
Impala Shell 命令汇总和 ImpalaSQL研究
1、Impala 外部 Shell
Impala外部Shell 就是不进入Impala内部,直接执行的ImpalaShell 例如通过外部Shell查看Impala帮助可以使用: $ impala-shell -h 这样就可以查看了;
再例如显示一个SQL语句的执行计划: $ impala-shell -p select count(*) from t_stu
下面是Impala的外部Shell的一些参数:
• -h (--help) 帮助
• -v (--version) 查询版本信息
• -V (--verbose) 启用详细输出
• --quiet 关闭详细输出
• -p 显示执行计划
• -i hostname (--impalad=hostname) 指定连接主机格式hostname:port 默认端口21000
• -r(--refresh_after_connect)刷新所有元数据
• -q query (--query=query) 从命令行执行查询,不进入impala-shell
• -d default_db (--database=default_db) 指定数据库
• -B(--delimited)去格式化输出
• --output_delimiter=character 指定分隔符
• --print_header 打印列名
• -f query_file(--query_file=query_file)执行查询文件,以分号分隔
• -o filename (--output_file filename) 结果输出到指定文件
• -c 查询执行失败时继续执行
• -k (--kerberos) 使用kerberos安全加密方式运行impala-shell
• -l 启用LDAP认证
• -u 启用LDAP时,指定用户名
2、Impala内部Shell
使用命令 $ impala-sehll 可以进入impala,在这里可以像Hive一样正常使用SQL,而且还有一些内部的impala命令:
• help
• connect <hostname:port> 连接主机,默认端口21000
• refresh <tablename> 增量刷新元数据库
• invalidate metadata 全量刷新元数据库
• explain <sql> 显示查询执行计划、步骤信息
• set explain_level 设置显示级别(0,1,2,3)
• shell <shell> 不退出impala-shell执行Linux命令
• profile (查询完成后执行) 查询最近一次查询的底层信息
例:查看帮助可以直接使用: help ,要刷新一个表的增量元数据可以使用 refresh t_stu;
3、Impala 的监护管理
可以通过下面的链接来访问Impala的监护管理页面:
• 查看StateStore
– http://node1:25020/
• 查看Catalog
– http://node1:25010/
4、Impala 存储&&分区
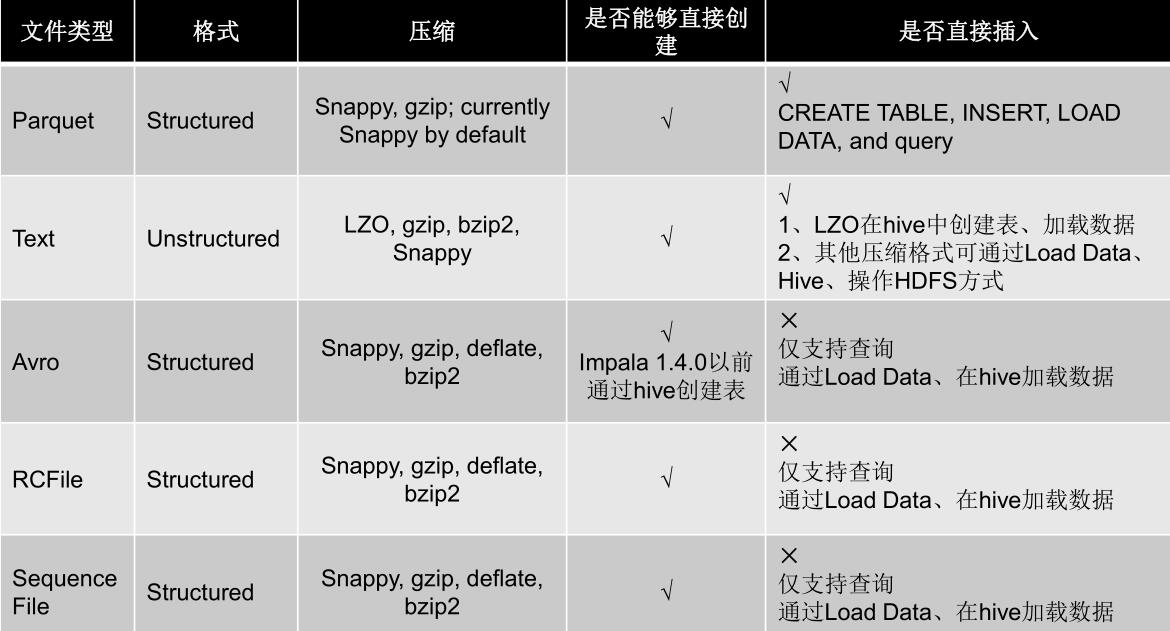
下面是Impala对文件的格式及压缩类型的支持

• 添加分区方式
– 1、partitioned by 创建表时,添加该字段指定分区列表
– 2、使用alter table 进行分区的添加和删除操作
|
1
2
3
4
|
create table t_person(id int, name string, age int) partitioned by (type string);
alter table t_person add partition (sex=‘man');
alter table t_person drop partition (sex=‘man');
alter table t_person drop partition (sex=‘man‘,type=‘boss’);
|
• 分区内添加数据
|
1
2
|
insert into t_person partition (type='boss') values (1,’zhangsan’,18),(2,’lisi’,23)
insert into t_person partition (type='coder') values(3,wangwu’,22),(4,’zhaoliu’,28),(5,’tianqi’,24)
|
• 查询指定分区数据
|
1
|
select id,name from t_person where type=‘coder
|
5、Impala SQL VS HiveQL
下面是Impala对基础数据类型和扩展数据类型的支持

• 此外,Impala不支持HiveQL以下特性:
– 可扩展机制,例如:TRANSFORM、自定义文件格式、自定义SerDes
– XML、JSON函数
– 某些聚合函数:
• covar_pop, covar_samp, corr, percentile, percentile_approx,histogram_numeric, collect_set
• Impala仅支持:AVG,COUNT,MAX,MIN,SUM
– 多Distinct查询
– HDF、UDAF
– 以下语句:
ANALYZE TABLE (Impala:COMPUTE STATS)、DESCRIBE COLUMN、
DESCRIBE DATABASE、EXPORT TABLE、IMPORT TABLE、SHOW
TABLE EXTENDED、SHOW INDEXES、SHOW COLUMNS
6、Impala SQL
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
--创建数据库create database db1;
use db1;-- 删除数据库use default;
drop database db1;
--创建表(内部表)-- 默认方式创建表:create table t_person1(
id int,
name string)
--指定存储方式:create table t_person2(
id int,
name string
)row format delimitedfields terminated by ‘\0’ (impala1.3.1版本以上支持‘\0’ )
stored as textfile;
--其他方式创建内部表--使用现有表结构:create table tab_3 like tab_1;
--指定文本表字段分隔符:alter table tab_3 set serdeproperties(‘serialization.format’=‘,’,’field.delim’=‘,’);
--插入数据-- 直接插入值方式:insert into t_person values (1,hex(‘hello world’));
--从其他表插入数据:insert (overwrite) into tab_3 select * form tab_2 ;
--批量导入文件方式方式:load data local inpath ‘/xxx/xxx’ into table tab_1;
--创建表(外部表)--默认方式创建表:create external table tab_p1(
id int,
name string
)location ‘/user/xxx.txt’
--指定存储方式:create external table tab_p2 like parquet_tab
‘/user/xxx/xxx/1.dat’
partition (year int , month tinyint, day tinyint)
location ‘/user/xxx/xxx’
stored as parquet;
--视图--创建视图:create view v1 as select count(id) as total from tab_3 ;
--查询视图:select * from v1;
--查看视图定义:describe formatted v1 |
• 注意:
– 1)不能向impala的视图进行插入操作
– 2)insert 表可以来自视图
• 数据文件处理
– 加载数据:
• 1、insert语句:插入数据时每条数据产生一个数据文件,不建议用此方式加载批量数据
• 2、load data方式:再进行批量插入时使用这种方式比较合适
• 3、来自中间表:此种方式使用于从一个小文件较多的大表中读取文件并写入新的表生产少量的数据文件。也可以通过此种方式进行格式转换。
– 空值处理:
• impala将“\n”表示为NULL,在结合sqoop使用是注意做相应的空字段过滤,
• 也可以使用以下方式进行处理:
alter table name set tblproperties(“serialization.null.format”=“null”)
----------------------------------------------------------------------------------------------------------------------------------
本文主要介绍Impala shell命令
1、-h 外能帮助
格式:$ impala-shell -h
2、-r 刷新整个元数据*
(Refresh Impala catalog after connecting,默认为false)
2.1 在hive创建表t1
hive> create table t1(id int ,name string);
OK
Time taken: 0.423 seconds
2.2 通过impala-shell 查看对应的表,发现不存在,原因是需要通过手动涮新hive metadata
show tables;
$ impala-shell -r
执行后,在通过show tables 可以查看到刚才的表
3、-B 去格式化,查询大数据量时可以提高性能*
3.1 在impala shell中 初始化数据
insert into table t1(id,name) values(100,'sfl');
insert into table t1(id,name) values(101,'zs');
insert into table t1(id,name) values(102,'ls');
3.2 在impala 查看数据和hive中查看数据
select * from t1;
发现结果完成一致,原因就是impala和hive中存储的数据都存在同一个元数据中
3.3 通过-B 演示
$ impala-shell -B -q 'select * from shenfuli.t1;' -o a.txt
$ more a.txt
102 ls
100 sfl
101 zs
通过-B发现,输出格式通过Hive的输出内容一致,由于-r是对整个元数据库进行刷新,实际生产环境中不建议这么用。
3.4 通过-B --print_header 可以显示列的名称
$ impala-shell -B --print_header -q 'select * from shenfuli.t1;' -o c.txt
$ more c.txt
id name
100 sfl
102 ls
101 zs
4、 -v 查看对应版本
$ impala-shell -v
Impala Shell v2.2.0-cdh5.4.4 (a13d3c6) built on Mon Jul 6 16:57:34 PDT 2015
$ impala-shell
Starting Impala Shell without Kerberos authentication
Connected to crxy168:21000
Server version: impalad version 2.2.0-cdh5.4.4 RELEASE (build a13d3c6b203e79a284b509df821bffbe229e6dc3)
Welcome to the Impala shell. Press TAB twice to see a list of available commands.
Copyright (c) 2012 Cloudera, Inc. All rights reserved.
(Shell build version: Impala Shell v2.2.0-cdh5.4.4 (a13d3c6) built on Mon Jul 6 16:57:34 PDT 2015)
注: 一般情况下升级Impala后,需要检查Impala version和Impala shell version,两个版本必须一致,否则可能会出现查询异常的情况。
5、 -f 执行查询文件*
--query_file 指定查询文件
$ cat impala-sql
select * from shenfuli.t1;
$ impala-shell -f impala-sql ;
$ impala-shell -B -f impala-sql -o d.txt;
$ more d.txt
102 ls
100 sfl
101 zs
说明: 实际工作中的SQL语句都是通过写到一个文件中,然后通过-f命令调用。
6、 -o 保存执行结果到文件*
--output_file 指定输出文件名
7、 -q 不进入impala-shell执行查询
$ impala-shell -q 'select * from shenfuli.t1' --output_file=b.txt
$ more b.txt
+-----+------+
| id | name |
+-----+------+
| 102 | ls |
| 100 | sfl |
| 101 | zs |
+-----+------+
8、 -p 显示执行计划
--quiet 不显示多余信息
$ impala-shell -q 'select * from shenfuli.t1;' -p >1.txt
说明: 文件1.txt 含有详细的执行计划,通过该文件可以分析SQL,优化SQL语句。
9、刷新某个表元数据
refresh <tablename> 属于增量刷新
说明: 相比-r,通过refresh 一个表更加使用,并且属于增量刷新。
10、显示一个查询的执行计划及各步骤信息
explain <sql> 可以设置set explain_level,总共分成4个级别,分别0-3。数字越大,输出信息越详细
11、显示查询底层信息(底层执行计划,用于性能优化)
profile 在查询完成之后执行
在集群中运行一段时间发现执行变慢,可以只用profile来检查
参考from:
https://blog.csdn.net/hxpjava1/article/details/54924856
https://blog.csdn.net/shenfuli/article/details/49075003



相关推荐
Hadoop 是一个基于分布式存储和计算的开源框架,Hive 是基于 Hadoop 的一个数据仓库工具,Impala 是一个高性能的分布式SQL查询引擎。在这篇文章中,我们将会了解 Hadoop 文件系统、Hive 和 Impala 的基本操作。 ...
3. **标准SQL支持**:Impala支持标准SQL语法,使得用户可以直接使用熟悉的SQL语句进行数据查询。 4. **低延迟**:Impala通过内存计算技术和高效的查询优化策略,实现对大数据集的低延迟响应。 5. **可扩展性**:...
Impala是一个现代的开源SQL查询引擎,它从头开始就被设计为充分利用Hadoop的灵活性和可扩展性。其核心设计目标是结合传统分析型数据库的熟悉SQL支持和多用户性能,同时提供Apache Hadoop的可扩展性和灵活性,以及...
关于IMPALA SQL 从基础语法开始 包括 函数 聚合函数 编写流程等等,对于学过ORACLE SQL的同学,来看IMPALA SQL 会比较熟悉,ORACEL 跟IMPALA 语法和函数类型 定义上 都稍有区别,但是,我已经在文档中写下了实例,...
Impala专注于提供低延迟的交互式SQL查询,直接在Hadoop集群上运行,与Hive配合使用,并利用相同的数据存储和元数据。 在开始介绍Apache Impala之前,首先要了解它的优势。Impala带来了更快的查询速度,减少了对复杂...
在安全模式下,需要通过Kerberos认证来连接impala-shell,具体操作为执行`kinit`命令和`impala-shell`命令。 在数据导入部分,文档讲解了Impala中的“内部表”和“外部表”的概念。内部表由Impala管理,删除时会...
#### 2.5 ImpalaShell - **命令行参数**:用于控制Impala-shell的行为,如指定主机名、端口等。 - **执行命令**:在Impala-shell中输入SQL语句或其他命令来执行查询或管理任务。 #### 2.6 Impala性能优化 - **...
3. **Impala Shell**:Impala自带的命令行工具,方便直接对Impala进行操作。 **文件“car.html”** 提到的"car.html"文件可能包含一个关于汽车数据的示例或者是一个用于演示Impala查询的测试数据集。在Impala中,...
- **Impala SQL 方言**: 提供类似于 SQL-92 的查询语言,但具有额外的功能和优化。 - **编程接口**: 提供多种编程接口,如 Java API,便于开发者集成应用。 - **与 Hive 的协同工作**: Impala 与 Hive 共享相同的元...
这可能需要调整系统中Impala Shell的默认版本,通过alternatives命令将Impala Shell的链接指向新版本的二进制程序。 验证Impala与Kudu的集成,你可以打开Impala Shell并执行SQL查询,如`select if (version() like ...
3. **CLI**:提供命令行工具Impala Shell,以及其他接口如Hue、JDBC和ODBC,供用户进行查询。 **与Hive的关系** Hive主要适用于长时间的批处理查询分析,而Impala则更适合实时交互式SQL查询。两者的元数据、SQL...
Apache Hadoop生态圈的顶级项目之一,解决了传统Lamda架构处理Hadoop上快速变化数据的存储和处理技术过于复杂的问题,同时Kudu能够与Hadoop生态的其他组件比如Impala、Spark、Flume和Kafka等组件集成,大大降低了对...
Impala provides fast, interactive SQL queries directly on your Apache Hadoop data stored in HDFS, HBase, or theAmazon Simple Storage Service (S3). In addition to using the same unified storage ...
* Impala SQL Dialect:Impala 使用的一种基于 SQL 的查询语言 * Impala Programming Interfaces:Impala 提供了多种编程接口,例如 JDBC、ODBC 等 Impala 在 Hadoop 生态系统中的角色 Impala 在 Hadoop 生态系统...
2. MASTER 节点上安装 Impala-shell:使用以下命令安装 Impala-shell: ``` sudo yum install impala-shell ``` Impala 配置 在安装完成后,需要对 Impala 进行配置。Impala 的配置文件位于 `/etc/default/impala`...
由于impala处理日期的函数如date_sub(),date_trunc(),last_day()等这些日期处理函数还需要进行日期格式化为yyyy-MM-dd使用,sql代码段过长,导致频繁嵌套过于复杂.所以自定义udf函数解决这些问题.以下为实现过程.
通过上述知识点的详细说明,我们可以深入理解Impala的架构设计和运行机制,以及它是如何通过Thrift RPC通信来协调各个组件,实现高效的SQL查询处理。Impala相较于传统Hadoop的MapReduce处理方式,能够以更低的延迟和...
集成Impala意味着我们可以直接在SpringBoot应用中执行SQL查询,访问存储在Impala的数据。 2. **yml文件**: `application-dev.yml`是SpringBoot应用的配置文件,用于定义开发环境的配置属性。在这个特定的例子中,...
在Impala的架构中,Impala守护进程是执行SQL查询的前端,Impala状态存储负责维护集群状态的元数据,而Impala目录服务则管理和检索元数据。这些组件共同协作,实现高效的数据查询和处理。Impala将元数据存储在Hive元...
Impala 的初体验可以通过启动 Impala shell,查看数据库,打开默认数据库等操作来实现。 Impala 是一种高性能的交互式 SQL 查询引擎,具有多种优点,但也存在一些缺点。Impala 的架构、安装和监护管理都是非常重要...