- жөҸи§Ҳ: 436496 ж¬Ў
- жҖ§еҲ«:

- жқҘиҮӘ: ж·ұеңі
-

ж–Үз« еҲҶзұ»
- е…ЁйғЁеҚҡе®ў (280)
- Javaж ёеҝғжҠҖжңҜ (40)
- JVM/еҶ…еӯҳжЁЎеһӢ/и°ғдјҳ/жҺ’й”ҷ (23)
- Javaеә”з”ЁжҠҖжңҜ (44)
- зі»з»ҹжһ¶жһ„ (3)
- и®ҫи®ЎжЁЎејҸ (2)
- йҖҡз”ЁжҠҖжңҜ (10)
- жңҚеҠЎеҷЁй…ҚзҪ® (3)
- 硬件 (8)
- linuxжҠҖжңҜ (21)
- javascript (17)
- webжҠҖжңҜ (9)
- зҪ‘з»ңйҖҡи®Ҝ (10)
- ж•°жҚ®еә“ (35)
- жҗңзҙўеј•ж“Һ (4)
- иӢұиҜӯ (5)
- з”ҹжҙ»йҡҸ笔 (11)
- з»ҸжөҺ (7)
- жҠ•иө„зҗҶиҙў (11)
- зӨҫдјҡеӨ§еӯҰ (20)
- еӣҫеғҸеӨ„зҗҶжҠҖжңҜ (1)
- жҖ§иғҪдёҺдјҳеҢ– (5)
зӨҫеҢәзүҲеқ—
- жҲ‘зҡ„иө„и®Ҝ ( 0)
- жҲ‘зҡ„и®әеқӣ ( 1)
- жҲ‘зҡ„й—®зӯ” ( 0)
еӯҳжЎЈеҲҶзұ»
- 2012-08 ( 1)
- 2012-06 ( 2)
- 2012-05 ( 2)
- жӣҙеӨҡеӯҳжЎЈ...
жңҖж–°иҜ„и®ә
-
Glogoпјҡ
жҘјдё»жӮЁеҘҪпјҢжҲ‘еңЁиҜ•йӘҢжӮЁзҡ„д»Јз Ғзҡ„ж—¶еҖҷеҸ‘зҺ°ж–°ејҖзҡ„дёүдёӘеӯҗзәҝзЁӢ并没жңүдёҖзӣҙ ...
java й«ҳ并еҸ‘ ReentrantLock -- еҸҜйҮҚе…Ҙзҡ„й”Ғ -
univasityпјҡ
жңҖиҝ‘еҸ‘и§үд№ҹиў«йҷҗйҖҹдәҶпјҢжҠ•иҜүдёҖдёӢе°ұеҘҪдёҖдјҡ~~ зңӢжқҘжҳҺеӨ©еҸҲиҰҒе’Ңз”өдҝЎM ...
ADSLдёҠзҪ‘йҖҹеәҰж…ў йғҪжҳҜеёҗеҸ·йҷҗйҖҹжғ№зҡ„зҘё -
liuyuanhui0301пјҡ
В
java й«ҳ并еҸ‘ ReentrantLock -- еҸҜйҮҚе…Ҙзҡ„й”Ғ -
dang_javaпјҡ
е‘ө.еҫҲеҘҪзҡ„иҜҙжҳҺж–ҮжЎЈ.
JXTAжҠҖжңҜдёҺеә”з”ЁеҸ‘еұ• -
helloqidiпјҡ
и°ўи°ўпјҢеӯҰд№ дәҶ
SQLдёӯexistsе’Ңinзҡ„еҢәеҲ«
зӣ®еүҚеңЁJavaдёӯеӯҳеңЁдёӨз§Қй”ҒжңәеҲ¶пјҡsynchronizedе’ҢLockпјҢLockжҺҘеҸЈеҸҠе…¶е®һзҺ°зұ»жҳҜJDK5еўһеҠ зҡ„еҶ…е®№пјҢе…¶дҪңиҖ…жҳҜеӨ§еҗҚйјҺйјҺзҡ„并еҸ‘专家Doug LeaгҖӮжң¬ж–Ү并дёҚжҜ”иҫғsynchronizedдёҺLockеӯ°дјҳеӯ°еҠЈпјҢеҸӘжҳҜд»Ӣз»ҚдәҢиҖ…зҡ„е®һзҺ°еҺҹзҗҶгҖӮ
В В ж•°жҚ®еҗҢжӯҘйңҖиҰҒдҫқиө–й”ҒпјҢйӮЈй”Ғзҡ„еҗҢжӯҘеҸҲдҫқиө–и°Ғпјҹsynchronizedз»ҷеҮәзҡ„зӯ”жЎҲжҳҜеңЁиҪҜ件еұӮйқўдҫқиө–JVMпјҢиҖҢLockз»ҷеҮәзҡ„ж–№жЎҲжҳҜеңЁзЎ¬д»¶еұӮйқўдҫқиө–зү№ж®Ҡзҡ„CPUжҢҮд»ӨпјҢеӨ§е®¶еҸҜиғҪдјҡиҝӣдёҖжӯҘиҝҪй—®пјҡJVMеә•еұӮеҸҲжҳҜеҰӮдҪ•е®һзҺ°synchronizedзҡ„пјҹ
В В жң¬ж–ҮжүҖжҢҮиҜҙзҡ„JVMжҳҜжҢҮHotspotзҡ„6u23зүҲжң¬пјҢдёӢйқўйҰ–е…Ҳд»Ӣз»Қsynchronizedзҡ„е®һзҺ°пјҡ
В В synrhronizedе…ій”®еӯ—з®ҖжҙҒгҖҒжё…жҷ°гҖҒиҜӯд№үжҳҺзЎ®пјҢеӣ жӯӨеҚідҪҝжңүдәҶLockжҺҘеҸЈпјҢдҪҝз”Ёзҡ„иҝҳжҳҜйқһеёёе№ҝжіӣгҖӮе…¶еә”з”ЁеұӮзҡ„иҜӯд№үжҳҜеҸҜд»ҘжҠҠд»»дҪ•дёҖдёӘйқһnullеҜ№иұЎ дҪңдёә"й”Ғ"пјҢеҪ“synchronizedдҪңз”ЁеңЁж–№жі•дёҠж—¶пјҢй”ҒдҪҸзҡ„дҫҝжҳҜеҜ№иұЎе®һдҫӢпјҲthisпјүпјӣеҪ“дҪңз”ЁеңЁйқҷжҖҒж–№жі•ж—¶й”ҒдҪҸзҡ„дҫҝжҳҜеҜ№иұЎеҜ№еә”зҡ„Classе®һдҫӢпјҢеӣ дёә Classж•°жҚ®еӯҳеңЁдәҺж°ёд№…еёҰпјҢеӣ жӯӨйқҷжҖҒж–№жі•й”ҒзӣёеҪ“дәҺиҜҘзұ»зҡ„дёҖдёӘе…ЁеұҖй”ҒпјӣеҪ“synchronizedдҪңз”ЁдәҺжҹҗдёҖдёӘеҜ№иұЎе®һдҫӢж—¶пјҢй”ҒдҪҸзҡ„дҫҝжҳҜеҜ№еә”зҡ„д»Јз Ғеқ—гҖӮеңЁ HotSpot JVMе®һзҺ°дёӯпјҢй”ҒжңүдёӘдё“й—Ёзҡ„еҗҚеӯ—пјҡеҜ№иұЎзӣ‘и§ҶеҷЁгҖӮ
В 1. зәҝзЁӢзҠ¶жҖҒеҸҠзҠ¶жҖҒиҪ¬жҚў
В В еҪ“еӨҡдёӘзәҝзЁӢеҗҢж—¶иҜ·жұӮжҹҗдёӘеҜ№иұЎзӣ‘и§ҶеҷЁж—¶пјҢеҜ№иұЎзӣ‘и§ҶеҷЁдјҡи®ҫзҪ®еҮ з§ҚзҠ¶жҖҒз”ЁжқҘеҢәеҲҶиҜ·жұӮзҡ„зәҝзЁӢпјҡ
В
- Contention ListпјҡжүҖжңүиҜ·жұӮй”Ғзҡ„зәҝзЁӢе°Ҷиў«йҰ–е…Ҳж”ҫзҪ®еҲ°иҜҘз«һдәүйҳҹеҲ—
- Entry ListпјҡContention ListдёӯйӮЈдәӣжңүиө„ж јжҲҗдёәеҖҷйҖүдәәзҡ„зәҝзЁӢ被移еҲ°Entry List
- Wait SetпјҡйӮЈдәӣи°ғз”Ёwaitж–№жі•иў«йҳ»еЎһзҡ„зәҝзЁӢиў«ж”ҫзҪ®еҲ°Wait Set
- OnDeckпјҡд»»дҪ•ж—¶еҲ»жңҖеӨҡеҸӘиғҪжңүдёҖдёӘзәҝзЁӢжӯЈеңЁз«һдәүй”ҒпјҢиҜҘзәҝзЁӢз§°дёәOnDeck
- OwnerпјҡиҺ·еҫ—й”Ғзҡ„зәҝзЁӢз§°дёәOwner
- !OwnerпјҡйҮҠж”ҫй”Ғзҡ„зәҝзЁӢ
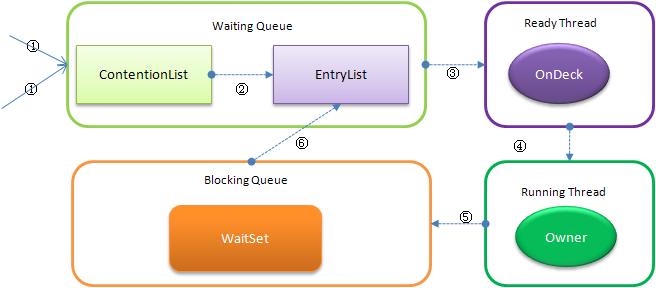
1.1 ContentionListиҷҡжӢҹйҳҹеҲ—
ContentionList并дёҚжҳҜдёҖдёӘзңҹжӯЈзҡ„QueueпјҢиҖҢеҸӘжҳҜдёҖдёӘиҷҡжӢҹйҳҹеҲ—пјҢеҺҹеӣ еңЁдәҺContentionListжҳҜз”ұNodeеҸҠе…¶nextжҢҮ й’ҲйҖ»иҫ‘жһ„жҲҗпјҢ并дёҚеӯҳеңЁдёҖдёӘQueueзҡ„ж•°жҚ®з»“жһ„гҖӮContentionListжҳҜдёҖдёӘеҗҺиҝӣе…ҲеҮәпјҲLIFOпјүзҡ„йҳҹеҲ—пјҢжҜҸж¬Ўж–°еҠ е…ҘNodeж—¶йғҪдјҡеңЁйҳҹеӨҙиҝӣиЎҢпјҢ йҖҡиҝҮCASж”№еҸҳ第дёҖдёӘиҠӮзӮ№зҡ„зҡ„жҢҮй’Ҳдёәж–°еўһиҠӮзӮ№пјҢеҗҢж—¶и®ҫзҪ®ж–°еўһиҠӮзӮ№зҡ„nextжҢҮеҗ‘еҗҺз»ӯиҠӮзӮ№пјҢиҖҢеҸ–еҫ—ж“ҚдҪңеҲҷеҸ‘з”ҹеңЁйҳҹе°ҫгҖӮжҳҫ然пјҢиҜҘз»“жһ„е…¶е®һжҳҜдёӘLock- Freeзҡ„йҳҹеҲ—гҖӮ
еӣ дёәеҸӘжңүOwnerзәҝзЁӢжүҚиғҪд»Һйҳҹе°ҫеҸ–е…ғзҙ пјҢд№ҹеҚізәҝзЁӢеҮәеҲ—ж“ҚдҪңж— дәүз”ЁпјҢеҪ“然д№ҹе°ұйҒҝе…ҚдәҶCASзҡ„ABAй—®йўҳгҖӮ
1.2 EntryList
2. иҮӘж—Ӣй”Ғ
- еҰӮжһңе№іеқҮиҙҹиҪҪе°ҸдәҺCPUsеҲҷдёҖзӣҙиҮӘж—Ӣ
- еҰӮжһңжңүи¶…иҝҮ(CPUs/2)дёӘзәҝзЁӢжӯЈеңЁиҮӘж—ӢпјҢеҲҷеҗҺжқҘзәҝзЁӢзӣҙжҺҘйҳ»еЎһ
- еҰӮжһңжӯЈеңЁиҮӘж—Ӣзҡ„зәҝзЁӢеҸ‘зҺ°OwnerеҸ‘з”ҹдәҶеҸҳеҢ–еҲҷ延иҝҹиҮӘж—Ӣж—¶й—ҙпјҲиҮӘж—Ӣи®Ўж•°пјүжҲ–иҝӣе…Ҙйҳ»еЎһ
- еҰӮжһңCPUеӨ„дәҺиҠӮз”өжЁЎејҸеҲҷеҒңжӯўиҮӘж—Ӣ
- иҮӘж—Ӣж—¶й—ҙзҡ„жңҖеқҸжғ…еҶөжҳҜCPUзҡ„еӯҳеӮЁе»¶иҝҹпјҲCPU AеӯҳеӮЁдәҶдёҖдёӘж•°жҚ®пјҢеҲ°CPU Bеҫ—зҹҘиҝҷдёӘж•°жҚ®зӣҙжҺҘзҡ„ж—¶й—ҙе·®пјү
- иҮӘж—Ӣж—¶дјҡйҖӮеҪ“ж”ҫејғзәҝзЁӢдјҳе…Ҳзә§д№Ӣй—ҙзҡ„е·®ејӮ
3. еҒҸеҗ‘й”Ғ
3.1 CASеҸҠSMPжһ¶жһ„
3.2 еҒҸеҗ‘и§ЈйҷӨ
4. жҖ»з»“
йҖҡиҝҮдёҠйқўзҡ„д»Ӣз»ҚеҸҜд»ҘзңӢеҮәпјҢsynchronizedзҡ„еә•еұӮе®һзҺ°дё»иҰҒдҫқйқ Lock-Freeзҡ„йҳҹеҲ—пјҢеҹәжң¬жҖқи·ҜжҳҜиҮӘж—ӢеҗҺйҳ»еЎһпјҢз«һдәүеҲҮжҚўеҗҺ继з»ӯз«һдәүй”ҒпјҢзЁҚеҫ®зүәзүІдәҶе…¬е№іжҖ§пјҢдҪҶиҺ·еҫ—дәҶй«ҳеҗһеҗҗйҮҸгҖӮдёӢйқўдјҡ继з»ӯд»Ӣз»ҚJVMй”Ғдёӯзҡ„Lock
В
еүҚж–ҮпјҲж·ұе…ҘJVMй”ҒжңәеҲ¶-synchronized пјүеҲҶжһҗдәҶJVMдёӯзҡ„synchronizedе®һзҺ°пјҢжң¬ж–Ү继з»ӯеҲҶжһҗJVMдёӯзҡ„еҸҰдёҖз§Қй”ҒLockзҡ„е®һзҺ°гҖӮдёҺsynchronizedдёҚеҗҢзҡ„жҳҜпјҢLockе®Ңе…Ёз”ЁJavaеҶҷжҲҗпјҢеңЁjavaиҝҷдёӘеұӮйқўжҳҜж— е…іJVMе®һзҺ°зҡ„гҖӮ
еңЁ java.util.concurrent.locksеҢ…дёӯжңүеҫҲеӨҡLockзҡ„е®һзҺ°зұ»пјҢеёёз”Ёзҡ„жңүReentrantLockгҖҒ ReadWriteLockпјҲе®һзҺ°зұ»ReentrantReadWriteLockпјүпјҢе…¶е®һзҺ°йғҪдҫқиө– java.util.concurrent.AbstractQueuedSynchronizerзұ»пјҢе®һзҺ°жҖқи·ҜйғҪеӨ§еҗҢе°ҸејӮпјҢеӣ жӯӨжҲ‘们д»Ҙ ReentrantLockдҪңдёәи®Іи§ЈеҲҮе…ҘзӮ№гҖӮ
1. ReentrantLockзҡ„и°ғз”ЁиҝҮзЁӢ
з»ҸиҝҮи§ӮеҜҹReentrantLockжҠҠжүҖжңүLockжҺҘеҸЈзҡ„ж“ҚдҪңйғҪ委жҙҫеҲ°дёҖдёӘSyncзұ»дёҠпјҢиҜҘзұ»з»§жүҝдәҶAbstractQueuedSynchronizerпјҡ
- static В abstract В class В SyncВ extends В AbstractQueuedSynchronizerВ В
SyncеҸҲжңүдёӨдёӘеӯҗзұ»пјҡ
- final В static В class В NonfairSyncВ extends В SyncВ В
- final В static В class В FairSyncВ extends В SyncВ В
жҳҫ然жҳҜдёәдәҶж”ҜжҢҒе…¬е№ій”Ғе’Ңйқһе…¬е№ій”ҒиҖҢе®ҡд№үпјҢй»ҳи®Өжғ…еҶөдёӢдёәйқһе…¬е№ій”ҒгҖӮ
е…ҲзҗҶдёҖдёӢReentrant.lock()ж–№жі•зҡ„и°ғз”ЁиҝҮзЁӢпјҲй»ҳи®Өйқһе…¬е№ій”Ғпјүпјҡ

иҝҷ дәӣи®ЁеҺҢзҡ„TemplateжЁЎејҸеҜјиҮҙеҫҲйҡҫзӣҙи§Ӯзҡ„зңӢеҲ°ж•ҙдёӘи°ғз”ЁиҝҮзЁӢпјҢе…¶е®һйҖҡиҝҮдёҠйқўи°ғз”ЁиҝҮзЁӢеҸҠAbstractQueuedSynchronizerзҡ„жіЁйҮҠеҸҜд»Ҙ еҸ‘зҺ°пјҢAbstractQueuedSynchronizerдёӯжҠҪиұЎдәҶз»қеӨ§еӨҡж•°Lockзҡ„еҠҹиғҪпјҢиҖҢеҸӘжҠҠtryAcquire方法延иҝҹеҲ°еӯҗзұ»дёӯе®һзҺ°гҖӮ tryAcquireж–№жі•зҡ„иҜӯд№үеңЁдәҺз”Ёе…·дҪ“еӯҗзұ»еҲӨж–ӯиҜ·жұӮзәҝзЁӢжҳҜеҗҰеҸҜд»ҘиҺ·еҫ—й”ҒпјҢж— и®әжҲҗеҠҹдёҺеҗҰAbstractQueuedSynchronizerйғҪе°ҶеӨ„зҗҶ еҗҺйқўзҡ„жөҒзЁӢгҖӮ
2.В й”Ғе®һзҺ°пјҲеҠ й”Ғпјү
з®ҖеҚ•иҜҙжқҘпјҢAbstractQueuedSynchronizerдјҡжҠҠжүҖжңүзҡ„иҜ·жұӮзәҝзЁӢ жһ„жҲҗдёҖдёӘCLHйҳҹеҲ—пјҢеҪ“дёҖдёӘзәҝзЁӢжү§иЎҢе®ҢжҜ•пјҲlock.unlock()пјүж—¶дјҡжҝҖжҙ»иҮӘе·ұзҡ„еҗҺ继иҠӮзӮ№пјҢдҪҶжӯЈеңЁжү§иЎҢзҡ„зәҝзЁӢ并дёҚеңЁйҳҹеҲ—дёӯпјҢиҖҢйӮЈдәӣзӯүеҫ…жү§иЎҢзҡ„зәҝзЁӢе…Ё йғЁеӨ„дәҺйҳ»еЎһзҠ¶жҖҒпјҢз»ҸиҝҮи°ғжҹҘзәҝзЁӢзҡ„жҳҫејҸйҳ»еЎһжҳҜйҖҡиҝҮи°ғз”ЁLockSupport.park()е®ҢжҲҗпјҢиҖҢLockSupport.park()еҲҷи°ғз”Ё sun.misc.Unsafe.park()жң¬ең°ж–№жі•пјҢеҶҚиҝӣдёҖжӯҘпјҢHotSpotеңЁLinuxдёӯдёӯйҖҡиҝҮи°ғз”Ёpthread_mutex_lockеҮҪж•°жҠҠ зәҝзЁӢдәӨз»ҷзі»з»ҹеҶ…ж ёиҝӣиЎҢйҳ»еЎһгҖӮ
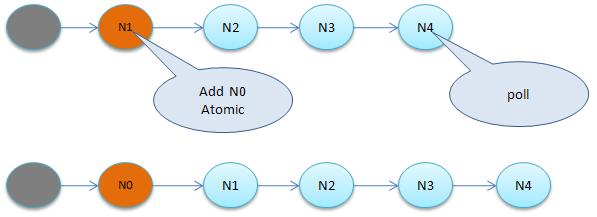
иҜҘйҳҹеҲ—еҰӮеӣҫпјҡ

дёҺsynchronizedзӣёеҗҢзҡ„жҳҜпјҢиҝҷд№ҹжҳҜдёҖдёӘиҷҡжӢҹйҳҹеҲ—пјҢдёҚеӯҳеңЁйҳҹеҲ—е®һдҫӢпјҢд»…еӯҳеңЁиҠӮзӮ№д№Ӣй—ҙзҡ„еүҚеҗҺе…ізі»гҖӮд»Өдәәз–‘жғ‘зҡ„жҳҜдёәд»Җд№ҲйҮҮз”ЁCLHйҳҹеҲ—е‘ўпјҹеҺҹз”ҹзҡ„CLHйҳҹеҲ—жҳҜз”ЁдәҺиҮӘж—Ӣй”ҒпјҢдҪҶDoug LeaжҠҠе…¶ж”№йҖ дёәйҳ»еЎһй”ҒгҖӮ
еҪ“жңүзәҝзЁӢз«һдәүй”Ғж—¶пјҢиҜҘзәҝзЁӢдјҡйҰ–е…Ҳе°қиҜ•иҺ·еҫ—й”ҒпјҢиҝҷеҜ№дәҺйӮЈдәӣе·Із»ҸеңЁйҳҹеҲ—дёӯжҺ’йҳҹзҡ„зәҝзЁӢжқҘиҜҙжҳҫеҫ—дёҚе…¬е№іпјҢиҝҷд№ҹжҳҜйқһе…¬е№ій”Ғзҡ„з”ұжқҘпјҢдёҺsynchronizedе®һзҺ°зұ»дјјпјҢиҝҷж ·дјҡжһҒеӨ§жҸҗй«ҳеҗһеҗҗйҮҸгҖӮ
еҰӮ жһңе·Із»ҸеӯҳеңЁRunningзәҝзЁӢпјҢеҲҷж–°зҡ„з«һдәүзәҝзЁӢдјҡиў«иҝҪеҠ еҲ°йҳҹе°ҫпјҢе…·дҪ“жҳҜйҮҮз”ЁеҹәдәҺCASзҡ„Lock-Freeз®—жі•пјҢеӣ дёәзәҝзЁӢ并еҸ‘еҜ№Tailи°ғз”ЁCASеҸҜиғҪдјҡ еҜјиҮҙе…¶д»–зәҝзЁӢCASеӨұиҙҘпјҢи§ЈеҶіеҠһжі•жҳҜеҫӘзҺҜCASзӣҙиҮіжҲҗеҠҹгҖӮAbstractQueuedSynchronizerзҡ„е®һзҺ°йқһеёёзІҫе·§пјҢд»ӨдәәеҸ№дёәи§ӮжӯўпјҢдёҚе…Ҙз»ҶиҠӮ йҡҫд»Ҙе®Ңе…ЁйўҶдјҡе…¶зІҫй«“пјҢдёӢйқўиҜҰз»ҶиҜҙжҳҺе®һзҺ°иҝҮзЁӢпјҡ
2.1 Sync.nonfairTryAcquire
nonfairTryAcquireж–№жі•е°ҶжҳҜlockж–№жі•й—ҙжҺҘи°ғз”Ёзҡ„第дёҖдёӘж–№жі•пјҢжҜҸж¬ЎиҜ·жұӮй”Ғж—¶йғҪдјҡйҰ–е…Ҳи°ғз”ЁиҜҘж–№жі•гҖӮ
- final В boolean В nonfairTryAcquire( int В acquires)В {В В
- В В В В final В ThreadВ currentВ =В Thread.currentThread();В В
- В В В В int В cВ =В getState();В В
- В В В В if В (cВ ==В 0 )В {В В
- В В В В В В В В if В (compareAndSetState( 0 ,В acquires))В {В В
- В В В В В В В В В В В В setExclusiveOwnerThread(current);В В
- В В В В В В В В В В В В return В true ;В В
- В В В В В В В В }В В
- В В В В }В В
- В В В В else В if В (currentВ ==В getExclusiveOwnerThread())В {В В
- В В В В В В В В int В nextcВ =В cВ +В acquires;В В
- В В В В В В В В if В (nextcВ <В 0 )В //В overflow В В
- В В В В В В В В В В В В throw В new В Error( "MaximumВ lockВ countВ exceeded" );В В
- В В В В В В В В setState(nextc);В В
- В В В В В В В В return В true ;В В
- В В В В }В В
- В В В В return В false ;В В
- }В В
иҜҘж–№жі•дјҡйҰ–е…ҲеҲӨж–ӯеҪ“еүҚзҠ¶жҖҒпјҢеҰӮжһңc==0иҜҙжҳҺжІЎжңүзәҝзЁӢжӯЈеңЁз«һдәүиҜҘй”ҒпјҢеҰӮжһңдёҚc !=0 иҜҙжҳҺжңүзәҝзЁӢжӯЈжӢҘжңүдәҶиҜҘй”ҒгҖӮ
еҰӮ жһңеҸ‘зҺ°c==0пјҢеҲҷйҖҡиҝҮCASи®ҫзҪ®иҜҘзҠ¶жҖҒеҖјдёәacquires,acquiresзҡ„еҲқе§Ӣи°ғз”ЁеҖјдёә1пјҢжҜҸж¬ЎзәҝзЁӢйҮҚе…ҘиҜҘй”ҒйғҪдјҡ+1пјҢжҜҸж¬ЎunlockйғҪдјҡ -1пјҢдҪҶдёә0ж—¶йҮҠж”ҫй”ҒгҖӮеҰӮжһңCASи®ҫзҪ®жҲҗеҠҹпјҢеҲҷеҸҜд»Ҙйў„и®Ўе…¶д»–д»»дҪ•зәҝзЁӢи°ғз”ЁCASйғҪдёҚдјҡеҶҚжҲҗеҠҹпјҢд№ҹе°ұи®ӨдёәеҪ“еүҚзәҝзЁӢеҫ—еҲ°дәҶиҜҘй”ҒпјҢд№ҹдҪңдёәRunningзәҝзЁӢпјҢеҫҲ жҳҫ然иҝҷдёӘRunningзәҝзЁӢ并жңӘиҝӣе…Ҙзӯүеҫ…йҳҹеҲ—гҖӮ
еҰӮжһңc !=0 дҪҶеҸ‘зҺ°иҮӘе·ұе·Із»ҸжӢҘжңүй”ҒпјҢеҸӘжҳҜз®ҖеҚ•ең°++acquiresпјҢ并дҝ®ж”№statusеҖјпјҢдҪҶеӣ дёәжІЎжңүз«һдәүпјҢжүҖд»ҘйҖҡиҝҮsetStatusдҝ®ж”№пјҢиҖҢйқһCASпјҢд№ҹе°ұжҳҜиҜҙиҝҷж®өд»Јз Ғе®һзҺ°дәҶеҒҸеҗ‘й”Ғзҡ„еҠҹиғҪпјҢ并且е®һзҺ°зҡ„йқһеёёжјӮдә®гҖӮ
2.2 AbstractQueuedSynchronizer.addWaiter
addWaiterж–№жі•иҙҹиҙЈжҠҠеҪ“еүҚж— жі•иҺ·еҫ—й”Ғзҡ„зәҝзЁӢеҢ…иЈ…дёәдёҖдёӘNodeж·»еҠ еҲ°йҳҹе°ҫпјҡ
- private В NodeВ addWaiter(NodeВ mode)В {В В
- В В В В NodeВ nodeВ =В new В Node(Thread.currentThread(),В mode);В В
- В В В В //В TryВ theВ fastВ pathВ ofВ enq;В backupВ toВ fullВ enqВ onВ failure В В
- В В В В NodeВ predВ =В tail;В В
- В В В В if В (predВ !=В null )В {В В
- В В В В В В В В node.prevВ =В pred;В В
- В В В В В В В В if В (compareAndSetTail(pred,В node))В {В В
- В В В В В В В В В В В В pred.nextВ =В node;В В
- В В В В В В В В В В В В return В node;В В
- В В В В В В В В }В В
- В В В В }В В
- В В В В enq(node);В В
- В В В В return В node;В В
- }В В
е…¶дёӯеҸӮж•°modeжҳҜзӢ¬еҚ й”ҒиҝҳжҳҜе…ұдә«й”ҒпјҢй»ҳи®ӨдёәnullпјҢзӢ¬еҚ й”ҒгҖӮиҝҪеҠ еҲ°йҳҹе°ҫзҡ„еҠЁдҪңеҲҶдёӨжӯҘпјҡ
- еҰӮжһңеҪ“еүҚйҳҹе°ҫе·Із»ҸеӯҳеңЁ(tail!=null)пјҢеҲҷдҪҝз”ЁCASжҠҠеҪ“еүҚзәҝзЁӢжӣҙж–°дёәTail
- еҰӮжһңеҪ“еүҚTailдёәnullжҲ–еҲҷзәҝзЁӢи°ғз”ЁCASи®ҫзҪ®йҳҹе°ҫеӨұиҙҘпјҢеҲҷйҖҡиҝҮenq方法继з»ӯи®ҫзҪ®Tail
дёӢйқўжҳҜenqж–№жі•пјҡ
- private В NodeВ enq( final В NodeВ node)В {В В
- В В В В for В (;;)В {В В
- В В В В В В В В NodeВ tВ =В tail;В В
- В В В В В В В В if В (tВ ==В null )В {В //В MustВ initialize В В
- В В В В В В В В В В В В NodeВ hВ =В new В Node();В //В DummyВ header В В
- В В В В В В В В В В В В h.nextВ =В node;В В
- В В В В В В В В В В В В node.prevВ =В h;В В
- В В В В В В В В В В В В if В (compareAndSetHead(h))В {В В
- В В В В В В В В В В В В В В В В tailВ =В node;В В
- В В В В В В В В В В В В В В В В return В h;В В
- В В В В В В В В В В В В }В В
- В В В В В В В В }В В
- В В В В В В В В else В {В В
- В В В В В В В В В В В В node.prevВ =В t;В В
- В В В В В В В В В В В В if В (compareAndSetTail(t,В node))В {В В
- В В В В В В В В В В В В В В В В t.nextВ =В node;В В
- В В В В В В В В В В В В В В В В return В t;В В
- В В В В В В В В В В В В }В В
- В В В В В В В В }В В
- В В В В }В В
- }В В
иҜҘж–№жі•е°ұжҳҜеҫӘзҺҜи°ғз”ЁCASпјҢеҚідҪҝжңүй«ҳ并еҸ‘зҡ„еңәжҷҜпјҢж— йҷҗеҫӘзҺҜе°ҶдјҡжңҖз»ҲжҲҗеҠҹжҠҠеҪ“еүҚзәҝзЁӢиҝҪеҠ еҲ°йҳҹе°ҫпјҲжҲ–и®ҫзҪ®йҳҹеӨҙпјүгҖӮжҖ»иҖҢиЁҖд№ӢпјҢaddWaiterзҡ„зӣ®зҡ„е°ұжҳҜйҖҡиҝҮCASжҠҠеҪ“еүҚзҺ°еңЁиҝҪеҠ еҲ°йҳҹе°ҫпјҢ并иҝ”еӣһеҢ…иЈ…еҗҺзҡ„Nodeе®һдҫӢгҖӮ
жҠҠзәҝзЁӢиҰҒеҢ…иЈ…дёәNodeеҜ№иұЎзҡ„дё»иҰҒеҺҹеӣ пјҢйҷӨдәҶз”ЁNodeжһ„йҖ дҫӣиҷҡжӢҹйҳҹеҲ—еӨ–пјҢиҝҳз”ЁNodeеҢ…иЈ…дәҶеҗ„з§ҚзәҝзЁӢзҠ¶жҖҒпјҢиҝҷдәӣзҠ¶жҖҒиў«зІҫеҝғи®ҫи®ЎдёәдёҖдәӣж•°еӯ—еҖјпјҡ
- SIGNAL(-1)В пјҡзәҝзЁӢзҡ„еҗҺ继зәҝзЁӢжӯЈ/е·Іиў«йҳ»еЎһпјҢеҪ“иҜҘзәҝзЁӢreleaseжҲ–cancelж—¶иҰҒйҮҚж–°иҝҷдёӘеҗҺ继зәҝзЁӢ(unpark)
- CANCELLED(1)пјҡеӣ дёәи¶…ж—¶жҲ–дёӯж–ӯпјҢиҜҘзәҝзЁӢе·Із»Ҹиў«еҸ–ж¶Ҳ
- CONDITION(-2)пјҡиЎЁжҳҺиҜҘзәҝзЁӢиў«еӨ„дәҺжқЎд»¶йҳҹеҲ—пјҢе°ұжҳҜеӣ дёәи°ғз”ЁдәҶCondition.awaitиҖҢиў«йҳ»еЎһ
- PROPAGATE(-3)пјҡдј ж’ӯе…ұдә«й”Ғ
- 0пјҡ0д»ЈиЎЁж— зҠ¶жҖҒ
2.3 AbstractQueuedSynchronizer.acquireQueued
acquireQueuedзҡ„дё»иҰҒдҪңз”ЁжҳҜжҠҠе·Із»ҸиҝҪеҠ еҲ°йҳҹеҲ—зҡ„зәҝзЁӢиҠӮзӮ№пјҲaddWaiterж–№жі•иҝ”еӣһеҖјпјүиҝӣиЎҢйҳ»еЎһпјҢдҪҶйҳ»еЎһеүҚеҸҲйҖҡиҝҮtryAccquireйҮҚиҜ•жҳҜеҗҰиғҪиҺ·еҫ—й”ҒпјҢеҰӮжһңйҮҚиҜ•жҲҗеҠҹиғҪеҲҷж— йңҖйҳ»еЎһпјҢзӣҙжҺҘиҝ”еӣһ
- final В boolean В acquireQueued( final В NodeВ node,В int В arg)В {В В
- В В В В try В {В В
- В В В В В В В В boolean В interruptedВ =В false ;В В
- В В В В В В В В for В (;;)В {В В
- В В В В В В В В В В В В final В NodeВ pВ =В node.predecessor();В В
- В В В В В В В В В В В В if В (pВ ==В headВ &&В tryAcquire(arg))В {В В
- В В В В В В В В В В В В В В В В setHead(node);В В
- В В В В В В В В В В В В В В В В p.nextВ =В null ;В //В helpВ GC В В
- В В В В В В В В В В В В В В В В return В interrupted;В В
- В В В В В В В В В В В В }В В
- В В В В В В В В В В В В if В (shouldParkAfterFailedAcquire(p,В node)В &&В В
- В В В В В В В В В В В В В В В В parkAndCheckInterrupt())В В
- В В В В В В В В В В В В В В В В interruptedВ =В true ;В В
- В В В В В В В В }В В
- В В В В }В catch В (RuntimeExceptionВ ex)В {В В
- В В В В В В В В cancelAcquire(node);В В
- В В В В В В В В throw В ex;В В
- В В В В }В В
- }В В
д»”
з»ҶзңӢзңӢиҝҷдёӘж–№жі•жҳҜдёӘж— йҷҗеҫӘзҺҜпјҢж„ҹи§үеҰӮжһңp == head &&
tryAcquire(arg)жқЎд»¶дёҚж»Ўи¶іеҫӘзҺҜе°Ҷж°ёиҝңж— жі•з»“жқҹпјҢеҪ“然дёҚдјҡеҮәзҺ°жӯ»еҫӘзҺҜпјҢеҘҘз§ҳеңЁдәҺ第12иЎҢзҡ„parkAndCheckInterruptдјҡжҠҠ
еҪ“еүҚзәҝзЁӢжҢӮиө·пјҢд»ҺиҖҢйҳ»еЎһдҪҸзәҝзЁӢзҡ„и°ғз”Ёж ҲгҖӮ
- private В final В boolean В parkAndCheckInterrupt()В {В В
- В В В В LockSupport.park(this );В В
- В В В В return В Thread.interrupted();В В
- }В В
еҰӮ еүҚйқўжүҖиҝ°пјҢLockSupport.parkжңҖз»ҲжҠҠзәҝзЁӢдәӨз»ҷзі»з»ҹпјҲLinuxпјүеҶ…ж ёиҝӣиЎҢйҳ»еЎһгҖӮеҪ“然д№ҹдёҚжҳҜ马дёҠжҠҠиҜ·жұӮдёҚеҲ°й”Ғзҡ„зәҝзЁӢиҝӣиЎҢйҳ»еЎһпјҢиҝҳиҰҒжЈҖжҹҘиҜҘзәҝзЁӢ зҡ„зҠ¶жҖҒпјҢжҜ”еҰӮеҰӮжһңиҜҘзәҝзЁӢеӨ„дәҺCancelзҠ¶жҖҒеҲҷжІЎжңүеҝ…иҰҒпјҢе…·дҪ“зҡ„жЈҖжҹҘеңЁshouldParkAfterFailedAcquireдёӯпјҡ
- В В private В static В boolean В shouldParkAfterFailedAcquire(NodeВ pred,В NodeВ node)В {В В
- В В В В В В int В wsВ =В pred.waitStatus;В В
- В В В В В В if В (wsВ ==В Node.SIGNAL)В В
- В В В В В В В В В В /* В
- В В В В В В В В В В В *В ThisВ nodeВ hasВ alreadyВ setВ statusВ askingВ aВ release В
- В В В В В В В В В В В *В toВ signalВ it,В soВ itВ canВ safelyВ park В
- В В В В В В В В В В В */ В В
- В В В В В В В В В В return В true ;В В
- В В В В В В if В (wsВ >В 0 )В {В В
- В В В В В В В В В В /* В
- В В В В В В В В В В В *В PredecessorВ wasВ cancelled.В SkipВ overВ predecessorsВ and В
- В В В В В В В В В В В *В indicateВ retry. В
- В В В В В В В В В В В */ В В
- В В В do В {В В
- node.prevВ =В predВ =В pred.prev;В В
- В В В }В while В (pred.waitStatusВ >В 0 );В В
- В В В pred.nextВ =В node;В В
- В В В В В В }В else В {В В
- В В В В В В В В В В /* В
- В В В В В В В В В В В *В waitStatusВ mustВ beВ 0В orВ PROPAGATE.В IndicateВ thatВ we В
- В В В В В В В В В В В *В needВ aВ signal,В butВ don'tВ parkВ yet.В CallerВ willВ needВ to В
- В В В В В В В В В В В *В retryВ toВ makeВ sureВ itВ cannotВ acquireВ beforeВ parking.В В
- В В В В В В В В В В В */ В В
- В В В В В В В В В В compareAndSetWaitStatus(pred,В ws,В Node.SIGNAL);В В
- В В В В В В }В В В
- В В В В В В return В false ;В В
- В В }В В
жЈҖжҹҘеҺҹеҲҷеңЁдәҺпјҡ
- 规еҲҷ1пјҡеҰӮжһңеүҚ继зҡ„иҠӮзӮ№зҠ¶жҖҒдёәSIGNALпјҢиЎЁжҳҺеҪ“еүҚиҠӮзӮ№йңҖиҰҒunparkпјҢеҲҷиҝ”еӣһжҲҗеҠҹпјҢжӯӨж—¶acquireQueuedж–№жі•зҡ„第12иЎҢпјҲparkAndCheckInterruptпјүе°ҶеҜјиҮҙзәҝзЁӢйҳ»еЎһ
- 规еҲҷ2пјҡеҰӮжһңеүҚ继иҠӮзӮ№зҠ¶жҖҒдёәCANCELLED(ws>0)пјҢиҜҙжҳҺеүҚзҪ®иҠӮзӮ№е·Із»Ҹиў«ж”ҫејғпјҢеҲҷеӣһжәҜеҲ°дёҖдёӘйқһеҸ–ж¶Ҳзҡ„еүҚ继иҠӮзӮ№пјҢиҝ”еӣһfalseпјҢacquireQueuedж–№жі•зҡ„ж— йҷҗеҫӘзҺҜе°ҶйҖ’еҪ’и°ғз”ЁиҜҘж–№жі•пјҢзӣҙиҮіи§„еҲҷ1иҝ”еӣһtrueпјҢеҜјиҮҙзәҝзЁӢйҳ»еЎһ
- 规еҲҷ3пјҡеҰӮжһңеүҚ继иҠӮзӮ№зҠ¶жҖҒдёәйқһSIGNALгҖҒйқһCANCELLEDпјҢеҲҷи®ҫзҪ®еүҚ继зҡ„зҠ¶жҖҒдёәSIGNALпјҢиҝ”еӣһfalseеҗҺиҝӣе…ҘacquireQueuedзҡ„ж— йҷҗеҫӘзҺҜпјҢдёҺ规еҲҷ2еҗҢ
жҖ»дҪ“зңӢжқҘпјҢshouldParkAfterFailedAcquireе°ұжҳҜйқ еүҚ继иҠӮзӮ№еҲӨж–ӯеҪ“еүҚзәҝзЁӢжҳҜеҗҰеә”иҜҘиў«йҳ»еЎһпјҢеҰӮжһңеүҚ继иҠӮзӮ№еӨ„дәҺCANCELLEDзҠ¶жҖҒпјҢеҲҷйЎәдҫҝеҲ йҷӨиҝҷдәӣиҠӮзӮ№йҮҚж–°жһ„йҖ йҳҹеҲ—гҖӮ
иҮіжӯӨпјҢй”ҒдҪҸзәҝзЁӢзҡ„йҖ»иҫ‘е·Із»Ҹе®ҢжҲҗпјҢдёӢйқўи®Ёи®әи§Јй”Ғзҡ„иҝҮзЁӢгҖӮ
3. и§Јй”Ғ
иҜ·жұӮй”ҒдёҚжҲҗеҠҹзҡ„зәҝзЁӢдјҡиў«жҢӮиө·еңЁacquireQueuedж–№жі•зҡ„第12иЎҢпјҢ12иЎҢд»ҘеҗҺзҡ„д»Јз Ғеҝ…йЎ»зӯүзәҝзЁӢиў«и§Јй”Ғй”ҒжүҚиғҪжү§иЎҢпјҢеҒҮеҰӮиў«йҳ»еЎһзҡ„зәҝзЁӢеҫ—еҲ°и§Јй”ҒпјҢеҲҷжү§иЎҢ第13иЎҢпјҢеҚіи®ҫзҪ®interrupted = trueпјҢд№ӢеҗҺеҸҲиҝӣе…Ҙж— йҷҗеҫӘзҺҜгҖӮ
д»Һ ж— йҷҗеҫӘзҺҜзҡ„д»Јз ҒеҸҜд»ҘзңӢеҮәпјҢ并дёҚжҳҜеҫ—еҲ°и§Јй”Ғзҡ„зәҝзЁӢдёҖе®ҡиғҪиҺ·еҫ—й”ҒпјҢеҝ…йЎ»еңЁз¬¬6иЎҢдёӯи°ғз”ЁtryAccquireйҮҚж–°з«һдәүпјҢеӣ дёәй”ҒжҳҜйқһе…¬е№ізҡ„пјҢжңүеҸҜиғҪиў«ж–°еҠ е…Ҙзҡ„зәҝ зЁӢиҺ·еҫ—пјҢд»ҺиҖҢеҜјиҮҙеҲҡиў«е”ӨйҶ’зҡ„зәҝзЁӢеҶҚж¬Ўиў«йҳ»еЎһпјҢиҝҷдёӘз»ҶиҠӮе……еҲҶдҪ“зҺ°дәҶвҖңйқһе…¬е№івҖқзҡ„зІҫй«“гҖӮйҖҡиҝҮд№ӢеҗҺе°ҶиҰҒд»Ӣз»Қзҡ„и§Јй”ҒжңәеҲ¶дјҡзңӢеҲ°пјҢ第дёҖдёӘиў«и§Јй”Ғзҡ„зәҝзЁӢе°ұжҳҜHeadпјҢ еӣ жӯӨp == headзҡ„еҲӨж–ӯеҹәжң¬йғҪдјҡжҲҗеҠҹгҖӮ
иҮіжӯӨеҸҜд»ҘзңӢеҲ°пјҢжҠҠtryAcquire方法延иҝҹеҲ°еӯҗзұ»дёӯе®һзҺ°зҡ„еҒҡжі•йқһеёёзІҫеҰҷ并具жңүжһҒејәзҡ„еҸҜжү©еұ•жҖ§пјҢд»ӨдәәеҸ№дёәи§ӮжӯўпјҒеҪ“然зІҫеҰҷзҡ„дёҚжҳҜиҝҷдёӘTemplaeи®ҫи®ЎжЁЎејҸпјҢиҖҢжҳҜDoug LeaеҜ№й”Ғз»“жһ„зҡ„зІҫеҝғеёғеұҖгҖӮ
и§Јй”Ғд»Јз ҒзӣёеҜ№з®ҖеҚ•пјҢдё»иҰҒдҪ“зҺ°еңЁAbstractQueuedSynchronizer.releaseе’ҢSync.tryReleaseж–№жі•дёӯпјҡ
class AbstractQueuedSynchronizer
- public В final В boolean В release( int В arg)В {В В
- В В В В if В (tryRelease(arg))В {В В
- В В В В В В В В NodeВ hВ =В head;В В
- В В В В В В В В if В (hВ !=В null В &&В h.waitStatusВ !=В 0 )В В
- В В В В В В В В В В В В unparkSuccessor(h);В В
- В В В В В В В В return В true ;В В
- В В В В }В В
- В В В В return В false ;В В
- }В В
class Sync
- protected В final В boolean В tryRelease( int В releases)В {В В
- В В В В int В cВ =В getState()В -В releases;В В
- В В В В if В (Thread.currentThread()В !=В getExclusiveOwnerThread())В В
- В В В В В В В В throw В new В IllegalMonitorStateException();В В
- В В В В boolean В freeВ =В false ;В В
- В В В В if В (cВ ==В 0 )В {В В
- В В В В В В В В freeВ =В true ;В В
- В В В В В В В В setExclusiveOwnerThread(null );В В
- В В В В }В В
- В В В В setState(c);В В
- В В В В return В free;В В
- }В В
tryReleaseдёҺtryAcquireиҜӯд№үзӣёеҗҢпјҢжҠҠеҰӮдҪ•йҮҠж”ҫзҡ„йҖ»иҫ‘延иҝҹеҲ°еӯҗзұ»дёӯгҖӮtryReleaseиҜӯд№үеҫҲжҳҺзЎ®пјҡеҰӮжһңзәҝзЁӢеӨҡж¬Ўй”Ғе®ҡпјҢеҲҷиҝӣиЎҢеӨҡж¬ЎйҮҠж”ҫпјҢзӣҙиҮіstatus==0еҲҷзңҹжӯЈйҮҠж”ҫй”ҒпјҢжүҖи°“йҮҠж”ҫй”ҒеҚіи®ҫзҪ®statusдёә0пјҢеӣ дёәж— з«һдәүжүҖд»ҘжІЎжңүдҪҝз”ЁCASгҖӮ
releaseзҡ„иҜӯд№үеңЁдәҺпјҡеҰӮжһңеҸҜд»ҘйҮҠж”ҫй”ҒпјҢеҲҷе”ӨйҶ’йҳҹеҲ—第дёҖдёӘзәҝзЁӢпјҲHeadпјүпјҢе…·дҪ“е”ӨйҶ’д»Јз ҒеҰӮдёӢпјҡ
- private В void В unparkSuccessor(NodeВ node)В {В В
- В В В В /* В
- В В В В В *В IfВ statusВ isВ negativeВ (i.e.,В possiblyВ needingВ signal)В try В
- В В В В В *В toВ clearВ inВ anticipationВ ofВ signalling.В ItВ isВ OKВ ifВ this В
- В В В В В *В failsВ orВ ifВ statusВ isВ changedВ byВ waitingВ thread. В
- В В В В В */ В В
- В В В В int В wsВ =В node.waitStatus;В В
- В В В В if В (wsВ <В 0 )В В
- В В В В В В В В compareAndSetWaitStatus(node,В ws,В 0 );В В В
- В В
- В В В В /* В
- В В В В В *В ThreadВ toВ unparkВ isВ heldВ inВ successor,В whichВ isВ normally В
- В В В В В *В justВ theВ nextВ node.В В ButВ ifВ cancelledВ orВ apparentlyВ null, В
- В В В В В *В traverseВ backwardsВ fromВ tailВ toВ findВ theВ actual В
- В В В В В *В non-cancelledВ successor. В
- В В В В В */ В В
- В В В В NodeВ sВ =В node.next;В В
- В В В В if В (sВ ==В null В ||В s.waitStatusВ >В 0 )В {В В
- В В В В В В В В sВ =В null ;В В
- В В В В В В В В for В (NodeВ tВ =В tail;В tВ !=В null В &&В tВ !=В node;В tВ =В t.prev)В В
- В В В В В В В В В В В В if В (t.waitStatusВ <=В 0 )В В
- В В В В В В В В В В В В В В В В sВ =В t;В В
- В В В В }В В
- В В В В if В (sВ !=В null )В В
- В В В В В В В В LockSupport.unpark(s.thread);В В
- }В В
иҝҷ
ж®өд»Јз Ғзҡ„ж„ҸжҖқеңЁдәҺжүҫеҮә第дёҖдёӘеҸҜд»Ҙunparkзҡ„зәҝзЁӢпјҢдёҖиҲ¬иҜҙжқҘhead.next ==
headпјҢHeadе°ұжҳҜ第дёҖдёӘзәҝзЁӢпјҢдҪҶHead.nextеҸҜиғҪиў«еҸ–ж¶ҲжҲ–иў«зҪ®дёәnullпјҢеӣ жӯӨжҜ”иҫғзЁіеҰҘзҡ„еҠһжі•жҳҜд»ҺеҗҺеҫҖеүҚжүҫ第дёҖдёӘеҸҜз”ЁзәҝзЁӢгҖӮиІҢдјјеӣһжәҜдјҡеҜјиҮҙжҖ§
иғҪйҷҚдҪҺпјҢе…¶е®һиҝҷдёӘеҸ‘з”ҹзҡ„еҮ зҺҮеҫҲе°ҸпјҢжүҖд»ҘдёҚдјҡжңүжҖ§иғҪеҪұе“ҚгҖӮд№ӢеҗҺдҫҝжҳҜйҖҡзҹҘзі»з»ҹеҶ…ж ёз»§з»ӯиҜҘзәҝзЁӢпјҢеңЁLinuxдёӢжҳҜйҖҡиҝҮpthread_mutex_unlock
е®ҢжҲҗгҖӮд№ӢеҗҺпјҢиў«и§Јй”Ғзҡ„зәҝзЁӢиҝӣе…ҘдёҠйқўжүҖиҜҙзҡ„йҮҚж–°з«һдәүзҠ¶жҖҒгҖӮ
4. Lock VS Synchronized
AbstractQueuedSynchronizerйҖҡиҝҮжһ„йҖ дёҖдёӘеҹәдәҺйҳ»еЎһзҡ„CLHйҳҹеҲ—е®№зәіжүҖжңүзҡ„йҳ»еЎһзәҝзЁӢпјҢиҖҢеҜ№иҜҘйҳҹеҲ—зҡ„ж“ҚдҪңеқҮйҖҡиҝҮLock-FreeпјҲCASпјүж“ҚдҪңпјҢдҪҶеҜ№е·Із»ҸиҺ·еҫ—й”Ғзҡ„зәҝзЁӢиҖҢиЁҖпјҢReentrantLockе®һзҺ°дәҶеҒҸеҗ‘й”Ғзҡ„еҠҹиғҪгҖӮ
synchronized зҡ„еә•еұӮд№ҹжҳҜдёҖдёӘеҹәдәҺCASж“ҚдҪңзҡ„зӯүеҫ…йҳҹеҲ—пјҢдҪҶJVMе®һзҺ°зҡ„жӣҙзІҫз»ҶпјҢжҠҠзӯүеҫ…йҳҹеҲ—еҲҶдёәContentionListе’ҢEntryListпјҢзӣ®зҡ„жҳҜдёәдәҶйҷҚдҪҺзәҝзЁӢ зҡ„еҮәеҲ—йҖҹеәҰпјӣеҪ“然д№ҹе®һзҺ°дәҶеҒҸеҗ‘й”ҒпјҢд»Һж•°жҚ®з»“жһ„жқҘиҜҙдәҢиҖ…и®ҫи®ЎжІЎжңүжң¬иҙЁеҢәеҲ«гҖӮдҪҶsynchronizedиҝҳе®һзҺ°дәҶиҮӘж—Ӣй”ҒпјҢ并й’ҲеҜ№дёҚеҗҢзҡ„зі»з»ҹе’Ң硬件дҪ“зі»иҝӣиЎҢдәҶдјҳ еҢ–пјҢиҖҢLockеҲҷе®Ңе…Ёдҫқйқ зі»з»ҹйҳ»еЎһжҢӮиө·зӯүеҫ…зәҝзЁӢгҖӮ
еҪ“然LockжҜ”synchronizedжӣҙйҖӮеҗҲеңЁеә”з”ЁеұӮжү©еұ•пјҢеҸҜд»Ҙ继жүҝ AbstractQueuedSynchronizerе®ҡд№үеҗ„з§Қе®һзҺ°пјҢжҜ”еҰӮе®һзҺ°иҜ»еҶҷй”ҒпјҲReadWriteLockпјүпјҢе…¬е№іжҲ–дёҚе…¬е№ій”ҒпјӣеҗҢж—¶пјҢLockеҜ№ еә”зҡ„Conditionд№ҹжҜ”wait/notifyиҰҒж–№дҫҝзҡ„еӨҡгҖҒзҒөжҙ»зҡ„еӨҡгҖӮ


- 2011-09-19 01:00
- жөҸи§Ҳ 991
- иҜ„и®ә(0)
- еҲҶзұ»:зј–зЁӢиҜӯиЁҖ
- жҹҘзңӢжӣҙеӨҡ
еҸ‘иЎЁиҜ„и®ә

-
java жӯЈеҲҷиЎЁиҫҫејҸ йқһжҚ•иҺ·з»„(зү№ж®Ҡжһ„йҖ )Special Constructs(Non-Capturing)
2011-06-20 23:15 1671й’ҲеҜ№Java APIж–ҮжЎЈдёӯзҡ„жӯЈеҲҷиЎЁиҫҫејҸе…ідәҺзү№ж®Ҡжһ„йҖ (йқһжҚ•иҺ·з»„) ... -
Javaж–Ү件жҳ е°„[mmap]жҸӯз§ҳ
2011-06-08 20:10 1210В еүҚиЁҖ зӣёдҝЎзҺ°еңЁе ... -
еҺҹеҲӣ javaзҡ„MmapдәҢдёүдәӢ
2011-06-08 19:46 1217иҪ¬иҮӘ пјҡhttp://blog.csdn.net/kabini ... -
java е®үе…ЁжІҷз®ұжЁЎеһӢиҜҰи§Ј
2011-04-18 16:29 963иө·еҲ°з¬¬дёҖйҒ“е®үе…ЁдҝқйҡңдҪңз ... -
йқһйҳ»еЎһз®—жі•-ReentrantLockд»Јз Ғеү–жһҗд№ӢReentrantLock.lock
2011-04-15 13:59 1105ReentrantLockжҳҜjava.util.concurr ... -
CyclicBarrierдёҺCountDownLatchгҖҒж …ж ҸдёҺи®Ўж•°еҷЁ
2011-04-15 10:39 1498еңЁеӨҡзәҝзЁӢи®ҫи®ЎдёӯпјҢжҲ‘зҢңеёёеёёдјҡйҒҮеҲ°зәҝзЁӢй—ҙзӣёдә’зӯүеҫ…д»ҘеҸҠжҹҗдёӘзәҝзЁӢзӯүеҫ…1 ... -
Java KeyStore
2011-04-13 17:17 1487з®Җд»ӢJavaиҮӘеёҰзҡ„keytoolе·Ҙе…·жҳҜдёӘеҜҶй’Ҙе’ҢиҜҒд№Ұз®ЎзҗҶе·Ҙе…·гҖӮе®ғ ... -
Security Managers and the JavaTM 2 SDK
2011-04-12 13:37 795The original Link : http://do ... -
Something about SecurityManager
2011-04-12 13:33 806The Java Security was made up o ... -
Using the Java SecurityManager with Tomcat
2011-04-12 13:30 1022Why use a SecurityManager? The ... -
Javaе®үе…Ёз®ЎзҗҶеҷЁпјҲSecurity Manager)(
2011-04-11 14:54 914иҪ¬иҪҪиҮӘпјҡ http://blog.sina.com.cn/s/ ... -
JavaеҜ№иұЎзҡ„ејәгҖҒиҪҜгҖҒејұе’Ңиҷҡеј•з”Ё(1)
2011-04-01 08:44 822жң¬ж–Үд»Ӣз»ҚJavaеҜ№иұЎзҡ„ејәг ... -
JavaеҜ№иұЎзҡ„ејәеј•з”ЁгҖҒиҪҜеј•з”ЁгҖҒејұеј•з”Ёе’Ңиҷҡеј•з”Ё
2011-04-01 08:39 931еңЁJDK1.2д»ҘеүҚзҡ„зүҲжң¬дёӯпјҢе ... -
java й«ҳ并еҸ‘ ReentrantLock -- еҸҜйҮҚе…Ҙзҡ„й”Ғ
2011-03-30 08:09 2408ReentrantLock -- еҸҜйҮҚе…Ҙзҡ„й”Ғ еҸҜйҮҚе…Ҙй”ҒжҢҮ ... -
зәҝзЁӢиҝҗиЎҢж ҲдҝЎжҒҜзҡ„иҺ·еҸ–
2011-03-24 17:23 1337зәҝзЁӢиҝҗиЎҢж ҲдҝЎжҒҜзҡ„иҺ·еҸ– ... -
javaеәҸеҲ—еҢ–вҖ”вҖ”Serializable
2011-03-15 23:17 1091зұ»йҖҡиҝҮе®һзҺ° java.io.Serializable жҺҘеҸЈ ... -
Java aio(ејӮжӯҘзҪ‘з»ңIO)еҲқжҺў
2011-03-11 16:34 1596жҢүз…§гҖҠUnixзҪ‘з»ңзј–зЁӢгҖӢзҡ„ ... -
JAVA NIO з®Җд»Ӣ
2011-03-11 13:38 11371. В еҹәжң¬ жҰӮеҝө IO жҳҜдё»еӯҳе’ҢеӨ–йғЁи®ҫеӨҮ ( зЎ¬зӣҳгҖҒз»Ҳ ... -
[еӯ—иҠӮз Ғзі»еҲ—]ObjectWeb ASMжһ„е»әMethod Monitor
2011-03-08 18:08 954В В В В В еңЁеүҚйқўзҡ„зҜҮз« дёӯпјҢжҲ‘们зңӢеҲ°Java Instru ... -
ж·ұе…ҘдәҶи§ЈJava ClassLoaderгҖҒBytecode гҖҒASMгҖҒcglib
2011-03-08 16:35 893дёҖгҖҒJava ClassLoader 1пјҢд»Җд ...
зӣёе…іжҺЁиҚҗ
дәҶи§Ј JVM й”ҒжңәеҲ¶дёӯзҡ„ synchronized е’Ң Lock е®һзҺ°еҺҹзҗҶ еңЁ Java дёӯпјҢй”ҒжңәеҲ¶жҳҜж•°жҚ®еҗҢжӯҘзҡ„е…ій”®пјҢеӯҳеңЁдёӨз§Қй”ҒжңәеҲ¶пјҡsynchronized е’Ң LockгҖӮдәҶи§ЈиҝҷдёӨз§Қй”ҒжңәеҲ¶зҡ„е®һзҺ°еҺҹзҗҶеҜ№дәҺзҗҶи§Ј Java 并еҸ‘зј–зЁӢйқһеёёйҮҚиҰҒгҖӮ synchronized й”Ғ...
гҖҠж·ұе…ҘJVMеҶ…ж ёвҖ”еҺҹзҗҶгҖҒиҜҠж–ӯдёҺдјҳеҢ–гҖӢжҳҜдёҖд»Ҫж·ұеәҰжҺўзҙўJavaиҷҡжӢҹжңәпјҲJVMпјүзҡ„и§Ҷйў‘ж•ҷзЁӢпјҢж—ЁеңЁеё®еҠ©ејҖеҸ‘иҖ…е…ЁйқўзҗҶи§ЈJVMзҡ„е·ҘдҪңжңәеҲ¶пјҢжҺҢжҸЎжҖ§иғҪиҜҠж–ӯжҠҖе·§пјҢ并иғҪиҝӣиЎҢжңүж•Ҳзҡ„дјҳеҢ–гҖӮжң¬ж•ҷзЁӢиҰҶзӣ–дәҶд»ҺеҹәзЎҖеҲ°й«ҳзә§зҡ„JVMдё»йўҳпјҢдёҚд»…йҖӮз”ЁдәҺJava...
JavaиҷҡжӢҹжңәпјҲJVMпјүжҳҜиҝҗиЎҢJavaзЁӢеәҸзҡ„е…ій”®е№іеҸ°пјҢе…¶еҶ…йғЁз»“жһ„е’ҢеҶ…еӯҳз®ЎзҗҶжңәеҲ¶йқһеёёеӨҚжқӮдё”зІҫз»ҶгҖӮе®ғе°ҶеҶ…еӯҳеҲҶдёәиӢҘе№ІдёӘдёҚеҗҢзҡ„ж•°жҚ®еҢәеҹҹпјҢд»Ҙдҫҝз®ЎзҗҶJavaзЁӢеәҸзҡ„иҝҗиЎҢж—¶ж•°жҚ®гҖӮдёӢйқўе°ҶиҜҰз»Ҷд»Ӣз»ҚJVMдёӯзҡ„иҝҗиЎҢж—¶ж•°жҚ®еҢәпјҢд»ҘеҸҠJavaеҶ…еӯҳжЁЎеһӢ...
JVMиҝҗиЎҢжңәеҲ¶з®Җд»Ӣ е ҶгҖҒж ҲгҖҒж–№жі•еҢәзӯү JVMеҗҜеҠЁжөҒзЁӢ еҶ…еӯҳжЁЎеһӢе’Ңvolatileе®һдҫӢ и§ЈйҮҠе’Ңзј–иҜ‘иҝҗиЎҢзҡ„жҰӮеҝө д»Ӣз»ҚJVMзҡ„еҶ…йғЁз»“жһ„гҖҒеҗҜеҠЁжөҒзЁӢд»ҘеҸҠеҶ…еӯҳжЁЎеһӢгҖӮ并д»Ӣз»ҚJVMеӯ—иҠӮз Ғзҡ„жү§иЎҢж–№ејҸгҖӮ 第дёүиҜҫ еёёз”ЁJVMеҸӮж•° е Ҷзҡ„еҲҶй…ҚеҸӮж•° ж ҲеҲҶй…ҚеҸҠ...
ж №жҚ®жҸҗдҫӣзҡ„ж–Ү件дҝЎжҒҜпјҢвҖңеңЈжҖқеӣӯеј йҫҷ ж·ұе…ҘзҗҶи§ЈjvmвҖқпјҢжҲ‘们еҸҜд»ҘжҺЁж–ӯеҮәиҝҷд»Ҫиө„ж–ҷдё»иҰҒе…іжіЁдәҺJavaиҷҡжӢҹжңә(JVM)зҡ„ж·ұе…ҘзҗҶи§Је’Ңе®һи·өеә”з”ЁгҖӮJVMжҳҜJavaејҖеҸ‘зҺҜеўғдёӯйқһеёёж ёеҝғзҡ„дёҖдёӘз»„жҲҗйғЁеҲҶпјҢе®ғдёҚд»…дёәJavaзЁӢеәҸжҸҗдҫӣдәҶиҝҗиЎҢж—¶зҺҜеўғпјҢиҝҳиҙҹиҙЈ...
гҖҠж·ұе…ҘJVMеҶ…ж ёвҖ”еҺҹзҗҶгҖҒиҜҠж–ӯдёҺдјҳеҢ–гҖӢжҳҜдёҖд»Ҫе…Ёйқўж¶өзӣ–JavaиҷҡжӢҹжңәж ёеҝғзҹҘиҜҶзҡ„ж•ҷзЁӢпјҢе…ұи®Ў11дёӘз« иҠӮпјҢж—ЁеңЁеё®еҠ©иҜ»иҖ…ж·ұе…ҘзҗҶи§ЈJVMзҡ„е·ҘдҪңеҺҹзҗҶпјҢжҺҢжҸЎж•…йҡңиҜҠж–ӯжҠҖе·§пјҢ并иғҪиҝӣиЎҢжңүж•Ҳзҡ„жҖ§иғҪдјҳеҢ–гҖӮиҝҷд»Ҫиө„ж–ҷжҳҜжҜҸдёҖдёӘJavaејҖеҸ‘иҖ…иҝӣйҳ¶зҡ„еҝ…еӨҮ...
гҖҠж·ұе…ҘJVMеҶ…ж ёвҖ”вҖ”еҺҹзҗҶгҖҒиҜҠж–ӯдёҺдјҳеҢ–гҖӢжҳҜдёҖд»Ҫж·ұеәҰжҺўи®ЁJavaиҷҡжӢҹжңәж ёеҝғжңәеҲ¶гҖҒй—®йўҳиҜҠж–ӯе’ҢжҖ§иғҪдјҳеҢ–зҡ„дё“дёҡиө„ж–ҷгҖӮиҝҷд»Ҫиө„ж–ҷж¶өзӣ–дәҶJVMзҡ„еҗ„дёӘж–№йқўпјҢеҜ№дәҺJavaејҖеҸ‘иҖ…жқҘиҜҙпјҢзҗҶи§Је’ҢжҺҢжҸЎиҝҷдәӣзҹҘиҜҶиҮіе…ійҮҚиҰҒгҖӮ йҰ–е…ҲпјҢжҲ‘们иҰҒдәҶи§ЈJVM...
5. **зәҝзЁӢй—ҙйҖҡдҝЎ**пјҡйҷӨдәҶй”ҒжңәеҲ¶пјҢJVMиҝҳжҸҗдҫӣдәҶдёҖзі»еҲ—зҡ„зәҝзЁӢй—ҙйҖҡдҝЎе·Ҙе…·пјҢеҰӮ`ThreadLocal`гҖҒ`Wait/Notify`гҖҒ`CountDownLatch`гҖҒ`Semaphore`гҖҒ`CyclicBarrier`зӯүпјҢз”ЁдәҺи§ЈеҶізәҝзЁӢй—ҙзҡ„еҗҢжӯҘй—®йўҳпјҢдҪҝеӨҡзәҝзЁӢзЁӢеәҸжӣҙеҠ зҒөжҙ»е’ҢеҸҜжҺ§...
9. **并еҸ‘дёҺеӨҡзәҝзЁӢ**пјҡJVMж”ҜжҢҒеӨҡзәҝзЁӢпјҢзәҝзЁӢй—ҙйҖҡдҝЎе’ҢеҗҢжӯҘйҖҡиҝҮй”ҒгҖҒдҝЎеҸ·йҮҸгҖҒеҺҹеӯҗеҸҳйҮҸзӯүжңәеҲ¶е®һзҺ°гҖӮзҗҶи§ЈзәҝзЁӢжЁЎеһӢе’Ң并еҸ‘еҺҹиҜӯеҜ№дәҺзј–еҶҷй«ҳж•Ҳ并еҸ‘зЁӢеәҸиҮіе…ійҮҚиҰҒгҖӮ 10. **ејӮеёёеӨ„зҗҶ**пјҡJavaејӮеёёеӨ„зҗҶжңәеҲ¶йҖҡиҝҮtry-catch-finally...
жң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁиҝҷдёӨдёӘдё»йўҳпјҢеё®еҠ©зҗҶи§ЈJVMеҰӮдҪ•з®ЎзҗҶе’ҢдјҳеҢ–еҶ…еӯҳгҖӮ **дёҖгҖҒзұ»еҠ иҪҪеҷЁе’ҢеҸҢдәІе§”жҙҫжңәеҲ¶** зұ»еҠ иҪҪеҷЁжҳҜJVMзҡ„дёҖдёӘз»„жҲҗйғЁеҲҶпјҢиҙҹиҙЈеҠ иҪҪJavaзұ»еҲ°еҶ…еӯҳдёӯгҖӮеҠ иҪҪиҝҮзЁӢеҢ…жӢ¬дә”дёӘжӯҘйӘӨпјҡ 1. **еҠ иҪҪ**пјҡд»ҺзЈҒзӣҳиҜ»еҸ–еӯ—иҠӮз Ғ...
гҖҠж·ұе…ҘзҗҶи§ЈJavaиҷҡжӢҹжңәгҖӢжҳҜJavaејҖеҸ‘иҖ…ж·ұе…ҘдәҶи§ЈJVMпјҲJava Virtual Machineпјүзҡ„еҝ…еӨҮд№ҰзұҚпјҢе°Өе…¶еҜ№дәҺжғіиҰҒжҸҗеҚҮжҠҖжңҜж·ұеәҰгҖҒдјҳеҢ–зЁӢеәҸжҖ§иғҪзҡ„е·ҘзЁӢеёҲжқҘиҜҙпјҢжӣҙжҳҜдёҚеҸҜжҲ–зјәзҡ„еҸӮиҖғиө„ж–ҷгҖӮиҝҷжң¬д№Ұзҡ„第дәҢзүҲе…ЁйқўиҰҶзӣ–дәҶJVMзҡ„жңҖж–°еҸ‘еұ•пјҢеҢ…жӢ¬...
2019жңҖж–°ж·ұе…ҘзҗҶи§ЈJVMеҶ…еӯҳз»“жһ„еҸҠиҝҗиЎҢеҺҹзҗҶпјҲJVMи°ғдјҳпјүй«ҳзә§ж ёеҝғиҜҫзЁӢи§Ҷйў‘ж•ҷзЁӢдёӢиҪҪгҖӮJVMжҳҜJavaзҹҘиҜҶдҪ“зі»дёӯзҡ„йҮҚиҰҒйғЁеҲҶпјҢеҜ№JVMеә•еұӮзҡ„дәҶи§ЈжҳҜжҜҸдёҖдҪҚJavaзЁӢеәҸе‘ҳж·ұе…ҘJavaжҠҖжңҜйўҶеҹҹзҡ„йҮҚиҰҒеӣ зҙ гҖӮжң¬иҜҫзЁӢиҜ•еӣҫйҖҡиҝҮз®ҖеҚ•жҳ“жҮӮзҡ„ж–№ејҸпјҢзі»з»ҹ...
йҖҡиҝҮж·ұе…ҘеӯҰд№ JVMпјҢејҖеҸ‘иҖ…еҸҜд»ҘжӣҙеҘҪең°зҗҶи§ЈJavaзЁӢеәҸзҡ„иҝҗиЎҢжңәеҲ¶пјҢдјҳеҢ–д»Јз ҒжҖ§иғҪпјҢи§ЈеҶіеҶ…еӯҳжәўеҮәгҖҒзәҝзЁӢе®үе…Ёзӯүй—®йўҳпјҢжҸҗеҚҮзі»з»ҹзҡ„зЁіе®ҡжҖ§е’Ңж•ҲзҺҮгҖӮгҖҠInside Java Virtual MachineгҖӢиҝҷж ·зҡ„иө„жәҗпјҢжӯЈжҳҜдёәдәҶеё®еҠ©жҲ‘们系з»ҹжҖ§ең°жҺўзҙўе’Ң...
жң¬ж–Үе°Ҷж·ұе…ҘжҺўи®ЁJavaй”ҒжңәеҲ¶пјҢ并еҹәдәҺжҸҗдҫӣзҡ„"йқўеҗ‘Javaй”ҒжңәеҲ¶зҡ„еӯ—иҠӮз ҒиҮӘеҠЁйҮҚжһ„жЎҶжһ¶"жқҘи®Ёи®әе…¶иғҢеҗҺзҡ„еҺҹзҗҶе’Ңеә”з”ЁгҖӮ еңЁJavaдёӯпјҢй”Ғдё»иҰҒеҲҶдёәеҶ…зҪ®й”ҒпјҲд№ҹз§°дёәзӣ‘и§ҶеҷЁй”Ғпјүе’ҢжҳҫејҸй”ҒгҖӮеҶ…зҪ®й”ҒжҳҜйҖҡиҝҮsynchronizedе…ій”®еӯ—е®һзҺ°зҡ„пјҢе®ғжҸҗдҫӣ...
JavaжҸҗдҫӣдәҶеӨҡз§Қ并еҸ‘е·Ҙе…·е’ҢжңәеҲ¶пјҢеҰӮsynchronizedе…ій”®еӯ—гҖҒvolatileе…ій”®еӯ—гҖҒеҗ„з§Қй”ҒжңәеҲ¶гҖҒд»ҘеҸҠjava.util.concurrentеҢ…дёӢзҡ„并еҸ‘зұ»е’ҢжҺҘеҸЈгҖӮ жҸҸиҝ°дёӯжҸҗеҲ°дәҶдёҖдёӘеҚҡж–Үй“ҫжҺҘпјҢе°Ҫз®ЎжІЎжңүз»ҷеҮәе…·дҪ“еҶ…е®№пјҢдҪҶж №жҚ®ж ҮйўҳпјҢжҲ‘们еҸҜд»ҘжҺЁжөӢиҜҘ...
JVMжҸҗдҫӣзҡ„еҗҢжӯҘжңәеҲ¶гҖҒй”Ғзӯ–з•ҘзӯүйғҪжҳҜдҝқиҜҒзәҝзЁӢе®үе…Ёзҡ„жүӢж®өгҖӮ 11. жҖ»з»“дёҺеҸӮиҖғиө„ж–ҷ JVMи°ғдјҳж¶үеҸҠзҡ„зҹҘиҜҶзӮ№з№ҒеӨҡпјҢд»Һеҹәжң¬жҰӮеҝөеҲ°й«ҳзә§жҠҖжңҜйғҪжңүж¶үзҢҺгҖӮзӣёе…ізҡ„еҸӮиҖғиө„ж–ҷе’Ңе·Ҙе…·еҜ№дәҺеӯҰд№ JVMи°ғдјҳд№ҹжңүеҫҲеӨ§её®еҠ©пјҢеҢ…жӢ¬е®ҳж–№ж–ҮжЎЈгҖҒдё“дёҡзӨҫеҢәгҖҒ...
JavaжҸҗдҫӣдәҶеӨҡз§Қй”ҒжңәеҲ¶пјҢеҰӮsynchronizedгҖҒLockжҺҘеҸЈзӯүпјҢзҗҶи§Је…¶е·ҘдҪңеҺҹзҗҶе’ҢжҖ§иғҪзү№жҖ§еҜ№дәҺзј–еҶҷй«ҳжҖ§иғҪ并еҸ‘д»Јз ҒиҮіе…ійҮҚиҰҒгҖӮ 10. **Classж–Ү件结жһ„** (10.Classж–Ү件结жһ„.pptx) Classж–Ү件еҢ…еҗ«дәҶзұ»зҡ„е…ғж•°жҚ®пјҢзҗҶи§Је…¶з»“жһ„иғҪеё®еҠ©...
Javaдёӯзҡ„й”ҒжңәеҲ¶дё»иҰҒжңүдёӨз§ҚпјҡеҒҸеҗ‘й”Ғ(Biased Locking)гҖҒиҪ»йҮҸзә§й”Ғ(Lightweight Locking)е’ҢйҮҚйҮҸзә§й”Ғ(Heavyweight Locking)гҖӮжӯӨеӨ–пјҢJavaиҝҳжҸҗдҫӣдәҶеҗ„з§ҚеҗҢжӯҘжңәеҲ¶жқҘзЎ®дҝқеӨҡзәҝзЁӢзҺҜеўғдёӢзҡ„ж•°жҚ®е®үе…ЁжҖ§пјҢеҰӮsynchronizedе…ій”®еӯ—гҖҒ...