
本篇讨论同时使用多个ES Cluster进行搜索的时候,如何保证数据的一致性。
• 名词解释
Cluster:集群,一个集群包含多个Node,且会有一个Master Node。
Node:节点,一般来说一个机器部署一个Node。
Shard:分片,指的是一个Index分成多少份,这些Shards会分散到各个Node上面。
• 为什么要使用多个ES Cluster?
高可用方面:
ElastcSearch拥有许多高可用的特性,例如Replica,例如Data Node挂掉后的数据迁移,例如Master Node挂掉后的自动重选,但这不代表万无一失了。常见的坑是,某个Node表现糟糕但是偏偏又没挂(挂了反而更好),此时整个Cluster的性能就会被一个坑爹Node拖累,这往往就是雪崩的开始。因此,从高可用方面来考虑,应当部署多个ES Cluster(部分作为灾备)。
性能方面:
单个Cluster的搜索能力是有瓶颈的。Cluster越大,Node越多,自然Shard就越多。而Shard不是越多越好,Shard增多会导致通讯成本的增加、查询收束时Re-ranking环节的负担增加。如果有100台机器,那么比起一个100 Node、300 Shards的巨型Cluster,使用十个10 Node 30 Shards的小型Cluster可能表现会更好。
• 什么叫多个ElastcSearch Cluster的一致性问题?
本篇讨论的就是使用多个小型Cluster、而不是一个巨大Cluster进行搜索时会出现的问题。
假设部署了两个Cluster,记为Cluster A和Cluster B,请求均摊去两个Cluster。有一天,你对两个Cluster同时新增了一条数据,但由于一些网络延迟之类的理由,A已经添加了但是B还没有,这时候一个用户搜索请求进来,可能会出现这么个情况:
如果请求的pageSize=4。page=1时,用户请求去了Cluster B;page=2时,用户请求去了Cluster A。这样,用户会看到以下的结果:
 如果请求的pageSize=4。page=1时,用户请求去了Cluster B;page=2时,用户请求去了Cluster A。这样,用户会看到以下的结果:
如果请求的pageSize=4。page=1时,用户请求去了Cluster B;page=2时,用户请求去了Cluster A。这样,用户会看到以下的结果:用户:黑人问号.jpg
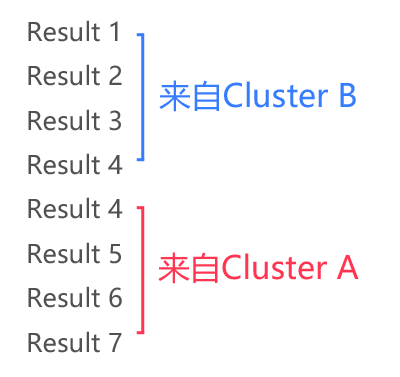 用户:黑人问号.jpg
用户:黑人问号.jpg更糟糕的是,万一在ES前面有一层缓存挡着,而缓存不巧记录了这个诡异的结果,那影响就会扩大了(所有用户:黑人问号.jpg)。
• 解决方案A:单点大法
1. 进入业务请求低谷期时,把所有请求切去1个ES Cluster;
2. 所有ES Cluster开始进行数据同步;
3. 同步完毕后,同时准备离开请求低谷期了,请求开始均摊到多个ES Cluster上。
优点:简单粗暴就是美。能简单粗暴解决的,就不要套复杂的东西。
缺点:1)每天高峰期不能新增数据;2)必须要在低谷期内完成所有数据同步,万一数据同步流程很长且时间不可控则很难实现;3)单点要能够顶过低谷期,万一流量判断错误、或者被攻击,导致单点崩溃,可能发生严重事故。
• 解决方案B:切别名大法
多个ElastcSearch Index的名字切换是个原子操作(搜索"elasticsearch alias"),所以可以这样:
1. 创建两个一样的Index(记为A1、A2);
2. 同步数据到A1;
3. 同步完后,设置别名A,指向刚刚同步好数据的A1(记为A->A1);
4. 使用A进行搜索,请求均摊到每个ES Cluster上;
5. 每次Re-load的时候,所有ES Cluster将数据更新到那个待机中的Index(例如A->A1,那么就更新A2,反之亦然)。在所有ES Cluster都完成数据更新后,同时切换别名(如A->A1,则A->A2,反之亦然)。
优点:比方案A优雅多了。
缺点:1)每个Index要创建两份,存储成本翻倍;2)跟方案A一样,不能实时添加数据;3)实际上,只要是均摊请求,就会出现不一致的问题,ElasticSearch可能根据分片的不同会出现不同的得分,不应使用均摊。
• 解决方案C:哈希大法
1. 对请求进行哈希/散列,确保一个请求每次都会去到同一个ES Cluster;
2. 每个ES Cluster该干嘛干嘛。
优点:比方案B优雅多了,还能实时添加数据。
缺点:万一其中一个ES Cluster挂掉了,怎么办?均摊请求的做法可以很轻松地将挂掉的ES Cluster整个踢出去,那哈希法呢?
• 解决方案D:一致性哈希大法
终于还是到了这一招,新增一层虚拟层,将每个ES Cluster抽象成一个环上的虚拟节点。每个请求在哈希后,先映射去虚拟层,再映射去真实的ES Cluster。
由于每个ES Cluster都存储了完整的数据拷贝,我们并不需要考虑一致性哈希的数据迁移问题。每次新增/删除ES Cluster,就重新分配虚拟节点的位置(环上均分),就可以了。

• 一个新的问题:如何确保多个ES Cluster的更新操作的一致性?
上述全文都在讨论搜索的一致性,那么如何保证插入/更新的一致性呢?
我的解法是,加入一层可以被多人重复消费的消息队列(例如Kafka),作为所有ES Cluster插入/更新的中间层。

这个方案的好处是:
1)主更新程序只有一个,提高可控性和发现问题的能力;
2)使用消息队列来统一发布内容,降低了对数据源的压力;
3)图中消费者这个角色,Elastic Stack官方提供了一个轻量级高可用解决方案,就是Beat。
• 最后留一个小问题
前文讨论了多个Cluster+缓存时出现的一致性问题,其实单Cluster+缓存也可能出现这个问题(极少就是了)。那么,有没有办法彻底解决这个问题呢?
• 结语
ElasticSearch本身是个分布式系统,但如果将其作为一个更大的分布式系统的一个单元的话,将会出现什么问题呢?本文希望可以通过循序渐进的方法,分析围绕ES的高可用方案设计,有许多问题是分布式系统里常见的问题,希望可以对读者有所启发。
https://zhuanlan.zhihu.com/p/24302699



相关推荐
Elasticsearch 广泛应用于日志分析、信息检索、网站搜索、监控等多个领域,因其强大的全文搜索功能和实时分析性能而备受赞誉。 在Windows平台上部署Elasticsearch 8.14.1,你需要先下载对应的安装包,这个压缩文件...
3. **依赖(Dependency)**: 介绍了如何在Java项目中添加ElasticSearch Java API依赖,特别是推荐使用与ElasticSearch版本号一致的transport版本号。这是使用ElasticSearch Java API前的必要配置。 4. **Java客户端...
Elasticsearch是一个开源的全文搜索引擎,它以分布式、RESTful服务的方式提供快速、高可用、可扩展的数据搜索和分析能力。这个"elasticsearch-7.4.0-win64.rar"压缩包包含了Elasticsearch 7.4.0版本的Windows 64位...
2. **集群(Cluster)**:由一个或多个节点组成,它们共享相同的集群名称,共同管理数据并保持数据的一致性。 3. **索引(Index)**:类似于数据库中的表,用于存储具有相同结构的数据。 4. **文档(Document)**:索引中...
3. **动态映射**: 默认情况下,Elasticsearch允许动态映射,但生产环境中应谨慎使用,避免数据类型不一致的问题。 4. **索引别名(Aliases)**: 提供一种对多个索引进行操作的抽象,方便管理和维护。 5. **性能优化**:...
- **集群(Cluster)**:由多个节点组成,共同管理数据并保持数据的一致性。 - **路由(Routing)**:根据文档的_id和指定的路由值决定文档存储在哪个分片上。 3. **全文检索** - **倒排索引(Inverted Index)**:...
Elasticsearch提供了多种级别的一致性保证,如quorum、all等,确保在节点故障情况下仍能保证数据的安全写入。 综上所述,Elasticsearch是一个功能强大、灵活性高的搜索和分析引擎,其分布式架构和丰富的数据处理...
它将数据分布在多个节点上,每个节点都可以处理一部分数据,实现了数据的冗余备份和故障恢复。在源码中,我们可以看到如何通过集群通信(如 `Transport` 模块)来协调各个节点,以及如何使用 `Shard` 和 `Replica` ...
- 数据在Elasticsearch中被分片存储,每个索引可以有多个分片,分片可以分布在不同的节点上,提高读写性能和可扩展性。 - 分片可以有副本,副本在节点故障时提供容错能力,确保数据的高可用性。 **6. 查询与分析*...
1. **分布式特性**:Elasticsearch 最大的特点之一就是其分布式特性,它能够将数据分布在多个节点上,通过自动分片和副本分片实现高可用性和容错性。这意味着即使某个节点出现问题,数据也不会丢失,系统仍能正常...
- **节点和分片**:节点是 Elasticsearch 的执行单元,可以包含多个索引。每个索引被划分为多个**分片(shards)**,包括**主分片(primary shards)**和**副本分片(replica shards)**。 - **主分片**:原始数据...
Elasticsearch支持多节点集群,可以通过修改`elasticsearch.yml`中的`cluster.name`字段将多个节点加入同一个集群。节点间的通信默认使用TCP端口9300。 **数据索引与查询** Elasticsearch的数据模型基于文档,可以...
5. **Elasticsearch如何保证数据一致性?** ES使用软实时性,即数据写入后,经过短暂延迟后才对外可见。在更新或删除操作时,使用版本控制确保并发一致性。 6. **Elasticsearch如何处理数据丢失?** 通过副本分片...
为了确保集群内的一致性和兼容性,所有 Elasticsearch 节点和客户端都应该使用相同的 JVM 版本。 如果使用了已知存在错误的 Java 版本,Elasticsearch 将会拒绝启动。可以通过设置 `JAVA_HOME` 环境变量来指定 ...
9. **数据持久化**:Elasticsearch使用Translog(事务日志)确保数据的一致性和持久化,即使在节点故障后,也能通过Translog恢复未被写入磁盘的数据。 10. **监控和管理**:2.4.1版本已具备基本的健康检查和指标...
2. 集群(Cluster):由多个节点组成,共同维护数据的完整性和一致性。每个集群有一个唯一的名称,节点通过这个名字加入集群。 三、索引与搜索 1. 索引(Index):类似于数据库的表,用于存储具有相似特性的数据。...
9. **错误处理与重试机制**:在数据导入过程中,可能会遇到网络问题、索引冲突等异常,需要设计合理的错误处理和重试机制,确保数据的完整性和一致性。 10. **监控与报警**:使用Elastic Stack中的Kibana进行可视化...
Elasticsearch 集群由多个节点构成,每个节点都是运行 Elasticsearch 服务的服务器实例。节点负责存储数据、参与集群管理和决策过程。 ##### 2.2 数据分片与副本 - **数据分片**:Elasticsearch 将数据分割为多个...
- **集群(Cluster)**: Elasticsearch 集群由多个节点组成,共享相同的数据,并共同维护整个集群的状态。 - **节点(Node)**: 节点是集群中的单一实例,负责存储数据和参与集群操作。 - **索引(Index)**: ...