gxsenjoy
- 浏览: 9939 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
转自:
http://www.blogjava.net/decode360/archive/2009/07/14/287767.html
说到HWM,我们首先要简要的谈谈ORACLE的逻辑存储管理.我们知道,ORACLE在逻辑存储上分4个粒度:表空间,段,区和块.
(1)块:是粒度最小的存储单位,现在标准的块大小是8K,ORACLE每一次I/O操作也是按块来操作的,也就是说当ORACLE从数据文件读数据时,是读取多少个块,而不是多少行.
(2)区:由一系列相邻的块而组成,这也是ORACLE空间分配的基本单位,举个例子来说,当我们创建一个表PM_USER时,首先ORACLE会分配一区的空间给这个表,随着不断的INSERT数据到PM_USER,原来的这个区容不下插入的数据时,ORACLE是以区为单位进行扩展的,也就是说再分配多少个区给PM_USER,而不是多少个块.
(3)段:是由一系列的区所组成,一般来说,当创建一个对象时(表,索引),就会分配一个段给这个对象.所以从某种意义上来说,段就是某种特定的数据.如CREATE TABLE PM_USER,这个段就是数据段,而CREATE INDEX ON PM_USER(NAME),ORACLE同样会分配一个段给这个索引,但这是一个索引段了.查询段的信息可以通过数据字典: SELECT * FROM USER_SEGMENTS来获得,
(4)表空间:包含段,区及块.表空间的数据物理上储存在其所在的数据文件中.一个数据库至少要有一个表空间.
OK,我们现在回到HWM上来,那么,什么是高水位标记呢?这就跟ORACLE的段空间管理相关了.
(一)ORACLE用HWM来界定一个段中使用的块和未使用的块.
举个例子来说,当我们创建一个表:PT_SCHE_DETAIL时,ORACLE就会为这个对象分配一个段.在这个段中,即使我们未插入任何记录,也至少有一个区被分配,第一个区的第一个块就称为段头(SEGMENT HEADE),段头中就储存了一些信息,基中HWM的信息就存储在此.此时,因为第一个区的第一块用于存储段头的一些信息,虽然没有存储任何实际的记录,但也算是被使用,此时HWM是位于第2个块.当我们不断插入数据到PM_USER后,第1个块已经放不下后面新插入的数据,此时,ORACLE将高水位之上的块用于存储新增数据,同时,HWM本身也向上移.也就是说,当我们不断插入数据时,HWM会往不断上移,这样,在HWM之下的,就表示使用过的块,HWM之上的就表示已分配但从未使用过的块.
(二)HWM在插入数据时,当现有空间不足而进行空间的扩展时会向上移,但删除数据时不会往下移.
这就好比是水库的水位,当涨水时,水位往上移,当水退出后,最高水位的痕迹还是清淅可见.
考虑让我们看一个段,如一张表,其中填满了块,如图 1 所示。在正常操作过程中,删除了一些行,如图 2 所示。现有就有了许多浪费的空间:(I) 在表的上一个末端和现有的块之间,以及 (II) 在块内部,其中还有一些没有删除的行。

HWM01
图1:分配给该表的块。用灰色正方形表示行
ORACLE 不会释放空间以供其他对象使用,有一条简单的理由:由于空间是为新插入的行保留的,并且要适应现有行的增长。被占用的最高空间称为最高使用标记 (HWM),如图 2 所示。
HWM02
图2:行后面的块已经删除了;HWM 仍保持不变
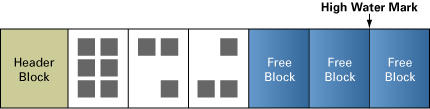
(三)HWM的信息存储在段头当中.
HWM本身的信息是储存在段头.在段空间是手工管理方式时,ORACLE是通过FREELIST(一个单向链表)来管理段内的空间分配.在段空间是自动管理方式时(ASSM),ORACLE是通过BITMAP来管理段内的空间分配.
(四)ORACLE的全表扫描是读取高水位标记(HWM)以下的所有块.
所以问题就产生了.当用户发出一个全表扫描时,ORACLE 始终必须从段一直扫描到 HWM,即使它什么也没有发现。该任务延长了全表扫描的时间。
(五)当用直接路径插入行时 — 例如,通过直接加载插入(用 APPEND 提示插入)或通过 SQL*LOADER 直接路径 — 数据块直接置于 HWM 之上。它下面的空间就浪费掉了。
我们来分析这两个问题,后者只是带来空间的浪费,但前者不仅是空间的浪费,而且会带来严重的性能问题.我们来看看下面的例子:
(A)我们先来搭建测试的环境,第一步先创建一个段空间为手工管理的表空间:
CREATE TABLESPACE "RAINNY"
LOGGING
DATAFILE 'D:ORACLE_HOMEORADATARAINNYRAINNY.ORA' SIZE 5M
AUTOEXTEND
ON NEXT 10M MAXSIZE UNLIMITED EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT MANUAL;
(B)创建一个表,注意,此表的第二个字段我故意设成是CHAR(100),以让此表在插入1千万条记录后,空间有足够大:
CREATE TABLE TEST_TAB(C1 NUMBER(10),C2 CHAR(100)) TABLESPACE RAINNY;
插入记录
DECLARE
I NUMBER(10);
BEGIN
FOR I IN 1..10000000 LOOP
INSERT INTO TEST_TAB VALUES(I,'TESTSTRING');
END LOOP;
COMMIT;
END;
/
(C)我们来查询一下,看在插入一千万条记录后所访问的块数和查询所用时间:
SQL> SET TIMING ON
SQL> SET AUTOTRACE TRACEONLY
SQL> SELECT COUNT(*) FROM TEST_TAB;
ELAPSED: 00:01:03.05
EXECUTION PLAN
------------------------------------------------------------
0 SELECT STATEMENT OPTIMIZER=CHOOSE (COST=15056 CARD=1)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST_TAB' (COST=15056 CARD=10000
000)
STATISTICS
----------------------------------------------------------
0 RECURSIVE CALLS
0 DB BLOCK GETS
156310 CONSISTENT GETS
154239 PHYSICAL READS
0 REDO SIZE
379 BYTES SENT VIA SQL*NET TO CLIENT
503 BYTES RECEIVED VIA SQL*NET FROM CLIENT
2 SQL*NET ROUNDTRIPS TO/FROM CLIENT
0 SORTS (MEMORY)
0 SORTS (DISK)
1 ROWS PROCESSED
我们来看上面的执行计划,这句SQL总供耗时是:1分3秒.访问方式是采用全表扫描方式(FTS),逻辑读了156310个BLOCK,物理读了154239个BLOCK.
我们来分析一下这个表:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=> 'TEST',
TABNAME=> 'TEST_TAB',
PARTNAME=> NULL);END;
/
发现这个表目前使用的BLOCK有: 156532,未使用的BLOCK(EMPTY_BLOCKS)为:0,总行数为(NUM_ROWS):1000 0000
(D)接下来我们把此表的记录用DELETE方式删掉,然后再来看看SELECT COUNT(*) FROM TEST_TAB所花的时间:
DELETE FROM TEST_TAB;
COMMIT;
SQL> SELECT COUNT(*) FROM TEST_TAB;
ELAPSED: 00:01:04.03
EXECUTION PLAN
----------------------------------------------------------
0 SELECT STATEMENT OPTIMIZER=CHOOSE (COST=15056 CARD=1)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST_TAB' (COST=15056 CARD=1)
STATISTICS
----------------------------------------------------------
0 RECURSIVE CALLS
0 DB BLOCK GETS
156310 CONSISTENT GETS
155565 PHYSICAL READS
0 REDO SIZE
378 BYTES SENT VIA SQL*NET TO CLIENT
503 BYTES RECEIVED VIA SQL*NET FROM CLIENT
2 SQL*NET ROUNDTRIPS TO/FROM CLIENT
0 SORTS (MEMORY)
0 SORTS (DISK)
1 ROWS PROCESSED
大家来看,在DELETE表后,此时表中已没有一条记录,为什么SELECT COUNT(*) FROM TEST_TAB花的时间为1分4秒, 反而比有记录稍微长点,这是为什么呢?而且大家看,其逻辑读了156310个 BLOCK,跟之前有一千万行记录时差不多,ORACLE怎么会这么笨啊?
我们在DELETE表后再次分析表,看看有什么变化:
这时, TEST_TAB表目前使用的BLOCK是: 156532,未使用的BLOCK(EMPTY_BLOCKS)为:0,总行数为(NUM_ROWS)已变成:0
为什么表目前使的BLOCK数还是156532呢?
问题的根源就在于ORACLE的HWM.也就是说,在新增记录时,HWM会慢慢往上移,但是在删除记录后,HWM却不会往下移,也就是说,DELETE一千万条记录后,此表的HWM根本没移动,还在原来的那个位置,所以,HWM以下的块数同样也是一样的.ORACLE的全表扫描是读取ORACLE高水位标记下的所有BLOCK,也就是说,不管HWM下的BLOCK现在实际有没有存放数据,ORACLE都会一一读取,这样,大家可想而知,在我们DELETE表后,ORACLE读了大量的空块,耗去了大量的时间.
我们再来看DELETE表后段空间实际使用的状况:
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................164352 --总共164352块
TOTAL BYTES.............................1346371584
UNUSED BLOCKS...........................7168 --有7168块没有用过,也就是在HWM上面的块数
UNUSED BYTES............................58720256
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................158856-- BLOCK ID 是针对数据文件来编号的,表示最后使用的一个EXTENT的第一个BLOCK的编号
LAST USED BLOCK.........................1024 --在最后使用的一个EXTENT 中一共用了1024块
PL/SQL PROCEDURE SUCCESSFULLY COMPLETED
总共用了164352块,除了一个SEGMENT HEADER,实际总共用了164351个块,有7168块从来没有使用过。LAST USED BLOCK表示在最后一个使用的EXTENT 中使用的BLOCK, 结合 LAST USED EXT BLOCK ID可以计算 HWM 位置 :
LAST USED EXT BLOCK ID + LAST USED BLOCK -1 = HWM 所在的数据文件的BLOCK编号
代入得出: 158856+1024-1=159879,这个就是HWM所有的BLOCK编号
HWM所在的块:TOTAL BLOCKS- UNUSED BLOCKS=164352-7168=157184,也就是说,HWM在第157184个块,其BLOCKID是159879
(E)结下来,我们再做几个试验:
第一步:执行ALTER TABLE TEST_TAB DEALLOCATE UNUSED;
我们看看段空间的使用状况:
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................157184
TOTAL BYTES.............................1287651328
UNUSED BLOCKS...........................0
UNUSED BYTES............................0
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................158856
LAST USED BLOCK.........................1024
此时我们再代入上面的公式,算出HWM的位置: 157184-0=157184 HWM所在的BLOCK ID是158856+1024-1=159879,跟刚刚的没有变化,也就是说执行ALTER TABLE TEST_TAB DEALLOCATE UNUSED后,段的高水位标记的位置没有改变,但是大家看看UNUSED BLOCKS变为0了,总的块数减少到157184,这证明,DEALLOCATE UNUSED为释放HWM上面的未使用空间,但是并不会释放HWM下面的自由空间,也不会移动HWM的位置.
第二步:我们再来看看执行ALTER TABLE TEST_TAB MOVE后段空间的使用状况:
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................8
TOTAL BYTES.............................65536
UNUSED BLOCKS...........................5
UNUSED BYTES............................40960
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................2632
LAST USED BLOCK.........................3
此时,总共用到的块数已变为8, 我们再代入上面的公式,算出HWM的位置: 8-5=3 HWM所在的BLOCK ID是2632+3-1=2634,
OK,我们发现,此时HWM的位置已经发生变化,现在HWM的位置是在第3个BLOCK,其BLOCK ID是2634,所有数据文件的ID是9(这个没有发生变化,数据文件还是原来的那个数据文件,只是释放了原来的自由空间),最后使用的块数也变为3,也就是说已经使用了3块,HWM就是在最后一个使用的块上,即第3个块上.大家可能会觉得奇怪,为什么释放空间后,未使用的块还有5个啊?也就是说HWM之上还是有5个已分配但从未使用的块.答案就跟HWM移动的规律有关.当我们在插入数据时,ORACLE首先在HWM之下的块当中定位自由空间(通过自由列表FREELIST),如果FREELIST当中没有自由块了,ORACLE就开始往上扩展,而HWM也跟着往上移,每5块移动一次.我们来看ORACLE的说明:
The high water mark is:
-Recorded in the segment header block
-Set to the beginning of the segment on the creation
-Incremented in five-block increments as rows are inserted
-Reset by the truncate command
-Never reset by the delete command
-Space above the high-water-mark can be reclaimed at the table level by using the following command:
ALTER TABLE DEALLOCATE UNUSED…
我们再来看看:SELECT COUNT(*) FROM TEST_TAB所花的时间:
SQL> SELECT COUNT(*) FROM TEST_TAB;
ELAPSED: 00:00:00.00
EXECUTION PLAN
----------------------------------------------------------
0 SELECT STATEMENT OPTIMIZER=CHOOSE
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST_TAB'
STATISTICS
----------------------------------------------------------
0 RECURSIVE CALLS
0 DB BLOCK GETS
3 CONSISTENT GETS
0 PHYSICAL READS
0 REDO SIZE
378 BYTES SENT VIA SQL*NET TO CLIENT
503 BYTES RECEIVED VIA SQL*NET FROM CLIENT
2 SQL*NET ROUNDTRIPS TO/FROM CLIENT
0 SORTS (MEMORY)
0 SORTS (DISK)
1 ROWS PROCESSED
很快,不到1秒.
我们最后再来对表作一次分析, 此时这个表目前使用的BLOCK为: 0,未使用的BLOCK(EMPTY_BLOCKS)为:0,总行数为(NUM_ROWS):0
从中我们也可以发现,分析表和SHOW_SPACE显示的数据有点不一致.那么哪个是准的呢?其实这两个都是准的,只不过计算的方法有点不同.事实上,当你创建了一个对象如表以后,不管你有没有插入数据,它都会占用一些块,ORACLE也会给它分配必要的空间.同样,用ALTER TABLE MOVE释放自由空间后,还是保留了一些空间给这个表.
最后,我们再来执行TRUNCATE命令,截断这个表,看看段空间的使用状况:
TRUNCATE TABLE TEST_TAB;
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................8
TOTAL BYTES.............................65536
UNUSED BLOCKS...........................5
UNUSED BYTES............................40960
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................2632
LAST USED BLOCK.........................3
PL/SQL PROCEDURE SUCCESSFULLY COMPLETED
SQL>
我们发现TRUNCATE后和MOVE没有什么变化.
为了,最终验证一下我上面的观点,我再DROP一下表,然后新建这个表,看看这时在没有插入任何数据之前,是否ORACLE确实有给这个对象分配必要的空间:
DROP TABLE TEST_TAB;
CREATE TABLE TEST_TAB(C1 NUMBER(10),C2 CHAR(100)) TABLESPACE RAINNY;
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................8
TOTAL BYTES.............................65536
UNUSED BLOCKS...........................5
UNUSED BYTES............................40960
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................2112
LAST USED BLOCK.........................3
大家看,即使我没有插入任何一行记录,ORACLE还是给它分配了8个块.当然这个跟建表语句的INITIAL 参数及MINEXTENTS参数有关:请看TEST_TAB的存储参数:
S TORAGE
(
INITIAL 64K
MINEXTENTS 1
MAXEXTENTS UNLIMITED
);
也就是说,在这个对象创建以后,ORACLE至少给它分配一个区,初始大小是64K,一个标准块的大小是8K,刚好是8个BLOCK.
总结:
在9I中:
(1)如果MINEXTENT 可以使ALTER TABLE TABLENAME DEALLOCATE UNUSED将HWM以上所有没使用的空间释放
(2)如果MINEXTENT >HWM 则释放MINEXTENTS 以上的空间。如果要释放HWM以上的空间则使用KEEP 0。
ALTER TABLE TABLESNAME DEALLOCATE UNUSED KEEP 0;
(3) TRUNCATE TABLE DROP STORAGE(缺省值)命令可以将MINEXTENT 之上的空间完全释放(交还给操作系统),并且重置HWM。
(4)如果仅是要移动HWM,而不想让表长时间锁住,可以用TRUNCATE TABLE REUSE STORAGE,仅将HWM重置。
(5)ALTER TABLE MOVE会将HWM移动,但在MOVE时需要双倍的表空间,而且如果表上有索引的话,需要重构索引
(6)DELETE表不会重置HWM,也不会释放自由的空间(也就是说DELETE空出来的空间只能给对象本身将来的INSERT/UPDATE使用,不能给其它的对象使用)
在ORACLE 10G:
可以使用ALTER TABLE TEST_TAB SHRINK SPACE命令来联机移动HWM,
如果要同时压缩表的索引,可以发布:ALTER TABLE TEST_TAB SHRINK SPACE CASCADE
注意:在使用此命令时需要先使行可迁移row movement(具体见例子)。
与使用ALTER TABLE MOVE 不同的是执行此命令后并不需要重构索引。
Oracle 官方说明
Shrinking Database Segments Online
You use online segment shrink to reclaim fragmented free space below the high water mark in an Oracle Database segment. The benefits of segment shrink are these:
* Compaction of data leads to better cache utilization, which in turn leads to better online transaction processing (OLTP) performance.
* The compacted data requires fewer blocks to be scanned in full table scans, which in turns leads to better decision support system (DSS) performance.
Segment shrink is an online, in-place operation. DML operations and queries can be issued during the data movement phase of segment shrink. Concurrent DML operation are blocked for a short time at the end of the shrink operation, when the space is deallocated. Indexes are maintained during the shrink operation and remain usable after the operation is complete. Segment shrink does not require extra disk space to be allocated.
Segment shrink reclaims unused space both above and below the high water mark. In contrast, space deallocation reclaims unused space only above the high water mark. In shrink operations, by default, the database compacts the segment, adjusts the high water mark, and releases the reclaimed space.
Segment shrink requires that rows be moved to new locations. Therefore, you must first enable row movement in the object you want to shrink and disable any rowid-based triggers defined on the object.
Shrink operations can be performed only on segments in locally managed tablespaces with automatic segment space management (ASSM). Within an ASSM tablespace, all segment types are eligible for online segment shrink except these:
* IOT mapping tables
* Tables with rowid based materialized views
* Tables with function-based indexes
操作的过程:
SQL> create table demo as select * from dba_source;
Table created.
Elapsed: 00:00:05.83
SQL> select count(*) from demo;
COUNT(*)
----------
210992
Elapsed: 00:00:01.06
SQL> insert into demo select * from demo;
210992 rows created.
Elapsed: 00:00:59.83
SQL> commit;
Commit complete.
//得到一个40万条记录的表,下面来查看这个表空间分布情况。
SQL> exec show_space('demo','auto');
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.07
SQL> set serveroutput on
SQL> exec show_space('demo','auto');
Total Blocks............................9216
Total Bytes.............................75497472
Unused Blocks...........................768
Unused Bytes............................6291456
Last Used Ext FileId....................4
Last Used Ext BlockId...................8328
Last Used Block.........................256
一共有9216个数据块,HWM在9216-768=8448这个块.
也可以通过查看extents得到HWM=8*16+128*63+256=8192+256=8448
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.01
SQL> delete from demo where rownum<220000;
219999 rows deleted.
Elapsed: 00:00:40.99
SQL> commit;
Commit complete.
Elapsed: 00:00:00.01
SQL> exec show_space('demo','auto');
Total Blocks............................9216
Total Bytes.............................75497472
Unused Blocks...........................768
Unused Bytes............................6291456
Last Used Ext FileId....................4
Last Used Ext BlockId...................8328
Last Used Block.........................256
PL/SQL procedure successfully completed.
//删除操作后表的HWM没有变化,还是在第8448块这个位置。
Elapsed: 00:00:00.00
SQL> alter table demo shrink space;
alter table demo shrink space
*
ERROR at line 1:
ORA-10636: ROW MOVEMENT is not enabled
//先要enable row movement才能shrink
Elapsed: 00:00:00.09
SQL> alter table demo enable row movement;
Table altered.
Elapsed: 00:00:00.10
SQL> alter table demo shrink space;
Table altered.
Elapsed: 00:01:35.51
SQL> exec show_space('demo','auto');
Total Blocks............................3656
Total Bytes.............................29949952
Unused Blocks...........................0
Unused Bytes............................0
Last Used Ext FileId....................4
Last Used Ext BlockId...................3720
Last Used Block.........................72
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.02
//可以看到HWM降到了3656这个块上面!
参考资料:
http://tolywang.itpub.net/post/48/307529
http://www.itpub.net/viewthread.php?tid=205560
http://www.blogjava.net/decode360/archive/2009/07/14/287767.html
说到HWM,我们首先要简要的谈谈ORACLE的逻辑存储管理.我们知道,ORACLE在逻辑存储上分4个粒度:表空间,段,区和块.
(1)块:是粒度最小的存储单位,现在标准的块大小是8K,ORACLE每一次I/O操作也是按块来操作的,也就是说当ORACLE从数据文件读数据时,是读取多少个块,而不是多少行.
(2)区:由一系列相邻的块而组成,这也是ORACLE空间分配的基本单位,举个例子来说,当我们创建一个表PM_USER时,首先ORACLE会分配一区的空间给这个表,随着不断的INSERT数据到PM_USER,原来的这个区容不下插入的数据时,ORACLE是以区为单位进行扩展的,也就是说再分配多少个区给PM_USER,而不是多少个块.
(3)段:是由一系列的区所组成,一般来说,当创建一个对象时(表,索引),就会分配一个段给这个对象.所以从某种意义上来说,段就是某种特定的数据.如CREATE TABLE PM_USER,这个段就是数据段,而CREATE INDEX ON PM_USER(NAME),ORACLE同样会分配一个段给这个索引,但这是一个索引段了.查询段的信息可以通过数据字典: SELECT * FROM USER_SEGMENTS来获得,
(4)表空间:包含段,区及块.表空间的数据物理上储存在其所在的数据文件中.一个数据库至少要有一个表空间.
OK,我们现在回到HWM上来,那么,什么是高水位标记呢?这就跟ORACLE的段空间管理相关了.
(一)ORACLE用HWM来界定一个段中使用的块和未使用的块.
举个例子来说,当我们创建一个表:PT_SCHE_DETAIL时,ORACLE就会为这个对象分配一个段.在这个段中,即使我们未插入任何记录,也至少有一个区被分配,第一个区的第一个块就称为段头(SEGMENT HEADE),段头中就储存了一些信息,基中HWM的信息就存储在此.此时,因为第一个区的第一块用于存储段头的一些信息,虽然没有存储任何实际的记录,但也算是被使用,此时HWM是位于第2个块.当我们不断插入数据到PM_USER后,第1个块已经放不下后面新插入的数据,此时,ORACLE将高水位之上的块用于存储新增数据,同时,HWM本身也向上移.也就是说,当我们不断插入数据时,HWM会往不断上移,这样,在HWM之下的,就表示使用过的块,HWM之上的就表示已分配但从未使用过的块.
(二)HWM在插入数据时,当现有空间不足而进行空间的扩展时会向上移,但删除数据时不会往下移.
这就好比是水库的水位,当涨水时,水位往上移,当水退出后,最高水位的痕迹还是清淅可见.
考虑让我们看一个段,如一张表,其中填满了块,如图 1 所示。在正常操作过程中,删除了一些行,如图 2 所示。现有就有了许多浪费的空间:(I) 在表的上一个末端和现有的块之间,以及 (II) 在块内部,其中还有一些没有删除的行。
HWM01
图1:分配给该表的块。用灰色正方形表示行
ORACLE 不会释放空间以供其他对象使用,有一条简单的理由:由于空间是为新插入的行保留的,并且要适应现有行的增长。被占用的最高空间称为最高使用标记 (HWM),如图 2 所示。
HWM02
图2:行后面的块已经删除了;HWM 仍保持不变
(三)HWM的信息存储在段头当中.
HWM本身的信息是储存在段头.在段空间是手工管理方式时,ORACLE是通过FREELIST(一个单向链表)来管理段内的空间分配.在段空间是自动管理方式时(ASSM),ORACLE是通过BITMAP来管理段内的空间分配.
(四)ORACLE的全表扫描是读取高水位标记(HWM)以下的所有块.
所以问题就产生了.当用户发出一个全表扫描时,ORACLE 始终必须从段一直扫描到 HWM,即使它什么也没有发现。该任务延长了全表扫描的时间。
(五)当用直接路径插入行时 — 例如,通过直接加载插入(用 APPEND 提示插入)或通过 SQL*LOADER 直接路径 — 数据块直接置于 HWM 之上。它下面的空间就浪费掉了。
我们来分析这两个问题,后者只是带来空间的浪费,但前者不仅是空间的浪费,而且会带来严重的性能问题.我们来看看下面的例子:
(A)我们先来搭建测试的环境,第一步先创建一个段空间为手工管理的表空间:
CREATE TABLESPACE "RAINNY"
LOGGING
DATAFILE 'D:ORACLE_HOMEORADATARAINNYRAINNY.ORA' SIZE 5M
AUTOEXTEND
ON NEXT 10M MAXSIZE UNLIMITED EXTENT MANAGEMENT LOCAL
SEGMENT SPACE MANAGEMENT MANUAL;
(B)创建一个表,注意,此表的第二个字段我故意设成是CHAR(100),以让此表在插入1千万条记录后,空间有足够大:
CREATE TABLE TEST_TAB(C1 NUMBER(10),C2 CHAR(100)) TABLESPACE RAINNY;
插入记录
DECLARE
I NUMBER(10);
BEGIN
FOR I IN 1..10000000 LOOP
INSERT INTO TEST_TAB VALUES(I,'TESTSTRING');
END LOOP;
COMMIT;
END;
/
(C)我们来查询一下,看在插入一千万条记录后所访问的块数和查询所用时间:
SQL> SET TIMING ON
SQL> SET AUTOTRACE TRACEONLY
SQL> SELECT COUNT(*) FROM TEST_TAB;
ELAPSED: 00:01:03.05
EXECUTION PLAN
------------------------------------------------------------
0 SELECT STATEMENT OPTIMIZER=CHOOSE (COST=15056 CARD=1)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST_TAB' (COST=15056 CARD=10000
000)
STATISTICS
----------------------------------------------------------
0 RECURSIVE CALLS
0 DB BLOCK GETS
156310 CONSISTENT GETS
154239 PHYSICAL READS
0 REDO SIZE
379 BYTES SENT VIA SQL*NET TO CLIENT
503 BYTES RECEIVED VIA SQL*NET FROM CLIENT
2 SQL*NET ROUNDTRIPS TO/FROM CLIENT
0 SORTS (MEMORY)
0 SORTS (DISK)
1 ROWS PROCESSED
我们来看上面的执行计划,这句SQL总供耗时是:1分3秒.访问方式是采用全表扫描方式(FTS),逻辑读了156310个BLOCK,物理读了154239个BLOCK.
我们来分析一下这个表:
BEGIN
DBMS_STATS.GATHER_TABLE_STATS(OWNNAME=> 'TEST',
TABNAME=> 'TEST_TAB',
PARTNAME=> NULL);END;
/
发现这个表目前使用的BLOCK有: 156532,未使用的BLOCK(EMPTY_BLOCKS)为:0,总行数为(NUM_ROWS):1000 0000
(D)接下来我们把此表的记录用DELETE方式删掉,然后再来看看SELECT COUNT(*) FROM TEST_TAB所花的时间:
DELETE FROM TEST_TAB;
COMMIT;
SQL> SELECT COUNT(*) FROM TEST_TAB;
ELAPSED: 00:01:04.03
EXECUTION PLAN
----------------------------------------------------------
0 SELECT STATEMENT OPTIMIZER=CHOOSE (COST=15056 CARD=1)
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST_TAB' (COST=15056 CARD=1)
STATISTICS
----------------------------------------------------------
0 RECURSIVE CALLS
0 DB BLOCK GETS
156310 CONSISTENT GETS
155565 PHYSICAL READS
0 REDO SIZE
378 BYTES SENT VIA SQL*NET TO CLIENT
503 BYTES RECEIVED VIA SQL*NET FROM CLIENT
2 SQL*NET ROUNDTRIPS TO/FROM CLIENT
0 SORTS (MEMORY)
0 SORTS (DISK)
1 ROWS PROCESSED
大家来看,在DELETE表后,此时表中已没有一条记录,为什么SELECT COUNT(*) FROM TEST_TAB花的时间为1分4秒, 反而比有记录稍微长点,这是为什么呢?而且大家看,其逻辑读了156310个 BLOCK,跟之前有一千万行记录时差不多,ORACLE怎么会这么笨啊?
我们在DELETE表后再次分析表,看看有什么变化:
这时, TEST_TAB表目前使用的BLOCK是: 156532,未使用的BLOCK(EMPTY_BLOCKS)为:0,总行数为(NUM_ROWS)已变成:0
为什么表目前使的BLOCK数还是156532呢?
问题的根源就在于ORACLE的HWM.也就是说,在新增记录时,HWM会慢慢往上移,但是在删除记录后,HWM却不会往下移,也就是说,DELETE一千万条记录后,此表的HWM根本没移动,还在原来的那个位置,所以,HWM以下的块数同样也是一样的.ORACLE的全表扫描是读取ORACLE高水位标记下的所有BLOCK,也就是说,不管HWM下的BLOCK现在实际有没有存放数据,ORACLE都会一一读取,这样,大家可想而知,在我们DELETE表后,ORACLE读了大量的空块,耗去了大量的时间.
我们再来看DELETE表后段空间实际使用的状况:
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................164352 --总共164352块
TOTAL BYTES.............................1346371584
UNUSED BLOCKS...........................7168 --有7168块没有用过,也就是在HWM上面的块数
UNUSED BYTES............................58720256
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................158856-- BLOCK ID 是针对数据文件来编号的,表示最后使用的一个EXTENT的第一个BLOCK的编号
LAST USED BLOCK.........................1024 --在最后使用的一个EXTENT 中一共用了1024块
PL/SQL PROCEDURE SUCCESSFULLY COMPLETED
总共用了164352块,除了一个SEGMENT HEADER,实际总共用了164351个块,有7168块从来没有使用过。LAST USED BLOCK表示在最后一个使用的EXTENT 中使用的BLOCK, 结合 LAST USED EXT BLOCK ID可以计算 HWM 位置 :
LAST USED EXT BLOCK ID + LAST USED BLOCK -1 = HWM 所在的数据文件的BLOCK编号
代入得出: 158856+1024-1=159879,这个就是HWM所有的BLOCK编号
HWM所在的块:TOTAL BLOCKS- UNUSED BLOCKS=164352-7168=157184,也就是说,HWM在第157184个块,其BLOCKID是159879
(E)结下来,我们再做几个试验:
第一步:执行ALTER TABLE TEST_TAB DEALLOCATE UNUSED;
我们看看段空间的使用状况:
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................157184
TOTAL BYTES.............................1287651328
UNUSED BLOCKS...........................0
UNUSED BYTES............................0
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................158856
LAST USED BLOCK.........................1024
此时我们再代入上面的公式,算出HWM的位置: 157184-0=157184 HWM所在的BLOCK ID是158856+1024-1=159879,跟刚刚的没有变化,也就是说执行ALTER TABLE TEST_TAB DEALLOCATE UNUSED后,段的高水位标记的位置没有改变,但是大家看看UNUSED BLOCKS变为0了,总的块数减少到157184,这证明,DEALLOCATE UNUSED为释放HWM上面的未使用空间,但是并不会释放HWM下面的自由空间,也不会移动HWM的位置.
第二步:我们再来看看执行ALTER TABLE TEST_TAB MOVE后段空间的使用状况:
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................8
TOTAL BYTES.............................65536
UNUSED BLOCKS...........................5
UNUSED BYTES............................40960
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................2632
LAST USED BLOCK.........................3
此时,总共用到的块数已变为8, 我们再代入上面的公式,算出HWM的位置: 8-5=3 HWM所在的BLOCK ID是2632+3-1=2634,
OK,我们发现,此时HWM的位置已经发生变化,现在HWM的位置是在第3个BLOCK,其BLOCK ID是2634,所有数据文件的ID是9(这个没有发生变化,数据文件还是原来的那个数据文件,只是释放了原来的自由空间),最后使用的块数也变为3,也就是说已经使用了3块,HWM就是在最后一个使用的块上,即第3个块上.大家可能会觉得奇怪,为什么释放空间后,未使用的块还有5个啊?也就是说HWM之上还是有5个已分配但从未使用的块.答案就跟HWM移动的规律有关.当我们在插入数据时,ORACLE首先在HWM之下的块当中定位自由空间(通过自由列表FREELIST),如果FREELIST当中没有自由块了,ORACLE就开始往上扩展,而HWM也跟着往上移,每5块移动一次.我们来看ORACLE的说明:
The high water mark is:
-Recorded in the segment header block
-Set to the beginning of the segment on the creation
-Incremented in five-block increments as rows are inserted
-Reset by the truncate command
-Never reset by the delete command
-Space above the high-water-mark can be reclaimed at the table level by using the following command:
ALTER TABLE DEALLOCATE UNUSED…
我们再来看看:SELECT COUNT(*) FROM TEST_TAB所花的时间:
SQL> SELECT COUNT(*) FROM TEST_TAB;
ELAPSED: 00:00:00.00
EXECUTION PLAN
----------------------------------------------------------
0 SELECT STATEMENT OPTIMIZER=CHOOSE
1 0 SORT (AGGREGATE)
2 1 TABLE ACCESS (FULL) OF 'TEST_TAB'
STATISTICS
----------------------------------------------------------
0 RECURSIVE CALLS
0 DB BLOCK GETS
3 CONSISTENT GETS
0 PHYSICAL READS
0 REDO SIZE
378 BYTES SENT VIA SQL*NET TO CLIENT
503 BYTES RECEIVED VIA SQL*NET FROM CLIENT
2 SQL*NET ROUNDTRIPS TO/FROM CLIENT
0 SORTS (MEMORY)
0 SORTS (DISK)
1 ROWS PROCESSED
很快,不到1秒.
我们最后再来对表作一次分析, 此时这个表目前使用的BLOCK为: 0,未使用的BLOCK(EMPTY_BLOCKS)为:0,总行数为(NUM_ROWS):0
从中我们也可以发现,分析表和SHOW_SPACE显示的数据有点不一致.那么哪个是准的呢?其实这两个都是准的,只不过计算的方法有点不同.事实上,当你创建了一个对象如表以后,不管你有没有插入数据,它都会占用一些块,ORACLE也会给它分配必要的空间.同样,用ALTER TABLE MOVE释放自由空间后,还是保留了一些空间给这个表.
最后,我们再来执行TRUNCATE命令,截断这个表,看看段空间的使用状况:
TRUNCATE TABLE TEST_TAB;
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................8
TOTAL BYTES.............................65536
UNUSED BLOCKS...........................5
UNUSED BYTES............................40960
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................2632
LAST USED BLOCK.........................3
PL/SQL PROCEDURE SUCCESSFULLY COMPLETED
SQL>
我们发现TRUNCATE后和MOVE没有什么变化.
为了,最终验证一下我上面的观点,我再DROP一下表,然后新建这个表,看看这时在没有插入任何数据之前,是否ORACLE确实有给这个对象分配必要的空间:
DROP TABLE TEST_TAB;
CREATE TABLE TEST_TAB(C1 NUMBER(10),C2 CHAR(100)) TABLESPACE RAINNY;
SQL> EXEC SHOW_SPACE('TEST_TAB','TEST');
TOTAL BLOCKS............................8
TOTAL BYTES.............................65536
UNUSED BLOCKS...........................5
UNUSED BYTES............................40960
LAST USED EXT FILEID....................9
LAST USED EXT BLOCKID...................2112
LAST USED BLOCK.........................3
大家看,即使我没有插入任何一行记录,ORACLE还是给它分配了8个块.当然这个跟建表语句的INITIAL 参数及MINEXTENTS参数有关:请看TEST_TAB的存储参数:
S TORAGE
(
INITIAL 64K
MINEXTENTS 1
MAXEXTENTS UNLIMITED
);
也就是说,在这个对象创建以后,ORACLE至少给它分配一个区,初始大小是64K,一个标准块的大小是8K,刚好是8个BLOCK.
总结:
在9I中:
(1)如果MINEXTENT 可以使ALTER TABLE TABLENAME DEALLOCATE UNUSED将HWM以上所有没使用的空间释放
(2)如果MINEXTENT >HWM 则释放MINEXTENTS 以上的空间。如果要释放HWM以上的空间则使用KEEP 0。
ALTER TABLE TABLESNAME DEALLOCATE UNUSED KEEP 0;
(3) TRUNCATE TABLE DROP STORAGE(缺省值)命令可以将MINEXTENT 之上的空间完全释放(交还给操作系统),并且重置HWM。
(4)如果仅是要移动HWM,而不想让表长时间锁住,可以用TRUNCATE TABLE REUSE STORAGE,仅将HWM重置。
(5)ALTER TABLE MOVE会将HWM移动,但在MOVE时需要双倍的表空间,而且如果表上有索引的话,需要重构索引
(6)DELETE表不会重置HWM,也不会释放自由的空间(也就是说DELETE空出来的空间只能给对象本身将来的INSERT/UPDATE使用,不能给其它的对象使用)
在ORACLE 10G:
可以使用ALTER TABLE TEST_TAB SHRINK SPACE命令来联机移动HWM,
如果要同时压缩表的索引,可以发布:ALTER TABLE TEST_TAB SHRINK SPACE CASCADE
注意:在使用此命令时需要先使行可迁移row movement(具体见例子)。
与使用ALTER TABLE MOVE 不同的是执行此命令后并不需要重构索引。
Oracle 官方说明
Shrinking Database Segments Online
You use online segment shrink to reclaim fragmented free space below the high water mark in an Oracle Database segment. The benefits of segment shrink are these:
* Compaction of data leads to better cache utilization, which in turn leads to better online transaction processing (OLTP) performance.
* The compacted data requires fewer blocks to be scanned in full table scans, which in turns leads to better decision support system (DSS) performance.
Segment shrink is an online, in-place operation. DML operations and queries can be issued during the data movement phase of segment shrink. Concurrent DML operation are blocked for a short time at the end of the shrink operation, when the space is deallocated. Indexes are maintained during the shrink operation and remain usable after the operation is complete. Segment shrink does not require extra disk space to be allocated.
Segment shrink reclaims unused space both above and below the high water mark. In contrast, space deallocation reclaims unused space only above the high water mark. In shrink operations, by default, the database compacts the segment, adjusts the high water mark, and releases the reclaimed space.
Segment shrink requires that rows be moved to new locations. Therefore, you must first enable row movement in the object you want to shrink and disable any rowid-based triggers defined on the object.
Shrink operations can be performed only on segments in locally managed tablespaces with automatic segment space management (ASSM). Within an ASSM tablespace, all segment types are eligible for online segment shrink except these:
* IOT mapping tables
* Tables with rowid based materialized views
* Tables with function-based indexes
操作的过程:
SQL> create table demo as select * from dba_source;
Table created.
Elapsed: 00:00:05.83
SQL> select count(*) from demo;
COUNT(*)
----------
210992
Elapsed: 00:00:01.06
SQL> insert into demo select * from demo;
210992 rows created.
Elapsed: 00:00:59.83
SQL> commit;
Commit complete.
//得到一个40万条记录的表,下面来查看这个表空间分布情况。
SQL> exec show_space('demo','auto');
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.07
SQL> set serveroutput on
SQL> exec show_space('demo','auto');
Total Blocks............................9216
Total Bytes.............................75497472
Unused Blocks...........................768
Unused Bytes............................6291456
Last Used Ext FileId....................4
Last Used Ext BlockId...................8328
Last Used Block.........................256
一共有9216个数据块,HWM在9216-768=8448这个块.
也可以通过查看extents得到HWM=8*16+128*63+256=8192+256=8448
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.01
SQL> delete from demo where rownum<220000;
219999 rows deleted.
Elapsed: 00:00:40.99
SQL> commit;
Commit complete.
Elapsed: 00:00:00.01
SQL> exec show_space('demo','auto');
Total Blocks............................9216
Total Bytes.............................75497472
Unused Blocks...........................768
Unused Bytes............................6291456
Last Used Ext FileId....................4
Last Used Ext BlockId...................8328
Last Used Block.........................256
PL/SQL procedure successfully completed.
//删除操作后表的HWM没有变化,还是在第8448块这个位置。
Elapsed: 00:00:00.00
SQL> alter table demo shrink space;
alter table demo shrink space
*
ERROR at line 1:
ORA-10636: ROW MOVEMENT is not enabled
//先要enable row movement才能shrink
Elapsed: 00:00:00.09
SQL> alter table demo enable row movement;
Table altered.
Elapsed: 00:00:00.10
SQL> alter table demo shrink space;
Table altered.
Elapsed: 00:01:35.51
SQL> exec show_space('demo','auto');
Total Blocks............................3656
Total Bytes.............................29949952
Unused Blocks...........................0
Unused Bytes............................0
Last Used Ext FileId....................4
Last Used Ext BlockId...................3720
Last Used Block.........................72
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.02
//可以看到HWM降到了3656这个块上面!
参考资料:
http://tolywang.itpub.net/post/48/307529
http://www.itpub.net/viewthread.php?tid=205560
分享到:


发表评论

相关推荐
内容概要:本文详细介绍了基于MATLAB GUI界面和卷积神经网络(CNN)的模糊车牌识别系统。该系统旨在解决现实中车牌因模糊不清导致识别困难的问题。文中阐述了整个流程的关键步骤,包括图像的模糊还原、灰度化、阈值化、边缘检测、孔洞填充、形态学操作、滤波操作、车牌定位、字符分割以及最终的字符识别。通过使用维纳滤波或最小二乘法约束滤波进行模糊还原,再利用CNN的强大特征提取能力完成字符分类。此外,还特别强调了MATLAB GUI界面的设计,使得用户能直观便捷地操作整个系统。 适合人群:对图像处理和深度学习感兴趣的科研人员、高校学生及从事相关领域的工程师。 使用场景及目标:适用于交通管理、智能停车场等领域,用于提升车牌识别的准确性和效率,特别是在面对模糊车牌时的表现。 其他说明:文中提供了部分关键代码片段作为参考,并对实验结果进行了详细的分析,展示了系统在不同环境下的表现情况及其潜在的应用前景。
嵌入式八股文面试题库资料知识宝典-计算机专业试题.zip
嵌入式八股文面试题库资料知识宝典-C and C++ normal interview_3.zip
内容概要:本文深入探讨了一款额定功率为4kW的开关磁阻电机,详细介绍了其性能参数如额定功率、转速、效率、输出转矩和脉动率等。同时,文章还展示了利用RMxprt、Maxwell 2D和3D模型对该电机进行仿真的方法和技术,通过外电路分析进一步研究其电气性能和动态响应特性。最后,文章提供了基于RMxprt模型的MATLAB仿真代码示例,帮助读者理解电机的工作原理及其性能特点。 适合人群:从事电机设计、工业自动化领域的工程师和技术人员,尤其是对开关磁阻电机感兴趣的科研工作者。 使用场景及目标:适用于希望深入了解开关磁阻电机特性和建模技术的研究人员,在新产品开发或现有产品改进时作为参考资料。 其他说明:文中提供的代码示例仅用于演示目的,实际操作时需根据所用软件的具体情况进行适当修改。
少儿编程scratch项目源代码文件案例素材-剑客冲刺.zip
少儿编程scratch项目源代码文件案例素材-几何冲刺 转瞬即逝.zip
内容概要:本文详细介绍了基于PID控制器的四象限直流电机速度驱动控制系统仿真模型及其永磁直流电机(PMDC)转速控制模型。首先阐述了PID控制器的工作原理,即通过对系统误差的比例、积分和微分运算来调整电机的驱动信号,从而实现转速的精确控制。接着讨论了如何利用PID控制器使有刷PMDC电机在四个象限中精确跟踪参考速度,并展示了仿真模型在应对快速负载扰动时的有效性和稳定性。最后,提供了Simulink仿真模型和详细的Word模型说明文档,帮助读者理解和调整PID控制器参数,以达到最佳控制效果。 适合人群:从事电力电子与电机控制领域的研究人员和技术人员,尤其是对四象限直流电机速度驱动控制系统感兴趣的读者。 使用场景及目标:适用于需要深入了解和掌握四象限直流电机速度驱动控制系统设计与实现的研究人员和技术人员。目标是在实际项目中能够运用PID控制器实现电机转速的精确控制,并提高系统的稳定性和抗干扰能力。 其他说明:文中引用了多篇相关领域的权威文献,确保了理论依据的可靠性和实用性。此外,提供的Simulink模型和Word文档有助于读者更好地理解和实践所介绍的内容。
嵌入式八股文面试题库资料知识宝典-2013年海康威视校园招聘嵌入式开发笔试题.zip
少儿编程scratch项目源代码文件案例素材-驾驶通关.zip
小区开放对周边道路通行能力影响的研究.pdf
内容概要:本文探讨了冷链物流车辆路径优化问题,特别是如何通过NSGA-2遗传算法和软硬时间窗策略来实现高效、环保和高客户满意度的路径规划。文中介绍了冷链物流的特点及其重要性,提出了软时间窗概念,允许一定的配送时间弹性,同时考虑碳排放成本,以达到绿色物流的目的。此外,还讨论了如何将客户满意度作为路径优化的重要评价标准之一。最后,通过一段简化的Python代码展示了遗传算法的应用。 适合人群:从事物流管理、冷链物流运营的专业人士,以及对遗传算法和路径优化感兴趣的科研人员和技术开发者。 使用场景及目标:适用于冷链物流企业,旨在优化配送路线,降低运营成本,减少碳排放,提升客户满意度。目标是帮助企业实现绿色、高效的物流配送系统。 其他说明:文中提供的代码仅为示意,实际应用需根据具体情况调整参数设置和模型构建。
少儿编程scratch项目源代码文件案例素材-恐怖矿井.zip
内容概要:本文详细介绍了基于STM32F030的无刷电机控制方案,重点在于高压FOC(磁场定向控制)技术和滑膜无感FOC的应用。该方案实现了过载、过欠压、堵转等多种保护机制,并提供了完整的源码、原理图和PCB设计。文中展示了关键代码片段,如滑膜观测器和电流环处理,以及保护机制的具体实现方法。此外,还提到了方案的移植要点和实际测试效果,确保系统的稳定性和高效性。 适合人群:嵌入式系统开发者、电机控制系统工程师、硬件工程师。 使用场景及目标:适用于需要高性能无刷电机控制的应用场景,如工业自动化设备、无人机、电动工具等。目标是提供一种成熟的、经过验证的无刷电机控制方案,帮助开发者快速实现并优化电机控制性能。 其他说明:提供的资料包括详细的原理图、PCB设计文件、源码及测试视频,方便开发者进行学习和应用。
基于有限体积法Godunov格式的管道泄漏检测模型研究.pdf
嵌入式八股文面试题库资料知识宝典-CC++笔试题-深圳有为(2019.2.28)1.zip
少儿编程scratch项目源代码文件案例素材-几何冲刺 V1.5.zip
Android系统开发_Linux内核配置_USB-HID设备模拟_通过root权限将Android设备转换为全功能USB键盘的项目实现_该项目需要内核支持configFS文件系统
C# WPF - LiveCharts Project
少儿编程scratch项目源代码文件案例素材-恐怖叉子 动画.zip
嵌入式八股文面试题库资料知识宝典-嵌⼊式⼯程师⾯试⾼频问题.zip