
┬ĀHashMapõĖ║õ╗Ćõ╣łńö©ń║óķ╗æµĀæĶĆīõĖŹńö©ĶĘ│ĶĪ©?
1ŃĆüĶĘ│ĶĪ©ķ£ĆĶ”üń╗┤µŖżķóØÕż¢ńÜäÕżÜÕ▒éķōŠĶĪ©’╝īµś»ń®║ķŚ┤µŹóµŚČķŚ┤ńÜäÕüܵ│Ģ’╝īń║óķ╗æµĀæõĖŹńö©ÕŹĀńö©ÕżÜõĮÖńÜäń®║ķŚ┤
2ŃĆüÕÉīµŚČHashMapńÜäEntryÕ╣ȵ▓Īµ£ēÕåģÕ£©ńÜäµÄÆÕ║ÅÕģ│ń│╗’╝īµēĆõ╗źõ╣¤µŚĀµ│ĢõĮ┐ńö©ĶĘ│ĶĪ©’╝īÕøĀõĖ║ĶĘ│ĶĪ©µ£¼Ķ║½Ķ”üµ▒éĶ”üÕŁśÕ£©µÄÆÕ║ÅÕģ│ń│╗’╝łõĖ¬õ║║Ķ«żõĖ║µ£ĆķćŹĶ”ü’╝ē
µĆ╗ń╗ō
keyńÜähashcodeµŚĀµ│ĢµÄÆÕ║Å’╝īµēĆõ╗źµŚĀµ│ĢÕ«×ńÄ░ĶĘ│ĶĪ©ń╗ōµ×ä’╝īķéŻõĖŹńö©hashCodeõĖŹÕ░▒ÕźĮõ║åÕÉŚ’╝¤ÕģČÕ«×Õ”éµ×£µ£ēĶ┐ÖõĖ¬ń¢æķŚ«Õ░▒ĶĄ░Ķ┐øõ║åõĖĆõĖ¬µŁ╗ĶāĪÕÉīŃĆ鵣ŻÕøĀõĖ║ńö©õ║åhashCodeµēŹÕŽHashMap’╝īõĖŹńö©hashńÜäMapõ╣¤µ£ēÕæĆ’╝īµ£ēÕ«×ńÄ░õ║åµÄÆÕ║ÅÕģ│ń│╗ńÜäMap’╝īµ»öÕ”éTreeMap’╝łõĮ┐ńö©TreeMapµēƵ£ēńÜäkeyķāĮÕ┐ģķĪ╗ńø┤µÄźµł¢ķŚ┤µÄźńÜäÕ«×ńÄ░ComparableµÄźÕÅŻ’╝īÕÉ”ÕłÖõ╝ܵŖźcannot be cast to java.lang.ComparableŃĆéÕĮōńäČ’╝īńø┤µÄźķććńö©TreeMap(Comparator<? super K> comparator)µ×äķĆĀÕÖ©õ╣¤µś»ÕÅ»õ╗źńÜäŃĆé)ÕåŹµ»öÕ”éÕ║ĢÕ▒éÕ░▒µś»ĶĘ│ĶĪ©ńÜäConcurrentSkipListMapŃĆé
┬Ā
µēĆõ╗źÕ¤║õ║ÄĶĘ│ĶĪ©Õ«×ńÄ░ńÜäMapõ╣¤µ£ē’╝īÕ¤║õ║Äń║óķ╗æµĀæÕ«×ńÄ░ńÜäMapõ╣¤µ£ē’╝īÕŬµś»ń£ŗõĖÜÕŖĪÕ£║µÖ»µØźķĆēµŗ®Õō¬õĖĆõĖ¬µØźńö©ŃĆéÕ”éµ×£õĮĀÕ£©õ╣ÄķÜŵ£║µ¤źĶ»óµĢłńÄćķéŻÕ░▒µś»HashMap,Õ”éµ×£Ķ”üµ▒éń║┐ń©ŗÕ«ēÕģ©ķéŻÕ░▒µś»ConcurrentHashMap’╝øÕ”éµ×£Ķ”üµ▒éµÄÆÕ║Å’╝īĶīāÕø┤µ¤źĶ»óķéŻÕ░▒µś»ConcurrentSkipListMapŃĆé
┬Ā
redisńÜäzsetõĖ║õ╗Ćõ╣łńö©ĶĘ│ĶĪ©ĶĆīõĖŹńö©ń║óķ╗æµĀæ?
1ŃĆüĶĘ│ĶĪ©ńÜäÕ«×ńÄ░µø┤ÕŖĀń«ĆÕŹĢ’╝īõĖŹńö©µŚŗĶĮ¼ĶŖéńé╣’╝īńøĖÕ»╣µĢłńÄćµø┤ķ½ś
2ŃĆüĶĘ│ĶĪ©Õ£©ĶīāÕø┤µ¤źĶ»óńÜ䵌ČÕĆÖńÜäµĢłńÄ浜»ķ½śõ║Äń║óķ╗æµĀæńÜä’╝īÕøĀõĖ║ĶĘ│ĶĪ©µś»õ╗ÄõĖŖÕ▒éÕŠĆõĖŗÕ▒鵤źµēŠńÜä’╝īõĖŖÕ▒éńÜäÕī║Õ¤¤ĶīāÕø┤µø┤Õ╣┐’╝īÕÅ»õ╗źÕ┐½ķĆ¤Õ«ÜõĮŹÕł░µ¤źĶ»óńÜäĶīāÕø┤’╝łµłæĶ«żõĖ║µś»µ£ĆķćŹĶ”üńÜä’╝ē
3ŃĆüÕ╣│ĶĪĪµĀæńÜäµÅÆÕģźÕÆīÕłĀķÖżµōŹõĮ£ÕÅ»ĶāĮÕ╝ĢÕÅæÕŁÉµĀæńÜäĶ░āµĢ┤ŃĆüķĆ╗ĶŠæÕżŹµØé’╝īĶĆīĶĘ│ĶĪ©ÕŬķ£ĆĶ”üń╗┤µŖżńøĖķé╗ĶŖéńé╣ÕŹ│ÕÅ»
4ŃĆüµ¤źµēŠÕŹĢõĖ¬key’╝īĶĘ│ĶĪ©ÕÆīÕ╣│ĶĪĪµĀæµŚČķŚ┤ÕżŹµØéÕ║”ķāĮµś»O(logN)
µĆ╗ń╗ō
õ╗Äredisµ£¼Ķ║½Õć║ÕÅæ’╝īredisµś»õĖĆõĖ¬ÕŹĢń║┐ń©ŗńÜäµ£ŹÕŖĪ’╝īÕ«āµø┤ÕŖĀĶ┐Įµ▒鵤źĶ»óķƤÕ║”’╝īredisµ£¼Ķ║½µś»Õ¤║õ║ÄÕåģÕŁśńÜä’╝īµēĆõ╗źÕ«āńÜäµĆ¦ĶāĮńōČķółÕ£©õ║ÄÕåģÕŁśÕÆīńĮæń╗£ÕĖ”Õ«Į’╝īĶĆīõĖŹÕ£©õ║ÄCPUŃĆéń║óķ╗æµĀæµ£¼Ķ║½ńÜäÕ«×ńÄ░µ»öĶŠāÕżŹµØé’╝īµ»Åµ¼Īµ¢░Õó×ŃĆüõ┐«µö╣ķāĮĶ”üń╗┤µŖżĶŖéńé╣ńÜ䵌ŗĶĮ¼ŃĆüÕÅśĶē▓’╝īńøĖÕ»╣ĶĆīĶ©Ćµø┤ÕŖĀµČłĶĆŚÕåģÕŁś’╝īĶĆīĶĘ│ĶĪ©õ┐«µö╣Õģāń┤ĀÕŬķ£ĆĶ”üń╗┤µŖżÕēŹÕÉÄõĖżõĖ¬ĶŖéńé╣ÕŹ│ÕÅ»ŃĆéµēĆõ╗źÕ£©õ┐ØķÜ£µ¤źĶ»óķƤÕ║”ńÜäÕēŹµÅÉ’╝īÕåģÕŁśµČłĶĆŚµø┤Õ░ÅńÜäµø┤ķĆéÕÉłredisŃĆé┬Ā
┬Ā
õĖĆŃĆüń║óķ╗æµĀæ
┬Ā
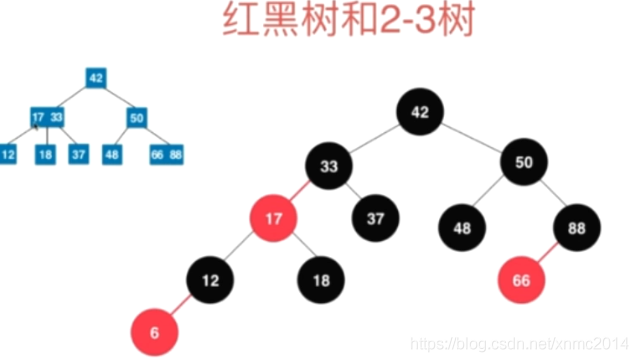
┬Ā
µ»ÅõĖ¬ĶŖéńé╣µł¢ĶĆģµś»ń║óĶē▓’╝īµł¢ĶĆģµś»ķ╗æĶē▓’╝łÕ«Üõ╣ē’╝ē
µĀ╣ĶŖéńé╣õĖĆիܵś»ķ╗æĶē▓ńÜä’╝łÕ»╣Õ║ö2-3µĀæńÜä2ĶŖéńé╣ÕÆī3ĶŖéńé╣’╝ē
ń®║ĶŖéńé╣µś»ķ╗æĶē▓ńÜä
Õ”éµ×£õĖĆõĖ¬ĶŖéńé╣µś»ń║óĶē▓ńÜä’╝īķéŻõ╣łÕ«āńÜäÕŁ®ÕŁÉĶŖéńé╣ķāĮµś»ķ╗æĶē▓ńÜä
µĀ╣ĶŖéńé╣Õł░õ╗╗µäÅõĖĆõĖ¬ÕÅČÕŁÉĶŖéńé╣µēĆń╗ÅĶ┐ćńÜäķ╗æĶŖéńé╣õĖ¬µĢ░µś»õĖƵĀĘńÜä’╝īÕŹ│ń║óķ╗æµĀæµś»õĖĆķóŚõ┐صīüķ╗æÕ╣│ĶĪĪńÜäõ║īÕÅēµĀæ’╝īõĖŹµś»Õ╣│ĶĪĪõ║īÕÅēµĀæ’╝īõĮåÕĘ”ÕÅ│ÕŁÉµĀæńÜäķ╗æĶē▓ĶŖéńé╣õ┐صīüń╗ØÕ»╣ńÜäÕ╣│ĶĪĪ’╝īÕó×ÕłĀµö╣µ¤źÕżŹµØéÕ║” O(logN)’╝īµĘ╗ÕŖĀÕÆīÕłĀķÖżµōŹõĮ£µ»öAVLµĀæÕ┐½
┬Ā
ĶŖéńé╣µ£ēõĖżĶē▓’╝īķØ×ń║óÕŹ│ķ╗æ
µĀ╣Ķē▓µś»ķ╗æ
µēƵ£ēÕÅČÕŁÉµś»ķ╗æĶē▓ń®║ĶŖéńé╣
ń║óĶē▓ĶŖéńé╣ńÜäÕŁÉĶŖéńé╣ķāĮµś»ķ╗æĶē▓’╝łõĖŹĶāĮµ£ēõĖżõĖ¬Ķ┐×ń╗ŁńÜäń║óĶē▓ĶŖéńé╣ńøĖĶ┐×’╝ē
õ╗Äõ╗╗õĮĢõĖĆõĖ¬ĶŖéńé╣Õł░Õģȵ»ÅõĖ¬ÕÅČÕŁÉńÜäÕżÜµ£ēĶĘ»ÕŠäķāĮÕīģÕɽńøĖÕÉīµĢ░ńø«ńÜäķ╗æĶē▓ĶŖéńé╣
┬Ā
┬Ā
ĶŖéńé╣ÕłåõĖżĶē▓’╝īrootµś»ķ╗æĶē▓’╝īÕÅČÕŁÉµłÉķ╗æń®║’╝īń║óĶē▓õĖŹńøĖĶ┐×’╝īÕŁÉĶŖéńé╣ķ╗æĶē▓µĢ░ńø«ńøĖÕÉī
┬Ā
ÕÅśµŹóµ£ēõĖżń¦Ź’╝īÕÅśĶē▓ÕÆīµŚŗĶĮ¼
┬Ā
µÅÆÕģźµ£ē5ń¦ŹµāģÕåĄ’╝ܵ¢░ĶŖéńé╣ķ╗śĶ«żķó£Ķē▓µś»ń║óĶē▓
┬Ā
µ¢░ńé╣õĖ║µĀæµĀ╣’╝ÜõĖĆõĖŗÕ░▒ÕÅśķ╗æ’╝ø
ńłČńé╣µś»ķ╗æĶē▓’╝ܵ¢░ńé╣ńø┤µÄźµ¢╣’╝ø
ńłČĶŖéńé╣ÕÆīÕÅöÕÅöĶŖéńé╣ķāĮµś»ń║óĶē▓’╝ÜńłČŃĆüńłĘŃĆüÕÅöõĖēĶŖéńé╣ķāĮĶ”üÕÅśĶē▓’╝ø
ńłČĶŖéńé╣µś»ń║óĶē▓’╝īÕÅöÕÅöĶŖéńé╣µś»ķ╗æĶē▓µł¢ĶĆģµ▓Īµ£ēÕÅöÕÅöĶŖéńé╣’╝īõĖöµ¢░ĶŖéńé╣µś»ńłČĶŖéńé╣ńÜäÕÅ│ÕŁ®ÕŁÉ’╝īńłČĶŖéńé╣µś»ńź¢ńłČĶŖéńé╣ńÜäÕĘ”ÕŁ®ÕŁÉ’╝Üõ╗źńłČĶŖéńé╣õĖ║ĶĮ┤’╝īÕĘ”µŚŗĶĮ¼’╝ø’╝łµ£ēķĢ£ÕāÅ’╝ē
ńłČĶŖéńé╣µś»ń║óĶē▓’╝īÕÅöÕÅöĶŖéńé╣µś»ķ╗æĶē▓µł¢ĶĆģµ▓Īµ£ēÕÅöÕÅöĶŖéńé╣’╝īõĖöµ¢░ĶŖéńé╣µś»ńłČĶŖéńé╣ńÜäÕĘ”ÕŁ®ÕŁÉ’╝īńłČĶŖéńé╣µś»ńź¢ńłČĶŖéńé╣ńÜäÕĘ”ÕŁ®ÕŁÉ’╝Üõ╗źńź¢ńłČĶŖéńé╣õĖ║ĶĮ┤’╝īÕÅ│µŚŗĶĮ¼’╝ø’╝łµ£ēķĢ£ÕāÅ’╝ē
┬Ā
õ║īŃĆüĶĘ│ĶĪ©
õ╣ŗÕēŹµłæõ╗¼ń¤źķüō’╝īõ║īÕłåµ¤źµēŠõŠØĶĄ¢µĢ░ń╗äńÜäķÜŵ£║Ķ«┐ķŚ«’╝īµēĆõ╗źÕŬĶāĮńö©µĢ░ń╗äµØźÕ«×ńÄ░ŃĆéÕ”éµ×£µĢ░µŹ«ÕŁśÕé©Õ£©ķōŠĶĪ©õĖŁ’╝īÕ░▒ń£¤ńÜäµ▓Īµ│Ģńö©õ║īÕłåµ¤źµēŠõ║åÕÉŚ’╝¤ĶĆīÕ«×ķÖģõĖŖ’╝īµłæõ╗¼ÕŬķ£ĆĶ”üÕ»╣ķōŠĶĪ©ń©ŹÕŖĀµö╣ķĆĀ’╝īÕ░▒ÕÅ»õ╗źÕ«×ńÄ░ń▒╗õ╝╝ŌĆ£õ║īÕłåŌĆØńÜ䵤źµēŠń«Śµ│Ģ’╝īĶ┐Öń¦Źµö╣ķĆĀõ╣ŗÕÉÄńÜäµĢ░µŹ«ń╗ōµ×äÕŽõĮ£ĶĘ│ĶĪ©’╝łSkip List’╝ēŃĆé
┬Ā

┬Ā
ConcurrentSkipListMapµś»Õ£©JDK 1.6õĖŁµ¢░Õó×ńÜä’╝īõĖ║õ║åÕ»╣ķ½śÕ╣ČÕÅæÕ£║µÖ»õĖŗńÜäµ£ēÕ║ÅMapµÅÉõŠøµø┤ÕźĮńÜäµö»µīü’╝īÕ«āµ£ēÕćĀõĖ¬ńē╣ńé╣’╝Ü
┬Ā
ķ½śÕ╣ČÕÅæÕ£║µÖ»
keyµś»µ£ēÕ║ÅńÜä
µĘ╗ÕŖĀŃĆüÕłĀķÖżŃĆüµ¤źµēŠµōŹõĮ£ķāĮµś»Õ¤║õ║ÄĶĘ│ĶĪ©ń╗ōµ×ä’╝łSkip List’╝ēÕ«×ńÄ░ńÜä
keyÕÆīvalueķāĮõĖŹĶāĮõĖ║null
┬Ā
ĶĘ│ĶĪ©’╝łSkip List’╝ēµś»õĖĆń¦Źń▒╗õ╝╝õ║ÄķōŠĶĪ©ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕģȵ¤źĶ»óŃĆüµÅÆÕģźŃĆüÕłĀķÖżńÜ䵌ČķŚ┤ÕżŹµØéÕ║”ķāĮµś» O(logn)ŃĆé
Õ£©õ╝Āń╗¤ńÜäÕŹĢķōŠĶĪ©ń╗ōµ×äõĖŁ’╝īµ¤źµēŠµ¤ÉõĖ¬Õģāń┤Āķ£ĆĶ”üõ╗ÄķōŠĶĪ©ńÜäÕż┤ķā©µīēķĪ║Õ║ÅķüŹÕÄå’╝īńø┤Õł░µēŠÕł░ńø«µĀćÕģāń┤ĀõĖ║µŁó’╝īµ¤źµēŠńÜ䵌ČķŚ┤ÕżŹµØéÕ║”õĖ║O(n)ŃĆé
┬Ā
ĶĆīĶĘ│ĶĪ©ń╗ōÕÉłõ║åµĀæÕÆīķōŠĶĪ©ńÜäńē╣ńé╣’╝īÕģČńē╣µĆ¦Õ”éõĖŗ’╝Ü┬Ā
ĶĘ│ĶĪ©ńö▒ÕŠłÕżÜÕ▒éń╗䵳ɒ╝ø
µ»ÅõĖĆÕ▒éķāĮµś»õĖĆõĖ¬µ£ēÕ║ÅńÜäķōŠĶĪ©’╝ø
µ£ĆÕ║ĢÕ▒éńÜäķōŠĶĪ©ÕīģÕɽµēƵ£ēÕģāń┤Ā’╝ø
Õ»╣õ║ĵ»ÅõĖĆÕ▒éńÜäõ╗╗µäÅõĖĆõĖ¬ĶŖéńé╣’╝īõĖŹõ╗ģµ£ēµīćÕÉæÕģČõĖŗõĖĆõĖ¬ĶŖéńé╣ńÜäµīćķÆł’╝īõ╣¤µ£ēµīćÕÉæÕģČõĖŗõĖĆÕ▒éńÜäµīćķÆł’╝ø
Õ”éµ×£õĖĆõĖ¬Õģāń┤ĀÕć║ńÄ░Õ£©Level nÕ▒éńÜäķōŠĶĪ©õĖŁ’╝īÕłÖÕ«āÕ£©Level nÕ▒éõ╗źõĖŗńÜäķōŠĶĪ©õ╣¤ķāĮõ╝ÜÕć║ńÄ░ŃĆé
┬Ā
Skip ListõŠŗÕŁÉ’╝Ü┬Ā
õĖŗÕøŠµś»õĖĆń¦ŹÕÅ»ĶāĮńÜäĶĘ│ĶĪ©ń╗ōµ×ä’╝Ü
┬Ā
Õ”éÕøŠ’╝ī[1]ÕÆī[40]ĶŖéńé╣µ£ē3Õ▒é’╝ī[8]ÕÆī[18]ĶŖéńé╣µ£ē2Õ▒éŃĆéµ»ÅõĖĆÕ▒éķāĮµś»µ£ēÕ║ÅńÜäķōŠĶĪ©ŃĆé┬Ā
Õ”éµ×£Ķ”üµ¤źµēŠńø«µĀćĶŖéńé╣[15]’╝īÕż¦Ķć┤Ķ┐ćń©ŗÕ”éõĖŗ’╝Ü┬Ā
ķ”¢Õģłµ¤źń£ŗ[1]ĶŖéńé╣ńÜäń¼¼1Õ▒é’╝īÕÅæńÄ░[1]ĶŖéńé╣ńÜäõĖŗõĖĆõĖ¬ĶŖéńé╣õĖ║[40]’╝īÕż¦õ║Ä15’╝īķéŻõ╣łµ¤źµēŠ[1]ĶŖéńé╣ńÜäõĖŗõĖĆÕ▒é’╝ø
µ¤źµēŠ[1]ĶŖéńé╣ńÜäń¼¼2Õ▒é’╝īÕÅæńÄ░[1]ĶŖéńé╣ńÜäõĖŗõĖĆõĖ¬ĶŖéńé╣õĖ║[8]’╝īÕ░Åõ║Ä15’╝īµÄźńØƵ¤źń£ŗõĖŗõĖĆõĖ¬ĶŖéńé╣’╝īÕÅæńÄ░õĖŗõĖĆõĖ¬ĶŖéńé╣µś»[18]’╝īÕż¦õ║Ä15’╝īÕøĀµŁżµ¤źµēŠ[8]ĶŖéńé╣ńÜäõĖŗõĖĆÕ▒é’╝ø
µ¤źµēŠ[8]ĶŖéńé╣ńÜäń¼¼2Õ▒é’╝īÕÅæńÄ░[8]ĶŖéńé╣ńÜäõĖŗõĖĆõĖ¬ĶŖéńé╣µś»[10]’╝īÕ░Åõ║Ä15’╝īµÄźńØƵ¤źń£ŗõĖŗõĖĆõĖ¬ĶŖéńé╣[13]’╝īÕ░Åõ║Ä15’╝īµÄźńØƵ¤źń£ŗõĖŗõĖĆõĖ¬ĶŖéńé╣[15]’╝īÕÅæńÄ░ÕģČÕĆ╝ńŁēõ║Ä15’╝īÕøĀµŁżµēŠÕł░õ║åńø«µĀćĶŖéńé╣’╝īń╗ōµØ¤µ¤źĶ»óŃĆé
┬Ā
ĶĘ│ĶĪ©Õ«×ķÖģõĖŖµś»õĖĆń¦Ź ń®║ķŚ┤µŹóµŚČķŚ┤ ńÜäµĢ░µŹ«ń╗ōµ×äŃĆé
ConcurrentSkipListMapńö©Õł░õ║åõĖżń¦Źń╗ōµ×äńÜäĶŖéńé╣ŃĆé
┬Ā
ConcurrentSkipListMap ńÜäĶŖéńé╣õĖ╗Ķ”üńö▒ Node, Index, HeadIndex µ×䵳É;õĖŗķØ󵜻õĖĆõĖ¬ÕģĖÕ×ŗńÜäConcurrentSkipListMap ńÜäÕ«×õŠŗńÜäń╗ōµ×äÕøŠ’╝Ü
┬Ā
Redis õĖ║õĮĢķĆēńö©ĶĘ│ĶĪ©
µ£ēÕ║ÅńÜäÕŹĢķōŠĶĪ© O(N)
µÅÉķ½śµ¤źµēŠµĢłńÄć --ŃĆŗ Õ»╣ķōŠĶĪ©Õ╗║ń½ŗń┤óÕ╝Ģ
Õ╗║ń½ŗõ║åÕżÜń║¦ń┤óÕ╝Ģ’╝īµ»ÅÕ▒éń┤óÕ╝ĢõĖŁ’╝īµ»ÅõĖ¬ĶŖéńé╣µīćÕÉæµ£ēõĖżõĖ¬µīćÕÉæ’╝īÕÉæÕÅ│ÕÆīÕÉæõĖŗ
µ»ÅõĖĆÕ▒éń┤óÕ╝ĢĶŖéńé╣õĖ¬µĢ░µś»õĖŗÕ▒éĶŖéńé╣õĖ¬µĢ░ńÜäõĖĆÕŹŖ
µ¤źĶ»óµĢłńÄćO(logN), µÅÆÕģź’╝īÕłĀķÖżõ╣¤µś»
ķĆÜĶ┐ćķÜŵ£║ÕćĮµĢ░ń╗┤µīüÕ╣│ĶĪĪµĆ¦’╝īÕĮōÕŠĆĶĘ│ĶĪ©õĖŁµÅÆÕģźµĢ░µŹ«µŚČ’╝īÕÅ»õ╗źķĆÜĶ┐ćķÜŵ£║ÕćĮµĢ░ķĆēµŗ®ķĆēµŗ®ÕÉæÕō¬õ║øń┤óÕ╝ĢõĖŁµĘ╗ÕŖĀĶŖéńé╣’╝ī
RedisõĖŁńÜäµ£ēÕ║ÅķøåÕÉłµś»ķĆÜĶ┐ćĶĘ│ĶĪ©µØźÕ«×ńÄ░ńÜä’╝īõĖźµĀ╝ńé╣Ķ«▓’╝īÕģČÕ«×Ķ┐śńö©Õł░õ║åµĢŻÕłŚĶĪ©ŃĆéÕ”éµ×£õĮĀÕÄ╗µ¤źń£ŗRedisńÜäÕ╝ĆÕÅæµēŗÕåī’╝īÕ░▒õ╝ÜÕÅæńÄ░’╝īRedisõĖŁńÜäµ£ēÕ║ÅķøåÕÉłµö»µīüńÜäµĀĖÕ┐āµōŹõĮ£õĖ╗Ķ”üµ£ēõĖŗķØóĶ┐ÖÕćĀõĖ¬’╝Ü
µÅÆÕģźõĖĆõĖ¬µĢ░µŹ«’╝ø
ÕłĀķÖżõĖĆõĖ¬µĢ░µŹ«’╝ø
µ¤źµēŠõĖĆõĖ¬µĢ░µŹ«’╝ø
┬Ā
µīēńģ¦Õī║ķŚ┤µ¤źµēŠµĢ░µŹ«’╝łµ»öՔ鵤źµēŠÕĆ╝Õ£©[100, 356]õ╣ŗķŚ┤ńÜäµĢ░µŹ«’╝ē’╝ø
Ķ┐Łõ╗ŻĶŠōÕć║µ£ēÕ║ÅÕ║ÅÕłŚŃĆé
ÕģČõĖŁ’╝īµÅÆÕģźŃĆüÕłĀķÖżŃĆüµ¤źµēŠõ╗źÕÅŖĶ┐Łõ╗ŻĶŠōÕć║µ£ēÕ║ÅÕ║ÅÕłŚĶ┐ÖÕćĀõĖ¬µōŹõĮ£’╝īń║óķ╗æµĀæõ╣¤ÕÅ»õ╗źÕ«īµłÉ’╝īµŚČķŚ┤ÕżŹµØéÕ║”ĶʤĶĘ│ĶĪ©µś»õĖƵĀĘńÜäŃĆéõĮåµś»’╝īµīēńģ¦Õī║ķŚ┤µØźµ¤źµēŠµĢ░µŹ«Ķ┐ÖõĖ¬µōŹõĮ£’╝īń║óķ╗æµĀæńÜäµĢłńÄćµ▓Īµ£ēĶĘ│ĶĪ©ķ½śŃĆé
Õ»╣õ║ĵīēńģ¦Õī║ķŚ┤µ¤źµēŠµĢ░µŹ«Ķ┐ÖõĖ¬µōŹõĮ£’╝īĶĘ│ĶĪ©ÕÅ»õ╗źÕüÜÕł░O(logn)ńÜ䵌ČķŚ┤ÕżŹµØéÕ║”Õ«ÜõĮŹÕī║ķŚ┤ńÜäĶĄĘńé╣’╝īńäČÕÉÄÕ£©ÕĤզŗķōŠĶĪ©õĖŁķĪ║Õ║ÅÕŠĆÕÉÄķüŹÕÄåÕ░▒ÕÅ»õ╗źõ║åŃĆéĶ┐ÖµĀĘÕüÜķØ×ÕĖĖķ½śµĢłŃĆé
┬Ā
┬Ā
ÕĮōńäČ’╝īRedisõ╣ŗµēĆõ╗źńö©ĶĘ│ĶĪ©µØźÕ«×ńÄ░µ£ēÕ║ÅķøåÕÉł’╝īĶ┐śµ£ēÕģČõ╗¢ÕĤÕøĀ’╝īµ»öÕ”é’╝īĶĘ│ĶĪ©µø┤Õ«╣µśōõ╗ŻńĀüÕ«×ńÄ░ŃĆéĶÖĮńäČĶĘ│ĶĪ©ńÜäÕ«×ńÄ░õ╣¤õĖŹń«ĆÕŹĢ’╝īõĮåµ»öĶĄĘń║óķ╗æµĀæµØźĶ»┤Ķ┐śµś»ÕźĮµćéŃĆüÕźĮÕåÖÕżÜõ║å’╝īĶĆīń«ĆÕŹĢÕ░▒µäÅÕæ│ńØĆÕÅ»Ķ»╗µĆ¦ÕźĮ’╝īõĖŹÕ«╣µśōÕć║ķöÖŃĆéĶ┐śµ£ē’╝īĶĘ│ĶĪ©µø┤ÕŖĀńüĄµ┤╗’╝īÕ«āÕÅ»õ╗źķĆÜĶ┐ćµö╣ÕÅśń┤óÕ╝Ģµ×äÕ╗║ńŁ¢ńĢź’╝īµ£ēµĢłÕ╣│ĶĪĪµē¦ĶĪīµĢłńÄćÕÆīÕåģÕŁśµČłĶĆŚŃĆé
┬Ā
ÕģČõĖŁ’╝īµÅÆÕģźŃĆüÕłĀķÖżŃĆüµ¤źµēŠõ╗źÕÅŖĶ┐Łõ╗ŻĶŠōÕć║µ£ēÕ║ÅÕ║ÅÕłŚĶ┐ÖÕćĀõĖ¬µōŹõĮ£’╝īń║óķ╗æµĀæõ╣¤ÕÅ»õ╗źÕ«īµłÉ’╝īµŚČķŚ┤ÕżŹµØéÕ║”ÕÆīĶĘ│ĶĪ©µś»õĖƵĀĘńÜäŃĆé
õĮåµś»’╝īµīēńģ¦Õī║ķŚ┤µ¤źµēŠµĢ░µŹ«Ķ┐ÖõĖ¬µōŹõĮ£’╝īń║óķ╗æµĀæńÜäµĢłńÄćµ▓Īµ£ēĶĘ│ĶĪ©ķ½śŃĆéĶĘ│ĶĪ©ÕÅ»õ╗źÕ£© O(logn)
µŚČķŚ┤ÕżŹµØéÕ║”Õ«ÜõĮŹÕī║ķŚ┤ńÜäĶĄĘńé╣’╝īńäČÕÉÄÕ£©ÕĤզŗķōŠĶĪ©õĖŁķĪ║Õ║ÅÕÉæÕÉĵ¤źĶ»óÕ░▒ÕÅ»õ╗źõ║å’╝īĶ┐ÖµĀĘķØ×ÕĖĖķ½śµĢłŃĆé
µŁżÕż¢’╝īńøĖµ»öõ║Äń║óķ╗æµĀæ’╝īĶĘ│ĶĪ©Ķ┐śÕģʵ£ēõ╗ŻńĀüµø┤Õ«╣µśōÕ«×ńÄ░ŃĆüÕÅ»Ķ»╗µĆ¦ÕźĮŃĆüõĖŹÕ«╣µśōÕć║ķöÖŃĆüµø┤ÕŖĀńüĄµ┤╗ńŁēõ╝śńé╣’╝īÕøĀµŁż Redis ńö©ĶĘ│ĶĪ©µØźÕ«×ńÄ░µ£ēÕ║ÅķøåÕÉł
┬Ā
ĶĘ│ĶĪ©ķ½śµĢłńÜäÕŖ©µĆüµÅÆÕģźÕÆīÕłĀķÖż’╝¤
Õ£©ķōŠĶĪ©õĖŁ’╝īÕ”éµ×£µłæõ╗¼ń¤źķüōĶ”üµÅÆÕģźµĢ░µŹ«ńÜäõĮŹńĮ«’╝īķéŻõ╣łµÅÆÕģźńÜ䵌ČķŚ┤ÕżŹµØéÕ║”Õ░▒õĖ║ O(1)ŃĆéÕ£©ĶĘ│ĶĪ©õĖŁ’╝īµ¤źµēŠńÜ䵌ČķŚ┤ÕżŹµØéÕ║”õĖ║ O(logn)’╝īÕøĀµŁż’╝īÕŖ©µĆüµÅÆÕģźµĢ░µŹ«ńÜ䵌ČķŚ┤ÕżŹµØéÕ║”õ╣¤Õ░▒µś» O(logn)
õ║åŃĆé
┬Ā
õ╗ÄķōŠĶĪ©õĖŁÕłĀķÖżń╗ōńé╣ńÜ䵌ČÕĆÖ’╝īÕ”éµ×£ń╗ōńé╣Õ£©ń┤óÕ╝ĢõĖŁõ╣¤µ£ēÕć║ńÄ░’╝īķéŻõ╣łµłæõ╗¼ķÖżõ║åĶ”üÕłĀķÖżÕĤզŗķōŠĶĪ©õĖŁńÜäń╗ōńé╣’╝īĶ┐śĶ”üÕłĀķÖżń┤óÕ╝ĢõĖŁńÜäŃĆé
ÕĮōµłæõ╗¼õĖŹÕü£Õ£░ÕŠĆĶĘ│ĶĪ©õĖŁµÅÆÕģźµĢ░µŹ«ńÜ䵌ČÕĆÖ’╝īÕ”éµ×£µłæõ╗¼õĖŹµø┤µ¢░ń┤óÕ╝Ģ’╝īÕ░▒µ£ēÕÅ»ĶāĮÕć║ńÄ░µ¤ÉõĖżõĖ¬ń╗ōńé╣õ╣ŗķŚ┤µĢ░µŹ«ķØ×ÕĖĖÕżÜńÜäµāģÕåĄŃĆéµ×üń½»µāģÕåĄõĖŗ’╝īĶĘ│ĶĪ©Ķ┐śõ╝ÜķĆĆÕī¢õĖ║ÕŹĢķōŠĶĪ©ŃĆé
┬Ā
ÕøĀµŁż’╝īµłæõ╗¼ķ£ĆĶ”üµ¤Éń¦Źµēŗµ«ĄµØźń╗┤µŖżń┤óÕ╝ĢõĖÄÕĤզŗķōŠĶĪ©Õż¦Õ░Åõ╣ŗķŚ┤ńÜäÕ╣│ĶĪĪ’╝īõ╣¤Õ░▒µś»Ķ»┤’╝īÕ”éµ×£ķōŠĶĪ©ń╗ōńé╣ÕÅśÕżÜõ║å’╝īń┤óÕ╝ĢÕĆ╝Õ░▒ńøĖÕ║öÕ£░Õó×ÕŖĀõĖĆõ║øŃĆé
┬Ā
ÕĮōµłæõ╗¼ÕŠĆĶĘ│ĶĪ©õĖŁµÅÆÕģźµĢ░µŹ«ńÜ䵌ČÕĆÖ’╝īµłæõ╗¼ÕÅ»õ╗źķĆēµŗ®ÕÉīµŚČõ╣¤Õ░åĶ┐ÖõĖ¬µĢ░µŹ«µÅÆÕģźÕł░ķā©Õłåń┤óÕ╝ĢÕ▒éõĖŁŃĆéĶĆīµÅÆÕģźÕł░Õō¬õ║øń┤óÕ╝ĢÕ▒éõĖŁ’╝īÕłÖńö▒õĖĆõĖ¬ķÜŵ£║ÕćĮµĢ░ńö¤µłÉõĖĆõĖ¬ķÜŵ£║µĢ░ÕŁŚµØźÕå│Õ«ÜŃĆéÕ”éµ×£Ķ┐ÖõĖ¬µĢ░ÕŁŚõĖ║ K’╝īķ鯵łæõ╗¼Õ░▒Õ░åµĢ░µŹ«µÅÆÕģźÕł░ń¼¼õĖĆń║¦Õł░ń¼¼ K ń║¦ń┤óÕ╝ĢõĖŁŃĆé
┬Ā
┬Ā
┬Ā
┬Ā
┬Ā



ńøĖÕģ│µÄ©ĶŹÉ
structure ĶĘ│ĶĪ© vs ń║óķ╗æµĀæ’╝īÕ»╣µ»öõ║åõĖżń¦ŹµĢ░µŹ«ń╗ōµ×äńÜäõ╝śÕŖŻ ĶĘ│ĶĪ©’╝łSkip List’╝ēµś»õĖĆń¦ŹÕ¤║õ║ÄÕ╣ČĶĪīķōŠĶĪ©ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īń▒╗õ╝╝õ║ÄÕ╣│ĶĪĪµĀæ’╝īńö©õ║ÄÕ£©µ£ēÕ║ÅńÜäÕ║ÅÕłŚõĖŁÕ┐½ķƤµ¤źµēŠõĖĆõĖ¬Õģāń┤ĀŃĆéÕ«āķĆÜĶ┐ćÕ£©ķōŠĶĪ©õĖŖµ¢╣Õó×ÕŖĀÕżÜń║¦ń┤óÕ╝Ģ’╝īõ╗źÕ«×ńÄ░Õ┐½ķƤµ¤źµēŠńÜäńø«ńÜäŃĆé...
ĶĘ│ĶĪ©Õ£©µÅÆÕģźÕÆīÕłĀķÖżµōŹõĮ£µŚČ’╝īÕŬķ£ĆĶ”üĶ░āµĢ┤ķā©Õłåń┤óÕ╝ĢµīćķÆł’╝īĶĆīõĖŹµś»ÕāÅń║óķ╗æµĀæÕÆīAVLµĀæķ鯵ĀĘķ£ĆĶ”üĶ┐øĶĪīÕż¦ķćÅńÜäµĀæµŚŗĶĮ¼µōŹõĮ£ŃĆéÕøĀµŁż’╝īÕ£©ķ½śÕ╣ČÕÅæńÜäµāģÕåĄõĖŗ’╝īĶĘ│ĶĪ©ńÜäµĆ¦ĶāĮńøĖÕ»╣ĶŠāÕźĮŃĆé 4. ÕōłÕĖīĶĪ©: ÕōłÕĖīĶĪ©µś»õĖĆń¦ŹÕ¤║õ║ÄÕōłÕĖīÕćĮµĢ░Õ«×ńÄ░ńÜäµĢ░µŹ«ń╗ōµ×ä’╝īÕ«ā...
õĖÄń║óķ╗æµĀæńøĖµ»ö’╝īĶĘ│ĶĪ©Õ£©µ¤Éõ║øÕÅéµĢ░Ķ«ŠńĮ«õĖŗÕÅ»õ╗źµø┤ĶŖéń£üÕåģÕŁśŃĆé - Ziplistµś»RedisÕ£©ÕŁśÕé©Õ░æķćÅÕģāń┤ĀµŚČõĮ┐ńö©ńÜäõĖĆń¦Źńē╣µ«ŖķōŠĶĪ©ń╗ōµ×ä’╝īÕ«āµś»õĖ║õ║åĶŖéń£üÕåģÕŁśĶĆīĶ«ŠĶ«ĪńÜä’╝īĶĆīõĖŹµś»ńö©õ║ĵø┐õ╗ŻĶĘ│ĶĪ©ŃĆéZiplistķĆéńö©õ║ÄÕģāń┤ĀµĢ░ķćÅĶŠāÕ░æńÜäµāģÕåĄ’╝īĶĆīĶĘ│ĶĪ©ÕłÖķĆéńö©...
ÕĖĖĶ¦üńÜäµĢ░µŹ«ń╗ōµ×äµ£ēń║óķ╗æµĀæŃĆüµ£ĆÕ░ÅÕĀåŃĆüĶĘ│ĶĪ©ÕÆīµŚČķŚ┤ĶĮ«ŃĆé 1. **ń║óķ╗æµĀæ**’╝Üń║óķ╗æµĀæµś»õĖĆń¦ŹĶć¬Õ╣│ĶĪĪõ║īÕÅēµ¤źµēŠµĀæ’╝īµÅÆÕģźŃĆüÕłĀķÖżÕÆīµ¤źµēŠńÜ䵌ČķŚ┤ÕżŹµØéÕ║”ÕØćõĖ║O(log n)ŃĆéÕ£©Õ«ÜµŚČÕÖ©õĖŁ’╝īń║óķ╗æµĀæÕÅ»õ╗źõ┐ØĶ»üĶŖéńé╣ńÜäµ£ēÕ║ÅµĆ¦’╝īµēŠÕł░µ£ĆĶ┐æńÜäիܵŚČõ╗╗ÕŖĪ’╝īõĮåõĖŹ...
Ķ┐Öń¦ŹĶ«ŠĶ«ĪõĮ┐ÕŠŚĶĘ│ĶĪ©ĶāĮÕż¤Õ£©õĖĆÕ«Üń©ŗÕ║”õĖŖµ©Īµŗ¤õ║īÕÅēµÉ£ń┤óµĀæńÜäÕ┐½ķƤµ¤źµēŠµĆ¦ĶāĮ’╝īÕÉīµŚČķü┐ÕģŹõ║åń║óķ╗æµĀæńŁēÕ╣│ĶĪĪµĀæÕ£©ń╗┤µŖżÕ╣│ĶĪĪµŚČµēĆķ£ĆńÜäķóØÕż¢Õ╝ĆķöĆŃĆé #### õĖēŃĆüĶĘ│ĶĪ©ńÜäÕģ│ķö«µōŹõĮ£ µĀ╣µŹ«ń╗ÖÕ«ÜńÜäķā©Õłåõ╗ŻńĀüńż║õŠŗ’╝īµłæõ╗¼ÕÅ»õ╗źµĘ▒ÕģźµÄóĶ«©ĶĘ│ĶĪ©ńÜäõĖĆõ║øÕģ│ķö«µōŹõĮ£...
ÕÉīµŚČ’╝īĶĘ│ĶĪ©ńÜ䵤źµēŠŃĆüµÅÆÕģźÕÆīÕłĀķÖżµōŹõĮ£Õ£©Õ╣│ÕØćµāģÕåĄõĖŗõĖÄń║óķ╗æµĀæńøĖÕĮō’╝īõĮåÕ£©µ£ĆÕØŵāģÕåĄõĖŗ’╝īń║óķ╗æµĀæńÜäµōŹõĮ£µŚČķŚ┤ÕżŹµØéÕ║”õ╗ŹõĖ║O(log n)’╝īĶĆīĶĘ│ĶĪ©ÕÅ»ĶāĮĶŠŠÕł░O(n)ŃĆéńäČĶĆī’╝īńö▒õ║ÄRedisõĖ╗Ķ”üÕ║öńö©õ║Äń╝ōÕŁś’╝īµĢ░µŹ«Ķ¦äµ©ĪķĆÜÕĖĖõĖŹõ╝Üńē╣Õł½Õż¦’╝īõĖöµĢ░µŹ«ńÜäĶ»╗ÕÅ¢Ķ┐£...
µĆ¦ĶāĮõĖŖÕÆīń║óķ╗æµĀæ’╝īAVLµĀæõĖŹńøĖõĖŖõĖŗ’╝īõĮåĶĘ│ĶĪ©ńÜäÕĤńÉåķØ×ÕĖĖń«ĆÕŹĢ’╝īńø«ÕēŹRedisÕÆīLevelDBõĖŁķāĮµ£ēńö©Õł░ŃĆé ĶĘ│ĶĪ©ńÜäÕ«Üõ╣ē ĶĘ│ĶĪ©µś»õĖĆń¦ŹÕÅ»õ╗źµø┐õ╗ŻÕ╣│ĶĪĪµĀæńÜäµĢ░µŹ«ń╗ōµ×äŃĆéĶĘ│ĶĪ©Ķ┐Įµ▒éńÜ䵜»µ”éńÄćµĆ¦Õ╣│ĶĪĪ’╝īĶĆīõĖŹµś»õĖźµĀ╝Õ╣│ĶĪĪŃĆéÕøĀµŁż’╝īĶʤÕ╣│ĶĪĪõ║īÕÅēµĀæńøĖµ»ö’╝īĶĘ│ĶĪ©...
8’╝Ä7ń║óķ╗æµĀæ 8’╝Ä8Õ░Åń╗ō ń¼¼9ń½Ā õ╝śÕģłķś¤ÕłŚÕÆīÕĀåµÄÆÕ║Å 9’╝Ä1õ╝śÕģłķś¤ÕłŚ 9.2ÕĀå 9’╝Ä3ÕĀåµÄÆÕ║Å 9’╝Ä4µē®Õ▒Ģõ╝śÕģłķś¤ÕłŚ 9’╝Ä5Õ░Åń╗ō ń¼¼10ń½Ā ńŖȵĆüµ£║ÕÆīµŁŻÕłÖĶĪ©ĶŠŠÕ╝Å 10’╝Ä1ńŖȵĆüµ£║ 10’╝Ä2µŁŻÕłÖĶĪ©ĶŠŠÕ╝Å 10’╝Ä3Õ░Åń╗ō ń¼¼11ń½ĀµĢ░µŹ«ÕÄŗń╝® 11’╝Ä1µĢ░µŹ«ĶĪ©ńż║ 11’╝Ä2...
ķćŹńé╣Ķ«©Ķ«║õ║åµĢ░µŹ«ń╗ōµ×äÕ£©ń«Śµ│ĢĶ«ŠĶ«ĪŃĆüµĢ░µŹ«Õ║ōń«ĪńÉåŃĆüµōŹõĮ£ń│╗ń╗¤ÕÅŖõ║║ÕĘźµÖ║ĶāĮõĖŁńÜäÕģĘõĮōÕ║öńö©Õ«×õŠŗ’╝īÕ╣ČÕ▒Ģµ£øõ║åµ¢░Õ×ŗµĢ░µŹ«ń╗ōµ×äÕ”éĶĘ│ĶĪ©ŃĆüń║óķ╗æµĀæŃĆüÕłåÕĖāÕ╝ÅÕōłÕĖīĶĪ©ŃĆüķćÅÕŁÉµĢ░µŹ«ń╗ōµ×äÕ£©µ£¬µØźńÜäńĀöń®ČÕÅæÕ▒Ģµ¢╣ÕÉæŃĆé ķĆéńö©õ║║ńŠż’╝ÜĶ«Īń«Śµ£║ńøĖÕģ│õĖōõĖÜńÜäÕŁ”ńö¤ŃĆüńĀöń®Č...
- ńøĖµ»öõ║ÄÕÉīµĀʵÅÉõŠøO(logN)µ¤źµēŠµĢłńÄćńÜäBµĀæŃĆüAVLµĀæÕÆīń║óķ╗æµĀæ’╝īĶĘ│ĶĪ©ńÜäÕ«×ńÄ░µø┤ń«ĆÕŹĢ’╝īõĖŹķ£ĆĶ”üÕżŹµØéńÜäÕ╣│ĶĪĪµōŹõĮ£ŃĆé 6. **Õ╣ČÕÅæÕżäńÉå**’╝Ü - ńö▒õ║ÄĶĘ│ĶĪ©Õ¤║õ║ÄķōŠĶĪ©’╝īÕÅ»õ╗źÕ«×ńÄ░µŚĀķöüµōŹõĮ£’╝īÕ░żÕģČķĆéÕÉłÕżÜĶ»╗õĖĆÕåÖńÜäÕ╣ČÕÅæÕ£║µÖ»ŃĆé ĶĘ│ĶĪ©ńÜäC++Õ«×ńÄ░ķĆÜÕĖĖ...
ĶĘ│ĶĪ©ńøĖÕ»╣õ║ÄÕģČõ╗¢µĢ░µŹ«ń╗ōµ×äÕ”éÕ╣│ĶĪĪõ║īÕÅēµĀæ’╝łÕ”éAVLµĀæŃĆüń║óķ╗æµĀæ’╝ēĶĆīĶ©Ć’╝īÕģʵ£ēĶŠāõĮÄńÜäń®║ķŚ┤ÕżŹµØéÕ║”’╝īÕøĀõĖ║õĖŹķ£ĆĶ”üĶ┐øĶĪīµŚŗĶĮ¼ńŁēµōŹõĮ£µØźõ┐صīüÕ╣│ĶĪĪŃĆéÕģȵ¤źĶ»óµĢłńÄćńÜäÕ╣│ÕØ浌ČķŚ┤ÕżŹµØéÕ║”õĖ║O(logn)’╝īĶÖĮńäȵ£ĆÕØŵāģÕåĄõĖŗńÜäÕżŹµØéÕ║”õĖ║O(n)’╝īõĮåÕ«×ķÖģÕ║öńö©õĖŁńö▒õ║Ä...
AdvancedDataStructures:Õż¦ÕŁ”µŚČµ£¤ÕŁ”õ╣ĀµĢ░µŹ«ń╗ōµ×äńÜäC ++µ║ÉńĀü’╝īÕīģÕɽAVLµĀæ’╝īTreap’╝īÕżÜõĖ¬µ£ēÕ║ÅķōŠĶĪ©ÕÉłÕ╣Č’╝īõ║īÕÅēµ¤źµēŠµĀæ’╝īõ║īķĪ╣ÕĀå’╝īń║óķ╗æµĀæ’╝īµēŁµø▓µĀæ’╝īĶĘ│ĶĪ©’╝īµĀłõĖĵĢ░ķćÅńøĖõ║Ƶ©Īµŗ¤õ╗źÕÅŖµ£ĆÕ░Å’╝łÕż¦’╝ēÕĆ╝µö╣Õ¢ä’╝īõĖ╗ÕĖŁµĀæńÜäC ++ńēłÕ«×ńÄ░’╝īµ¼óĶ┐ĵīćÕć║...
ÕÉīµŚČ’╝īõĖ║õ║åµĆ¦ĶāĮõ╝śÕī¢’╝īÕÅ»õ╗źķććńö©µø┤ķ½śµĢłńÜäµĢ░µŹ«ń╗ōµ×äÕ”éĶć¬Õ╣│ĶĪĪõ║īÕÅēµÉ£ń┤óµĀæ’╝łAVLµł¢ń║óķ╗æµĀæ’╝ēµø┐õ╗ŻÕ║ĢÕ▒éķōŠĶĪ©’╝īõĮåĶ┐ÖÕ░åÕó×ÕŖĀÕ«×ńÄ░ńÜäÕżŹµØéµĆ¦ŃĆé ķĆÜĶ┐ćĶ┐Öń¦Źµ¢╣Õ╝Å’╝īĶĘ│ĶĪ©ĶāĮÕż¤Õ£©C++õĖŁÕ«×ńÄ░ķ½śµĢłõĖöńüĄµ┤╗ńÜäµĢ░µŹ«µ¤źµēŠÕŖ¤ĶāĮ’╝īńē╣Õł½ķĆéÕÉłÕżäńÉåÕż¦ķćÅÕŖ©µĆüÕÅśÕī¢...
õ║īÕÅēµĀæńÜäµ”éÕ┐ĄÕÅ»õ╗źµŗōÕ▒ĢÕł░ÕżÜń¦ŹÕżŹµØéńÜäµĀæń╗ōµ×ä’╝īõŠŗÕ”éÕ╣│ĶĪĪõ║īÕÅēµĀæ’╝łAVL Tree’╝ēŃĆüń║óķ╗æµĀæ’╝łRed-Black Tree’╝ēńŁēŃĆéÕ«āõ╗¼ĶāĮÕż¤õ╗źĶŠāķ½śńÜäµĢłńÄćĶ┐øĶĪīµÉ£ń┤óŃĆüµÅÆÕģźÕÆīÕłĀķÖżµōŹõĮ£’╝īÕ░żÕģČÕ£©Õ«×ńÄ░õ╝śÕģłķś¤ÕłŚŃĆüÕĀåÕÆīµÄÆÕ║Åń«Śµ│ĢõĖŁµē«µ╝öńØĆķćŹĶ”üĶ¦ÆĶē▓ŃĆéõ║īÕÅēµÉ£ń┤ó...
µ£¼µ¢ćÕ░åµĘ▒ÕģźµÄóĶ«©µĀćķóśŌĆ£c.rar_c++Õī║ķŚ┤µĀæ_Õī║ķŚ┤µĀæŌĆصēƵȥńø¢ńÜäÕćĀõĖ¬ķćŹĶ”üń¤źĶ»åńé╣’╝ÜÕī║ķŚ┤µĀæŃĆüń║óķ╗æµĀæŃĆüõ║īÕłåµ¤źµēŠŃĆüÕżÜń¦ŹµÄÆÕ║Åń«Śµ│Ģõ╗źÕÅŖÕ┐½ķƤń¤®ķśĄĶ┐Éń«ŚŃĆéĶ┐Öõ║øń¤źĶ»åńé╣Õ£©Õ«×ķÖģń╝¢ń©ŗõĖŁµ£ēńØĆÕ╣┐µ│øńÜäÕ║öńö©’╝īÕ░żÕģȵś»Õ£©µĢ░µŹ«ń╗ōµ×äÕÆīń«Śµ│ĢĶ«ŠĶ«ĪõĖŁŃĆé 1. **...
µ£¼µ¢ćµŚ©Õ£©µÄóĶ«©õĖŹÕÉīńÜäÕŁŚÕģĖÕ«×ńÄ░µ¢╣Õ╝Å’╝īÕīģµŗ¼ÕōłÕĖīĶĪ©’╝łHash Tables’╝ēŃĆüń║óķ╗æµĀæ’╝łRed-Black Trees’╝ēŃĆüAVLµĀæ’╝łAVL Trees’╝ēõ╗źÕÅŖĶĘ│ĶĪ©’╝łSkip Lists’╝ēŃĆéķĆēµŗ®Ķ┐Öõ║øµĢ░µŹ«ń╗ōµ×äĶ┐øĶĪīńĀöń®ČńÜäÕĤÕøĀÕ£©õ║ÄõĮ£ĶĆģÕ£©ÕĘźõĖÜÕ«×ĶĘĄõĖŁńÜäń╗ÅÕÄåŌĆöŌĆöÕ£©ÕŠłÕżÜÕ£║ÕÉłõĖŗ...
ĶĆīÕłåÕĖāÕ╝Åń│╗ń╗¤ķ½śń║¦ń╗ōµ×äÕ”éĶĘ│ĶĪ©ŃĆüń║óķ╗æµĀæÕłÖńö©õ║Äõ╝śÕī¢ÕżŹµØéńÜäµĢ░µŹ«Õ║ōµōŹõĮ£ŃĆé Õ£©AIµŖƵ£»ńÜäÕ║öńö©õĖŁ’╝īµĢ░µŹ«ń╗ōµ×äńÜäõĮ£ńö©µø┤µś»µśŠĶæŚŃĆéAI AgentńÜäÕżÜõ╗╗ÕŖĪÕŹÅÕÉīõĮ┐ńö©ÕøŠń╗ōµ×äµØźń«ĪńÉåõ╗╗ÕŖĪõŠØĶĄ¢Õģ│ń│╗’╝īķü┐ÕģŹÕŠ¬ńÄ»Õå▓ń¬ü’╝īÕ╣ČķĆÜĶ┐ćõ╝śÕģłķś¤ÕłŚÕŖ©µĆüÕłåķģŹķ½śõ╝śÕģłń║¦...
Ķ┐ÖõĖżń¦ŹµĢ░µŹ«ń╗ōµ×äõĖÄõ╝Āń╗¤ńÜäAVLµĀæŃĆüń║óķ╗æµĀæŃĆüBµĀæµł¢õ╝ĖÕ▒ĢµĀæńøĖµ»ö’╝īÕģČńē╣ńé╣Õ£©õ║ÄÕ«āõ╗¼õ╗źõĖĆń¦ŹķÜŵ£║ńÜäµ¢╣Õ╝ÅĶ┐øĶĪīÕ╣│ĶĪĪ’╝īõ╗ÄĶĆīń«ĆÕī¢õ║åÕ«×ńÄ░Ķ┐ćń©ŗŃĆé TreapµĀæ’╝īõ╣¤Ķó½ń¦░õĖ║õ║īÕÅēµÉ£ń┤óµĀæÕĀå’╝īµś»õĖĆń¦Źõ║īÕÅēµÉ£ń┤óµĀæ’╝īÕ«āÕ░åÕĀå’╝łHeap’╝ēńÜäµĆ¦Ķ┤©õĖÄõ║īÕÅēµÉ£ń┤óµĀæ...
ń¼¼1 Ķ»Š|µĢ░µŹ«ń╗ōµ×äõĖÄń«Śµ│ĢµĆ╗Ķ¦ł ń¼¼ 2Ķ»Š|Ķ«Łń╗āÕćåÕżćÕÆīÕżŹµØéÕ║”Õłåµ×É ń¼¼ 3 Ķ»Š|µĢ░ń╗äŃĆüķōŠĶĪ©ŃĆüĶĘ│ĶĪ© ...ń¼¼ 15 Ķ»Š|ń║óķ╗æµĀæÕÆīAVLµĀæ ń¼¼ 16 Ķ»Š|õĮŹĶ┐Éń«Ś ń¼¼ 17 Ķ»Š|ÕĖāķÜåĶ┐ćµ╗żÕÖ©ÕÆīLRU Cache ń¼¼ 18 Ķ»Š|µÄÆÕ║Å ń¼¼ 19 Ķ»Š|ÕŁŚń¼”õĖ▓µōŹõĮ£ ń¼¼ 20Ķ»Š|Õ«īń╗ōõĖ▓Ķ«▓
ń║óķ╗æµĀæ ń║óķ╗æµĀæ ĶĘ│ĶĪ© hls µĄüÕ¬ÆõĮō server golangńż║õŠŗ ctp go ctp go ctp go golang lua robot µ£║ÕÖ©õ║║ httpõ╗ŻńÉå golang oracle golang sql drivers mysql proxy cluster go ÕłåÕĖāÕ╝ŵ¢ćõ╗Čń│╗ń╗¤ µ¢ćµĪŻńö¤µłÉÕĘźÕģĘ ńł¼ĶÖ½ html µŖōÕÅ¢...