consistent hashingô ÓÛÌ°ÌˋÍ´ô 1997ô Í¿ÇͯÝÍ´ÒÛ¤Ìô Consistent hashing and random treesô ð¡ÙÒ¨Ìͤÿ¥ÓÛÍÍ´ô cacheô Ó°£Ó£ð¡ÙͤӴÒÑÌËÒÑÍ¿¢Ì°ÿ¥
1ô ̘ͤͤÌ₤
Ì₤ÍÎð§ Ìô Nô ð¡ˆô cacheô ÌÍÀÍ´ÿ¥ÍÕÂÓÛÓϯô cacheô ÿ¥ÿ¥ÕÈð¿ÍÎð§Í¯ð¡ð¡ˆÍ₤¿ÒÝÀô objectô Ì Í¯Í¯ô Nô ð¡ˆô cacheô ð¡ÍÂÿ¥ð§ ̓Í₤Ò§ð¥ÕÓ´ÓÝ£ð¥¥ð¡ÕÂÓÕÓ´Ì¿Ì°ÒÛÀÓÛô objectô Óô hashô Í¥ÿ¥ÓÑÍÍÍÓÌ Í¯Í¯Í¯ô Nô ð¡ˆô cacheô ÿ¥
hash(object)%N
ð¡ÍÕ§Ò¢ÒÀÌÙÈÍ¡¡ÿ¥ÍÒÒÍÎð¡Óð¡ÊÓÏÌ
Íçÿ¥
1ô ð¡ð¡ˆô cacheô ÌÍÀÍ´ô m downô Ìð¤ÿ¥Í´ÍÛÕ
ͤӴð¡ÙÍ¢
ÕÀ£ÒÎÒÒÒ¢ÓÏÌ
Íçÿ¥ÿ¥Ò¢Ì ñÌÌÌ Í¯Í¯ô cache mô ÓÍ₤¿ÒÝÀÕ§ð¥ÍÊÝÌÿ¥Ìð¿Íÿ¥ÕÒÎÌô cache mô ð£ô cacheô ð¡ÙÓÏ£ÕÊÿ¥Ò¢ÌÑÍô cacheô Ì₤ô N-1ô ͯÿ¥Ì ͯÍ
˜Í¥ÍÌð¤ô hash(object)%(N-1)ô ÿ¥
2ô ÓÝð¤ÒÛ¢ÕÛÍ Õÿ¥ÕÒÎÌñ£Í ô cacheô ÿ¥Ò¢ÌÑÍô cacheô Ì₤ô N+1ô ͯÿ¥Ì ͯÍ
˜Í¥ÍÌð¤ô hash(object)%(N+1)ô ÿ¥
1ô Íô 2ô ÌÍ°Óð£ð¿ÿ¥Ò¢ÌÍ°ÓÓˆÓÑð¿ÕÇÍ ð¿ÌÌÓô cacheô Õ§ÍÊÝÌð¤ÐÍ₤¿ð¤ÌÍÀÍ´ÒÒ´ÿ¥Ò¢Ì₤ð¡Í¤ÓƒÕƒÿ¥ÌLj̯ÇÒ˜ÓÒÛ¢ÕÛÕ§ð¥ÓÇÌËÍýÍÍͯÌÍÀÍ´ÿ¥
ÍÌËÒÒÓ˜˜ð¡ð¡ˆÕÛÕÂÿ¥ÓÝð¤ÓÀ˜ð£ÑÒ§ÍÒÑÌËÒÑÍ¥¤ÿ¥ð§ Í₤ҧ̰ÒÛˋÍÕÂÌñ£Í ÓÒÓ¿ÍÊÍÓ¿ÌÇ£ÿ¥ÌƒÓÑð¡ÕÂÓô hashô ÓÛÌ°ð¿Íð¡Í¯Ð
ô ô Ìð£ð¿Ì¿Ì°Í₤ð£ËÌ¿ÍÒ¢ð¡ˆÓÑÍçÍÂÿ¥Ò¢Í¯ÝÌ₤ô consistent hashing...
2 hashô ÓÛÌ°ÍÍÒ¯ÌÏ
ÐÐô Hashô ÓÛÌ°Óð¡ð¡ˆÒÀÀÕÌÌ Ì₤ÍÒ¯ÌÏÿ¥ô Monotonicityô ÿ¥ÿ¥ÍÛð¿ÍÎð¡ÿ¥
ÐÐÍÒ¯ÌÏÌ₤ÌÍÎÌÍñýÓ£Ìð¡ð¤Í
ÍÛ¿ÕÒ¢ÍÍ¡ÍÌǃͯð¤Ó¡Í¤ÓÓ¥Íýð¡Ùÿ¥ÍÌ̯ÓÓ¥ÍýÍ Í
ËͯӰ£Ó£ð¡ÙÐÍÍ¡ÓÓ£ÌͤҧÍÊð¢Ò₤ÍÌÍñýÍÕ
ÓÍ
ÍÛ¿Í₤ð£ËÒÂ¨Ì Í¯Í¯Ì¯ÓÓ¥Íýð¡ÙÍ£ÿ¥Òð¡ð¥ÒÂ¨Ì Í¯Í¯ÌÏÓÓ¥ÍýÕÍð¡ÙÓÍ
Ñð£Ó¥ÍýͤÐ
ÍÛ¿ÌÓͯÿ¥ð¡ÕÂÓÓÛÍô hashô ÓÛÌ°ô hash(object)%Nô Õƒð£ËÌ£ÀÒÑ°ÍÒ¯ÌÏÒÎÌÝÐ
3 consistent hashingô ÓÛÌ°ÓÍÓ
consistent hashingô Ì₤ð¡ÓÏô hashô ÓÛÌ°ÿ¥ÓÛÍÓÒ₤Çÿ¥Í´ÓÏ£ÕÊô /ô Ìñ£Í ð¡ð¡ˆô cacheô ÌÑÿ¥ÍÛÒ§ÍÊͯ§Í₤ҧͯÓÌ¿ÍÍñýÍÙÍ´ô keyô Ì Í¯Í
°Ó°£ÿ¥Í¯§Í₤Ò§ÓÌ£ÀÒÑ°ÍÒ¯ÌÏÓÒÎÌÝÐ
ð¡ÕÂͯÝÌËÌÓ
Ïô 5ô ð¡ˆÌÙËÕˆÊÓÛÍÒÛýÒÛýô consistent hashingô ÓÛÌ°Ó̘ͤÍÓÐ
3.1ô Ó₤ͧÂhashô Óˋ¤ÕÇ
ÒÒÕÍ¡¡Óô hashô ÓÛÌ°Õ§Ì₤ͯô valueô Ì Í¯Í¯ð¡ð¡ˆô 32ô ð¡¤Óô keyô Í¥ÿ¥ð¿Í°Ì₤ô 0~2^32-1ô ̘ÀÌ¿Ó̯ͥÓˋ¤ÕÇÿ¥Ìð£˜Í₤ð£ËͯҢð¡ˆÓˋ¤ÕÇÌ°ÒÝÀÌð¡ð¡ˆÕÎÿ¥ô 0ô ÿ¥Í¯ƒÿ¥ô 2^32-1ô ÿ¥Ó¡ÌËÓÍÓ₤ÿ¥ÍÎð¡ÕÂ̓ô 1ô ÌÓʤÓÕÈÌ ñÐ

̓ô 1ô Ó₤ͧÂô hashô Óˋ¤ÕÇ
3.2ô ÌÍ₤¿ÒÝÀÌ Í¯Í¯hashô Óˋ¤ÕÇ
ÌËð¡ÌËÒÒô 4ô ð¡ˆÍ₤¿ÒÝÀô object1~object4ô ÿ¥ÕÒ¢ô hashô ̯ͧÒÛÀÓÛͤÓô hashô Í¥ô keyô Í´Ó₤ð¡ÓÍÍ¡ÍÎ̓ô 2ô ÌÓʤÐ
hash(object1) = key1;
ãÎ ãÎ
hash(object4) = key4;

̓ô 2 4ô ð¡ˆÍ₤¿ÒÝÀÓô keyô Í¥ÍÍ¡
3.3ô Ìcacheô Ì Í¯Í¯hashô Óˋ¤ÕÇ
Consistent hashingô Ó̘ͤḬ̀ͯÝÌ₤ͯÍ₤¿ÒÝÀÍô cacheô Õ§Ì Í¯Í¯Íð¡ð¡ˆô hashô ̯ͥÓˋ¤ÕÇð¡Ùÿ¥Í¿Ñð¡ð§¢Ó´Ó¡ÍÓô hashô ÓÛÌ°Ð
ÍÒۃͧÍÌô A,Bô Íô Cô Í
Ýô 3ô ͯô cacheô ÿ¥ÕÈð¿Í
ÑÌ Í¯Ó£ÌͯÍÎ̓ô 3ô ÌÓʤÿ¥ð£ð£˜Í´ô hashô Óˋ¤ÕÇð¡Ùÿ¥ð£ËÍ₤¿Í¤Óô hashô Í¥ÌÍÐ
hash(cache A) = key A;
ãÎ ãÎ
hash(cache C) = key C;

̓ô 3 cacheô ÍÍ₤¿ÒÝÀÓô keyô Í¥ÍÍ¡
ô
Ò₤ÇͯҢÕÿ¥ÕÀ¤ðƒ¢Ìð¡ð¡ô cacheô Óô hashô ÒÛÀÓÛÿ¥ð¡Ò˜ÓÌ¿Ì°Í₤ð£Ëð§¢Ó´ô cacheô ̤ʹÓô IPô ͯÍÌÒ
̤ʹÍð§ð¡¤ô hashô ÒƒÍ
ËÐ
3.4ô ÌÍ₤¿ÒÝÀÌ Í¯Í¯cache
ӯʹô cacheô ÍÍ₤¿ÒÝÀÕ§ÍñýÓ£ÕÒ¢Íð¡ð¡ˆô hashô ÓÛÌ°Ì Í¯Í¯ô hashô ̯ͥÓˋ¤ÕÇð¡Ùð¤ÿ¥ÌËð¡ÌËÒÎÒÒÓͯÝÌ₤ÍÎð§Í¯Í₤¿ÒÝÀÌ Í¯Í¯ô cacheô ð¡ÕÂð¤Ð
Í´Ò¢ð¡ˆÓ₤ͧÂÓˋ¤ÕÇð¡Ùÿ¥ÍÎÌÌý¢ÓÕÀ¤ÌÑÕÌ¿Íð£Í₤¿ÒÝÀÓô keyô ͥͤÍÿ¥ÓÇͯÕÒÏð¡ð¡ˆô cacheô ÿ¥ÕÈð¿Í¯ÝͯÒ₤ËÍ₤¿ÒÝÀÍÙÍ´Í´Ò¢ð¡ˆô cacheô ð¡ÿ¥Í ð¡¤Í₤¿ÒÝÀÍô cacheô Óô hashô Í¥Ì₤ͤÍÛÓÿ¥Í ÌÙÊÒ¢ð¡ˆô cacheô Í¢
ÓÑÌ₤Í₤ð¡ÍÓÀÛÍÛÓÐÒ¢Ì ñð¡Í¯Ý̃ͯð¤Í₤¿ÒÝÀÍô cacheô ÓÌ Í¯Ì¿Ì°ð¤Íÿ¥ÿ¥
ðƒÓÑÓ£ÏÓ£Ùð¡ÕÂÓðƒÍÙÿ¥ÍÒÏ̓ô 3ô ÿ¥ÿ¥ÕÈð¿Ì ¿ÌÛð¡ÕÂÓÌ¿Ì°ÿ¥Í₤¿ÒÝÀô object1ô ͯÒ¨ÍÙʹͯô cache Aô ð¡ÿ¥ô object2ô Íô object3ô Í₤¿Í¤Í¯ô cache Cô ÿ¥ô object4ô Í₤¿Í¤Í¯ô cache Bô ÿ¥
3.5ô ÒÍ₤cacheô ÓÍÍ´
ÍÕÂÒÛýÒ¢ÿ¥ÕÒ¢ô hashô ÓÑÍÌÝð§ÓÌ¿Ì°Í¡ÎÌËÓÌÍÊÏÕÛÕÂͯÝÍ´ð¤ð¡Ò§Ì£ÀÒÑ°ÍÒ¯ÌÏÿ¥Í§ô cacheô ÌÌÍÍ´ÌÑÿ¥ô cacheô ð¥ÍÊÝÌÿ¥Ò¢ÒÍ₤¿ÍͯÌÍÀÍ´Õ ÌÍñ´ÍÊÏÓÍýÍ£ÿ¥Ó¯Í´Í¯ÝÌËÍÌÍÌô consistent hashingô ÓÛÌ°Ð
3.5.1ô ÓÏ£ÕÊô cache
ÒÒÍÒÛƒô cache Bô ÌÌð¤ÿ¥Ì ¿ÌÛð¡ÕÂÒÛýͯÓÌ Í¯Ì¿Ì°ÿ¥Ò¢ÌÑÍͧÝÍÓͯð£
Ì₤ÕÈð¤Ìý¢ô cache Bô ÕÌÑÕÕÍÓÇͯð¡ð¡ð¡ˆô cacheô ÿ¥ô cache Cô ÿ¥ð¿ÕÇÓÍ₤¿ÒÝÀÿ¥ð¿Í°Ì₤̘ÌËÌ Í¯Í¯ô cache Bô ð¡ÓÕÈð¤Í₤¿ÒÝÀÐ
Í ÌÙÊÒ¢Õð£
ÕÒÎÍÍ´Í₤¿ÒÝÀô object4ô ÿ¥Í¯Í
ÑÕÌ¯Ì Í¯Í¯ô cache Cô ð¡Í°Í₤ÿ¥ÍÒÏ̓ô 4ô Ð

̓ô 4 Cache Bô Ò¨ÓÏ£ÕÊÍÓô cacheô Ì Í¯
3.5.2ô Ìñ£Í ô cache
ÍÒÒÌñ£Í ð¡Í¯Ì¯Óô cache Dô ÓÌ
Íçÿ¥ÍÒۃʹҢð¡ˆÓ₤ͧÂô hashô Óˋ¤ÕÇð¡Ùÿ¥ô cache Dô ÒÂ¨Ì Í¯Í´Í₤¿ÒÝÀô object2ô Íô object3ô ð¿ÕÇÐÒ¢ÌÑÍͧÝÍÓͯð£
Ì₤ÕÈð¤Ìý¢ô cache Dô ÕÌÑÕÕÍÓÇͯð¡ð¡ð¡ˆô cacheô ÿ¥ô cache Bô ÿ¥ð¿ÕÇÓÍ₤¿ÒÝÀÿ¥ÍÛð£˜Ì₤ð¿Ì˜ÌËÌ Í¯Í¯ô cache Cô ð¡Í₤¿ÒÝÀÓð¡Õ´Íÿ¥ÿ¥Í¯Ò¢ð¤Í₤¿ÒÝÀÕÌ¯Ì Í¯Í¯ô cache Dô ð¡Í°Í₤Ð
ô
Í ÌÙÊÒ¢Õð£
ÕÒÎÍÍ´Í₤¿ÒÝÀô object2ô ÿ¥Í¯Í
ÑÕÌ¯Ì Í¯Í¯ô cache Dô ð¡ÿ¥ÍÒÏ̓ô 5ô Ð

̓ô 5ô Ìñ£Í ô cache Dô ÍÓÌ Í¯Í
°Ó°£
4ô ÒÌÒÓ¿
ÒÕô Hashô ÓÛÌ°ÓÍÎð¡ð¡ˆÌÌ Ì₤Í¿°ÒÀÀÌÏô (Balance)ô ÿ¥ÍÛð¿ÍÎð¡ÿ¥
Í¿°ÒÀÀÌÏ
ÐÐÍ¿°ÒÀÀÌÏÌ₤ÌÍÍ¡ÓÓ£ÌÒ§ÍÊͯ§Í₤Ò§Íͯ͡ÌÌÓÓ¥Íýð¡ÙÍ£ÿ¥Ò¢Ì ñÍ₤ð£Ëð§¢ÍƒÌÌÓÓ¥ÍýÓˋ¤ÕÇէ̓ͯÍˋÓ´Ð
hashô ÓÛÌ°Í¿Ñð¡Ì₤ð¢Ò₤Ó£Í₤¿ÓÍ¿°ÒÀÀÿ¥ÍÎÌô cacheô ҃ͯÓÒ₤ÿ¥Í₤¿ÒÝÀÍ¿Ñð¡Ò§Ò¨ÍÍÓÌ Í¯Í¯ô cacheô ð¡ÿ¥Ì₤ÍÎÍ´ð¡ÕÂÓðƒÍÙð¡Ùÿ¥ð£
Õ´Ó§ýô cache Aô Íô cache Cô ÓÌ
Íçð¡ÿ¥Í´ô 4ô ð¡ˆÍ₤¿ÒÝÀð¡Ùÿ¥ô cache Aô ð£
ÍÙÍ´ð¤ô object1ô ÿ¥Òô cache Cô ÍÍÙÍ´ð¤ô object2ô Ðô object3ô Íô object4ô ÿ¥ÍÍ¡Ì₤̓ð¡ÍÒÀÀÓÐ
ð¡¤ð¤ÒÏÈÍ°Ò¢ÓÏÌ
Íçÿ¥ô consistent hashingô Í¥Í
Ëð¤ãÒÌÒÓ¿ãÓÌÎÍ¢çÿ¥ÍÛÍ₤ð£ËÍÎð¡ÍÛð¿ÿ¥
ãÒÌÒÓ¿ãÿ¥ô virtual nodeô ÿ¥Ì₤ÍÛÕ
ÒÓ¿Í´ô hashô Óˋ¤ÕÇÓÍÊÍÑÍÿ¥ô replicaô ÿ¥ÿ¥ð¡ÍÛÕ
ð¡ˆÒÓ¿Í₤¿Í¤ð¤ÒËÍ¿ýð¡ˆãÒÌÒÓ¿ãÿ¥Ò¢ð¡ˆÍ₤¿Í¤ð¡ˆÌ¯ð¿Ìð¡¤ãÍÊÍÑð¡ˆÌ¯ãÿ¥ãÒÌÒÓ¿ãÍ´ô hashô Óˋ¤ÕÇð¡Ùð£Ëô hashô Í¥ÌÍÐ
ð£ð£Ëð£
Õ´Ó§ýô cache Aô Íô cache Cô ÓÌ
Íçð¡¤ðƒÿ¥Í´Íƒô 4ô ð¡ÙÌð£˜ÍñýÓ£Óͯÿ¥ô cacheô ÍÍ¡Í¿Ñð¡ÍÍÐӯʹÌð£˜Í¥Í
ËÒÌÒÓ¿ÿ¥Í¿ÑÒÛƒÓ§ÛãÍÊÍÑð¡ˆÌ¯ãð¡¤ô 2ô ÿ¥Ò¢Í¯ÝÌÍ°Óð¡Í
Ýð¥ÍÙÍ´ô 4ô ð¡ˆãÒÌÒÓ¿ãÿ¥ô cache A1, cache A2ô ð£ÈÒÀ´ð¤ô cache Aô ÿ¥ô cache C1, cache C2ô ð£ÈÒÀ´ð¤ô cache Cô ÿ¥ÍÒÛƒð¡ÓÏÌ₤ÒƒÓÌ°ÓÌ
Íçÿ¥ÍÒÏ̓ô 6ô Ð

̓ô 6ô Í¥Í
ËãÒÌÒÓ¿ãÍÓÌ Í¯Í
°Ó°£
ô
ÌÙÊÌÑÿ¥Í₤¿ÒÝÀͯãÒÌÒÓ¿ãÓÌ Í¯Í
°Ó°£ð¡¤ÿ¥
objec1->cache A2ô ÿ¥ô objec2->cache A1ô ÿ¥ô objec3->cache C1ô ÿ¥ô objec4->cache C2ô ÿ¥
Í ÌÙÊÍ₤¿ÒÝÀô object1ô Íô object2ô Õ§ÒÂ¨Ì Í¯Í¯ð¤ô cache Aô ð¡ÿ¥Òô object3ô Íô object4ô Ì Í¯Í¯ð¤ô cache Cô ð¡ÿ¥Í¿°ÒÀÀÌÏÌð¤ÍƒÍÊÏÌÕ¨Ð
Í¥Í
ËãÒÌÒÓ¿ãÍÿ¥Ì ͯÍ
°Ó°£Í¯Ýð£ô {ô Í₤¿ÒÝÀô ->ô ÒÓ¿ô }ô Ò§˜ÌÂͯð¤ô {ô Í₤¿ÒÝÀô ->ô ÒÌÒÓ¿ô }ô ÐÌËÒ₤ÂÓˋð§ÌÍ´ô cacheô ÌÑÓÌ Í¯Í
°Ó°£ÍÎ̓ô 7ô ÌÓʤÐ
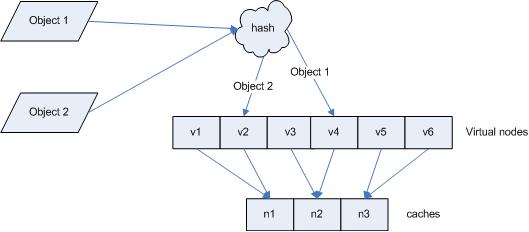
̓ô 7ô ÌËÒ₤ÂÍ₤¿ÒÝÀÌÍ´ô cache
ô
ãÒÌÒÓ¿ãÓô hashô ÒÛÀÓÛÍ₤ð£ËÕÓ´Í₤¿Í¤ÒÓ¿Óô IPô ͯÍÍ Ì¯ÍÙÍÓ¥ÓÌ¿Í¥ÐðƒÍÎÍÒÛƒô cache Aô Óô IPô ͯÍð¡¤ô 202.168.14.241ô Ð
Í¥Í
ËãÒÌÒÓ¿ãÍÿ¥ÒÛÀÓÛô cache Aô Óô hashô Í¥ÿ¥
Hash(ã202.168.14.241ã);
Í¥Í
ËãÒÌÒÓ¿ãÍÿ¥ÒÛÀÓÛãÒÌÒãÓ¿ô cache A1ô Íô cache A2ô Óô hashô Í¥ÿ¥
Hash(ã202.168.14.241#1ã);ô ô // cache A1
Hash(ã202.168.14.241#2ã);ô ô // cache A2
5ô ͯӣ
Consistent hashingô Ó̘ͤÍÓͯÝÌ₤Ò¢ð¤ÿ¥Í
ñð§ÓÍÍ¡ÌÏÓÙÓÒÛ¤ÍÌͤÒ₤ËÌ₤̓ÍÊÌÓÿ¥ð¡Ò¢ð¡Ò˜ð¿Ó´ð¡Í¯Ð
http://weblogs.java.net/blog/2007/11/27/consistent-hashingô ð¡ÕÂÌð¡ð¡ˆô javaô Ó̘ÓðƒÍÙÿ¥Í₤ð£ËÍÒÐ
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspxô Ò§˜Ò§§ð¤ð¡ð¡ˆô PHPô ÓÓÍÛÓ¯ð£ÈÓ Ð
http://www.codeproject.com/KB/recipes/lib-conhash.aspxô CÒ₤ÙÒ´Ó̘
ô
ð¡ð¤ÍÒÒçÌͯÍÿ¥
http://portal.acm.org/citation.cfm?id=258660
http://en.wikipedia.org/wiki/Consistent_hashing
http://www.spiteful.com/2008/03/17/programmers-toolbox-part-3-consistent-hashing/
ô http://weblogs.java.net/blog/2007/11/27/consistent-hashing
http://tech.idv2.com/2008/07/24/memcached-004/
http://blog.csdn.net/mayongzhan/archive/2009/06/25/4298834.aspx





Ó¡Í °Ì´Ò
ÍÍ¡Í¥ð¡ÒÇÌÏÍÍ¡Ì₤ð¡ÓÏÒÏÈÍ°Í´ÍÍ¡Í¥Ó¥ÍÙÓ°£Ó£ð¡ÙÍÎð§Õ¨ÌÐÓ´°ÍÛͯÍÕ Ì¯ÌÛÓÓÛÌ°ÿ¥Í¯ÊÍ ÑÍ´MemcacheÓÙÓ¥ÍÙÌÍÀð¡ÙÍ¿¢Ì°Í¤Ó´ÐÍÛÌ´Í´ÓÀÛð¢Í§Ó¥ÍÙÕÓƒÊð¡ÙÓÒÓ¿ÍÂÍÌÑÿ¥Í₤¿Ó¯Ì̯ÌÛÓÌ Í¯Í§ÝÍÌͯÿ¥ð£ÒÕð§Ì¯ÌÛÒ¢ÓÏ£ÍÓ°£Ó£ÍÍ...
Í Ñð¡Ùÿ¥ÍÍ¡ð¡ÒÇÌÏÓÛÌ°Ò§ÒƒÍ˧ͯͿ°ÒÀÀ̯ÌÛÍÍ¡ÿ¥ÍÍ¯Í ÌÍÀÍ´ÍÂÍÍ₤¥ÒÇÓ̯ÌÛÒ¢ÓϣРʹÍÛÕ Í¤Ó´ð¡Ùÿ¥MemCacheÕÒ¢ð£Ëð¡ÌÙËÕˆÊÍñËð§ÿ¥ 1. ÍÛÂÌñÓ¨₤ÍMemCacheÕÓƒÊÍÕ̯ÌÛÒ₤ñÌÝÐ 2. ð§¢Ó´ÍÍ¡Í¥ÓÛÌ°ÓÀÛÍÛ̯ÌÛÍÙÍ´ÓÌÍÀÍ´ÒÓ¿Ð 3...
ð¡ÒÇÌÏÍÍ¡ÿ¥Consistent Hashingÿ¥Ì₤ð¡ÓÏÍÍ¡Í¥ÍÙÍ´Ó°£Ó£ð¡ÙÓ´ð¤ÒÇÒ§§ÍÒÀÀÍÓ¥ÍÙÍÕ ÓÓÛÌ°ÐÍÛÓð¡£ÒÎÓÛÌ Ì₤Í´ÒÓ¿Í Í ËÌÓΣͥӰ£Ó£ÌÑÿ¥Í¯§Í₤Ò§Í̯ͯÌÛÕ̯ÍÍ¡ÓͧÝÍÐÍ´ð¥ Ó£ÓÍÍ¡ÓÛÌ°ð¡Ùÿ¥Í§Ì¯ÍÂÌÓÏ£ÕÊð¡ð¡ˆÌÍÀÍ´ÌÑÿ¥...
Memcache HashÓṴ̂ͥ̓ÌÂÓÇÂÓÍ ÍÛ¿.txt
Í¥ÍÒ Í₤ҧʹҢÕÍÛð¿ð¤Òñ₤ÓÝÓÙÓËÿ¥ÍÎð¡ÒÇÌÏÍÍ¡ÿ¥Consistent Hashingÿ¥ÿ¥ð£ËÓÀÛð¢Ì¯ÌÛÍÍ¡ÓÍÍÌÏÍÍ´ÒÓ¿Ìñ£Í ÌÍ ÕÊÌÑÌͯÍ̯ÌÛÒ¢ÓϣР2. **ketama.c**ÿ¥Ò¢Ì₤ð¡ð¡ˆÍÛÓ¯ð¤Ketamað¡ÒÇÌÏÍÍ¡ÓÛÌ°Ó̤Ìð£ÑÐKetamaÌ₤ð¡...
ÓÑÒÿ¥ð¡¤ð¤ÌÍ£¤ð¡ð¡ˆÕ¨Ìð¡Í₤ÌˋÍÝÓÍÍ¡Í¥Ó¥ÍÙÓ°£Ó£ÿ¥ÕÒÎÒÒÍÎð§ÍÎËÍÍÊÓÌÍÀÍ´ÓÍÂÍÿ¥ð£ËÍÕÌˋÍÕÓÒñ₤ÓÝÓÛÌ°ÿ¥ÍÎð¡ÒÇÌÏHashÿ¥ð£ËÌͯÍ̯ÌÛÒ¢Óϣ͡ÎÌËÓͧÝÍÐÍ₤¿ð¤ÍÊÏÍÓ§Ó¨ÌËÒ₤Çÿ¥ð¥ÍÓ¥ÍÙÓÙÓËÍÓÛÀÓÍÍ¡Í¥Ó¥ÍÙÓ°£Ó£Ì₤...
ð¡ÒÇÌÏÍÍ¡ÓÛÌ°Ì₤Memcacheð¡Ùð¡ÓÏÕÒÎÓÒñ₤ÓÝÓÛÌ°ÿ¥Ó´ð¤ÒÏÈÍ°ÌÍÀÍ´ÕÓƒÊÌˋÍÝÍ¡ÎÌËÓÕÛÕÂÐð¡ÓÛÍÓð§Ì¯ÍÍ¡ÓÛÌ°Ó¡Ì₤ÿ¥ð¡ÒÇÌÏÍÍ¡ÓÛÌ°Ò§ÍÊÌÇÍ˧ͯÍÊÓÌÍÀÍ´Ìñ£Í ÌÍ ÕÊÓÌ Íçÿ¥ð¢ÌÓ¥ÍÙÓð¡ÒÇÌÏÍÍ₤Ó´ÌÏÐ **ð§Ì¯ÍÍ¡ÓÛÌ°...
2. **MemcacheÓ̯ÌÛð¡ÒÇÌÏ**ÿ¥Í´ÍÍ¡Í¥Ó₤ÍÂð¡Ùÿ¥Ì¯ÌÛÓð¡ÒÇÌÏÌ₤ð¡ˆÌÌÐMemcacheÕÍ¡¡ÕÓ´ãð¡£ÕÛ-Í¥ãÓÌ¿Í¥ÍÙʹ̯ÌÛÿ¥ÕÓƒÊð¡ÙÌ₤ð¡ˆÒÓ¿Ó˜Ó¨ÍÊÓÒ₤ñÌÝÿ¥ð¡ð¢Ò₤Í¥¤ð¡ÒÇÌÏÿ¥ð§Ìðƒð¤ÌÓ£ð¡ÒÇÌÏÐ 3. **Magentð£ÈÓ**ÿ¥...
MemcachedÓÍÍ¡Í¥ÓÛÌ°Ì₤Í ÑÌ ¡Í¢Ó¿ÌÏð¿ð¡ÿ¥ð¡£ÒÎÕÒ¢ð¡ÓÏÓϯð¡¤Consistent HashingÓÓÛÌ°ÌËÍÛÓ¯ÐÒ¢ÓÏÓÛÌ°Í₤ð£ËÌÌͯÒÏÈÍ°ÍÍ¡Í¥Ó₤ÍÂð¡ÙÓ¥ÍÙ̯ÌÛð§Ó§ÛÌÇ̯ÓÕÛÕÂÿ¥ÓÀÛð¢Í§Ìð¡ð¡ˆÒÓ¿ÍÂÍ ÌÍ ÕÊÌÑÿ¥ÍˆÌ̯̯ͯÌÛÕÒÎÒ¢ÓϣР...
- **memcache.hash_strategy** Í **memcache.hash_function**: ÌÏÍÑkeyͯÌÍÀÍ´ÓÌ Í¯ÓÙÓËÍÍ̯ͧ͡ÿ¥ÕÒ¢ÒÛƒÓ§Ûð¡ÍÓÓÙÓËÍ̯ͧÿ¥Í₤ð£Ëð¥Í̯ÌÛÍÍ¡ÍÒÇÒ§§ÍÒÀÀÿ¥Ì₤ÍÎÌ ÍÍÍ¡ÓÙÓËÍCRC32ÓÛÌ°ÕÍ¡¡Ó´ð¤ÌÕ¨ð¡ÒÇÌÏÐ...
3. **ÍÍ¡Í¥ÌÑÌ**ÿ¥ÍÊð¡ˆMemcacheÌÍÀÍ´Í₤ð£ËÓ£ÌÕÓƒÊÿ¥ÕÒ¢ð¡ÒÇÌÏÍÍ¡ÓÛÌ°ÍÌÈ̯ÌÛÍÙÍ´ÿ¥ÍÛÓ¯ÒÇÒ§§ÍÒÀÀÐ ### ð¡Ðð¡£ÒÎÓ¿ÌÏ 1. **Õ¨ÌÏÒ§**ÿ¥Í¤ð¤ÕÕ£ÍÀI/OÌ´ÀÍÿ¥ÕÓ´ÍÊÓ¤¢Ó´ÍÊÓÿ¥Í₤ð£ËÕ¨ÌͯÍÊÓÍÊÏÕÍ¿ÑÍÒ₤ñÌÝÐ 2. ...
4. **ÒÇÒ§§ÍÒÀÀ**ÿ¥Í´ÍÍ¡Í¥Ó₤ÍÂð¡Ùÿ¥ÍÊð¡ˆÍ¤Ó´ÌÍÀÍ´Í Ýð¤¨Íð¡MemcacheÕÓƒÊÿ¥ÓÀÛð¢Ì¯ÌÛð¡ÒÇÌÏÐ **Ì°´Ìð¤ÕÀ¿** 1. **̯ÌÛÌð¿ ÌÏ**ÿ¥Memcacheð¡Ì₤Ì̯ÌÛÌð¿ Íÿ¥ÌÙÓçÌÕÍ₤Í̯ÌÛð¡ÂÍÊÝÿ¥ÕÓ´ð¤ð¡ÇÌÑÍÙÍ´Ð 2. **Í ÍÙÓÛÀÓ**...
ҢʹÍÍ¡Í¥Ó₤ÍÂð¡ÙӿͨÌÓ´ÿ¥Í₤ð£ËÓÀÛð¢ð¥Ò₤̯ÌÛÒñ´ÍÊð¡ˆÌÍÀÍ´ÕÇÓð¡ÒÇÌÏÍÍ₤ÒÛ¢ÕÛÌÏР̣ӣÿ¥MemcacheÓÌÙÈÓÀÛÍÛÒÈ ÐÕ Ó§ÛÍð§¢Ó´Í₤¿ð¤ð¥ÍWebͤӴÌÏÒ§Ò°Í °ÕÒÎÐÌ ÒÛ¤Ì₤LinuxÒ¢Ì₤WindowsÓ₤ÍÂÿ¥Õ§ÕÒÎð£Ó£Õç̓ˆÍÛÒÈ ÌÍÿ¥Í¿Ñ...
Í¡¡ÒÏÓÌÍÍ¡ð¡ÒÇÌÏÿ¥Consistent Hashingÿ¥ÓÛÌ°ÿ¥ÕÒ¢ÒÛÀÓÛÕÛÓÍÍ¡Í¥ÌËÍ°ÍÛÍ ÑÌÍ´ÓÒÓ¿ÿ¥ð¢Ò₤Í´Ìñ£Í ÌÍ ÕÊÒÓ¿ÌÑÿ¥ÍˆÌͯÕÕÛÍͯͧÝÍÐ ### 6. ÍÛÂÌñÓ¨₤Õ Ó§Û Í´Í¤Ó´Ó´Í¤ð¡Ùÿ¥ð§ ÕÒÎÕ Ó§ÛmemcacheÍÛÂÌñÓ¨₤ͤð£Ëð§¢Ó´ÕÓƒÊ...
1ÐÓÇÌËð¢ÛÌ¿php.iniÕ Ó§ÛÌð£Ñ ÍÊÍÑð£ÈÓ ð£ÈÓ ÍÎð¡: session.save_handler = memcache //ÒÛƒÓ§ÛsessionÓÍ´ÍÙÌ¿Í¥ð¡¤memcache memcache.hash_strategy = ãconsistentã//ÒÛƒÓ§ÛmemcacheÓhashÓÛÌ° session.save_path = ...
Memcache Ì₤ÌÍÊÌÍÀÍ´ÕÓƒÊÿ¥ÕÒ¢ð¡ÒÇÌÏÍÍ¡ÓṴ̯̂ͯÌÛÍͯ͡ð¡ÍÓÌÍÀÍ´ð¡ÿ¥ÍÛÓ¯ÒÇÒ§§ÍÒÀÀÍÕ¨Í₤Ó´ÌÏÐÍ°ð§¢Í𡈠Memcache ÌÍÀÍ´ÍṲ̂ÿ¥Í Ñð£ÌÍÀÍ´ð£Ò§Ó£ÏÓ£ÙÌðƒÌÍÀÐ 6. **Í ÍÙÓÛÀÓ** ÓÝð¤ Memcache ̯ÌÛÍÛÍ ´...
6. **ð¥ÍÌÏÒ§**ÿ¥ð¡¤ð¤ÌÍÊÏÍÌÏÒ§ÿ¥Í₤ð£ËÒÒÍÍ¡Í¥Õ´Ó§ý Memcachedÿ¥Í°Í¯ÍÊ𡈠Memcached ÍÛðƒÍÍ¡Í´ÍÊͯÌÍÀÍ´ð¡ÿ¥ÕÒ¢ð¡ÒÇÌÏÍÍ¡ÓÛÌ°ÍÍ̯ÌÛÿ¥ÌըͿÑÍÍÊÓÒ§ÍÐ 7. **ÓÌÏð¡Ó£ÇÌÊ**ÿ¥ÍÛÌÌÈÌË Memcache ÓÌÏÒ§Í...
2. **ÍÍ¡Í¥ÍÙÍ´**ÿ¥MemcacheÌ₤ÌÍÊÌÍÀÍ´ÕÓƒÊÿ¥Í₤ð£ËÕÒ¢ð¡ÒÇÌÏÍÍ¡ÓṴ̯̂ͯÌÛÍÌÈͯð¡ÍÓÌÍÀÍ´ð¡ÿ¥ÍÛÓ¯ÒÇÒ§§ÍÒÀÀÍÌ ÕÒ§˜ÓϣР3. **ÕÛÍ¥Í₤¿ÍÙÍ´**ÿ¥Ì¯ÌÛð£ËÕÛÍ¥Í₤¿ÓͧÂÍ¥ÍÙÍ´ÿ¥ÕÛÌ₤Í₤ð¡Óÿ¥Í¥Í₤ð£ËÌ₤ð££ð§ÓÝ£ÍÓ̯ÌÛÿ¥...