- 浏览: 1415775 次
- 性别:

- 来自: 广州
-

文章分类
最新评论
-
sdgxxtc:
[quo[color=red]te][/color]
C#使用OleDb读取Excel,生成SQL语句 -
zcs302567601:
博主,你好,一直都有个问题没有搞明白,就是 2.x的版本是通过 ...
NGUI所见即所得之UIPanel -
一样的追寻:
感谢楼主!
有向强连通和网络流大讲堂——史无前例求解最大流(最小割)、最小费用最大流 -
cp1993518:
感谢!从你的博客里学到了很多
Unity日志工具——封装,跳转 -
cp1993518:
学习了~,话说现在的版本custom还真的变委托了
NGUI所见即所得之UIGrid & UITable
选择排序(selection sorts)算法大串讲
本文内容框架:
§1 选择排序
§2 锦标赛排序
§3 堆排序
§4 Smooth Sort
§5 小结
§1 选择排序
选择排序(Selection sort)
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。下图能够帮助很直观的理解出选择排序算法的思想:

void select_sort( int *a, int n)
{
register int i, j, min, t;
for( i = 0; i < n - 1; i ++)
{
min = i;
//查找最小值
for( j = i + 1; j < n; j ++)
if( a[ min] > a[ j])
min = j;
//交换
if( min != i)
{
t = a[ min];
a[ min] = a[ i];
a[ i] = t;
}
}
}
选择排序的交换操作介于和次之间。选择排序的比较操作为次之间。选择排序的赋值操作介于和次之间。比较次数O(n^2),比较次数与关键字的初始状态无关,总的比较次数N=(n-1)+(n-2)+...+1=n*(n-1)/2。 交换次数O(n),最好情况是,已经有序,交换0次;最坏情况是,逆序,交换n-1次。 交换次数比冒泡排序少多了,由于交换所需CPU时间比比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
简单选择排序算法改进
传统的简单选择排序,每趟循环只能确定一个元素排序后的定位。我们可以考虑改进为每趟循环确定两个元素(当前趟最大和最小记录)的位置,从而减少排序所需的循环次数。改进后对n个数据进行排序,最多只需进行[n/2]趟循环即可。
§2 锦标赛排序
锦标赛排序(tournament iree sort)
直接选择排序要执行n-1趟(i=0,1,…,n-2),第i越要从n-i个对象中选出一个具有最小排序码的对象,需要进行n-i-1次排序码比较。当n比较大时,排序码比较次数相当多。这是因为在后一趟比较选择时,往往把前一趟已做过的比较又重复做了 一遍,没有把前一趟比较的结果保留下来。
锦标赛排序(tournament iree sort)克服了这一缺点。它的思想与体育比赛类似。首先取得n个对象的排序码,进行两两比较,得到[n/2]个比较的优胜者(排序码小者),作 为第一步比较的结果保留下来。然后对这[n/2]个对象再进行排序码的两两比较,……, 如此重复,直到选出一个排序码最小的对象为止。
#include <stdio.h>
#include <stdlib.h>
int _;
#define swap(x, y) { _=x;x=y;y=_; }
//#define max(x, y) ( ((x)>(y))?(x):(y) )
//#define min(x, y) ( ((x)<(y))?(x):(y) )
#define MAX (int)(((unsigned)(~((int)0)))>>1)
#define MIN (-MAX-1)
void Adjust(int *b, int x, int n)
{
int l = x * 2 + 1;
int r = l + 1;
//printf("%d\n", MAX);
if (l >= n) {
b[x] = MAX;
return;
}
else if (r >= n) {
b[x] = b[l];
return;
}
if (b[l] == b[x]) {
Adjust(b, l, n);
}
else {
Adjust(b, r, n);
}
b[x] = min(b[l], b[r]);
}
void GameSort(int *a, int n)
{
int i, len, *b;
void Out(int *, int);
len = 1;
while (len < n) {
len <<= 1;
}
len = 2 * len - 1;
b = (int *)malloc(sizeof(int) * len);
for (i=len/2; i<len; i++) {
b[i] = (i-len/2<n) ? (a[i-len/2]) : (MAX);
}
for (i=len/2-1; i>=0; i--) {
b[i] = min(b[2 * i + 1], b[2 * i + 2]);
}
for (i=0; i<n; i++) {
a[i] = b[0];
Out(b, len); //不断跟踪输出完全二叉树b[]状态
Adjust(b, 0, len);
}
free(b);
}
int main()
{
int a[] = { 21, 25, 49, 25, 16, 8, 63, 63, 100, 1002 };
int i, n = 9;
for (i=0; i<n; i++) {
printf("%5d", a[i]);
}
printf("\n");
GameSort(a, n);
for (i=0; i<n; i++) {
printf("%5d", a[i]);
}
printf("\n");
return 0;
}
// ---- 输出部分, 与程序算法无关 ----
// ---- 为了打出那个树状, 好看 ----
#include <math.h>
void Out(int *a, int n)
{
void _Out(int *, int);
//printf("%d===\n", n / 2 + 1);
_Out(a + (n / 2), n / 2 + 1);
}
void _Out(int *a, int n)
{
static int i, j, set = 0;
int len = log((double)n) / log((double)2) + 1;
int l, r, have;
int **b = (int **)malloc(sizeof(int *) * len);
for (i=0; i<len; i++) {
b[i] = (int *)malloc(sizeof(int) * n);
for (j=0; j<n; j++) {
b[i][j] = MIN;
}
}
//printf("%d\n", MIN);
for (i=0; i<n; i++) {
b[len - 1][i] = a[i];
}
for (i=len-1; i>=1; i--) {
have = 0;
for (j=0; j<n; j++) {
if (b[i][j] != MIN) {
(++have==1)?(l=j):(r=j);
}
if (have == 2) {
b[i-1][(l+r)/2] = min(b[i][l], b[i][r]);
have = 0;
}
}
}
printf("\n ---- Set %d ----\n", set++);
for (i=0; i<len; i++) {
for (j=0; j<n; j++) {
if (b[i][j] == MIN) {
printf(" ");
}
else if (b[i][j] == MAX) {
printf(" MAX");
}
else {
printf(" %02d", b[i][j]);
}
}
printf("\n");
}
}
§3 堆排序
堆排序(heap sort)
锦标赛算法有两个缺点:辅助存储空间较多、最大值进行多余的比较。堆排序就是在锦标赛排序的基础上改进——只需要O(1)的辅助存储空间,减少最大值的比较。

二叉堆是完全二叉树或者是近似完全二叉树。
二叉堆满足二个特性:
1.父结点的键值总是大于或等于(小于或等于)任何一个子节点的键值。
2.每个结点的左子树和右子树都是一个二叉堆(都是最大堆或最小堆)。
当父结点的键值总是大于或等于任何一个子节点的键值时为最大堆。当父结点的键值总是小于或等于任何一个子节点的键值时为最小堆。下图展示一个最小堆:
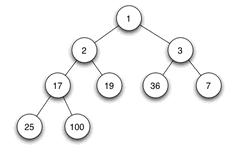
堆的存储
一般都用数组来表示堆,i结点的父结点下标就为(i – 1) / 2。它的左右子结点下标分别为2 * i + 1和2 * i + 2。如第0个结点左右子结点下标分别为1和2。

在堆的数据结构中,堆中的最大值总是位于根节点。堆中定义以下几种操作:
最大堆调整(Max_Heapify):将堆的末端子结点作调整,使得子结点永远小于父结点
创建最大堆(Build_Max_Heap):将堆所有数据重新排序
堆排序(HeapSort):移除位在第一个数据的根结点,并做最大堆调整的递归运算
#include <cstdio>
#include <cstdlib>
#include <cmath>
const int HEAP_SIZE = 13; //堆大小
int parent(int);
int left(int);
int right(int);
void Max_Heapify(int [], int, int);
void Build_Max_Heap(int []);
void print(int []);
void HeapSort(int [], int);
/*父结点*/
int parent(int i)
{
return (int)floor((i - 1) / 2);
}
/*左子结点*/
int left(int i)
{
return (2 * i + 1);
}
/*右子结点*/
int right(int i)
{
return (2 * i + 2);
}
/*从单一子结点创建最大堆*/
void Max_Heapify(int A[], int i, int heap_size)
{
int l = left(i);
int r = right(i);
int largest;
int temp;
if(l < heap_size && A[l] > A[i])
{
largest = l;
}
else
{
largest = i;
}
if(r < heap_size && A[r] > A[largest])
{
largest = r;
}
if(largest != i)
{
temp = A[i];
A[i] = A[largest];
A[largest] = temp;
Max_Heapify(A, largest, heap_size);
}
}
/*建立最大堆*/
void Build_Max_Heap(int A[])
{
for(int i = (HEAP_SIZE-1)/2; i >= 0; i--)
{
Max_Heapify(A, i, HEAP_SIZE);
}
}
/*输出最大堆*/
void print(int A[])
{
for(int i = 0; i < HEAP_SIZE;i++)
{
printf("%d ", A[i]);
}
printf("\n");
}
/*利用堆进行排序*/
void HeapSort(int A[], int heap_size)
{
Build_Max_Heap(A);
int temp;
for(int i = heap_size - 1; i >= 0; i--)
{
temp = A[0];
A[0] = A[i];
A[i] = temp;
Max_Heapify(A, 0, i);
}
print(A);
}
/*测试*/
int main(int argc, char* argv[])
{
int A[HEAP_SIZE] = {19, 1, 10, 14, 16, 4, 7, 9, 3, 2, 8, 5, 11};
HeapSort(A, HEAP_SIZE);
system("pause");
return 0;
}
堆的操作
堆的操作主要是插入和删除,插入总是将插入元素放在堆的末尾,然后进行恢复堆次序处理;删除操作是将要删除元素和最后一个元素替换,然后进行恢复堆次序处理。其实归根结底也是堆的调整操作,只是多了对堆大小(元素个数)的修改)。
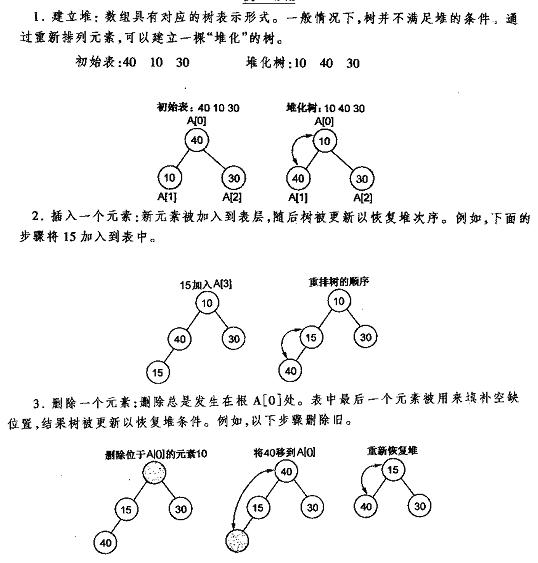
§4 Smooth Sort
Smooth Sort算法
Smooth Sort基本思想和Heap Sort相同,但Smooth Sort使用的是一种由多个堆组成的优先队列,这种优先队列在取出最大元素后剩余元素可以就地调整成优先队列,所以Smooth Sort不用像Heap Sort那样反向地构建堆,在数据基本有序时可以达到O(n)复杂度。Smooth Sort算法在维基百科上有详细介绍。
Smooth Sort是所有算法中时间复杂度理论值最好的,但由于Smooth Sort所用的优先队列是基于一种不平衡的结构,复杂度因子很大,所以该算法的实际效率并不是很好。
#include <cstdio>
#include <cstdlib>
#include <ctime>
static unsigned int set_times = 0;
static unsigned int cmp_times = 0;
template<typename item_type> void setval(item_type& item1, item_type& item2) {
set_times += 1;
item1 = item2;
return;
}
template<typename item_type> int compare(item_type& item1, item_type& item2) {
cmp_times += 1;
return item1 < item2;
}
template<typename item_type> void swap(item_type& item1, item_type& item2) {
item_type item3;
setval(item3, item1);
setval(item1, item2);
setval(item2, item3);
return;
}
static const unsigned int leonardo[] = {
1, 1, 3, 5, 9, 15, 25, 41, 67, 109, 177, 287, 465, 753, 1219, 1973,
3193, 5167, 8361, 13529, 21891, 35421, 57313, 92735, 150049, 242785,
392835, 635621, 1028457, 1664079, 2692537, 4356617, 7049155, 11405773,
18454929, 29860703, 48315633, 78176337, 126491971, 204668309, 331160281,
535828591, 866988873, 1402817465, 2269806339u, 3672623805u,
};
template<typename item_type> inline void smooth_sort_fix(
item_type* array, int current_heap, int level_index, int* levels) {
int prev_heap;
int max_child;
int child_heap1;
int child_heap2;
int current_level;
while(level_index > 0) {
prev_heap = current_heap - leonardo[levels[level_index]];
if(compare(array[current_heap], array[prev_heap])) {
if(levels[level_index] > 1) {
child_heap1 = current_heap - 1 - leonardo[levels[level_index] - 2];
child_heap2 = current_heap - 1;
if(compare(array[prev_heap], array[child_heap1])) break;
if(compare(array[prev_heap], array[child_heap2])) break;
}
swap(array[current_heap], array[prev_heap]);
current_heap = prev_heap;
level_index -= 1;
} else break;
}
current_level = levels[level_index];
while(current_level > 1) {
max_child = current_heap;
child_heap1 = current_heap - 1 - leonardo[current_level - 2];
child_heap2 = current_heap - 1;
if(compare(array[max_child], array[child_heap1])) max_child = child_heap1;
if(compare(array[max_child], array[child_heap2])) max_child = child_heap2;
if(max_child == child_heap1) {
swap(array[current_heap], array[child_heap1]);
current_heap = child_heap1;
current_level -= 1;
}
else if(max_child == child_heap2) {
swap(array[current_heap], array[child_heap2]);
current_heap = child_heap2;
current_level -= 2;
} else break;
}
return;
}
template<typename item_type> void smooth_sort(item_type* array, int size) {
int levels[64] = {1};
int toplevel = 0;
int i;
for(i = 1; i < size; i++) {
if(toplevel > 0 && levels[toplevel - 1] - levels[toplevel] == 1) {
toplevel -= 1;
levels[toplevel] += 1;
} else if(levels[toplevel] != 1) {
toplevel += 1;
levels[toplevel] = 1;
} else {
toplevel += 1;
levels[toplevel] = 0;
}
smooth_sort_fix(array, i, toplevel, levels);
}
for(i = size - 2; i > 0; i--) {
if(levels[toplevel] <= 1) {
toplevel -= 1;
} else {
levels[toplevel] -= 1;
levels[toplevel + 1] = levels[toplevel] - 1;
toplevel += 1;
smooth_sort_fix(array, i - leonardo[levels[toplevel]], toplevel - 1, levels);
smooth_sort_fix(array, i, toplevel, levels);
}
}
return;
}
int main(int argc, char** argv) {
int capacity = 0;
int size = 0;
int i;
clock_t clock1;
clock_t clock2;
double data;
double* array = NULL;
// generate randomized test case
while(scanf("%lf", &data) == 1) {
if(size == capacity) {
capacity = (size + 1) * 2;
array = (double*)realloc(array, capacity * sizeof(double));
}
array[size++] = data;
}
// sort
clock1 = clock();
smooth_sort(array, size);
clock2 = clock();
// output test result
fprintf(stderr, "smooth_sort:\t");
fprintf(stderr, "time %.2lf\t", (double)(clock2 - clock1) / CLOCKS_PER_SEC);
fprintf(stderr, "cmp_per_elem %.2lf\t", (double)cmp_times / size);
fprintf(stderr, "set_per_elem %.2lf\n", (double)set_times / size);
for(i = 0; i < size; i++) {
fprintf(stdout, "%lf\n", array[i]);
}
free(array);
return 0;
}
§5 小结
这篇博文列举了选择排序的几个算法,管中窥豹,不求甚解。如果你有任何建议或者批评和补充,请留言指出,不胜感激,更多参考请移步互联网。
参考:
①MoreWindows: http://blog.csdn.net/morewindows/article/details/6709644
②RichSelian: http://www.cnblogs.com/richselian/archive/2011/09/16/2179148.html
③kapinter: http://zdker.blog.163.com/blog/static/584834200659636560/
④更多参考来着维基百科


发表评论

-
C# 调用Delegate.CreateDelegate方法出现“未处理ArgumentException”错误解决
2013-05-31 12:24 3602在C# 调用Delegate.Create ... -
数组问题集结号
2012-12-06 22:01 0数组是最简单的数据结构,数组问题作为公司招聘的笔试和面试题目 ... -
算法问题分析笔记
2012-12-05 11:59 01.Crash Balloon Zhejiang Univer ... -
Java基础进阶整理
2012-11-26 09:59 2352Java学习笔记整理 ... -
Java学习笔记整理
2012-11-24 23:43 211Java学习笔记整理 本文档是我个人 ... -
《C++必知必会》学习笔记
2012-11-24 23:40 2671《C++必知必会》学� ... -
《C++必知必会》学习笔记
2012-11-24 23:34 1《C++必知必会》学习笔� ... -
C语言名题精选百则——排序
2012-11-04 23:29 128第5章排 序 问题5.1 二分插入法(BIN ... -
C语言名题精选百则——查找
2012-11-04 23:29 4187尊重他人的劳动,支持原创 本篇博文,D.S.Q ... -
基本技术——贪心法、分治法、动态规划三大神兵
2012-11-03 19:30 0基本技术——贪心法、分治法、动态规划三大神兵 -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:12 35711优先队列三大利器——二项堆、斐波那契堆、Pairing ... -
优先队列三大利器——二项堆、斐波那契堆、Pairing 堆
2012-11-03 13:01 3优先队列三大利器——二项堆、斐波那契堆、Pairing 堆 ... -
排序算法群星豪华大汇演
2012-10-30 00:09 3186排序算法群星豪华大汇演 排序算法相对简单些,但是由于 ... -
分布排序(distribution sorts)算法大串讲
2012-10-29 15:33 4700分布排序(distribution sorts)算法大串讲 ... -
归并排序(merge sorts)算法大串讲
2012-10-29 10:04 8347归并排序(merge sorts)算法大串讲 ... -
交换排序(exchange sorts)算法大串讲
2012-10-29 00:22 4443交换排序(exchange sorts)算法大串讲 本 ... -
插入排序(insertion sorts)算法大串讲
2012-10-28 11:30 2779插入排序(insertion sorts� ... -
伸展树(Splay Tree)尽收眼底
2012-10-27 15:11 5615伸展树(Splay Tree)尽收眼底 本文内容 ... -
红黑树(Red-Black Tree)不在话下
2012-10-26 20:54 2265红黑树(Red-Black Tree) 红黑树定义 红黑树 ... -
平衡二叉树(AVL)原理透析和编码解密
2012-10-26 10:22 3042平衡二叉树(AVL)原理透析和编码解密 本文内容 ...
相关推荐
不同排序算法在不同应用场景下的效率差异较大,通常需要根据具体情况选择最合适的排序方法。 在学习这些排序算法的过程中,我们不仅能够提升对算法原理的理解,还能够锻炼编程能力和问题解决能力。掌握这些基本排序...
在提供的"sorts"压缩包中,可能包含了上述各种排序算法的C#源代码,你可以使用Visual Studio(VS)打开并运行这些代码,查看每个算法的执行效果。这些代码实例是学习和实践排序算法的好资源,特别适合作为毕业设计...
swift-sorts, Swift中,实现了排序算法的集合 Swift 排序 快速实现的排序算法集合。Read Read ,Apples, ,, ,, 。请参见 objective-c 排序和 c 排序比较。算法快速 sorted()快速排序堆排序规则插入排序规则选择...
综上所述,"SORTS.zip 全排序"项目可能涵盖了C#中各种排序算法的实现,以及通过界面展示排序结果和将结果存储为二维数组的功能。对于初学者和经验丰富的开发者来说,这都是一个很好的学习和实践项目。
简单选择排序是一种不稳定的排序算法。其基本思想是从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。...
做了个Java Swing 图形界面,选择3中排序方法进行排序。工程用NetBeans 打开,运行Main.java文件或直接点击运行主程序,3种算法在源包中的sorts文件夹...QKSort.java(快速排序算法) SelectSort.java(简单选择排序)
在提供的压缩包"sorts"中,可能包含了实现这些排序算法的C++源代码。这些代码遵循面向对象的设计原则,结构紧凑,逻辑清晰,是学习和理解这些排序算法的好资源。通过阅读和分析这些代码,我们可以更深入地了解每种...
JavaScript的排序算法也是理解和优化性能的关键,尤其是当处理大量数据时,选择正确的排序算法和优化方法至关重要。 排序在前端开发中的应用非常广泛,不仅限于简单的列表排序,还包括但不限于搜索、数据处理、用户...
首先,简单选择排序(Simple Selection Sort)是一种直观的排序算法。它的工作原理是每次遍历未排序序列,找到最小(或最大)元素,存放到排序序列的起始位置,直到全部待排序的数据元素排完。虽然简单,但效率较低...
本篇将深入探讨"Sorts.zip"中的C++数据结构实现,特别是排序算法。 在C++中,排序算法是处理数组、向量等数据集合时的重要工具。它们的目标是按照特定规则(如升序或降序)重新排列元素。以下是几种常见的排序算法...
排序算法的种类繁多,包括简单排序和高效排序两大类。简单排序如冒泡排序、选择排序和插入排序,虽然实现简单,但效率较低,适用于数据量较小的情况。高效排序包括快速排序、归并排序、堆排序等,这些算法在时间...
此外,系统可能还包括了性能分析,比如时间复杂度和空间复杂度的讨论,以及不同数据规模下的运行效率对比,帮助用户了解在实际应用中如何选择合适的排序算法。 总之,"数据结构算法演示系统"是一个强大的学习工具,...
在“python,python-sorts.rar”这个压缩包中,我们很可能找到了关于Python排序算法的资料。排序是计算机科学中的基本概念,它涉及到如何有效地对一组数据进行排列,使得它们按照特定的顺序(如升序或降序)呈现。...
排序算法用于将一组数据按照特定顺序重新排列,常见的排序算法有冒泡排序、选择排序、插入排序、快速排序、归并排序等。每种排序算法都有其独特的应用场景和性能特点,例如冒泡排序简单易懂但效率较低,而快速排序和...
`scala-sorts` 项目专注于展示如何在 Scala 中实现不同的排序算法。这里我们将深入探讨这些算法,以及它们在实际编程中的应用。 首先,让我们了解排序算法的基本概念。排序是将一组数据按照特定顺序排列的过程。在...
排序算法可以分为几大类:如冒泡排序、选择排序、插入排序、快速排序、归并排序等。 ### 1. 冒泡排序(Bubble Sort) 冒泡排序是一种简单的排序算法。它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序...
《sorts:带打字稿的排序算法》 在编程领域,排序算法是核心基础知识之一,对于提升程序效率和理解数据处理逻辑至关重要。本资源主要关注的是使用TypeScript实现的各种排序算法,TypeScript是一种强类型、面向对象的...
冒泡排序算法是一种基础的排序算法,因其重复地走访要排序的数列,一次比较两个元素,如果它们的顺序错误就把它们交换过来,就像水底下的气泡一样,越大的气泡会经过交换慢慢浮到数列的顶端,故称冒泡排序。...
本压缩包“数据结构-C++之11-sorts.zip”聚焦于在C++环境下实现数据排序的算法,包含至少11种不同的排序算法实现。 排序算法是数据结构课程和软件开发中的核心内容之一。它们在提高数据处理效率方面起着关键作用,...
通过本文件包中的14_sorts文件,学生和开发者可以更深入地学习和实践C++中的各种排序算法,这不仅对理解数据结构有帮助,而且对于提升编程能力和解决问题的能力都有非常积极的作用。在实际开发中,掌握这些排序算法...