
Spark有几种部署的模式,单机版、集群版等等,平时单机版在数据量不大的时候可以跟传统的java程序一样进行断电调试、但是在集群上调试就比较麻烦了...远程断点不太方便,只能通过Log的形式进行数据分析,利用spark ui做性能调整和优化。
那么本篇就介绍下如何利用Ui做性能分析,因为本人的经验也不是很丰富,所以只能作为一个入门的介绍。
大体上会按照下面的思路进行讲解:
- 怎么访问Spark UI
- SparkUI能看到什么东西?job,stage,storage,environment,excutors
- 调优的一些经验总结
Spark UI入口
如果是单机版本,在单机调试的时候输出信息中已经提示了UI的入口:
17/02/26 13:55:48 INFO SparkEnv: Registering OutputCommitCoordinator
17/02/26 13:55:49 INFO Utils: Successfully started service 'SparkUI' on port 4040.
17/02/26 13:55:49 INFO SparkUI: Started SparkUI at http://192.168.1.104:4040
17/02/26 13:55:49 INFO Executor: Starting executor ID driver on host localhost单机调试的时候,可以直接登陆:http://192.168.1.104:4040
如果是集群模式,可以通过Spark日志服务器xxxxx:18088者yarn的UI进入到应用xxxx:8088,进入相应的Spark UI界面。
主页介绍
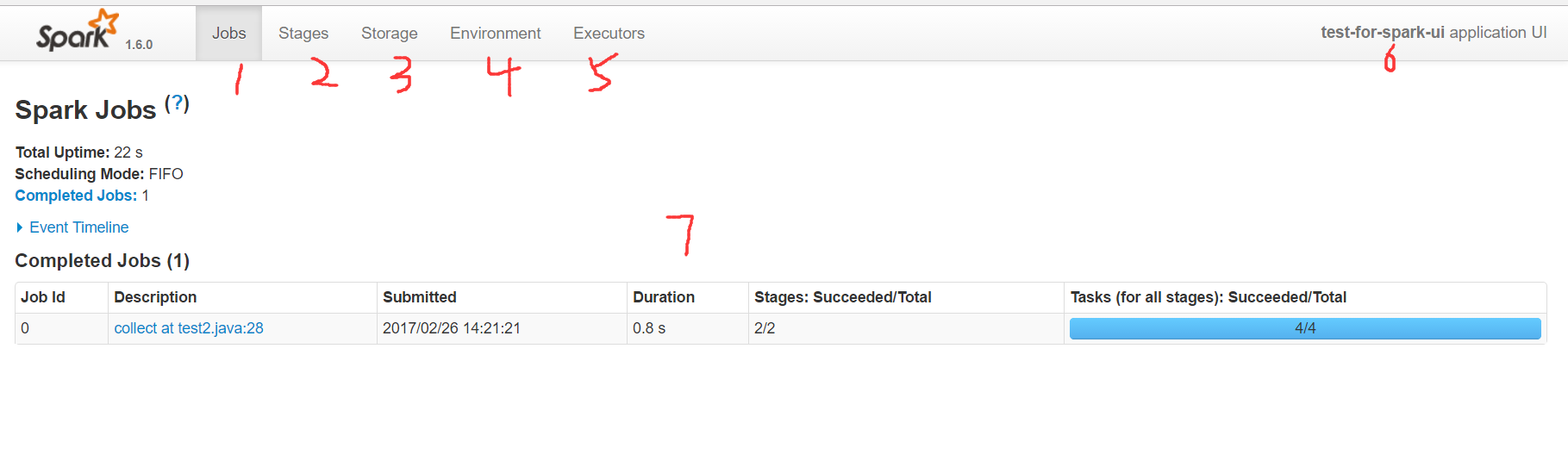
上面就是Spark的UI主页,首先进来能看到的是Spark当前应用的job页面,在上面的导航栏:
- 1 代表job页面,在里面可以看到当前应用分析出来的所有任务,以及所有的excutors中action的执行时间。
- 2 代表stage页面,在里面可以看到应用的所有stage,stage是按照宽依赖来区分的,因此粒度上要比job更细一些
- 3 代表storage页面,我们所做的cache persist等操作,都会在这里看到,可以看出来应用目前使用了多少缓存
- 4 代表environment页面,里面展示了当前spark所依赖的环境,比如jdk,lib等等
- 5 代表executors页面,这里可以看到执行者申请使用的内存以及shuffle中input和output等数据
- 6 这是应用的名字,代码中如果使用setAppName,就会显示在这里
- 7 是job的主页面。
模块讲解
下面挨个介绍一下各个页面的使用方法和实践,为了方便分析,我这里直接使用了分布式计算里面最经典的helloworld程序——WordCount,这个程序用于统计某一段文本中一个单词出现的次数。原始的文本如下:
for the shadow of lost knowledge at least protects you from many illusions
上面这句话是有一次逛知乎,一个标题为 读那么多书,最后也没记住多少,还为什么读书?其中有一个回复,引用了上面的话,也是我最喜欢的一句。意思是:“知识,哪怕是知识的幻影,也会成为你的铠甲,保护你不被愚昧反噬”(来自知乎——《为什么读书?》)
程序代码如下:
public static void main(String[] args) throws InterruptedException {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[2]");
sparkConf.setAppName("test-for-spark-ui");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
//知识,哪怕是知识的幻影,也会成为你的铠甲,保护你不被愚昧反噬。
JavaPairRDD<String,Integer> counts = sc.textFile( "C:\\Users\\xinghailong\\Desktop\\你为什么要读书.txt" )
.flatMap(line -> Arrays.asList(line.split(" ")))
.mapToPair(s -> new Tuple2<String,Integer>(s,1))
.reduceByKey((x,y) -> x+y);
counts.cache();
List<Tuple2<String,Integer>> result = counts.collect();
for(Tuple2<String,Integer> t2 : result){
System.out.println(t2._1+" : "+t2._2);
}
sc.stop();
}这个程序首先创建了SparkContext,然后读取文件,先使用` `进行切分,再把每个单词转换成二元组,再根据key进行累加,最后输出打印。为了测试storage的使用,我这对计算的结果添加了缓存。
job页面
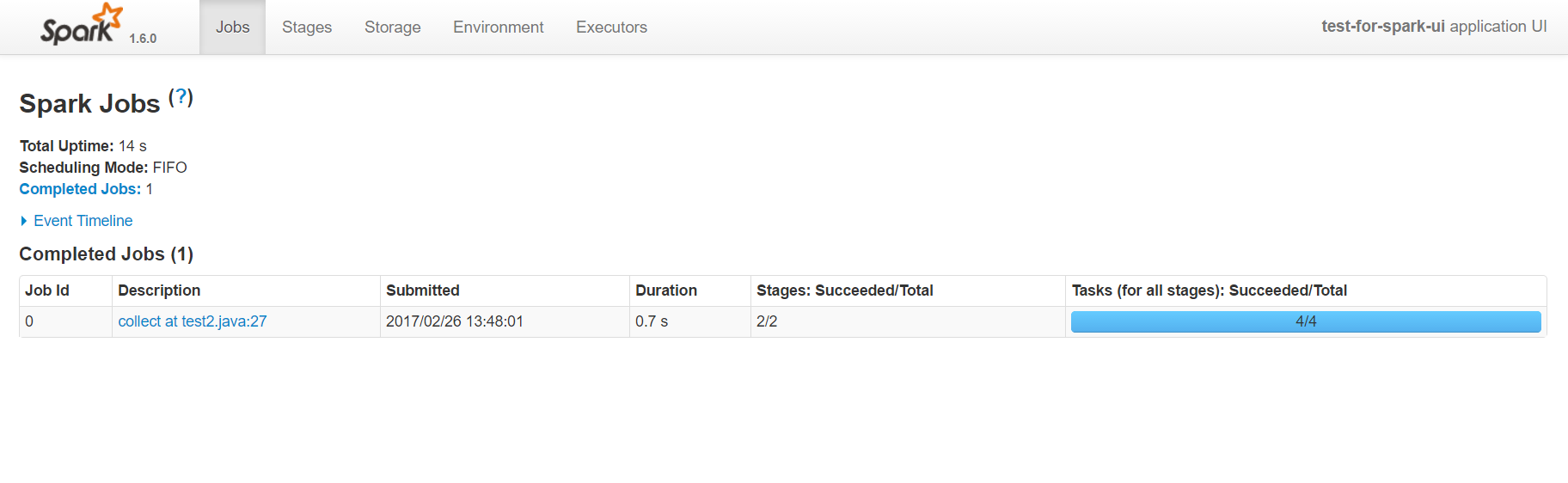
主页可以分为两部分,一部分是event timeline,另一部分是进行中和完成的job任务。
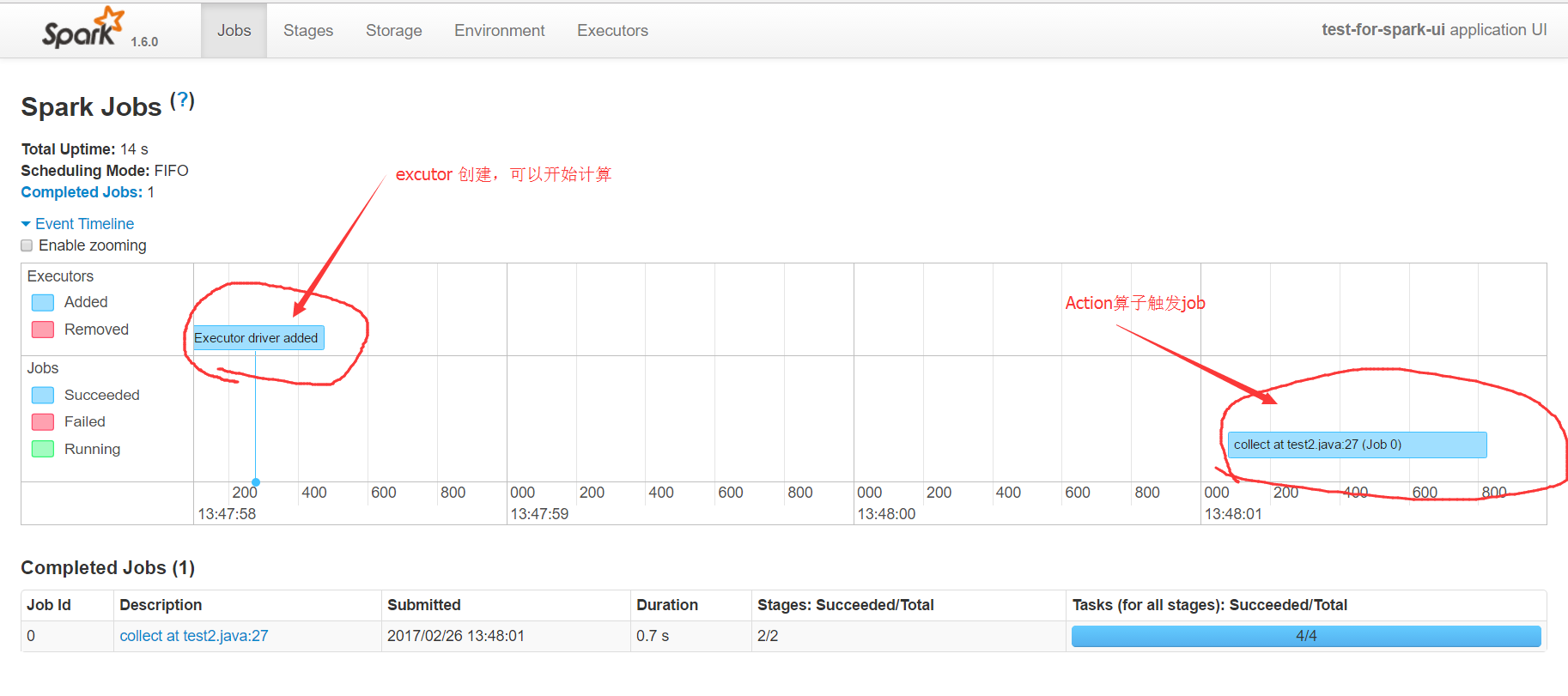
第一部分event timeline展开后,可以看到executor创建的时间点,以及某个action触发的算子任务,执行的时间。通过这个时间图,可以快速的发现应用的执行瓶颈,触发了多少个action。
第二部分的图表,显示了触发action的job名字,它通常是某个count,collect等操作。有spark基础的人都应该知道,在spark中rdd的计算分为两类,一类是transform转换操作,一类是action操作,只有action操作才会触发真正的rdd计算。具体的有哪些action可以触发计算,可以参考api。collect at test2.java:27描述了action的名字和所在的行号,这里的行号是精准匹配到代码的,所以通过它可以直接定位到任务所属的代码,这在调试分析的时候是非常有帮助的。Duration显示了该action的耗时,通过它也可以对代码进行专门的优化。最后的进度条,显示了该任务失败和成功的次数,如果有失败的就需要引起注意,因为这种情况在生产环境可能会更普遍更严重。点击能进入该action具体的分析页面,可以看到DAG图等详细信息。
stage页面
在Spark中job是根据action操作来区分的,另外任务还有一个级别是stage,它是根据宽窄依赖来区分的。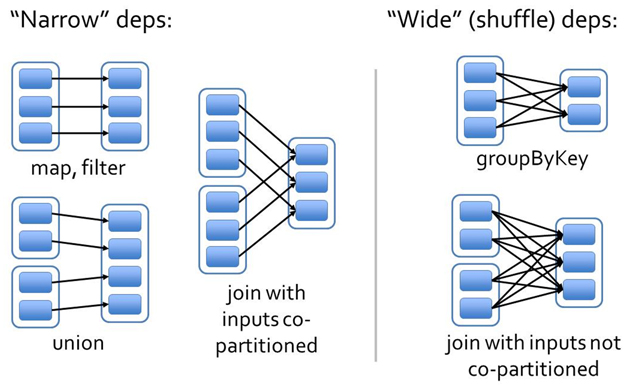
窄依赖是指前一个rdd计算能出一个唯一的rdd,比如map或者filter等;宽依赖则是指多个rdd生成一个或者多个rdd的操作,比如groupbykey reducebykey等,这种宽依赖通常会进行shuffle。
因此Spark会根据宽窄依赖区分stage,某个stage作为专门的计算,计算完成后,会等待其他的executor,然后再统一进行计算。
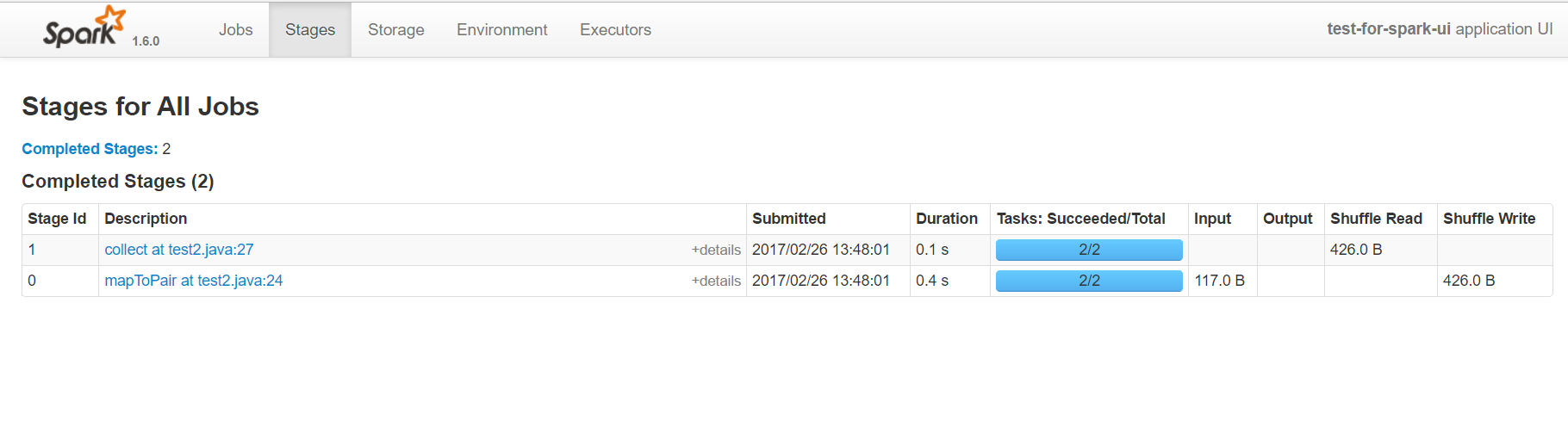
stage页面的使用基本上跟job类似,不过多了一个DAG图。这个DAG图也叫作血统图,标记了每个rdd从创建到应用的一个流程图,也是我们进行分析和调优很重要的内容。比如上面的wordcount程序,就会触发acton,然后生成一段DAG图:
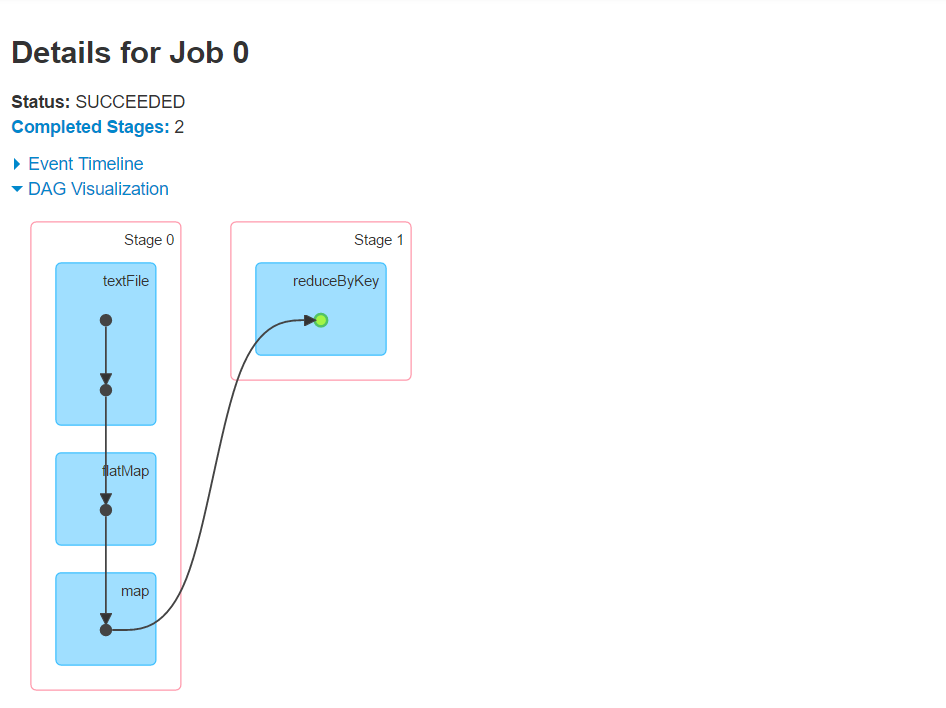
从这个图可以看出,wordcount会生成两个dag,一个是从读数据到切分到生成二元组,第二个进行了reducebykey,产生shuffle。
点击进去还可以看到详细的DAG图,鼠标移到上面,可以看到一些简要的信息。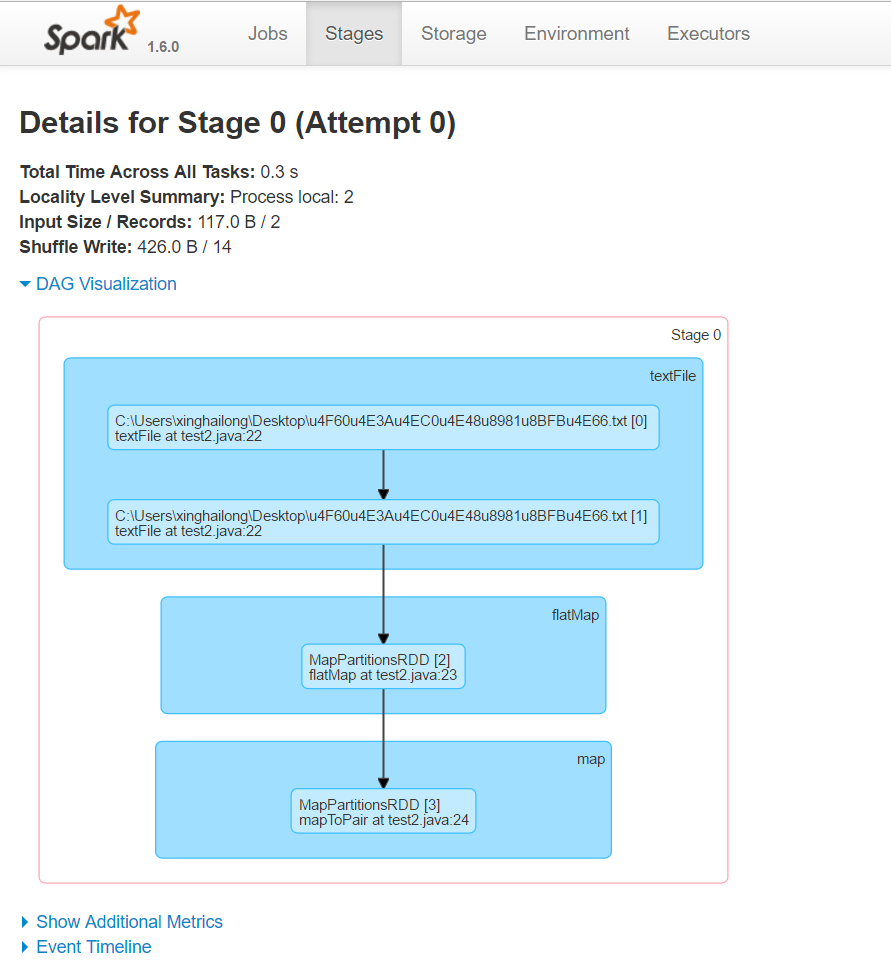
storage页面
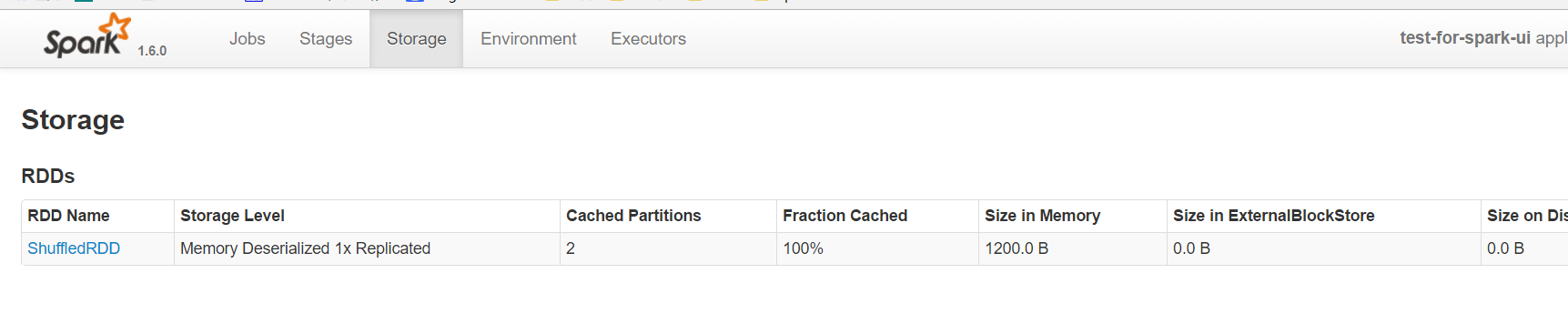
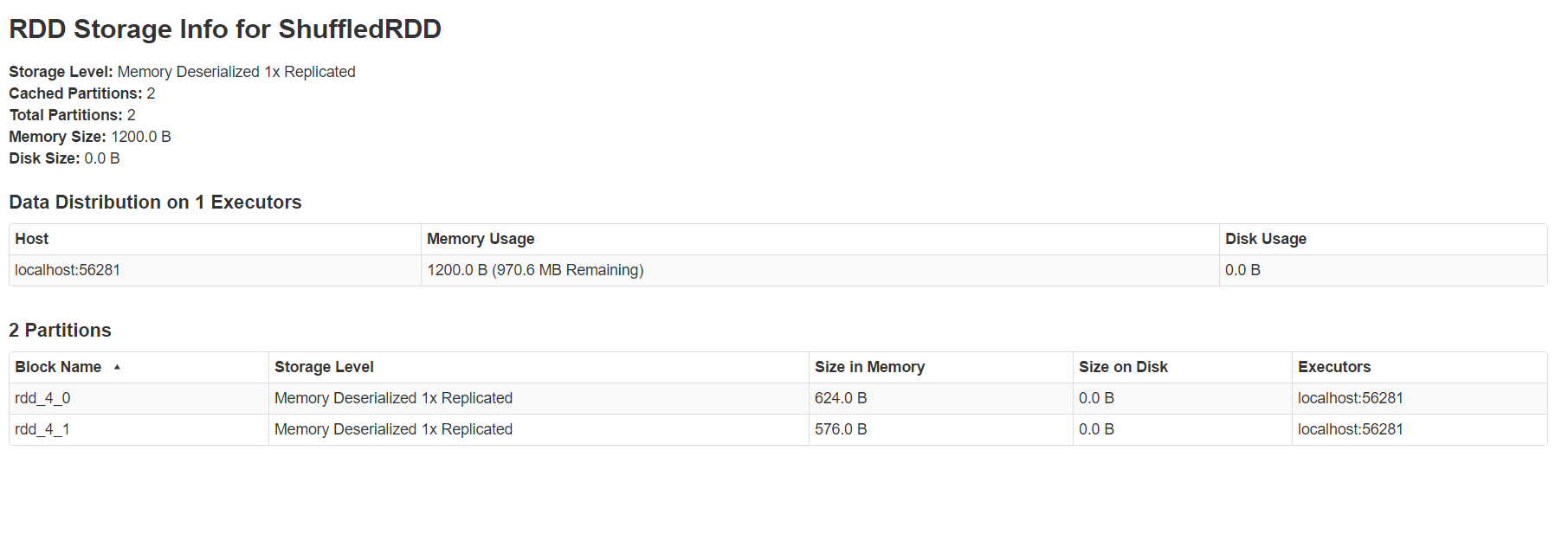
storage页面能看出目前使用的缓存,点击进去可以看到具体在每个机器上,使用的block的情况。
environment页面
这个页面一般不太用,因为环境基本上不会有太多差异的,不用时刻关注它。
excutors页面
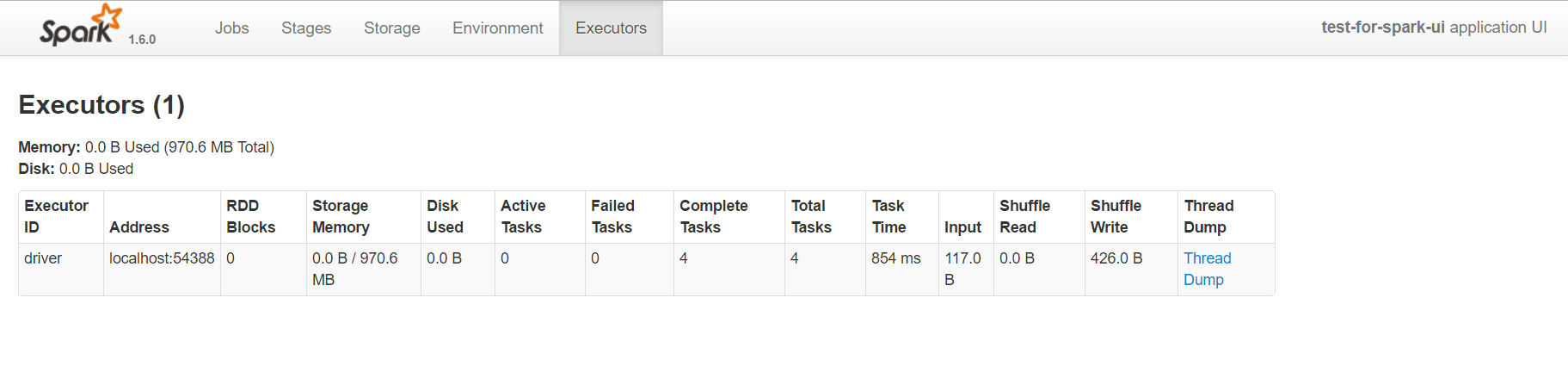
这个页面比较常用了,一方面通过它可以看出来每个excutor是否发生了数据倾斜,另一方面可以具体分析目前的应用是否产生了大量的shuffle,是否可以通过数据的本地性或者减小数据的传输来减少shuffle的数据量。
调优的经验总结
1 输出信息
在Spark应用里面可以直接使用System.out.println把信息输出出来,系统会直接拦截out输出到spark的日志。像我们使用的yarn作为资源管理系统,在yarn的日志中就可以直接看到这些输出信息了。这在数据量很大的时候,做一些show()(默认显示20),count() 或者 take(10)的时候会很方便。
2 内存不够
当任务失败,收到sparkContext shutdown的信息时,基本都是执行者的内存不够。这个时候,一方面可以调大--excutor-memory参数,另一方面还是得回去看看程序。如果受限于系统的硬件条件,无法加大内存,可以采用局部调试法,检查是在哪里出现的内存问题。比如,你的程序分成几个步骤,一步一步的打包运行,最后检查出现问题的点就可以了。
3 ThreadPool
线程池不够,这个是因为--excutor-core给的太少了,出现线程池不够用的情况。这个时候就需要调整参数的配置了。
4 physical memory不够

这种问题一般是driver memory不够导致的,driver memory通常存储了以一些调度方面的信息,这种情况很有可能是你的调度过于复杂,或者是内部死循环导致。
5 合理利用缓存
在Spark的计算中,不太建议直接使用cache,万一cache的量很大,可能导致内存溢出。可以采用persist的方式,指定缓存的级别为MEMORY_AND_DISK,这样在内存不够的时候,可以把数据缓存到磁盘上。另外,要合理的设计代码,恰当地使用广播和缓存,广播的数据量太大会对传输带来压力,缓存过多未及时释放,也会导致内存占用。一般来说,你的代码在需要重复使用某一个rdd的时候,才需要考虑进行缓存,并且在不使用的时候,要及时unpersist释放。
6 尽量避免shuffle
这个点,在优化的过程中是很重要的。比如你需要把两个rdd按照某个key进行groupby,然后在进行leftouterjoin,这个时候一定要考虑大小表的问题。如果把大表关联到小表,那么性能很可能会很惨。而只需要简单的调换一下位置,性能就可能提升好几倍。
写在最后
大数据计算总是充满了各种神奇的色彩,节点之间的分布式,单节点内多线程的并行化,只有多去了解一些原理性的东西,才能用好这些工具。
最后还是献上最喜欢的那句话——知识,哪怕是知识的幻影,也会成为你的铠甲,保护你不被愚昧反噬。



相关推荐
Spark性能优化是一个重要的大数据处理话题。在处理大规模数据集时,性能优化直接关系到任务的执行效率,尤其在资源有限的情况下。本文将着重于介绍Spark中的高级性能优化技巧,特别是针对数据倾斜和shuffle过程的...
根据提供的文件内容,这份文档是关于Apache Spark的性能优化指南,特别强调了在大数据处理场景下如何通过对Spark作业进行优化来提升性能。以下是关于文档中提到的各个方面的详细知识点: 1. **Spark作业性能优化的...
本文主要探讨Spark性能优化的基础篇,包括开发调优和资源调优,旨在帮助开发者创建出更高效的Spark作业。 首先,开发调优是性能优化的关键步骤。在开发Spark作业时,遵循一些基本的开发原则可以显著提高性能: 1. ...
本资料是集合20篇知网被引最高的基于spark的大数据论文,包括大数据Spark技术研究_刘峰波、大数据下基于Spark的电商实时推荐系统的设计与实现_岑凯伦、基于Spark的Apriori算法的改进_牛海玲、基于Spark的大数据混合...
spark优化,spark优化,spark优化,spark优化,spark优化
### Spark Web UI 详解 ...Spark Web UI 是一款强大的工具,对于理解和优化 Spark 应用程序至关重要。通过对 Spark Web UI 的深入学习,可以帮助开发者更好地掌握 Spark 的运行机制,并有效地提升应用程序的性能。
本篇资源摘要信息将为读者提供基于Spark SQL构建即席查询平台的知识点总结,涵盖了即席查询的概念、Spark的选择理由、基于Spark的架构设计、性能优化、安全和资源隔离等方面的详细内容。 一、即席查询的概念 即席...
### Spark性能优化指南—高级篇 #### 数据倾斜调优 数据倾斜是Spark处理大数据时最常见的问题之一,它严重影响了任务的执行效率。本章节重点探讨数据倾斜现象的原因、识别方式及解决方案。 ##### 调优概述 数据...
Spark性能优化防止数据倾斜 Spark性能优化是大数据处理的关键一步,数据倾斜是Spark作业中一个常见的问题。数据倾斜是指在大数据计算中,少数task执行时间远远长于其他task,导致整个Spark作业的性能下降。Spark...
### Spark性能优化研究 #### 研究背景与意义 随着大数据时代的到来,全球数据量呈爆炸性增长态势,遵循所谓的“新摩尔定律”,即全球数据量大约每18个月就会翻一番,年增长率达到了59%。这种快速增长不仅体现在...
【毕业设计】基于Spark图计算的社会网络分析系统的设计和实现——顶点分析系统源码【毕业设计】基于Spark图计算的社会网络分析系统的设计和实现——顶点分析系统源码【毕业设计】基于Spark图计算的社会网络分析系统...
基于Spark的电影推荐系统的设计与实现.docx基于Spark的电影推荐系统的设计与实现.docx基于Spark的电影推荐系统的设计与实现.docx基于Spark的电影推荐系统的设计与实现.docx基于Spark的电影推荐系统的设计与实现.docx...
Spark是一种快速、通用且可扩展的大数据处理引擎,它提供了基于内存计算的DAG(有向无环图)执行模型,相较于Hadoop MapReduce,Spark能够提供更高的计算性能。Spark的核心组件包括Spark Core、Spark SQL、Spark ...
《Spark大数据处理:技术、应用与性能优化》这本书全面涵盖了Spark在大数据领域的核心技术和实践应用,同时也深入探讨了性能优化的策略与方法。Spark作为一款快速、通用且可扩展的数据处理框架,因其高效的内存计算...
总的来说,基于Spark的外卖大数据平台分析系统,充分利用了Spark的高性能计算能力,实现了对外卖数据的实时处理和深度分析。通过这样的系统,不仅可以提升外卖服务的运营效率,还能为用户提供更贴心的服务,推动整个...
《基于Spark的全球新冠疫情系统的分析与实现》 在大数据时代,快速、高效地处理和分析海量数据成为关键。Apache Spark作为一个分布式计算框架,以其高效的数据处理能力,成为了大数据领域的重要工具。本文将深入...