gxsenjoy
- жөҸи§Ҳ: 9886 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: еҢ—дә¬
-

ж–Үз« еҲҶзұ»
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 0)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2016-11 ( 1)
- 2015-11 ( 1)
- 2015-09 ( 1)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
еә”з”ЁиҮӘпјҡhttp://blog.csdn.net/qh_java/article/details/9084091
javaеҶ…еӯҳеҲҶй…ҚеҲҶжһҗ
жң¬ж–Үе°Ҷз”ұжө…е…Ҙж·ұиҜҰз»Ҷд»Ӣз»ҚJavaеҶ…еӯҳеҲҶй…Қзҡ„еҺҹзҗҶпјҢд»Ҙеё®еҠ©ж–°жүӢжӣҙиҪ»жқҫзҡ„еӯҰд№ JavaгҖӮиҝҷзұ»ж–Үз« зҪ‘дёҠжңүеҫҲеӨҡпјҢдҪҶеӨ§еӨҡжҜ”иҫғйӣ¶зўҺгҖӮжң¬ж–Үд»Һи®ӨзҹҘиҝҮзЁӢи§’еәҰеҮәеҸ‘пјҢе°ҶеёҰз»ҷиҜ»иҖ…дёҖдёӘзі»з»ҹзҡ„д»Ӣз»ҚгҖӮ
иҝӣе…ҘжӯЈйўҳеүҚйҰ–е…ҲиҰҒзҹҘйҒ“зҡ„жҳҜJavaзЁӢеәҸиҝҗиЎҢеңЁJVM(Java Virtual MachineпјҢJavaиҷҡжӢҹжңә)дёҠпјҢеҸҜд»ҘжҠҠJVMзҗҶи§ЈжҲҗJavaзЁӢеәҸе’Ңж“ҚдҪңзі»з»ҹд№Ӣй—ҙзҡ„жЎҘжўҒпјҢJVMе®һзҺ°дәҶJavaзҡ„е№іеҸ°ж— е…іжҖ§пјҢз”ұжӯӨеҸҜи§ҒJVMзҡ„йҮҚиҰҒжҖ§гҖӮжүҖд»ҘеңЁеӯҰд№ JavaеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзҡ„ж—¶еҖҷдёҖе®ҡиҰҒзүўи®°иҝҷдёҖеҲҮйғҪжҳҜеңЁJVMдёӯиҝӣиЎҢзҡ„пјҢJVMжҳҜеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзҡ„еҹәзЎҖдёҺеүҚжҸҗгҖӮ
з®ҖеҚ•йҖҡдҝ—зҡ„и®ІпјҢдёҖдёӘе®Ңж•ҙзҡ„JavaзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдјҡж¶үеҸҠд»ҘдёӢеҶ…еӯҳеҢәеҹҹпјҡ
l еҜ„еӯҳеҷЁпјҡJVMеҶ…йғЁиҷҡжӢҹеҜ„еӯҳеҷЁпјҢеӯҳеҸ–йҖҹеәҰйқһеёёеҝ«пјҢзЁӢеәҸдёҚеҸҜжҺ§еҲ¶гҖӮ
l ж ҲпјҡдҝқеӯҳеұҖйғЁеҸҳйҮҸзҡ„еҖјеҢ…жӢ¬пјҡ1.дҝқеӯҳеҹәжң¬ж•°жҚ®зұ»еһӢзҡ„еҖјпјӣ2.дҝқеӯҳеј•з”ЁеҸҳйҮҸпјҢеҚіе ҶеҢәеҜ№иұЎзҡ„еј•з”Ё(жҢҮй’Ҳ)гҖӮд№ҹеҸҜд»Ҙз”ЁжқҘдҝқеӯҳеҠ иҪҪж–№жі•ж—¶зҡ„её§гҖӮ
l е Ҷпјҡз”ЁжқҘеӯҳж”ҫеҠЁжҖҒдә§з”ҹзҡ„ж•°жҚ®пјҢжҜ”еҰӮnewеҮәжқҘзҡ„еҜ№иұЎгҖӮжіЁж„ҸеҲӣе»әеҮәжқҘзҡ„еҜ№иұЎеҸӘеҢ…еҗ«еұһдәҺеҗ„иҮӘзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢ并дёҚеҢ…жӢ¬жҲҗе‘ҳж–№жі•гҖӮеӣ дёәеҗҢдёҖдёӘзұ»зҡ„еҜ№иұЎжӢҘжңүеҗ„иҮӘзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢеӯҳеӮЁеңЁеҗ„иҮӘзҡ„е ҶдёӯпјҢдҪҶжҳҜ他们е…ұдә«иҜҘзұ»зҡ„ж–№жі•пјҢ并дёҚжҳҜжҜҸеҲӣе»әдёҖдёӘеҜ№иұЎе°ұжҠҠжҲҗе‘ҳж–№жі•еӨҚеҲ¶дёҖж¬ЎгҖӮ
l еёёйҮҸжұ пјҡJVMдёәжҜҸдёӘе·ІеҠ иҪҪзҡ„зұ»еһӢз»ҙжҠӨдёҖдёӘеёёйҮҸжұ пјҢеёёйҮҸжұ е°ұжҳҜиҝҷдёӘзұ»еһӢз”ЁеҲ°зҡ„еёёйҮҸзҡ„дёҖдёӘжңүеәҸйӣҶеҗҲгҖӮеҢ…жӢ¬зӣҙжҺҘеёёйҮҸ(еҹәжң¬зұ»еһӢпјҢString)е’ҢеҜ№е…¶д»–зұ»еһӢгҖҒж–№жі•гҖҒеӯ—ж®өзҡ„з¬ҰеҸ·еј•з”Ё(1)гҖӮжұ дёӯзҡ„ж•°жҚ®е’Ңж•°з»„дёҖж ·йҖҡиҝҮзҙўеј•и®ҝй—®гҖӮз”ұдәҺеёёйҮҸжұ еҢ…еҗ«дәҶдёҖдёӘзұ»еһӢжүҖжңүзҡ„еҜ№е…¶д»–зұ»еһӢгҖҒж–№жі•гҖҒеӯ—ж®өзҡ„з¬ҰеҸ·еј•з”ЁпјҢжүҖд»ҘеёёйҮҸжұ еңЁJavaзҡ„еҠЁжҖҒй“ҫжҺҘдёӯиө·дәҶж ёеҝғдҪңз”ЁгҖӮеёёйҮҸжұ еӯҳеңЁдәҺе ҶдёӯгҖӮ
l д»Јз Ғж®өпјҡз”ЁжқҘеӯҳж”ҫд»ҺзЎ¬зӣҳдёҠиҜ»еҸ–зҡ„жәҗзЁӢеәҸд»Јз ҒгҖӮ
l ж•°жҚ®ж®өпјҡз”ЁжқҘеӯҳж”ҫstaticдҝ®йҘ°зҡ„йқҷжҖҒжҲҗе‘ҳпјҲеңЁjavaдёӯstaticзҡ„дҪңз”Ёе°ұжҳҜиҜҙжҳҺиҜҘеҸҳйҮҸпјҢж–№жі•пјҢд»Јз Ғеқ—жҳҜеұһдәҺзұ»зҡ„иҝҳжҳҜеұһдәҺе®һдҫӢзҡ„пјүгҖӮ
дёӢйқўжҳҜеҶ…еӯҳиЎЁзӨәеӣҫпјҡ
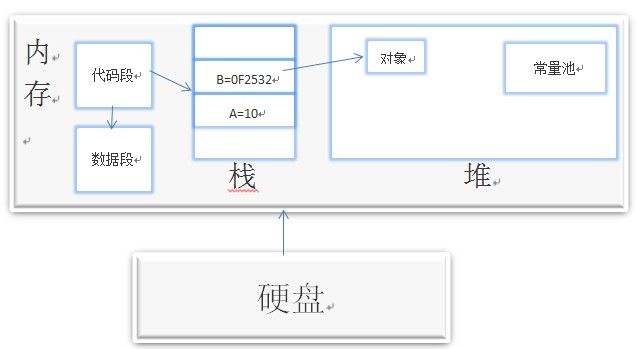
дёҠеӣҫдёӯеӨ§иҮҙжҸҸиҝ°дәҶJavaеҶ…еӯҳеҲҶй…ҚпјҢжҺҘдёӢжқҘйҖҡиҝҮе®һдҫӢиҜҰз»Ҷи®Іи§ЈJavaзЁӢеәҸжҳҜеҰӮдҪ•еңЁеҶ…еӯҳдёӯиҝҗиЎҢзҡ„пјҲжіЁпјҡд»ҘдёӢеӣҫзүҮеј•з”ЁиҮӘе°ҡеӯҰе Ӯ马士е…өиҖҒеёҲзҡ„J2SEиҜҫ件пјҢеӣҫеҸідҫ§жҳҜзЁӢеәҸд»Јз ҒпјҢе·Ұдҫ§жҳҜеҶ…еӯҳеҲҶй…ҚзӨәж„ҸеӣҫпјҢжҲ‘дјҡдёҖдёҖеҠ дёҠжіЁйҮҠпјүгҖӮ
йў„еӨҮзҹҘиҜҶпјҡ
1.дёҖдёӘJavaж–Ү件пјҢеҸӘиҰҒжңүmainе…ҘеҸЈж–№жі•пјҢжҲ‘们е°ұи®ӨдёәиҝҷжҳҜдёҖдёӘJavaзЁӢеәҸпјҢеҸҜд»ҘеҚ•зӢ¬зј–иҜ‘иҝҗиЎҢгҖӮ
2.ж— и®әжҳҜжҷ®йҖҡзұ»еһӢзҡ„еҸҳйҮҸиҝҳжҳҜеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸ(дҝ—з§°е®һдҫӢ)пјҢйғҪеҸҜд»ҘдҪңдёәеұҖйғЁеҸҳйҮҸпјҢ他们йғҪеҸҜд»ҘеҮәзҺ°еңЁж ҲдёӯгҖӮеҸӘдёҚиҝҮжҷ®йҖҡзұ»еһӢзҡ„еҸҳйҮҸеңЁж ҲдёӯзӣҙжҺҘдҝқеӯҳе®ғжүҖеҜ№еә”зҡ„еҖјпјҢиҖҢеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸдҝқеӯҳзҡ„жҳҜдёҖдёӘжҢҮеҗ‘е ҶеҢәзҡ„жҢҮй’ҲпјҢйҖҡиҝҮиҝҷдёӘжҢҮй’ҲпјҢе°ұеҸҜд»ҘжүҫеҲ°иҝҷдёӘе®һдҫӢеңЁе ҶеҢәеҜ№еә”зҡ„еҜ№иұЎгҖӮеӣ жӯӨпјҢжҷ®йҖҡзұ»еһӢеҸҳйҮҸеҸӘеңЁж ҲеҢәеҚ з”ЁдёҖеқ—еҶ…еӯҳпјҢиҖҢеј•з”Ёзұ»еһӢеҸҳйҮҸиҰҒеңЁж ҲеҢәе’Ңе ҶеҢәеҗ„еҚ дёҖеқ—еҶ…еӯҳгҖӮ
зӨәдҫӢпјҡ

1.JVMиҮӘеҠЁеҜ»жүҫmainж–№жі•пјҢжү§иЎҢ第дёҖеҸҘд»Јз ҒпјҢеҲӣе»әдёҖдёӘTestзұ»зҡ„е®һдҫӢпјҢеңЁж ҲдёӯеҲҶй…ҚдёҖеқ—еҶ…еӯҳпјҢеӯҳж”ҫдёҖдёӘжҢҮеҗ‘е ҶеҢәеҜ№иұЎзҡ„еј•з”ЁеҸҳйҮҸпјҲжҢҮй’Ҳ110925пјүпјҢjavaдёӯзҡ„еј•з”ЁеҸҳйҮҸе°ұжҳҜCиҜӯиЁҖдёӯжҢҮй’Ҳзҡ„дёҖдёӘеҢ…иЈ…пјҢжүҖд»Ҙеј•з”ЁеҸҳйҮҸдёӯеӯҳж”ҫзҡ„иҝҳжҳҜе ҶеҶ…еӯҳдёӯеҜ№иұЎзҡ„ең°еқҖгҖӮ
2.еҲӣе»әдёҖдёӘintеһӢзҡ„еҸҳйҮҸdateпјҢз”ұдәҺжҳҜеҹәжң¬зұ»еһӢпјҢзӣҙжҺҘеңЁж Ҳдёӯеӯҳж”ҫdateеҜ№еә”зҡ„еҖј9гҖӮ
3.еҲӣе»әдёӨдёӘBirthDateзұ»зҡ„е®һдҫӢd1гҖҒd2пјҢеңЁж ҲдёӯеҲҶеҲ«еӯҳж”ҫдәҶеҜ№еә”зҡ„жҢҮй’ҲжҢҮеҗ‘еҗ„иҮӘзҡ„еҜ№иұЎгҖӮ他们еңЁе®һдҫӢеҢ–ж—¶и°ғз”ЁдәҶжңүеҸӮж•°зҡ„жһ„йҖ ж–№жі•пјҢеӣ жӯӨеҜ№иұЎдёӯжңүиҮӘе®ҡд№үеҲқе§ӢеҖјгҖӮ

и°ғз”ЁtestеҜ№иұЎзҡ„change1ж–№жі•пјҢ并且д»ҘdateдёәеҸӮж•°гҖӮJVMиҜ»еҲ°иҝҷж®өд»Јз Ғж—¶пјҢжЈҖжөӢеҲ°iжҳҜеұҖйғЁеҸҳйҮҸпјҢеӣ жӯӨдјҡжҠҠiж”ҫеңЁж ҲдёӯпјҢ并且жҠҠdateзҡ„еҖјиөӢз»ҷiгҖӮ
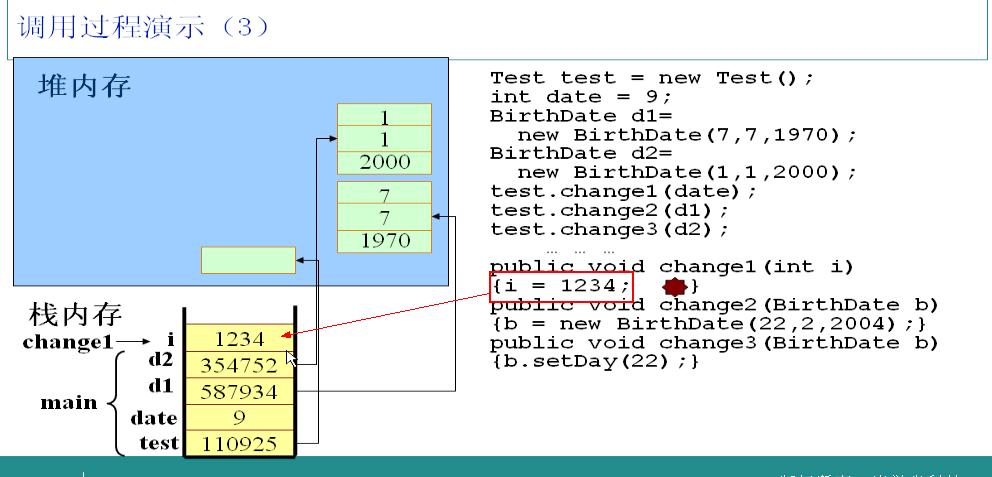
жҠҠ1234иөӢз»ҷiгҖӮеҫҲз®ҖеҚ•зҡ„дёҖжӯҘгҖӮ

change1ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеҸҳйҮҸiжүҖеҚ з”Ёзҡ„ж Ҳз©әй—ҙгҖӮ
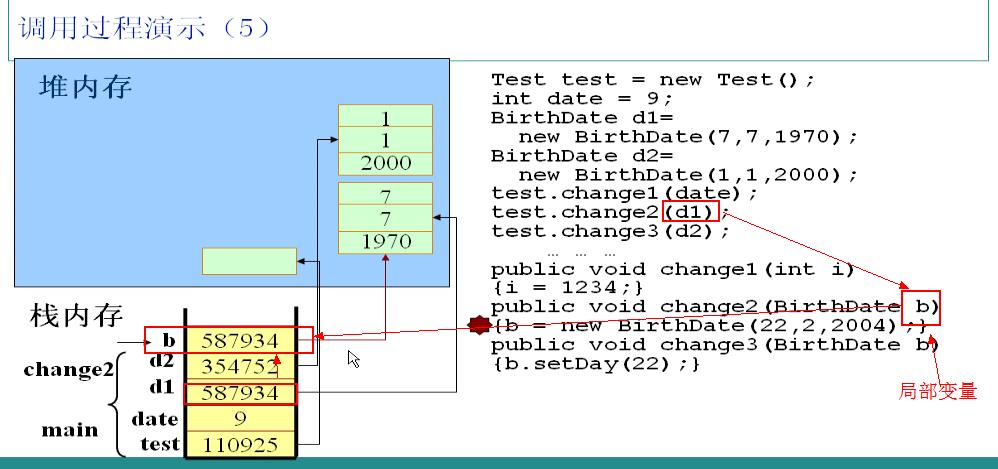
и°ғз”ЁtestеҜ№иұЎзҡ„change2ж–№жі•пјҢд»Ҙе®һдҫӢd1дёәеҸӮж•°гҖӮJVMжЈҖжөӢеҲ°change2ж–№жі•дёӯзҡ„bеҸӮж•°дёәеұҖйғЁеҸҳйҮҸпјҢз«ӢеҚіеҠ е…ҘеҲ°ж ҲдёӯпјҢз”ұдәҺжҳҜеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸпјҢжүҖд»Ҙbдёӯдҝқеӯҳзҡ„жҳҜd1дёӯзҡ„жҢҮй’ҲпјҢжӯӨж—¶bе’Ңd1жҢҮеҗ‘еҗҢдёҖдёӘе Ҷдёӯзҡ„еҜ№иұЎгҖӮеңЁbе’Ңd1д№Ӣй—ҙдј йҖ’жҳҜжҢҮй’ҲгҖӮ

change2ж–№жі•дёӯеҸҲе®һдҫӢеҢ–дәҶдёҖдёӘBirthDateеҜ№иұЎпјҢ并且иөӢз»ҷbгҖӮеңЁеҶ…йғЁжү§иЎҢиҝҮзЁӢжҳҜпјҡеңЁе ҶеҢәnewдәҶдёҖдёӘеҜ№иұЎпјҢ并且жҠҠиҜҘеҜ№иұЎзҡ„жҢҮй’ҲдҝқеӯҳеңЁж Ҳдёӯзҡ„bеҜ№еә”з©әй—ҙпјҢжӯӨж—¶е®һдҫӢbдёҚеҶҚжҢҮеҗ‘е®һдҫӢd1жүҖжҢҮеҗ‘зҡ„еҜ№иұЎпјҢдҪҶжҳҜе®һдҫӢd1жүҖжҢҮеҗ‘зҡ„еҜ№иұЎе№¶ж— еҸҳеҢ–пјҢиҝҷж ·ж— жі•еҜ№d1йҖ жҲҗд»»дҪ•еҪұе“ҚгҖӮ

change2ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеј•з”ЁеҸҳйҮҸbжүҖеҚ зҡ„ж Ҳз©әй—ҙпјҢжіЁж„ҸеҸӘжҳҜйҮҠж”ҫдәҶж Ҳз©әй—ҙпјҢе Ҷз©әй—ҙиҰҒзӯүеҫ…иҮӘеҠЁеӣһ收гҖӮ
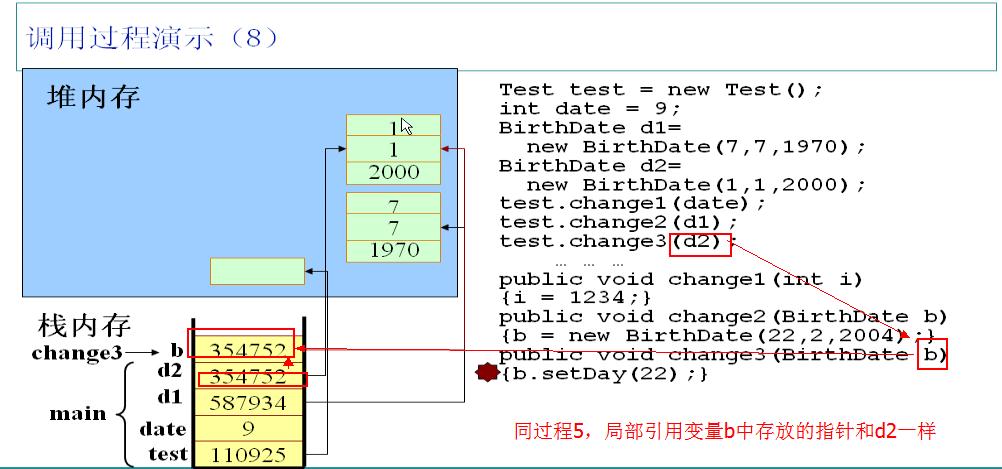
и°ғз”Ёtestе®һдҫӢзҡ„change3ж–№жі•пјҢд»Ҙе®һдҫӢd2дёәеҸӮж•°гҖӮеҗҢзҗҶпјҢJVMдјҡеңЁж ҲдёӯдёәеұҖйғЁеј•з”ЁеҸҳйҮҸbеҲҶй…Қз©әй—ҙпјҢ并且жҠҠd2дёӯзҡ„жҢҮй’Ҳеӯҳж”ҫеңЁbдёӯпјҢжӯӨж—¶d2е’ҢbжҢҮеҗ‘еҗҢдёҖдёӘеҜ№иұЎгҖӮеҶҚи°ғз”Ёе®һдҫӢbзҡ„setDayж–№жі•пјҢе…¶е®һе°ұжҳҜи°ғз”Ёd2жҢҮеҗ‘зҡ„еҜ№иұЎзҡ„setDayж–№жі•гҖӮ

и°ғз”Ёе®һдҫӢbзҡ„setDayж–№жі•дјҡеҪұе“Қd2пјҢеӣ дёәдәҢиҖ…жҢҮеҗ‘зҡ„жҳҜеҗҢдёҖдёӘеҜ№иұЎгҖӮ

change3ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеј•з”ЁеҸҳйҮҸbгҖӮ
д»ҘдёҠе°ұжҳҜJavaзЁӢеәҸиҝҗиЎҢж—¶еҶ…еӯҳеҲҶй…Қзҡ„еӨ§иҮҙжғ…еҶөгҖӮе…¶е®һд№ҹжІЎд»Җд№ҲпјҢжҺҢжҸЎдәҶжҖқжғіе°ұеҫҲз®ҖеҚ•дәҶгҖӮж— йқһе°ұжҳҜдёӨз§Қзұ»еһӢзҡ„еҸҳйҮҸпјҡеҹәжң¬зұ»еһӢе’Ңеј•з”Ёзұ»еһӢгҖӮдәҢиҖ…дҪңдёәеұҖйғЁеҸҳйҮҸпјҢйғҪж”ҫеңЁж ҲдёӯпјҢеҹәжң¬зұ»еһӢзӣҙжҺҘеңЁж ҲдёӯдҝқеӯҳеҖјпјҢеј•з”Ёзұ»еһӢеҸӘдҝқеӯҳдёҖдёӘжҢҮеҗ‘е ҶеҢәзҡ„жҢҮй’ҲпјҢзңҹжӯЈзҡ„еҜ№иұЎеңЁе ҶйҮҢгҖӮдҪңдёәеҸӮж•°ж—¶еҹәжң¬зұ»еһӢе°ұзӣҙжҺҘдј еҖјпјҢеј•з”Ёзұ»еһӢдј жҢҮй’ҲпјҲеңЁjavaдёӯеҸӘжңүеҖјдј йҖ’жІЎжңүең°еқҖдј йҖ’дҪҶжҳҜеј•з”ЁеҸҳйҮҸдёӯеӯҳж”ҫзҡ„жҳҜе ҶдёӯеҜ№иұЎзҡ„ең°еқҖпјҢжүҖд»Ҙд№ҹеҸҜд»ҘзҗҶи§Јдёәең°еқҖдј йҖ’пјүгҖӮ
е°Ҹз»“пјҡ
1.еҲҶжё…д»Җд№ҲжҳҜеҜ№иұЎеј•з”ЁеҸҳйҮҸпјҲеј•з”ЁеҸҳйҮҸпјүд»Җд№ҲжҳҜеҜ№иұЎгҖӮClass a= new Class();жӯӨж—¶aеҸ«еҜ№иұЎеј•з”ЁеҸҳйҮҸпјҢиҖҢдёҚиғҪиҜҙaжҳҜеҜ№иұЎгҖӮеј•з”ЁеҸҳйҮҸеңЁж ҲдёӯпјҢеҜ№иұЎеңЁе ҶдёӯпјҢж“ҚдҪңеј•з”ЁеҸҳйҮҸе®һйҷ…дёҠжҳҜйҖҡиҝҮеј•з”Ёй—ҙжҺҘж“ҚдҪңеҜ№иұЎгҖӮеӨҡдёӘеј•з”ЁеҸҳйҮҸеҸҜд»Ҙеј•з”ЁеҲ°еҗҢдёҖдёӘеҜ№иұЎгҖӮ
2.ж Ҳдёӯзҡ„ж•°жҚ®е’Ңе Ҷдёӯзҡ„ж•°жҚ®й”ҖжҜҒ并дёҚжҳҜеҗҢжӯҘзҡ„гҖӮж–№жі•дёҖж—Ұз»“жқҹпјҢж Ҳдёӯзҡ„еұҖйғЁеҸҳйҮҸз«ӢеҚій”ҖжҜҒпјҢдҪҶжҳҜе ҶдёӯеҜ№иұЎдёҚдёҖе®ҡй”ҖжҜҒгҖӮеӣ дёәеҸҜиғҪжңүе…¶д»–еҸҳйҮҸд№ҹжҢҮеҗ‘дәҶиҝҷдёӘеҜ№иұЎпјҢзӣҙеҲ°ж ҲдёӯжІЎжңүеҸҳйҮҸжҢҮеҗ‘е Ҷдёӯзҡ„еҜ№иұЎж—¶пјҢе®ғжүҚй”ҖжҜҒпјҢиҖҢдё”иҝҳдёҚжҳҜ马дёҠй”ҖжҜҒпјҢиҰҒзӯүеһғеңҫеӣһ收жү«жҸҸж—¶жүҚеҸҜд»Ҙиў«й”ҖжҜҒгҖӮ
3.жҜҸдёӘж–№жі•жү§иЎҢзҡ„ж—¶еҖҷйғҪдјҡе»әз«ӢиҮӘе·ұзҡ„ж ҲеҢәпјҢеңЁж–№жі•дёӯе®ҡд№үзҡ„еұҖйғЁеҸҳйҮҸпјҲеҸӮж•°пјҢж–№жі•дёӯе®ҡд№үзҡ„еҸҳйҮҸпјүйғҪеңЁж ҲеҢәдёӯеӯҳж”ҫеҪ“ж–№жі•з»“жқҹж—¶иҝҷдәӣеұҖйғЁеҸҳйҮҸд№ҹе°ұз»“жқҹдәҶпјҢдҪҶжҳҜе ҶеҶ…еӯҳдёӯзҡ„еҜ№иұЎдёҚдјҡйҡҸзқҖж–№жі•зҡ„з»“жқҹиҖҢй”ҖжҜҒиҖҢжҳҜеҲӨж–ӯиҝҳжңүжІЎжңүеј•з”ЁеҸҳйҮҸеј•з”ЁеҲ°иҝҷдёӘеҜ№иұЎеҰӮжһңжңүзҡ„иҜқе°ұжҳҜиҜҙиҝҷдёӘеҜ№иұЎеҸҜиҫҫжүҖд»ҘдёҚдјҡиҪ»жҳ“зҡ„иў«GCеӣһ收пјҢеҰӮжһңиҝҷдёӘеҜ№иұЎжІЎжңүиў«еј•з”ЁеҰӮжһңиҝҷж—¶еһғеңҫеӣһ收系з»ҹејҖе§Ӣеӣһ收дҪҶеҸ‘зҺ°иҝҷдёӘеҜ№иұЎжІЎжңүеј•з”Ёзҡ„иҜқе°ұдјҡи°ғз”ЁfinalizeпјҲпјүж–№жі•жқҘеҲӨж–ӯиҝҷдёӘеҜ№иұЎжҳҜеҗҰеҸҜд»ҘеҶҚж¬ЎеҸҜиҫҫеҰӮжһңеҸҜд»Ҙзҡ„дёҚдјҡеӣһ收дҪҶжҳҜдёҚиҝҮдёҚеҸҜиҫҫзҡ„иҜқеҸҜиғҪдјҡиў«еӣһ收пјҲдёҚжҳҜдёҖе®ҡдјҡиў«еӣһ收иҝҷйҮҢжҳҜдёҚдёҖе®ҡдјҡеӣһ收еӣ дёәиҝҷйҮҢиҝҳжңүеҜ№иұЎзҡ„еј•з”Ёзұ»еһӢеҰӮпјҡејәеј•з”ЁпјҢиҪҜеј•з”ЁпјҲsoftReferenceжқҘе®һзҺ°пјүпјҢејұеј•з”ЁпјҲWeakReferenceжқҘе®һзҺ°пјүзӯүеӣ зҙ жңүе…іпјҢиҝҳиҰҒиҖғиҷ‘е…¶д»–зҡ„еӣ зҙ дёҚеңЁиҝҷйҮҢдёҖдёҖиҜҙжҳҺпјүеҰӮжһңеҸҜиҫҫзҡ„иҜқиҝҳжҳҜдёҚдјҡеӣһ收зҡ„гҖӮ
4.д»ҘдёҠзҡ„ж ҲгҖҒе ҶгҖҒд»Јз Ғж®өгҖҒж•°жҚ®ж®өзӯүзӯүйғҪжҳҜзӣёеҜ№дәҺеә”з”ЁзЁӢеәҸиҖҢиЁҖзҡ„гҖӮжҜҸдёҖдёӘеә”з”ЁзЁӢеәҸйғҪеҜ№еә”е”ҜдёҖзҡ„дёҖдёӘJVMе®һдҫӢпјҢжҜҸдёҖдёӘJVMе®һдҫӢйғҪжңүиҮӘе·ұзҡ„еҶ…еӯҳеҢәеҹҹпјҢдә’дёҚеҪұе“ҚпјҢи°ғз”ЁJVMд№ҹе°ұжҳҜжҝҖжҙ»дёҖдёӘиҝӣзЁӢгҖӮ并且иҝҷдәӣеҶ…еӯҳеҢәеҹҹжҳҜжүҖжңүзәҝзЁӢе…ұдә«зҡ„гҖӮиҝҷйҮҢжҸҗеҲ°зҡ„ж Ҳе’Ңе ҶйғҪжҳҜж•ҙдҪ“дёҠзҡ„жҰӮеҝөпјҢиҝҷдәӣе Ҷж ҲиҝҳеҸҜд»Ҙз»ҶеҲҶгҖӮ
5.зұ»дёӯе®ҡд№үзҡ„е®һдҫӢжҲҗе‘ҳеҸҳйҮҸеңЁдёҚеҗҢеҜ№иұЎдёӯеҗ„дёҚзӣёеҗҢпјҢйғҪжңүиҮӘе·ұзҡ„еӯҳеӮЁз©әй—ҙ(жҲҗе‘ҳеҸҳйҮҸеңЁе Ҷдёӯзҡ„еҜ№иұЎдёӯ)гҖӮиҖҢзұ»дёӯе®ҡд№үзҡ„ж–№жі•еҚҙжҳҜиҜҘзұ»зҡ„жүҖжңүеҜ№иұЎе…ұдә«зҡ„пјҢеҸӘжңүдёҖеҘ—пјҢеҜ№иұЎдҪҝз”Ёж–№жі•зҡ„ж—¶еҖҷж–№жі•жүҚиў«еҺӢе…Ҙж ҲпјҢж–№жі•дёҚдҪҝз”ЁеҲҷдёҚеҚ з”ЁеҶ…еӯҳгҖӮ
д»ҘдёҠеҲҶжһҗеҸӘж¶үеҸҠдәҶж Ҳе’Ңе ҶпјҢиҝҳжңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„еҶ…еӯҳеҢәеҹҹпјҡеёёйҮҸжұ пјҢиҝҷдёӘең°ж–№еҫҖеҫҖеҮәзҺ°дёҖдәӣиҺ«еҗҚе…¶еҰҷзҡ„й—®йўҳгҖӮеёёйҮҸжұ жҳҜе№Іеҳӣзҡ„дёҠиҫ№е·Із»ҸиҜҙжҳҺдәҶпјҢд№ҹжІЎеҝ…иҰҒзҗҶи§ЈеӨҡд№Ҳж·ұеҲ»пјҢеҸӘиҰҒи®°дҪҸе®ғз»ҙжҠӨдәҶдёҖдёӘе·ІеҠ иҪҪзұ»зҡ„еёёйҮҸе°ұеҸҜд»ҘдәҶгҖӮжҺҘдёӢжқҘз»“еҗҲдёҖдәӣдҫӢеӯҗиҜҙжҳҺеёёйҮҸжұ зҡ„зү№жҖ§гҖӮ
йў„еӨҮзҹҘиҜҶпјҡ
еҹәжң¬зұ»еһӢе’Ңеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»гҖӮеҹәжң¬зұ»еһӢжңүпјҡbyteгҖҒshortгҖҒcharгҖҒintгҖҒlongгҖҒbooleanгҖӮеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»еҲҶеҲ«жҳҜпјҡByteгҖҒShortгҖҒCharacterгҖҒIntegerгҖҒLongгҖҒBooleanгҖӮжіЁж„ҸеҢәеҲҶеӨ§е°ҸеҶҷгҖӮдәҢиҖ…зҡ„еҢәеҲ«жҳҜпјҡеҹәжң¬зұ»еһӢдҪ“зҺ°еңЁзЁӢеәҸдёӯжҳҜжҷ®йҖҡеҸҳйҮҸпјҢеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»жҳҜзұ»пјҢдҪ“зҺ°еңЁзЁӢеәҸдёӯжҳҜеј•з”ЁеҸҳйҮҸгҖӮеӣ жӯӨдәҢиҖ…еңЁеҶ…еӯҳдёӯзҡ„еӯҳеӮЁдҪҚзҪ®дёҚеҗҢпјҡеҹәжң¬зұ»еһӢеӯҳеӮЁеңЁж ҲдёӯпјҢиҖҢеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»еӯҳеӮЁеңЁе ҶдёӯгҖӮдёҠиҫ№жҸҗеҲ°зҡ„иҝҷдәӣеҢ…иЈ…зұ»йғҪе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢиҖҢдёӨз§Қжө®зӮ№ж•°зұ»еһӢзҡ„еҢ…иЈ…зұ»еҲҷжІЎжңүе®һзҺ°гҖӮеҸҰеӨ–пјҢStringзұ»еһӢд№ҹе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜгҖӮ
е®һдҫӢпјҡ
з»“жһңеҲҶжһҗпјҡ
1.iе’Ңi0еқҮжҳҜжҷ®йҖҡзұ»еһӢ(int)зҡ„еҸҳйҮҸпјҢжүҖд»Ҙж•°жҚ®зӣҙжҺҘеӯҳеӮЁеңЁж ҲдёӯпјҢиҖҢж ҲжңүдёҖдёӘеҫҲйҮҚиҰҒзҡ„зү№жҖ§пјҡж Ҳдёӯзҡ„ж•°жҚ®еҸҜд»Ҙе…ұдә«гҖӮеҪ“жҲ‘们е®ҡд№үдәҶint i = 40;пјҢеҶҚе®ҡд№үint i0 = 40;иҝҷж—¶еҖҷдјҡиҮӘеҠЁжЈҖжҹҘж ҲдёӯжҳҜеҗҰжңү40иҝҷдёӘж•°жҚ®пјҢеҰӮжһңжңүпјҢi0дјҡзӣҙжҺҘжҢҮеҗ‘iзҡ„40пјҢдёҚдјҡеҶҚж·»еҠ дёҖдёӘж–°зҡ„40гҖӮ
2.i1е’Ңi2еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәIntegerжҳҜеҢ…иЈ…зұ»гҖӮз”ұдәҺIntegerеҢ…иЈ…зұ»е®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢеӣ жӯӨi1гҖҒi2зҡ„40еқҮжҳҜд»ҺеёёйҮҸжұ дёӯиҺ·еҸ–зҡ„пјҢеқҮжҢҮеҗ‘еҗҢдёҖдёӘең°еқҖпјҢеӣ жӯӨi1==12гҖӮ
3.еҫҲжҳҺжҳҫиҝҷжҳҜдёҖдёӘеҠ жі•иҝҗз®—пјҢJavaзҡ„ж•°еӯҰиҝҗз®—йғҪжҳҜеңЁж ҲдёӯиҝӣиЎҢзҡ„пјҢJavaдјҡиҮӘеҠЁеҜ№i1гҖҒi2иҝӣиЎҢжӢҶз®ұж“ҚдҪңиҪ¬еҢ–жҲҗж•ҙеһӢпјҢеӣ жӯӨi1еңЁж•°еҖјдёҠзӯүдәҺi2+i3гҖӮ
4.i4е’Ңi5еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәIntegerжҳҜеҢ…иЈ…зұ»гҖӮдҪҶжҳҜз”ұдәҺ他们еҗ„иҮӘйғҪжҳҜnewеҮәжқҘзҡ„пјҢеӣ жӯӨдёҚеҶҚд»ҺеёёйҮҸжұ еҜ»жүҫж•°жҚ®пјҢиҖҢжҳҜд»Һе Ҷдёӯеҗ„иҮӘnewдёҖдёӘеҜ№иұЎпјҢ然еҗҺеҗ„иҮӘдҝқеӯҳжҢҮеҗ‘еҜ№иұЎзҡ„жҢҮй’ҲпјҢжүҖд»Ҙi4е’Ңi5дёҚзӣёзӯүпјҢеӣ дёә他们жүҖеӯҳең°еқҖдёҚеҗҢпјҢжүҖеј•з”ЁеҲ°зҡ„еҜ№иұЎдёҚеҗҢгҖӮ
5.иҝҷд№ҹжҳҜдёҖдёӘеҠ жі•иҝҗз®—пјҢе’Ң3еҗҢзҗҶгҖӮ
6.d1е’Ңd2еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәDoubleжҳҜеҢ…иЈ…зұ»гҖӮдҪҶDoubleеҢ…иЈ…зұ»жІЎжңүе®һзҺ°еёёйҮҸжұ жҠҖжңҜпјҢеӣ жӯӨDoubled1=1.0;зӣёеҪ“дәҺDouble d1=new Double(1.0);пјҢжҳҜд»Һе ҶnewдёҖдёӘеҜ№иұЎпјҢd2еҗҢзҗҶгҖӮеӣ жӯӨd1е’Ңd2еӯҳж”ҫзҡ„жҢҮй’ҲдёҚеҗҢпјҢжҢҮеҗ‘зҡ„еҜ№иұЎдёҚеҗҢпјҢжүҖд»ҘдёҚзӣёзӯүгҖӮ
е°Ҹз»“пјҡ
1.д»ҘдёҠжҸҗеҲ°зҡ„еҮ з§Қеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»еқҮе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢдҪҶ他们з»ҙжҠӨзҡ„еёёйҮҸд»…д»…жҳҜгҖҗ-128иҮі127гҖ‘иҝҷдёӘиҢғеӣҙеҶ…зҡ„еёёйҮҸпјҢеҰӮжһңеёёйҮҸеҖји¶…иҝҮиҝҷдёӘиҢғеӣҙпјҢе°ұдјҡд»Һе ҶдёӯеҲӣе»әеҜ№иұЎпјҢдёҚеҶҚд»ҺеёёйҮҸжұ дёӯеҸ–гҖӮжҜ”еҰӮпјҢжҠҠдёҠиҫ№дҫӢеӯҗж”№жҲҗInteger i1 = 400; Integer i2 = 400;пјҢеҫҲжҳҺжҳҫи¶…иҝҮдәҶ127пјҢж— жі•д»ҺеёёйҮҸжұ иҺ·еҸ–еёёйҮҸпјҢе°ұиҰҒд»Һе Ҷдёӯnewж–°зҡ„IntegerеҜ№иұЎпјҢиҝҷж—¶i1е’Ңi2е°ұдёҚзӣёзӯүдәҶгҖӮ
2.Stringзұ»еһӢд№ҹе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢдҪҶжҳҜзЁҚеҫ®жңүзӮ№дёҚеҗҢгҖӮStringеһӢжҳҜе…ҲжЈҖжөӢеёёйҮҸжұ дёӯжңүжІЎжңүеҜ№еә”еӯ—з¬ҰдёІпјҢеҰӮжһңжңүпјҢеҲҷеҸ–еҮәжқҘпјӣеҰӮжһңжІЎжңүпјҢеҲҷжҠҠеҪ“еүҚзҡ„ж·»еҠ иҝӣеҺ»гҖӮ
д»ҘдёҠзҹҘиҜҶзӮ№еҰӮжңүдёҚжҳҺпјҢжҲ–й”ҷиҜҜиҝҳжңӣеӨ§е®¶жү№иҜ„жҢҮжӯЈпјҢд№ҹеёҢжңӣд»ҘдёҠзҹҘиҜҶзӮ№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҗҢж—¶еёҢжңӣеӨ§е®¶еёёжқҘе…үйЎҫпјҒ
javaеҶ…еӯҳеҲҶй…ҚеҲҶжһҗ
жң¬ж–Үе°Ҷз”ұжө…е…Ҙж·ұиҜҰз»Ҷд»Ӣз»ҚJavaеҶ…еӯҳеҲҶй…Қзҡ„еҺҹзҗҶпјҢд»Ҙеё®еҠ©ж–°жүӢжӣҙиҪ»жқҫзҡ„еӯҰд№ JavaгҖӮиҝҷзұ»ж–Үз« зҪ‘дёҠжңүеҫҲеӨҡпјҢдҪҶеӨ§еӨҡжҜ”иҫғйӣ¶зўҺгҖӮжң¬ж–Үд»Һи®ӨзҹҘиҝҮзЁӢи§’еәҰеҮәеҸ‘пјҢе°ҶеёҰз»ҷиҜ»иҖ…дёҖдёӘзі»з»ҹзҡ„д»Ӣз»ҚгҖӮ
иҝӣе…ҘжӯЈйўҳеүҚйҰ–е…ҲиҰҒзҹҘйҒ“зҡ„жҳҜJavaзЁӢеәҸиҝҗиЎҢеңЁJVM(Java Virtual MachineпјҢJavaиҷҡжӢҹжңә)дёҠпјҢеҸҜд»ҘжҠҠJVMзҗҶи§ЈжҲҗJavaзЁӢеәҸе’Ңж“ҚдҪңзі»з»ҹд№Ӣй—ҙзҡ„жЎҘжўҒпјҢJVMе®һзҺ°дәҶJavaзҡ„е№іеҸ°ж— е…іжҖ§пјҢз”ұжӯӨеҸҜи§ҒJVMзҡ„йҮҚиҰҒжҖ§гҖӮжүҖд»ҘеңЁеӯҰд№ JavaеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзҡ„ж—¶еҖҷдёҖе®ҡиҰҒзүўи®°иҝҷдёҖеҲҮйғҪжҳҜеңЁJVMдёӯиҝӣиЎҢзҡ„пјҢJVMжҳҜеҶ…еӯҳеҲҶй…ҚеҺҹзҗҶзҡ„еҹәзЎҖдёҺеүҚжҸҗгҖӮ
з®ҖеҚ•йҖҡдҝ—зҡ„и®ІпјҢдёҖдёӘе®Ңж•ҙзҡ„JavaзЁӢеәҸиҝҗиЎҢиҝҮзЁӢдјҡж¶үеҸҠд»ҘдёӢеҶ…еӯҳеҢәеҹҹпјҡ
l еҜ„еӯҳеҷЁпјҡJVMеҶ…йғЁиҷҡжӢҹеҜ„еӯҳеҷЁпјҢеӯҳеҸ–йҖҹеәҰйқһеёёеҝ«пјҢзЁӢеәҸдёҚеҸҜжҺ§еҲ¶гҖӮ
l ж ҲпјҡдҝқеӯҳеұҖйғЁеҸҳйҮҸзҡ„еҖјеҢ…жӢ¬пјҡ1.дҝқеӯҳеҹәжң¬ж•°жҚ®зұ»еһӢзҡ„еҖјпјӣ2.дҝқеӯҳеј•з”ЁеҸҳйҮҸпјҢеҚіе ҶеҢәеҜ№иұЎзҡ„еј•з”Ё(жҢҮй’Ҳ)гҖӮд№ҹеҸҜд»Ҙз”ЁжқҘдҝқеӯҳеҠ иҪҪж–№жі•ж—¶зҡ„её§гҖӮ
l е Ҷпјҡз”ЁжқҘеӯҳж”ҫеҠЁжҖҒдә§з”ҹзҡ„ж•°жҚ®пјҢжҜ”еҰӮnewеҮәжқҘзҡ„еҜ№иұЎгҖӮжіЁж„ҸеҲӣе»әеҮәжқҘзҡ„еҜ№иұЎеҸӘеҢ…еҗ«еұһдәҺеҗ„иҮӘзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢ并дёҚеҢ…жӢ¬жҲҗе‘ҳж–№жі•гҖӮеӣ дёәеҗҢдёҖдёӘзұ»зҡ„еҜ№иұЎжӢҘжңүеҗ„иҮӘзҡ„жҲҗе‘ҳеҸҳйҮҸпјҢеӯҳеӮЁеңЁеҗ„иҮӘзҡ„е ҶдёӯпјҢдҪҶжҳҜ他们е…ұдә«иҜҘзұ»зҡ„ж–№жі•пјҢ并дёҚжҳҜжҜҸеҲӣе»әдёҖдёӘеҜ№иұЎе°ұжҠҠжҲҗе‘ҳж–№жі•еӨҚеҲ¶дёҖж¬ЎгҖӮ
l еёёйҮҸжұ пјҡJVMдёәжҜҸдёӘе·ІеҠ иҪҪзҡ„зұ»еһӢз»ҙжҠӨдёҖдёӘеёёйҮҸжұ пјҢеёёйҮҸжұ е°ұжҳҜиҝҷдёӘзұ»еһӢз”ЁеҲ°зҡ„еёёйҮҸзҡ„дёҖдёӘжңүеәҸйӣҶеҗҲгҖӮеҢ…жӢ¬зӣҙжҺҘеёёйҮҸ(еҹәжң¬зұ»еһӢпјҢString)е’ҢеҜ№е…¶д»–зұ»еһӢгҖҒж–№жі•гҖҒеӯ—ж®өзҡ„з¬ҰеҸ·еј•з”Ё(1)гҖӮжұ дёӯзҡ„ж•°жҚ®е’Ңж•°з»„дёҖж ·йҖҡиҝҮзҙўеј•и®ҝй—®гҖӮз”ұдәҺеёёйҮҸжұ еҢ…еҗ«дәҶдёҖдёӘзұ»еһӢжүҖжңүзҡ„еҜ№е…¶д»–зұ»еһӢгҖҒж–№жі•гҖҒеӯ—ж®өзҡ„з¬ҰеҸ·еј•з”ЁпјҢжүҖд»ҘеёёйҮҸжұ еңЁJavaзҡ„еҠЁжҖҒй“ҫжҺҘдёӯиө·дәҶж ёеҝғдҪңз”ЁгҖӮеёёйҮҸжұ еӯҳеңЁдәҺе ҶдёӯгҖӮ
l д»Јз Ғж®өпјҡз”ЁжқҘеӯҳж”ҫд»ҺзЎ¬зӣҳдёҠиҜ»еҸ–зҡ„жәҗзЁӢеәҸд»Јз ҒгҖӮ
l ж•°жҚ®ж®өпјҡз”ЁжқҘеӯҳж”ҫstaticдҝ®йҘ°зҡ„йқҷжҖҒжҲҗе‘ҳпјҲеңЁjavaдёӯstaticзҡ„дҪңз”Ёе°ұжҳҜиҜҙжҳҺиҜҘеҸҳйҮҸпјҢж–№жі•пјҢд»Јз Ғеқ—жҳҜеұһдәҺзұ»зҡ„иҝҳжҳҜеұһдәҺе®һдҫӢзҡ„пјүгҖӮ
дёӢйқўжҳҜеҶ…еӯҳиЎЁзӨәеӣҫпјҡ
дёҠеӣҫдёӯеӨ§иҮҙжҸҸиҝ°дәҶJavaеҶ…еӯҳеҲҶй…ҚпјҢжҺҘдёӢжқҘйҖҡиҝҮе®һдҫӢиҜҰз»Ҷи®Іи§ЈJavaзЁӢеәҸжҳҜеҰӮдҪ•еңЁеҶ…еӯҳдёӯиҝҗиЎҢзҡ„пјҲжіЁпјҡд»ҘдёӢеӣҫзүҮеј•з”ЁиҮӘе°ҡеӯҰе Ӯ马士е…өиҖҒеёҲзҡ„J2SEиҜҫ件пјҢеӣҫеҸідҫ§жҳҜзЁӢеәҸд»Јз ҒпјҢе·Ұдҫ§жҳҜеҶ…еӯҳеҲҶй…ҚзӨәж„ҸеӣҫпјҢжҲ‘дјҡдёҖдёҖеҠ дёҠжіЁйҮҠпјүгҖӮ
йў„еӨҮзҹҘиҜҶпјҡ
1.дёҖдёӘJavaж–Ү件пјҢеҸӘиҰҒжңүmainе…ҘеҸЈж–№жі•пјҢжҲ‘们е°ұи®ӨдёәиҝҷжҳҜдёҖдёӘJavaзЁӢеәҸпјҢеҸҜд»ҘеҚ•зӢ¬зј–иҜ‘иҝҗиЎҢгҖӮ
2.ж— и®әжҳҜжҷ®йҖҡзұ»еһӢзҡ„еҸҳйҮҸиҝҳжҳҜеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸ(дҝ—з§°е®һдҫӢ)пјҢйғҪеҸҜд»ҘдҪңдёәеұҖйғЁеҸҳйҮҸпјҢ他们йғҪеҸҜд»ҘеҮәзҺ°еңЁж ҲдёӯгҖӮеҸӘдёҚиҝҮжҷ®йҖҡзұ»еһӢзҡ„еҸҳйҮҸеңЁж ҲдёӯзӣҙжҺҘдҝқеӯҳе®ғжүҖеҜ№еә”зҡ„еҖјпјҢиҖҢеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸдҝқеӯҳзҡ„жҳҜдёҖдёӘжҢҮеҗ‘е ҶеҢәзҡ„жҢҮй’ҲпјҢйҖҡиҝҮиҝҷдёӘжҢҮй’ҲпјҢе°ұеҸҜд»ҘжүҫеҲ°иҝҷдёӘе®һдҫӢеңЁе ҶеҢәеҜ№еә”зҡ„еҜ№иұЎгҖӮеӣ жӯӨпјҢжҷ®йҖҡзұ»еһӢеҸҳйҮҸеҸӘеңЁж ҲеҢәеҚ з”ЁдёҖеқ—еҶ…еӯҳпјҢиҖҢеј•з”Ёзұ»еһӢеҸҳйҮҸиҰҒеңЁж ҲеҢәе’Ңе ҶеҢәеҗ„еҚ дёҖеқ—еҶ…еӯҳгҖӮ
зӨәдҫӢпјҡ
1.JVMиҮӘеҠЁеҜ»жүҫmainж–№жі•пјҢжү§иЎҢ第дёҖеҸҘд»Јз ҒпјҢеҲӣе»әдёҖдёӘTestзұ»зҡ„е®һдҫӢпјҢеңЁж ҲдёӯеҲҶй…ҚдёҖеқ—еҶ…еӯҳпјҢеӯҳж”ҫдёҖдёӘжҢҮеҗ‘е ҶеҢәеҜ№иұЎзҡ„еј•з”ЁеҸҳйҮҸпјҲжҢҮй’Ҳ110925пјүпјҢjavaдёӯзҡ„еј•з”ЁеҸҳйҮҸе°ұжҳҜCиҜӯиЁҖдёӯжҢҮй’Ҳзҡ„дёҖдёӘеҢ…иЈ…пјҢжүҖд»Ҙеј•з”ЁеҸҳйҮҸдёӯеӯҳж”ҫзҡ„иҝҳжҳҜе ҶеҶ…еӯҳдёӯеҜ№иұЎзҡ„ең°еқҖгҖӮ
2.еҲӣе»әдёҖдёӘintеһӢзҡ„еҸҳйҮҸdateпјҢз”ұдәҺжҳҜеҹәжң¬зұ»еһӢпјҢзӣҙжҺҘеңЁж Ҳдёӯеӯҳж”ҫdateеҜ№еә”зҡ„еҖј9гҖӮ
3.еҲӣе»әдёӨдёӘBirthDateзұ»зҡ„е®һдҫӢd1гҖҒd2пјҢеңЁж ҲдёӯеҲҶеҲ«еӯҳж”ҫдәҶеҜ№еә”зҡ„жҢҮй’ҲжҢҮеҗ‘еҗ„иҮӘзҡ„еҜ№иұЎгҖӮ他们еңЁе®һдҫӢеҢ–ж—¶и°ғз”ЁдәҶжңүеҸӮж•°зҡ„жһ„йҖ ж–№жі•пјҢеӣ жӯӨеҜ№иұЎдёӯжңүиҮӘе®ҡд№үеҲқе§ӢеҖјгҖӮ
и°ғз”ЁtestеҜ№иұЎзҡ„change1ж–№жі•пјҢ并且д»ҘdateдёәеҸӮж•°гҖӮJVMиҜ»еҲ°иҝҷж®өд»Јз Ғж—¶пјҢжЈҖжөӢеҲ°iжҳҜеұҖйғЁеҸҳйҮҸпјҢеӣ жӯӨдјҡжҠҠiж”ҫеңЁж ҲдёӯпјҢ并且жҠҠdateзҡ„еҖјиөӢз»ҷiгҖӮ
жҠҠ1234иөӢз»ҷiгҖӮеҫҲз®ҖеҚ•зҡ„дёҖжӯҘгҖӮ
change1ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеҸҳйҮҸiжүҖеҚ з”Ёзҡ„ж Ҳз©әй—ҙгҖӮ
и°ғз”ЁtestеҜ№иұЎзҡ„change2ж–№жі•пјҢд»Ҙе®һдҫӢd1дёәеҸӮж•°гҖӮJVMжЈҖжөӢеҲ°change2ж–№жі•дёӯзҡ„bеҸӮж•°дёәеұҖйғЁеҸҳйҮҸпјҢз«ӢеҚіеҠ е…ҘеҲ°ж ҲдёӯпјҢз”ұдәҺжҳҜеј•з”Ёзұ»еһӢзҡ„еҸҳйҮҸпјҢжүҖд»Ҙbдёӯдҝқеӯҳзҡ„жҳҜd1дёӯзҡ„жҢҮй’ҲпјҢжӯӨж—¶bе’Ңd1жҢҮеҗ‘еҗҢдёҖдёӘе Ҷдёӯзҡ„еҜ№иұЎгҖӮеңЁbе’Ңd1д№Ӣй—ҙдј йҖ’жҳҜжҢҮй’ҲгҖӮ
change2ж–№жі•дёӯеҸҲе®һдҫӢеҢ–дәҶдёҖдёӘBirthDateеҜ№иұЎпјҢ并且иөӢз»ҷbгҖӮеңЁеҶ…йғЁжү§иЎҢиҝҮзЁӢжҳҜпјҡеңЁе ҶеҢәnewдәҶдёҖдёӘеҜ№иұЎпјҢ并且жҠҠиҜҘеҜ№иұЎзҡ„жҢҮй’ҲдҝқеӯҳеңЁж Ҳдёӯзҡ„bеҜ№еә”з©әй—ҙпјҢжӯӨж—¶е®һдҫӢbдёҚеҶҚжҢҮеҗ‘е®һдҫӢd1жүҖжҢҮеҗ‘зҡ„еҜ№иұЎпјҢдҪҶжҳҜе®һдҫӢd1жүҖжҢҮеҗ‘зҡ„еҜ№иұЎе№¶ж— еҸҳеҢ–пјҢиҝҷж ·ж— жі•еҜ№d1йҖ жҲҗд»»дҪ•еҪұе“ҚгҖӮ
change2ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеј•з”ЁеҸҳйҮҸbжүҖеҚ зҡ„ж Ҳз©әй—ҙпјҢжіЁж„ҸеҸӘжҳҜйҮҠж”ҫдәҶж Ҳз©әй—ҙпјҢе Ҷз©әй—ҙиҰҒзӯүеҫ…иҮӘеҠЁеӣһ收гҖӮ
и°ғз”Ёtestе®һдҫӢзҡ„change3ж–№жі•пјҢд»Ҙе®һдҫӢd2дёәеҸӮж•°гҖӮеҗҢзҗҶпјҢJVMдјҡеңЁж ҲдёӯдёәеұҖйғЁеј•з”ЁеҸҳйҮҸbеҲҶй…Қз©әй—ҙпјҢ并且жҠҠd2дёӯзҡ„жҢҮй’Ҳеӯҳж”ҫеңЁbдёӯпјҢжӯӨж—¶d2е’ҢbжҢҮеҗ‘еҗҢдёҖдёӘеҜ№иұЎгҖӮеҶҚи°ғз”Ёе®һдҫӢbзҡ„setDayж–№жі•пјҢе…¶е®һе°ұжҳҜи°ғз”Ёd2жҢҮеҗ‘зҡ„еҜ№иұЎзҡ„setDayж–№жі•гҖӮ
и°ғз”Ёе®һдҫӢbзҡ„setDayж–№жі•дјҡеҪұе“Қd2пјҢеӣ дёәдәҢиҖ…жҢҮеҗ‘зҡ„жҳҜеҗҢдёҖдёӘеҜ№иұЎгҖӮ
change3ж–№жі•жү§иЎҢе®ҢжҜ•пјҢз«ӢеҚійҮҠж”ҫеұҖйғЁеј•з”ЁеҸҳйҮҸbгҖӮ
д»ҘдёҠе°ұжҳҜJavaзЁӢеәҸиҝҗиЎҢж—¶еҶ…еӯҳеҲҶй…Қзҡ„еӨ§иҮҙжғ…еҶөгҖӮе…¶е®һд№ҹжІЎд»Җд№ҲпјҢжҺҢжҸЎдәҶжҖқжғіе°ұеҫҲз®ҖеҚ•дәҶгҖӮж— йқһе°ұжҳҜдёӨз§Қзұ»еһӢзҡ„еҸҳйҮҸпјҡеҹәжң¬зұ»еһӢе’Ңеј•з”Ёзұ»еһӢгҖӮдәҢиҖ…дҪңдёәеұҖйғЁеҸҳйҮҸпјҢйғҪж”ҫеңЁж ҲдёӯпјҢеҹәжң¬зұ»еһӢзӣҙжҺҘеңЁж ҲдёӯдҝқеӯҳеҖјпјҢеј•з”Ёзұ»еһӢеҸӘдҝқеӯҳдёҖдёӘжҢҮеҗ‘е ҶеҢәзҡ„жҢҮй’ҲпјҢзңҹжӯЈзҡ„еҜ№иұЎеңЁе ҶйҮҢгҖӮдҪңдёәеҸӮж•°ж—¶еҹәжң¬зұ»еһӢе°ұзӣҙжҺҘдј еҖјпјҢеј•з”Ёзұ»еһӢдј жҢҮй’ҲпјҲеңЁjavaдёӯеҸӘжңүеҖјдј йҖ’жІЎжңүең°еқҖдј йҖ’дҪҶжҳҜеј•з”ЁеҸҳйҮҸдёӯеӯҳж”ҫзҡ„жҳҜе ҶдёӯеҜ№иұЎзҡ„ең°еқҖпјҢжүҖд»Ҙд№ҹеҸҜд»ҘзҗҶи§Јдёәең°еқҖдј йҖ’пјүгҖӮ
е°Ҹз»“пјҡ
1.еҲҶжё…д»Җд№ҲжҳҜеҜ№иұЎеј•з”ЁеҸҳйҮҸпјҲеј•з”ЁеҸҳйҮҸпјүд»Җд№ҲжҳҜеҜ№иұЎгҖӮClass a= new Class();жӯӨж—¶aеҸ«еҜ№иұЎеј•з”ЁеҸҳйҮҸпјҢиҖҢдёҚиғҪиҜҙaжҳҜеҜ№иұЎгҖӮеј•з”ЁеҸҳйҮҸеңЁж ҲдёӯпјҢеҜ№иұЎеңЁе ҶдёӯпјҢж“ҚдҪңеј•з”ЁеҸҳйҮҸе®һйҷ…дёҠжҳҜйҖҡиҝҮеј•з”Ёй—ҙжҺҘж“ҚдҪңеҜ№иұЎгҖӮеӨҡдёӘеј•з”ЁеҸҳйҮҸеҸҜд»Ҙеј•з”ЁеҲ°еҗҢдёҖдёӘеҜ№иұЎгҖӮ
2.ж Ҳдёӯзҡ„ж•°жҚ®е’Ңе Ҷдёӯзҡ„ж•°жҚ®й”ҖжҜҒ并дёҚжҳҜеҗҢжӯҘзҡ„гҖӮж–№жі•дёҖж—Ұз»“жқҹпјҢж Ҳдёӯзҡ„еұҖйғЁеҸҳйҮҸз«ӢеҚій”ҖжҜҒпјҢдҪҶжҳҜе ҶдёӯеҜ№иұЎдёҚдёҖе®ҡй”ҖжҜҒгҖӮеӣ дёәеҸҜиғҪжңүе…¶д»–еҸҳйҮҸд№ҹжҢҮеҗ‘дәҶиҝҷдёӘеҜ№иұЎпјҢзӣҙеҲ°ж ҲдёӯжІЎжңүеҸҳйҮҸжҢҮеҗ‘е Ҷдёӯзҡ„еҜ№иұЎж—¶пјҢе®ғжүҚй”ҖжҜҒпјҢиҖҢдё”иҝҳдёҚжҳҜ马дёҠй”ҖжҜҒпјҢиҰҒзӯүеһғеңҫеӣһ收жү«жҸҸж—¶жүҚеҸҜд»Ҙиў«й”ҖжҜҒгҖӮ
3.жҜҸдёӘж–№жі•жү§иЎҢзҡ„ж—¶еҖҷйғҪдјҡе»әз«ӢиҮӘе·ұзҡ„ж ҲеҢәпјҢеңЁж–№жі•дёӯе®ҡд№үзҡ„еұҖйғЁеҸҳйҮҸпјҲеҸӮж•°пјҢж–№жі•дёӯе®ҡд№үзҡ„еҸҳйҮҸпјүйғҪеңЁж ҲеҢәдёӯеӯҳж”ҫеҪ“ж–№жі•з»“жқҹж—¶иҝҷдәӣеұҖйғЁеҸҳйҮҸд№ҹе°ұз»“жқҹдәҶпјҢдҪҶжҳҜе ҶеҶ…еӯҳдёӯзҡ„еҜ№иұЎдёҚдјҡйҡҸзқҖж–№жі•зҡ„з»“жқҹиҖҢй”ҖжҜҒиҖҢжҳҜеҲӨж–ӯиҝҳжңүжІЎжңүеј•з”ЁеҸҳйҮҸеј•з”ЁеҲ°иҝҷдёӘеҜ№иұЎеҰӮжһңжңүзҡ„иҜқе°ұжҳҜиҜҙиҝҷдёӘеҜ№иұЎеҸҜиҫҫжүҖд»ҘдёҚдјҡиҪ»жҳ“зҡ„иў«GCеӣһ收пјҢеҰӮжһңиҝҷдёӘеҜ№иұЎжІЎжңүиў«еј•з”ЁеҰӮжһңиҝҷж—¶еһғеңҫеӣһ收系з»ҹејҖе§Ӣеӣһ收дҪҶеҸ‘зҺ°иҝҷдёӘеҜ№иұЎжІЎжңүеј•з”Ёзҡ„иҜқе°ұдјҡи°ғз”ЁfinalizeпјҲпјүж–№жі•жқҘеҲӨж–ӯиҝҷдёӘеҜ№иұЎжҳҜеҗҰеҸҜд»ҘеҶҚж¬ЎеҸҜиҫҫеҰӮжһңеҸҜд»Ҙзҡ„дёҚдјҡеӣһ收дҪҶжҳҜдёҚиҝҮдёҚеҸҜиҫҫзҡ„иҜқеҸҜиғҪдјҡиў«еӣһ收пјҲдёҚжҳҜдёҖе®ҡдјҡиў«еӣһ收иҝҷйҮҢжҳҜдёҚдёҖе®ҡдјҡеӣһ收еӣ дёәиҝҷйҮҢиҝҳжңүеҜ№иұЎзҡ„еј•з”Ёзұ»еһӢеҰӮпјҡејәеј•з”ЁпјҢиҪҜеј•з”ЁпјҲsoftReferenceжқҘе®һзҺ°пјүпјҢејұеј•з”ЁпјҲWeakReferenceжқҘе®һзҺ°пјүзӯүеӣ зҙ жңүе…іпјҢиҝҳиҰҒиҖғиҷ‘е…¶д»–зҡ„еӣ зҙ дёҚеңЁиҝҷйҮҢдёҖдёҖиҜҙжҳҺпјүеҰӮжһңеҸҜиҫҫзҡ„иҜқиҝҳжҳҜдёҚдјҡеӣһ收зҡ„гҖӮ
4.д»ҘдёҠзҡ„ж ҲгҖҒе ҶгҖҒд»Јз Ғж®өгҖҒж•°жҚ®ж®өзӯүзӯүйғҪжҳҜзӣёеҜ№дәҺеә”з”ЁзЁӢеәҸиҖҢиЁҖзҡ„гҖӮжҜҸдёҖдёӘеә”з”ЁзЁӢеәҸйғҪеҜ№еә”е”ҜдёҖзҡ„дёҖдёӘJVMе®һдҫӢпјҢжҜҸдёҖдёӘJVMе®һдҫӢйғҪжңүиҮӘе·ұзҡ„еҶ…еӯҳеҢәеҹҹпјҢдә’дёҚеҪұе“ҚпјҢи°ғз”ЁJVMд№ҹе°ұжҳҜжҝҖжҙ»дёҖдёӘиҝӣзЁӢгҖӮ并且иҝҷдәӣеҶ…еӯҳеҢәеҹҹжҳҜжүҖжңүзәҝзЁӢе…ұдә«зҡ„гҖӮиҝҷйҮҢжҸҗеҲ°зҡ„ж Ҳе’Ңе ҶйғҪжҳҜж•ҙдҪ“дёҠзҡ„жҰӮеҝөпјҢиҝҷдәӣе Ҷж ҲиҝҳеҸҜд»Ҙз»ҶеҲҶгҖӮ
5.зұ»дёӯе®ҡд№үзҡ„е®һдҫӢжҲҗе‘ҳеҸҳйҮҸеңЁдёҚеҗҢеҜ№иұЎдёӯеҗ„дёҚзӣёеҗҢпјҢйғҪжңүиҮӘе·ұзҡ„еӯҳеӮЁз©әй—ҙ(жҲҗе‘ҳеҸҳйҮҸеңЁе Ҷдёӯзҡ„еҜ№иұЎдёӯ)гҖӮиҖҢзұ»дёӯе®ҡд№үзҡ„ж–№жі•еҚҙжҳҜиҜҘзұ»зҡ„жүҖжңүеҜ№иұЎе…ұдә«зҡ„пјҢеҸӘжңүдёҖеҘ—пјҢеҜ№иұЎдҪҝз”Ёж–№жі•зҡ„ж—¶еҖҷж–№жі•жүҚиў«еҺӢе…Ҙж ҲпјҢж–№жі•дёҚдҪҝз”ЁеҲҷдёҚеҚ з”ЁеҶ…еӯҳгҖӮ
д»ҘдёҠеҲҶжһҗеҸӘж¶үеҸҠдәҶж Ҳе’Ңе ҶпјҢиҝҳжңүдёҖдёӘйқһеёёйҮҚиҰҒзҡ„еҶ…еӯҳеҢәеҹҹпјҡеёёйҮҸжұ пјҢиҝҷдёӘең°ж–№еҫҖеҫҖеҮәзҺ°дёҖдәӣиҺ«еҗҚе…¶еҰҷзҡ„й—®йўҳгҖӮеёёйҮҸжұ жҳҜе№Іеҳӣзҡ„дёҠиҫ№е·Із»ҸиҜҙжҳҺдәҶпјҢд№ҹжІЎеҝ…иҰҒзҗҶи§ЈеӨҡд№Ҳж·ұеҲ»пјҢеҸӘиҰҒи®°дҪҸе®ғз»ҙжҠӨдәҶдёҖдёӘе·ІеҠ иҪҪзұ»зҡ„еёёйҮҸе°ұеҸҜд»ҘдәҶгҖӮжҺҘдёӢжқҘз»“еҗҲдёҖдәӣдҫӢеӯҗиҜҙжҳҺеёёйҮҸжұ зҡ„зү№жҖ§гҖӮ
йў„еӨҮзҹҘиҜҶпјҡ
еҹәжң¬зұ»еһӢе’Ңеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»гҖӮеҹәжң¬зұ»еһӢжңүпјҡbyteгҖҒshortгҖҒcharгҖҒintгҖҒlongгҖҒbooleanгҖӮеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»еҲҶеҲ«жҳҜпјҡByteгҖҒShortгҖҒCharacterгҖҒIntegerгҖҒLongгҖҒBooleanгҖӮжіЁж„ҸеҢәеҲҶеӨ§е°ҸеҶҷгҖӮдәҢиҖ…зҡ„еҢәеҲ«жҳҜпјҡеҹәжң¬зұ»еһӢдҪ“зҺ°еңЁзЁӢеәҸдёӯжҳҜжҷ®йҖҡеҸҳйҮҸпјҢеҹәжң¬зұ»еһӢзҡ„еҢ…иЈ…зұ»жҳҜзұ»пјҢдҪ“зҺ°еңЁзЁӢеәҸдёӯжҳҜеј•з”ЁеҸҳйҮҸгҖӮеӣ жӯӨдәҢиҖ…еңЁеҶ…еӯҳдёӯзҡ„еӯҳеӮЁдҪҚзҪ®дёҚеҗҢпјҡеҹәжң¬зұ»еһӢеӯҳеӮЁеңЁж ҲдёӯпјҢиҖҢеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»еӯҳеӮЁеңЁе ҶдёӯгҖӮдёҠиҫ№жҸҗеҲ°зҡ„иҝҷдәӣеҢ…иЈ…зұ»йғҪе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢиҖҢдёӨз§Қжө®зӮ№ж•°зұ»еһӢзҡ„еҢ…иЈ…зұ»еҲҷжІЎжңүе®һзҺ°гҖӮеҸҰеӨ–пјҢStringзұ»еһӢд№ҹе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜгҖӮ
е®һдҫӢпјҡ
public class test {
public static void main(String[] args) {
objPoolTest();
}
public static void objPoolTest() {
int i = 40;
int i0 = 40;
Integer i1 = 40;
Integer i2 = 40;
Integer i3 = 0;
Integer i4 = new Integer(40);
Integer i5 = new Integer(40);
Integer i6 = new Integer(0);
Double d1=1.0;
Double d2=1.0;
//еңЁjavaдёӯеҜ№дәҺеј•з”ЁеҸҳйҮҸжқҘиҜҙвҖң==вҖқе°ұжҳҜеҲӨж–ӯиҝҷдёӨдёӘеј•з”ЁеҸҳйҮҸжүҖеј•з”Ёзҡ„жҳҜдёҚжҳҜеҗҢдёҖдёӘеҜ№иұЎ
System.out.println("i==i0\t" + (i == i0));
System.out.println("i1==i2\t" + (i1 == i2));
System.out.println("i1==i2+i3\t" + (i1 == i2 + i3));
System.out.println("i4==i5\t" + (i4 == i5));
System.out.println("i4==i5+i6\t" + (i4 == i5 + i6));
System.out.println("d1==d2\t" + (d1==d2));
System.out.println();
}
}
з»“жһңпјҡ
[java] view plaincopy
i==i0 true
i1==i2 true
i1==i2+i3 true
i4==i5 false
i4==i5+i6 true
d1==d2 false
з»“жһңеҲҶжһҗпјҡ
1.iе’Ңi0еқҮжҳҜжҷ®йҖҡзұ»еһӢ(int)зҡ„еҸҳйҮҸпјҢжүҖд»Ҙж•°жҚ®зӣҙжҺҘеӯҳеӮЁеңЁж ҲдёӯпјҢиҖҢж ҲжңүдёҖдёӘеҫҲйҮҚиҰҒзҡ„зү№жҖ§пјҡж Ҳдёӯзҡ„ж•°жҚ®еҸҜд»Ҙе…ұдә«гҖӮеҪ“жҲ‘们е®ҡд№үдәҶint i = 40;пјҢеҶҚе®ҡд№үint i0 = 40;иҝҷж—¶еҖҷдјҡиҮӘеҠЁжЈҖжҹҘж ҲдёӯжҳҜеҗҰжңү40иҝҷдёӘж•°жҚ®пјҢеҰӮжһңжңүпјҢi0дјҡзӣҙжҺҘжҢҮеҗ‘iзҡ„40пјҢдёҚдјҡеҶҚж·»еҠ дёҖдёӘж–°зҡ„40гҖӮ
2.i1е’Ңi2еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәIntegerжҳҜеҢ…иЈ…зұ»гҖӮз”ұдәҺIntegerеҢ…иЈ…зұ»е®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢеӣ жӯӨi1гҖҒi2зҡ„40еқҮжҳҜд»ҺеёёйҮҸжұ дёӯиҺ·еҸ–зҡ„пјҢеқҮжҢҮеҗ‘еҗҢдёҖдёӘең°еқҖпјҢеӣ жӯӨi1==12гҖӮ
3.еҫҲжҳҺжҳҫиҝҷжҳҜдёҖдёӘеҠ жі•иҝҗз®—пјҢJavaзҡ„ж•°еӯҰиҝҗз®—йғҪжҳҜеңЁж ҲдёӯиҝӣиЎҢзҡ„пјҢJavaдјҡиҮӘеҠЁеҜ№i1гҖҒi2иҝӣиЎҢжӢҶз®ұж“ҚдҪңиҪ¬еҢ–жҲҗж•ҙеһӢпјҢеӣ жӯӨi1еңЁж•°еҖјдёҠзӯүдәҺi2+i3гҖӮ
4.i4е’Ңi5еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәIntegerжҳҜеҢ…иЈ…зұ»гҖӮдҪҶжҳҜз”ұдәҺ他们еҗ„иҮӘйғҪжҳҜnewеҮәжқҘзҡ„пјҢеӣ жӯӨдёҚеҶҚд»ҺеёёйҮҸжұ еҜ»жүҫж•°жҚ®пјҢиҖҢжҳҜд»Һе Ҷдёӯеҗ„иҮӘnewдёҖдёӘеҜ№иұЎпјҢ然еҗҺеҗ„иҮӘдҝқеӯҳжҢҮеҗ‘еҜ№иұЎзҡ„жҢҮй’ҲпјҢжүҖд»Ҙi4е’Ңi5дёҚзӣёзӯүпјҢеӣ дёә他们жүҖеӯҳең°еқҖдёҚеҗҢпјҢжүҖеј•з”ЁеҲ°зҡ„еҜ№иұЎдёҚеҗҢгҖӮ
5.иҝҷд№ҹжҳҜдёҖдёӘеҠ жі•иҝҗз®—пјҢе’Ң3еҗҢзҗҶгҖӮ
6.d1е’Ңd2еқҮжҳҜеј•з”Ёзұ»еһӢпјҢеңЁж ҲдёӯеӯҳеӮЁжҢҮй’ҲпјҢеӣ дёәDoubleжҳҜеҢ…иЈ…зұ»гҖӮдҪҶDoubleеҢ…иЈ…зұ»жІЎжңүе®һзҺ°еёёйҮҸжұ жҠҖжңҜпјҢеӣ жӯӨDoubled1=1.0;зӣёеҪ“дәҺDouble d1=new Double(1.0);пјҢжҳҜд»Һе ҶnewдёҖдёӘеҜ№иұЎпјҢd2еҗҢзҗҶгҖӮеӣ жӯӨd1е’Ңd2еӯҳж”ҫзҡ„жҢҮй’ҲдёҚеҗҢпјҢжҢҮеҗ‘зҡ„еҜ№иұЎдёҚеҗҢпјҢжүҖд»ҘдёҚзӣёзӯүгҖӮ
е°Ҹз»“пјҡ
1.д»ҘдёҠжҸҗеҲ°зҡ„еҮ з§Қеҹәжң¬зұ»еһӢеҢ…иЈ…зұ»еқҮе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢдҪҶ他们з»ҙжҠӨзҡ„еёёйҮҸд»…д»…жҳҜгҖҗ-128иҮі127гҖ‘иҝҷдёӘиҢғеӣҙеҶ…зҡ„еёёйҮҸпјҢеҰӮжһңеёёйҮҸеҖји¶…иҝҮиҝҷдёӘиҢғеӣҙпјҢе°ұдјҡд»Һе ҶдёӯеҲӣе»әеҜ№иұЎпјҢдёҚеҶҚд»ҺеёёйҮҸжұ дёӯеҸ–гҖӮжҜ”еҰӮпјҢжҠҠдёҠиҫ№дҫӢеӯҗж”№жҲҗInteger i1 = 400; Integer i2 = 400;пјҢеҫҲжҳҺжҳҫи¶…иҝҮдәҶ127пјҢж— жі•д»ҺеёёйҮҸжұ иҺ·еҸ–еёёйҮҸпјҢе°ұиҰҒд»Һе Ҷдёӯnewж–°зҡ„IntegerеҜ№иұЎпјҢиҝҷж—¶i1е’Ңi2е°ұдёҚзӣёзӯүдәҶгҖӮ
2.Stringзұ»еһӢд№ҹе®һзҺ°дәҶеёёйҮҸжұ жҠҖжңҜпјҢдҪҶжҳҜзЁҚеҫ®жңүзӮ№дёҚеҗҢгҖӮStringеһӢжҳҜе…ҲжЈҖжөӢеёёйҮҸжұ дёӯжңүжІЎжңүеҜ№еә”еӯ—з¬ҰдёІпјҢеҰӮжһңжңүпјҢеҲҷеҸ–еҮәжқҘпјӣеҰӮжһңжІЎжңүпјҢеҲҷжҠҠеҪ“еүҚзҡ„ж·»еҠ иҝӣеҺ»гҖӮ
д»ҘдёҠзҹҘиҜҶзӮ№еҰӮжңүдёҚжҳҺпјҢжҲ–й”ҷиҜҜиҝҳжңӣеӨ§е®¶жү№иҜ„жҢҮжӯЈпјҢд№ҹеёҢжңӣд»ҘдёҠзҹҘиҜҶзӮ№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҗҢж—¶еёҢжңӣеӨ§е®¶еёёжқҘе…үйЎҫпјҒ
еҲҶдә«еҲ°пјҡ


- 2015-04-28 11:35
- жөҸи§Ҳ 512
- иҜ„и®ә(0)
- еҲҶзұ»:зј–зЁӢиҜӯиЁҖ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
Java并еҸ‘зј–зЁӢпјҡvolatileе…ій”®еӯ—и§Јжһҗ
2015-11-04 14:24 422иҪ¬иҮӘпјҡhttp://www.cnblogs.com ... -
дҪҝз”Ёatomicе®һзҺ°й“¶иЎҢеӯҳеҸ–ж¬ҫ
2015-06-26 16:23 602дёҖгҖҒеә”з”ЁеңәжҷҜ В В еңЁйҖҡеёёжғ…еҶөдёӢпјҢжҲ‘们еңЁз”ЁеӨҡзәҝзЁӢеӨ„зҗҶдёҖдёӘй—® ... -
CyclicBarrierзҡ„дҪҝз”Ё
2015-06-26 16:01 446дёҖгҖҒеә”з”ЁиғҢжҷҜ еңЁе®һйҷ…зҡ„еә”з”ЁдёӯпјҢжҲ‘们жңүж—¶еҖҷйңҖиҰҒеҗҜеҠЁеӨҡдёӘзәҝзЁӢжқҘе®Ң ... -
Java synchronizedиҜҰи§Ј
2015-04-30 11:34 451[size=x-large]еҺҹж–Үең°еқҖпјҡhttp://www.c ... -
javaж— жі•иҪ¬еҢ–ж—¶й—ҙй—®йўҳ
2014-11-18 10:41 801дёҖгҖҒй—®йўҳдә§з”ҹзҡ„иғҢжҷҜ дёӯй—ҙ件пјҡtomcat6 jdkпјҡ1.6 ... -
springmvcз»“еҗҲquartzе®һзҺ°е®ҡж—¶д»»еҠЎ
2014-10-17 16:34 1639дёҖгҖҒй—®йўҳиғҢжҷҜ еңЁжҲ‘д»¬е® ... -
javaи§Јжһҗexcel
2014-10-17 16:01 747дёҖгҖҒй—®йўҳиғҢжҷҜ д»ҠеӨ©дҪҝз”Ёjxl.jarеҢ…и§Јжһҗexcleж—¶пјҢеҸ‘зҺ°дёҖ ...
зӣёе…іжҺЁиҚҗ
зӢ¬еӯҗжЈӢdemo.rar
дә‘е®үе…ЁиҒ”зӣҹиҪҜ件е®ҡд№үиҫ№з•ҢSDPж ҮеҮҶ规иҢғ2.0202239йЎө.pdf
UniappејҖеҸ‘зҡ„еҫ®е•ҶдёӘдәәзӣёеҶҢеӨҡз«Ҝе°ҸзЁӢеәҸжәҗз ҒгҖӮдҪҝз”Ё HBuilder X еҜје…Ҙжң¬ең°йЎ№зӣ®пјҢдҝ®ж”№е°ҸзЁӢеәҸAppIDпјҢд»ҘеҸҠUni-appеә”з”Ёж ҮиҜҶпјҢи°ғиҜ•еҸ‘еёғеҚіеҸҜгҖӮ е°ҸзЁӢеәҸжәҗз Ғзү№зӮ№пјҡ 1гҖҒйҰ–йЎөиҝӣиЎҢзӣёеҶҢеұ•зӨәпјҢйҮҮз”ЁеҲҶйЎө 2гҖҒеҲ—иЎЁйЎөйқўд»Ҙж–Үеӯ—еҪўејҸиҝӣиЎҢеҲҶзұ»пјҢз®ЎзҗҶе‘ҳеҸҜиҝӣиЎҢж·»еҠ пјҢдҝ®ж”№е’ҢжҺ’еәҸ 3гҖҒжҜҸдёӘеҲ—иЎЁдёӢжңүеӨҡдёӘзӣёеҶҢпјҢз®ЎзҗҶе‘ҳеҸҜиҝӣиЎҢж·»еҠ пјҢдҝ®ж”№е’ҢжҺ’еәҸ 4гҖҒжҜҸдёӘзӣёеҶҢжңүеӨҡеј еӣҫзүҮпјҢжңүе°Ҹеӣҫе’ҢеӨ§еӣҫжЁЎејҸиҝӣиЎҢеҲҮжҚў 5гҖҒзӣёеҶҢдёӯеҸҜд»Ҙй•ҝжҢүеӣҫзүҮиҝӣиЎҢйҖүжӢ©еҲ йҷӨе’Ңи®ҫдёәе°Ғйқў 6гҖҒзӣёеҶҢеҸҜд»ҘиҝӣиЎҢеҲҶдә« 7гҖҒжҲ‘зҡ„йЎөйқўжңүз®ЎзҗҶе‘ҳзҷ»еҪ•пјҢиҒ”зі»е®ўжңҚзӯүеҠҹиғҪ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҹәдәҺFPGAзҡ„144иҫ“еҮәйҖҡйҒ“еҸҜеҲҮжҚўз”өеҺӢжәҗзі»з»ҹзҡ„и®ҫи®ЎдёҺе®һзҺ°пјҢж¶өзӣ–зі»з»ҹжҖ»дҪ“жһ¶жһ„гҖҒFPGA硬件и®ҫи®ЎгҖҒдёҠдҪҚжңәиҪҜ件и®ҫи®Ўд»ҘеҸҠзі»з»ҹйӣҶжҲҗж–№жЎҲгҖӮзі»з»ҹз”ұдёҠдҪҚжңәжҺ§еҲ¶иҪҜ件пјҲPCз«ҜпјүгҖҒFPGAжҺ§еҲ¶ж ёеҝғе’Ңй«ҳеҺӢиҫ“еҮәжЁЎеқ—пјҲ144йҖҡйҒ“пјүдёүйғЁеҲҶз»„жҲҗгҖӮFPGA硬件и®ҫи®ЎйғЁеҲҶиҜҰз»ҶжҸҸиҝ°дәҶVerilogд»Јз Ғе®һзҺ°пјҢеҢ…жӢ¬PWMз”ҹжҲҗжЁЎеқ—гҖҒUARTйҖҡдҝЎжЁЎеқ—е’Ңжё©еәҰзӣ‘жҺ§жЁЎеқ—гҖӮ硬件и®ҫи®ЎиҜҙжҳҺдёӯжҸҗеҸҠдәҶFPGAйҖүеһӢгҖҒPWMз”ҹжҲҗж–№ејҸгҖҒйҖҡдҝЎжҺҘеҸЈгҖҒй«ҳеҺӢиҫ“еҮәжЁЎеқ—е’ҢдҝқжҠӨз”өи·Ҝзҡ„и®ҫи®ЎиҰҒзӮ№гҖӮдёҠдҪҚжңәиҪҜ件йҮҮз”ЁPythonзј–еҶҷпјҢе®һзҺ°дәҶи®ҫеӨҮиҝһжҺҘгҖҒе‘Ҫд»ӨеҸ‘йҖҒгҖҒеәҸеҲ—жҺ§еҲ¶зӯүеҠҹиғҪпјҢ并жҸҗдҫӣдәҶдёҖдёӘеӣҫеҪўз”ЁжҲ·з•ҢйқўпјҲGUIпјүз”ЁдәҺж–№дҫҝзҡ„ж“ҚдҪңе’Ңй…ҚзҪ®гҖӮ йҖӮеҗҲдәәзҫӨпјҡе…·еӨҮдёҖе®ҡ硬件и®ҫи®Ўе’Ңзј–зЁӢеҹәзЎҖзҡ„з”өеӯҗе·ҘзЁӢеёҲгҖҒFPGAејҖеҸ‘иҖ…еҸҠз§‘з ”дәәе‘ҳгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж Үпјҡв‘ йҖӮз”ЁдәҺйңҖиҰҒзІҫзЎ®жҺ§еҲ¶еӨҡйҖҡйҒ“з”өеҺӢиҫ“еҮәзҡ„е®һйӘҢзҺҜеўғжҲ–е·Ҙдёҡеә”з”ЁеңәжҷҜпјӣв‘Ўеё®еҠ©з”ЁжҲ·зҗҶи§Је’ҢжҺҢжҸЎFPGAеңЁеӨҚжқӮжҺ§еҲ¶зі»з»ҹдёӯзҡ„еә”з”ЁпјҢеҢ…жӢ¬PWMжҺ§еҲ¶гҖҒUARTйҖҡдҝЎеҸҠеӨҡйҖҡйҒ“дҝЎеҸ·еӨ„зҗҶпјӣв‘ўдёәз ”з©¶дәәе‘ҳжҸҗдҫӣдёҖдёӘеҸҜжү©еұ•зҡ„е№іеҸ°пјҢз”ЁдәҺжөӢиҜ•е’ҢйӘҢиҜҒдёҚеҗҢзҡ„з”өеҺӢжәҗжҺ§еҲ¶з®—жі•е’Ңзӯ–з•ҘгҖӮ йҳ…иҜ»е»әи®®пјҡз”ұдәҺж¶үеҸҠ硬件е’ҢиҪҜ件дёӨж–№йқўзҡ„еҶ…е®№пјҢе»әи®®иҜ»иҖ…е…ҲзҶҹжӮүFPGAеҹәзЎҖзҹҘиҜҶе’ҢVerilogиҜӯиЁҖпјҢеҗҢж—¶е…·еӨҮдёҖе®ҡзҡ„Pythonзј–зЁӢз»ҸйӘҢгҖӮеңЁйҳ…иҜ»иҝҮзЁӢдёӯпјҢеә”з»“еҗҲ硬件з”өи·Ҝеӣҫе’Ңд»Јз ҒжіЁйҮҠпјҢйҖҗжӯҘзҗҶи§Јзі»з»ҹзҡ„еҗ„дёӘз»„жҲҗйғЁеҲҶеҸҠе…¶зӣёдә’е…ізі»гҖӮжӯӨеӨ–пјҢе®һйҷ…еҠЁжүӢжҗӯе»әе’Ңи°ғиҜ•иҜҘзі»з»ҹе°ҶжңүеҠ©дәҺеҠ ж·ұеҜ№ж•ҙдёӘи®ҫи®Ўзҡ„зҗҶи§ЈгҖӮ
ең°зә§еёӮж”ҝеәңйҖҡиҝҮеҲ¶е®ҡзӣёе…іж”ҝзӯ–жқҘжҺЁеҠЁж•°еӯ—з»ҸжөҺзҡ„еҸ‘еұ•е’Ңж•°еӯ—ж”ҝеәңзҡ„е»әи®ҫгҖӮиҝҷдәӣж”ҝзӯ–еҸҜиғҪеҢ…жӢ¬йј“еҠұдјҒдёҡж•°еӯ—еҢ–иҪ¬еһӢгҖҒдҝғиҝӣж•°еӯ—жҠҖжңҜеҲӣж–°гҖҒеҠ ејәж•°еӯ—еҹәзЎҖи®ҫж–Ҫе»әи®ҫгҖҒдјҳеҢ–ж•°еӯ—ж”ҝеҠЎжңҚеҠЎзӯүж–№йқўзҡ„еҶ…е®№гҖӮж”ҝзӯ–еҲ¶е®ҡзҡ„йў‘зҺҮе’ҢеҠӣеәҰпјҢеҸҜд»ҘеңЁдёҖе®ҡзЁӢеәҰдёҠеҸҚжҳ ж”ҝеәңеҜ№ж•°еӯ—йўҶеҹҹзҡ„е…іжіЁеәҰгҖӮ еңЁең°зә§еёӮж”ҝеәңж•°еӯ—е…іжіЁеәҰзҡ„иғҢжҷҜдёӢпјҢиҜҚйў‘еҲҶжһҗжҲҗдёәдәҶдёҖз§Қжңүж•Ҳзҡ„е·Ҙе…·пјҢз”Ёд»ҘиЎЎйҮҸж”ҝеәңж–Ү件е’Ңе®Јдј иө„ж–ҷдёӯж¶үеҸҠж•°еӯ—жҠҖжңҜе’Ңж•°еӯ—еҢ–иҪ¬еһӢзӣёе…іиҜҚжұҮзҡ„йў‘ж¬ЎпјҢиҝӣиҖҢжҸӯзӨәж”ҝеәңеҜ№иҝҷдёҖйўҶеҹҹзҡ„е…іжіЁзЁӢеәҰе’ҢйҮҚи§Ҷж–№еҗ‘гҖӮ ж•°жҚ®еҗҚз§°пјҡең°зә§еёӮ-ж”ҝеәңж•°еӯ—е…іжіЁеәҰгҖҒиҜҚйў‘
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»ҶжҺўи®ЁдәҶеңЁAndroidе№іеҸ°дёҠиҝӣиЎҢеӣҫеғҸжЁЎжқҝеҢ№й…Қзҡ„жҠҖжңҜжҢ‘жҲҳе’Ңи§ЈеҶіж–№жЎҲпјҢзү№еҲ«жҳҜеңЁеӨ„зҗҶдёҚеҗҢе°әеҜёе’Ңж—ӢиҪ¬и§’еәҰзҡ„зӣ®ж Үзү©ж—¶зҡ„ж–№жі•гҖӮж–Үдёӯд»Ӣз»ҚдәҶдҪҝз”ЁOpenCVжһ„е»әеӣҫеғҸйҮ‘еӯ—еЎ”гҖҒеӨ„зҗҶж—ӢиҪ¬жЁЎжқҝд»ҘеҸҠеҲ©з”ЁNEONжҢҮд»ӨйӣҶдјҳеҢ–жҖ§иғҪзҡ„е…·дҪ“е®һзҺ°гҖӮжӯӨеӨ–пјҢж–Үз« иҝҳи®Ёи®әдәҶеңЁarmeabi-v7aе’Ңarm64-v8aиҝҷдёӨз§Қдё»иҰҒARMжһ¶жһ„дёӢзҡ„дјҳеҢ–жҠҖе·§пјҢеҰӮеҶ…еӯҳеҜ№йҪҗгҖҒSIMDжҢҮд»ӨдјҳеҢ–гҖҒRenderScript并иЎҢеӨ„зҗҶзӯүгҖӮдҪңиҖ…еҲҶдә«дәҶи®ёеӨҡе®һи·өз»ҸйӘҢпјҢеҢ…жӢ¬еҰӮдҪ•йҒҝе…Қеёёи§Ғзҡ„жҖ§иғҪ瓶йўҲе’Ңе…је®№жҖ§й—®йўҳгҖӮ йҖӮеҗҲдәәзҫӨпјҡжңүдёҖе®ҡAndroidејҖеҸ‘з»ҸйӘҢпјҢе°Өе…¶жҳҜзҶҹжӮүOpenCVе’ҢNDKзј–зЁӢзҡ„дёӯзә§еҸҠд»ҘдёҠејҖеҸ‘иҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒеңЁз§»еҠЁи®ҫеӨҮдёҠиҝӣиЎҢй«ҳж•ҲеӣҫеғҸиҜҶеҲ«зҡ„еә”з”ЁејҖеҸ‘пјҢеҰӮе®һж—¶и§Ҷйў‘жөҒдёӯзҡ„зү©дҪ“жЈҖжөӢгҖҒжёёжҲҸеҶ…зҡ„йҒ“е…·иҜҶеҲ«зӯүгҖӮзӣ®ж ҮжҳҜжҸҗй«ҳжЁЎжқҝеҢ№й…Қзҡ„йҖҹеәҰе’ҢеҮҶзЎ®жҖ§пјҢеҗҢж—¶зЎ®дҝқеңЁдёҚеҗҢ硬件й…ҚзҪ®дёӢзҡ„зЁіе®ҡжҖ§е’Ңе…је®№жҖ§гҖӮ е…¶д»–иҜҙжҳҺпјҡж–Үз« жҸҗдҫӣдәҶдё°еҜҢзҡ„д»Јз ҒзүҮж®өе’Ңе®һйҷ…жЎҲдҫӢпјҢеё®еҠ©иҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’Ңеә”з”ЁжүҖд»Ӣз»Қзҡ„жҠҖжңҜгҖӮзү№еҲ«ејәи°ғдәҶеңЁдёҚеҗҢARMжһ¶жһ„дёӢзҡ„дјҳеҢ–зӯ–з•ҘпјҢдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶе®қиҙөзҡ„еҸӮиҖғиө„ж–ҷгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮжҺўи®ЁдәҶдёҖз§Қж”№иҝӣзҡ„зІ’еӯҗзҫӨдјҳеҢ–пјҲPSOпјүз®—жі•еңЁеҫ®з”өзҪ‘еӨҡзӣ®ж ҮдјҳеҢ–и°ғеәҰдёӯзҡ„еә”з”ЁгҖӮдј з»ҹPSOеңЁи§ЈеҶіжӯӨзұ»еӨҚжқӮй—®йўҳж—¶еёёйҷ·е…ҘеұҖйғЁжңҖдјҳи§ЈпјҢиҖҢж”№иҝӣзүҲйҖҡиҝҮеј•е…ҘеҠЁжҖҒжғҜжҖ§еӣ еӯҗе’ҢиҮӘйҖӮеә”еҸҳејӮж“ҚдҪңпјҢжҳҫи‘—жҸҗеҚҮдәҶз®—жі•жҖ§иғҪгҖӮж–ҮдёӯиҜҰз»Ҷд»Ӣз»ҚдәҶиҝҷдёӨз§Қж”№иҝӣжҺӘж–Ҫзҡ„е…·дҪ“е®һзҺ°ж–№жі•еҸҠе…¶еҜ№з®—法收ж•ӣжҖ§е’Ңи§ЈиҙЁйҮҸзҡ„еҪұе“ҚгҖӮжӯӨеӨ–пјҢиҝҳеұ•зӨәдәҶиҜҘз®—жі•еңЁе®һйҷ…еҫ®з”өзҪ‘и°ғеәҰд»»еҠЎдёӯзҡ„иЎЁзҺ°пјҢзү№еҲ«жҳҜеңЁжқғиЎЎз»ҸжөҺжҲҗжң¬дёҺзҺҜеўғж•ҲзӣҠж–№йқўзҡ„иғҪеҠӣгҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢз”өеҠӣзі»з»ҹдјҳеҢ–гҖҒжҷәиғҪз”өзҪ‘з ”з©¶зҡ„дё“дёҡдәәеЈ«д»ҘеҸҠеҜ№иҝӣеҢ–з®—жі•ж„ҹе…ҙи¶Јзҡ„еӯҰиҖ…е’ҢжҠҖжңҜдәәе‘ҳгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒиҝӣиЎҢй«ҳж•ҲиғҪжәҗз®ЎзҗҶзҡ„еңәеҗҲпјҢеҰӮеҲҶеёғејҸеҸ‘з”өзі»з»ҹзҡ„规еҲ’дёҺиҝҗиЎҢгҖӮдё»иҰҒзӣ®зҡ„жҳҜеҜ»жүҫж—ўиғҪйҷҚдҪҺжҲҗжң¬еҸҲиғҪеҮҸе°‘зҺҜеўғжұЎжҹ“зҡ„жңҖдҪіи°ғеәҰж–№жЎҲгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯжҸҗдҫӣдәҶеӨ§йҮҸдјӘд»Јз ҒзүҮж®өеё®еҠ©иҜ»иҖ…зҗҶи§Је…·дҪ“зҡ„жҠҖжңҜз»ҶиҠӮпјҢ并ејәи°ғдәҶеҸӮж•°и°ғиҠӮеҜ№дәҺжңҖз»Ҳз»“жһңзҡ„йҮҚиҰҒжҖ§гҖӮеҗҢж—¶жҢҮеҮәпјҢиҜҘж–№жі•дёҚд»…йҷҗдәҺеҫ®з”өзҪ‘йўҶеҹҹпјҢиҝҳеҸҜд»Ҙжү©еұ•еә”з”ЁдәҺе…¶д»–зұ»еһӢзҡ„дјҳеҢ–й—®йўҳгҖӮ
Delphi 12.3жҺ§д»¶д№ӢTeeChart Offline Keygen.7z
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҰӮдҪ•еҲ©з”ЁMATLABиҝӣиЎҢеұҲе…үеәҰи®Ўз®—еҸҠе…¶ж•°жҚ®еӨ„зҗҶж–№жі•гҖӮйҰ–е…Ҳи§ЈйҮҠдәҶеұҲе…үеәҰзҡ„еҹәжң¬жҰӮеҝөе’Ңи®Ўз®—е…¬ејҸпјҢжҺҘзқҖеұ•зӨәдәҶеҰӮдҪ•йҖҡиҝҮMATLABд»Јз ҒиҜ»еҸ–гҖҒжё…зҗҶе’ҢиҪ¬жҚўз„Ұи·қж•°жҚ®дёәеұҲе…үеәҰпјҢ并иҝӣиЎҢдәҶеҝ…иҰҒзҡ„еҚ•дҪҚиҪ¬жҚўгҖӮй’ҲеҜ№еҸҜиғҪеҮәзҺ°зҡ„ејӮеёёеҖје’ҢеҷӘеЈ°пјҢж–ҮдёӯжҸҗдҫӣдәҶжңүж•Ҳзҡ„ж•°жҚ®жё…жҙ—жүӢж®өгҖӮжӯӨеӨ–пјҢиҝҳжҺўи®ЁдәҶеҰӮдҪ•еҜ№еұҲе…үеәҰж•°жҚ®иҝӣиЎҢз»ҹи®ЎеҲҶжһҗд»ҘеҸҠеҸҜи§ҶеҢ–е‘ҲзҺ°пјҢеҰӮз»ҳеҲ¶и¶ӢеҠҝеӣҫе’Ңж•ЈзӮ№еӣҫзӯүгҖӮжңҖеҗҺпјҢжҸҗеҲ°дәҶе°ҶMATLABд»Јз ҒиҪ¬еҢ–дёәC++д»Јз Ғд»ҘдҫҝйӣҶжҲҗеҲ°зЎ¬д»¶зі»з»ҹзҡ„й«ҳзә§еә”з”ЁгҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢе…үеӯҰз ”з©¶гҖҒзңјз§‘еҢ»з–—и®ҫеӨҮејҖеҸ‘зҡ„жҠҖжңҜдәәе‘ҳпјҢд»ҘеҸҠеҜ№MATLABжңүе…ҙи¶Јзҡ„еӯҰд№ иҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒзІҫзЎ®еӨ„зҗҶе’ҢеҲҶжһҗе…үеӯҰж•°жҚ®зҡ„з ”з©¶жңәжһ„жҲ–дјҒдёҡпјҢж—ЁеңЁжҸҗй«ҳеұҲе…үеәҰи®Ўз®—зҡ„ж•ҲзҺҮе’ҢеҮҶзЎ®жҖ§пјҢзЎ®дҝқж•°жҚ®иҙЁйҮҸзҡ„еҗҢж—¶дјҳеҢ–е®һйӘҢз»“жһңгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯдёҚд»…ж¶өзӣ–дәҶеҹәжң¬зҡ„ж“ҚдҪңжӯҘйӘӨпјҢиҝҳеҢ…жӢ¬дәҶи®ёеӨҡе®һз”Ёзҡ„е°ҸиҙҙеЈ«е’ҢжҠҖжңҜз»ҶиҠӮпјҢжңүеҠ©дәҺиҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’ҢжҺҢжҸЎзӣёе…іеҶ…е®№гҖӮеҗҢж—¶ејәи°ғдәҶеҚ•дҪҚдёҖиҮҙжҖ§зҡ„йҮҚиҰҒжҖ§пјҢжҸҗйҶ’ејҖеҸ‘иҖ…жіЁж„ҸжҪңеңЁзҡ„й—®йўҳгҖӮ
349421c2-4955-4132-b4da-808a3a171bfe.pdf
1744300906657718_download.jsp
гҖҗеҶ…е®№жҰӮиҰҒгҖ‘ жң¬ж–ҮиҜҰз»Ҷи§ЈжһҗдәҶдјҒдёҡзӯӣйҖүз®ҖеҺҶзҡ„вҖңдёүйҮҚй—ЁвҖқзі»з»ҹпјҢеҢ…жӢ¬ATSзі»з»ҹеҲқзӯӣгҖҒHRеӨҚж ёе’ҢдёҡеҠЎйғЁй—Ёз»ҲжһҒиҜ„дј°дёүдёӘйҳ¶ж®өгҖӮйҰ–е…ҲпјҢATSзі»з»ҹдҪңдёәе…ій”®иҜҚеҢ№й…Қеј•ж“ҺпјҢејәи°ғдәҶе…ій”®иҜҚзҡ„йҮҚиҰҒжҖ§еҸҠе…¶дјҳеҢ–ж–№жі•пјӣе…¶ж¬ЎпјҢHRеңЁ6з§’еҶ…йҖҡиҝҮвҖңи–„зүҮеҲӨж–ӯвҖқиҜ„дј°з®ҖеҺҶзҡ„иҒҢдёҡиҝһиҙҜжҖ§гҖҒжҲҗе°ұйҮҸеҢ–е’ҢеІ—дҪҚеҢ№й…ҚеәҰпјӣжңҖеҗҺпјҢдёҡеҠЎйғЁй—ЁеҲҷдҫ§йҮҚдәҺжҠҖжңҜиғҪеҠӣе’Ңж–ҮеҢ–йҖӮй…ҚжҖ§зҡ„з»јеҗҲиҜ„дј°гҖӮж–Үз« иҝҳжҸӯзӨәдәҶеҗ„зҺҜиҠӮдёӯзҡ„еҝғзҗҶеӯҰеҺҹзҗҶе’Ңи®ӨзҹҘеҒҸе·®пјҢ并жҸҗдҫӣдәҶй’ҲеҜ№жҖ§зҡ„дјҳеҢ–е»әи®®гҖӮ гҖҗйҖӮеҗҲдәәзҫӨгҖ‘ жӯЈеңЁжұӮиҒҢжҲ–жңүжұӮиҒҢжү“з®—зҡ„иҒҢеңәдәәеЈ«пјҢе°Өе…¶жҳҜеёҢжңӣжҸҗеҚҮз®ҖеҺҶйҖҡиҝҮзҺҮзҡ„жұӮиҒҢиҖ…гҖӮ гҖҗдҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮгҖ‘ в‘ её®еҠ©жұӮиҒҢиҖ…зҗҶи§ЈдјҒдёҡзӯӣйҖүз®ҖеҺҶзҡ„е…·дҪ“жөҒзЁӢпјӣ в‘ЎжҸҗдҫӣз®ҖеҺҶдјҳеҢ–зҡ„е…·дҪ“ж–№жі•пјҢеҰӮе…ій”®иҜҚдјҳеҢ–гҖҒжҲҗе°ұйҮҸеҢ–гҖҒжЎҲдҫӢеҮҶеӨҮзӯүпјӣ в‘ўжҢҮеҜјжұӮиҒҢиҖ…еҰӮдҪ•ж №жҚ®дёҚеҗҢйҳ¶ж®өзҡ„иҜ„е®Ўзү№зӮ№и°ғж•ҙз®ҖеҺҶеҶ…е®№гҖӮ гҖҗе…¶д»–иҜҙжҳҺгҖ‘ ж–Үз« з»“еҗҲдәҶжңҖж–°зҡ„жӢӣиҒҳи¶ӢеҠҝз ”з©¶жҠҘе‘Ҡе’ҢеҝғзҗҶеӯҰзҗҶи®әпјҢејәи°ғз®ҖеҺҶдёҚд»…жҳҜйҖҡиҝҮзӯӣйҖүзҡ„е·Ҙе…·пјҢжӣҙжҳҜеұ•зӨәдёӘдәәиғҪеҠӣе’Ңд»·еҖјзҡ„е№іеҸ°гҖӮжұӮиҒҢиҖ…еә”е……еҲҶеҲ©з”ЁиҝҷдәӣеҝғзҗҶ规еҫӢпјҢжү“йҖ жӣҙе…·еҗёеј•еҠӣзҡ„з®ҖеҺҶпјҢдёәеҗҺз»ӯйқўиҜ•еҒҡеҘҪй“әеһ«гҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶдҪҝз”ЁPFC2D5.0иҝӣиЎҢдәҢз»ҙеІ©зҹіеҚ•иҪҙеҺӢзј©жЁЎжӢҹзҡ„е…·дҪ“ж–№жі•е’Ңд»Јз Ғе®һзҺ°гҖӮйҰ–е…ҲпјҢйҖҡиҝҮи®ҫе®ҡжЁЎеһӢзҡ„еҹәжң¬еҸӮж•°еҰӮйў—зІ’з”ҹжҲҗгҖҒзІҳз»“и®ҫзҪ®гҖҒеҠ иҪҪжҺ§еҲ¶зӯүпјҢжһ„е»әдәҶдёҖдёӘе®Ңж•ҙзҡ„еІ©зҹіж ·е“ҒжЁЎеһӢгҖӮжҺҘзқҖпјҢж·ұе…ҘжҺўи®ЁдәҶеҠ иҪҪиҝҮзЁӢдёӯеә”еҠӣеә”еҸҳжӣІзәҝзҡ„еҸҳеҢ–规еҫӢд»ҘеҸҠиғҪйҮҸеҲҶжһҗзҡ„ж–№жі•пјҢеҢ…жӢ¬еј№жҖ§еә”еҸҳиғҪгҖҒеҠЁиғҪе’ҢиҖ—ж•ЈиғҪзҡ„зӣ‘жөӢгҖӮжӯӨеӨ–пјҢиҝҳжҸҗдҫӣдәҶиЈӮйҡҷз»ҹи®Ўзҡ„жҠҖжңҜжүӢж®өпјҢиғҪеӨҹзІҫзЎ®жҚ•жҚүеІ©зҹіеҶ…йғЁиЈӮйҡҷзҡ„еҸ‘еұ•жғ…еҶөгҖӮжңҖеҗҺпјҢејәи°ғдәҶеҸӮж•°и°ғж•ҙеҜ№жЁЎжӢҹж•Ҳжһңзҡ„еҪұе“ҚпјҢ并з»ҷеҮәдәҶдјҳеҢ–е»әи®®гҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢеІ©еңҹе·ҘзЁӢгҖҒең°иҙЁеҠӣеӯҰз ”з©¶зҡ„дё“дёҡдәәеЈ«е’ҢжҠҖжңҜзҲұеҘҪиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒж·ұе…ҘдәҶи§ЈеІ©зҹіеҠӣеӯҰзү№жҖ§зҡ„з ”з©¶дәәе‘ҳпјҢеё®еҠ©д»–们жҺҢжҸЎPFC2DиҪҜ件зҡ„еә”з”ЁжҠҖе·§пјҢжҸҗеҚҮз§‘з ”иғҪеҠӣгҖӮеҗҢж—¶пјҢд№ҹдёәзӣёе…ійўҶеҹҹзҡ„еӯҰз”ҹжҸҗдҫӣдәҶдёҖеҘ—е®һз”Ёзҡ„еӯҰд№ иө„ж–ҷгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯжҸҗдҫӣзҡ„д»Јз ҒеҸҜд»ҘзӣҙжҺҘеә”з”ЁдәҺPFC2D5.0зҺҜеўғпјҢдҫҝдәҺз”ЁжҲ·еҝ«йҖҹдёҠжүӢ并иҝӣиЎҢе®һйӘҢйӘҢиҜҒгҖӮйҖҡиҝҮеҜ№дёҚеҗҢеҸӮж•°зҡ„и°ғж•ҙпјҢеҸҜд»ҘжЁЎжӢҹеӨҡз§Қзұ»еһӢзҡ„еІ©зҹіз ҙеқҸиЎҢдёәпјҢдёәе®һйҷ…е·ҘзЁӢйЎ№зӣ®жҸҗдҫӣзҗҶи®әж”ҜжҢҒгҖӮ
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҰӮдҪ•дҪҝз”ЁFluentиҝӣиЎҢжҝҖе…үз„ҠжҺҘзҡ„ж•°еҖјжЁЎжӢҹпјҢйҮҚзӮ№и®Іи§ЈдәҶй”ҘеҪўй«ҳж–Ҝзғӯжәҗзҡ„е»әжЁЎж–№жі•гҖӮж–Үз« йҰ–е…Ҳи§ЈйҮҠдәҶй”ҘеҪўй«ҳж–Ҝзғӯжәҗзҡ„зү№зӮ№еҸҠе…¶дёҺжҷ®йҖҡй«ҳж–Ҝзғӯжәҗзҡ„еҢәеҲ«пјҢ然еҗҺз»ҷеҮәдәҶе…·дҪ“зҡ„UDFд»Јз Ғе®һзҺ°пјҢеҢ…жӢ¬зғӯжәҗејәеәҰзҡ„и®Ўз®—гҖҒзғӯжөҒиЎ°еҮҸзҡ„жҺ§еҲ¶д»ҘеҸҠзғӯжәҗ移еҠЁзҡ„е®һзҺ°гҖӮжӯӨеӨ–пјҢиҝҳи®Ёи®әдәҶзҪ‘ж јеҲ’еҲҶгҖҒжқҗж–ҷеҸӮж•°и®ҫзҪ®гҖҒеёёи§Ғй”ҷиҜҜжҺ’жҹҘе’ҢдјҳеҢ–жҠҖе·§зӯүж–№йқўзҡ„еҶ…е®№гҖӮйҖҡиҝҮе®һдҫӢе’Ңж“ҚдҪңи§Ҷйў‘пјҢеё®еҠ©иҜ»иҖ…еҝ«йҖҹжҺҢжҸЎжҝҖе…үз„ҠжҺҘж•°еҖјжЁЎжӢҹзҡ„ж–№жі•е’ҢжҠҖжңҜиҰҒзӮ№гҖӮ йҖӮеҗҲдәәзҫӨпјҡе…·жңүдёҖе®ҡCFDеҹәзЎҖ并еёҢжңӣж·ұе…ҘеӯҰд№ жҝҖе…үз„ҠжҺҘж•°еҖјжЁЎжӢҹзҡ„з ”з©¶дәәе‘ҳе’Ңе·ҘзЁӢеёҲгҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒзІҫзЎ®жЁЎжӢҹжҝҖе…үз„ҠжҺҘиҝҮзЁӢзҡ„з ”з©¶йЎ№зӣ®жҲ–е·Ҙдёҡеә”з”ЁпјҢж—ЁеңЁжҸҗй«ҳжЁЎжӢҹзІҫеәҰпјҢеҮҸе°‘иҜ•йӘҢжҲҗжң¬пјҢдјҳеҢ–з„ҠжҺҘе·ҘиүәеҸӮж•°гҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯжҸҗдҫӣдәҶеӨ§йҮҸе®һз”Ёзҡ„ж“ҚдҪңжҠҖе·§е’ҢжіЁж„ҸдәӢйЎ№пјҢеҰӮзҪ‘ж јеҲ’еҲҶе»әи®®гҖҒжқҗж–ҷеҸӮж•°йҖүжӢ©гҖҒUDFд»Јз Ғи°ғиҜ•зӯүпјҢжңүеҠ©дәҺи§ЈеҶіе®һйҷ…ж“ҚдҪңдёӯеҸҜиғҪйҒҮеҲ°зҡ„й—®йўҳгҖӮеҗҢж—¶пјҢйҷ„еёҰзҡ„ж“ҚдҪңи§Ҷйў‘е’ҢGitHubдёҠзҡ„е®Ңж•ҙжЎҲдҫӢеҢ…д№ҹдёәеҲқеӯҰиҖ…жҸҗдҫӣдәҶе®қиҙөзҡ„еӯҰд№ иө„жәҗгҖӮ
еәҸеҲ—еҢ–.md
"ResumePlatformFront 笔иҜ•йқўиҜ•е…Ёж”»з•ҘдёҺиө„жәҗе®қе…ё"вҖ”вҖ”дёҖз«ҷејҸеүҚз«ҜжұӮиҒҢи§ЈеҶіж–№жЎҲпјҒзІҫйҖүй«ҳ频笔иҜ•зңҹйўҳи§ЈжһҗгҖҒеӨ§еҺӮйқўиҜ•з»ҸйӘҢеҲҶдә«гҖҒе®һжҲҳйЎ№зӣ®жЁЎжқҝеҸҠжҠҖиғҪиҝӣйҳ¶жҢҮеҚ—пјҢеҠ©дҪ зі»з»ҹж”»е…ӢеүҚз«ҜжұӮиҒҢйҡҫе…ігҖӮд»Һз®ҖеҺҶдјҳеҢ–еҲ°Offerи°ҲеҲӨпјҢиҰҶзӣ–жұӮиҒҢе…ЁжөҒзЁӢпјҢй…ҚеҘ—е…Қиҙ№иө„жәҗеә“жҢҒз»ӯжӣҙж–°гҖӮж— и®әеә”еұҠз”ҹиҝҳжҳҜиҝӣйҳ¶ејҖеҸ‘иҖ…пјҢиҝҷйҮҢйғҪжҳҜдҪ ж–©иҺ·еҝғд»ӘOfferзҡ„ејәеҠӣеҗҺзӣҫпјҒ
weixin205еҫ®дҝЎе°ҸзЁӢеәҸзәҝдёҠж•ҷиӮІе•ҶеҹҺssm(ж–ҮжЎЈ+жәҗз Ғ)_kaic
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҰӮдҪ•еҲ©з”ЁCOMSOLиҪҜ件жһ„е»әеІ©зҹіжҚҹдјӨдёҺжё©еәҰгҖҒжё—жөҒиҖҰеҗҲзҡ„еӨҡзү©зҗҶеңәжЁЎеһӢгҖӮйҰ–е…Ҳи§ЈйҮҠдәҶжё©еәҰеҸҳеҢ–еј•иө·еІ©зҹіиҶЁиғҖ/收缩д»ҘеҸҠжё—жөҒеҺӢеҠӣж”№еҸҳиЈӮзә№еҸ‘еұ•зҡ„зү©зҗҶжңәеҲ¶пјҢ并йҖҡиҝҮPDEж–№зЁӢз»„иҝӣиЎҢжҸҸиҝ°гҖӮжҺҘзқҖеұ•зӨәдәҶе…·дҪ“зҡ„е®һзҺ°ж–№жі•пјҢеҰӮе®ҡд№үжҚҹдјӨеҸҳйҮҸгҖҒи®ҫзҪ®еҜјзғӯзі»ж•°е’Ңжё—йҖҸзҺҮйҡҸжҚҹдјӨеҸҳеҢ–зҡ„е…ізі»пјҢд»ҘеҸҠеј•е…Ҙжё©еәҰдҝ®жӯЈзҡ„Mohr-CoulombеҮҶеҲҷгҖӮж–Үдёӯиҝҳи®Ёи®әдәҶжұӮи§ЈеҷЁй…ҚзҪ®жҠҖе·§пјҢејәи°ғдәҶйқһзәҝжҖ§ж”¶ж•ӣй—®йўҳзҡ„и§ЈеҶіж–№жЎҲгҖӮжӯӨеӨ–пјҢдҪңиҖ…еҲҶдә«дәҶдёҖдәӣе®һйҷ…е»әжЁЎиҝҮзЁӢдёӯйҒҮеҲ°зҡ„й—®йўҳеҸҠи§ЈеҶіз»ҸйӘҢпјҢеҰӮеҸӮж•°йҖүжӢ©дёҚеҪ“еҜјиҮҙзҡ„жЁЎеһӢеҸ‘ж•ЈзӯүгҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢеІ©еңҹе·ҘзЁӢгҖҒең°иҙЁе·ҘзЁӢеҸҠзӣёе…ійўҶеҹҹзҡ„з ”з©¶дәәе‘ҳе’ҢжҠҖжңҜдәәе‘ҳпјҢзү№еҲ«жҳҜеҜ№еӨҡзү©зҗҶеңәиҖҰеҗҲд»ҝзңҹж„ҹе…ҙи¶Јзҡ„еӯҰиҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺйңҖиҰҒж·ұе…ҘзҗҶи§ЈеІ©зҹіеңЁжё©еәҰгҖҒжё—жөҒе’Ңеә”еҠӣе…ұеҗҢдҪңз”ЁдёӢзҡ„жҚҹдјӨжј”еҢ–规еҫӢзҡ„з ”з©¶йЎ№зӣ®гҖӮзӣ®ж ҮжҳҜеё®еҠ©иҜ»иҖ…жҺҢжҸЎCOMSOLдёӯеӨҡзү©зҗҶеңәиҖҰеҗҲжЁЎеһӢзҡ„е»әз«Ӣж–№жі•пјҢжҸҗй«ҳж•°еҖјжЁЎжӢҹзҡ„еҮҶзЎ®жҖ§гҖӮ е…¶д»–иҜҙжҳҺпјҡж–Үз« дёҚд»…жҸҗдҫӣдәҶзҗҶи®әиғҢжҷҜпјҢиҝҳеҢ…жӢ¬еӨ§йҮҸе®һз”Ёзҡ„д»Јз ҒзүҮж®өе’Ңи°ғиҜ•е»әи®®пјҢжңүеҠ©дәҺиҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’Ңеә”з”ЁжүҖеӯҰзҹҘиҜҶгҖӮ
2023-04-06-йЎ№зӣ®з¬”и®°-第еӣӣзҷҫе…ӯеҚҒеӣӣйҳ¶ж®ө-иҜҫеүҚе°ҸеҲҶдә«_е°ҸеҲҶдә«1.еқҡжҢҒжҸҗдәӨgitee е°ҸеҲҶдә«2.дҪңдёҡдёӯжҸҗдәӨд»Јз Ғ е°ҸеҲҶдә«3.еҶҷд»Јз ҒжіЁж„Ҹд»Јз ҒйЈҺж ј 4.3.1еҸҳйҮҸзҡ„дҪҝз”Ё 4.4еҸҳйҮҸзҡ„дҪңз”ЁеҹҹдёҺз”ҹе‘Ҫе‘Ёжңҹ 4.4.1еұҖйғЁеҸҳйҮҸзҡ„дҪңз”Ёеҹҹ 4.4.2е…ЁеұҖеҸҳйҮҸзҡ„дҪңз”Ёеҹҹ 4.4.2.1е…ЁеұҖеҸҳйҮҸзҡ„дҪңз”Ёеҹҹ_1 4.4.2.462еұҖеҸҳйҮҸзҡ„дҪңз”Ёеҹҹ_462- 2025-04-10
еҶ…е®№жҰӮиҰҒпјҡжң¬ж–ҮиҜҰз»Ҷд»Ӣз»ҚдәҶеҹәдәҺж»‘иҶңи§ӮжөӢеҷЁзҡ„ж°ёзЈҒеҗҢжӯҘз”өжңәпјҲPMSMпјүж— дј ж„ҹеҷЁжҺ§еҲ¶жҠҖжңҜеҸҠе…¶еңЁMATLAB/Simulinkдёӯзҡ„д»ҝзңҹе®һзҺ°гҖӮйҰ–е…Ҳйҳҗиҝ°дәҶPMSMзҡ„зү№зӮ№еҸҠе…¶еңЁзҺ°д»Је·Ҙдёҡдёӯзҡ„йҮҚиҰҒең°дҪҚпјҢжҺҘзқҖйҮҚзӮ№и®Іи§ЈдәҶиҪ¬еӯҗзЈҒеңәе®ҡеҗ‘зҹўйҮҸжҺ§еҲ¶пјҲFOCпјүзҡ„е·ҘдҪңеҺҹзҗҶпјҢзү№еҲ«жҳҜз”өжөҒзҺҜзҡ„и®ҫи®Ўе’Ңз”өеҺӢи§ЈиҖҰзҡ„дҪңз”ЁгҖӮ然еҗҺж·ұе…ҘжҺўи®ЁдәҶдёҖйҳ¶ж»‘иҶңи§ӮжөӢеҷЁзҡ„е®һзҺ°ж–№жі•пјҢеұ•зӨәдәҶеҰӮдҪ•йҖҡиҝҮз”өжңәзҡ„з”өеҺӢе’Ңз”өжөҒдҝЎеҸ·дј°и®ЎиҪ¬еӯҗдҪҚзҪ®е’ҢйҖҹеәҰгҖӮжңҖеҗҺпјҢйҖҡиҝҮжҗӯе»әе®Ңж•ҙзҡ„Simulinkд»ҝзңҹжЁЎеһӢ并иҝҗиЎҢд»ҝзңҹпјҢиҜ„дј°дәҶжҺ§еҲ¶зӯ–з•Ҙзҡ„жҖ§иғҪпјҢ并жҸҗдҫӣдәҶй…ҚеҘ—зҡ„иӢұж–Үж–ҮзҢ®д»ҘдҫӣиҝӣдёҖжӯҘз ”з©¶гҖӮ йҖӮеҗҲдәәзҫӨпјҡд»ҺдәӢз”өжңәжҺ§еҲ¶зі»з»ҹи®ҫи®Ўзҡ„з ”еҸ‘е·ҘзЁӢеёҲе’ҢжҠҖжңҜзҲұеҘҪиҖ…пјҢе°Өе…¶жҳҜеҜ№ж— дј ж„ҹеҷЁжҺ§еҲ¶жҠҖжңҜе’Ңж»‘иҶңи§ӮжөӢеҷЁж„ҹе…ҙи¶Јзҡ„иҜ»иҖ…гҖӮ дҪҝз”ЁеңәжҷҜеҸҠзӣ®ж ҮпјҡйҖӮз”ЁдәҺеёҢжңӣж·ұе…ҘдәҶи§ЈPMSMж— дј ж„ҹеҷЁжҺ§еҲ¶жҠҖжңҜзҡ„е·ҘзЁӢеёҲпјҢж—ЁеңЁеё®еҠ©д»–们жҺҢжҸЎж»‘иҶңи§ӮжөӢеҷЁзҡ„и®ҫи®Ўе’Ңе®һзҺ°пјҢжҸҗй«ҳзі»з»ҹзҡ„еҸҜйқ жҖ§е’ҢйҷҚдҪҺжҲҗжң¬гҖӮеҗҢж—¶пјҢд№ҹдёәеҗҺз»ӯзҡ„е®һйҷ…еә”з”Ёе’ҢдјҳеҢ–жҸҗдҫӣдәҶзҗҶи®әдҫқжҚ®е’ҢжҠҖжңҜж”ҜжҢҒгҖӮ е…¶д»–иҜҙжҳҺпјҡж–ҮдёӯжҸҗдҫӣзҡ„д»Јз ҒзүҮж®өе’Ңд»ҝзңҹжЁЎеһӢжңүеҠ©дәҺиҜ»иҖ…жӣҙеҘҪең°зҗҶи§Је’Ңе®һи·өзӣёе…іжҠҖжңҜпјҢиҖҢй…ҚеҘ—зҡ„иӢұж–Үж–ҮзҢ®еҲҷдёәж·ұе…Ҙз ”з©¶жҸҗдҫӣдәҶе®қиҙөзҡ„еҸӮиҖғиө„ж–ҷгҖӮ