
内部因素
es的一致性主要有两个方面:
-
使用lucene索引机制带来的refresh问题
-
使用分片和复制带来的副本一致性问题(
consistency:one、all、quorum)
外部因素
外部因素的话,就是如果使用db跟es的同步机制的话,那么这里的同步有一定的延时,另外也有可能因为异常情况发生不一致的情况,比如事务回滚之类的。
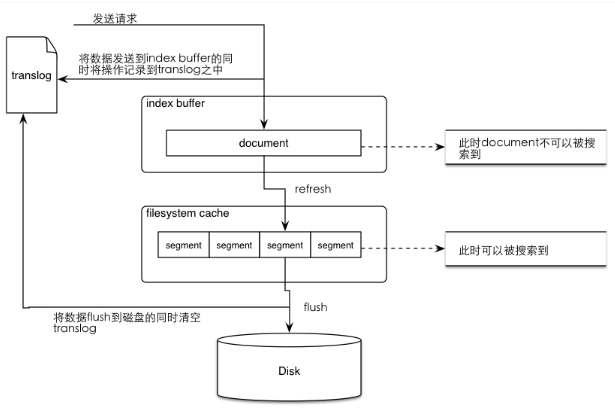
更新操作之后refresh
org.springframework.data.elasticsearch.repository.support.AbstractElasticsearchRepository
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Cannot save 'null' entity.");
elasticsearchOperations.index(createIndexQuery(entity));
elasticsearchOperations.refresh(entityInformation.getIndexName());
return entity;
}
public <S extends T> List<S> save(List<S> entities) {
Assert.notNull(entities, "Cannot insert 'null' as a List.");
Assert.notEmpty(entities, "Cannot insert empty List.");
List<IndexQuery> queries = new ArrayList<IndexQuery>();
for (S s : entities) {
queries.add(createIndexQuery(s));
}
elasticsearchOperations.bulkIndex(queries);
elasticsearchOperations.refresh(entityInformation.getIndexName());
return entities;
}一旦有更改就refresh到filesystem cache,这样就可以被搜索到。
副本一致性问题
但是还有一个问题,一旦有多个replication,就涉及到一致性的问题。
-
如果consistency是one,那么写入速度快,不能保证读到最新的更改;
-
如果是quorum则是相对折中的版本,write的时候,W>N/2,即参与写入操作的节点数W,必须超过副本节点数N的一半。如果是quorum策略,则读取要保证一致性的话,就得使用read quorum,读取N个副本中的W个然后仲裁得到最新数据。或者是指定从primary上面去读。
相关的类
org/elasticsearch/action/WriteConsistencyLevel.java
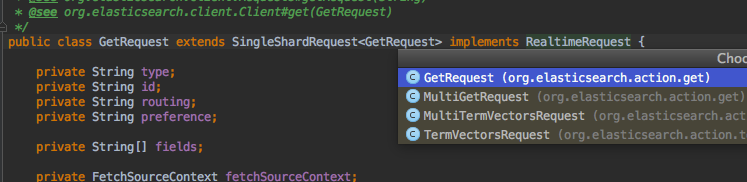
org/elasticsearch/action/RealtimeRequest.java-
realtime request
es提供了realtime request,就是从translog里头读,可以保证是最新的。
public class GetRequest extends SingleShardRequest<GetRequest> implements RealtimeRequest {
//......
}但是注意get是最新的,但是检索等其他方法不是(如果需要搜索出来也是最新的,需要refresh,这个会刷新该shard但不是整个index,因此如果read请求分发到repliac shard,那么可能读到的不是最新的数据,这个时候就需要指定preference=_primary)。
-
all策略即强一致的策略
小结
如果要保证读的强一致:
-
当write consistency不是all的时候,需要指定从primary shard读
-
当write consistency为all的时候,而且replication是sync模式(默认),无需额外指定,如果replication是async模式,则需要从primary shard读取。
curl -XGET 192.168.99.100:9200/myindex/_settings
curl -XPUT '192.168.99.100:9200/myindex/_settings' -d '
{
"index" : {
"action.write_consistency" : "all"
}
}'但是都需要在update的时候手工refresh。
如果是读多写少的应用(特别是replica不多的时候),则可以指定write consistency为all,这样就可以很好地利用replica shard的读来提升es的读性能呢。
参考
https://segmentfault.com/a/1190000005844120



相关推荐
在使用Spring Data Elasticsearch框架时,可能会遇到一个常见的问题,即版本兼容性问题。Spring Data Elasticsearch 5.4.0设计时可能并未考虑到与Elasticsearch 5.4.1的完全兼容,导致在升级Elasticsearch到5.4.1后...
Elasticsearch(ES)作为一个流行的分布式搜索引擎,其核心特性之一就是强大的分布式一致性。本篇主要探讨ES集群的构成、节点发现、Master选举、错误检测以及集群扩缩容的机制。 **1. ES集群构成** 一个ES集群由多...
在使用Elasticsearch时,管理员需要对其集群进行适当的配置和维护,以保证数据的一致性、完整性和高性能。例如,集群中的数据被自动地分布和复制到不同的节点,以防单点故障导致数据丢失。此外,Elasticsearch还提供...
总结,确保 Elasticsearch 的安全性至关重要。启用安全功能、设置用户密码以及使用 SSL/TLS 加密通信是防止未授权访问的基本措施。在集群环境中,还需确保所有节点的安全配置一致,证书分发到位。遵循这些步骤,你...
主要问题在于Elasticsearch集群的数据一致性。在正常的集群运行状态下,所有节点对于集群中master节点的选择应该是一致的,但在网络不稳定时,就可能出现所谓的“脑裂”现象,即不同的节点对master节点的选择出现...
8. 日志记录:`logs`目录用于存放Elasticsearch运行时的日志文件,这对于排查问题和监控系统状态非常有用。 9. 库文件:`lib`目录下是Elasticsearch运行所需的Java库,包括Lucene和其他依赖项。 10. 模块化设计:`...
重新编译的过程确保了所有指令都能被ARM芯片正确解析,避免了兼容性问题,使Elasticsearch在华为服务器上运行更加顺畅。 在安装和使用Elasticsearch-6.6.0-SNAPSHOT时,用户应遵循官方文档的指导,配置适当的硬件...
- **单节点配置**:在`elasticsearch.yml`中,可以设置`cluster.name`以定义集群名称,保持所有节点的集群名称一致,它们就会自动加入同一集群。 - **内存设置**:根据你的系统资源调整`jvm.options`中的堆大小。...
数据湖应用解析:Spark on Elasticsearch一致性问题探讨 Spark与Elasticsearch(ES)的整合,是大数据领域中备受关注的组合。Spark作为一个强大的分布式计算引擎,搭配ES的优秀搜索引擎能力,广泛应用于日志分析、...
3. **依赖(Dependency)**: 介绍了如何在Java项目中添加ElasticSearch Java API依赖,特别是推荐使用与ElasticSearch版本号一致的transport版本号。这是使用ElasticSearch Java API前的必要配置。 4. **Java客户端...
2. **更强的集群一致性**:引入了新的跨节点通信协议,提升了集群的一致性和可靠性。 3. **更丰富的API**:2.0的RESTful API进一步完善,提供更强大的数据管理和查询能力。 4. **更高效的存储**:优化了存储层,...
4. **包结构**:压缩包中的"es"文件夹很可能包含Elasticsearch的核心库文件,这些文件是运行Elasticsearch服务的基础。"other"文件夹中的内容可能包含额外的依赖或辅助工具,其具体用途可能需要进一步探索或文档说明...
Elasticsearch是一个开源的全文搜索引擎,它以分布式、RESTful服务的方式提供快速、高可用、可扩展的数据搜索和分析能力。这个"elasticsearch-7.4.0-win64.rar"压缩包包含了Elasticsearch 7.4.0版本的Windows 64位...
Elasticsearch 8.4.1 的更新可能包含性能提升、新的功能以及已知问题的修复。对于开发者和管理员来说,持续关注官方文档,了解新版本的变化,是保持系统稳定和高效的关键。同时,定期备份数据和监控集群状态也是必要...
综上所述,这个项目旨在解决Elasticsearch在处理中文时的动态词典更新问题,结合MySQL数据库的高效管理和更新能力,实现了词典的实时热更新,从而提高了系统的灵活性和适应性。在实施过程中,我们需要充分理解...
用户需要确保MySQL中的数据类型与Elasticsearch的映射正确,以保证数据的一致性和可用性。 4. **全文搜索与分析**: 一旦数据被导入Elasticsearch,就可以利用其强大的全文搜索、聚合和分析功能进行复杂查询。...
5. **监控和日志**:在执行过程中,密切关注 Elasticsearch 集群的状态和 elasticsearch-dump 的输出日志,以便及时发现和解决问题。 总的来说,elasticsearch-dump 是一个实用的工具,它为 Elasticsearch 用户提供...
2. **集群(Cluster)**:由一个或多个节点组成,它们共享相同的集群名称,共同管理数据并保持数据的一致性。 3. **索引(Index)**:类似于数据库中的表,用于存储具有相同结构的数据。 4. **文档(Document)**:索引中...
5.6版本进一步优化了集群间的通信和数据分布策略,确保高可用性和数据一致性。 2. **RESTful API**:Elasticsearch通过HTTP RESTful接口与客户端进行交互,这使得它易于集成到各种应用程序中。5.6版本提供了稳定且...
还会涉及索引的生命周期管理,包括热温冷数据的划分,以及如何利用Translog保证数据的一致性。 最后,源代码可能还涵盖了Elasticsearch的集群管理和监控,如如何调整节点配置以提高性能,或者如何使用监控工具(如...