- 浏览: 178888 次
- 性别:

- 来自: 北京
-

文章分类
最新评论
-
chenyi1125:
StateStats 是自己定义的类吧,有哪些属性,如何与我 ...
mongodb sum 操作 -
yongquan812:
...
最全的 Twitter Bootstrap 开发资源清单 -
mccxj:
不是已经提供个params的属性来添加路径的参数了么?我对分页 ...
grails 查询结果分页 简单实现 -
sphinxdwood:
请问第22行有什么用?params.ft_inlist = K ...
grails 查询结果分页 简单实现 -
walsh:
classpath的配置不正确吧
java基础
在JBoss Rules 学习(一):什么是Rule中,我们介绍了JBoss Rules中对Rule的表示,其中提到了JBoss Rule中主要采用的RETE算法来进行规则匹配。下面将详细的介绍一下RETE算法在JBoss Rule中的实现,最后随便提一下JBoss Rules中也可以使用的另一种规则匹配算法Leaps。
1.Rete 算法 :
Rete 在拉丁语中是 ”net” ,有网络的意思。 RETE 算法可以分为两部分:规则编译( rule compilation )和运行时执行( runtime execution )。
编译算法描述了规则如何在 Production Memory 中产生一个有效的辨别网络。用一个非技术性的词来说,一个辨别网络就是用来过滤数据。方法是通过数据在网络中的传播来过滤数据。在顶端节点将会有很多匹配的数据。当我们顺着网络向下走,匹配的数据将会越来越少。在网络的最底部是终端节点( terminal nodes )。在 Dr Forgy 的 1982 年的论文中,他描述了 4 种基本节点: root , 1-input, 2-input and terminal 。下图是 Drools 中的 RETE 节点类型:
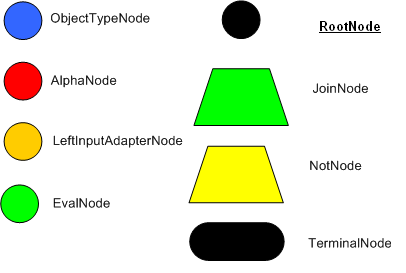
Figure 1. Rete Nodes
根节点( RootNode )是所有的对象进入网络的入口。然后,从根节点立即进入到 ObjectTypeNode 。 ObjectTypeNode 的作用是使引擎只做它需要做的事情。例如,我们有两个对象集: Account 和 Order 。如果规则引擎需要对每个对象都进行一个周期的评估,那会浪费很多的时间。为了提高效率,引擎将只让匹配 object type 的对象通过到达节点。通过这种方法,如果一个应用 assert 一个新的 account ,它不会将 Order 对象传递到节点中。很多现代 RETE 实现都有专门的 ObjectTypeNode 。在一些情况下, ObjectTypeNode 被用散列法进一步优化。
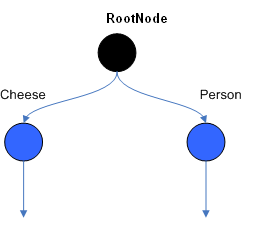
Figure 2 . ObjectTypeNodes
ObjectTypeNode 能够传播到 AlphaNodes, LeftInputAdapterNodes 和 BetaNodes 。
1-input 节点通常被称为 AlphaNode 。 AlphaNodes 被用来评估字面条件( literal conditions )。虽然, 1982 年的论文只提到了相等条件(指的字面上相等),很多 RETE 实现支持其他的操作。例如, Account.name = = “Mr Trout” 是一个字面条件。当一条规则对于一种 object type 有多条的字面条件,这些字面条件将被链接在一起。这是说,如果一个应用 assert 一个 account 对象,在它能到达下一个 AlphaNode 之前,它必须先满足第一个字面条件。在 Dr. Forgy 的论文中,他用 IntraElement conditions 来表述。下面的图说明了 Cheese 的 AlphaNode 组合( name = = “cheddar” , strength = = “strong” ):
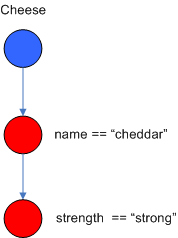
Figure 3. AlphaNodes
Drools 通过散列法优化了从 ObjectTypeNode 到 AlphaNode 的传播。每次一个 AlphaNode 被加到一个 ObjectTypeNode 的时候,就以字面值( literal value )作为 key ,以 AlphaNode 作为 value 加入 HashMap 。当一个新的实例进入 ObjectTypeNode 的时候,不用传递到每一个 AlphaNode ,它可以直接从 HashMap 中获得正确的 AlphaNode ,避免了不必要的字面检查。
<!--[if !supportEmptyParas]-->
2-input 节点通常被称为 BetaNode 。 Drools 中有两种 BetaNode : JoinNode 和 NotNode 。 BetaNodes 被用来对 2 个对象进行对比。这两个对象可以是同种类型,也可以是不同类型。
我们约定 BetaNodes 的 2 个输入称为左边( left )和右边( right )。一个 BetaNode 的左边输入通常是 a list of objects 。在 Drools 中,这是一个数组。右边输入是 a single object 。两个 NotNode 可以完成‘ exists ’检查。 Drools 通过将索引应用在 BetaNodes 上扩展了 RETE 算法。下图展示了一个 JoinNode 的使用:

Figure 4 . JoinNode
注意到图中的左边输入用到了一个 LeftInputAdapterNode ,这个节点的作用是将一个 single Object 转化为一个单对象数组( single Object Tuple ),传播到 JoinNode 节点。因为我们上面提到过左边输入通常是 a list of objects 。
<!--[if !supportEmptyParas]-->
Terminal nodes 被用来表明一条规则已经匹配了它的所有条件( conditions )。 在这点,我们说这条规则有了一个完全匹配( full match )。在一些情况下,一条带有“或”条件的规则可以有超过一个的 terminal node 。
Drools 通过节点的共享来提高规则引擎的性能。因为很多的规则可能存在部分相同的模式,节点的共享允许我们对内存中的节点数量进行压缩,以提供遍历节点的过程。下面的两个规则就共享了部分节点:
when
Cheese( $chedddar : name == " cheddar " )
$person : Person( favouriteCheese == $cheddar )
then
System.out.println( $person.getName() + " likes cheddar " );
end
when
Cheese( $chedddar : name == " cheddar " )
$person : Person( favouriteCheese != $cheddar )
then
System.out.println( $person.getName() + " does likes cheddar " );
end
这里我们先不探讨这两条 rule 到的是什么意思,单从一个直观的感觉,这两条 rule 在它们的 LHS 中基本都是一样的,只是最后的 favouriteCheese ,一条规则是等于 $cheddar ,而另一条规则是不等于 $cheddar 。下面是这两条规则的节点图:
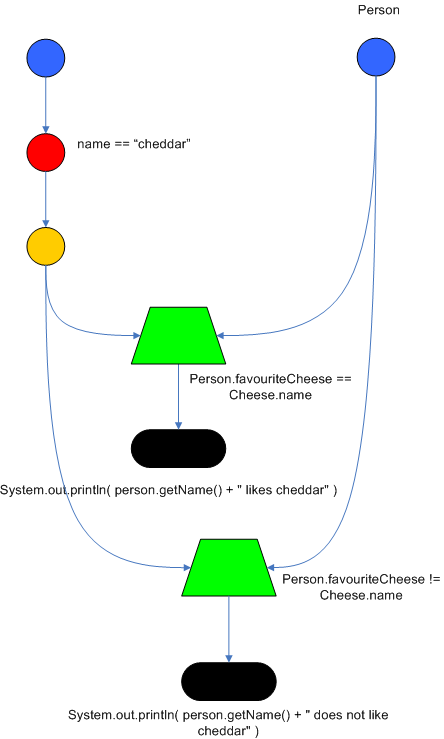
Figure 5 . Node Sharing
从图上可以看到,编译后的 RETE 网络中, AlphaNode 是共享的,而 BetaNode 不是共享的。上面说的相等和不相等就体现在 BetaNode 的不同。然后这两条规则有各自的 Terminal Node 。
<!--[if !supportEmptyParas]-->
RETE 算法的第二个部分是运行时( runtime )。当一个应用 assert 一个对象,引擎将数据传递到 root node 。从那里,它进入 ObjectTypeNode 并沿着网络向下传播。当数据匹配一个节点的条件,节点就将它记录到相应的内存中。这样做的原因有以下几点:主要的原因是可以带来更快的性能。虽然记住完全或部分匹配的对象需要内存,它提供了速度和可伸缩性的特点。当一条规则的所有条件都满足,这就是完全匹配。而只有部分条件满足,就是部分匹配。(我觉得引擎在每个节点都有其对应的内存来储存满足该节点条件的对象,这就造成了如果一个对象是完全匹配,那这个对象就会在每个节点的对应内存中都存有其映象。)
2. Leaps 算法:
Production systems 的 Leaps 算法使用了一种“ lazy ”方法来评估条件( conditions )。一种 Leaps 算法的修改版本的实现,作为 Drools v3 的一部分,尝试结合 Leaps 和 RETE 方法的最好的特点来处理 Working Memory 中的 facts 。
古典的 Leaps 方法将所有的 asserted 的 facts ,按照其被 asserted 在 Working Memory 中的顺序( FIFO ),放在主堆栈中。它一个个的检查 facts ,通过迭代匹配 data type 的 facts 集合来找出每一个相关规则的匹配。当一个匹配的数据被发现时,系统记住此时的迭代位置以备待会的继续迭代,并且激发规则结果( consequence )。当结果( consequence )执行完成以后,系统就会继续处理处于主堆栈顶部的 fact 。如此反复。


发表评论

-
mybatis 一些总结
2014-04-09 13:06 1360最近用mybatis开发,一些总结: 结合spring ... -
STOMP protocol
2013-12-18 00:41 1170STOMP,Streaming Text Ori ... -
java 反射机制更改私有属性 重复创建单例类对象
2012-11-04 00:16 2322单例类: package com.shenli. ... -
log4j.xml web.xml配置
2012-10-29 23:53 9936log4j.xml配置实现配置实现配置实现配置实现 先写 ... -
log4j.xml 配置
2012-10-29 23:30 1032<?xml version="1.0& ... -
Maven 2 plugin fails with cannot find symbol exception when defining two locatio
2012-10-17 23:58 1246https://confluence.atlassian.co ... -
maven 1.5 编译级别
2012-09-25 10:36 877在pom.mxl中增加以下内容 <b ... -
eclipse debug 问题解决
2012-05-18 15:15 0eclipse 问题解决 问题描述:3.7.2里面安装了mav ... -
eclipse plugin update
2012-05-18 14:52 887eclipse plugin update site 总结 ... -
JVM 学习 (2)实战 OutOfMemoryError异常
2012-03-13 17:37 0首先来制造Java堆溢出: import jav ... -
JVM 学习(1)运行时数据区
2012-03-13 11:40 856今天开始学习JVM 先看看运行时数据区的结构: ... -
Ubuntu 上使用 Rxtx
2009-09-04 17:45 0ubuntu下安装和配置RXTX实现串口通讯 RXTX是一套 ... -
自己写的线程池
2009-06-05 15:54 14391 .线程池类:TPTaskProxy import ... -
Ant 获取svn工程并编译
2008-08-05 12:49 3336<?xml version="1.0" ... -
Acegi配置文档
2008-08-05 12:40 1106Acegi是基于Spring的一个� ... -
java基础
2008-06-05 13:33 2398Java基础 从事java相关的编程工 ... -
JBoss Rules 1
2008-06-05 11:33 1666JBoss Rules 学习(一): 什么是Rule ... -
junit4参数化测试和easymock的使用
2008-06-05 11:20 3357利用junit4的一些新特性,我们可以方便的对多个参数进行测试 ... -
html编码转换工具
2008-06-04 13:07 3097对于html的特殊标记的处理,有一个好办法,可以轻松的实现ht ...
相关推荐
之前学习jboss rules 只能自己一点点的啃英文用户指南,后来终于找到了中文版的翻译版本,真是高兴,立即奉献给大家,让对规则引擎感兴趣的朋友也能一堵为快。 内容摘要:JBoss Rules 的前身是Codehaus的一个开源...
JBoss Rules,现名为Drools,是一款强大的开源业务规则管理系统(BRMS),它允许开发者在应用程序中嵌入复杂的业务规则。本入门资料集锦涵盖了从基础到高级的多个方面,帮助初学者全面理解并掌握如何使用JBoss Rules...
jboss rules 中文用户指南,mht文件,共十章。
jboss rules 中文学习资料.chm
### JBoss Rules 学习知识点概述 #### 一、JBoss Rules 介绍 - **前身与演变**:JBoss Rules 的前身是 Codehaus 下的一个开源项目名为 Drools。随着其功能和技术的成熟,该项目被 JBoss 收购,并重新命名为 JBoss ...
【JBoss Rules 初学实例】是针对Drools规则引擎的一个入门教程,适用于初次接触该框架的开发者。Drools是一款开源的业务规则管理系统,它允许开发人员以声明式的方式编写业务规则,使得复杂的逻辑处理变得更加简洁...
### jBoss Rules 用户指南知识点详解 #### 一、规则引擎概念及背景 ##### 1.1 什么是规则引擎 规则引擎是一种软件系统,它能够基于一组预定义的规则来处理数据,进而推导出结论或者执行特定的操作。规则引擎的...
### Drools JBoss Rules 5 开发者指南 #### 知识点一:Drools 平台介绍 - **定义与背景**:Drools 是一个开源业务规则管理系统(Business Rule Management System, BRMS),它支持开发人员通过声明式编程来实现...
Drools JBoss Rules是JBoss企业中间件产品套件的一部分,它是一个基于Java平台的业务规则引擎(Business Rules Engine),它允许业务逻辑从业务应用程序中分离出来,并以一种易于管理和维护的方式呈现。Drools JBoss...
JBOSSRULES使用文档
myeclipse安装drools jboss rules规则引擎
### Drools JBoss Rules 5.0 Developer's Guide #### 概述 《Drools JBoss Rules 5.0 Developer's Guide》是一本专为希望利用Drools平台开发基于规则的业务逻辑的开发者而编写的指南。本书由Michal Bali撰写,于...
《JBoss Drools Business Rules》是一本由 Paul Browne 编写的书籍,首次出版于2009年,该书旨在介绍如何利用 JBoss Drools 捕获、自动化及重用业务流程。本书版权属于 Packt Publishing,并在 Birmingham 和 Mumbai...
规则引擎 Drools-JBoss Rules 规则引擎是人工智能(Artificial Intelligence)领域中的一种技术,用于实现专家系统,专家系统使用知识表示把知识编码简化成一个可用于推理的知识库。规则引擎是一个基于规则的方法...
### Drools JBoss Rules 5.0 Developer's Guide:规则引擎技术详解 #### 一、概述 《Drools JBoss Rules 5.0 Developer's Guide》是一本深入讲解Drools规则引擎技术的书籍。本书由Michal Bali编写,旨在帮助读者...
JAVA规则引擎JBOSS RULES,也被称为DROOLS,是一种强大的业务规则管理系统,它允许开发者用自然语言来编写业务规则,并在运行时执行这些规则。DROOLS 6.5是该规则引擎的一个版本,提供了许多改进和新特性,以提高...