
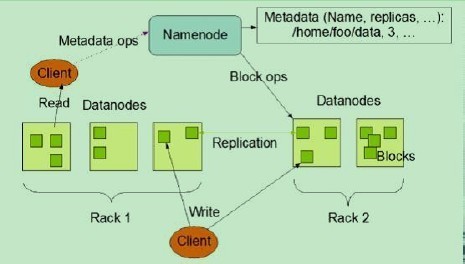
1)NameNode、DataNode和Client
NameNode可以看作是分布式文件系统中的管理者,主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包括了文件信息、每一个文件对应的文件块的信息和每一个文件块在DataNode的信息等。
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同时周期性地将所有存在的Block信息发送给NameNode。
Client就是需要获取分布式文件系统文件的应用程序。
2)文件写入
Client向NameNode发起文件写入的请求。
NameNode根据文件大小和文件块配置情况,返回给Client它所管理部分DataNode的信息。
Client将文件划分为多个Block,根据DataNode的地址信息,按顺序写入到每一个DataNode块中。
3)文件读取
Client向NameNode发起文件读取的请求。
NameNode返回文件存储的DataNode的信息。
Client读取文件信息。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
通信方式介绍:
在hadoop系统中,master/slaves/client的对应关系是:
master---namenode;
slaves---datanode;
client---dfsclient;
那究竟是通过什么样的方式进行通信的呢,在这里从大体介绍一下:
简单地讲:
client和namenode之间是通过rpc通信;
datanode和namenode之间是通过rpc通信;
client和datanode之间是通过简单的socket通信。
随便拔一下DFSClient的代码,可以看到它有一个成员变量public final ClientProtocolnamenode;
而再拔一下DataNode的代码,可以看到它也有一个成员变量public DatanodeProtocolnamenode
来自群组: Hadoop技术组



相关推荐
在Hadoop中,客户端(Client)负责提交任务、读写数据,而服务器端则包括NameNode、DataNode和TaskTracker等组件,它们处理客户端请求,管理数据存储和任务调度。 二、HDFS通信 1. 客户端与NameNode交互: 当...
值得注意的是,Hadoop 0.20.2及0.19版本中,客户端与DataNode的通信协议是基于socket的,而0.23及以后的版本中,协议有所改变,采用了protobuf作为序列化方式,这使得数据交换更加高效和简洁。 总结来说,Hadoop...
- **8019**:`dfs.ha.zkfc.port`,ZKFC与ZooKeeper之间的通信端口,用于实现NameNode的故障转移。 #### YARN(Yet Another Resource Negotiator)端口配置 - **ResourceManager** - **8032**:`yarn....
Hadoop使用远程过程调用(RPC)来实现NameNode和DataNode之间的通信,以及客户端与NameNode的交互。 - **3.2.1 Client类** 客户端API包含在`org.apache.hadoop.ipc`包下,主要负责发起RPC请求,如打开文件、关闭...
在HDFS中,文件的读写操作都是通过Client与NameNode和DataNode的交互来实现的。 HDFS的应用场景非常广泛,例如数据分析、日志处理、数据挖掘等。然而,HDFS不适合做网盘应用,也不支持文件的修改。 HDFS的高可用...
3. **Sqoop/Hadoop集成及应用开发**:Sqoop是一个用于在Hadoop和关系型数据库之间传输数据的工具。结合使用可以更加方便地进行数据迁移和处理。 4. **Hbase/Hadoop集成及应用开发**:HBase是一个构建在Hadoop之上的...
DataNode是Hadoop分布式文件系统HDFS(Hadoop Distributed File System)的核心组件之一,负责存储和管理数据块。下面是DataNode的职责和相关知识点: 一、 DataNode的职责 DataNode的主要职责是存储和管理数据块...
HDFS的架构可以分为三个部分: Namenode、Datanode和Client。Namenode是HDFS的中心节点,负责管理文件系统的元数据,Datanode是HDFS的数据节点,负责存储文件数据,而Client是用户与HDFS交互的接口。 Hadoop的另一...
021 Hadoop 五大服务与配置文件中的对应关系 022 分析Hadoop 三种启动停止方式的Shell 脚本 023 去除警告【Warning$HADOOP HOME is deprecated。】 024 Hadoop相关命令中的【–config configdir】作用 025 Hadoop ...
HDFS配置hdfs-site.xml则涉及NameNode和DataNode的相关参数,如副本数量和数据存储路径: ```xml <name>dfs.replication <value>3 <name>dfs.namenode.name.dir <value>/app/hadoop/data/nn <name>...
首先,Hdfs工作原理中主要关键词包括NameNode、SecondaryNameNode和DataNode。NameNode是整个Hdfs集群的管理中心,负责管理其他的DataNode节点,记录各个块的信息。SecondaryNameNode可以帮助NameNode完成fsimage和...
NameNode是HDFS的主节点,负责管理文件系统的命名空间(元数据),包括文件名、文件的块列表以及块与DataNode之间的映射关系。DataNode是工作节点,存储实际的数据块,并根据NameNode的指令执行数据的读写操作。 在...
NameNode和DataNode之间、客户端与NameNode之间都通过RPC进行通信。这些RPC调用涉及到各种操作,如文件的打开、关闭、重命名等。 #### 二、HDFS源码的理解和分析 ##### 2.1 集群系统工作状态 HDFS集群的正常运行...
hadoop-hdfs专注于实现HDFS,包括数据节点(DataNode)、名称节点(NameNode)以及客户端接口等。hadoop-mapreduce负责MapReduce的实现,包括作业调度、任务执行和资源管理。 在源码包中,开发者可以查看到Hadoop的...
Hadoop是一款开源的大数据处理框架,由Apache基金会开发,它主要设计用于分布式存储和处理海量数据。这个"hadop jar包.rar"文件很显然是包含了运行Hadoop相关程序所需的jar包集合,用户解压后可以直接使用,省去了...
HDFS 由三部分组成:NameNode、DataNode 和 Client。 * NameNode:负责管理文件系统的命名空间、集群配置信息和存储块的复制。 * DataNode:文件存储的基本单元,存储文件块在本地文件系统中,并周期性地发送报告给...
- **知识点说明**:如果DataNode的日志中报告不兼容的文件版本,通常意味着NameNode和DataNode之间存在版本不匹配。在这种情况下,重新格式化NameNode可能是一种解决方案,但这通常会导致数据丢失,因此在实际操作...
Hadoop 测试题 Hadoop 测试题主要涵盖了 Hadoop ...33. DataNode 首次加入 cluster 的时候,如果 log 中报告不兼容文件版本,那需要 NameNode 执行“Hadoop namenode -format”操作格式化磁盘。因此,正确答案是 √。
Hadoop的主要任务部署在三个部分:Client机器、主节点(NameNode和JobTracker)和从节点(DataNode)。主节点负责监督Hadoop的关键功能模块HDFS(Hadoop分布式文件系统)和MapReduce。HDFS的NameNode负责监控和调度...
例如,你可以深入到HDFS的源码中,了解NameNode如何维护文件系统的元数据,DataNode如何存储和传输数据块,以及如何通过BlockPlacementPolicy处理数据冗余和容错。 对于MapReduce部分,你可以看到JobTracker和...