
学Java的都知道hashMap的底层是“链表散列”的数据结构也也可以说是hash表。在put的实话先根据key的hashcode重新计算hash值的,而我们又知道hash是一种算法。所以哈希码并不是完全唯一的。
查看哈希码百科:

哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表
一:为什么说hashmap的put方法是根据key进行hashcode计算的呢?
查看源码:

在查看hash方法,如下:

查看putVal方法:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node [] tab; Node p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode )p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
二:hashmap怎么解决key的hash值冲突问题的?

上图是源码截图,说明:
1:初始化map的大小。默认是16
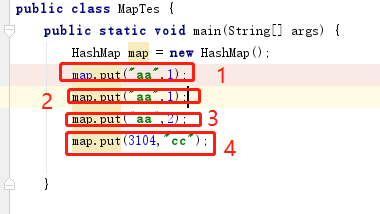
示例代码:HashMap map = new HashMap();
2:如果tab为空,就newNode一个放到链表中
示例代码:map.put("aa",1); 也就是图-1测试代码中的1
3:根据key算出的hash值如果存在,且key的值和map中已经存在的值equals了。所以就不处理。
如下图:
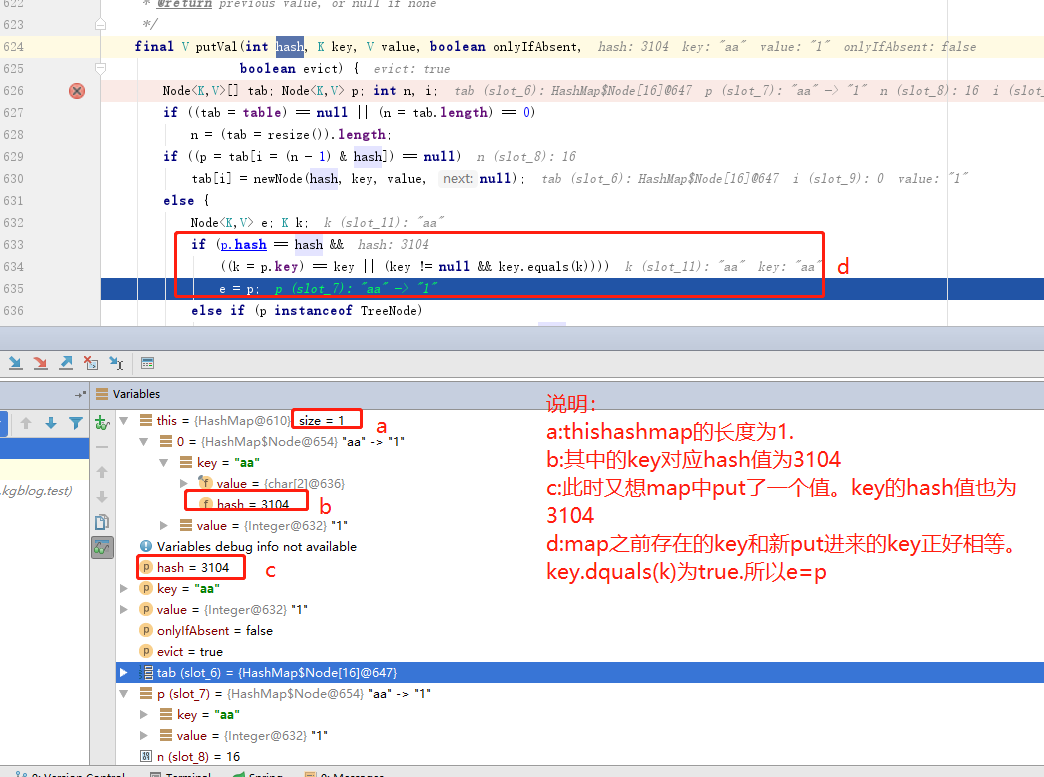
测试代码如图-1测试代码中的1和 2
4:如果p是TreeNode的子类进行putTreeValu
5:如果key的hash值和map中已经存在的key的hash相等且key不同的时候,如果数组该位置上没有元素,就直接将该元素放到此数组中的该位置上。
如图-1测试代码 1和4中key的hesh值都为3104
图-1测试代码
在来看下Node这个内部类:

三:在来看看怎么get方法
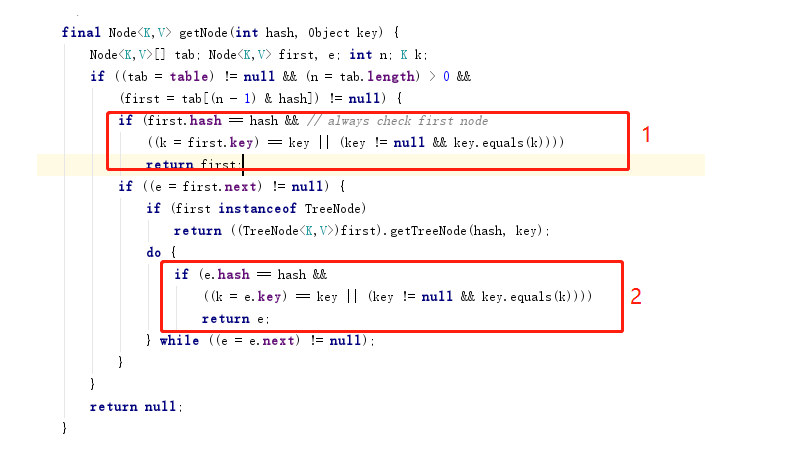
说明:
1:如果链表中第一个值的hash值和需要获取的key的hash值相等的话,就直接取出。
2:如果链表first.next !=null就循环查找链表中的key,知道查询到key.equals(k) 取出对应的值。
查看源码或许感觉不懂,那么画图来说明:

总结:
数据结构:哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表。
map的put方法:
1:new hashMap的时候初始化默认大小为16
2:当map.put("aa",1)的时候判断map没有值,就把aa算的hash值放到0X004的位置
3:当再次执行map.put("aa",1)的是计算aa的hash值为3104.此时在OX004的位置已经有数据了。进行判断存在的key和新put的key是否相同。相同不处理,值覆盖
4:执行map.put("aa",2)的时候key和已经存在的key相同就直接覆盖value了
5:执行map.put(3104,"cc")的时候,key的hash值也为3104.此时数组中OX004已经存在数据,判断key是否相同。发现3104和aa不相同【注:此时就发生了hash冲突】,那么就aa这个链表前面追加3104
6:执行map.put("bb","cc")。假设bb计算出的hash值是3105就存放在了OX005上。
其他依次类推
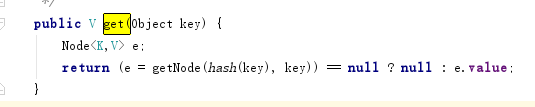
map的get方法:
当执行map.get("bb")的时候先计算出bb的hash值为3105在对应的位置(也就是0X005)取出第一个判断值是不是bb如果是就直接取出value.
当执行map.get("aa")的时候先计算出aa的hash值为3104,去对应的位置取出判断值(3104)不等于(aa)且还有next。就循环取出进行比较。



相关推荐
一致性哈希(Consistent Hashing)是一种分布式哈希表(DHT)的算法,它主要应用于分布式缓存、负载均衡等场景,旨在解决在动态扩展或收缩系统规模时,尽量减少数据迁移的问题。在这个简单的实现中,我们将探讨如何...
【一致性哈希与Chord1】是一篇关于分布式哈希算法的文章,主要讨论了一致性哈希和普通哈希的区别,以及如何通过引入虚拟节点来优化一致性哈希的分布问题。 1. **普通哈希算法**: - Java中的`HashMap`类是一个典型...
3. 数据一致性:为了保证数据的一致性,可能需要使用诸如CAS(Compare and Swap)或其他无锁算法来更新HashMap中的数据。 4. 故障恢复:如果进程崩溃,如何保证其他进程可以正确地处理这种情况,避免数据丢失或损坏...
此外,对于大型数据集,优化哈希函数以减少冲突和提高查询效率是关键,这可能涉及到动态调整数组大小、使用更复杂的哈希算法或者采用一致性哈希等策略。 总的来说,这个项目提供了一个实践理解哈希表和哈希函数的...
如果多个线程并发地访问并修改`HashMap`,则可能导致数据不一致性问题。为了在多线程环境中安全地使用`HashMap`,开发者需要自己负责同步,例如使用`Collections.synchronizedMap(new HashMap,V>())`创建线程安全的`...
HashMap的工作原理基于哈希函数,它将键(Key)转化为一个哈希码(Hash Code),这个哈希码用于确定键值对在数组中的位置。当两个不同的键经过哈希函数处理后得到相同的哈希码时,就会发生哈希碰撞。为了解决这个...
相反,如果你的应用程序需要处理多线程并发问题,并且对线程安全性有严格要求,那么 `Hashtable` 或者通过 `Collections.synchronizedMap()` 包装后的 `HashMap` 更适合。了解这些区别有助于开发者在实际开发过程中...
### HashMap和ConcurrentHashMap...综上所述,面试时通常会针对HashMap和ConcurrentHashMap的实现原理、它们的差异、以及在并发环境下如何保证数据的一致性和线程安全进行提问。了解这些知识点有助于在面试中脱颖而出。
这些类型的对象已经重写了`equals()`和`hashCode()`方法,确保了键对象的不可变性和哈希一致性,从而减少了哈希冲突的可能性。 ##### 3.2 初始化参数的选择 初始化HashMap时,可以通过指定初始容量和加载因子来...
这个设计是为了在保证空间效率的同时,尽量减少哈希冲突的可能性。 4. 入库操作:当我们使用put()方法添加键值对时,首先计算键的哈希码,然后找到对应的桶(Bucket)。如果桶中没有其他键值对,就直接放入;如果有...
在多线程环境中,为了保证数据的一致性和正确性,通常需要引入锁机制,但这会增加额外的开销,降低并发性能。Go语言提供了通道(Channel)和原子操作(Atomic Operations)等原生并发工具,使得无锁实现成为可能。 ...
- **字段属性**:包括`serialVersionUID`用于序列化一致性,`DEFAULT_INITIAL_CAPACITY`定义了默认初始容量(16),`MAXIMUM_CAPACITY`表示最大容量(2^30),`LOAD_FACTOR`是默认负载因子(0.75)。 4. **哈希桶...
在Java中实现一致性哈希,可以使用JDK自带的`java.util.HashMap`或者第三方库如Google的Guava库中的`com.google.common.hash.Hashing`类来计算哈希值。然后,为了实现环形结构,可以自定义一个`Node`类表示节点,并...
在使用HashMap时,需要注意几个关键点:1) 键必须正确实现hashCode()和equals()方法,以确保哈希计算和比较的一致性;2) 避免使用null键和null值,因为HashMap的null键和null值有特殊含义;3) 考虑负载因子和初始...
如果在多线程环境中使用,需要额外的同步措施来确保数据的一致性和安全性。 ### HashMap 和 HashTable 的区别 #### 相同点 - **线程安全性**:尽管HashMap是非线程安全的,但在某些情况下,两个类都会使用同步...
如何用TreeMap实现一致性hash? ConcurrentHashMap是如何在保证并发安全的同时提高性能? ConcurrentHashMap是如何让多线程同时参与扩容? LinkedBlockingQueue、DelayQueue是如何实现的? CopyOnWriteArrayList是...
此外,HashMap还有一个内部字段`modCount`,在ArrayList和HashMap中都有,用于记录结构修改的次数,主要用于并发控制,确保在多线程环境下数据的一致性。当多个线程同时修改HashMap时,`modCount`的检查可以防止并发...
线程安全:在多线程环境下,为了保证数据一致性,我们需要确保对HashMap的操作是线程安全的。这通常通过使用互斥量(mutex)、原子操作(atomic)或者读写锁(read-write lock)等同步原语来实现。在C++中,`std::...
哈希表(Hashmap)是一种常见的数据结构,它在计算机科学和编程...然而,实际应用中,可能还需要考虑其他因素,如线程安全、内存效率和数据一致性。理解这些原理并实践,对于提升C语言编程能力及数据结构掌握至关重要。
- **键的equals和hashCode方法**:由于HashMap是根据键的hashCode来计算索引的,因此键对象需要合理重写equals和hashCode方法,保证哈希的一致性和准确性。 #### 七、结语 通过深入解析HashMap在JDK 7.0中的底层...