
4 105,4.0
5 104,8.0
4 104,8.0
5 103,8.0
4 103,8.0
5 102,4.0
4 102,4.0
5 101,8.0
4 101,8.0
3 107,5.0
3 105,5.0
3 104,5.0
3 101,5.0
ињРи°МStep4_Update2.javaпЉМжЯ•зЬЛиЊУеЗЇзїУжЮЬ
~ hadoop fs -cat /user/hdfs/recommend/step6/part-r-00000
1 107,5.0
1 106,18.0
1 105,15.5
1 104,33.5
1 103,39.0
1 102,31.5
1 101,44.0
2 107,4.0
2 106,20.5
2 105,15.5
2 104,36.0
2 103,41.5
2 102,32.5
2 101,45.5
3 107,15.5
3 106,16.5
3 105,26.0
3 104,38.0
3 103,24.5
3 102,18.5
3 101,40.0
4 107,9.5
4 106,33.0
4 105,26.0
4 104,55.0
4 103,53.5
4 102,37.0
4 101,63.0
5 107,11.5
5 106,34.5
5 105,32.0
5 104,59.0
5 103,56.5
5 102,42.5
5 101,68.0
ињЩж†ЈжИСдїђе∞±жККеОЯжЭ•еЖЕе≠ШдЄ≠иЃ°зЃЧзЪДйГ®еИЖпЉМйАЪињЗMapReduceеЃЮзО∞дЇЖпЉМзїУжЮЬдЄОдєЛйЧіStep4зЪДзїУжЮЬдЄАиЗігАВ
дї£з†БеЈ≤зїПжЫіжЦ∞еИ∞githubпЉМиѓЈйЬАи¶БзЪДеРМе≠¶жЫіжЦ∞жЯ•зЬЛгАВ
https://github.com/bsspirit/maven_hadoop_template/tree/master/src/main/java/org/conan/myhadoop/recommend
иљђиљљиѓЈж≥®жШОеЗЇе§ДпЉЪ
http://blog.fens.me/hadoop-mapreduce-recommend/



зЫЄеЕ≥жО®иНР
жЬђй°єзЫЃжШѓйТИеѓєињЩдЄАйЬАж±ВпЉМжЮДеїЇзЪДдЄАдЄ™еЯЇдЇОHadoopзЪДе§ІжХ∞жНЃе§ДзРЖеє≥еП∞дЄКзЪДзФµељ±жО®иНРз≥їзїЯгАВй°єзЫЃйЗЗзФ®HadoopдљЬдЄЇе§ІжХ∞жНЃе§ДзРЖж°ЖжЮґпЉМPythonдљЬдЄЇеЉАеПСиѓ≠и®АпЉМMySQLдљЬдЄЇжХ∞жНЃе≠ШеВ®пЉМжЧ®еЬ®йАЪињЗеИЖжЮРзФ®жИЈзЪДеОЖеП≤и°МдЄЇеТМеБПе•љпЉМдЄЇзФ®жИЈжПРдЊЫдЄ™жАІеМЦ...
ж†ЗйҐШ "еЯЇдЇО hadoop зФµељ±жО®иНРз≥їзїЯ.zip" жЪЧз§ЇжИСдїђеЕ≥ж≥®зЪДжШѓдЄАдЄ™еИ©зФ®Hadoopж°ЖжЮґжЮДеїЇзЪДзФµељ±жО®иНРз≥їзїЯгАВHadoopжШѓApacheиљѓдїґеЯЇйЗСдЉЪзЪДдЄАдЄ™еЉАжЇРй°єзЫЃпЉМеЃГдЄЇе§ІиІДж®°жХ∞жНЃе§ДзРЖжПРдЊЫдЇЖеИЖеЄГеЉПиЃ°зЃЧж®°еЮЛгАВеЬ®ињЩдЄ™з≥їзїЯдЄ≠пЉМHadoopеПѓиÚ襀зФ®жЭ•...
жЬђй°єзЫЃ"зФµељ±жО®иНРз≥їзїЯзЪДиЃЊиЃ°дЄОеЃЮзО∞"еЕЕеИЖеИ©зФ®дЇЖHadoopзЪДMapReduceиЃ°зЃЧж°ЖжЮґпЉМзїУеРИеНПеРМињЗжї§зЃЧж≥ХпЉМдЄЇзФ®жИЈжПРдЊЫдЄ™жАІеМЦзЪДзФµељ±жО®иНРжЬНеК°гАВеРМжЧґпЉМйАЪињЗSpringBootеТМMySQLжЮДеїЇдЇЖдЄАдЄ™еЃМжХізЪДзФµељ±зЃ°зРЖеРОеП∞з≥їзїЯгАВ й¶ЦеЕИпЉМжИСдїђжЭ•зЬЛ...
жЬђй°єзЫЃжШѓеЯЇдЇОHadoopеє≥еП∞пЉМйЗЗзФ®JavaзЉЦз®Лиѓ≠и®АпЉМжЮДеїЇдЇЖдЄАе•ЧеЃМжХізЪДзФµељ±жО®иНРз≥їзїЯпЉМжЧ®еЬ®еЃЮзО∞е§ІиІДж®°жХ∞жНЃе§ДзРЖдЄЛзЪДйЂШжХИжО®иНРжЬНеК°гАВ й¶ЦеЕИпЉМжИСдїђи¶БзРЖиІ£HadoopзЪДж†ЄењГзїДдїґвАФвАФHadoop Distributed File System (HDFS) еТМ MapReduce...
гАРж†ЗйҐШгАСпЉЪвАЬеЯЇдЇОPython+HadoopзЪДзФµељ±жО®иНРз≥їзїЯвАЭжШѓдЄАдЄ™еЕЄеЮЛзЪДе§ІжХ∞жНЃе§ДзРЖдЄОжЬЇеЩ®е≠¶дє†зїУеРИзЪДй°єзЫЃпЉМзФ®дЇОеЬ®жµЈйЗПзФµељ±жХ∞жНЃдЄ≠дЄЇзФ®жИЈжО®иНРдїЦдїђеПѓиГљжДЯеЕіиґ£зЪДељ±зЙЗгАВеЬ®ињЩдЄ™жѓХдЄЪиЃЊиЃ°дЄ≠пЉМPython襀зФ®дљЬдЄїи¶БзЪДзЉЦз®Лиѓ≠и®АпЉМиАМHadoopжШѓ...
гАКеЯЇдЇОPHPдЄОHadoopзЪДзФµељ±жО®иНРз≥їзїЯиЃЊиЃ°дЄОеЃЮзО∞гАЛжШѓдЄАдЄ™жЈ±еЇ¶жОҐиЃ®е¶ВдљХеИ©зФ®ињЩдЄ§зІНжКАжЬѓжЮДеїЇйЂШжХИгАБеПѓжЙ©е±ХзЪДжО®иНРз≥їзїЯзЪДдЄУйҐШгАВеЬ®ињЩдЄ™й°єзЫЃдЄ≠пЉМPHPдљЬдЄЇеРОзЂѓеЉАеПСиѓ≠и®АпЉМзФ®дЇОе§ДзРЖзФ®жИЈжО•еП£еТМдЄЪеК°йАїиЊСпЉМиАМHadoopеИЩдљЬдЄЇе§ІжХ∞жНЃе§ДзРЖж°ЖжЮґ...
### еЯЇдЇОHadoopзЪДзФµељ±жО®иНРз≥їзїЯзЪДз†Фз©ґдЄОеЃЮзО∞ #### Hadoopж°ЖжЮґзЪДзЙєзВєдЄОдЉШеКњ HadoopжШѓдЄАдЄ™еЉАжЇРиљѓдїґж°ЖжЮґпЉМдЄУдЄЇеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІеЮЛжХ∞жНЃйЫЖиАМиЃЊиЃ°гАВеЃГзФ±дЄ§дЄ™ж†ЄењГзїДдїґзїДжИРпЉЪHadoopеИЖеЄГеЉПжЦЗдїґз≥їзїЯпЉИHDFSпЉЙеТМMapReduceзЉЦз®Л...
ж†ЗйҐШдЄ≠зЪДвАЬPython+Spark+Hadoopе§ІжХ∞жНЃеЯЇдЇОзФ®жИЈзФїеГПзФµељ±жО®иНРз≥їзїЯжѓХдЄЪжЇРз†БвАЭжМЗзЪДжШѓдЄАдЄ™дљњзФ®PythonгАБApache SparkеТМApache HadoopжЮДеїЇзЪДе§ІжХ∞жНЃе§ДзРЖй°єзЫЃпЉМжЧ®еЬ®еЃЮзО∞дЄАдЄ™еЯЇдЇОзФ®жИЈзФїеГПзЪДзФµељ±жО®иНРз≥їзїЯгАВињЩдЄ™з≥їзїЯеПѓиГљеИ©зФ®е§І...
жАїзїУпЉМеИ©зФ®HadoopжЮДеїЇзФµељ±жО®иНРз≥їзїЯпЉМдЄНдїЕиГље§Яе§ДзРЖжµЈйЗПжХ∞жНЃпЉМињШиГљжПРдЊЫдЄ™жАІеМЦжЬНеК°пЉМжПРеНЗзФ®жИЈжї°жДПеЇ¶гАВињЩдЄ™й°єзЫЃдЄЇжИСдїђе±Хз§ЇдЇЖе§ІжХ∞жНЃжКАжЬѓеЬ®еЃЮйЩЕеЇФзФ®дЄ≠зЪДеЉЇе§Іе®БеКЫпЉМеРМжЧґдєЯдЄЇжИСдїђжПРдЊЫдЇЖе≠¶дє†еТМжОМжП°HadoopзЪДеЃЮиЈµеє≥еП∞гАВеЬ®дЄНжЦ≠...
гАРжППињ∞гАСпЉЪвАЬињЩдЄ™й°єзЫЃжШѓеИ©зФ®MapReduceж°ЖжЮґпЉМзїУеРИJavaWebжКАжЬѓпЉМжЮДеїЇзЪДдЄАдЄ™е∞ПеЮЛзФµељ±жО®иНРз≥їзїЯгАВеЃГжЧ®еЬ®еИ©зФ®зФ®жИЈзЪДеОЖеП≤иІВељ±и°МдЄЇпЉМйАЪињЗжХ∞жНЃеИЖжЮРжЭ•дЄЇзФ®жИЈжО®иНРжЬАеПѓиГљжДЯеЕіиґ£зЪДзФµељ±гАВMapReduceжШѓе§ІжХ∞жНЃе§ДзРЖзЪДдЄАзІНж†ЄењГеЈ•еЕЈпЉМеЄЄ...
еЬ®жЬђй°єзЫЃдЄ≠пЉМжИСдїђе∞ЖиЃЊиЃ°дЄАдЄ™еЯЇдЇОHadoopзЪДзФµељ±жО®иНРз≥їзїЯпЉМиѓ•з≥їзїЯжЧ®еЬ®еИ©зФ®е§ІжХ∞жНЃе§ДзРЖзЪДиГљеКЫпЉМдЄЇзФ®жИЈжПРдЊЫдЄ™жАІеМЦзЪДзФµељ±жО®иНРгАВHadoopжШѓдЄАдЄ™еЉАжЇРж°ЖжЮґпЉМеЃГеЕБиЃЄеИЖеЄГеЉПе≠ШеВ®еТМе§ДзРЖе§ІиІДж®°жХ∞жНЃйЫЖпЉМйЭЮеЄЄйАВеРИе§ДзРЖжµЈйЗПзФ®жИЈи°МдЄЇжХ∞жНЃгАВ...
жЬђжЦЗжЧ®еЬ®йАЪињЗеїЇзЂЛдЄАе•ЧйЂШжХИзЪДжХ∞жНЃе§ДзРЖеє≥еП∞пЉМеИ©зФ®HadoopеИЖеЄГеЉПиЃ°зЃЧж°ЖжЮґе§ДзРЖе§ІиІДж®°зЪДзФµељ±жХ∞жНЃпЉМеЃЮзО∞еѓєжЬ™дЄКжШ†зФµељ±зЪДиѓДеИЖйҐДжµЛеКЯиГљпЉМдїОиАМдЄЇзФ®жИЈжПРдЊЫжЫіз≤ЊеЗЖзЪДзФµељ±жО®иНРжЬНеК°пЉМеРМжЧґдєЯдЄЇзФµељ±йЩҐзЇњжПРдЊЫеЖ≥з≠ЦжФѓжМБпЉМеЄЃеК©дїЦдїђжЫіе•љеЬ∞...
еЬ®ињЩдЄ™еРНдЄЇвАЬе§ІжХ∞жНЃеЃЮиЃ≠й°єзЫЃжЇРз†БпЉЪзФµељ±жО®иНРз≥їзїЯ.zipвАЭзЪДеОЛзЉ©еМЕдЄ≠пЉМжИСдїђдЄїи¶БжОҐиЃ®зЪДжШѓдЄАдЄ™еЯЇдЇОе§ІжХ∞жНЃжКАжЬѓжЮДеїЇзЪДзФµељ±жО®иНРз≥їзїЯгАВињЩдЄ™з≥їзїЯзЪДж†ЄењГзЫЃж†ЗжШѓеИ©зФ®жµЈйЗПзЪДзФ®жИЈи°МдЄЇжХ∞жНЃпЉМдЄЇзФ®жИЈжПРдЊЫдЄ™жАІеМЦзЪДзФµељ±жО®иНРпЉМжПРйЂШзФ®жИЈдљУй™М...
еЬ®ињЩдЄ™еРНдЄЇ"Python+Spark+Hadoopе§ІжХ∞жНЃеЯЇдЇОзФ®жИЈзФїеГПзФµељ±жО®иНРз≥їзїЯж°ИдЊЛиЃЊиЃ°.zip"зЪДеОЛзЉ©еМЕдЄ≠пЉМжИСдїђиБЪзД¶дЇОдЄАдЄ™еИ©зФ®дЇЇеЈ•жЩЇиГљжКАжЬѓпЉМзЙєеИЂжШѓжЬЇеЩ®е≠¶дє†зЃЧж≥ХпЉМжЮДеїЇзЪДе§ІжХ∞жНЃй©±еК®зЪДзФµељ±жО®иНРз≥їзїЯгАВиѓ•з≥їзїЯеЯЇдЇОHadoopеИЖеЄГеЉПиЃ°зЃЧж°ЖжЮґ...
зФµељ±жО®иНРзљСзЂЩжШѓдЄАдЄ™еЯЇдЇОHadoopзФЯжАБз≥їзїЯзЪДе§ІжХ∞жНЃй°єзЫЃпЉМеЃГеИ©зФ®дЇЖHBaseеТМMySQLжХ∞жНЃеЇУпЉМеєґйАЪињЗеНПеРМињЗжї§зЃЧж≥ХдЄЇзФ®жИЈжПРдЊЫдЄ™жАІеМЦзЪДзФµељ±жО®иНРгАВеЬ®ињЩдЄ™й°єзЫЃдЄ≠пЉМжИСдїђдЄїи¶БеЕ≥ж≥®дї•дЄЛеЗ†дЄ™еЕ≥йФЃзЯ•иѓЖзВєпЉЪ 1. **HadoopзФЯжАБ**пЉЪHadoopжШѓ...
ж†ЗйҐШдЄ≠зЪДвАЬеЯЇдЇОHadoopеТМSparkзФ±JavaеТМPythonиѓ≠и®АеЉАеПСзЪДзФµељ±жО®иНРз≥їзїЯвАЭи°®жШОињЩжШѓдЄАдЄ™дљњзФ®е§ІжХ∞жНЃе§ДзРЖж°ЖжЮґHadoopеТМењЂйАЯиЃ°зЃЧеЉХжУОSparkпЉМзїУеРИJavaеТМPythonзЉЦз®Лиѓ≠и®АеЃЮзО∞зЪДзФµељ±жО®иНРй°єзЫЃгАВињЩдЄ™з≥їзїЯеПѓиГљжґЙеПКеИ∞е§ЪдЄ™еЕ≥йФЃжКАжЬѓзВєпЉМ...
ињЩдЄ™й°єзЫЃжШѓеЯЇдЇО Movielens жХ∞жНЃйЫЖзЪДзФµељ±жО®иНРз≥їзїЯпЉМдљњзФ® Python3.x еЃЮзО∞пЉМеМЕеРЂдЇЖеЃЮзО∞ињЩдЄАеКЯиГљзЪДж†ЄењГдї£з†БгАВдЄЛйЭҐе∞Жиѓ¶зїЖйШРињ∞зЫЄеЕ≥зЯ•иѓЖзВєгАВ 1. ** Movielens жХ∞жНЃйЫЖ**пЉЪ Movielens жШѓдЄАдЄ™жµБи°МзЪДжХ∞жНЃйЫЖпЉМзФ± GroupLens з†Фз©ґ...
иѓ•жѓХдЄЪиЃЊиЃ°й°єзЫЃдЄїи¶БиБЪзД¶дЇОжЮДеїЇдЄАдЄ™еЯЇдЇОPythonгАБSparkеТМHadoopзЪДе§ІжХ∞жНЃе§ДзРЖеє≥еП∞пЉМзФ®дЇОеЃЮзО∞зФ®жИЈзФїеГПеТМзФµељ±жО®иНРз≥їзїЯгАВињЩдЄ™з≥їзїЯжЧ®еЬ®еИ©зФ®е§ІжХ∞жНЃжКАжЬѓжЭ•еИЖжЮРзФ®жИЈзЪДи°МдЄЇеТМеБПе•љпЉМдїОиАМжПРдЊЫдЄ™жАІеМЦзЪДзФµељ±жО®иНРжЬНеК°гАВ й¶ЦеЕИпЉМ...