- 浏览: 1415778 次
- 性别:

- 来自: 广州
-

文章分类
最新评论
-
sdgxxtc:
[quo[color=red]te][/color]
C#使用OleDb读取Excel,生成SQL语句 -
zcs302567601:
博主,你好,一直都有个问题没有搞明白,就是 2.x的版本是通过 ...
NGUI所见即所得之UIPanel -
一样的追寻:
感谢楼主!
有向强连通和网络流大讲堂——史无前例求解最大流(最小割)、最小费用最大流 -
cp1993518:
感谢!从你的博客里学到了很多
Unity日志工具——封装,跳转 -
cp1993518:
学习了~,话说现在的版本custom还真的变委托了
NGUI所见即所得之UIGrid & UITable
交换排序(exchange sorts)算法大串讲
本文内容框架:
§1 冒泡(Bubble Sort)排序及其改进
§2 鸡尾酒(Cocktail Sort)排序
§3 奇偶(Odd-even Sort)排序
§4 快速(Quick Sort)排序及其改进
§5 梳(Comb Sort)排序
§6 地精(Gnome Sort)排序
§7 小结
§1 冒泡(Bubble Sort)排序及其改进
冒泡排序(Bubble Sort)
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。

冒泡排序算法的步骤:
1.比较相邻的元素。如果第一个比第二个大,就交换他们两个。
2.对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。
3.针对所有的元素重复以上的步骤,除了最后一个。
4.持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
#include <stdio.h>
void bubbleSort(int arr[], int count)
{
int i = count, j;
int temp;
while(i > 0)
{
for(j = 0; j < i - 1; j++)
{
if(arr[j] > arr[j + 1])
{ temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
i--;
}
}
int main(int arc, char* const argv[])
{
//测试数据
int arr[] = {5, 4, 1, 3, 6};
//冒泡排序
bubbleSort(arr, 5);
//打印排序结果
int i;
for(i = 0; i < 5; i++)
printf("%4d", arr[i]);
}
冒泡排序算法最坏情况和平均复杂度是O(n²),甚至连插入排序(O(n²)算法复杂度)效率都比冒泡排序算法更好,唯一的优势在于基于它的改进算法——快速排序算法。
冒泡排序算法改进
上述的冒泡排序还可做如下的改进:
(1)记住最后一次交换发生位置index的冒泡排序
1.设置一标志性变量index, 用于记录每趟排序中最后一次进行交换的位置。由于index位置之后的记录均已交换到位, 故在进行下一趟排序时只要扫描到pos位置即可。
void bubbleSort1(int arr[], int count)
{
int i = count, j;
int temp;
int index=i;
while(i > 0)
{
for(j = 0; j < index-1; j++)
{
if(arr[j] > arr[j + 1])
{ temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
index=j;
}
}
i--;
}
}
2.如果某一趟没有数据交换,则表示已经排好序,就可以提前终止循环。
void bubbleSort2(int arr[], int count)
{
int i = count, j;
int temp;
bool isExchange=true;
while(i > 0&&isExchange)
{
isExchange=false;
for(j = 0; j < i - 1; j++)
{
if(arr[j] > arr[j + 1])
{ temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
isExchange=true;
}
}
i--;
}
}
当然上述两种改进方法可以同时使用……
(2) 改变扫描方向的冒泡排序(其实就是鸡尾酒排序算法)
①冒泡排序的不对称性
能一趟扫描完成排序的情况:
只有最轻的气泡位于R[n]的位置,其余的气泡均已排好序,那么也只需一趟扫描就可以完成排序。
【例】对初始关键字序列12,18,42,44,45,67,94,10就仅需一趟扫描。
需要n-1趟扫描完成排序情况:
当只有最重的气泡位于R[1]的位置,其余的气泡均已排好序时,则仍需做n-1趟扫描才能完成排序。
【例】对初始关键字序列:94,10,12,18,42,44,45,67就需七趟扫描。
②造成不对称性的原因
每趟扫描仅能使最重气泡"下沉"一个位置,因此使位于顶端的最重气泡下沉到底部时,需做n-1趟扫描。
③改进不对称性的方法
在排序过程中交替改变扫描方向,可改进不对称性。
void bubbleSort3(int arr[], int count)
{
int hight= count-1, low=0,j;
int temp;
int index=low
while(high> low)
{
for(j = low; j < high; j++)
{
if(arr[j] > arr[j + 1])
{ temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
index=j;
}
}
high=index;
for(j = high; j > low; j--)
{
if(arr[j] > arr[j - 1])
{ temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
index=j;
}
}
low=index;
}
}
§2 鸡尾酒(Cocktail Sort)排序
鸡尾酒排序(cocktai sort)算法
鸡尾酒排序等于是冒泡排序的轻微变形。不同的地方在于扫描方向是从低到高然后从高到低,而冒泡排序则仅从低到高去比较序列里的每个元素。他可以得到比冒泡排序稍微好一点的效能,原因是冒泡排序只从一个方向进行比对(由低到高),每次循环只移动一个项目。

鸡尾酒排序最糟或是平均所花费的次数都是,但如果序列在一开始已经大部分排序过的话,会接近。鸡尾酒排序最糟或是平均所花费的次数都是,但如果序列在一开始已经大部分排序过的话,会接近。
void CockTail(int arr[],int count)
{
int bottom = 0;
int top = count-1;
bool flag = true;
while(flag)
{
flag=false;
for(int i=bottom;i<top;i++)
{
if(arr[i]>arr[i+1])
{
swap(arr[i],arr[i+1]);
flag=true;
}
}
top--;
for(int j=top;j>bottom;j--)
{
if(arr[j-1]>arr[j])
{
swap(arr[j-1],arr[j]);
flag=true;
}
}
bottom++;
}
}
§3 奇偶(Even-old Sort)排序
奇偶排序(Odd-even sort)算法
该算法中,通过比较数组中相邻的(奇-偶)位置数字对,如果该奇偶对是错误的顺序(第一个大于第二个),则交换。下一步重复该操作,但针对所有的(偶-奇)位置数字对。如此交替进行下去。
void oddEvenSort(int *pArr, const int length)
{
int i, tmp;
bool sorted =false;
while(!sorted)
{
sorted=true;
for(i=1; i<length-1; i+=2)
{
if(*(pArr+i)>*(pArr+i+1))
{
sorted=false;
tmp=*(pArr+i);
*(pArr+i)=*(pArr+i+1);
*(pArr+i+1)=tmp;
}
}
for(i=0; i<length-1; i+=2)
{
if(*(pArr+i)>*(pArr+i+1))
{
sorted=false;
tmp=*(pArr+i);
*(pArr+i)=*(pArr+i+1);
*(pArr+i+1)=tmp;
}
}
}
}
§4 快速(Quick Sort)排序
快速排序(quick sort)算法
快速排序是冒泡排序的一种改进,冒泡排序排完一趟是最大值冒出来了,那么可不可以先选定一个值,然后扫描待排序序列,把小于该值的记录和大于该值的记录分成两个单独的序列,然后分别对这两个序列进行上述操作。这就是快速排序,我们把选定的那个值称为枢纽值,如果枢纽值为序列中的最大值,那么一趟快速排序就变成了一趟冒泡排序。

快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。
步骤为:
从数列中挑出一个元素,称为 "基准"(pivot),
重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区退出之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归的最底部情形,是数列的大小是零或一,也就是永远都已经被排序好了。虽然一直递归下去,但是这个算法总会退出,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
//快速排序(两端交替着向中间扫描)
void quickSort1(int *a,int low,int high)
{
int pivotkey=a[low];//以a[low]为枢纽值
int i=low,j=high;
if(low>=high)
return;
//一趟快速排序
while(i<j){//双向扫描
while(i < j && a[j] >= pivotkey)
j--;
a[i]=a[j];
while(i < j && a[i] <= pivotkey)
i++;
a[j]=a[i];
}
a[i]=pivotkey;//放置枢纽值
//分别对左边、右边排序
quickSort1(a,low,i-1);
quickSort1(a,i+1,high);
}
//快速排序(以最后一个记录的值为枢纽值,单向扫描数组)
void quickSort2(int *a,int low,int high)
{
int pivotkey=a[high];//以a[high]为枢纽值
int i=low-1,temp,j;
if(low>=high)
return;
//一趟快速排序
for(j=low;j<high;j++){
if(a[j]<=pivotkey){
i++;
temp=a[i];
a[i]=a[j];
a[j]=temp;
}
}
i++;
//放置枢纽值
temp=a[i];
a[i]=pivotkey;
a[high]=temp;
//分别对左边、右边排序
quickSort2(a,low,i-1);
quickSort2(a,i+1,high);
}
快速排序算法的几种改进
1.随机化算法
基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度
随机化快速排序的唯一缺点在于,一旦输入数据中有很多的相同数据,随机化的效果将直接减弱。对于极限情况,即对于n个相同的数排序,随机化快速排序的时间复杂度将毫无疑问的降低到O(n^2)。
2. 三平均分区法
与一般的快速排序方法不同,它并不是选择待排数组的第一个数作为中轴,而是选用待排数组最左边、最右边和最中间的三个元素的中间值作为中轴。这一改进对于原来的快速排序算法来说,主要有两点优势:
(1) 首先,它使得最坏情况发生的几率减小了。
(2) 其次,未改进的快速排序算法为了防止比较时数组越界,在最后要设置一个哨点。如果在分区排序时,中间的这个元素(也即中轴)是与最右边数过来第二个元素进行交换的话,那么就可以省略与这一哨点值的比较。
关于这一改进还有更进一步的改进,在继续的改进中不仅仅是为了选择更好的中轴才进行左中右三个元素的的比较,它同时将这三个数排好序后按照其顺序放回待排数组,这样就能够保证一个长度为n的待排数组在分区之后最长的子分区的长度为n-2,而不是原来的n-1。也可以在选取中轴值时,可以从由左中右三个中选取扩大到五个元素中或者更多元素中选取,一般的,会有(2t+1)平均分区法(median-of-(2t+1),三平均分区法英文为median-of-three)。
3. 根据分区大小调整算法
减少递归栈使用的优化,快速排序的实现需要消耗递归栈的空间,而大多数情况下都会通过使用系统递归栈来完成递归求解。对系统栈的频繁存取会影响到排序的效率。
快速排序对于小规模的数据集性能不是很好。没有插入性能高。
快速排序算法使用了分治技术,最终来说大的数据集都要分为小的数据集来进行处理。
当数据集较小时,不必继续递归调用快速排序算法,使用插入排序代替快速排序。STL中sort就是用的快排+插入排序的,使得最坏情况下的时间复杂度也是O(nlgn).这一改进被证明比持续使用快速排序算法要有效的多。
4. 不同的分区方案考虑
对于快速排序算法来说,实际上大量的时间都消耗在了分区上面,因此一个好的分区实现是非常重要的。尤其是当要分区的所有的元素值都相等是,一般的快速排序算法就陷入了最坏的一种情况,也即反复的交换相同的元素并返回最差的中轴值。无论是任何数据集,只要它们中包含了很多相同的元素的话,这都是一个严重的问题,因为许多“底层”的分区都会变得完全一样。
对于这种情况的一种改进办法就是将分区分为三块而不是原来的两块:一块是小于中轴值的所有元素,一块是等于中轴值的所有元素,另一块是大于中轴值的所有元素。另一种简单的改进方法是,当分区完成后,如果发现最左和最右两个元素值相等的话就避免递归调用而采用其他的排序算法来完成。
5. 使用多线程:快速排序是分而治之的思想,每个独立的段可以并行进行排序。因此可以利用计算机的并行处理能力来提高排序的性能;
在大多数情况下,创建一个线程所需要的时间要远远大于两个元素比较和交换的时间,因此,快速排序的并行算法不可能为每个分区都创建一个新的线程。一般来说,会在实现代码中设定一个阀值,如果分区的元素数目多于该阀值的话,就创建一个新的线程来处理这个分区的排序,否则的话就进行递归调用来排序。
总的来说,对于快速排序算法的改进主要集中在三个方面:
1 选取一个更好的中轴值
2 根据产生的子分区大小调整算法
3 不同的划分分区的方法
§5 梳(Comb Sort)排序
梳排序(Comb sort)算法
梳排序是改良自冒泡排序和快速排序,在冒泡排序中,只比较阵列中相邻的二项,即比较的二项的间距(Gap)是1,梳排序提出此间距其实可大于1,改自插入排序的希尔排序同样提出相同观点。梳排序中,开始时的间距设定为阵列长度,并在循环中以固定比率递减,通常递减率设定为1.3。在一次循环中,梳排序如同泡沫排序一样把阵列从首到尾扫描一次,比较及交换两项,不同的是两项的间距不固定于1。如果间距递减至1,梳排序假定输入阵列大致排序好,并以冒泡排序作最后检查及修正。O(n*logn)时间复杂度,O(1)空间复杂度,属于不稳定的排序算法。
void combsort(int *arr, int size) {
float shrink_factor = 1.247330950103979;
int gap = size, swapped = 1, swap, i;
while ((gap > 1) || swapped) {
if (gap > 1) gap = gap / shrink_factor;
swapped = 0;
i = 0;
while ((gap + i) < size) {
if (arr[i] - arr[i + gap] > 0) {
swap = arr[i];
arr[i] = arr[i + gap];
arr[i + gap] = swap;
swapped = 1;
}
++i;
}
}
}
梳排序算法举例:
假设输入为 8 4 3 7 6 5 2 1
目标为将之变成递增排序。 因为输入长度=8,开始时设定间距为8÷1.3≒6, 则比较8和2、4和1,并作交换两次。
8 4 3 7 6 5 2 1
2 4 3 7 6 5 8 1
2 1 3 7 6 5 8 4
第二次循环,更新间距为6÷1.3≒4。比较2和6、1和5,直至7和4,此循环中只须交换一次。
2 1 3 7 6 5 8 4
2 1 3 4 6 5 8 7
接下来的每次循环,间距依次递减为3 → 2 → 1,
间距=3时,不须交换
2 1 3 4 6 5 8 7
间距=2时,不须交换
2 1 3 4 6 5 8 7
间距h=1时,交换三次
2 1 3 4 6 5 8 7
1 2 3 4 6 5 8 7
1 2 3 4 5 6 8 7
1 2 3 4 5 6 7 8
上例中,共作了六次交换以完成排序。
§6 地精(Gnome Sort)排序
地精排序(Gnome Sort) 算法
地精排序也叫侏儒排序,是最简单的一种排序算法,它的概念很简单,无需嵌套循环。它的运行时间是Ø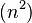 ,但如果列表最初几乎排序趋于O(Ñ)。直接看代码:
,但如果列表最初几乎排序趋于O(Ñ)。直接看代码:
void gnomesort(int n, int ar[]) {
int i = 0;
while (i < n) {
if (i == 0 || ar[i-1] <= ar[i]) i++;
else {int tmp = ar[i]; ar[i] = ar[i-1]; ar[--i] = tmp;}
}
}
写成C++模板函数
template<class T>
void gnome_sort_1(T data[], int n, bool comparator(T, T))
{
int i = 1;
while (i < n)
{
if (i > 0 && comparator(data[i], data[i-1]))
{
swap(data[i], data[i-1]);
i--;
}else
{
i++;
}
}
}
下面直接给出两个改进版本,读者可以自行体会:
template<class T>
void gnome_sort_2(T data[], int n, bool comparator(T, T))
{
int i = 1, previous_position = -1;
while (i < n)
{
if (i > 0 && comparator(data[i], data[i-1]))
{
// Mark the Gnome's previous position before traverse backward
if (previous_position == -1)
{
previous_position = i;
}
swap(data[i], data[i-1]);
i--;
}else
{
if (previous_position == -1)
{
i++;
}else
{
// After traverse backward, go to the position next to the previous
i = previous_position + 1;
previous_position = -1;
}
}
}
}
template<class T>
void gnome_sort_3(T data[], int n, bool comparator(T, T))
{
int i = 0, previous_position = -1;
T temp;
while (i < n)
{
if (i > 0 && comparator(temp, data[i-1]))
{
// Mark the Gnome's previous position before traverse backward
if (previous_position == -1)
{
previous_position = i;
}
data[i] = data[i-1];
i--;
}else
{
if (previous_position == -1)
{
i++;
}else
{
// Put the previous value here
data[i] = temp;
// After traverse backward, go to the position next to the previous
i = previous_position + 1;
previous_position = -1;
}
temp = data[i];
}
}
}
§7 小结
这篇博文列举了选择排序的7个算法,基本可以掌握其中概要,管中窥豹,不求甚解。如果你有任何建议或者批评和补充,请留言指出,不胜感激,更多参考请移步互联网。
参考:
①einstein991225: http://blog.csdn.net/einstein991225/article/details/7957077
②love__coder: http://blog.csdn.net/love__coder/article/details/7914819
③winark: http://blog.csdn.net/winark/article/details/5918944
④更多参考来着维基百科
顶
踩


评论
我之前也没怎么看明白,后来也发现这个图片的真谛,不过这些图片都是维基百科上的,不是作者原创,贴过来就是想有一个很直观的理解……
发表评论

-
C# 调用Delegate.CreateDelegate方法出现“未处理ArgumentException”错误解决
2013-05-31 12:24 3602在C# 调用Delegate.Create ... -
数组问题集结号
2012-12-06 22:01 0数组是最简单的数据结构,数组问题作为公司招聘的笔试和面试题目 ... -
算法问题分析笔记
2012-12-05 11:59 01.Crash Balloon Zhejiang Univer ... -
Java基础进阶整理
2012-11-26 09:59 2353Java学习笔记整理 ... -
Java学习笔记整理
2012-11-24 23:43 211Java学习笔记整理 本文档是我个人 ... -
《C++必知必会》学习笔记
2012-11-24 23:40 2671《C++必知必会》学� ... -
《C++必知必会》学习笔记
2012-11-24 23:34 1《C++必知必会》学习笔� ... -
C语言名题精选百则——排序
2012-11-04 23:29 128第5章排 序 问题5.1 二分插入法(BIN ... -
C语言名题精选百则——查找
2012-11-04 23:29 4187尊重他人的劳动,支持原创 本篇博文,D.S.Q ... -
基本技术——贪心法、分治法、动态规划三大神兵
2012-11-03 19:30 0基本技术——贪心法、分治法、动态规划三大神兵 -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:12 35711优先队列三大利器——二项堆、斐波那契堆、Pairing ... -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:01 3优先队列三大利器——二项堆、斐波那契堆、Pairing 堆 ... -
排序算法群星豪华大汇演
2012-10-30 00:09 3186排序算法群星豪华大汇演 排序算法相对简单些,但是由于 ... -
分布排序(distribution sorts)算法大串讲
2012-10-29 15:33 4700分布排序(distribution sorts)算法大串讲 ... -
归并排序(merge sorts)算法大串讲
2012-10-29 10:04 8347归并排序(merge sorts)算法大串讲 ... -
选择排序(selection sorts)算法大串讲
2012-10-28 12:55 3757选择排序(selection sorts)算法大串讲 本文内 ... -
插入排序(insertion sorts)算法大串讲
2012-10-28 11:30 2780插入排序(insertion sorts� ... -
伸展树(Splay Tree)尽收眼底
2012-10-27 15:11 5615伸展树(Splay Tree)尽收眼底 本文内容 ... -
红黑树(Red-Black Tree)不在话下
2012-10-26 20:54 2265红黑树(Red-Black Tree) 红黑树定义 红黑树 ... -
平衡二叉树(AVL)原理透析和编码解密
2012-10-26 10:22 3042平衡二叉树(AVL)原理透析和编码解密 本文内容 ...
相关推荐
swift-sorts, Swift中,实现了排序算法的集合 Swift 排序 快速实现的排序算法集合。Read Read ,Apples, ,, ,, 。请参见 objective-c 排序和 c 排序比较。算法快速 sorted()快速排序堆排序规则插入排序规则选择...
在计算机科学中,排序是一种基本而重要的数据处理操作,...最后,提及的"sorts-master"文件名称,可能指的是一个包含上述各种排序算法实现的代码库,这样的代码库对于学习、教学或实际项目开发来说都是非常宝贵的资源。
在提供的"sorts"压缩包中,可能包含了上述各种排序算法的C#源代码,你可以使用Visual Studio(VS)打开并运行这些代码,查看每个算法的执行效果。这些代码实例是学习和实践排序算法的好资源,特别适合作为毕业设计...
在提供的压缩包"sorts"中,可能包含了实现这些排序算法的C++源代码。这些代码遵循面向对象的设计原则,结构紧凑,逻辑清晰,是学习和理解这些排序算法的好资源。通过阅读和分析这些代码,我们可以更深入地了解每种...
综上所述,"SORTS.zip 全排序"项目可能涵盖了C#中各种排序算法的实现,以及通过界面展示排序结果和将结果存储为二维数组的功能。对于初学者和经验丰富的开发者来说,这都是一个很好的学习和实践项目。
冒泡排序是一种简单的排序算法,它重复地遍历待排序的数组,比较相邻两个元素,如果它们的顺序错误就把它们交换过来。遍历数组的工作是重复进行的,直到没有再需要交换的元素为止,也就是说该数组已经排序完成。 - ...
JavaScript的排序算法也是理解和优化性能的关键,尤其是当处理大量数据时,选择正确的排序算法和优化方法至关重要。 排序在前端开发中的应用非常广泛,不仅限于简单的列表排序,还包括但不限于搜索、数据处理、用户...
冒泡排序是最基础的排序算法,通过不断地交换相邻的逆序元素逐步达到排序的目的。选择排序则在每一轮中找到剩余未排序部分的最小值或最大值,放到正确的位置。插入排序是将每个元素依次插入到已排序的部分,保持有序...
《sorts:带打字稿的排序算法》 在编程领域,排序算法是核心基础知识之一,对于提升程序效率和理解数据处理逻辑至关重要。本资源主要关注的是使用TypeScript实现的各种排序算法,TypeScript是一种强类型、面向对象的...
本套文件“python-lianxi-sorts.rar”通过一系列的练习,旨在帮助Python初学者通过实际编码的方式掌握各种排序算法。这些练习题将以Python语言编写,通过从易到难的顺序排列,使学习者能够循序渐进地理解并实现每一...
`scala-sorts` 项目专注于展示如何在 Scala 中实现不同的排序算法。这里我们将深入探讨这些算法,以及它们在实际编程中的应用。 首先,让我们了解排序算法的基本概念。排序是将一组数据按照特定顺序排列的过程。在...
堆排序是一种利用堆这种数据结构所设计的一种排序算法,它通过将待排序的序列构造成一个大顶堆或小顶堆,然后进行多次的堆调整,将堆顶元素与未排序元素进行交换,最后得到有序序列。堆排序的时间复杂度稳定在O...
本篇将深入探讨"Sorts.zip"中的C++数据结构实现,特别是排序算法。 在C++中,排序算法是处理数组、向量等数据集合时的重要工具。它们的目标是按照特定规则(如升序或降序)重新排列元素。以下是几种常见的排序算法...
冒泡排序算法是一种基础的排序算法,因其重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,就像水底下的气泡一样,越大的气泡会经过交换慢慢浮到数列的顶端,故称冒泡排序。...
8. **字符串排序(String Sorts)**:091_51StringSorts.pdf 专门讨论字符串的排序问题,涉及到字符串比较的细节和特定的排序算法,如Trie树、Boyer-Moore排序等。 9. **基础符号表(Elementary Symbol Tables)**:061...
排序算法的种类繁多,包括简单排序和高效排序两大类。简单排序如冒泡排序、选择排序和插入排序,虽然实现简单,但效率较低,适用于数据量较小的情况。高效排序包括快速排序、归并排序、堆排序等,这些算法在时间...
排序一些排序算法的时序测试对不起,界面不是很直观……希望如果你能阅读代码,你就能弄清楚如何运行它。 我建议您将输出重定向到一个文件(扩展名为 .csv)并使用电子表格打开。 或者在 GnuPlot 中绘图! 例如使用...
本压缩包“数据结构-C++之11-sorts.zip”聚焦于在C++环境下实现数据排序的算法,包含至少11种不同的排序算法实现。 排序算法是数据结构课程和软件开发中的核心内容之一。它们在提高数据处理效率方面起着关键作用,...
在“python,python-sorts.rar”这个压缩包中,我们很可能找到了关于Python排序算法的资料。排序是计算机科学中的基本概念,它涉及到如何有效地对一组数据进行排列,使得它们按照特定的顺序(如升序或降序)呈现。...
冒泡排序是一种简单的排序算法,通过重复遍历待排序的数列,比较相邻元素的值,如果顺序错误就交换它们的位置,直到没有需要交换的元素为止。选择排序则通过不断选择剩余元素中最小的一个元素并将其放到已排序序列的...