
ه·² وœ‰çڑ„هپڑو³•وک¯و ¹وچ®ServerIPIndex[QQNUM%n]ه¾—هˆ°è¯·و±‚çڑ„وœچهٹ،ه™¨ï¼Œè؟™ç§چو–¹و³•ه¾ˆو–¹ن¾؟ه°†ç”¨وˆ·هˆ†هˆ°ن¸چهگŒçڑ„وœچهٹ،ه™¨ن¸ٹهژ»م€‚ن½†وک¯ه¦‚وœن¸€هڈ°وœچهٹ،ه™¨و»وژ‰ن؛†ï¼Œ é‚£ن¹ˆnه°±هڈکن¸؛ن؛†n-1,那ن¹ˆServerIPIndex[QQNUM%n]ن¸ژServerIPIndex[QQNUM%(n-1)]هں؛وœ¬ن¸ٹ都ن¸چن¸€و ·ن؛†ï¼Œو‰€ ن»¥ه¤§ه¤ڑو•°ç”¨وˆ·çڑ„请و±‚都ن¼ڑ转هˆ°ه…¶ن»–وœچهٹ،ه™¨ï¼Œè؟™و ·ن¼ڑهڈ‘ç”ںه¤§é‡ڈè®؟问错误م€‚
آ آ é—®ï¼ڑ ه¦‚ن½•و”¹è؟›وˆ–者وچ¢ن¸€ç§چو–¹و³•ï¼Œن½؟ه¾—ï¼ڑ
(1)ن¸€هڈ°وœچهٹ،ه™¨و»وژ‰هگژ,ن¸چن¼ڑé€ وˆگه¤§é¢ç§¯çڑ„è®؟问错误,
(2)هژںوœ‰çڑ„è®؟é—®هں؛وœ¬è؟کوک¯هپœç•™هœ¨هگŒن¸€هڈ°وœچهٹ،ه™¨ن¸ٹï¼›
(3)ه°½é‡ڈ考虑è´ںè½½ه‡è،،م€‚(و€è·¯ï¼ڑه¾€هˆ†ه¸ƒه¼ڈن¸€è‡´ه“ˆه¸Œç®—و³•و–¹é¢è€ƒè™‘م€‚)
- وœ€هœںçڑ„هٹو³•è؟کوک¯ç”¨و¨،ن½™و–¹و³•ï¼ڑهپڑو³•ه¾ˆç®€هچ•ï¼Œهپ‡è®¾وœ‰Nهڈ°وœچهٹ،ه™¨ï¼Œçژ°هœ¨ه®Œه¥½çڑ„وک¯M(M<=N),ه…ˆç”¨Nو±‚و¨،,ه¦‚وœن¸چèگ½هœ¨ه®Œه¥½çڑ„وœ؛ه™¨ن¸ٹ,然هگژه†چ用N-1و±‚و¨،,直هˆ°M.è؟™ç§چو–¹ه¼ڈه¯¹ن؛ژهڈçڑ„وœ؛ه™¨ن¸چه¤ڑçڑ„وƒ…ه†µن¸‹ï¼Œه…·وœ‰و›´ه¥½çڑ„稳ه®ڑو€§م€‚
- ن¸€è‡´و€§ه“ˆه¸Œç®—و³•م€‚
ه؛”用هœ؛و™¯
آ آ هœ¨هپڑوœچهٹ،ه™¨è´ںè½½ه‡è،،و—¶ه€™هڈ¯ن¾›é€‰و‹©çڑ„è´ںè½½ه‡è،،çڑ„ç®—و³•وœ‰ه¾ˆه¤ڑ,هŒ…و‹¬ï¼ڑآ è½®ه¾ھç®—و³•ï¼ˆRound Robin)م€په“ˆه¸Œç®—و³•ï¼ˆHASH)م€پوœ€ه°‘è؟وژ¥ç®—و³•ï¼ˆLeast Connection)م€په“چه؛”é€ںه؛¦ç®—و³•ï¼ˆResponse Time)م€پهٹ وƒو³•ï¼ˆWeighted )ç‰م€‚ه…¶ن¸ه“ˆه¸Œç®—و³•وک¯وœ€ن¸؛ه¸¸ç”¨çڑ„ç®—و³•.
آ آ آ ه…¸ه‹çڑ„ه؛”用هœ؛و™¯وک¯ï¼ڑ وœ‰Nهڈ°وœچهٹ،ه™¨وڈگن¾›ç¼“هکوœچهٹ،,需è¦په¯¹وœچهٹ،ه™¨è؟›è،Œè´ںè½½ه‡è،،,ه°†è¯·و±‚ه¹³ه‡هˆ†هڈ‘هˆ°و¯ڈهڈ°وœچهٹ،ه™¨ن¸ٹ,و¯ڈهڈ°وœ؛ه™¨è´ںè´£1/Nçڑ„وœچهٹ،م€‚
آ آ آ ه¸¸ç”¨çڑ„ç®—و³•وک¯ه¯¹hash结وœهڈ–ن½™و•° (hash() modآ N)ï¼ڑ ه¯¹وœ؛ه™¨ç¼–هڈ·ن»ژ0هˆ°N-1,وŒ‰ç…§è‡ھه®ڑن¹‰çڑ„hash()ç®—و³•ï¼Œه¯¹و¯ڈن¸ھ请و±‚çڑ„hash()ه€¼وŒ‰Nهڈ–و¨،,ه¾—هˆ°ن½™و•°i,然هگژه°†è¯·و±‚هˆ†هڈ‘هˆ°ç¼–هڈ·ن¸؛içڑ„وœ؛ه™¨م€‚ن½†è؟™و ·çڑ„ç®— و³•و–¹و³•هکهœ¨è‡´ه‘½é—®é¢ک,ه¦‚وœوںگن¸€هڈ°وœ؛ه™¨ه®•وœ؛,那ن¹ˆه؛”该èگ½هœ¨è¯¥وœ؛ه™¨çڑ„请و±‚ه°±و— و³•ه¾—هˆ°و£ç،®çڑ„ه¤„çگ†ï¼Œè؟™و—¶éœ€è¦په°†ه½“وژ‰çڑ„وœچهٹ،ه™¨ن»ژç®—و³•ن»ژهژ»é™¤ï¼Œو¤و—¶ه€™ن¼ڑوœ‰(N- 1)/Nçڑ„وœچهٹ،ه™¨çڑ„缓هکو•°وچ®éœ€è¦پé‡چو–°è؟›è،Œè®،ç®—ï¼›ه¦‚وœو–°ه¢ن¸€هڈ°وœ؛ه™¨ï¼Œن¼ڑوœ‰N /(N+1)çڑ„وœچهٹ،ه™¨çڑ„缓هکو•°وچ®éœ€è¦پè؟›è،Œé‡چو–°è®،ç®—م€‚ه¯¹ن؛ژç³»ç»ں而言,è؟™é€ڑه¸¸وک¯ن¸چهڈ¯وژ¥هڈ—çڑ„é¢ ç°¸ï¼ˆه› ن¸؛è؟™و„ڈه‘³ç€ه¤§é‡ڈ缓هکçڑ„ه¤±و•ˆوˆ–者و•°وچ®éœ€è¦پ转移)م€‚é‚£ن¹ˆï¼Œه¦‚ن½•è®¾ è®،ن¸€ن¸ھè´ںè½½ه‡è،،ç–略,ن½؟ه¾—هڈ—هˆ°ه½±ه“چçڑ„请و±‚ه°½هڈ¯èƒ½çڑ„ه°‘ه‘¢ï¼ں
آ آ آ هœ¨Memcachedم€پKey-Value Storeم€پBittorrent DHTم€پLVSن¸éƒ½é‡‡ç”¨ن؛†Consistent Hashingç®—و³•ï¼Œهڈ¯ن»¥è¯´Consistent Hashing وک¯هˆ†ه¸ƒه¼ڈç³»ç»ںè´ںè½½ه‡è،،çڑ„首选算و³•م€‚
Consistent Hashingç®—و³•وڈڈè؟°
آ آ آ ن¸‹é¢ن»¥Memcachedن¸çڑ„Consisten Hashingç®—و³•ن¸؛ن¾‹è¯´وکژم€‚
آ آ consistent hashingآ ç®—و³•و—©هœ¨آ 1997آ ه¹´ه°±هœ¨è®؛و–‡آ Consistent hashing and random treesآ ن¸è¢«وڈگه‡؛,目ه‰چهœ¨آ cacheآ ç³»ç»ںن¸ه؛”用è¶ٹو¥è¶ٹه¹؟و³›ï¼›
1آ هں؛وœ¬هœ؛و™¯
و¯”ه¦‚ن½ وœ‰آ Nآ ن¸ھآ cacheآ وœچهٹ،ه™¨ï¼ˆهگژé¢ç®€ç§°آ cacheآ ),那ن¹ˆه¦‚ن½•ه°†ن¸€ن¸ھه¯¹è±،آ objectآ وک ه°„هˆ°آ Nآ ن¸ھآ cacheآ ن¸ٹه‘¢ï¼Œن½ ه¾ˆهڈ¯èƒ½ن¼ڑ采用类ن¼¼ن¸‹é¢çڑ„é€ڑ用و–¹و³•è®،ç®—آ objectآ çڑ„آ hashآ ه€¼ï¼Œç„¶هگژه‡هŒ€çڑ„وک ه°„هˆ°هˆ°آ Nآ ن¸ھآ cacheآ ï¼›
hash(object)%N
ن¸€هˆ‡éƒ½è؟گè،Œو£ه¸¸ï¼Œه†چ考虑ه¦‚ن¸‹çڑ„ن¸¤ç§چوƒ…ه†µï¼›
- ن¸€ ن¸ھآ cacheآ وœچهٹ،ه™¨آ m downآ وژ‰ن؛†ï¼ˆهœ¨ه®é™…ه؛”用ن¸ه؟…é،»è¦پ考虑è؟™ç§چوƒ…ه†µï¼‰ï¼Œè؟™و ·و‰€وœ‰وک ه°„هˆ°آ cache mآ çڑ„ه¯¹è±،都ن¼ڑه¤±و•ˆï¼Œو€ژن¹ˆهٹ,需è¦پوٹٹآ cache mآ ن»ژآ cacheآ ن¸ç§»é™¤ï¼Œè؟™و—¶ه€™آ cacheآ وک¯آ N-1آ هڈ°ï¼Œوک ه°„ه…¬ه¼ڈهڈکوˆگن؛†آ hash(object)%(N-1)آ ï¼›
- ç”±ن؛ژè®؟é—®هٹ é‡چ,需è¦پو·»هٹ آ cacheآ ,è؟™و—¶ه€™آ cacheآ وک¯آ N+1آ هڈ°ï¼Œوک ه°„ه…¬ه¼ڈهڈکوˆگن؛†آ hash(object)%(N+1)آ ï¼›
آ آ 1آ ه’Œآ 2آ و„ڈه‘³ç€ن»€ن¹ˆï¼ںè؟™و„ڈه‘³ç€çھپ然ن¹‹é—´ه‡ ن¹ژو‰€وœ‰çڑ„آ cacheآ 都ه¤±و•ˆن؛†م€‚ه¯¹ن؛ژوœچهٹ،ه™¨è€Œè¨€ï¼Œè؟™وک¯ن¸€هœ؛çپ¾éڑ¾ï¼Œو´ھو°´èˆ¬çڑ„è®؟问都ن¼ڑç›´وژ¥ه†²هگ‘هگژهڈ°وœچهٹ،ه™¨ï¼›ه†چو¥ 考虑第ن¸‰ن¸ھé—®é¢ک,由ن؛ژç،¬ن»¶èƒ½هٹ›è¶ٹو¥è¶ٹه¼؛,ن½ هڈ¯èƒ½وƒ³è®©هگژé¢و·»هٹ çڑ„èٹ‚点ه¤ڑهپڑ点و´»ï¼Œوک¾ç„¶ن¸ٹé¢çڑ„آ hashآ ç®—و³•ن¹ںهپڑن¸چهˆ°م€‚
آ آ آ وœ‰ن»€ن¹ˆو–¹و³•هڈ¯ن»¥و”¹هڈکè؟™ن¸ھçٹ¶ه†µه‘¢ï¼Œè؟™ه°±وک¯consistent hashingم€‚
2 hashآ ç®—و³•ه’Œهچ•è°ƒو€§
م€€ Hashآ ç®—و³•çڑ„ن¸€ن¸ھè،،é‡ڈوŒ‡و ‡وک¯هچ•è°ƒو€§ï¼ˆآ Monotonicityآ ),ه®ڑن¹‰ه¦‚ن¸‹ï¼ڑ
م€€ هچ•è°ƒو€§وک¯وŒ‡ه¦‚وœه·²ç»ڈوœ‰ن¸€ن؛›ه†…ه®¹é€ڑè؟‡ه“ˆه¸Œهˆ†و´¾هˆ°ن؛†ç›¸ه؛”çڑ„缓ه†²ن¸ï¼Œهڈˆوœ‰و–°çڑ„缓ه†²هٹ ه…¥هˆ°ç³»ç»ںن¸م€‚ه“ˆه¸Œçڑ„结وœه؛”能ه¤ںن؟è¯پهژںوœ‰ه·²هˆ†é…چçڑ„ه†…ه®¹هڈ¯ن»¥è¢«وک ه°„هˆ°و–°çڑ„缓ه†²ن¸هژ»ï¼Œè€Œن¸چن¼ڑ被وک ه°„هˆ°و—§çڑ„缓ه†²é›†هگˆن¸çڑ„ه…¶ن»–缓ه†²هŒ؛م€‚
آ آ ه®¹وک“看هˆ°ï¼Œن¸ٹé¢çڑ„简هچ•آ hashآ ç®—و³•آ hash(object)%Nآ éڑ¾ن»¥و»،足هچ•è°ƒو€§è¦پو±‚م€‚
3 consistent hashingآ ç®—و³•çڑ„هژںçگ†
آ آ consistent hashingآ وک¯ن¸€ç§چآ hashآ ç®—و³•ï¼Œç®€هچ•çڑ„说,هœ¨ç§»é™¤آ /آ و·»هٹ ن¸€ن¸ھآ cacheآ و—¶ï¼Œه®ƒèƒ½ه¤ںه°½هڈ¯èƒ½ه°ڈçڑ„و”¹هڈکه·²هکهœ¨آ keyآ وک ه°„ه…³ç³»ï¼Œه°½هڈ¯èƒ½çڑ„و»،足هچ•è°ƒو€§çڑ„è¦پو±‚م€‚
آ آ ن¸‹é¢ه°±و¥وŒ‰ç…§آ 5آ ن¸ھو¥éھ¤ç®€هچ•è®²è®²آ consistent hashingآ ç®—و³•çڑ„هں؛وœ¬هژںçگ†م€‚
3.1آ çژ¯ه½¢hashآ ç©؛é—´
آ آ 考虑é€ڑه¸¸çڑ„آ hashآ ç®—و³•éƒ½وک¯ه°†آ valueآ وک ه°„هˆ°ن¸€ن¸ھآ 32آ ن¸؛çڑ„آ keyآ ه€¼ï¼Œن¹ںهچ³وک¯آ 0~2^32-1آ و¬،و–¹çڑ„و•°ه€¼ç©؛é—´ï¼›وˆ‘ن»¬هڈ¯ن»¥ه°†è؟™ن¸ھç©؛é—´وƒ³è±،وˆگن¸€ن¸ھ首(آ 0آ )ه°¾ï¼ˆآ 2^32-1آ )相وژ¥çڑ„هœ†çژ¯ï¼Œه¦‚ن¸‹é¢ه›¾آ 1آ و‰€ç¤؛çڑ„é‚£و ·م€‚

ه›¾آ 1آ çژ¯ه½¢آ hashآ ç©؛é—´
3.2آ وٹٹه¯¹è±،وک ه°„هˆ°hashآ ç©؛é—´
آ آ وژ¥ن¸‹و¥è€ƒè™‘آ 4آ ن¸ھه¯¹è±،آ object1~object4آ ,é€ڑè؟‡آ hashآ ه‡½و•°è®،ç®—ه‡؛çڑ„آ hashآ ه€¼آ keyآ هœ¨çژ¯ن¸ٹçڑ„هˆ†ه¸ƒه¦‚ه›¾آ 2آ و‰€ç¤؛م€‚
hash(object1) = key1;
… …
hash(object4) = key4;

ه›¾آ 2 4آ ن¸ھه¯¹è±،çڑ„آ keyآ ه€¼هˆ†ه¸ƒ
3.3آ وٹٹcacheآ وک ه°„هˆ°hashآ ç©؛é—´
آ آ Consistent hashingآ çڑ„هں؛وœ¬و€وƒ³ه°±وک¯ه°†ه¯¹è±،ه’Œآ cacheآ 都وک ه°„هˆ°هگŒن¸€ن¸ھآ hashآ و•°ه€¼ç©؛é—´ن¸ï¼Œه¹¶ن¸”ن½؟用相هگŒçڑ„hashآ ç®—و³•م€‚
آ آ هپ‡è®¾ه½“ه‰چوœ‰آ A,Bآ ه’Œآ Cآ ه…±آ 3آ هڈ°آ cacheآ ,那ن¹ˆه…¶وک ه°„结وœه°†ه¦‚ه›¾آ 3آ و‰€ç¤؛,ن»–ن»¬هœ¨آ hashآ ç©؛é—´ن¸ï¼Œن»¥ه¯¹ه؛”çڑ„آ hashه€¼وژ’هˆ—م€‚
hash(cache A) = key A;
… …
hash(cache C) = key C;

ه›¾آ 3 cacheآ ه’Œه¯¹è±،çڑ„آ keyآ ه€¼هˆ†ه¸ƒ
آ
آ آ 说هˆ°è؟™é‡Œï¼Œé،؛ن¾؟وڈگن¸€ن¸‹آ cacheآ çڑ„آ hashآ è®،算,ن¸€èˆ¬çڑ„و–¹و³•هڈ¯ن»¥ن½؟用آ cacheآ وœ؛ه™¨çڑ„آ IPآ هœ°ه€وˆ–者وœ؛ه™¨هگچن½œن¸؛hashآ 输ه…¥م€‚
3.4آ وٹٹه¯¹è±،وک ه°„هˆ°cache
آ آ çژ°هœ¨آ cacheآ ه’Œه¯¹è±،都ه·²ç»ڈé€ڑè؟‡هگŒن¸€ن¸ھآ hashآ ç®—و³•وک ه°„هˆ°آ hashآ و•°ه€¼ç©؛é—´ن¸ن؛†ï¼Œوژ¥ن¸‹و¥è¦پ考虑çڑ„ه°±وک¯ه¦‚ن½•ه°†ه¯¹è±،وک ه°„هˆ°آ cacheآ ن¸ٹé¢ن؛†م€‚
آ آ هœ¨è؟™ن¸ھçژ¯ه½¢ç©؛é—´ن¸ï¼Œه¦‚وœو²؟ç€é،؛و—¶é’ˆو–¹هگ‘ن»ژه¯¹è±،çڑ„آ keyآ ه€¼ه‡؛هڈ‘,直هˆ°éپ‡è§پن¸€ن¸ھآ cacheآ ,那ن¹ˆه°±ه°†è¯¥ه¯¹è±،هکه‚¨هœ¨è؟™ن¸ھآ cacheآ ن¸ٹ,ه› ن¸؛ه¯¹è±، ه’Œآ cacheآ çڑ„آ hashآ ه€¼وک¯ه›؛ه®ڑçڑ„,ه› و¤è؟™ن¸ھآ cacheآ ه؟…然وک¯ه”¯ن¸€ه’Œç،®ه®ڑçڑ„م€‚è؟™و ·ن¸چه°±و‰¾هˆ°ن؛†ه¯¹è±،ه’Œآ cacheآ çڑ„وک ه°„و–¹و³•ن؛†هگ—ï¼ںï¼پ
آ آ ن¾ç„¶ç»§ç»ن¸ٹé¢çڑ„ن¾‹هگ(هڈ‚è§په›¾آ 3آ ),那ن¹ˆو ¹وچ®ن¸ٹé¢çڑ„و–¹و³•ï¼Œه¯¹è±،آ object1آ ه°†è¢«هکه‚¨هˆ°آ cache Aآ ن¸ٹï¼›آ object2ه’Œآ object3آ ه¯¹ه؛”هˆ°آ cache Cآ ï¼›آ object4آ ه¯¹ه؛”هˆ°آ cache Bآ ï¼›
3.5آ 考ه¯ںcacheآ çڑ„هڈکهٹ¨
آ آ ه‰چé¢è®²è؟‡ï¼Œé€ڑè؟‡آ hashآ 然هگژو±‚ن½™çڑ„و–¹و³•ه¸¦و¥çڑ„وœ€ه¤§é—®é¢که°±هœ¨ن؛ژن¸چ能و»،足هچ•è°ƒو€§ï¼Œه½“آ cacheآ وœ‰و‰€هڈکهٹ¨و—¶ï¼Œcacheآ ن¼ڑه¤±و•ˆï¼Œè؟›è€Œه¯¹هگژهڈ°وœچهٹ،ه™¨é€ وˆگه·¨ه¤§çڑ„ه†²ه‡»ï¼Œçژ°هœ¨ه°±و¥هˆ†وگهˆ†وگآ consistent hashingآ ç®—و³•م€‚
3.5.1آ 移除آ cache
آ آ 考虑هپ‡è®¾آ cache Bآ وŒ‚وژ‰ن؛†ï¼Œو ¹وچ®ن¸ٹé¢è®²هˆ°çڑ„وک ه°„و–¹و³•ï¼Œè؟™و—¶هڈ—ه½±ه“چçڑ„ه°†ن»…وک¯é‚£ن؛›و²؟آ cache Bآ 逆و—¶é’ˆéپچهژ†ç›´هˆ°ن¸‹ن¸€ن¸ھآ cacheآ (آ cache Cآ )ن¹‹é—´çڑ„ه¯¹è±،,ن¹ںهچ³وک¯وœ¬و¥وک ه°„هˆ°آ cache Bآ ن¸ٹçڑ„é‚£ن؛›ه¯¹è±،م€‚
آ آ ه› و¤è؟™é‡Œن»…需è¦پهڈکهٹ¨ه¯¹è±،آ object4آ ,ه°†ه…¶é‡چو–°وک ه°„هˆ°آ cache Cآ ن¸ٹهچ³هڈ¯ï¼›هڈ‚è§په›¾آ 4آ م€‚

ه›¾آ 4 Cache Bآ 被移除هگژçڑ„آ cacheآ وک ه°„
3.5.2آ و·»هٹ آ cache
آ آ ه†چ考虑و·»هٹ ن¸€هڈ°و–°çڑ„آ cache Dآ çڑ„وƒ…ه†µï¼Œهپ‡è®¾هœ¨è؟™ن¸ھçژ¯ه½¢آ hashآ ç©؛é—´ن¸ï¼Œآ cache Dآ 被وک ه°„هœ¨ه¯¹è±،آ object2آ ه’Œobject3آ ن¹‹é—´م€‚è؟™و—¶هڈ—ه½±ه“چçڑ„ه°†ن»…وک¯é‚£ن؛›و²؟آ cache Dآ 逆و—¶é’ˆéپچهژ†ç›´هˆ°ن¸‹ن¸€ن¸ھآ cacheآ (آ cache Bآ )ن¹‹é—´çڑ„ه¯¹è±،(ه®ƒن»¬وک¯ن¹ںوœ¬و¥وک ه°„هˆ°آ cache Cآ ن¸ٹه¯¹è±،çڑ„ن¸€éƒ¨هˆ†ï¼‰ï¼Œه°†è؟™ن؛›ه¯¹è±،é‡چو–°وک ه°„هˆ°آ cache Dآ ن¸ٹهچ³هڈ¯م€‚
آ آ ه› و¤è؟™é‡Œن»…需è¦پهڈکهٹ¨ه¯¹è±،آ object2آ ,ه°†ه…¶é‡چو–°وک ه°„هˆ°آ cache Dآ ن¸ٹï¼›هڈ‚è§په›¾آ 5آ م€‚

ه›¾آ 5آ و·»هٹ آ cache Dآ هگژçڑ„وک ه°„ه…³ç³»
4آ è™ڑو‹ںèٹ‚点
考é‡ڈآ Hashآ ç®—و³•çڑ„هڈ¦ن¸€ن¸ھوŒ‡و ‡وک¯ه¹³è،،و€§آ (Balance)آ ,ه®ڑن¹‰ه¦‚ن¸‹ï¼ڑ
ه¹³è،،و€§
م€€م€€ه¹³è،،و€§وک¯وŒ‡ه“ˆه¸Œçڑ„结وœèƒ½ه¤ںه°½هڈ¯èƒ½هˆ†ه¸ƒهˆ°و‰€وœ‰çڑ„缓ه†²ن¸هژ»ï¼Œè؟™و ·هڈ¯ن»¥ن½؟ه¾—و‰€وœ‰çڑ„缓ه†²ç©؛间都ه¾—هˆ°هˆ©ç”¨م€‚
آ آ hashآ ç®—و³•ه¹¶ن¸چوک¯ن؟è¯پç»ه¯¹çڑ„ه¹³è،،,ه¦‚وœآ cacheآ 较ه°‘çڑ„è¯ï¼Œه¯¹è±،ه¹¶ن¸چ能被ه‡هŒ€çڑ„وک ه°„هˆ°آ cacheآ ن¸ٹ,و¯”ه¦‚هœ¨ن¸ٹé¢çڑ„ن¾‹هگن¸ï¼Œن»…部署آ cache Aآ ه’Œآ cache Cآ çڑ„وƒ…ه†µن¸‹ï¼Œهœ¨آ 4آ ن¸ھه¯¹è±،ن¸ï¼Œآ cache Aآ ن»…هکه‚¨ن؛†آ object1آ ,而آ cache Cآ هˆ™هکه‚¨ن؛†آ object2آ م€پآ object3آ ه’Œآ object4آ ï¼›هˆ†ه¸ƒوک¯ه¾ˆن¸چه‡è،،çڑ„م€‚
آ آ ن¸؛ن؛†è§£ه†³è؟™ç§چوƒ…ه†µï¼Œآ consistent hashingآ ه¼•ه…¥ن؛†â€œè™ڑو‹ںèٹ‚点â€çڑ„و¦‚ه؟µï¼Œه®ƒهڈ¯ن»¥ه¦‚ن¸‹ه®ڑن¹‰ï¼ڑ
“è™ڑو‹ںèٹ‚点â€ï¼ˆآ virtual nodeآ )وک¯ه®é™…èٹ‚点هœ¨آ hashآ ç©؛é—´çڑ„ه¤چهˆ¶ه“پ(آ replicaآ ),ن¸€ه®é™…ن¸ھèٹ‚点ه¯¹ه؛”ن؛†è‹¥ه¹²ن¸ھ“è™ڑو‹ںèٹ‚点â€ï¼Œè؟™ن¸ھه¯¹ه؛”ن¸ھو•°ن¹ںوˆگن¸؛“ه¤چهˆ¶ن¸ھو•°â€ï¼Œâ€œè™ڑو‹ںèٹ‚点â€هœ¨آ hashآ ç©؛é—´ن¸ن»¥آ hashآ ه€¼وژ’هˆ—م€‚
آ آ ن»چن»¥ن»…部署آ cache Aآ ه’Œآ cache Cآ çڑ„وƒ…ه†µن¸؛ن¾‹ï¼Œهœ¨ه›¾آ 4آ ن¸وˆ‘ن»¬ه·²ç»ڈ看هˆ°ï¼Œآ cacheآ هˆ†ه¸ƒه¹¶ن¸چه‡هŒ€م€‚çژ°هœ¨وˆ‘ن»¬ه¼•ه…¥è™ڑو‹ںèٹ‚点,ه¹¶è®¾ç½®â€œه¤چهˆ¶ن¸ھو•°â€ن¸؛آ 2آ ,è؟™ه°±و„ڈه‘³ç€ن¸€ه…±ن¼ڑهک هœ¨آ 4آ ن¸ھ“è™ڑو‹ںèٹ‚点â€ï¼Œآ cache A1, cache A2آ ن»£è،¨ن؛†آ cache Aآ ï¼›آ cache C1, cache C2آ ن»£è،¨ن؛†آ cache Cآ ï¼›هپ‡è®¾ن¸€ç§چو¯”较çگ†وƒ³çڑ„وƒ…ه†µï¼Œهڈ‚è§په›¾آ 6آ م€‚

ه›¾آ 6آ ه¼•ه…¥â€œè™ڑو‹ںèٹ‚点â€هگژçڑ„وک ه°„ه…³ç³»
آ
آ آ و¤و—¶ï¼Œه¯¹è±،هˆ°â€œè™ڑو‹ںèٹ‚点â€çڑ„وک ه°„ه…³ç³»ن¸؛ï¼ڑ
objec1->cache A2آ ï¼›آ objec2->cache A1آ ï¼›آ objec3->cache C1آ ï¼›آ objec4->cache C2آ ï¼›
آ آ ه› و¤ه¯¹è±،آ object1آ ه’Œآ object2آ 都被وک ه°„هˆ°ن؛†آ cache Aآ ن¸ٹ,而آ object3آ ه’Œآ object4آ وک ه°„هˆ°ن؛†آ cache Cآ ن¸ٹï¼›ه¹³è،،و€§وœ‰ن؛†ه¾ˆه¤§وڈگé«کم€‚
آ آ ه¼•ه…¥â€œè™ڑو‹ںèٹ‚点â€هگژ,وک ه°„ه…³ç³»ه°±ن»ژآ {آ ه¯¹è±،آ ->آ èٹ‚点آ }آ 转وچ¢هˆ°ن؛†آ {آ ه¯¹è±،آ ->آ è™ڑو‹ںèٹ‚点آ }آ م€‚وں¥è¯¢ç‰©ن½“و‰€هœ¨آ cacheو—¶çڑ„وک ه°„ه…³ç³»ه¦‚ه›¾آ 7آ و‰€ç¤؛م€‚
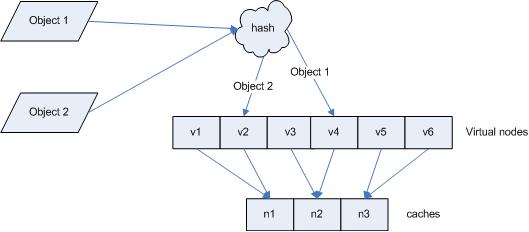
ه›¾آ 7آ وں¥è¯¢ه¯¹è±،و‰€هœ¨آ cache
آ
آ آ “è™ڑو‹ںèٹ‚点â€çڑ„آ hashآ è®،ç®—هڈ¯ن»¥é‡‡ç”¨ه¯¹ه؛”èٹ‚点çڑ„آ IPآ هœ°ه€هٹ و•°ه—هگژç¼€çڑ„و–¹ه¼ڈم€‚ن¾‹ه¦‚هپ‡è®¾آ cache Aآ çڑ„آ IPآ هœ°ه€ن¸؛202.168.14.241آ م€‚
آ آ ه¼•ه…¥â€œè™ڑو‹ںèٹ‚点â€ه‰چ,è®،ç®—آ cache Aآ çڑ„آ hashآ ه€¼ï¼ڑ
Hash(“202.168.14.241â€);
آ آ ه¼•ه…¥â€œè™ڑو‹ںèٹ‚点â€هگژ,è®،算“è™ڑو‹ںèٹ‚â€ç‚¹آ cache A1آ ه’Œآ cache A2آ çڑ„آ hashآ ه€¼ï¼ڑ
Hash(“202.168.14.241#1â€);آ آ // cache A1
Hash(“202.168.14.241#2â€);آ آ // cache A2



相ه…³وژ¨èچگ
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وœ€هˆç”±é؛»çœپçگ†ه·¥ه¦é™¢çڑ„Kç‰ن؛؛وڈگه‡؛,ه¹¶è¢«ه¹؟و³›ه؛”用ن؛ژهˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œن»¥è§£ه†³èٹ‚点هٹ¨و€پهڈکهŒ–و—¶و•°وچ®ن¸€è‡´و€§é—®é¢کم€‚ه…¶و ¸ه؟ƒو€وƒ³وک¯é€ڑè؟‡ه¼•ه…¥ه“ˆه¸Œçژ¯ï¼Œه°†و•°وچ®ه¯¹è±،ه‡هŒ€هˆ†ه¸ƒهœ¨ه“ˆه¸Œçژ¯ن¸ٹçڑ„ن¸چهگŒèٹ‚点ن¸ï¼Œن»¥و¤é™چن½ژèٹ‚点هڈکو›´ه¯¹...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯ن¸€ç§چهœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸è§£ه†³و•°وچ®هˆ†ç‰‡ه’Œè´ںè½½ه‡è،،é—®é¢کçڑ„ç®—و³•ï¼Œه®ƒن¸»è¦پ解ه†³ن؛†هœ¨هٹ¨و€پو·»هٹ وˆ–移除èٹ‚点و—¶ï¼Œه°½هڈ¯èƒ½ه°‘هœ°و”¹هڈکه·²ç»ڈهکهœ¨çڑ„و•°وچ®هˆ†ه¸ƒم€‚هœ¨ن؛‘è®،ç®—ه’Œه¤§و•°وچ®ه¤„çگ†é¢†هںں,ن¸€è‡´و€§ه“ˆه¸Œè¢«ه¹؟و³›ه؛”用,ن¾‹ه¦‚هœ¨هˆ†ه¸ƒه¼ڈ...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•é€ڑè؟‡ه°†ه“ˆه¸Œه€¼ç©؛间组织وˆگن¸€ن¸ھè™ڑو‹ںçڑ„çژ¯çٹ¶ç»“و„,ن½؟ه¾—و¯ڈن¸ھهکه‚¨èٹ‚点ن»…è´ںè´£çژ¯ن¸ٹçڑ„ن¸€و®µهŒ؛هںں,ن»ژ而وœ‰و•ˆه‡ڈه°‘ن؛†èٹ‚点هڈکهŒ–و—¶çڑ„و•°وچ®è؟پ移é‡ڈم€‚然而,ن¸€è‡´و€§ه“ˆه¸Œç®—و³•ن¹ںهکهœ¨ن¸€ن؛›é—®é¢ک,و¯”ه¦‚هœ¨èٹ‚点و•°é‡ڈ较ه°‘و—¶ï¼Œèٹ‚点间çڑ„...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯ن¸€ç§چهˆ†ه¸ƒه¼ڈه“ˆه¸Œï¼ˆDistributed Hash Table, DHT)وٹ€وœ¯ï¼Œه®ƒè§£ه†³ن؛†هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸و•°وچ®هˆ†ç‰‡ه’Œè´ںè½½ه‡è،،çڑ„é—®é¢کم€‚هœ¨ن¼ ç»ںçڑ„ه“ˆه¸Œç®—و³•ن¸ï¼Œه¦‚وœه¢هٹ وˆ–ه‡ڈه°‘وœچهٹ،ه™¨èٹ‚点,ن¼ڑه¯¼è‡´ه¤§é‡ڈو•°وچ®é‡چو–°هˆ†é…چ,而ن¸€è‡´و€§ه“ˆه¸Œ...
وœ¬و–‡é’ˆه¯¹è؟™ن¸€é—®é¢ک,و·±ه…¥ç ”究ن؛†ن¸€è‡´و€§ه“ˆه¸Œç®—و³•هœ¨هˆ†ه¸ƒه¼ڈو•°وچ®ه؛“و‰©ه±•ن¸çڑ„ه؛”用,ه¹¶وڈگه‡؛ن؛†ن¸€ç§چهˆ›و–°çڑ„و‰©ه±•و–¹و³•ï¼Œو—¨هœ¨وڈگé«کو‰©ه±•و•ˆçژ‡ï¼Œé™چن½ژو‰©ه±•وˆگوœ¬ï¼Œن¸؛ه¤§و•°وچ®çژ¯ه¢ƒن¸‹çڑ„و•°وچ®ه؛“ç®،çگ†ه¸¦و¥و–°çڑ„ن¼کهŒ–و–¹و،ˆم€‚ ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وœ€هˆç”±...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯ن¸€ç§چهˆ†ه¸ƒه¼ڈه“ˆه¸Œè،¨ï¼ˆDHT)ن¸ç”¨ن؛ژ解ه†³و•°وچ®هˆ†ç‰‡ه’Œè´ںè½½ه‡è،،é—®é¢کçڑ„ç®—و³•م€‚هœ¨ه¤§ه‹هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œن¾‹ه¦‚缓هکç³»ç»ںم€پهˆ†ه¸ƒه¼ڈو•°وچ®ه؛“ç‰ï¼Œن¸€è‡´و€§ه“ˆه¸Œèƒ½ه¤ںç،®ن؟ه½“èٹ‚点هٹ ه…¥وˆ–离ه¼€و—¶ï¼Œه°½هڈ¯èƒ½ه°‘çڑ„و•°وچ®éœ€è¦پè؟پ移,ن»ژ而ن؟وŒپ...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯ن¸€ç§چهˆ†ه¸ƒه¼ڈه“ˆه¸Œï¼ˆDistributed Hash Table, DHT)وٹ€وœ¯ï¼Œو—¨هœ¨è§£ه†³هœ¨هˆ†ه¸ƒه¼ڈçژ¯ه¢ƒن¸و•°وچ®هˆ†ه¸ƒن¸چه‡هŒ€çڑ„é—®é¢کم€‚Ketamaç®—و³•وک¯هں؛ن؛ژن¸€è‡´و€§ه“ˆه¸Œçڑ„ن¸€ç§چن¼کهŒ–ه®çژ°ï¼Œç”±Last.fmه…¬هڈ¸çڑ„Simon Willisonوڈگه‡؛,ه…¶ç›®و ‡وک¯هœ¨...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯ن¸€ç§چهœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ç”¨ن؛ژ解ه†³و•°وچ®هˆ†هڈ‘ه’Œè´ںè½½ه‡è،،é—®é¢کçڑ„ç®—و³•م€‚éڑڈç€ن؛’èپ”网وٹ€وœ¯çڑ„ه؟«é€ںهڈ‘ه±•ï¼Œهˆ†ه¸ƒه¼ڈç³»ç»ںه·²ç»ڈوˆگن¸؛و”¯و’‘ه¤§è§„و¨،وœچهٹ،çڑ„ه…³é”®وٹ€وœ¯ن¹‹ن¸€م€‚هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ï¼Œه¤ڑن¸ھèٹ‚点é€ڑè؟‡ç½‘络هچڈهگŒه·¥ن½œï¼Œوڈگن¾›é«کهڈ¯ç”¨و€§...
### ن¸€è‡´و€§ه“ˆه¸Œç®—و³•هڈٹه…¶هœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸çڑ„ه؛”用 #### و‘کè¦پ ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯ن¸€ç§چ用ن؛ژ解ه†³هˆ†ه¸ƒه¼ڈç³»ç»ںن¸èٹ‚点هٹ¨و€پهڈکهŒ–ه¯¼è‡´çڑ„و•°وچ®é‡چو–°هˆ†ه¸ƒé—®é¢کçڑ„ه…³é”®وٹ€وœ¯م€‚ه®ƒé€ڑè؟‡ه°†ه“ˆه¸Œç©؛é—´وک ه°„هˆ°ن¸€ن¸ھه¾ھçژ¯çڑ„ç©؛é—´ن¸ï¼Œه®çژ°ن؛†و•°وچ®èٹ‚点çڑ„é«کو•ˆ...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•ه؛”用هڈٹن¼کهŒ–وک¯IT领هںںن¸هˆ†ه¸ƒه¼ڈç³»ç»ں设è®،çڑ„و ¸ه؟ƒوٹ€وœ¯ن¹‹ن¸€ï¼Œç‰¹هˆ«وک¯هœ¨ه¤„çگ†ه¤§è§„و¨،و•°وچ®هˆ†ه¸ƒن¸ژ缓هکç³»ç»ںن¸ï¼Œه…¶é‡چè¦پو€§ن¸چ言而ه–»م€‚وœ¬و–‡ه°†و·±ه…¥وژ¢è®¨ن¸€è‡´و€§ه“ˆه¸Œç®—و³•çڑ„هں؛وœ¬و¦‚ه؟µم€په·¥ن½œهژںçگ†ن»¥هڈٹهœ¨ه®é™…هœ؛و™¯ن¸çڑ„ه؛”用ه’Œن¼کهŒ–...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•ن½œن¸؛解ه†³è؟™ن¸€é—®é¢کçڑ„é‡چè¦پو‰‹و®µن¹‹ن¸€ï¼Œè؟‘ن؛›ه¹´و¥ه¾—هˆ°ن؛†ه¹؟و³›ه…³و³¨ه’Œه؛”用م€‚ ن¸€è‡´و€§ه“ˆه¸Œç®—و³•ç”±David Kargerç‰ن؛؛هœ¨1997ه¹´وڈگه‡؛,ه®ƒوک¯ن¸€ç§چ特و®ٹçڑ„ه“ˆه¸Œç®—و³•ï¼Œن¸»è¦پ用ن؛ژهˆ†ه¸ƒه¼ڈç³»ç»ںن¸ه®çژ°è´ںè½½ه‡è،،م€‚ن¸ژن¼ ç»ںçڑ„ه“ˆه¸Œç®—و³•...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•
白è¯è§£وگï¼ڑن¸€è‡´و€§ه“ˆه¸Œç®—و³•1 ن¸€è‡´و€§ه“ˆه¸Œç®—و³•وک¯è§£ه†³هˆ†ه¸ƒه¼ڈ缓هکé—®é¢کçڑ„解ه†³و–¹و،ˆم€‚缓هکوœچهٹ،ه™¨و•°é‡ڈçڑ„هڈکهŒ–ن¼ڑه¼•èµ·ç¼“هکçڑ„é›ھه´©ï¼Œه¯¼è‡´و•´ن½“ç³»ç»ںهژ‹هٹ›è؟‡ه¤§è€Œه´©و؛ƒم€‚ن¸؛ن؛†è§£ه†³è؟™ن¸ھé—®é¢ک,ن¸€è‡´و€§ه“ˆه¸Œç®—و³•è¯ç”ںن؛†م€‚ هœ¨ن؛†è§£ن¸€è‡´و€§ه“ˆه¸Œ...
ن¸€è‡´و€§ه“ˆه¸Œç®—و³•ï¼ˆConsistent Hashing)وک¯ن¸€ç§چهœ¨هˆ†ه¸ƒه¼ڈç³»ç»ںن¸ه®çژ°è´ںè½½ه‡è،،çڑ„ç®—و³•ï¼Œه°¤ه…¶هœ¨هˆ†ه¸ƒه¼ڈ缓هکه¦‚Memcachedه’ŒRedisç‰هœ؛و™¯ن¸‹ه¹؟و³›ن½؟用م€‚ه®ƒè§£ه†³ن؛†ن¼ ç»ںه“ˆه¸Œç®—و³•هœ¨èٹ‚点ه¢ه‡ڈو—¶ه¯¼è‡´çڑ„ه¤§é‡ڈو•°وچ®è؟پ移问é¢ک,وڈگé«کن؛†ç³»ç»ںçڑ„هڈ¯ç”¨...
وœ¬é،¹ç›®ن»¥â€œهں؛ن؛ژNIO-EPOOLو¨،ه‹nettyه®çژ°çڑ„ه…·ه¤‡ن¸€è‡´و€§ه“ˆه¸Œç®—و³•çڑ„NAT端هڈ£وک ه°„ه™¨â€ن¸؛ن¸»é¢ک,و·±ه…¥وژ¢è®¨ن؛†Nettyهœ¨NAT端هڈ£وک ه°„ن¸çڑ„ه؛”用,ن»¥هڈٹن¸€è‡´و€§ه“ˆه¸Œç®—و³•هœ¨و¤è؟‡ç¨‹ن¸çڑ„ن½œç”¨م€‚ 首ه…ˆï¼Œوˆ‘ن»¬و¥ن؛†è§£NIO(Non-blocking I/O,é...
#资و؛گè¾¾ن؛؛هˆ†ن؛«è®،هˆ’#
#资و؛گè¾¾ن؛؛هˆ†ن؛«è®،هˆ’#
وœ¬و–‡ه°†وژ¢è®¨ن¸€ن¸ھهگچن¸؛"ufire-springcloud-platform"çڑ„é،¹ç›®ï¼Œè¯¥é،¹ç›®وک¯هں؛ن؛ژن¸€è‡´و€§ه“ˆه¸Œç®—و³•ه®çژ°WebSocketهˆ†ه¸ƒه¼ڈو‰©ه±•çڑ„ن¸€و¬،ه°è¯•ï¼Œه¹¶ç»“هگˆJenkinsم€پGitHub Hookه’ŒDocker Composeه®çژ°ن؛†è‡ھهٹ¨هŒ–وŒپç»éƒ¨ç½²م€‚ 1. **ن¸€è‡´و€§ه“ˆه¸Œç®—و³•...