
Spark1.5堆内存分配
这是spark1.5及以前堆内存分配图

下边对上图进行更近一步的标注,红线开始到结尾就是这部分的开始到结尾
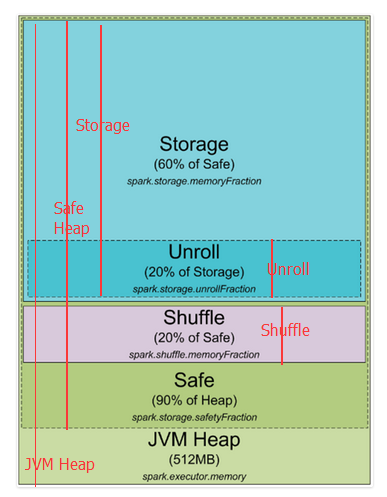
spark 默认分配512MB JVM堆内存。出于安全考虑和避免内存溢出,Spark只允许我们使用堆内存的90%,这在spark的spark.storage.safetyFraction 参数中配置着。也许你听说的spark是一个内存工具,Spark允许你存储数据在内存。其实,Spark不是真正的内存工具,它只是允许你使用内存的LRU(最近最少使用)缓存 。所以,一部分内存要被用来缓存你要处理的数据,这部分内存占可用安全堆内存的60%,这个值在spark.storage.memoryFraction参数中配置。所以如果你想知道你可以存多少数据在spark中,spark.storage.safetyFraction 默认值为0.9,spark.storage.memoryFraction的默认值为0.6,
Storage=总堆内存*0.9*0.6,所以你有54%的堆内存用来存储数据。
shuffle内存:
spark.shuffle.safetyFraction * spark.shuffle.memoryFraction
spark.shuffle.safetyFraction默认为0.8或80%,spark.shuffle.memoryFraction默认为0.2或20%,则你最终可以使用0.8*0.2=0.16或16%的JVM 堆内存用于shuffle。
Unroll内存:
spark允许数据以序列化或非序列化的形式存储,序列化的数据不能拿过来直接使用,所以就需要先反序列化,即unroll。
Heap Size*spark.storage.safetyFraction*spark.storage.memoryFraction*spark.storage.unrollFraction=Heap Size *0.9*0.6*0.2=Heap Size * 0.108或10.8%的JVM 堆内存。
到此为止,你应该就知道Spark是如何使用jvm内存的了,下边是集群模式,以yarn为例,其它类似。

在Yarn集群中,Yarn Resource Manager管理集群的资源(实际就是内存)和一系列运行在集群Node上yarn resource manager及集群Nodes资源的使用。从YARN的角度,每一个 Node都代表了一个可控制的内存资源,当你向Yarn Resource Manager申请资源时,它会反馈给你哪个yarn node manager 可以连接并启动一个execution container给你。每一个execution container都是一个可以提供堆内存的JVM,JVM的位置是由Yarn Resource manager选择的。
当你在Yarn上启动Spark时,你可以指定executor的数量(–num-executors flag or spark.executor.instances parameter)、每个executor的内存大小(–executor-memory flag or spark.executor.memory parameter)、每个executor的内核数量(–executor-cores flag of spark.executor.coresparameter)、每个task执行的内核数量(spark.task.cpusparameter),你也可以指定driver的内存大小(–driver-memory flag or spark.driver.memory parameter)。
当你在集群中执行某项任务时,一个job会被切分成stages,每个stage会被分成多个task,每个task会被单独分配,你可以把这些executor看成一个个执行task的槽池(a pool of tasks execution slots)。如下看一个例子:一个集群有12个节点(yarn node manager),每个节点有64G内存、32核的CPU(16个物理内核,一个物理内核可以虚拟成两个)。每个节点你可以启动两个executors、每个executor分配26G内存(留一部分用于system process、yarn NM、DataNode).所以集群一共可以处理 12 machines * 2 executors per machine * 12 cores per executor / 1 core for each task = 288 task slots。这意味着该集群可以并行运行288个task,充分利用集群的所有资源。你可以用来存储数据的内存为= 0.9 spark.storage.safetyFraction * 0.6 spark.storage.memoryFraction * 12 machines * 2 executors per machine * 26 GB per executor = 336.96 GB。没有那么多,但是也足够了。
到此,你已经知道spark如何分配 jvm内存,在集群中可以有多少个execution slots。那么什么是task,你可以把他想像成executor的某个线程,executor是一个进程 ,它可以多线程的执行task.
下边来解释一下另一个抽象概念"Partition",你用来分析的所有数据都将被切分成partitions,那么何为一个partition,它又是由什么决定的?partition的大小是由你使用的数据源决定的,在spark中你可以使用的所有读取数据的方式,大多你可以指定你的RDD中有多少个partitions。当你从HDFS中读取一个文件时,hadoop的InputFormat决定partition。通常由InputFormat输入的每一个 split对应于RDD中的一个partition,而每一个split通常相当于hdfs中的一个block(还有一些其它情况,暂不解释,如text file压缩后传过一整个partition不能直接使用)。
一个partition产生一个task,并在数据所在的节点task slot执行(数据本地性)
http://blog.csdn.net/u014686180/article/details/53082606



相关推荐
UnifiedMemoryManager 是 Spark 1.6 之后的默认内存管理方式,它将内存分配给存储和执行两个部分,但不再使用一刀切的方式,而是根据需要动态调整。Storage 部分的内存为 (10G-300M)*0.75/2 = 3479M,Executor 部分...
在实践中,对Spark内存的优化需要综合考虑执行内存与存储内存之间的比例,以及内存分配策略。合理分配内存不仅可以提升执行效率,还能有效防止内存溢出错误,是提升Spark应用性能的关键。 Spark的内存管理机制设计...
- **固定内存分配**:在某些情况下,也可以选择固定内存分配策略,即预先设置好存储内存和执行内存的比例。 ##### 4.2 内存回收 - **存储内存回收**:当存储内存不足时,Spark会根据LRU(Least Recently Used)算法...
在进行Spark编程和集群部署时,还需要特别注意CPU和内存的分配,要合理规划执行器的数量和大小,确保它们既能高效利用资源又不会相互干扰。资源的合理分配直接影响到Spark程序运行效率和集群的稳定性。 需要注意的...
- **内存分配**:增加Executor的数量虽然可以提高并行度,但也可能因为单个Executor可用内存减少而导致频繁的数据溢出甚至内存溢出。因此,在设计Executor数量时需要综合考虑机器内存大小和预期的并行度需求。 - **...
Spark内存管理是Spark性能优化的关键环节,它涉及到堆内和堆外两部分内存的规划与使用。Spark作为基于JVM的分布式计算框架,其内存管理建立在JVM的基础之上,但进行了更细致的划分和控制。 首先,让我们来讨论堆内...
Spark内存使用机制是Apache Spark高性能计算的关键组成部分,它在处理大规模数据时的高效性与内存管理密切相关。在Spark中,内存被分为多个部分,用于不同的功能,包括存储、执行和其他用途。以下是对Spark内存使用...
BigData321),我将忽略这些部分,并基于标题和描述中所提及的“Understanding-Memory-Management-In-Spark-For-Fun-And-Profit.pdf”和“spark内存的设计”来生成详细的知识点。 Apache Spark是一个强大的开源处理...
7. Spark内存管理: Spark利用内存存储中间结果,通过Tungsten项目优化了内存布局,减少序列化开销。同时,通过动态内存管理,自动平衡计算和存储需求。 8. Spark容错与弹性: 通过检查点和持久化策略,Spark能够在...
性能调优是Spark应用的关键环节,包括调整executor数量、内存分配、shuffle行为、数据序列化策略等。合理设置这些参数能显著提升Spark应用的效率。 **9. Spark的监控和日志管理** Spark提供了Web UI来监控应用程序...
Spark会根据任务的需求动态调整这两部分的内存分配。在某些情况下,如果Execution Memory不足,Spark会尝试将Storage Memory中的数据卸载到磁盘以释放内存。 3. **常见错误与解决方案** 在Spark on YARN环境中,...
这两个部分都需要使用内存,但是它们之间的内存分配却是一个难题。如果执行内存使用了太多的内存,存储内存将会受到影响,反之亦然。为了解决这个问题,Spark 采用统一的内存管理机制,这样可以更好地分配内存资源。...
资源分配是 Spark 生产优化的最后一个方面,Spark 任务的资源分配包括 CPU cores 和内存的分配。在 Spark 中,可以使用 spark.executor.cores 和 spark.executor.memory 等参数来控制资源的分配。 Spark 生产优化是...
1. **内存计算**:Spark通过将数据存储在内存中,实现了比Hadoop MapReduce更快的数据处理速度,提高了计算效率。 2. **弹性**:Spark能够自动将任务调度到空闲的节点上,从而实现对资源的有效利用。 3. **多模式...
- **Executor内存分配**:`spark.executor.memory`设置为8GB,表示Hive在Spark上的每个执行程序的最大Java堆栈内存;`spark.yarn.executor.memoryOverhead`设置为2GB,用于预留额外内存。需要注意的是,两者之和不能...
- Spark内存分为堆内内存(On-heap memory)和堆外内存(Off-heap memory),1.6版本之后引入了统一内存管理,Execution和Storage内存共享同一空间。 - Execution Memory用于计算过程中的临时数据,如Shuffle操作...
3. Spark内存管理 Spark的内存管理机制设计用于优化数据处理速度。它将内存划分为两部分:存储内存(Storage Memory)和执行内存(Execution Memory),分别用于存储RDD缓存和执行任务。此外,Spark还引入了Tachyon...
安装过程可能涉及到设置环境变量、配置文件和网络接口,以及调整内存和处理器核数等资源分配设置,以确保Spark能够高效运行。 Spark 2.3.2还支持Python API,也称为PySpark。PySpark允许数据科学家和工程师使用...
和Yarn中的Containers一样,在SparkOnYarn模式下,通常使用–num-executors来指定Application使用的executors数量,而–executor-memory和–executor-cores分别用来指定每个executor所使用的内存和虚拟CPU核数。...