
当前,很多用户的业务数据存放在传统关系型数据库上,例如阿里云的RDS,做业务读写操作。当数据量非常大的时候,此时传统关系型数据库会显得有些吃力,那么会经常有将mysql数据库的数据迁移到[大数据处理平台-大数据计算服务(Maxcompute,原ODPS)(https://www.aliyun.com/product/odps?spm=5176.doc27800.765261.309.dcjpg2),利用其强大的存储和计算能力进行各种查询计算,结果再回流到RDS。
一般情况下,业务数据是按日期来区分的,有的静态数据可能是按照区域或者地域来区分,在Maxcompute中数据可以按照分区来存放,可以简单理解为一份数据放在不同的子目录下,子目录的名称以日期来命名。那么在RDS数据迁移到Maxcompute上的过程中,很多用户希望可以自动的创建分区,动态的将RDS中的数据,比如按日期区分的数据存放到Maxcompute中,这个流程自动化创建。同步的工具是使用Maxcompute的配套产品-[大数据开发套件](https://data.aliyun.com/product/ide?spm=5176.7741945.765261.313.TQqfkK)。下面就举例说明RDS-Maxcompute自动分区几种方法的使用。
一,将RDS中的数据定时每天同步到Maxcompute中,自动创建按天日期的分区。
这里就要用到大数据开发套件-数据集成的功能,我们采用界面化的配置。
如图地方,设置Maxcompute的分区格式
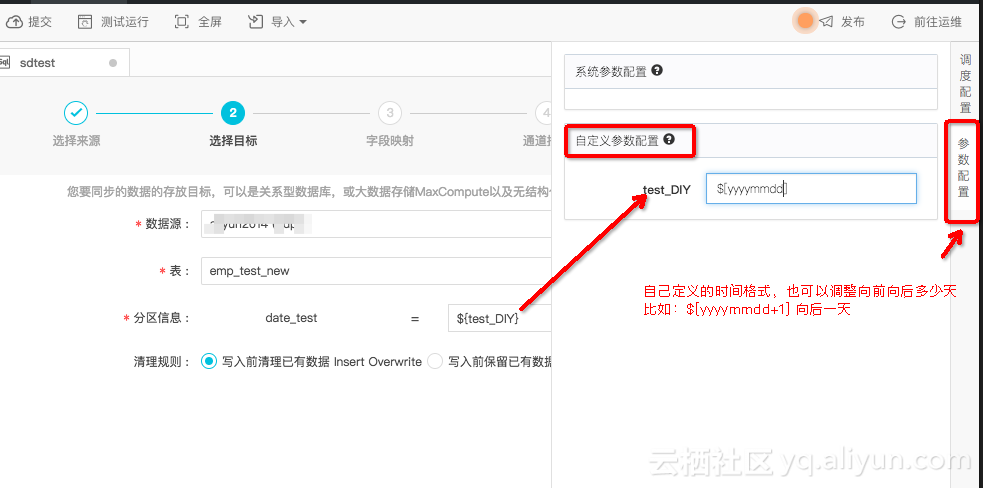
一般配置到这个地方的时候,默认是系统自带时间参数:${bdp.system.bizdate} 格式是yyyymmdd。也就是说在调度执行这个任务的时候,这个分区会被自动替换为 **任务执行日期的前一天**,相对用户比较方便的,因为一般用户业务数据是当前跑前一天的业务数据,这个日期也叫业务日期。
如图
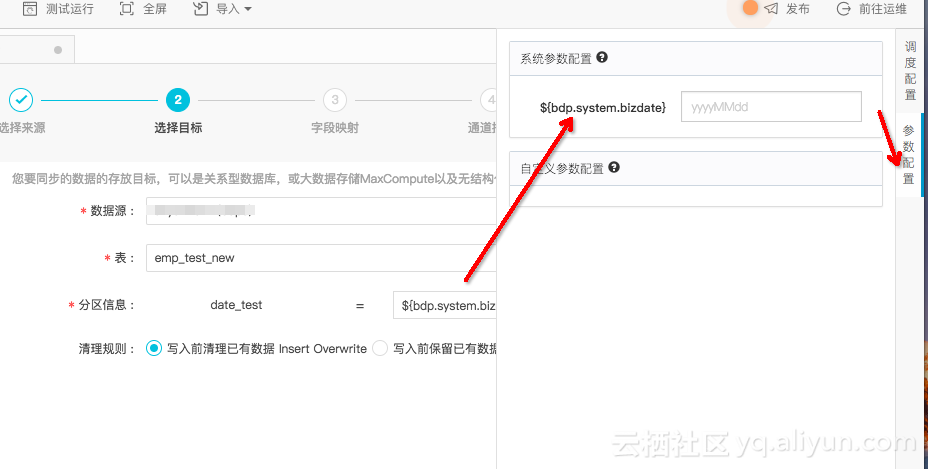
如果用户想使用当天任务运行的日期作为分区值,需要自定义这个参数,方法如图,也可以参考文档
https://help.aliyun.com/document_detail/30281.html?spm=5176.product30254.6.604.SDunjF
自定义的参数,格式非常灵活,日期是当天日期,用户可以自由选择哪一天,以及格式。
可供参考的变量参数配置方式如下:
后N年:$[add_months(yyyymmdd,12*N)]
前N年:$[add_months(yyyymmdd,-12*N)]
后N月:$[add_months(yyyymmdd,N)]
前N月:$[add_months(yyyymmdd,-N)]
后N周:$[yyyymmdd+7*N]
前N周:$[yyyymmdd-7*N]
后N天:$[yyyymmdd+N]
前N天:$[yyyymmdd-N]
后N小时:$[hh24miss+N/24]
前N小时:$[hh24miss-N/24]
后N分钟:$[hh24miss+N/24/60]
前N分钟:$[hh24miss-N/24/60]
注意:
请以中括号 [] 编辑自定义变量参数的取值计算公式,例如 key1=$[yyyy-mm-dd]。
默认情况下,自定义变量参数的计算单位为天。例如 $[hh24miss-N/24/60] 表示 (yyyymmddhh24miss-(N/24/60 * 1天)) 的计算结果,然后按 hh24miss 的格式取时分秒。
使用 add_months 的计算单位为月。例如 $[add_months(yyyymmdd,12 N)-M/24/60] 表示 (yyyymmddhh24miss-(12 N 1月))-(M/24/60 1天) 的结果,然后按 yyyymmdd 的格式取年月日。
如图,配置完成后,我们来测试运行看下,直接查看日志
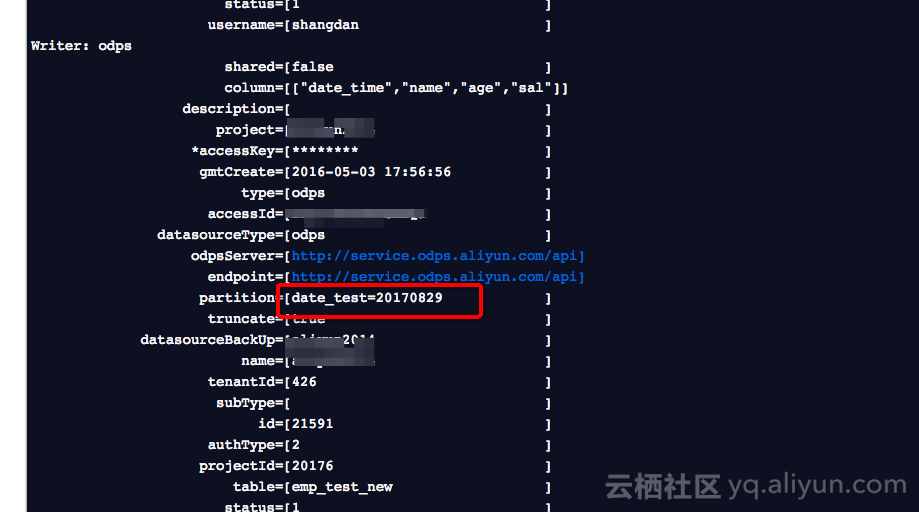
可以,看到日志中,Maxcompute(日志中打印原名ODPS)的信息中
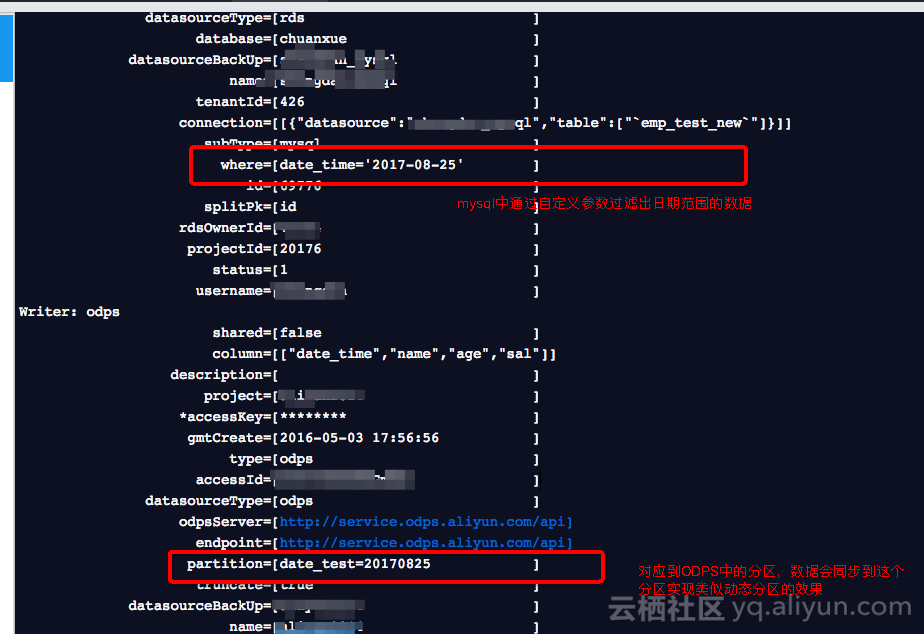
partition分区,date_test=20170829,自动替换成功。
再看下实际的数据过去了没呢
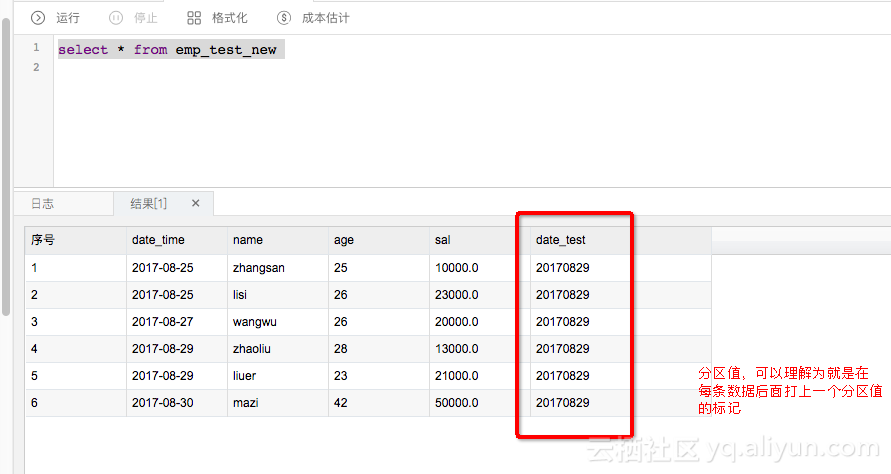
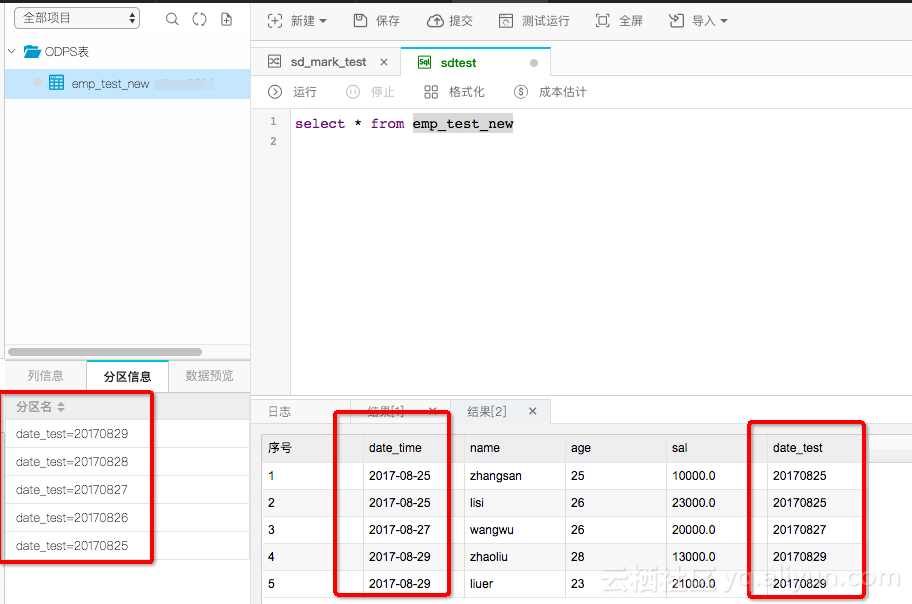
我们看到数据是过来了,成功自动创建了一个分区值。那么这个任务定时调度的时候,就会自动生成一个分区,每天自动的将RDS中的数据同步到Maxcompute中的按照日期创建的分区中。
二,如果用户的数据有很多运行日期之前的历史数据,怎么自动同步,自动分区呢。大数据开发套件-运维中心-有个补数据的功能。
首先,我们需要在RDS端把历史数据按照日期筛选出来,比如历史数据2017-08-25这天的数据,我要让他自动同步到Maxcompute的20170825的分区中。
在RDS阶段可以设置where过滤条件,如图
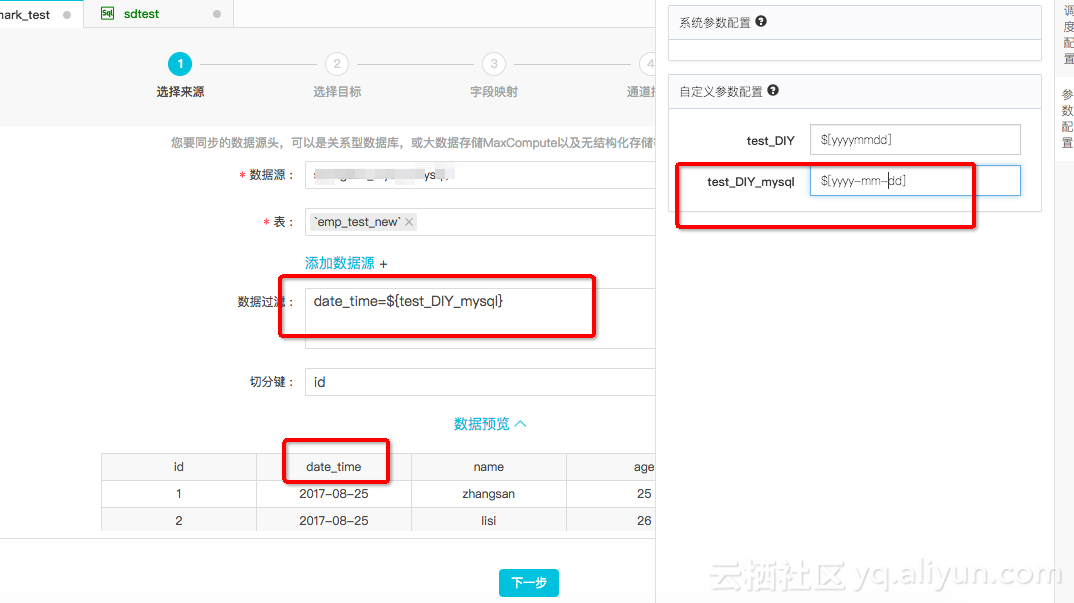
在Maxcompute页面,还是按照之前一样配置
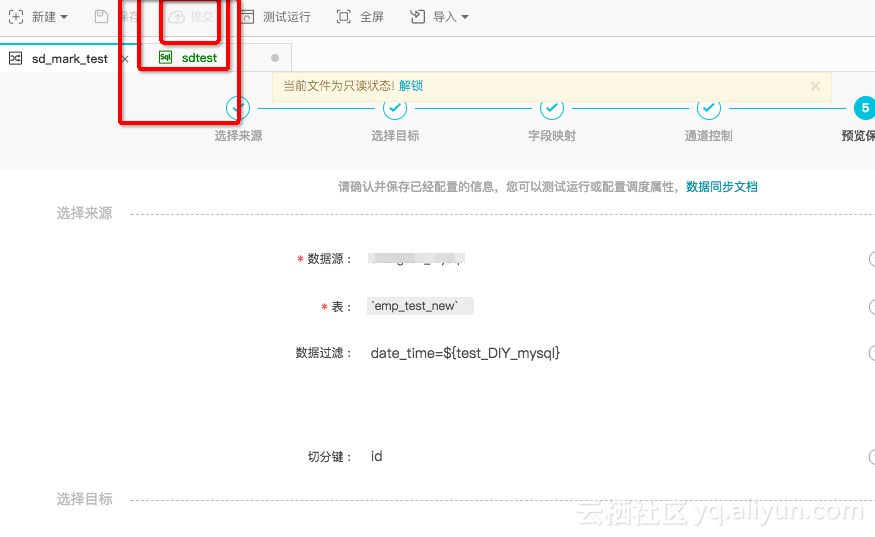
然后一定要 保存-提交。
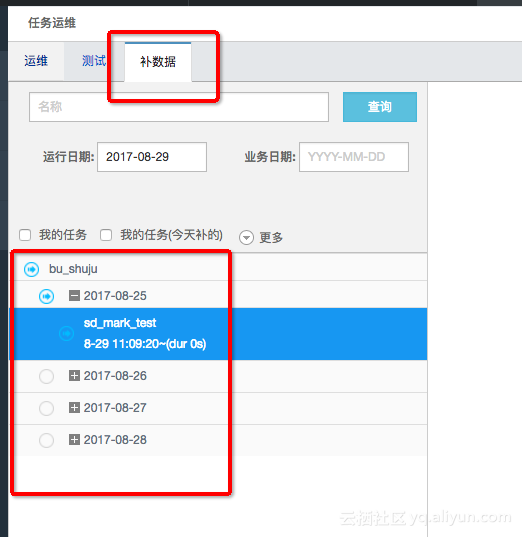
提交后到运维中心-任务管理-图形模式-补数据
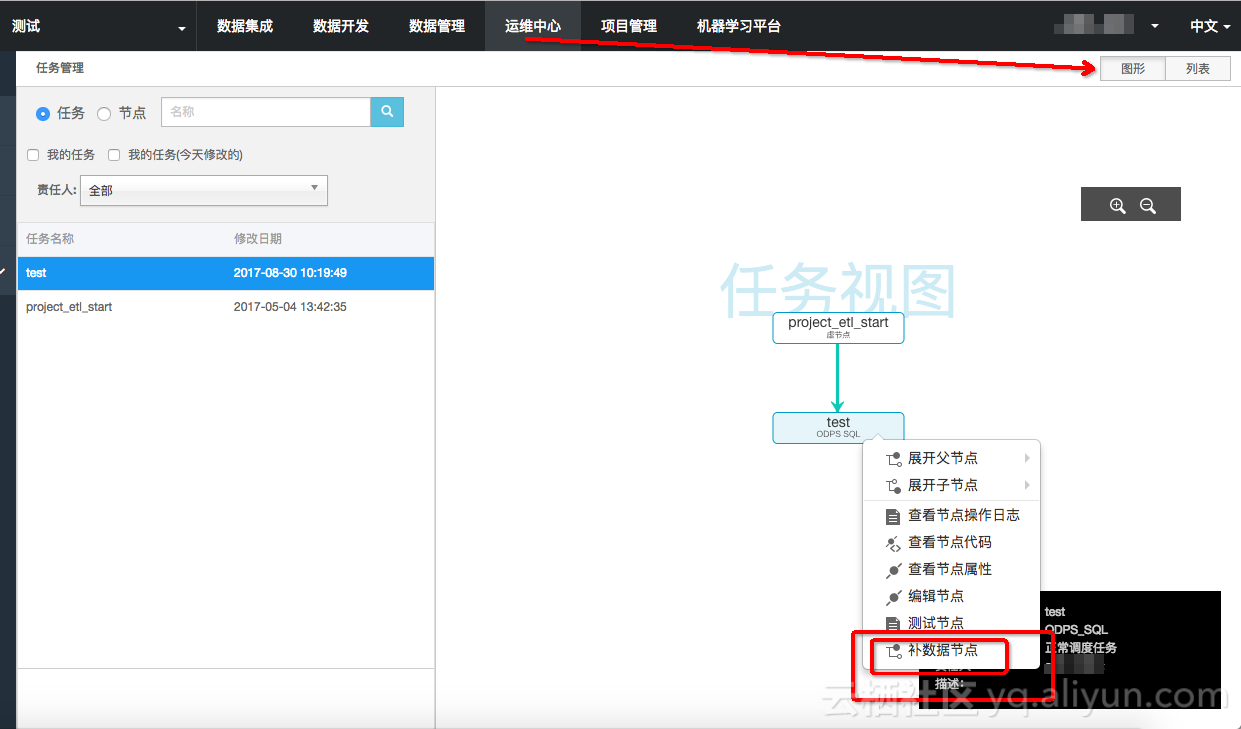
选择日期区间
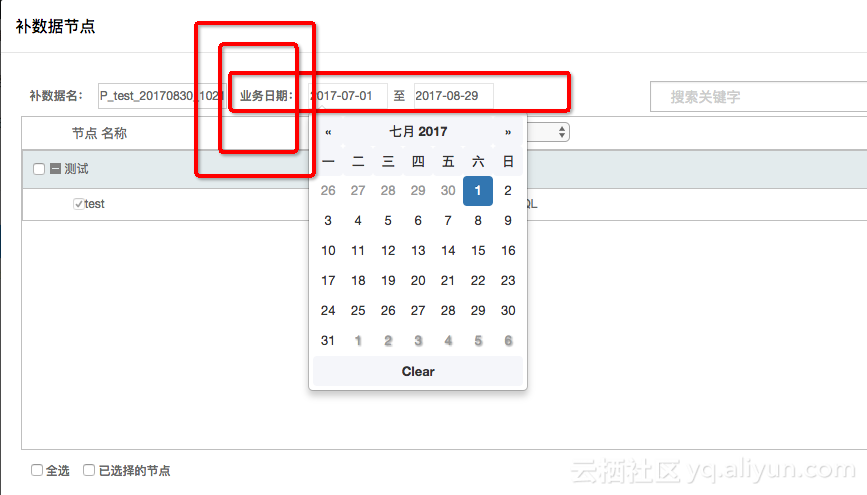
提交运行,这个时候就会同时生成多个同步的任务实例按顺序执行
看下运行的日志,可以看到运行过程对RDS数据的抽取,在Maxcompute自动创建的分区
看下运行结果,数据写入的情况,自动创建了分区,数据同步过来了。
三,如果用户数据量比较巨大,第一次全量的数据,或者并不是按照日期分区,是按照省份等分区。那么此时数据集成就不能做到自动分区了。也就是说,想按照RDS中某个字段进行hash,相同的字段值自动放到Maxcompute中以这个字段对应值的分区中。
同步本身是做不了的,是在Maxcompute中通过SQL完成,是Maxcompute的特有功能,实际上也是真正的动态分区,大家可以参考文章
。那么就需要我们先把数据全量同步到Maxcompute的一个临时表。
流程如下
1,先创建一个SQL脚本节点-用来创建临时表
drop table if exists emp_test_new_temp;
CREATE TABLE emp_test_new_temp
(date_time STRING,
name STRING,
age BIGINT,
sal DOUBLE); 2,创建同步任务的节点,就是简单的同步任务,将RDS数据全量同步到Maxcompute,不需要设置分区。
3,使用sql进行动态分区到目的表
drop table if exists emp_test_new;
--创建一个ODPS分区表(最终目的表)
CREATE TABLE emp_test_new (
date_time STRING,
name STRING,
age BIGINT,
sal DOUBLE
)
PARTITIONED BY (
date_test STRING
);
--执行动态分区sql,按照临时表的字段date_time自动分区,date_time字段中相同的数据值,会按照这个数据值自动创建一个分区值
--例如date_time中有些数据是2017-08-25,会自动在ODPS分区表中创建一个分区,date=2017-08-25
--动态分区sql如下
--可以注意到sql中select的字段多写了一个date_time,就是指定按照这个字段自动创建分区
insert overwrite table emp_test_new partition(date_test)select date_time,name,age,sal,date_time from emp_test_new_temp
--导入完成后,可以把临时表删除,节约存储成本
drop table if exists emp_test_new_temp;最后将三个节点配置成一个工作流,按顺序执行
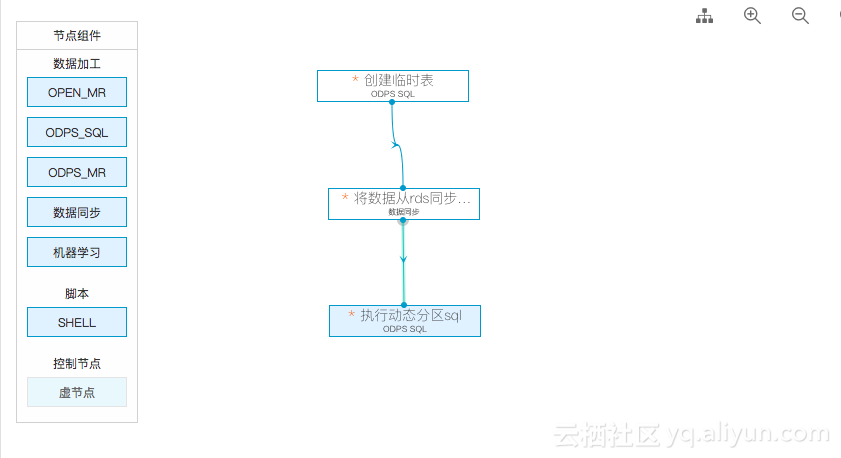
执行过程,我们重点观察,最后一个节点的动态分区过程
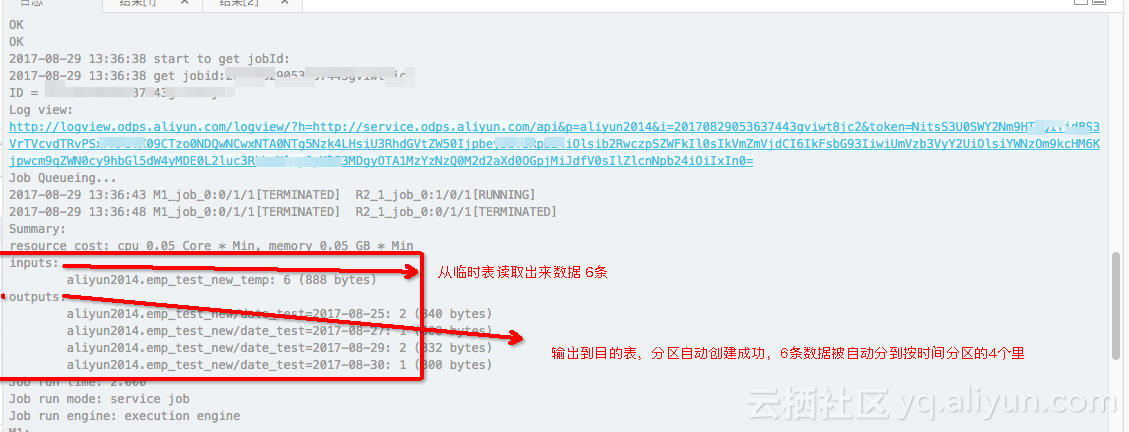
最后,看下数据
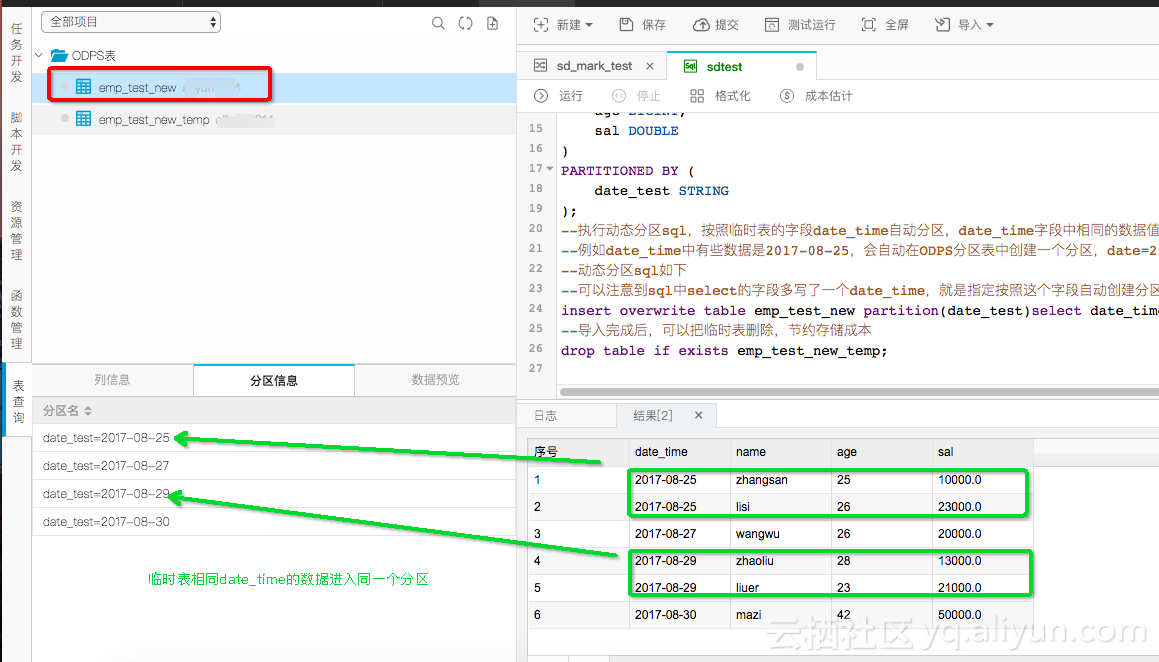
完成动态分区,自动化分区。是不是很神奇,相同的日期数据,到了同一个分区里。如果是以省份命名,也是如此,我自己都怕了。
大数据开发套件实际上可以完成绝大部分的自动化作业,尤其是数据同步迁移,调度等,界面化操作使得数据集成变得简单,不用苦逼的加班搞ETL了,你懂的。



相关推荐
阿里云提供了ECS(Elastic Compute Service)作为计算基础,ODPS(Open Data Processing Service)用于大数据处理,MaxCompute作为大数据存储和分析平台,以及RDS(Relational Database Service)等数据库服务。...
阿里云SLB-ECS-OSS-RDS与系统数据迁移是云计算领域中的一个重要概念,它涉及到阿里云的多个服务,包括SLB(负载均衡服务)、ECS(云服务器)、OSS(对象存储服务)和RDS(关系数据库服务)。本文将对这些服务进行...
Linux运维-运维课程MP4频-03阿里云-02-RDS-01阿里云RDS购买.mp4
通过上述产品矩阵,阿里云为企业构建了一套完善的大数据解决方案,涵盖了数据采集、存储、计算、分析到应用的全过程。结合Java技术,开发者可以利用阿里云提供的SDK和API,轻松实现与这些服务的集成,打造企业级的...
此外,资料还详细介绍了如何通过阿里云的解决方案实现数据治理、数据安全和数据迁移等关键功能,确保企业在享受数据带来的便利的同时,也能维护数据的安全性和合规性。总之,《阿里云大数据产品及解决方案》资料包是...
阿里巴巴大数据之路的数据技术篇主要探讨了企业大数据处理的架构及其核心组成部分,包括数据采集、计算、服务和应用四个层面。在整体架构中,数据采集层使用DataX等工具进行数据同步,数据计算层依赖MaxCompute这样...
阿里云-产品介绍+-+ECS弹性计算服务.pptx...阿里云-产品介绍+-+ RDS-v0.3.pptx 阿里云计算产品介绍V0.2.pptx 阿里云计算整体介绍.pptx 飞天开放平台编程指南20121214-Final版.pdf 飞天开放平台-大数据技术年会-4x3.pptx
6、阿里云-产品介绍+-+RDS-v0.3.pptx; 7、阿里云计算产品介绍V0.2.pptx; 8、阿里云计算整体介绍.pptx; 9、飞天开放平台-大数据技术年会-4x3.pptx; 10、飞天开放平台编程指南20121214-Final版.pdf
阿里云大数据工厂DataWorks是企业级的大数据开发和治理平台,提供数据集成、开发、管理和运维等一系列服务。在使用DataWorks进行数据同步任务时,可能会遇到各种错误,尤其是在从MaxCompute向其他数据源如RDS或...
### 阿里云计算及大数据的关键知识点 #### 一、计算模式的变革 - **历史沿革**:从20世纪60年代中期的大型机,到1981年的PC机和小型机,再到1996年的互联网数据中心,最终发展到2011年的云计算,每15年左右发生一...
大数据计算服务(MaxCompute)还提供了多种数据存储方式,包括阿里云对象存储(OSS)、阿里云关系数据库(RDS)和阿里云 NoSQL 数据库(DDS),满足不同企业的数据存储需求。 阿里云专有云Enterprise版大数据计算...
- 阿里云帮助政府将多个系统整合到云端,如交通、物价、民政、旅游、环保、房管等,为大数据应用打下基础。 - 大数据助力解决百姓民生问题,如贷款难、办事难,通过信用评估让信用成为财富。 - 云上贵州大数据...
* 初期业务架构:在该阶段,企业将其业务迁移到阿里云平台上,使用阿里云提供的云服务器(ECS)、云数据库(RDS)、专有网络(VPC)等资源。同时,企业还可以使用阿里云提供的安全服务,例如服务器安全加固、态势...
FM收音机中的RDS(Radio Data System)功能是一种先进的广播技术,允许无线电接收设备(如车载收音机)在接收音频信号的同时,接收额外的数字信息。这些信息包括电台名称、节目类型、天气预报、交通信息等,极大地...
阿里云计算与大数据技术是当前数字化转型的关键驱动力,它们共同构建了新时代的基础设施,改变了企业的运营模式和创新能力。云计算作为新基础设施的核心,以其弹性、可扩展性和高效性,正在逐步替代传统的IT架构,...
阿里云RDS数据库恢复到本地自建数据库中步骤详解 阿里云RDS数据库恢复到本地自建数据库是许多开发者和数据库管理员经常遇到的问题。由于阿里云RDS数据库的特殊性,恢复到本地自建数据库中变得非常复杂。因此,本...
标签:aws-rds-1.8.1-javadoc.jar,aws,rds,1.8.1,javadoc,jar包下载,依赖包
大数据实战Demo系统-MaxCompute数据仓库数据转换实践主要围绕如何在MaxCompute中构建数据仓库并执行数据转换,以实现高效的数据管理和分析。MaxCompute是阿里云提供的一个大规模数据处理平台,适用于大数据处理场景...
本报告“云计算全球龙头对比系列之二-坚实CBA战略,造就阿里云‘飞天’-200303”深入剖析了阿里云如何通过独特的CBA战略实现“飞天”式的快速发展,构建起强大的竞争优势。 CBA战略,即Cloud Base Architecture...
5. **数据导入与导出**:用户可以使用DataHub、ODPS Tunnel等工具进行数据导入导出,与其他阿里云服务如OSS(Object Storage Service)和RDS(Relational Database Service)集成,实现数据的无缝迁移。 6. **监控...