

简单说就是可以给ES集群中的节点分配不同角色,每种角色干的活都不一样。
Master
主要负责集群中索引的创建、删除以及数据的Rebalance等操作。Master不负责数据的索引和检索,所以负载较轻。当Master节点失联或者挂掉的时候,ES集群会自动从其他Master节点选举出一个Leader。为了防止脑裂,常常设置参数为discovery.zen.minimum_master_nodes=N/2+1,其中N为集群中Master节点的个数。建议集群中Master节点的个数为奇数个,如3个或者5个。
设置一个几点为Master节点的方式如下:
node.master: true
node.data: false
node.ingest: false
search.remote.connect: false
Data Node
主要负责集群中数据的索引和检索,一般压力比较大。建议和Master节点分开,避免因为Data Node节点出问题影响到Master节点。
设置一个几点为Data Node节点的方式如下:
node.master: false
node.data: true
node.ingest: false
search.remote.connect: false
Coordinating Node
对于协调节点,个人觉得官网说的很清楚,很简练。


Ingest Node
Ingest node专门对索引的文档做预处理,实际中不常用,除非文档在索引之前有大量的预处理工作需要做。Ingest node设置如下:
node.master: false node.master: false node.master: false
node.data: false
node.ingest: true
search.remote.connect: false
Tribe Node
Tribe Node主要用于跨级群透明访问。但是官方已经不建议使用了,在5.4.0版本以后已经废弃掉了,在7.0的版本中将移除该功能。在5.5版本以后建议使用Cross-cluster search替代Tribe Node。
总结:
小集群可以不考虑结群节点的角色划分,大规模ES集群建议将Master Node、Data Node和Coordinating Node独立出来,每个节点各司其职。
在生产环境下,如果不修改elasticsearch节点的角色信息,在高数据量,高并发的场景下集群容易出现脑裂等问题。
默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,即双重角色。
由两个属性控制:node.master和node.data,默认情况下这两个属性的值都是true:
* node.master:表示节点是否具有成为主节点的资格,值为true并不意味着这个节点就是主节点,真正的主节点是由多个具有主节点资格的节点进行选举产生的。
* node.data:表示节点是否存储数据。
这两个属性可以有四种组合:
* 第一种,这种组合表示这个节点即有成为主节点的资格,又存储数据,
这个时候如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。elasticsearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,这样相当于主节点和数据节点的角色混合到一块了。
node.master: true
node.data: true
* 第二种:这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。后期提供存储和查询服务。
node.master: false
node.data: true
第三种:这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。这个节点我们称为master节点
node.master: true
node.data: false
第四种:这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
node.master: false
node.data: false
默认情况下,每个节点都有成为主节点的资格,也会存储数据,还会处理客户端的请求。
在一个生产集群中我们可以对这些节点的职责进行划分。
建议集群中设置3台以上的节点作为master节点,这些节点只负责成为主节点,维护整个集群的状态。
再根据数据量设置一批data节点,这些节点只负责存储数据,后期提供建立索引和查询索引的服务,这样的话如果用户请求比较频繁,这些节点的压力也会比较大。
所以在集群中建议再设置一批client节点
这些节点只负责处理用户请求,实现请求转发,负载均衡等功能。
master节点:普通服务器即可(CPU 内存 消耗一般)
data节点:主要消耗磁盘,内存
client节点:普通服务器即可(如果要进行分组聚合操作的话,建议这个节点内存也分配多一点)
原文链接:https://blog.csdn.net/psc0606/article/details/80247662
1、问题引出
ES5.X节点类型多了ingest节点类型。
针对3个节点、5个节点或更多节点的集群,如何配置节点角色才能使得系统性能最优呢?
2、ES2.X及之前版本节点角色概述

3、ES5.X节点角色清单

由于其他几种类型节点和用途都很好理解,无非主节点、数据节点、路由节点。
Ingest的用途:
1)Ingest节点和集群中的其他节点一样,但是它能够创建多个处理器管道,用以修改传入文档。类似 最常用的Logstash过滤器已被实现为处理器。
2)Ingest节点 可用于执行常见的数据转换和丰富。 处理器配置为形成管道。 在写入时,Ingest Node有20个内置处理器,例如grok,date,gsub,小写/大写,删除和重命名。
3)在批量请求或索引操作之前,Ingest节点拦截请求,并对文档进行处理。
这样的处理器的一个例子可以是日期处理器,其用于解析字段中的日期。
另一个例子是转换处理器,它将字段值转换为目标类型,例如将字符串转换为整数。
4、ES5.X节点组合类型有多种类型,如何抉择?
Elasticsearch的员工 Christian_Dahlqvist解读如下:
一个节点的缺省配置是:主节点+数据节点两属性为一身。对于3-5个节点的小集群来讲,通常让所有节点存储数据和具有获得主节点的资格。你可以将任何请求发送给任何节点,并且由于所有节点都具有集群状态的副本,它们知道如何路由请求。
通常只有较大的集群才能开始分离专用主节点、数据节点。 对于许多用户场景,路由节点根本不一定是必需的。
专用协调节点(也称为client节点或路由节点)从数据节点中消除了聚合/查询的请求解析和最终阶段,并允许他们专注于处理数据。
在多大程度上这对集群有好处将因情况而异。 通常我会说,在查询大量使用情况下路由节点更常见。
5、ES5.X集群中如何设置节点角色
对于3个节点、5个节点甚至更多节点角色的配置,Elasticsearch官网、国内外论坛、博客都没有明确的定义。
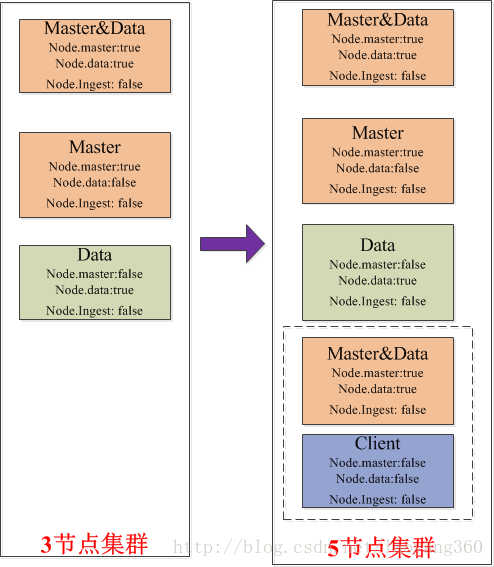
我的思考如下:
1)对于Ingest节点,如果我们没有格式转换、类型转换等需求,直接设置为false。
2)3-5个节点属于轻量级集群,要保证主节点个数满足((节点数/2)+1)。
3)轻量级集群,节点的多重属性如:Master&Data设置为同一个节点可以理解的。
4)如果进一步优化,5节点可以将Master和Data再分离。
6、小结
1)Elasticsearch博大精深,尤其新的5.X特性比较多,需要进一步深入研究;
2)集群的配置还有赖于进一步事件总结,再好的理论部署实践都是“花瓶”;
3)貌似图示划分了这么细、写了那么多,以官网为基准,也顺带调研了N多文档,但对Ingest节点的作用依然理解的不够深。希望大家评论探讨下。
原文链接:https://blog.csdn.net/laoyang360/article/details/78290484



相关推荐
Elasticsearch 的实用知识库分享涵盖了故障探测和恢复机制、集群故障探测、故障恢复机制、节点角色划分、集群架构原理、基本概念和工作原理、分布式搜索引擎、Translog 机制、refresh 机制和故障处理机制等方面的...
1. **Cluster(集群)**:ES集群由多个节点组成,其中一个节点担任主节点(Master Node),负责协调集群中的各种操作,如索引分配、节点状态管理和元数据更新。主节点是通过选举产生的,集群对外表现为一个整体,与...
2. 修改配置文件:`elasticsearch.yml`,设置节点名称、网络监听地址、集群名称、节点角色等。 3. 启动服务:运行Elasticsearch可执行文件启动服务。 4. 插件安装:根据需求安装相应的Elasticsearch插件,如Kibana...
`elasticsearch.yml` 文件包含了配置节点角色、内存分配、网络设置等关键参数。例如: - `node.name`: 设置节点的唯一名称。 - `cluster.name`: 指定要加入的集群名称。 - `network.host`: 配置节点监听的网络地址...
**节点(Nodes)** 是构成Elasticsearch集群的基本单元,每个节点都存储部分数据并参与集群的操作。Elasticsearch-admin允许用户监控每个节点的资源使用情况(如内存、CPU)、角色(主节点、数据节点等)以及节点间...
这种情况下,需要考虑网络配置、磁盘空间、内存大小等硬件资源,以及集群配置、节点角色划分等软件配置。 **2.3. 中文分词集成** 对于中文文本的处理,ElasticSearch内置了中文分词器,如IK分词器,以支持中文文档...
Elasticsearch是一个开源的全文搜索引擎,它以其高效、可扩展和易用性在IT行业中备受推崇,尤其在大数据分析和实时搜索领域应用...了解并掌握这些知识点,将有助于在Windows环境中构建高效且稳定的Elasticsearch集群。
4. **集群与节点**:Elasticsearch 以集群的形式运行,由多个节点组成。每个节点都是集群的一部分,可以存储和处理数据。通过配置 `cluster.name`,可以将多个节点加入同一个集群,实现数据的共享和负载均衡。 5. *...
接着,源代码部分可能包含了如何设置和配置Elasticsearch集群的示例。这可能包括创建索引、映射字段、导入数据、搜索查询以及性能优化等方面。例如,你可能会看到如何使用Java API或者curl命令来与Elasticsearch交互...
4. 集群和节点:Elasticsearch集群由多个节点组成,每个节点可以加入或离开集群,集群会自动调整数据分布。节点之间通过Gossip协议进行通信,确保集群状态的一致性。 5. 数据分片和副本:Elasticsearch将大型索引...
在Elasticsearch中,索引(Index)是文档的容器,可以将文档划分为逻辑分类。一个索引由多个分片(Shard)组成,分片可以分布在集群中的多个节点上。为了提高容错性,每个分片可以有多个副本(Replica),当主分片...
Elasticsearch集群中的节点能够自动发现彼此,形成一个动态变化的网络。源码展示了如何实现节点的加入、离开和重新平衡,以及心跳检测和故障检测机制。 9. 插件系统: Elasticsearch的插件机制使得开发者可以扩展其...
1. **节点(Node)**:Elasticsearch集群由多个节点组成,每个节点都是一个正在运行的Elasticsearch实例,可以存储和处理数据。 2. **索引(Index)**:索引是Elasticsearch中的逻辑空间,用于存储相似类型的数据,类似...
Elasticsearch 基于 Lucene 库,但提供了更高级别的 API 和集群管理能力,使得大规模数据搜索变得简单而高效。 **Elasticsearch 安装** 在安装 Elasticsearch 之前,确保你的系统已经安装了兼容的 Java 运行环境...
在《Elasticsearch技术解析与实战》一书中,你将详细了解到如何安装配置Elasticsearch,设置集群,以及优化索引和查询性能。《Elasticsearch 权威指南(中文版)清晰PDF》则更深入地探讨了高级特性和最佳实践,包括...
1. **节点(Node)**:Elasticsearch 集群中的每一个运行实例称为节点,节点之间通过网络进行通信。节点可以配置为主节点或数据节点,主节点负责集群状态的管理,数据节点则存储数据。 2. **集群(Cluster)**:由...
9. **监控与告警**:通过使用Elastic Stack中的Kibana,可以可视化Elasticsearch集群的状态,包括性能指标、日志等,同时可以设置告警规则。 10. **安全性**:Elasticsearch 7.7.1版本可能包含了安全管理功能,如...
- 在Elasticsearch集群中,节点之间会自动发现彼此,新加入的节点可以快速参与到集群工作中。同时,如果某个节点失效,集群会自动重新分配其上的分片,确保服务的连续性。 7. **映射(Mapping)** - 映射定义了...
为了管理和监控Elasticsearch集群,你可以使用Elasticsearch的内置工具,如cat API、监视器插件,或者集成第三方工具如Grafana、Prometheus等。定期检查和优化索引设置、内存使用情况、搜索性能等,确保集群的健康和...
默认情况下,节点会加入名为“elasticsearch”的集群,但可以设置不同的集群名称以创建独立的集群。节点数量理论上无上限,实际应用中通常为了性能和高可用性,会设置3个或更多的节点。 **三、分片(Shards)与副本...